阅读完需:约 125 分钟
当单机的PG数据库无法满足企业需求的时候,那么就要寻求其他的解决方案,为单机的数据库升级改造,建立HA高可用集群数据库,也可以是分布式的集群数据库,这里简单的介绍几种集群数据库的方案。
常用的高可用架构及基本原理包括:
- 共享存储;
- 流复制;
- 逻辑复制;
PG13的中文文档:
http://www.postgres.cn/docs/13/index.html
共享存储
共享存储是所用的存储空间相同,但实例运行放在不同的节点上。
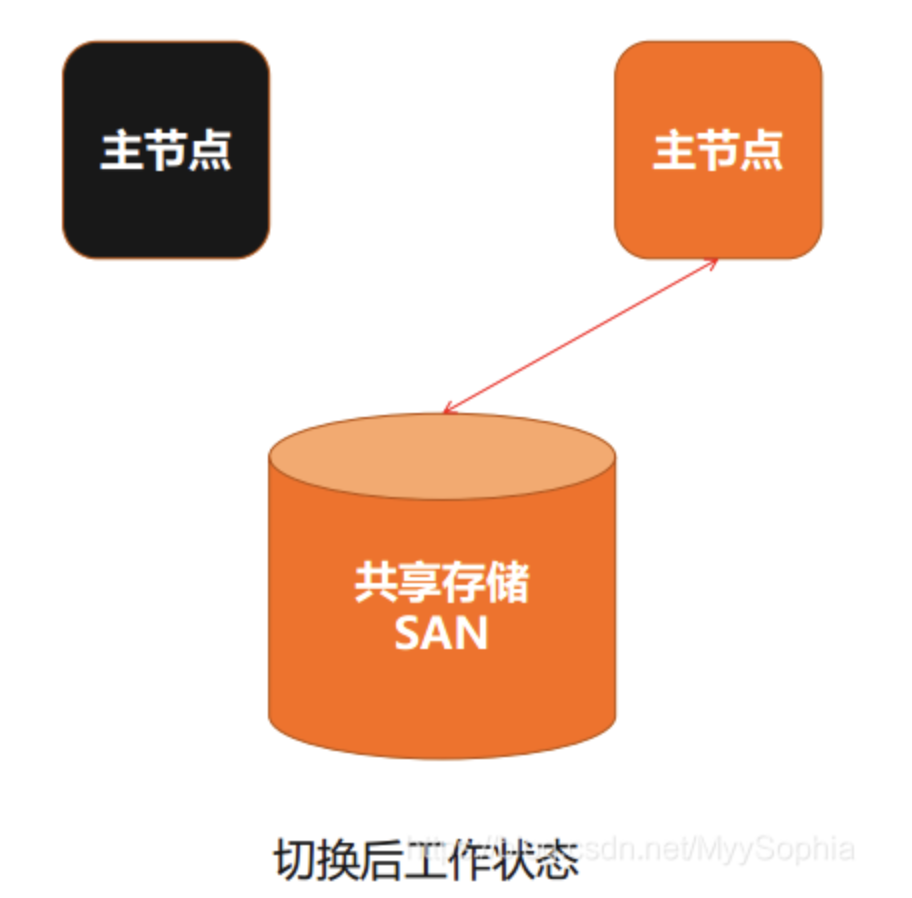
当在正常工作状态,主节点在计算机上启动,但是计算机里文件系统是接在SAN存储上,SAN存储同时也可以连接到备用节点,正常情况下主节点对共享存储进行读写,对外提供业务和服务。
当主节点故障时,会由备用节点接管数据库,重新启动实例做回滚。这种架构底层用到专门的存储叫SAN,它的好处是数据放在共享存储上,当主节点坏掉,从节点启动后会沿着主节点坏掉的时间点进行回滚,回滚到最后一次切换,经过Commit和Rollback,最后把数据库打开对外提供服务,不会丢数据。
流复制
在Oracle里面,可以用对等的DataGate概念对应PostgreSQL的流复制。根据数据流,每一个数据流Commit的时候会复制下去。
流复制分为:同步流复制和异步流复制。
根据用户不同的配置情况,在流复制里面可以搭建很多节。主节点上面,对外正常提供读写服务,然后通过流复制,可以挂一个或者多个从节点。在从节点上面,可以根据业务场景的需要,对高可用的需要或者负载均衡的需要,搭建一个或者多个二级从节点,根据业务需求,第二级从节点上再往后可以搭建第三、第四、第五等多级从节点。
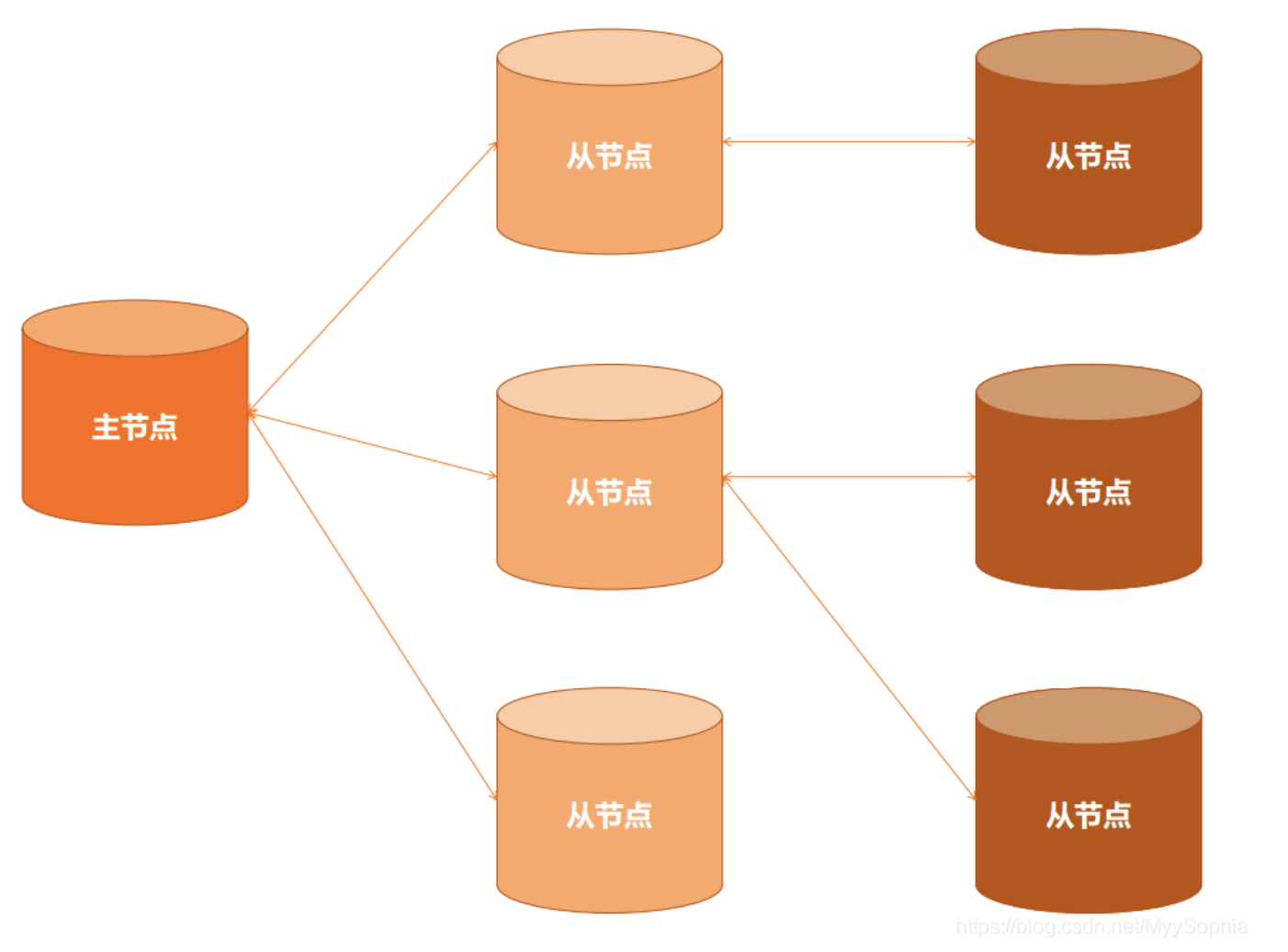
流复制特点总结:
- 主节点可以有多个从节点;
- 从节点上还可以挂载从节点;
- 从节点个数没有明确限制,层级无限制;
- 主从间可以同步复制、可以异步复制,也可以同步异步混合复制。
逻辑复制
逻辑复制是数据库内部数据块的具体操作,比如Insert、Delete操作解析出来,经过发布节点Sender进程向外发布之后,然后订阅节点对订阅 Publisher定义的指定名字进行搜索表的操作。
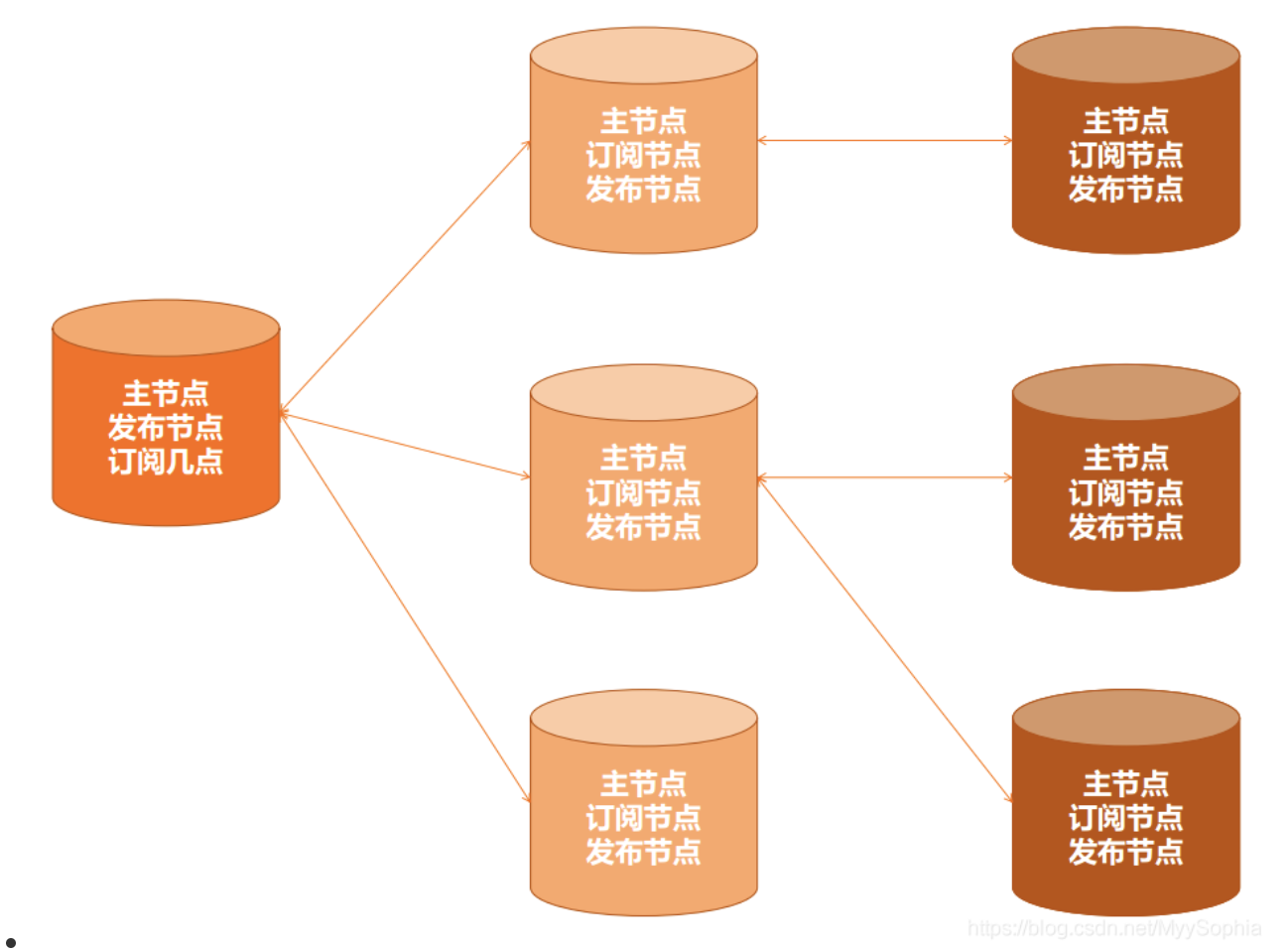
逻辑复制特点总结:
- 所有节点都是对等关系,都可读写;
- 所有节点可以是发布节点,订阅节点,也可以同时是发布节点和订阅节点。
逻辑复制和流复制之间的差别是:
- 流复制里只有一个主节点,可以挂很多从节点。逻辑复制里所有的节点都是对等的主节点,都可以提供对外读写操作。
- 逻辑复制实际是从逻辑上把 SQL解析出来,到其他订阅节点进行重放,相当于SQL的重新回放。流复制发布的数据是更改的数据块。
在众多的PostgreSQL HA方案中,流复制HA方案是性能,可靠性,部署成本等方面都比较好的,也是目前被普遍采用的方案。
数据库集群方案
PostgreSQL 本身不支持任何多主群集解决方案,例如 MySQL 或 Oracle。尽管如此,仍有许多商业和社区产品提供此实现,以及其他产品。
Corosync+Pacemaker
Pacemaker用于资源的转移,corosync用于心跳的检测。结合起来使用,实现对高可用架构的自动管理。心跳检测用来检测服务器是否还在提供服务,若出现服务器异常,就认为它挂掉了,此时pacemaker将会对资源进行转移。
Rubyrep
异步,多主机,多平台复制(在 Ruby 或 JRuby 中实现)和多 DBMS(MySQL或PostgreSQL)的解决方案。基于触发器,它不支持 DDL,用户或授权。使用和管理的简单性是其主要目标。
Bucardo
基于行的异步级联主从复制,使用触发器在数据库中排队;基于行的异步主-主复制,基于行,使用触发器和自定义冲突解决方案。Bucardo 需要专用的数据库并作为 Perl 守护程序运行,该守护程序与此数据库以及复制中涉及的所有其他数据库进行通信。它可以作为多主机或多从机运行。主从复制涉及到一个或多个目标的一个或多个源。源必须是 PostgreSQL,但是目标可以是 PostgreSQL,MySQL,Redis,Oracle,MariaDB,SQLite 或 MongoDB。
Pgpool-II+PgpoolAdmin
Pgpool-II相当于中间件,位于应用程序和PG服务端之间,对应用程序来说,Pgpool-II就相当于PG服务端;对PG服务端来说,Pgpool-II相当于PG客户端。由此可见,Pgpool-II与PG是解耦合的,基于这样的机制,Pgpool-II可以搭建在已经存在的任意版本的PG主从结构上,主从结构的实现与Pgpool-II无关,可以通过slony等工具或者PG自身的流复制机制实现。除了主从结构的集群,Pgpool-II也支持多主结构,称为复制模式,该模式下PG节点之间是对等的,没有主从关系,写操作同时在所有节点上执行,这种模式下写操作的代价很大,性能上不及主从模式。PG 9.3之后支持的流复制机制可以方便的搭建主从结构的集群(包括同步复制与异步复制),因此Pgpool-II中比较常用的模式是流复制主从模式。
Pgxc 与 Pgxl
Pgxc是经典的分布式数据库架构,是真正的企业级HTAP,我们看到市面上很多分布式数据库产品都是基于pgxc架构扩展而来。pgxc是和pg内核紧耦合的,是嵌入到pg内核中,最初pgxc的核心开发者将pgxc商业化,创建了stormdb,进行了一些并行算子优化,后来TransLattice公司将stormdb收购,并且将项目开源,就是现在的pgxl,所以pgxc和pgxl是一脉相承的,大部分代码是直接移植过来的。
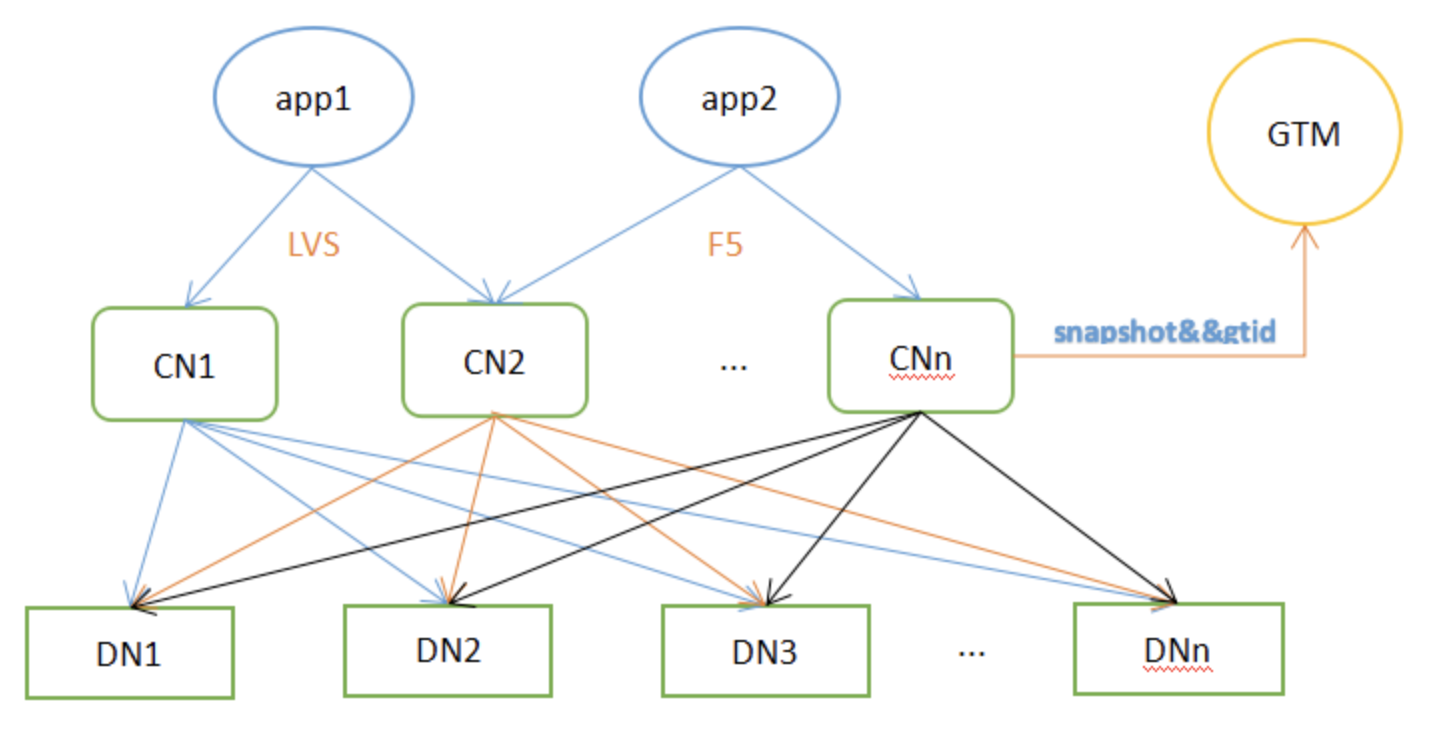
Postgres-XL的机制和Pgpool-II大不相同,它不是独立于PG的,是在PG源代码的基础上增加新功能实现的。简单来说,Postgres-XL将PG的SQL解析层的工作和数据存取层的工作分离到不同的两种节点上,分别称为Coordinator节点和Datanode节点,而且每种节点可以配置多个,共同协调完成原本单个PG实例完成的工作。此外,为了保证分布模式下事务能够正确执行,增加了一个GTM节点。为了避免单点故障,可以为所有节点配置对应的slave节点。
Postgres-XL的Coordinator节点是整个集群的数据访问入口,可以配置多个,然后在它们之上通过Nginx等工具实现负载均衡。Coordinator节点维护着数据的存储信息,但不存储数据本身。接收到一条SQL语句后,Coordinator解析SQL,制定执行计划,然后分发任务到相关的Datanode上,Datanode返回执行结果到Coordinator,Coordinator整合各个Datanode返回的结果,最后返回给客户端。
