阅读完需:约 18 分钟
在集群数据库里,数据库的读写分离也是常见的优化手段。
读写分离有很多种方式可以来实现,比如用sharding-jdbc等框架来实现,不过这里用最简单的方式。
方案使用了AbstractRoutingDataSource和mybatis plugin来动态的选择数据源选择这个方案的原因主要是不需要改动原有业务代码,非常友好
其实这个方案就是个多数据源的实现方式,之前都有过实践,这里再次记录一下,主要之前搭建了PG数据库集群需要读写分离来发挥集群的作用。
首先,我们需要两个数据库实例,一为master,一为slave。
所有的写操作,我们在master节点上操作
所有的读操作,我们在slave节点上操作
默认已经按照上面的集群搭建好了
需要注意的是:对于一次有读有写的事务,事务内的读操作也不应该在slave节点上,所有操作都应该在master节点上
整个实现主要有3个部分:
- 配置两个数据源
- 实现
AbstractRoutingDataSource来动态的使用数据源 - 实现
mybatis plugin来动态的选择数据源
Pom依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3.1</version>
</dependency>配置数据源
将数据库连接信息配置到application.yml文件中
spring:
datasource:
write:
type: com.zaxxer.hikari.HikariDataSource
username: ${DB_USER:liantu}
password: ${DB_PASSWD:liantu123}
url: jdbc:postgresql://${DB_HOST:82.157.173.00}:${DB_PORT:5000}/${DB_NAME:test}?currentSchema=${DB_SCHEMA:useroauth}&useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8
driver-class-name: org.postgresql.Driver
read:
type: com.zaxxer.hikari.HikariDataSource
username: ${DB_USER:liantu}
password: ${DB_PASSWD:liantu123}
url: jdbc:postgresql://${DB_HOST:82.157.173.00}:${DB_PORT:5001}/${DB_NAME:test}?currentSchema=${DB_SCHEMA:useroauth}&useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8
driver-class-name: org.postgresql.Driverwrite写数据源,对应到master节点的5000端口
read读数据源,对应到slave节点的5001端口
将两个数据源信息注入为DataSourceProperties:
@Configuration
public class DataSourcePropertiesConfig {
@Primary
@Bean("writeDataSourceProperties")
@ConfigurationProperties("spring.datasource.write")
public DataSourceProperties writeDataSourceProperties() {
return new DataSourceProperties();
}
@Bean("readDataSourceProperties")
@ConfigurationProperties("spring.datasource.read")
public DataSourceProperties readDataSourceProperties() {
return new DataSourceProperties();
}
}实现AbstractRoutingDataSource
spring提供了AbstractRoutingDataSource,提供了动态选择数据源的功能,替换原有的单一数据源后,即可实现读写分离:
@Component
public class CustomRoutingDataSource extends AbstractRoutingDataSource {
@Resource(name = "writeDataSourceProperties")
private DataSourceProperties writeProperties;
@Resource(name = "readDataSourceProperties")
private DataSourceProperties readProperties;
@Override
public void afterPropertiesSet() {
DataSource writeDataSource =
writeProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
DataSource readDataSource =
readProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
setDefaultTargetDataSource(writeDataSource);
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(DataSourceHolder.WRITE_DATASOURCE, writeDataSource);
dataSourceMap.put(DataSourceHolder.READ_DATASOURCE, readDataSource);
setTargetDataSources(dataSourceMap);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey() {
String key = DataSourceHolder.getDataSource();
if (key == null) {
// default datasource
return DataSourceHolder.WRITE_DATASOURCE;
}
return key;
}
}
AbstractRoutingDataSource内部维护了一个Map<Object, Object>的Map在初始化过程中,我们将write、read两个数据源加入到这个map调用数据源时:determineCurrentLookupKey()方法返回了需要使用的数据源对应的key
当前线程需要使用的数据源对应的key,是在DataSourceHolder类中维护的:
public class DataSourceHolder {
public static final String WRITE_DATASOURCE = "write";
public static final String READ_DATASOURCE = "read";
private static final ThreadLocal<String> LOCAL = new ThreadLocal<>();
private DataSourceHolder(){}
public static void putDataSource(String dataSource) {
LOCAL.set(dataSource);
}
public static String getDataSource() {
return LOCAL.get();
}
public static void clearDataSource() {
LOCAL.remove();
}
}关于AbstractRoutingDataSource的源码解释
/**
* DataSource的实现:根据一个指定的key,调用各种的目标的数据源。 之后,通常根据一些线程的事务上下文来指定数据源。
*/
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {
/**
* 目标数据源
*/
@Nullable
private Map<Object, Object> targetDataSources;
/**
* 默认的数据源
*/
@Nullable
private Object defaultTargetDataSource;
/**
* ??
*/
private boolean lenientFallback = true;
/**
* 数据源查找??