Postgres-XL的Datanode节点负责实际存取数据,数据在多个Datanode上的分布有两种方式:复制模式和分片模式,复制模式下,一个表的数据在指定的节点上存在多个副本;分片模式下,一个表的数据按照指定的规则分布在多个数据节点上,这些节点共同保存一份完整的数据。这两种模式的选择是在创建表的时候执行CREATE TABLE语句指定的,也可以通过ALTER TABLE语句改变数据的分布方式。
Greenplum
Greenplum是pivotal公司推出的一款开源olap的mpp数据库,greenplum的用户在某种程度上甚至超越了pg,很多人可能是通过greenplum才认识的pg,可见greenplum的风靡。
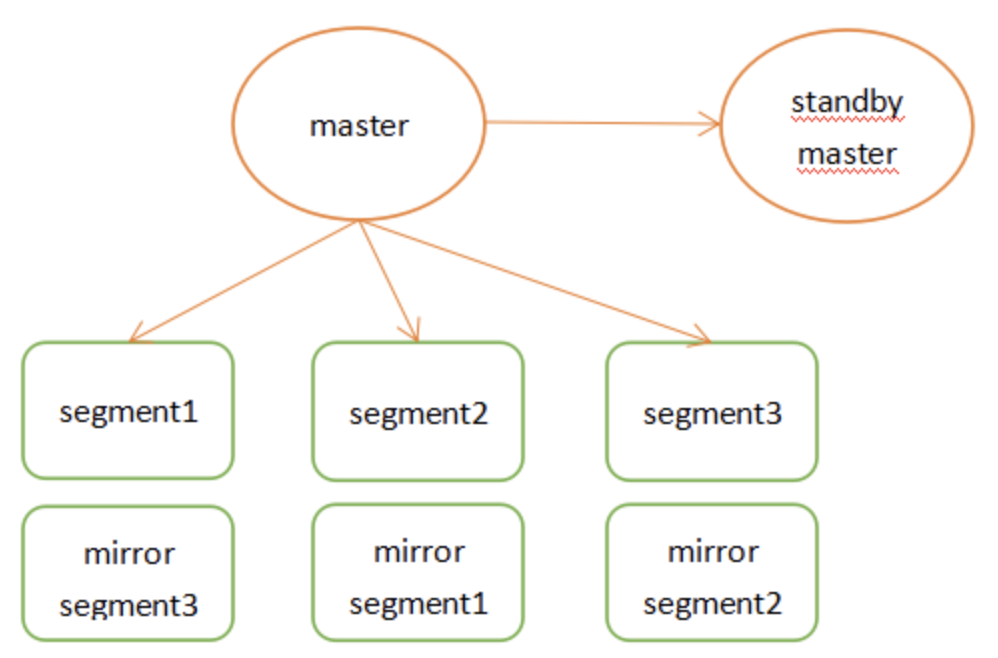
Master节点存储全局系统元数据信息,不存储真实数据。数据通过hash分布到不同的segment中,master作为sql的全局入口,负责在segment中分配工作负载,整合处理结果,返回客户端。
Citus
Citus以插件的方式扩展到postgresql中,独立于postgresql内核,所以能很快的跟上pg主版本的更新,部署也比较简单,是现在非常流行的分布式方案。
Citus可以把PG变成一个分布式数据库。目前在苏宁有大量的生产应用跑在Citus+pg的环境中。
Citus是一款基于PostgreSQL的开源分布式数据库,自动继承了PostgreSQL强大的SQL支持能力和应用生态(不仅仅是客户端协议的兼容还包括服务端扩展和管理工具的完全兼容)。 和其他类似的基于PostgreSQL的分布式方案,比如GreenPlum,PostgreSQL-XL,PostgreSQL-XC相比,Citus最大的不同在于Citus是一个PostgreSQL扩展而不是一个独立的代码分支。 因此,Citus可以用很小的代价和更快的速度紧跟PostgreSQL的版本演进;同时又能最大程度的保证数据库的稳定性和兼容性。
Citus节点主要分为协调节点和工作节点,协调节点不存储真实数据,只存储数据分布的元信息,实际的数据被分成若干分片,打散到不同worker节点中,应用连接协调节点,协调节点进行sql解析,生成分布式执行计划,下发到worker节点执行,cn将结果汇总返回客户端。
Citus的三种集群
因为,citus本身不支持HA,不像mongodb一样故障自动修复,但是可以结合pg的流复制,以及应用层jdbc数据驱动实现读写分离,故障切换。
第一种集群,增加读的能力
多个container节点,多个container节点进行流复制,保持元数据一致,在应用层设置多个读写分离,保证了数据的一致性,也保证了业务的高可用。
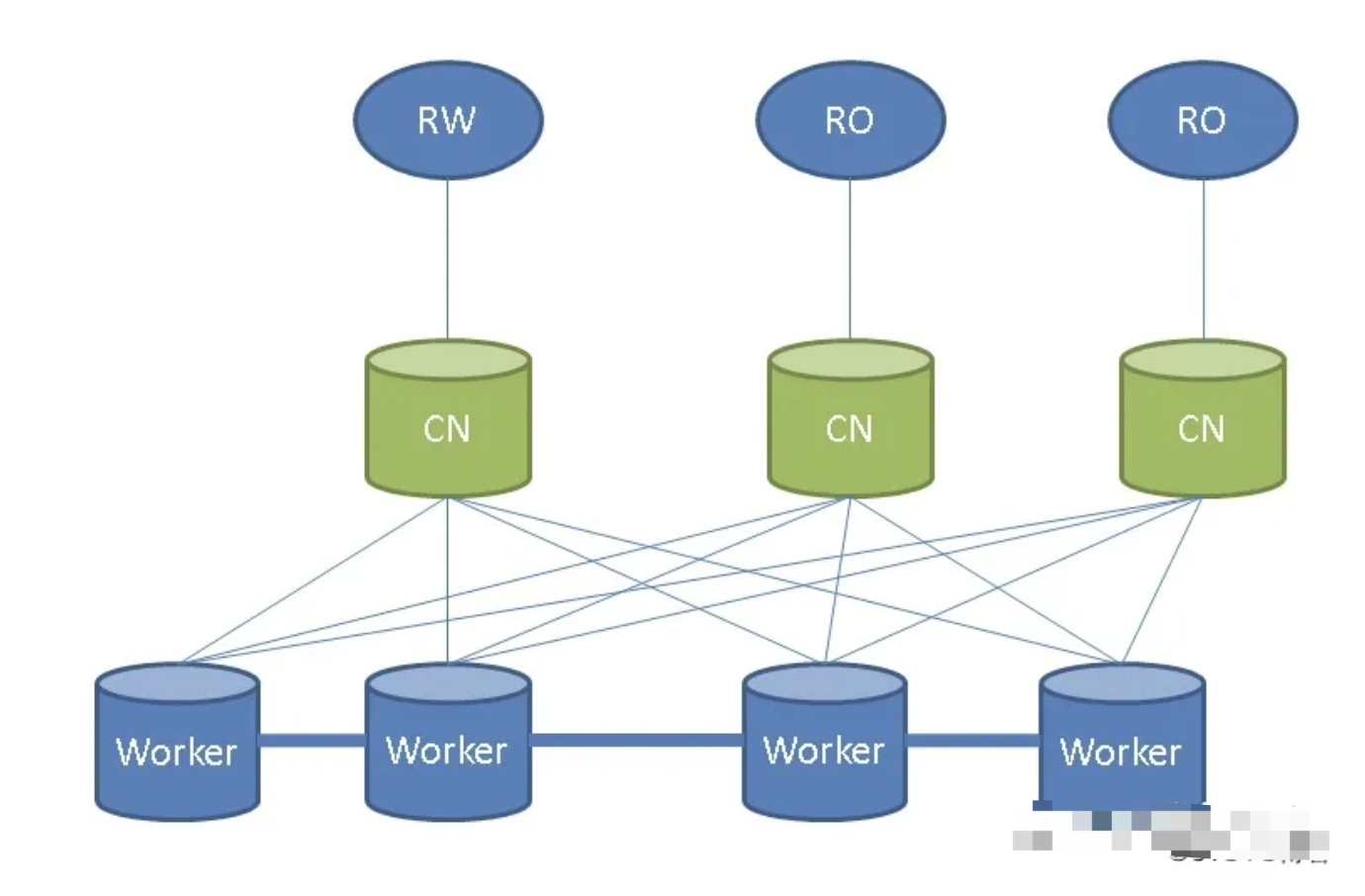
第二种集群,citus的MX功能
此功能可以说是解决了读和写的瓶颈,苏宁的架构中也是采用同样的思想。
原理:Mx功能的原理就是让其他的worker节点携带元数据,相当于携带元数据的worker节点都支持读写的能力,很大程度解决了读写的问题。
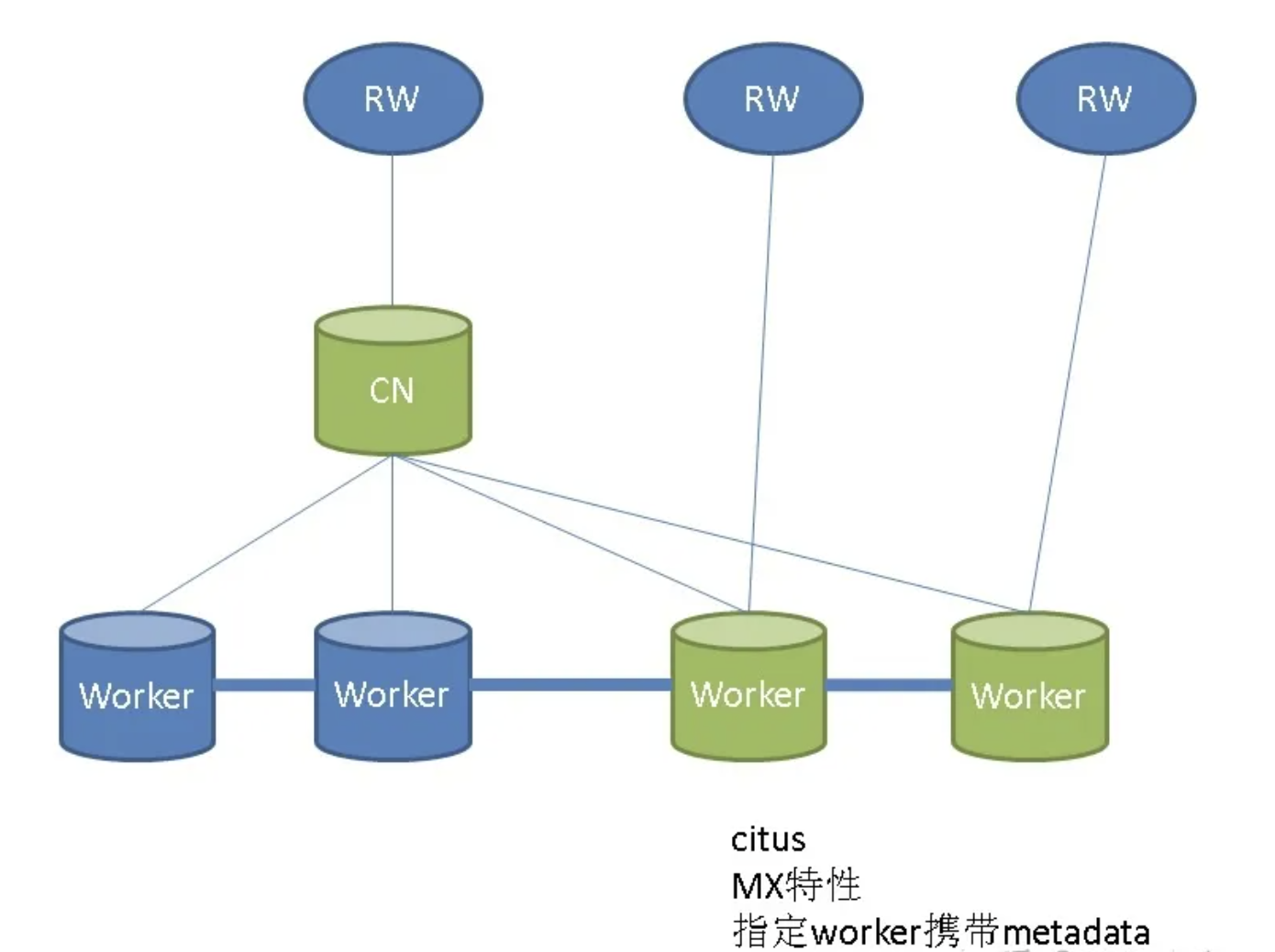
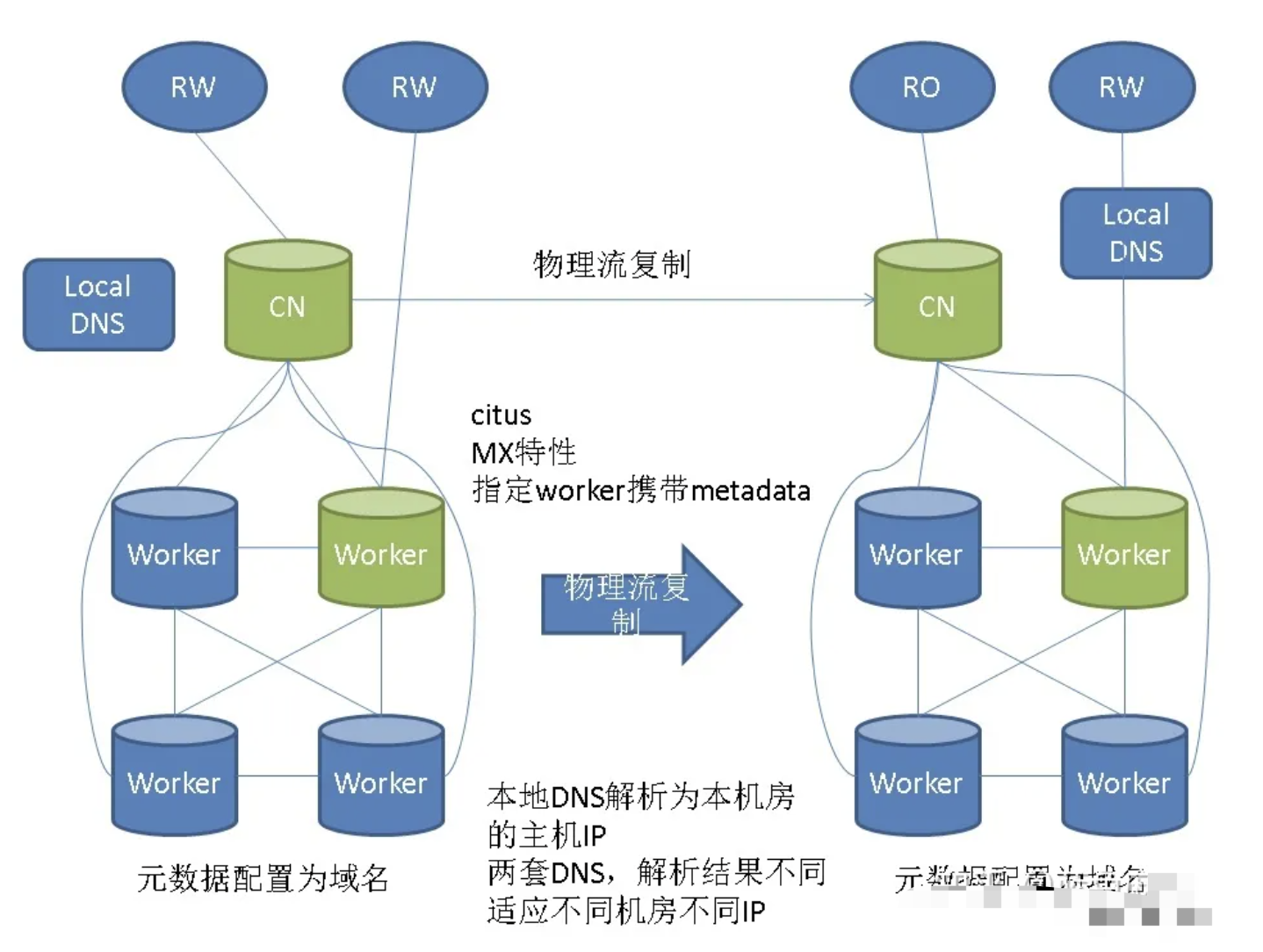
第三种集群,流复制,异地容灾。
使用不同的dns,解决两套集群IP不同的问题。扩展容灾能力。
这套集群是在MX的基础上解决异地容灾的方案,通过dns解析到不同的机房的数据库。
Citus中文文档
https://citus.hacker-linner.com/index.html
Citus官方文档
https://docs.citusdata.com/en/latest/index.html
Citus7.5版本官方文档
https://docs.citusdata.com/en/v7.5/get_started/what_is_citus.html
Citus安装测试体验
单节点Docker安装
docker run -d --name citus -p 5432:5432 -e POSTGRES_PASSWORD=mypass citusdata/citus:10.2验证是否安装了Citus插件
psql -U postgres -h localhost -d postgres -c "SELECT * FROM citus_version();"Docker多节点安装测试
7.5文档上的安装方式,最新的11.1就只有单机版本的
curl -L https://raw.githubusercontent.com/citusdata/docker/master/docker-compose.yml > docker-compose.yml我们需要下载docker-compose,compose的内容如下
# This file is auto generated from it's template,
# see citusdata/tools/packaging_automation/templates/docker/latest/docker-compose.tmpl.yml.
version: "3"
services:
master:
container_name: "${COMPOSE_PROJECT_NAME:-citus}_master"
image: "citusdata/citus:11.1.2"
ports: ["${COORDINATOR_EXTERNAL_PORT:-5432}:5432"]
labels: ["com.citusdata.role=Master"]
environment: &AUTH
POSTGRES_USER: "${POSTGRES_USER:-postgres}"
POSTGRES_PASSWORD: "${POSTGRES_PASSWORD}"
PGUSER: "${POSTGRES_USER:-postgres}"
PGPASSWORD: "${POSTGRES_PASSWORD}"
POSTGRES_HOST_AUTH_METHOD: "${POSTGRES_HOST_AUTH_METHOD:-trust}"
worker:
image: "citusdata/citus:11.1.2"
labels: ["com.citusdata.role=Worker"]
depends_on: [manager]
environment: *AUTH
command: "/wait-for-manager.sh"
volumes:
- healthcheck-volume:/healthcheck
manager:
container_name: "${COMPOSE_PROJECT_NAME:-citus}_manager"
image: "citusdata/membership-manager:0.3.0"
volumes:
- "${DOCKER_SOCK:-/var/run/docker.sock}:/var/run/docker.sock"
- healthcheck-volume:/healthcheck
depends_on: [master]
environment: *AUTH
volumes:
healthcheck-volume:启动docker-compose的命令
MASTER_EXTERNAL_PORT=5433 COMPOSE_PROJECT_NAME=citus docker-compose -p citus scale worker=6这里是启动了6个worker节点
关闭所有的节点
COMPOSE_PROJECT_NAME=citus docker-compose down -v在Citus上有分布式表,引用表,本地表,关键在于分布式表,引用表的创建
这里介绍常用的命令,具体的需要看文档操作
创建分布式表,第一个参数是表名,第二个参数是列名,通过列名来分片
SELECT create_distributed_table('github_events', 'repo_id');在各个数据库上增加citus,比如新创建了一个数据库,那么就要为新数据库赋予Citus的能力
这里要注意的是word节点上和协调节点上都要创建一样的数据库,都要创建citus插件
create extension citus;在新数据库中创建 Citus 扩展,并在协调器数据库中注册工作器。
// 第一个参数:协调节点的DNS名称,第二个参数协调器列出 PostgreSQL 连接的端口
SELECT citus_set_coordinator_host('coord.example.com', 5432);
// 在 Citus 元数据表 pg_dist_node 中注册集群中的新节点添加。
// 第一个参数:要添加的新节点的 DNS 名称或 IP 地址,第二个参数:PostgreSQL 在工作节点上侦听的端口
SELECT * from citus_add_node('node-name', 5432);
SELECT * from citus_add_node('node-name2', 5432);Citus表查询
分区表
// pg_dist_partition 表存储有关数据库中哪些表被分发的元数据。对于每个分布式表,它还存储有关分布方法的信息和有关分布列的详细信息。
SELECT * from pg_dist_partition;分片表
// pg_dist_shard 表存储有关表的各个分片的元数据。这包括有关分片属于哪个分布式表的信息以及有关该分片的分布列的统计信息。
// 在散列分布式表的情况下,它们是分配给该分片的散列令牌范围。这些统计信息用于在 SELECT 查询期间修剪掉不相关的分片。
SELECT * from pg_dist_shard;分片信息视图
这个比较重要,比较常用
// 除了上面描述的低级分片元数据表之外,Citus 还提供了一个citus_shards易于检查的视图:
// 每个分片在哪里(节点和端口),它属于什么类型的表,以及它的大小
SELECT * FROM citus_shards;分片放置表
// pg_dist_placement 表跟踪工作节点上分片的位置。分配给特定节点的每个分片称为分片放置。此表存储有关每个分片放置的运行状况和位置的信息。
SELECT * from pg_dist_placement;工作节点表
// pg_dist_node 表包含有关集群中工作节点的信息。
SELECT * from pg_dist_node;Citus表视图
// citus_tables 视图显示由 Citus 管理的所有表(分布式和参考表)的摘要。
SELECT * FROM citus_tables;时间分区视图
// Citus 提供 UDF 来管理Timeseries Data用例的分区。它还维护一个time_partitions视图来检查它管理的分区。
SELECT * FROM time_partitions;主机代管组表
// pg_dist_colocation 表包含有关哪些表的分片应该放在一起或co-located 的信息。
// 当两个表在同一个托管组中时,Citus 确保具有相同分区值的分片将放置在相同的工作节点上。
// 这可以实现连接优化、某些分布式汇总和外键支持。
// 当分片计数和分区列类型在两个表之间都匹配时,会推断出分片协同定位;但是,如果需要,可以在创建分布式表时指定自定义托管组。
SELECT * from pg_dist_colocation;再平衡器策略表
// 该表定义了rebalance_table_shards可以用来确定将分片移动到哪里的策略。
SELECT * FROM pg_dist_rebalance_strategy;Citus 效用函数文档:
https://developer.aliyun.com/article/955138
Citus11.X新版本介绍,从11版本开始Citus完全开源,与之前的不太一样
https://www.cnblogs.com/hacker-linner/p/16395975.html
Repmgr
Repmgr流复制管理工具对集群节点的管理是基于一个分布式的管理方式。每个节点都有自己的repmgr.conf配置文件,用来记录本节点的ID,节点名称,连接信息,数据库PGDATA目录等配置参数。在配置好这些参数后,就可以通过repmgr命令实现对集群节点的“一键式”部署。
部署完成后,每个节点都有自己的repmgrd守护进程来监控节点数据库状态,且每个节点维护自己的元数据表,用于记录所有集群节点的信息。其中主节点守护进程主要用来监控本节点数据库服务状态,备节点守护进程主要用来监控主节点和本节点数据库服务状态。在发生Auto Failover时,备节点在尝试N次连接主节点失败后,repmgrd会在所有备节点中选举一个候选备节点(选举机制参考以下Tips)提升为新主节点,然后其他备节点去Follow到该新主上,至此,形成一个新的集群状态。
Crunchy
官方文档
https://access.crunchydata.com/documentation/postgres-operator/5.0.3/
PGO是来自Crunchy Data的Postgres Operator,它为您提供了一个声明式 Postgres解决方案,可以自动管理您的PostgreSQL集群。
专为您的 GitOps 工作流程而设计,使用 PGO 在 Kubernetes 上使用 Postgres很容易。片刻之内,您就可以拥有一个完整的生产级 Postgres 集群,该集群具有高可用性、灾难恢复和监控以及安全的 TLS 通信。更棒的是,PGO 让您可以轻松自定义 Postgres 集群以适应您的工作负载!