*/
private DataSourceLookup dataSourceLookup = new JndiDataSourceLookup();
@Nullable
private Map<Object, DataSource> resolvedDataSources;
/**
* 被处理之后的数据源??
*/
@Nullable
private DataSource resolvedDefaultDataSource;
/**
* 根据指定查找的key获取目标数据源的映射,
* 映射的值可以是一个DataSource的实例,也可以是String。如果是String的话,会通过setDataSourceLookup方法进行解析。
* 指定的key可以是任意类型,这个类仅仅实现了通用的查找过程,具体的key标识将由resolveSpecifiedLookupKey(Object)方法和
* determineCurrentLookupKey()进行解析。
* 也就是说:
* #1.如果我们自己定义了Map中的value是字符串的话,就需要重写setDataSourceLookup这个方法进行返回正确的数据源。
* #2.如果我们自己定义了Map中的key的话,我们就需要重写resolveSpecifiedLookupKey方法和determineCurrentLookupKey()。
*/
public void setTargetDataSources(Map<Object, Object> targetDataSources) {
this.targetDataSources = targetDataSources;
}
/**
* 指定默认的数据源(如果存在的话)
* 如果我们自己定义了Map中的value是字符串的话,就需要重写setDataSourceLookup这个方法进行返回正确的数据源。
* 如果根据指定的key在targetDataSources中找不到Datasource的时候,就用使用这个默认的数据源。
*/
public void setDefaultTargetDataSource(Object defaultTargetDataSource) {
this.defaultTargetDataSource = defaultTargetDataSource;
}
/**
* 如果找不到指定的Datsource的时候,可以通知指定lenientFallback来确定是否使用默认数据源
* true: 找不到就会使用默认数据源
* false: 仅在key为null的时候进行回退。即当key为null的时候才使用默认的数据源,否则就会抛出IllegalStateException异常
*/
public void setLenientFallback(boolean lenientFallback) {
this.lenientFallback = lenientFallback;
}
/**
* 解析setTargetDataSource中数据源名称是dataSource的情况,默认值是JndiDataSourceLookup。
*/
public void setDataSourceLookup(@Nullable DataSourceLookup dataSourceLookup) {
this.dataSourceLookup = (dataSourceLookup != null ? dataSourceLookup : new JndiDataSourceLookup());
}
@Override
public void afterPropertiesSet() {
if (this.targetDataSources == null) {
throw new IllegalArgumentException("Property 'targetDataSources' is required");
}
this.resolvedDataSources = new HashMap<>(this.targetDataSources.size());
this.targetDataSources.forEach((key, value) -> {
Object lookupKey = resolveSpecifiedLookupKey(key);
DataSource dataSource = resolveSpecifiedDataSource(value);
this.resolvedDataSources.put(lookupKey, dataSource);
});
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource = resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}
/**
* 解析指定的key,对应着setTargetDataSources#2的情况。
* 默认是直接返回
*/
protected Object resolveSpecifiedLookupKey(Object lookupKey) {
return lookupKey;
}
/**
* 将指定的数据源对象解析为DataSource实例
* 默认是通过:setDataSourceLookup进行解析。
* 如果是字符串的话,可以用通过setDataSourceLookup设置自定义的dataSourceLookup。
*/
protected DataSource resolveSpecifiedDataSource(Object dataSource) throws IllegalArgumentException {
if (dataSource instanceof DataSource) {
return (DataSource) dataSource;
} else if (dataSource instanceof String) {
return this.dataSourceLookup.getDataSource((String) dataSource);
} else {
throw new IllegalArgumentException(
"Illegal data source value - only [javax.sql.DataSource] and String supported: " + dataSource);
}
}
@Override
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return determineTargetDataSource().getConnection(username, password);
}
@Override
@SuppressWarnings("unchecked")
public <T> T unwrap(Class<T> iface) throws SQLException {
if (iface.isInstance(this)) {
return (T) this;
}
return determineTargetDataSource().unwrap(iface);
}
@Override
public boolean isWrapperFor(Class<?> iface) throws SQLException {
return (iface.isInstance(this) || determineTargetDataSource().isWrapperFor(iface));
}
/**
* 检索当前目标数据源。
* 调用determineCurrentLookupKey获取key,在targetDataSources中进行查找,是否要会回退,使用默认数据源。
* 如果找不到数据源就抛出IllegalStateException异常。
*/
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
/**
* 确定当前查找建。
* 通常会实现这个方法类检测线程绑定的事务上下文.