借助诸如克隆 Postgres 集群、使用滚动更新以以最少的停机时间推出破坏性更改等便利性,PGO 已准备好在发布管道的每个阶段支持您的 Postgres 数据。PGO 专为弹性和正常运行时间而构建,可将您所需的 Postgres 保持在所需状态,因此您无需担心。
PGO 是凭借在 Kubernetes 上自动化 Postgres 管理方面的多年生产经验而开发的,提供无缝的云原生 Postgres 解决方案,让您的数据始终可用。
Stolon
Stolon 用于 PostgreSQL 高可用性的云原生 PostgreSQL 管理器。它是云原生的,因为它可以让您在容器中(kubernetes 集成)以及所有其他类型的基础设施(云 IaaS、旧式基础设施等)上保持高可用性 PostgreSQL。
- 利用 PostgreSQL 流式复制。
- 适应任何类型的分区。在尝试保持最大可用性的同时,它更喜欢一致性而不是可用性。
- kubernetes 集成让您实现 postgreSQL 高可用性。
- 使用 etcd、consul 或 kubernetes API server 等集群存储作为高可用数据存储和 leader 选举。
- 异步(默认)和同步复制。
- 在几分钟内完成集群设置。
- 轻松简单的集群管理。
- 可以与您首选的备份/恢复工具集成进行时间点恢复。
- 备用集群(用于多站点复制和接近零停机时间的迁移)。
- 自动服务发现和动态重新配置(处理 postgres 和 stolon 进程更改其地址)。
- 可以使用 pg_rewind 与当前 master 进行快速实例重新同步。
Patroni——2.1.4
Patroni:带有 ZooKeeper、etcd 或 Consul 的 PostgreSQL HA 模板
官方中文文档
https://postgres-cn.github.io/patroni-doccn/
官方地址
https://github.com/zalando/patroni
Patroni不仅简单易用而且功能非常强大。
- 支持自动failover和按需switchover
- 支持一个和多个备节点
- 支持级联复制
- 支持同步复制,异步复制
- 支持同步复制下备库故障时自动降级为异步复制(功效类似于MySQL的半同步,但是更加智能)
- 支持控制指定节点是否参与选主,是否参与负载均衡以及是否可以成为同步备机
- 支持通过
pg_rewind自动修复旧主 - 支持多种方式初始化集群和重建备机,包括
pg_basebackup和支持wal_e,pgBackRest,barman等备份工具的自定义脚本 - 支持自定义外部callback脚本
- 支持REST API
- 支持通过watchdog防止脑裂
- 支持k8s,docker等容器化环境部署
- 支持多种常见DCS(Distributed Configuration Store)存储元数据,包括etcd,ZooKeeper,Consul,Kubernetes
这里的集群方案采用Patroni来搭建,主要是因为Patroni轻量,自定义程度高,社区也活跃。
在搭建的过程中除了上述的这么框架,还有很多框架需要用到,启到了辅助的作用,比如:
对于负载均衡集群,可通过LVS,Nginx,Haproxy等
对于高可用集群,可通过keepalived,vipmanager等
对于数据库连接池,可通过PgBouncer等
这里碍于服务器资源等原因,基于官方的代码采用了比较简洁的搭建方式
总体搭建为:
Haproxy+Patroni+Etcd+(额外插件安装)PgCron+Timescaledb+Postgis
可以完善为:
keepalived+Haproxy+PgBouncer+Patroni+Etcd+(额外插件安装)PgCron+Timescaledb+PostGis+Citus
-
keepalived为Haproxy做HA,创建虚拟IP -
Haproxy为数据库做负载均衡和读写分离 -
PgBouncer为数据库做连接池,管理数据库连接 -
Patroni作为数据库集群方案,故障转移,流异步复制 -
Etcd作为Patroni的分布式存储基础 -
PgCron为数据库增加定时任务功能 -
Timescaledb为数据库赋予时序数据库功能 -
PostGis为数据库赋予处理地理信息的功能 -
Citus将数据库变为分布式数据库,提高分表分库能力
这里采用docker-compose搭建方式,源码在官方的github上,采用了2.1.4版本,Postgres14版本
Patroni搭建集群
修改DockerFile镜像构建
基于官方的Patroni2.1.4的DockerFile进行修改,
- 替换了PG数据库的版本,将数据库版本变更为14
- 替换镜像的下载源,改为阿里云下载
- 改原本在github上下载的包,改为在本地下载
- 分层构建的第二层改为
debian:bullseye源,目的是为了安装其他插件 - 在分层构建中安装
Timescaledb+Postgis+pg_cron插件
基本上就改了这些,完整的DockerFile如下:
## This Dockerfile is meant to aid in the building and debugging patroni whilst developing on your local machine
## It has all the necessary components to play/debug with a single node appliance, running etcd
ARG PG_MAJOR=14
ARG COMPRESS=false
ARG PGHOME=/home/postgres
ARG PGDATA=$PGHOME/data
ARG LC_ALL=C.UTF-8
ARG LANG=C.UTF-8
FROM postgres:$PG_MAJOR as builder
ARG PGHOME
ARG PGDATA
ARG LC_ALL
ARG LANG
ENV ETCDVERSION=3.3.13 CONFDVERSION=0.16.0
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list && \
apt clean && \
apt update
RUN set -ex \
&& export DEBIAN_FRONTEND=noninteractive \
&& echo 'APT::Install-Recommends "0";\nAPT::Install-Suggests "0";' > /etc/apt/apt.conf.d/01norecommend \
&& apt-get update -y \
# postgres:10 is based on debian, which has the patroni package. We will install all required dependencies
&& apt-cache depends patroni | sed -n -e 's/.*Depends: \(python3-.\+\)$/\1/p' \
| grep -Ev '^python3-(sphinx|etcd|consul|kazoo|kubernetes)' \
| xargs apt-get install -y vim curl less jq locales haproxy sudo \
python3-etcd python3-kazoo python3-pip busybox \
net-tools iputils-ping --fix-missing \
&& pip3 install dumb-init \
\
# Cleanup all locales but en_US.UTF-8
&& find /usr/share/i18n/charmaps/ -type f ! -name UTF-8.gz -delete \
&& find /usr/share/i18n/locales/ -type f ! -name en_US ! -name en_GB ! -name i18n* ! -name iso14651_t1 ! -name iso14651_t1_common ! -name 'translit_*' -delete \
&& echo 'en_US.UTF-8 UTF-8' > /usr/share/i18n/SUPPORTED \
\
# Make sure we have a en_US.UTF-8 locale available
&& localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8 \
\
# haproxy dummy config
&& echo 'global\n stats socket /run/haproxy/admin.sock mode 660 level admin' > /etc/haproxy/haproxy.cfg \
\
# vim config
&& echo 'syntax on\nfiletype plugin indent on\nset mouse-=a\nautocmd FileType yaml setlocal ts=2 sts=2 sw=2 expandtab' > /etc/vim/vimrc.local \
\
# Prepare postgres/patroni/haproxy environment
&& mkdir -p $PGHOME/.config/patroni /patroni /run/haproxy \
&& ln -s ../../postgres0.yml $PGHOME/.config/patroni/patronictl.yaml \
&& ln -s /patronictl.py /usr/local/bin/patronictl \
&& sed -i "s|/var/lib/postgresql.*|$PGHOME:/bin/bash|" /etc/passwd \
&& chown -R postgres:postgres /var/log \
\
# Download etcd
&& curl -sL http://en.enmalvi.com/etcd-v3.3.13-linux-amd64.tar.gz \
| tar xz -C /usr/local/bin --strip=1 --wildcards --no-anchored etcd etcdctl \
\
# Download confd
&& curl -sL http://en.enmalvi.com/confd-0.16.0-linux-amd64 \
> /usr/local/bin/confd && chmod +x /usr/local/bin/confd \
\
# Clean up all useless packages and some files
&& apt-get purge -y --allow-remove-essential python3-pip gzip bzip2 util-linux e2fsprogs \
libmagic1 bsdmainutils login ncurses-bin libmagic-mgc e2fslibs bsdutils \
exim4-config gnupg-agent dirmngr libpython2.7-stdlib libpython2.7-minimal \
&& apt-get autoremove -y \
&& apt-get clean -y \
&& rm -rf /var/lib/apt/lists/* \
/root/.cache \
/var/cache/debconf/* \
/etc/rc?.d \
/etc/systemd \
/docker-entrypoint* \
/sbin/pam* \
/sbin/swap* \
/sbin/unix* \
/usr/local/bin/gosu \
/usr/sbin/[acgipr]* \
/usr/sbin/*user* \
/usr/share/doc* \
/usr/share/man \
/usr/share/info \
/usr/share/i18n/locales/translit_hangul \
/usr/share/locale/?? \
/usr/share/locale/??_?? \
/usr/share/postgresql/*/man \
/usr/share/postgresql-common/pg_wrapper \
/usr/share/vim/vim80/doc \
/usr/share/vim/vim80/lang \
/usr/share/vim/vim80/tutor \
# /var/lib/dpkg/info/* \
&& find /usr/bin -xtype l -delete \
&& find /var/log -type f -exec truncate --size 0 {} \; \
&& find /usr/lib/python3/dist-packages -name '*test*' | xargs rm -fr \
&& find /lib/x86_64-linux-gnu/security -type f ! -name pam_env.so ! -name pam_permit.so ! -name pam_unix.so -delete
# perform compression if it is necessary
ARG COMPRESS
RUN if [ "$COMPRESS" = "true" ]; then \
set -ex \
# Allow certain sudo commands from postgres
&& echo 'postgres ALL=(ALL) NOPASSWD: /bin/tar xpJf /a.tar.xz -C /, /bin/rm /a.tar.xz, /bin/ln -snf dash /bin/sh' >> /etc/sudoers \
&& ln -snf busybox /bin/sh \
&& files="/bin/sh /usr/bin/sudo /usr/lib/sudo/sudoers.so /lib/x86_64-linux-gnu/security/pam_*.so" \
&& libs="$(ldd $files | awk '{print $3;}' | grep '^/' | sort -u) /lib/x86_64-linux-gnu/ld-linux-x86-64.so.* /lib/x86_64-linux-gnu/libnsl.so.* /lib/x86_64-linux-gnu/libnss_compat.so.*" \
&& (echo /var/run $files $libs | tr ' ' '\n' && realpath $files $libs) | sort -u | sed 's/^\///' > /exclude \
&& find /etc/alternatives -xtype l -delete \
&& save_dirs="usr lib var bin sbin etc/ssl etc/init.d etc/alternatives etc/apt" \
&& XZ_OPT=-e9v tar -X /exclude -cpJf a.tar.xz $save_dirs \
# we call "cat /exclude" to avoid including files from the $save_dirs that are also among
# the exceptions listed in the /exclude, as "uniq -u" eliminates all non-unique lines.
# By calling "cat /exclude" a second time we guarantee that there will be at least two lines
# for each exception and therefore they will be excluded from the output passed to 'rm'.
&& /bin/busybox sh -c "(find $save_dirs -not -type d && cat /exclude /exclude && echo exclude) | sort | uniq -u | xargs /bin/busybox rm" \
&& /bin/busybox --install -s \
&& /bin/busybox sh -c "find $save_dirs -type d -depth -exec rmdir -p {} \; 2> /dev/null"; \
fi
FROM debian:bullseye as timescaledb-gis
COPY --from=builder / /
ARG PG_MAJOR
ARG COMPRESS
ARG PGHOME
ARG PGDATA
ARG LC_ALL
ARG LANG
ARG PGBIN=/usr/lib/postgresql/$PG_MAJOR/bin
ENV LC_ALL=$LC_ALL LANG=$LANG EDITOR=/usr/bin/editor
ENV PGDATA=$PGDATA PATH=$PATH:$PGBIN
COPY patroni /patroni/
COPY extras/confd/conf.d/haproxy.toml /etc/confd/conf.d/
COPY extras/confd/templates/haproxy.tmpl /etc/confd/templates/
COPY patroni*.py docker/entrypoint.sh /
COPY postgres?.yml $PGHOME/
WORKDIR $PGHOME
RUN sed -i 's/env python/&3/' /patroni*.py \