* 返回的key需要与targetDatasources这个Map中的key的类型进行匹配,由resolveSpecifiedLookupKey进行解析。
*/
@Nullable
protected abstract Object determineCurrentLookupKey();
}实现Mybatis Plugin
上面提到了当前线程使用的数据源对应的key,这个key需要在mybatis plugin根据sql类型来确定 MybatisDataSourceInterceptor类:
@Component
@Intercepts({
@Signature(type = Executor.class, method = "update",
args = {MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class,
CacheKey.class, BoundSql.class})})
public class MybatisDataSourceInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
boolean synchronizationActive = TransactionSynchronizationManager.isSynchronizationActive();
if(!synchronizationActive) {
Object[] objects = invocation.getArgs();
MappedStatement ms = (MappedStatement) objects[0];
if (ms.getSqlCommandType().equals(SqlCommandType.SELECT)) {
if(!ms.getId().contains(SelectKeyGenerator.SELECT_KEY_SUFFIX)) {
DataSourceHolder.putDataSource(DataSourceHolder.READ_DATASOURCE);
return invocation.proceed();
}
}
}
DataSourceHolder.putDataSource(DataSourceHolder.WRITE_DATASOURCE);
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
}
}仅当未在事务中,并且调用的sql是select类型时,在DataSourceHolder中将数据源设为read其他情况下,AbstractRoutingDataSource会使用默认的write数据源
关于Mybatis插件的解释如下
至此,项目已经可以自动的在读、写数据源间切换,无需修改原有的业务代码
AbstractRoutingDataSource探究
多数据源让人最头痛的,不是配置多个数据源,而是如何能灵活动态的切换数据源。我们在spring配置中往往是配置一个dataSource来连接数据库,然后绑定给sessionFactory,在dao层代码中再指定sessionFactory来进行数据库操作。

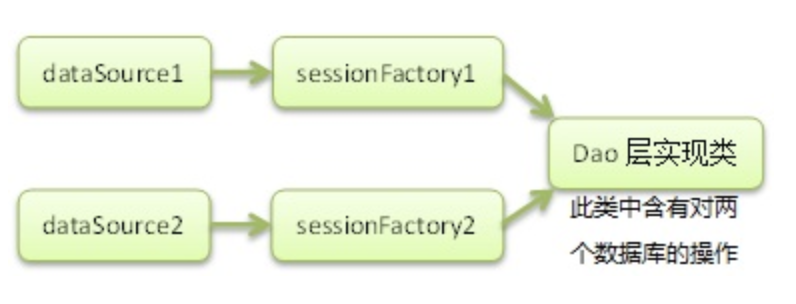
这是单数据源到多数据源的演变,具有多个SessionFactory,不具有灵活性,而且太笨重了。如果再加一个数据源,就需要再加一个SessionFactory。
SessionFactory,就是用来创建session会话(具体接下来讲)的工厂。如果存在多个Sessionfactory 那么Session是不是就乱套了,因此这种架构不可取。那么下面这种架构就应用而生。