# "fix" patroni configs
&& sed -i 's/^\( connect_address:\| - host\)/#&/' postgres?.yml \
&& sed -i 's/^ listen: 127.0.0.1/ listen: 0.0.0.0/' postgres?.yml \
&& sed -i "s|^\( data_dir: \).*|\1$PGDATA|" postgres?.yml \
&& sed -i "s|^#\( bin_dir: \).*|\1$PGBIN|" postgres?.yml \
&& sed -i 's/^ - encoding: UTF8/ - locale: en_US.UTF-8\n&/' postgres?.yml \
&& sed -i 's/^\(scope\|name\|etcd\| host\| authentication\| pg_hba\| parameters\):/#&/' postgres?.yml \
&& sed -i 's/^ \(replication\|superuser\|rewind\|unix_socket_directories\|\(\( \)\{0,1\}\(username\|password\)\)\):/#&/' postgres?.yml \
&& sed -i 's/^ parameters:/ pg_hba:\n - local all all trust\n - host replication all all md5\n - host all all all md5\n&\n max_connections: 100/' postgres?.yml \
&& if [ "$COMPRESS" = "true" ]; then chmod u+s /usr/bin/sudo; fi \
&& chmod +s /bin/ping \
&& chown -R postgres:postgres $PGHOME /run /etc/haproxy
RUN sed -i s/deb.debian.org/mirrors.aliyun.com/g /etc/apt/sources.list && ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone
RUN apt-get update
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get -y upgrade && \
DEBIAN_FRONTEND=noninteractive apt-get -y install gnupg apt-transport-https lsb-release curl
## Timescaledb
# https://packagecloud.io/timescale/timescaledb
#
RUN curl -s https://packagecloud.io/install/repositories/timescale/timescaledb/script.deb.sh | bash
RUN apt-get -q update && \
DEBIAN_FRONTEND=noninteractive apt-get -y install timescaledb-2-postgresql-14
# timescaledb-toolkit-postgresql-14
#RUN sed -r -i "s/[#]*\s*(shared_preload_libraries)\s*=\s*'(.*)'/\1 = 'timescaledb,\2'/;s/,'/'/" /usr/share/postgresql/postgresql.conf.sample
## Postgis
# https://trac.osgeo.org/postgis/wiki/UsersWikiPostGIS24UbuntuPGSQL10Apt
#
RUN apt-get -q update && \
DEBIAN_FRONTEND=noninteractive apt-get -y install postgresql-14-postgis-3 \
postgresql-14-postgis-3-scripts \
postgresql-14-pgrouting \
postgresql-14-pgrouting-scripts
## pg_cron
# https://github.com/citusdata/pg_cron
#
RUN apt-get -q update && \
DEBIAN_FRONTEND=noninteractive apt-get -y install postgresql-14-cron
## Extension plpython3
RUN DEBIAN_FRONTEND=noninteractive apt-get -y install python3 postgresql-plpython3-14 python3-requests
## Config
# extension timescaledb and others must be preloaded
RUN echo "shared_preload_libraries = 'timescaledb,pg_stat_statements,pg_cron'" >> /usr/share/postgresql/postgresql.conf.sample
# timescaledb telemetry off
RUN echo "timescaledb.telemetry_level=off" >> /usr/share/postgresql/postgresql.conf.sample
RUN rm -rf /var/lib/apt/lists/*
USER postgres
ENTRYPOINT ["/bin/sh", "/entrypoint.sh"]
构建的镜像包含了所有我们需要的插件与功能
修改Docker-Compost部署
关于compose的修改的不多,基本保持原样
- 开放haproxy的7000端口,可以查看集群的状态
- 为每个patroni集群,添加数据库账号密码
完整的部署文件如下:
# docker compose file for running a 3-node PostgreSQL cluster
# with 3-node etcd cluster as the DCS and one haproxy node
version: "2"
networks:
demo:
services:
etcd1: &etcd
image: patroni
networks: [ demo ]
environment:
ETCD_LISTEN_PEER_URLS: http://0.0.0.0:2380
ETCD_LISTEN_CLIENT_URLS: http://0.0.0.0:2379
ETCD_INITIAL_CLUSTER: etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380
ETCD_INITIAL_CLUSTER_STATE: new
ETCD_INITIAL_CLUSTER_TOKEN: tutorial
container_name: demo-etcd1
hostname: etcd1
command: etcd -name etcd1 -initial-advertise-peer-urls http://etcd1:2380
etcd2:
<<: *etcd
container_name: demo-etcd2
hostname: etcd2
command: etcd -name etcd2 -initial-advertise-peer-urls http://etcd2:2380
etcd3:
<<: *etcd
container_name: demo-etcd3
hostname: etcd3
command: etcd -name etcd3 -initial-advertise-peer-urls http://etcd3:2380
haproxy:
image: patroni
networks: [ demo ]
env_file: docker/patroni.env
hostname: haproxy
container_name: demo-haproxy
ports:
- "5000:5000"
- "5001:5001"
- "7000:7000"
command: haproxy
environment: &haproxy_env
ETCDCTL_ENDPOINTS: http://etcd1:2379,http://etcd2:2379,http://etcd3:2379
PATRONI_ETCD3_HOSTS: "'etcd1:2379','etcd2:2379','etcd3:2379'"
PATRONI_SCOPE: demo
patroni1:
image: patroni
networks: [ demo ]
env_file: docker/patroni.env
hostname: patroni1
container_name: demo-patroni1
environment:
<<: *haproxy_env
PATRONI_NAME: patroni1
PATRONI_SUPERUSER_USERNAME: liantu
PATRONI_SUPERUSER_PASSWORD: liantu123
# volumes:
# - /root/data:/var/lib/postgresql/data
patroni2:
image: patroni
networks: [ demo ]
env_file: docker/patroni.env
hostname: patroni2
container_name: demo-patroni2
environment:
<<: *haproxy_env
PATRONI_NAME: patroni2
PATRONI_SUPERUSER_USERNAME: liantu
PATRONI_SUPERUSER_PASSWORD: liantu123
patroni3:
image: patroni
networks: [ demo ]
env_file: docker/patroni.env
hostname: patroni3
container_name: demo-patroni3
environment:
<<: *haproxy_env
PATRONI_NAME: patroni3
PATRONI_SUPERUSER_USERNAME: liantu
PATRONI_SUPERUSER_PASSWORD: liantu123
值得注意的是这里的部署并没有做数据库的挂载。
剩下的内容可以跟着官方的代码走,就可以运行起来啦。
部署内容的讲解
主要分析一下官方的部署是如何进行的,这几个组件是如何交互,并调整参数的。
Etcd部署
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
关于Etcd的github地址,里面包含很多文档
https://github.com/etcd-io/etcd
上述的compose中关于Etcd,部署了3个Etcd,3个Etcd是通过Etcd的环境变量进行集成。
-
ETCD_INITIAL_ADVERTISE_PEER_URLS:该成员节点在整个集群中的通信地址列表,这个地址用来传输集群数据的地址。因此这个地址必须是可以连接集群中所有的成员的。 -
ETCD_LISTEN_PEER_URLS:该节点与其他节点通信时所监听的地址列表,多个地址使用逗号隔开,其格式可以划分为scheme://IP:PORT,这里的scheme可以是http、https -
ETCD_LISTEN_CLIENT_URLS:该节点与客户端通信时监听的地址列表 -
ETCD_ADVERTISE_CLIENT_URLS:广播给集群中其他成员自己的客户端地址列表 -
ETCD_INITIAL_CLUSTER_TOKEN:初始化集群token -
ETCD_INITIAL_CLUSTER:配置集群内部所有成员地址,其格式为:ETCD_NAME=ETCD_INITIAL_ADVERTISE_PEER_URLS,如果有多个使用逗号隔开 -
ETCD_INITIAL_CLUSTER_STATE:初始化集群状态,new表示新建
etcdctl是etcd的命令行客户端,可以使用它来查看和操作etcd
这里的是Patroni通过Etcd作为存储搭建的。
Haproxy部署
HAProxy是一个免费的负载均衡软件,可以运行于大部分主流的Linux操作系统上。
HAProxy提供了L4(TCP)和L7(HTTP)两种负载均衡能力,具备丰富的功能。HAProxy的社区非常活跃,版本更新快速(最新稳定版1.7.2于2017/01/13推出)。最关键的是,HAProxy具备媲美商用负载均衡器的性能和稳定性。
因为HAProxy的上述优点,它当前不仅仅是免费负载均衡软件的首选,更几乎成为了唯一选择。
http://docs.haproxy.org/2.2/intro.html#3.3.13
HAProxy的核心功能
- 负载均衡:L4和L7两种模式,支持RR/静态RR/LC/IP Hash/URI Hash/URL_PARAM Hash/HTTP_HEADER Hash等丰富的负载均衡算法
- 健康检查:支持TCP和HTTP两种健康检查模式
- 会话保持:对于未实现会话共享的应用集群,可通过Insert Cookie/Rewrite Cookie/Prefix Cookie,以及上述的多种Hash方式实现会话保持
- SSL:HAProxy可以解析HTTPS协议,并能够将请求解密为HTTP后向后端传输
- HTTP请求重写与重定向
- 监控与统计:HAProxy提供了基于Web的统计信息页面,展现健康状态和流量数据。基于此功能,使用者可以开发监控程序来监控HAProxy的状态
HAProxy的关键特性
性能
- 采用单线程、事件驱动、非阻塞模型,减少上下文切换的消耗,能在1ms内处理数百个请求。并且每个会话只占用数KB的内存。
- 大量精细的性能优化,如O(1)复杂度的事件检查器、延迟更新技术、Single-buffereing、Zero-copy forwarding等等,这些技术使得HAProxy在中等负载下只占用极低的CPU资源。
- HAProxy大量利用操作系统本身的功能特性,使得其在处理请求时能发挥极高的性能,通常情况下,HAProxy自身只占用15%的处理时间,剩余的85%都是在系统内核层完成的。
- HAProxy作者在8年前(2009)年使用1.4版本进行了一次测试,单个HAProxy进程的处理能力突破了10万请求/秒,并轻松占满了10Gbps的网络带宽。
稳定性
作为建议以单进程模式运行的程序,HAProxy对稳定性的要求是十分严苛的。按照作者的说法,HAProxy在13年间从未出现过一个会导致其崩溃的BUG,HAProxy一旦成功启动,除非操作系统或硬件故障,否则就不会崩溃(我觉得可能多少还是有夸大的成分)。
在上文中提到过,HAProxy的大部分工作都是在操作系统内核完成的,所以HAProxy的稳定性主要依赖于操作系统,作者建议使用2.6或3.x的Linux内核,对sysctls参数进行精细的优化,并且确保主机有足够的内存。这样HAProxy就能够持续满负载稳定运行数年之久。
HAProxy配置中分成五部分内容:
- global: 设置全局配置参数,属于进程的配置,通常是和操作系统相关。
- defaults:配置默认参数,这些参数可以被用到frontend,backend,Listen组件;
- frontend:接收请求的前端虚拟节点,Frontend可以更加规则直接指定具体使用后端的backend,相当于nginx中的server{}模块;
- backend:后端服务集群的配置,是真实服务器,一个Backend对应一个或者多个实体服务器,相当于nginx中的upstream{}模块;
- listen:frontend和backend的组合体。
global域的关键配置
- daemon:指定HAProxy以后台模式运行,通常情况下都应该使用这一配置
- user [username] :指定HAProxy进程所属的用户
- group [groupname] :指定HAProxy进程所属的用户组
- log [address] [device] [maxlevel] [minlevel]:日志输出配置,如log 127.0.0.1 local0 info warning,即向本机rsyslog或syslog的local0输出info到warning级别的日志。其中[minlevel]可以省略。HAProxy的日志共有8个级别,从高到低为emerg/alert/crit/err/warning/notice/info/debug
- pidfile :指定记录HAProxy进程号的文件绝对路径。主要用于HAProxy进程的停止和重启动作。
- maxconn :HAProxy进程同时处理的连接数,当连接数达到这一数值时,HAProxy将停止接收连接请求
frontend域的关键配置
- acl [name] [criterion] [flags] [operator] [value]:定义一条ACL,ACL是根据数据包的指定属性以指定表达式计算出的true/false值。如”acl url_ms1 path_beg -i /ms1/”定义了名为url_ms1的ACL,该ACL在请求uri以/ms1/开头(忽略大小写)时为true
- bind [ip]:[port]:frontend服务监听的端口
- default_backend [name]:frontend对应的默认backend disabled:禁用此frontend
- http-request [operation] [condition]:对所有到达此frontend的HTTP请求应用的策略,例如可以拒绝、要求认证、添加header、替换header、定义ACL等等。
- http-response [operation] [condition]:对所有从此frontend返回的HTTP响应应用的策略,大体同上
- log:同global域的log配置,仅应用于此frontend。如果要沿用global域的log配置,则此处配置为log global
- maxconn:同global域的maxconn,仅应用于此frontend
- mode:此frontend的工作模式,主要有http和tcp两种,对应L7和L4两种负载均衡模式
- option forwardfor:在请求中添加X-Forwarded-For Header,记录客户端ip option http-keep-alive:以KeepAlive模式提供服务
- option httpclose:与http-keep-alive对应,关闭KeepAlive模式,如果HAProxy主要提供的是接口类型的服务,可以考虑采用httpclose模式,以节省连接数资源。但如果这样做了,接口的调用端将不能使用HTTP连接池
- option httplog:开启httplog,HAProxy将会以类似Apache HTTP或Nginx的格式来记录请求日志
- option tcplog:开启tcplog,HAProxy将会在日志中记录数据包在传输层的更多属性
- stats uri [uri]:在此frontend上开启监控页面,通过[uri]访问
- stats refresh [time]:监控数据刷新周期
- stats auth [user]:[password]:监控页面的认证用户名密码
- timeout client [time]:指连接创建后,客户端持续不发送数据的超时时间
- timeout http-request [time]:指连接创建后,客户端没能发送完整HTTP请求的超时时间,主要用于防止DoS类攻击,即创建连接后,以非常缓慢的速度发送请求包,导致HAProxy连接被长时间占用
- use_backend [backend] if|unless [acl]:与ACL搭配使用,在满足/不满足ACL时转发至指定的backend
backend域的关键配置
- acl:同frontend域
- balance [algorithm]:在此backend下所有server间的负载均衡算法,常用的有roundrobin和source,完整的算法说明见官方文档configuration.html#4.2-balance
- cookie:在backend server间启用基于cookie的会话保持策略,最常用的是insert方式,如cookie HA_STICKY_ms1 insert indirect nocache,指HAProxy将在响应中插入名为HA_STICKY_ms1的cookie,其值为对应的server定义中指定的值,并根据请求中此cookie的值决定转发至哪个server。indirect代表如果请求中已经带有合法的HA_STICK_ms1 cookie,则HAProxy不会在响应中再次插入此cookie,nocache则代表禁止链路上的所有网关和缓存服务器缓存带有Set-Cookie头的响应。
- default-server:用于指定此backend下所有server的默认设置。具体见下面的server配置。
- disabled:禁用此backend http-request/http-response:同frontend域
- log:同frontend域
- mode:同frontend域
- option forwardfor:同frontend域
- option http-keep-alive:同frontend域
- option httpclose:同frontend域
- option httpchk [METHOD] [URL] [VERSION]:定义以http方式进行的健康检查策略。如option httpchk GET /healthCheck.html HTTP/1.1 option
- httplog:同frontend域
- option tcplog:同frontend域
- server [name] [ip]:[port] [params]:定义backend中的一个后端server,[params]用于指定这个server的参数,常用的包括有:
- check:指定此参数时,HAProxy将会对此server执行健康检查,检查方法在option httpchk中配置。同时还可以在check后指定inter, rise, fall三个参数,分别代表健康检查的周期、连续几次成功认为server UP,连续几次失败认为server DOWN,默认值是inter 2000ms rise 2 fall 3
- cookie [value]:用于配合基于cookie的会话保持,如cookie ms1.srv1代表交由此server处理的请求会在响应中写入值为ms1.srv1的cookie(具体的cookie名则在backend域中的cookie设置中指定)
- maxconn:指HAProxy最多同时向此server发起的连接数,当连接数到达maxconn后,向此server发起的新连接会进入等待队列。默认为0,即无限
- maxqueue:等待队列的长度,当队列已满后,后续请求将会发至此backend下的其他server,默认为0,即无限
- weight:server的权重,0-256,权重越大,分给这个server的请求就越多。weight为0的server将不会被分配任何新的连接。所有server默认weight为1
- timeout connect [time]:指HAProxy尝试与backend server创建连接的超时时间
- timeout check [time]:默认情况下,健康检查的连接+响应超时时间为server命令中指定的inter值,如果配置了timeout check,HAProxy会以inter作为健康检查请求的连接超时时间,并以timeout check的值作为健康检查请求的响应超时时间
- timeout server [time]:指backend server响应HAProxy请求的超时时间
default域
上文所属的frontend和backend域关键配置中,除acl、bind、http-request、http-response、use_backend外,其余的均可以配置在default域中。default域中配置了的项目,如果在frontend或backend域中没有配置,将会使用default域中的配置。
listen域
listen域是frontend域和backend域的组合,frontend域和backend域中所有的配置都可以配置在listen域下
搭建HAProxy最关键的是在于配置文件,配置文件包含了HAProxy运行的方式
配置文件示例
haproxy]# vim /usr/local/haproxy/conf/haproxy.cfg
global #全局配置
log 127.0.0.1 local0 #开启日志,日志等级为local0
maxconn 6000 #定义并发最大连接数6000
chroot /usr/local/haproxy #程序主目录
user root #用户
group root #用户组
daemon #以守护进程的方式运行
pidfile /usr/local/haproxy/haproxy.pid #pid文件生成位置
stats socket /run/haproxy/admin.sock mode 660 level admin
defaults #默认配置
log global #日志与全局配置相同
option dontlognull #日志中不记录空连接
retries 3 #定义连接后端服务器的失败重连次数,连接失败次数超过此值后将会将对应后端服务器标记为不可用
option redispatch #定义连接失败后将会话重新调度分发
timeout connect 10000 #设置成功连接到一台服务器的最长等待时间,默认单位是毫秒
timeout client 300000 #设置连接客户端发送数据时的成功连接最长等待时间,默认单位是毫秒
timeout server 300000 #设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒
maxconn 4000
fullconn 4000
listen nginx_status #nginx的listen
bind 0.0.0.0:7777 #定义frontend绑定监听端口
#定义backend,将被frontend调度
mode http #指定负载协议类型为http
option httplog #采用http日志格式
option httpchk GET /index.html
balance roundrobin #设置haproxy的调度算法为轮询
server 10.4.7.101 10.4.7.101:80 check port 80 inter 5s rise 2 fall 3 maxconn 2000#根据调度分配到真实的后台地址,参数解释:port 80:检测端口80, inter 5s:5秒检测一次,rise 2:检测成功2次表示服务器>可用,fall 3:检测失败3次后表示服务器不可用
server 10.4.7.102 10.4.7.102:80 check port 80 inter 5s rise 2 fall 3 maxconn 2000
timeout server 300000 #设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒
listen mariadb_cluster
bind 0.0.0.0:3366
mode tcp
balance roundrobin
server 10.4.7.101 10.4.7.101:3306 check port 3306 inter 5s rise 2 fall 3 maxconn 2000
server 10.4.7.102 10.4.7.102:3306 check port 3306 inter 5s rise 2 fall 3 maxconn 2000
listen admin_stats #web页面的listen
stats enable #开启统计风能
bind *:8888 #监听的ip端口号
mode http
stats refresh 30s #(可选)统计页面自动刷新时间
stats uri /haproxy #访问的uri ip:8888/haproxy
stats realm haproxy_admin #(可选)密码框提示文本
stats auth admin:admin #(可选)认证用户名和密码
stats hide-version #(可选)隐藏HAProxy的版本号
stats admin if TRUE #管理功能,需要开启stats auth成功登陆后可通过webui管理节点写好配置文件就可以启动HAProxy
#haproxy配置文件语法检查
haproxy -c -f /usr/local/haproxy/conf/haproxy.cfg
Configuration file is valid
#haproxy服务启动
systemctl start haproxy
#haproxy服务开机自启动
chkconfig --add haproxy
chkconfig haproxy on
chkconfig --list|grep haproxyHaproxy常用命令
# 检查配置文件语法
haproxy -c -f /etc/haproxy/haproxy.cfg
# 以daemon模式启动,以systemd管理的daemon模式启动
haproxy -D -f /etc/haproxy/haproxy.cfg [-p /var/run/haproxy.pid]
haproxy -Ds -f /etc/haproxy/haproxy.cfg [-p /var/run/haproxy.pid]
# 启动调试功能,将显示所有连接和处理信息在屏幕
haproxy -d -f /etc/haproxy/haproxy.cfg
# restart。需要使用st选项指定pid列表
haproxy -f /etc/haproxy.cfg [-p /var/run/haproxy.pid] -st `cat /var/run/haproxy.pid`
# graceful restart,即reload。需要使用sf选项指定pid列表
haproxy -f /etc/haproxy.cfg [-p /var/run/haproxy.pid] -sf `cat /var/run/haproxy.pid`
# 显示haproxy编译和启动信息
haproxy -vvHAProxy管理控制平台
当启动好HAProxy就可以启动管理界面查看集群的信息
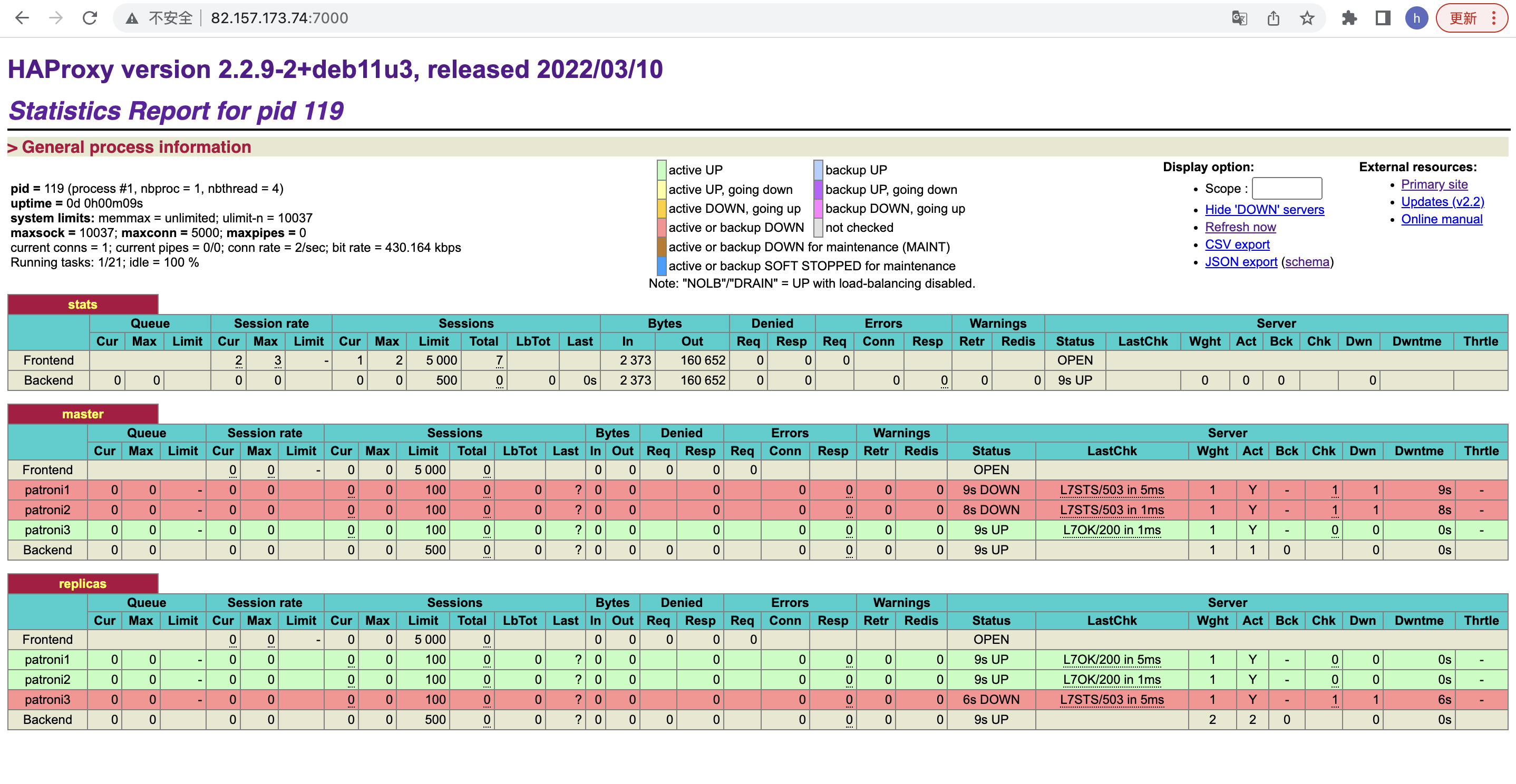
页面参数详解:
- Queue(等待队列)
Cur: 当前队列等待请求数
Max:队列最大等待请求数
Limit:队列中等待处理的最大请求阈值(只能用于 server 字段)。若队列中等待请求的数量超过该阈值,则下一个请求将被定向到其他服务器。默认为0,表示没有限制; - Session rate(每秒的连接会话):
cur: 当前每秒建立的会话数
max:从 HAProxy 启动到现在,每秒建立的最大会话数;
lim:每秒最多建立的会话阈值,只能用于 global 字段; - Sessions (当前会话数)
Total:从 HAProxy 启动到现在,总共建立的会话数;
Cur:当前建立连接的会话数;
Max:从 HAProxy 启动到现在,最多同时建立的会话数;
Limit: 最大并发会话数;
Lbtot: 从 HAProxy 启动到现在,服务器被负载命中次数;
Last:最新的会话创建于多久之前; - Bytes(出入流量)
In:输入字节数;
Out:输出字节数; - Denied
Req:拒绝请求的次数
Resp:拒绝响应的次数 - Errors
Req:错误请求数
Conn:错误连接数
Resp: 错误响应数 - Warnings
Retr: retries重新尝试连接次数
Redis:redispatches 重新分配次数(当 real server 挂掉后,强制定向到其他健康的服务器 ); - Server:
Status:状态以及该状态的持续时间,包括 UP 和 DOWN 两种状态;
LastChk:最近一次对后端服务器进行健康检查是在多久以前、检查结果。若出错,会提示错误原因;
Wght: (weight) : 权重
Act: 服务器是否处于活动状态(即非备份机,服务器),活动服务器(活动状态且非宕机)的数量(backend)。活动状态完全由属性 backup 决定,就算服务器宕机,只要未指定该字段,就算活动状态。
Bck: 服务器是否为备用机(Y:是),备用服务器(备用状态且非宕机)的数量(Backend);
正常情况下,备用机是不对外提供服务的,只有当所有非备用机都宕机之后,备用机才会提供服务。;
Chk:从HAProxy启动到现在,健康检测失败的累计次数;
Down:从HAProxy启动到现在,服务器宕机的累计次数;
Downtime: 从HAProxy启动到现在,服务器宕机的累计时间;
Throttle: 慢启动状态;
管理模式
可以对各个backend项的后端服务器进行管理
在左侧勾选好对应的后端节点,选择需要转换的模式,点击APPLY应用即可
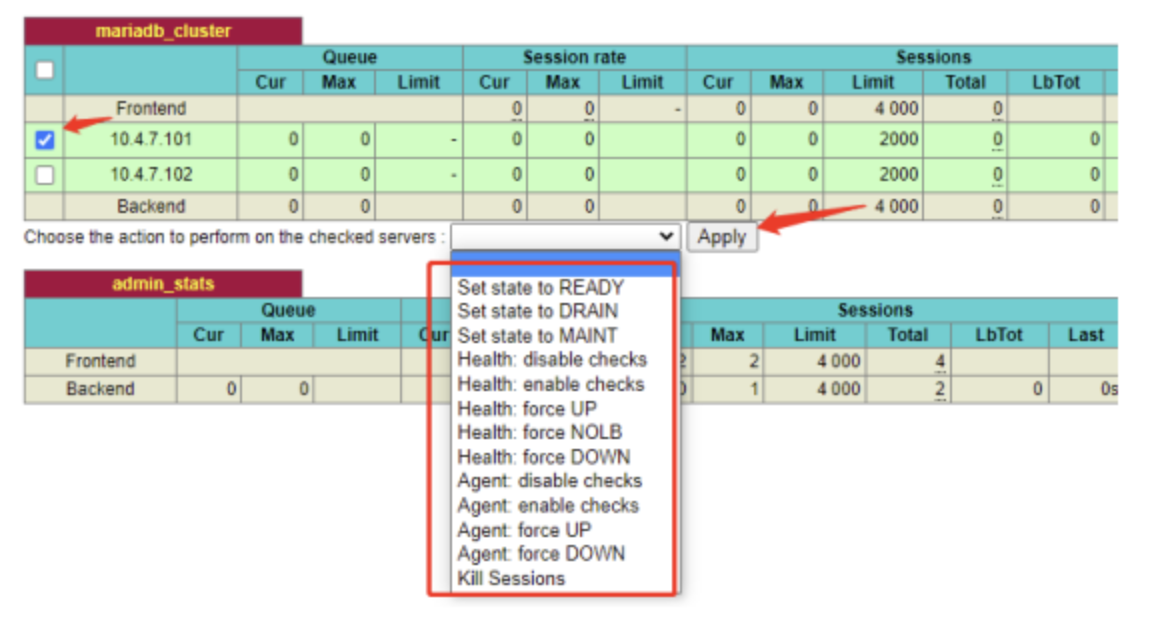
各个模式详情如下:
- Set state to READY:正常模式。若后端服务正常,则此操作后,后端服务将对外提供服务。
- Set state to DRAIN:排干模式,新的请求不再接收,旧的请求继续等待执行完毕。
- Set state to MAINT:维护模式。维护模式下,后端服务不再对外提供服务,并等待已有的请求结束连接,此操作会影响服 务器宕机次数 Dwn(+1)、宕机时间 Dwntme。
- Health: disable checks:停止健康检查。
- Health: enable checks: 启用健康检查。
- Health: force UP:强制将健康检查结果设置为 UP。指令执行后,服务器状态会马上变成 UP, 若后续健 康检查出错,服务器仍会变成 Down。
- Health: force NOLB:强制将服务剔除负载均衡。功能类似于 Health: force DOWN,区别在于 此操作不会影 响服务器宕机次数 Dwn、宕机时间 Dwntme。指令执行后,后端服务不 再参与负载均衡,即不对 外提供服务,若后续后端服 务恢复正常,则服务器状态会自动 转变成 UP,并继续对外提供服务。
- Health: force DOWN: 强制将健康检查结果设置为 Down,此操作会影响服务器宕机次数 Dwn(+1)、宕机时间 Dwntme。指令执行后,后端服务会被强制下线,将不再对外提供服务,若后续后端服务恢复正常,则服务器状态会自动转变成 UP,并继续对外提供 服务。
- kill Session:杀死所有会话。
服务上下线
通过更改Haproxy配置,然后热重启Haproxy(-st 指令)来上下线节点,是非常不错的方案!不过,在高频业务场景中,剔除后端节点再热重启Haproxy,可能出现业务请求异常问题,所以我们可以通过控制平台操作节点的在线状态来配合节点的平滑升级。
将节点调整为MAINT维护模式,之前连接不受影响,不会接受新的连接,当节点重启完成后改回READY状态,数据流重新轮询。
连接Patroni集群
按照上面的Haproxy配置,只要配置好Server的IP地址就可以连接到集群,但是在官方的配置中并没有手动的去配置,而是利用了Condf来自动的获取Patroni的信息进行配置,通过Etcd来获取Patroni的集群信息。
秘密就在entrypoint.sh启动文件上
#!/bin/sh
if [ -f /a.tar.xz ]; then
echo "decompressing image..."