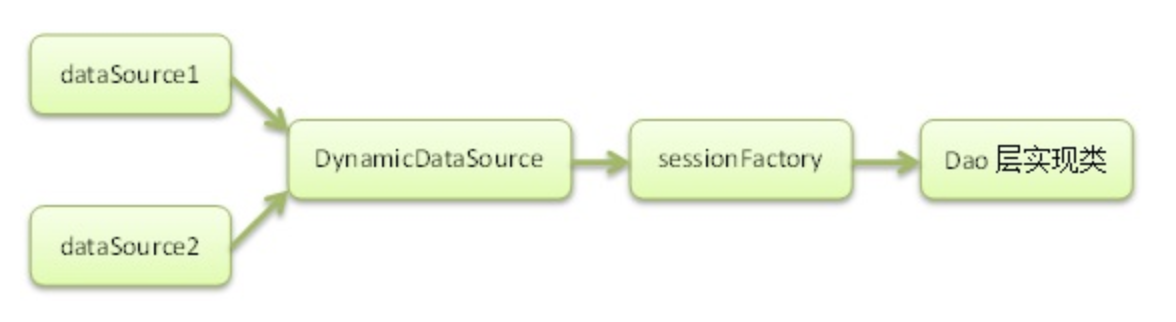
Spring的AbstractRoutingDataSource就是采用这种架构。
设计源码
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {
……
}
扩展Spring的AbstractRoutingDataSource抽象类(该类充当了DataSource的路由中介, 能有在运行时, 根据某种key值来动态切换到真正的DataSource上。)
从上可以看出它继承了AbstractDataSource,而AbstractDataSource不就是javax.sql.DataSource的子类吗,So我们可以分析下它的getConnection方法:
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}
public Connection getConnection(String username, String password) throws SQLException {
return determineTargetDataSource().getConnection(username, password);
}
获取连接的方法中,重点是determineTargetDataSource方法,看源码:
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
上面这段源码的重点在于determineCurrentLookupKey()方法,这是AbstractRoutingDataSource类中的一个抽象方法,而它的返回值是你所要用的数据源dataSource的key值,有了这个key值,resolvedDataSource(这是个map,由配置文件中设置好后存入的)就从中取出对应的DataSource,如果找不到,就用配置默认的数据源。
你要扩展AbstractRoutingDataSource类,并重写其中的determineCurrentLookupKey方法,来实现数据源的切换:
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 获取数据源(依赖于spring)
* @author linhy
*/
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey() {
return DataSourceHolder.getDataSource();
}
}
注意事项
关于读取数据库配置信息问题
上面的获取配置信息的时候是将DataSourceProperties注册为Bean,但是如果将DataSource注册为bean,那么会导致无法切换数据源,猜测是因为DataSource默认就是单数据源了(比如说在配置Druid数据库的时候使用DruidDataSourceBuilder.create().build()来创建数据源,很容易就将数据源注册为Bean了)
@Configuration
public class DataSourcePropertiesConfig {
@Primary
@Bean("writeDataSourceProperties")
@ConfigurationProperties("spring.datasource.write")
public DataSourceProperties writeDataSourceProperties() {
return new DataSourceProperties();
}
@Bean("readDataSourceProperties")