sudo tar xpJf /a.tar.xz -C / > /dev/null 2>&1
sudo rm /a.tar.xz
sudo ln -snf dash /bin/sh
fi
readonly PATRONI_SCOPE=${PATRONI_SCOPE:-batman}
PATRONI_NAMESPACE=${PATRONI_NAMESPACE:-/service}
readonly PATRONI_NAMESPACE=${PATRONI_NAMESPACE%/}
readonly DOCKER_IP=$(hostname --ip-address)
case "$1" in
haproxy)
haproxy -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid -D
CONFD="confd -prefix=$PATRONI_NAMESPACE/$PATRONI_SCOPE -interval=10 -backend"
if [ ! -z "$PATRONI_ZOOKEEPER_HOSTS" ]; then
while ! /usr/share/zookeeper/bin/zkCli.sh -server $PATRONI_ZOOKEEPER_HOSTS ls /; do
sleep 1
done
exec dumb-init $CONFD zookeeper -node $PATRONI_ZOOKEEPER_HOSTS
else
while ! etcdctl cluster-health 2> /dev/null; do
sleep 1
done
exec dumb-init $CONFD etcdv3 -node $(echo $ETCDCTL_ENDPOINTS | sed 's/,/ -node /g')
fi
;;
etcd)
exec "$@" -advertise-client-urls http://$DOCKER_IP:2379
;;
zookeeper)
exec /usr/share/zookeeper/bin/zkServer.sh start-foreground
;;
esac
## We start an etcd
if [ -z "$PATRONI_ETCD3_HOSTS" ] && [ -z "$PATRONI_ZOOKEEPER_HOSTS" ]; then
export PATRONI_ETCD_URL="http://127.0.0.1:2379"
etcd --data-dir /tmp/etcd.data -advertise-client-urls=$PATRONI_ETCD_URL -listen-client-urls=http://0.0.0.0:2379 > /var/log/etcd.log 2> /var/log/etcd.err &
fi
export PATRONI_SCOPE
export PATRONI_NAMESPACE
export PATRONI_NAME="${PATRONI_NAME:-$(hostname)}"
export PATRONI_RESTAPI_CONNECT_ADDRESS="$DOCKER_IP:8008"
export PATRONI_RESTAPI_LISTEN="0.0.0.0:8008"
export PATRONI_admin_PASSWORD="${PATRONI_admin_PASSWORD:-admin}"
export PATRONI_admin_OPTIONS="${PATRONI_admin_OPTIONS:-createdb, createrole}"
export PATRONI_POSTGRESQL_CONNECT_ADDRESS="$DOCKER_IP:5432"
export PATRONI_POSTGRESQL_LISTEN="0.0.0.0:5432"
export PATRONI_POSTGRESQL_DATA_DIR="${PATRONI_POSTGRESQL_DATA_DIR:-$PGDATA}"
export PATRONI_REPLICATION_USERNAME="${PATRONI_REPLICATION_USERNAME:-replicator}"
export PATRONI_REPLICATION_PASSWORD="${PATRONI_REPLICATION_PASSWORD:-replicate}"
export PATRONI_SUPERUSER_USERNAME="${PATRONI_SUPERUSER_USERNAME:-postgres}"
export PATRONI_SUPERUSER_PASSWORD="${PATRONI_SUPERUSER_PASSWORD:-postgres}"
exec python3 /patroni.py postgres0.yml
其他的先不用看,先来看看sh脚本中关于haproxy的判断设置
haproxy -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid -D
CONFD="confd -prefix=$PATRONI_NAMESPACE/$PATRONI_SCOPE -interval=10 -backend"
if [ ! -z "$PATRONI_ZOOKEEPER_HOSTS" ]; then
while ! /usr/share/zookeeper/bin/zkCli.sh -server $PATRONI_ZOOKEEPER_HOSTS ls /; do
sleep 1
done
exec dumb-init $CONFD zookeeper -node $PATRONI_ZOOKEEPER_HOSTS
else
while ! etcdctl cluster-health 2> /dev/null; do
sleep 1
done
exec dumb-init $CONFD etcdv3 -node $(echo $ETCDCTL_ENDPOINTS | sed 's/,/ -node /g')
fi
;;在这里,最关键的是先去etcdctl命令去判断etcd是否存活2个以上,再去用exec dumb-init $CONFD etcdv3 -node $(echo $ETCDCTL_ENDPOINTS | sed 's/,/ -node /g'),通过模版自动的生成配置,会定期更新 haproxy.cfg 与实际的 Patroni 节点列表,etcd并在必要时“重新加载” haproxy。
其实这个启动脚本上有很多关键的内容
- 获取Docker的IP地址
- 获取环境变量进行修改或填充
- 针对不同的镜像不同的启动创建,如果Haproxy,Etcd,Patroni等
- 设置了很多Patroni的默认环境变量
Haproxy的Confd模版-templates
global
maxconn 5000
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen master
bind *:5000
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
{{range gets "/members/*"}} server {{base .Key}} {{$data := json .Value}}{{base (replace (index (split $data.conn_url "/") 2) "@" "/" -1)}} maxconn 100 check port {{index (split (index (split $data.api_url "/") 2) ":") 1}}
{{end}}
listen replicas
bind *:5001
option httpchk OPTIONS /replica
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
{{range gets "/members/*"}} server {{base .Key}} {{$data := json .Value}}{{base (replace (index (split $data.conn_url "/") 2) "@" "/" -1)}} maxconn 100 check port {{index (split (index (split $data.api_url "/") 2) ":") 1}}
{{end}}
Haproxy的Confd模版-Conf.d
[template]
#prefix = "/service/batman"
#owner = "haproxy"
#mode = "0644"
src = "haproxy.tmpl"
dest = "/etc/haproxy/haproxy.cfg"
check_cmd = "/usr/sbin/haproxy -c -f {{ .src }}"
reload_cmd = "haproxy -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid -D -sf $(cat /var/run/haproxy.pid)"
keys = [
"/members/",
]
这里有一点需要注意的是,在下图中,HAproxy分别展示出了Patroni的master与replicas,那HAproxy是如何感知到哪个是主服务器哪个是备用服务器呢?
答案是通过HAproxy的健康检测功能
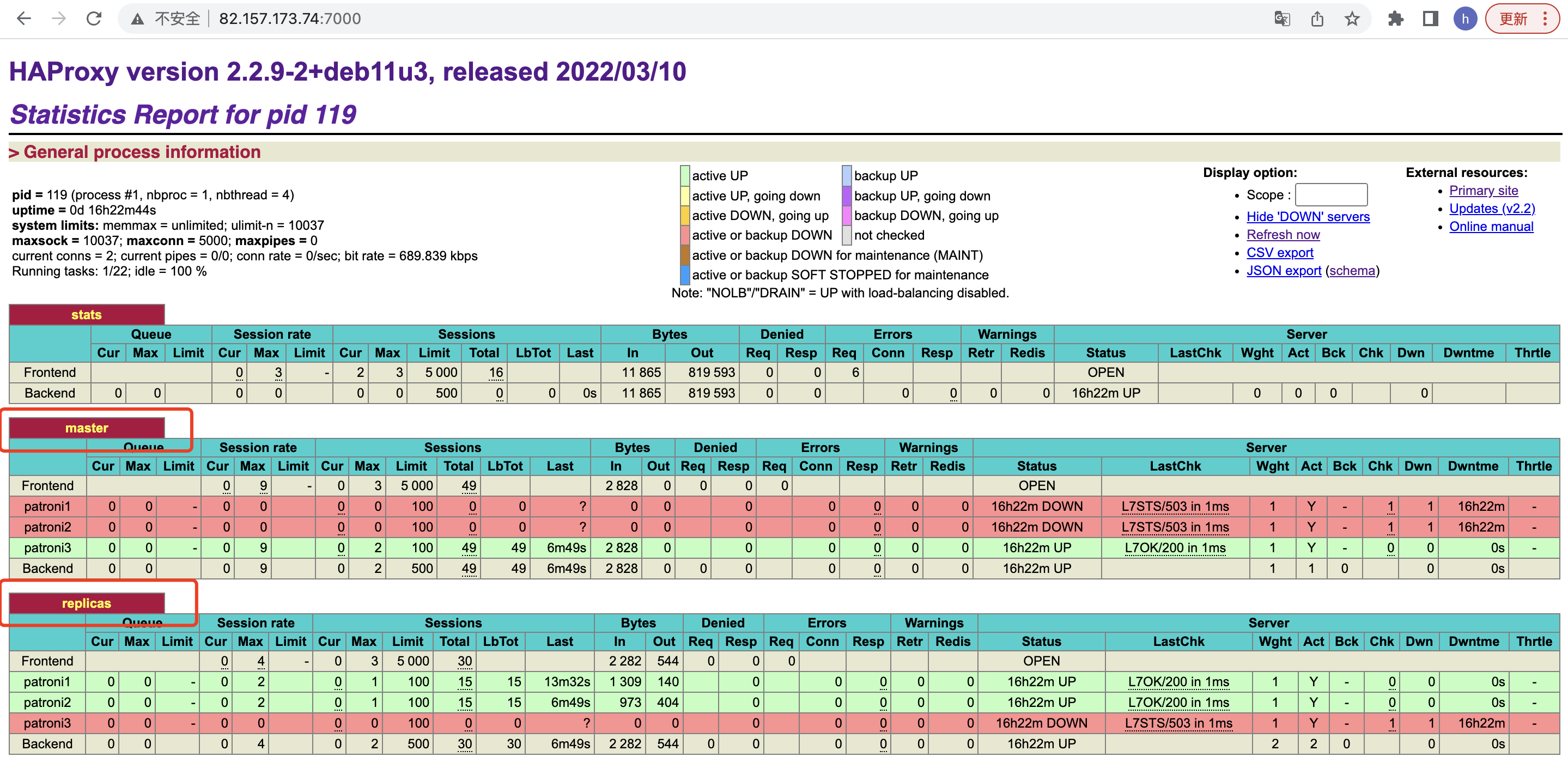
// 通过Http判断是否master节点,返回200状态码
option httpchk OPTIONS /master
http-check expect status 200
// 通过Http判断是否replica节点,返回200状态码
option httpchk OPTIONS /replica
http-check expect status 200HAproxy健康检查的三种方式
通过监听端口进行健康检测
这种检测方式,haproxy只会去检查server的端口,并不能保证服务真正可用。
listen http_proxy 0.0.0.0:80
mode http
cookie SERVERID
balance roundrobin
option httpchk
# 我在web01节点上监测172.30.1.107的9000端口是否存在,若存在说明服务正常,若不存在说明服务不正常
# 为了看到试验效果,我只在172.30.1.107安装了httpd服务,即并没有启动9000端口,因此状态页面应该可以看到该服务是异常的
server web01 172.30.1.106:80 cookie httpd-106 check port 9000 addr 172.30.1.107 inter 3000 fall 3 rise 5通过URI进行健康检测
这种检测方式,是用去GET后端server的web页面,基本可以代表后端服务的可用性。
option httpchk
option httpchk <uri>
option httpchk <method> <uri>
option httpchk <method> <uri> <version>在default、backend、listen使用,禁止在frontend使用。
method:可以指定http协议中的方法,默认使用 OPTIONS,然使用OPTIONS 对后端服务器的性能影响最小。
uri:默认 / ,也可以设置成其他的地址,也可以使用query的格式。
version:http的协议版本,可选项 HTTP/1.0和HTTP/1.1,默认HTTP/1.0,在有一些web服务中,需要加上HOST的信息,可以在HTTP/1.1后需要加上/r/n拼接HOST,例如:HTTP/1.1\r\nHost:www
option httpchk /chk.html
option httpchk OPTIONS /chk.html
option httpchk OPTIONS /chk.html HTTP/1.0
以上三个等同,只是写法不一样。
option httpchk OPTIONS /index.php?abc=abc HTTP/1.1\r\nHost:wwwlisten http_proxy 0.0.0.0:80
mode http
cookie SERVERID
balance roundrobin
#使用GET方法基于指定URL监控,使用的HTTP协议为HTTP/1.0(如果是基于yum方式安装的Apache httpd后端服务器不要写"HTTP 1.1"哟,最好使用"HTTP 1.0")
option httpchk GET /monitor/index.html HTTP/1.0
server web1 192.168.1.1:80 cookie server01 check
server web2 192.168.1.2:80 cookie serve02 check inter 500 rise 1 fall 2
通过request获取的头部信息进行匹配进行健康检测
这种检测方式,是基于一些高级、精细的监测需求,通过对后端头部访问的头部信息进行匹配检测。
listen http_proxy 0.0.0.0:80
mode http
cookie SERVERID
balance roundrobin
#通过request获取的头部信息进行匹配进行健康检测