@ConfigurationProperties("spring.datasource.read")
public DataSourceProperties readDataSourceProperties() {
return new DataSourceProperties();
}
}关于读取Mybatis-Plus配置信息问题
因为Mybatis-Plus的版本变化,旧版本的Plus配置插件只需要将插件注册为Bean即可,新版本需要将插件注册到SqlSessionFactory中
因为旧版本的Plus插件是和Mybatis一致都是实现Interceptor接口,而新版的Plus是整合了Mybatis的内容实现InnerInterceptor接口
而在注册插件时手动创建SqlSessionFactory的Bean时会导致MybatisPlus全局配置失效,比如:
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
typeEnumsPackage: com.linktopa.framework.domain.ucenter.entity.enums
global-config:
db-config:
id-type: auto
schema: ucenter
logic-delete-field: exist
logic-delete-value: false
logic-not-delete-value: true
configuration:
map-underscore-to-camel-case: true
call-setters-on-nulls: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl不生效原因:配置多数据源后,数据源对应的SqlSessionFactoryBean是单独设置的,没有加载在properties内的config配置
解决方案:重新将配置set到SqlSessionFactoryBean中
/** 全局自定义配置 */
@Bean(name = "globalConfig")
@ConfigurationProperties(prefix = "mybatis-plus.global-config")
public GlobalConfig globalConfig(){
return new GlobalConfig();
}
@Bean(name = "mybatisConfiguration")
@ConfigurationProperties(prefix = "mybatis-plus.configuration")
public MybatisConfiguration mybatisConfiguration(){
return new MybatisConfiguration();
} @Bean
public SqlSessionFactory
sqlSessionFactory(DataSource dataSource,
MybatisPlusInterceptor plusInterceptor,
MybatisPlusProperties mybatisProperties) throws Exception {
// 当使用myBatis-plus的时候需要使用 MybatisSqlSessionFactoryBean
MybatisSqlSessionFactoryBean sessionFactory = new MybatisSqlSessionFactoryBean();
sessionFactory.setDataSource(dataSource);
sessionFactory.setPlugins(plusInterceptor);
sessionFactory.setConfiguration(mybatisProperties.getConfiguration());
sessionFactory.setTypeEnumsPackage("com.linktopa.framework.domain.ucenter.entity.enums");
// 设置全局配置
sessionFactory.setGlobalConfig(globalConfig);
sessionFactory.setConfiguration(mybatisConfiguration);
// 插件安装
final MybatisDataSourceInterceptor dataSourceInterceptor= new MybatisDataSourceInterceptor();
sessionFactory.getConfiguration().addInterceptor(dataSourceInterceptor);
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sessionFactory.setMapperLocations(resolver.getResources("classpath:mapper/*.xml"));
return sessionFactory.getObject();
}
关于使用Druid连接池配置信息失效问题
在前面我使用的是Hikari,如果使用Druid那么需要使用以下方式配置信息,配置信息的参数与在yml配置文件的配置信息一致
@Override
public void afterPropertiesSet() {
DruidDataSource writeDataSource =
writeProperties.initializeDataSourceBuilder().type(DruidDataSource.class).build();
writeDataSource.setTimeBetweenConnectErrorMillis(3000);
DruidDataSource readDataSource =
readProperties.initializeDataSourceBuilder().type(DruidDataSource.class).build();
readDataSource.setTimeBetweenConnectErrorMillis(3000);
setDefaultTargetDataSource(writeDataSource);
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(DataSourceHolder.WRITE_DATASOURCE, writeDataSource);
dataSourceMap.put(DataSourceHolder.READ_DATASOURCE, readDataSource);
setTargetDataSources(dataSourceMap);
super.afterPropertiesSet();
}关于@Transactional事务注解导致无法切换数据源问题
在项目运行的时候,遇到了一个很大的问题,那就是很多方法上都有@Transactional,按照之前的Mybatsi插件代码,遇到事务会默认用主库进行读写
但是项目中添加了事务注解的代码,有读操作和写操作,读操作在写操作前面执行,导致数据源一开始是读库,但是后面无法切换成主库进行写操作,导致报错。
问题根源:
@transactional–>TransactionInterceptor.invoke()–>TransactionAspectSupport.createTransactionIfNecessary()–>AbstractPlatformTransactionManager.getTransaction()–>DataSourceTransactionManager.doBegin()–>AbstractRoutingDataSource.determineTargetDataSource()[lookupKey==null去拿默认的Datasource, 不为空则使用获取到的连接]–>TransactionSynchronizationManager.bindResource()[将连接将连接holder绑定到线程]—>Repository@Annotation–>执行一般调用链, 问题在于SpringManagedTransaction.getConnection()–>openConnection()–>DataSourceUtils.getConnection()–>TransactionSynchronizationManager.getResource(dataSource)不为空[从TransactionUtils的threadLocal中获取数据源], 所以不会再去调用DynamicDataSource去获取数据源
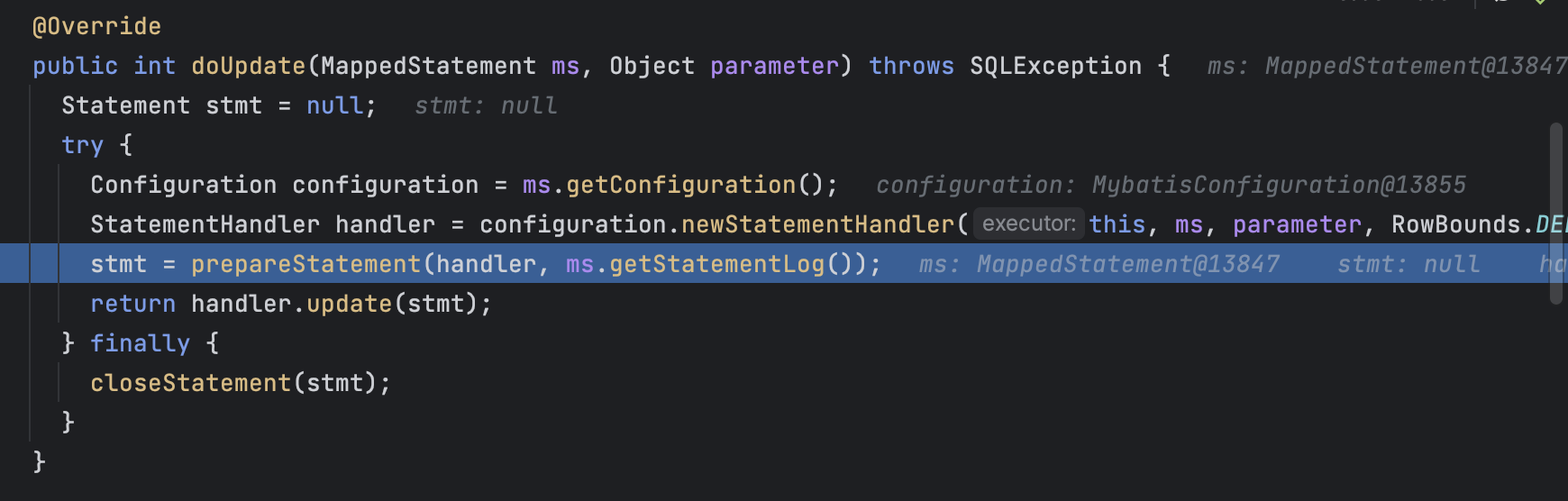

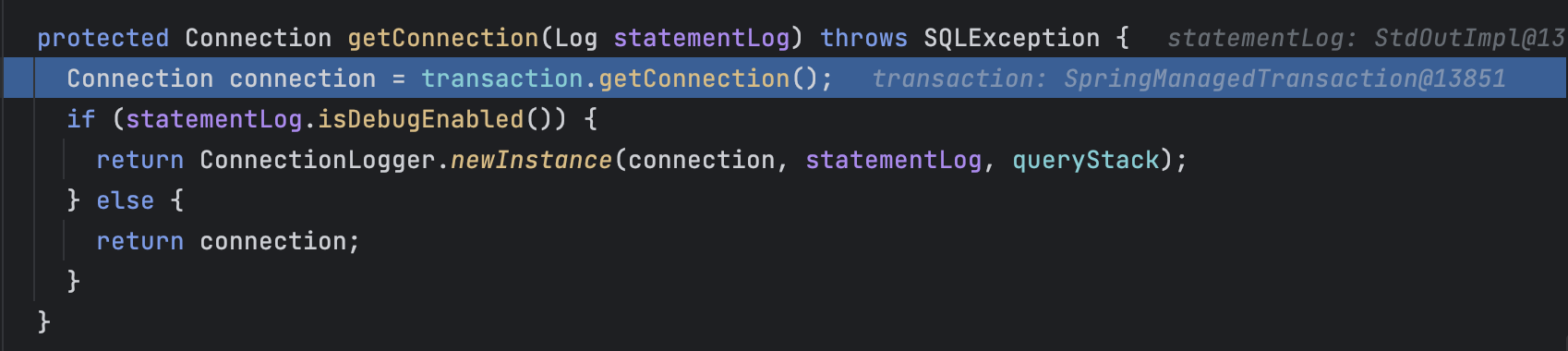

在这里如果没有连接会去获取连接
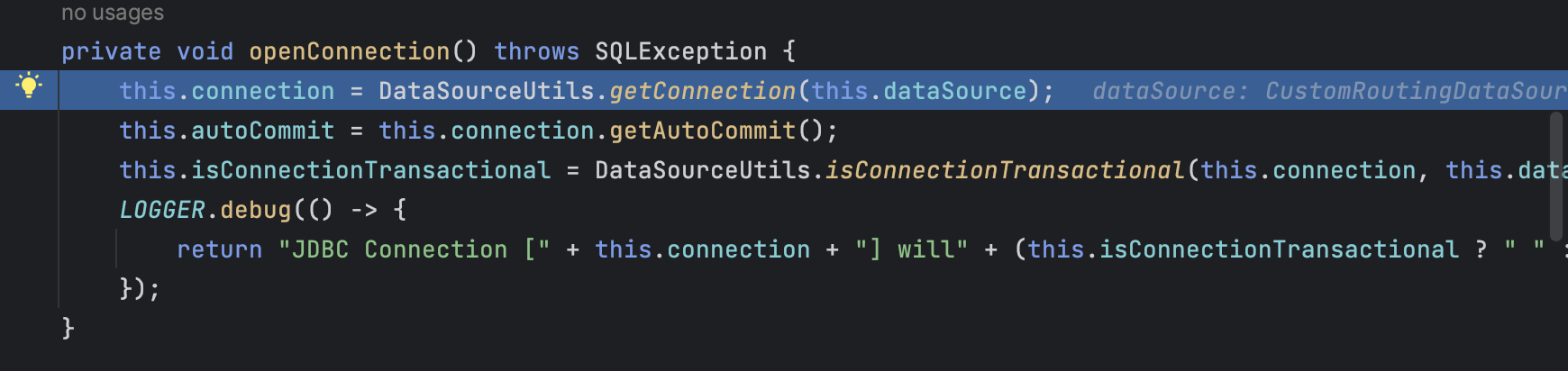
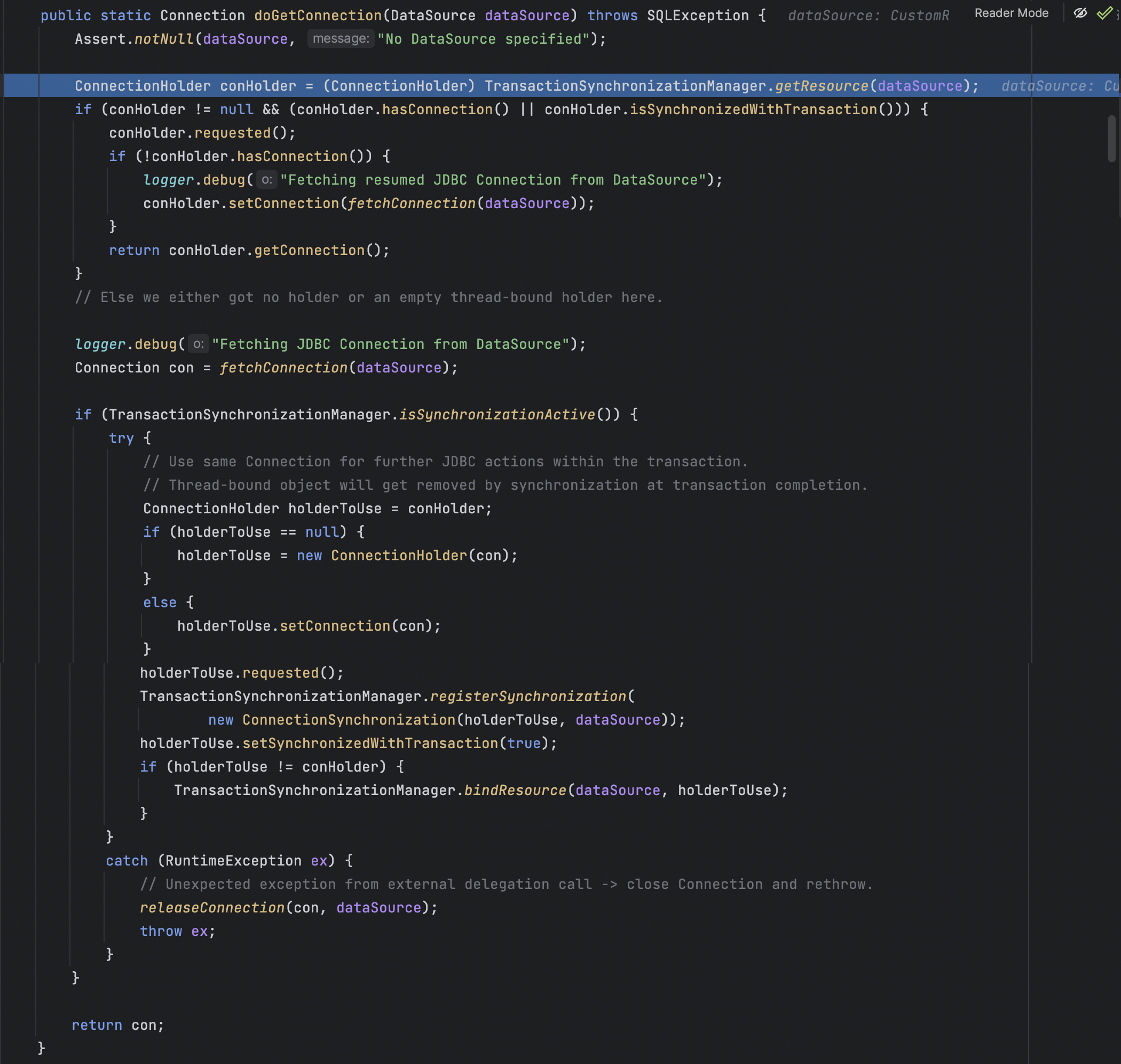
重点在这里,如果是事务就去获取ThreadLocal的资源,获取之前的数据源连接,导致无法切换数据源
第一种
将@Transactional注解的传播方式改变
@Transactional(rollbackFor = Exception.class,propagation = Propagation.SUPPORTS)@Transactional(rollbackFor = Exception.class,propagation = Propagation.NOT_SUPPORTED)这两种方式本质上就是非事务处理,取消事务,但是如果只有读操作可以,不然会很危险
第二种
对TransactionSynchronizationManager类进行覆盖重写,自定义事务注解(暂不考虑)
第三种
在@Transactional注解前修改数据源
Spring 事务原理
相信大家对这个都能说上来一些,Spring 事务是 Spring AOP 的一种具体应用
通过代理对象来调用目标对象,而在代理对象中有事务相关的增强处理
Spring 动态数据源原理
Spring AOP → 将我们指定的 lookupKey 放入 ThreadLocal
ThreadLocal → 线程内共享 lookupKey
DynamicDataSource → 对多数据源进行封装,根据 ThreadLocal 中的 lookupKey 动态选择具体的数据源
既然事务和动态数据源都是 Spring AOP 的具体应用,那么代理就存在先后顺序了
事务在前,动态数据源在后
此时,事务的前置增强处理会先生效,那么此时开始事务获取的 Connection 从哪来,既然是从 DynamicDataSource 获取的 Connection,那DynamicDataSource 根据 lookupKey 获取 Connection 的时候,会从 masterDataSource 数据源获取还是从 slaveDataSource 数据源获取?
因为之前的数据源是slaveDataSource,所以就获取了slaveDataSource
此时的动态数据源对事务不生效
动态数据源在前,事务在后
动态数据源的前置增强会先执行,DynamicDataSource 需要的 lookupKey 会先于事务绑定到当前线程,那么事务从 DynamicDataSource 获取 Connection 的时候就能根据当前线程的 lookupKey 来动态选择 masterDataSource 还是 slaveDataSource
如何保证事务中的动态数据源也有动态的效果,也就是如何保证动态数据源的前置增强先于事务
Spring AOP 是能够指定顺序的,只要我们显示的指定动态数据源的 AOP 先于 事务的 AOP 即可;如何指定顺序,常用的方式是实现 Order 接口,或者使用 @Order 注解,Order 的值越小,越先执行,所以我们只需要保证动态数据源的 Order 值小于事务的 Order 值即可
注意
网上很多的方式都是写一个另外的注解来切换数据源,在有需要切换的方法上添加注解,但是这违背了我想要最小改动的想法,所以这里我复用了@Transactional注解,另外写了一个AOP方法进行替换数据源
DataSourceExchange
@Component
@Aspect
@Order(1)
public class DataSourceExchange {
@Pointcut("(@annotation(org.springframework.transaction.annotation.Transactional) " +
"|| @within(org.springframework.transaction.annotation.Transactional) || " +
"@args(org.springframework.transaction.annotation.Transactional)) && within(com.linktopa.emergency..*)")
public void pointcut() {
}
@Before("pointcut()")
public void before(JoinPoint joinPoint) {
DataSourceHolder.putDataSource(DataSourceHolder.WRITE_DATASOURCE);
}
}
注意,这里的拦截代码我有修改,修改了拦截@Transactional注解的范围,因为有些项目在方法和类上都写了注解,下面的文章有解释如何AOP拦截注解
到这里其实就可以了,那么为什么DataSourceHolder.putDataSource(DataSourceHolder.WRITE_DATASOURCE);这一行就可以了呢?其实答案上面都说过了
当执行事务注解@Transactional的时候会一步一步的执行到DataSourceTransactionManager的doBegin()方法,会去拿出数据源
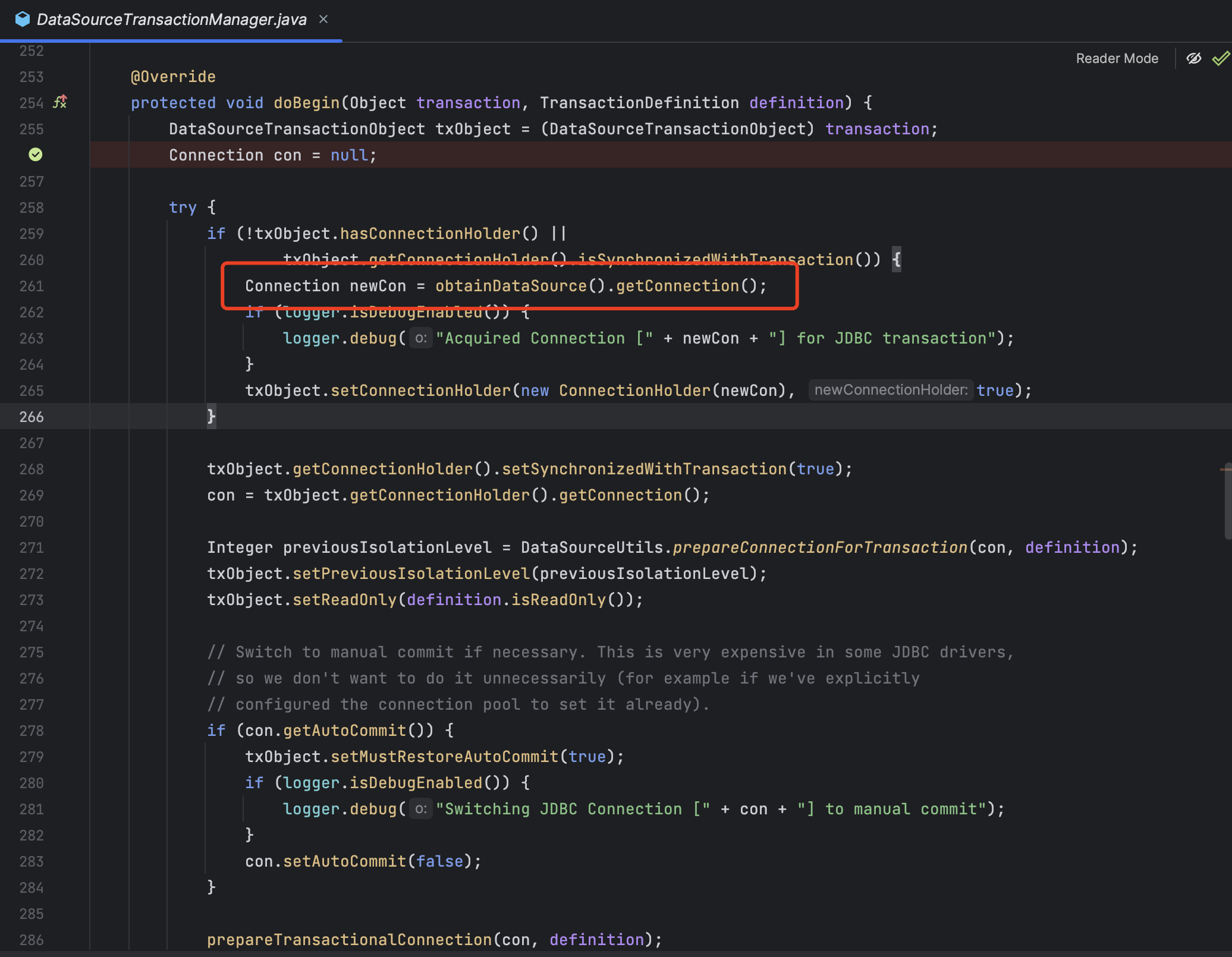
那去哪里拿数据源呢?还是会回到AbstractRoutingDataSource这里来拿数据源,这个类我们继承过的,写了切换数据源的方法。
最后还是回到了determineCurrentLookupKey()方法来通过key来选择数据源
总结就是无论有没有事务都会走这个AbstractRoutingDataSource类,没有事务就在获取数据源的时候走,有事务,事务会先走这个获取数据源保存在ThreadLocal中,而这个数据源是之前的数据源还没来得及切换,所以就有问题。