option httpchk HEAD /index.jsp HTTP/1.1\r\n\Host:\www.xxx.com
server web1 192.168.1.1:80 cookie server01 check
server web2 192.168.1.2:80 cookie serve02 check inter 500 rise 1 fall 2
扩展-Confd简介
当系统变的复杂,配置项越来越多,一方面配置管理变得繁琐,另一方面配置修改后需要重新上线同样十分痛苦。这时候,需要有一套集中化配置管理系统,一方面提供统一的配置管理,另一方面提供配置变更的自动下发,及时生效。
说道统一配置管理系统,大家应该比较熟悉,常见的:zookeeper、etcd、consul、git等等。
上述的集中配置中心使用的时候,部署图大致是这样的:
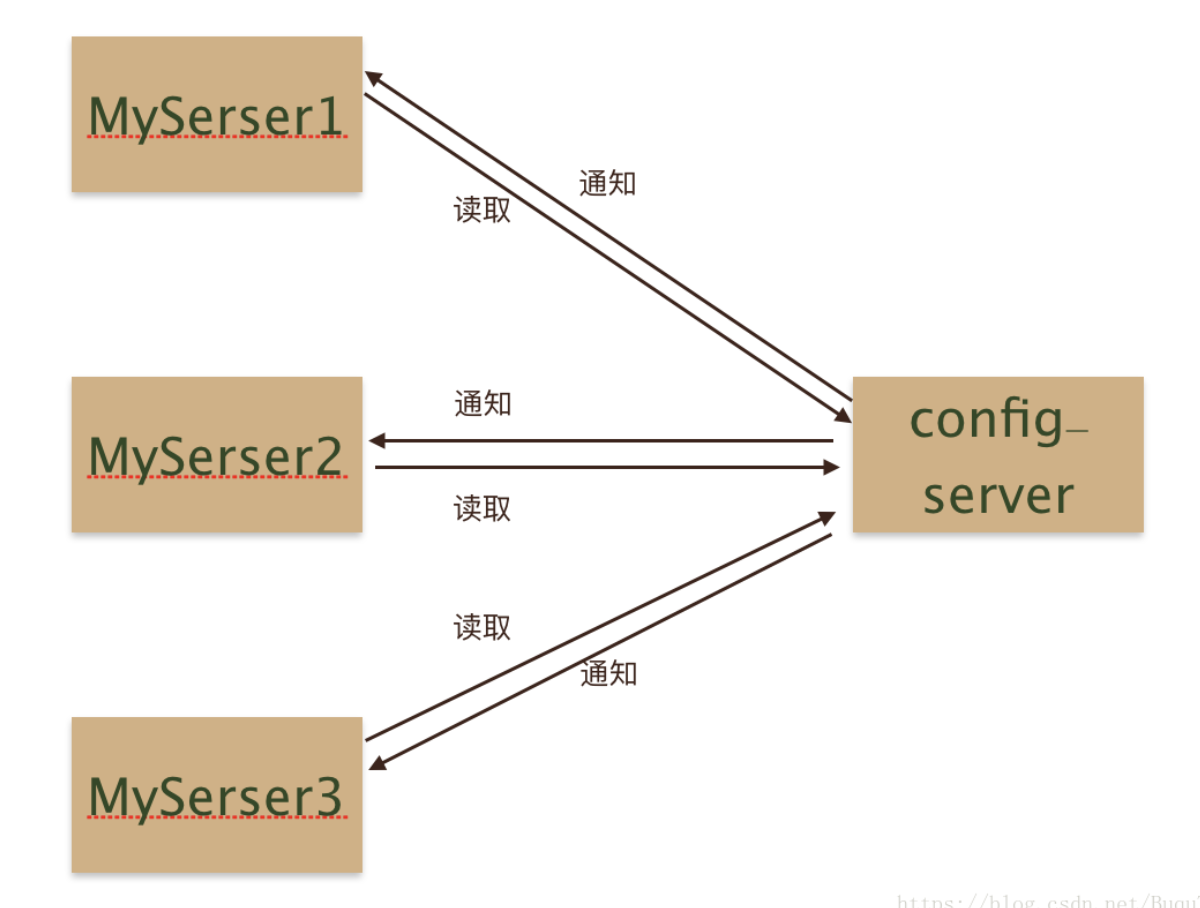
server端只需要调用config-server对应客户端获取配置,和监听配置变更就可以了。总体来说没有太大难度。
接下来要说一下confd,它提供了一种新的集成思路。confd的存在有点类似于快递员,买了东西不需要自己到店去取货了,confd这个快递员回把货取过来,然后送到家里,并且通知你货已经送到了。加入confd之后的架构大致是这样的
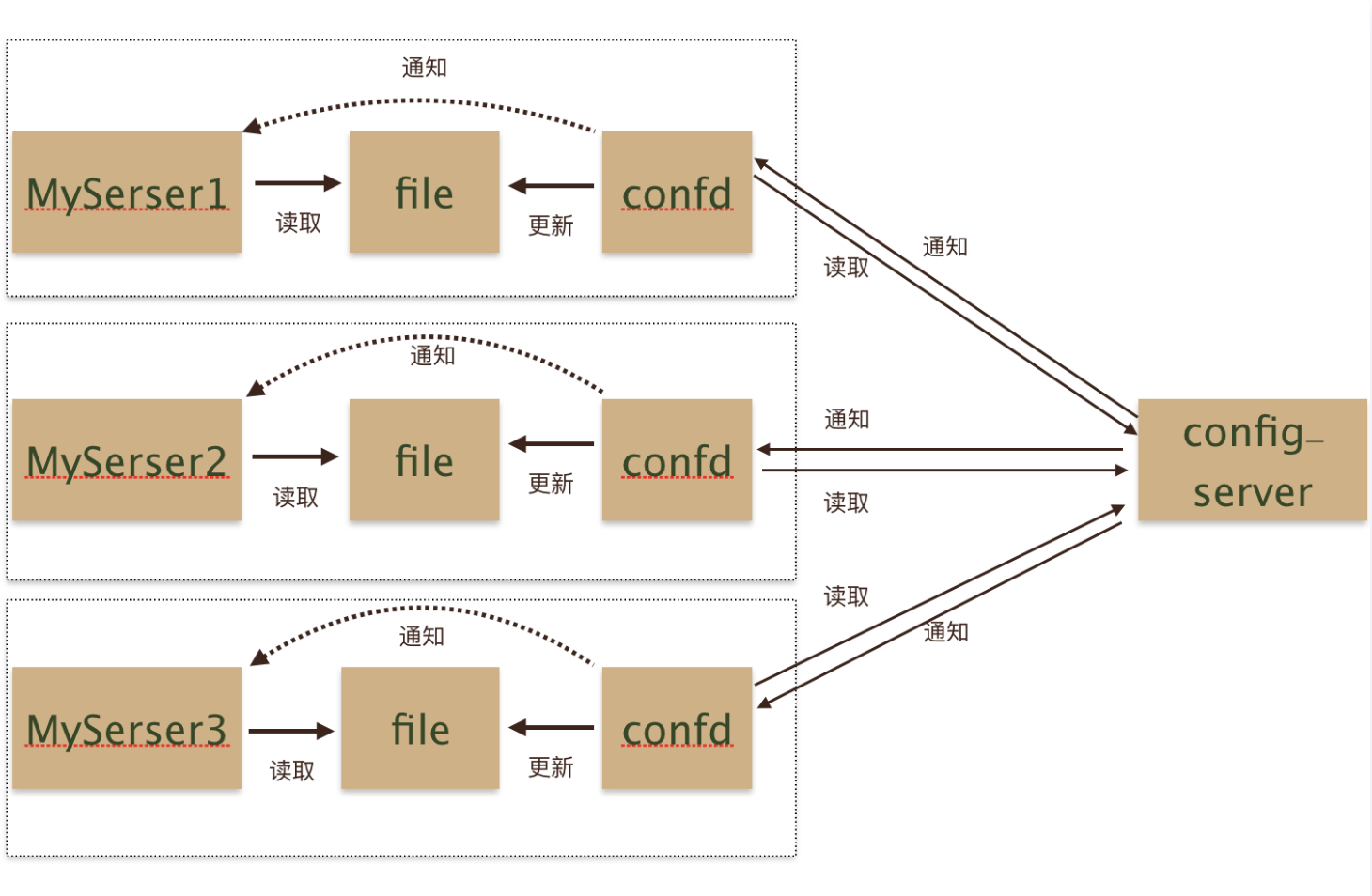
Confd是如何工作的
confd使用时有几个概念需要熟悉,并且熟悉他们之间的依赖关系,才能理解如何配置confd,不然会比较懵。这里我们先看一下confd配置的几个概念之间是如何交互的:
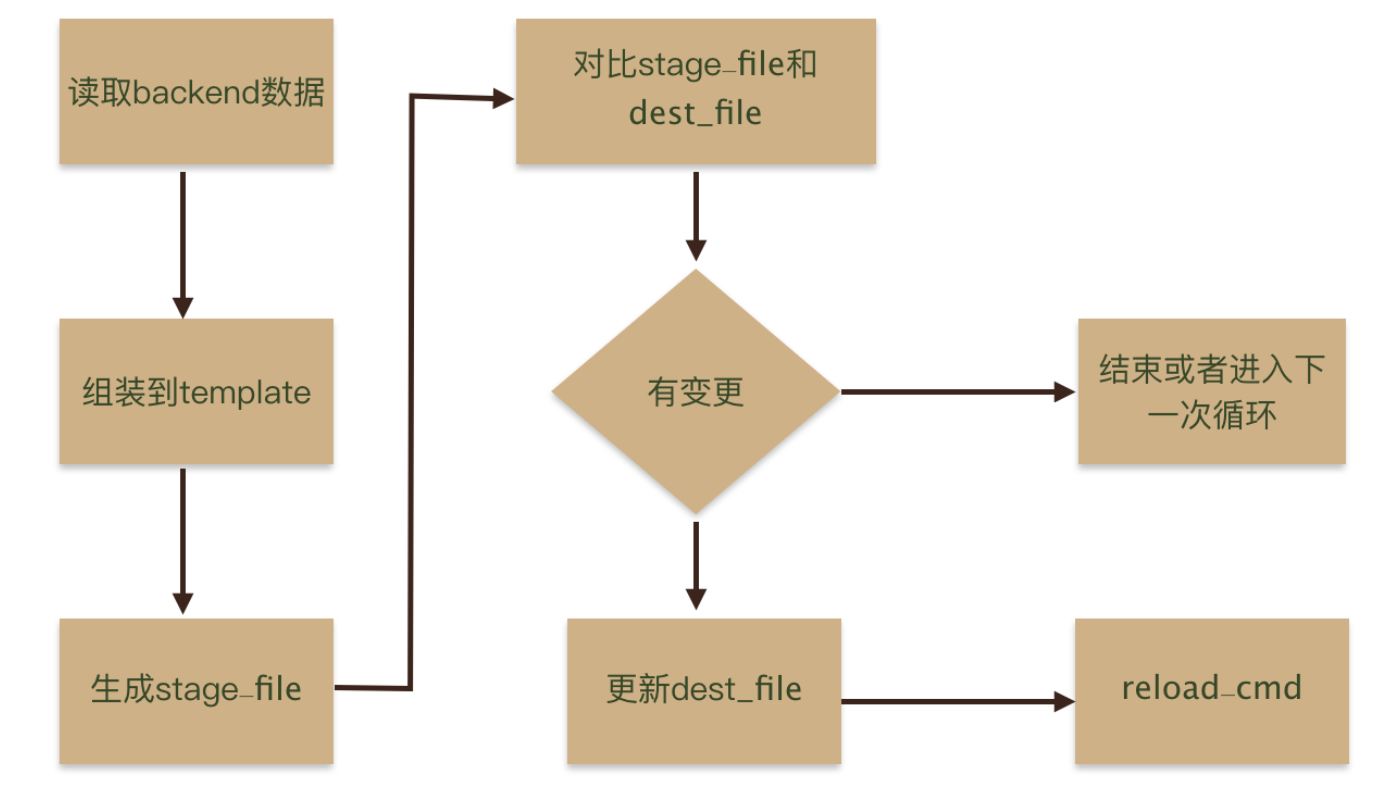
Confd的配置
Confd通过读取后端存储的配置信息来动态更新对应的配置文件,对应的后端存储可以是etcd,redis等,其中etcd的v3版本对应的存储后端为etcdv3。
confdir底下包含两个目录:
-
conf.d:confd的配置文件,主要包含配置的生成逻辑,例如模板源,后端存储对应的keys,命令执行等。 -
templates:配置模板Template,即基于不同组件的配置,修改为符合 Golang text templates的模板文件。
conf.d文件
模板源配置文件是TOML格式的文件,主要包含配置的生成逻辑,例如模板源,后端存储对应的keys,命令执行等。默认目录在/etc/confd/conf.d。
参数说明:
必要参数
-
dest(string) – The target file. -
keys(array of strings) – An array of keys. -
src(string) – The relative path of a configuration template.
可选参数
-
gid(int) – The gid that should own the file. Defaults to the effective gid. -
mode(string) – The permission mode of the file. -
uid(int) – The uid that should own the file. Defaults to the effective uid. -
reload_cmd(string) – The command to reload config. -
check_cmd(string) – The command to check config. Use{{.src}}to reference the rendered source template. -
prefix(string) – The string to prefix to keys.
例子:/etc/confd/conf.d/myapp-nginx.toml
[template]
prefix = "/myapp"
src = "nginx.tmpl"
dest = "/tmp/myapp.conf"
owner = "nginx"
mode = "0644"
keys = [
"/services/web"
]
check_cmd = "/usr/sbin/nginx -t -c {{.src}}"
reload_cmd = "/usr/sbin/service nginx reload"Template文件
Template定义了单一应用配置的模板,默认存储在/etc/confd/templates目录下,模板文件符合Go的text/template格式。
模板文件常用函数有base,get,gets,lsdir,json等。具体可参考https://github.com/kelseyhightower/confd/blob/master/docs/templates.md
例子:/etc/confd/templates/nginx.tmpl
{{range $dir := lsdir "/services/web"}}
upstream {{base $dir}} {
{{$custdir := printf "/services/web/%s/*" $dir}}{{range gets $custdir}}
server {{$data := json .Value}}{{$data.IP}}:80;
{{end}}
}
server {
server_name {{base $dir}}.example.com;
location / {
proxy_pass {{base $dir}};
}
}
{{end}}启动Confd的服务
confd支持以daemon或者onetime两种模式运行,当以daemon模式运行时,confd会监听后端存储的配置变化,并根据配置模板动态生成目标配置文件。
如果以daemon模式运行,则执行以下命令:
confd -watch -backend etcdv3 -node http://172.16.5.4:12379 &以onetime模式运行为例。其中对应的后端存储类型是etcdv3
confd -onetime -backend etcdv3 -node http://172.16.5.4:12379定时自动更新配置
confd -interval 60 -backend file -file /tmp/myapp.yamlinterval单位是秒,默认值是600秒
Patroni部署
终于到这个部署的重头戏——Patroni
Patroni的部署可以按照官方的来进行,但是这里比较关键的是Patroni的环境变量与配置文件。
比如上面的docker-compose配置中的环境变量PATRONI_ETCD3_HOSTS,就是设置Etcd的连接端口信息,PATRONI_SUPERUSER_USERNAME与PATRONI_SUPERUSER_PASSWORD就是数据库的账号密码。
按照目前的配置与官方的代码文件运行docker-compose up -d就可以运行起来啦。
Patroni详细配置
复制选择
Patroni 使用 Postgres 的流式复制,默认情况下是异步的。 Patroni 的异步复制配置允许maximum_lag_on_failover 设置。 此设置可确保如果跟随者超过领导者的一定数量的字节,也不会发生故障转移。应根据业务需求增加或减少此设置。 也可以使用同步复制来获得更好的持久性保证。
应用程序不应使用超级用户
从应用程序连接时,请始终使用非超级用户。Patroni才能正常访问数据库功能。通过使用应用程序中的超级用户,您可以通过设置superuser_reserved_connections来使用整个连接池,包括为超级用户保留的连接。但是如果Patroni由于连接池已满而无法访问主服务器,那么不希望有这种行为。
配置信息
Patroni配置存储在DCS(分布式配置存储)中。有3种类型的配置:
•动态配置。这些选项可随时在DCS中设置。如果更改的选项不是启动配置的一部分,则它们将异步(在下一个唤醒周期中)应用于每个节点,然后重新加载。如果节点需要重新启动以应用配置(对于具有context postmaster的选项,如果其值已更改),则会在members.data JSON中设置一个特殊标志pending_restart标记。此外,节点状态还通过显示“restart_pending”:true来表明这一点。
•本地配置(patroni.yml). 这些选项在配置文件中定义,优先于动态配置。可以通过向Patroni进程发送SIGHUP、执行POST/reload REST-API请求或执行patronictl reload.在运行时(无需重新启动Patroni)更改和重新加载Patroni.yml。
•环境配置。可以使用环境变量设置/覆盖某些“本地”配置参数。当您在动态环境中运行并且事先不知道某些参数时(例如,在docker内部运行时,不可能知道外部IP地址),环境配置非常有用。
本地配置可以是单个YAML文件或目录。当它是一个目录时,该目录中的所有YAML文件将按排序顺序逐个加载。如果在多个文件中定义了一个键,则以最后一个文件中出现的键为准。
某些PostgreSQL参数在主数据库和副本数据库上必须具有相同的值。
- max_connections: 100
- max_locks_per_transaction: 64
- max_worker_processes: 8
- max_prepared_transactions: 0
- wal_level: hot_standby
- wal_log_hints: on
- track_commit_timestamp: off
对于以下参数,PostgreSQL在主副本和所有副本之间不需要相等的值。但是考虑到副本随时可能成为主数据库的可能性,对它们进行不同的设置并没有多大意义。因此,Patroni将其值限制为动态配置。
- max_wal_senders: 5
- max_replication_slots: 5
- wal_keep_segments: 8
- wal_keep_size: 128MB
Patroni还控制着其他一些Postgres参数
- listen_addresses -是从postgresql.listen或从PATRONI_POSTGRESQL_LISTEN环境变量设置的
- port – 通过postgresql.listen或PATRONI_POSTGRESQL_LISTEN环境设置变量
- cluster_name – 从scope或PATRONI_SCOPE环境变量设置
- hot_standby: on (切换为备机时仍然提供查询服务)
这些都是常用的参数,详细的需要看官方文档
Patroni REST API
Patroni具有丰富的REST API,Patronictl自身在领导者竞赛中使用了patronictl工具,以执行故障转移/切换/重新初始化/重新启动/重新加载,通过HAProxy或任何其他类型的负载平衡器来执行HTTP健康检查 ,当然也可以用于监视。在下面,您将找到Patroni REST API端点的列表。
健康检查端点
对于所有运行状况检查,GET请求Patroni返回一个JSON文档以及该节点的状态以及HTTP状态代码。如果您不需要或不需要JSON文档,则可以考虑使用OPTIONS方法而不是GET。
- 仅当Patroni节点作为领导者运行时,对Patroni REST API的以下请求将返回HTTP状态代码200:
–GET/
–GET/master
–GET/primary
–GET/read-write - GET /standby-leader:仅当Patroni 节点在备用集群中作为leader 运行时才返回HTTP 状态代码200。
- GET /leader:当Patroni 节点有leader 锁时,返回HTTP 状态码200。 与前两个端点的主要区别在于它没有考虑 PostgreSQL 是作为主服务器还是作为后备领导者运行。
- GET /replica: replica健康检查端点。 仅当Patroni节点处于running状态,角色为replica且未设置noloadbalance标签时,才返回HTTP状态码200。
- GET /replica?lag=<max-lag>:replica检查端点。 除了从replica检查外,它还检查复制延迟并仅在低于指定值时返回状态代码 200。 出于性能原因,来自 DCS 的关键 cluster.last_leader_operation 用于 Leader wal 位置和replica上的计算延迟。 max-lag 可以以字节(整数)或人类可读的值指定,例如 16kB、64MB、1GB。
– GET /replica?lag=1048576
– GET /replica?lag=1024kB
– GET /replica?lag=10MB
– GET /replica?lag=1GB - GET /replica?tag_key1=value1&tag_key2=value2:replica检查端点。 此外,它还将在 yaml 的标签部分检查用户定义的标签 key1 和 key2 及其各自的值 配置管理。 如果没有为实例定义标签,或者 yaml 配置中的值与查询值不匹配,它将返回 HTTP 状态代码 503。
- 在以下请求中,由于我们正在检查leader或standby-leader的状态,因此 Patroni 不会应用任何用户定义的标签,它们将被忽略。
- GET /?tag_key1=value1&tag_key2=value2
- GET /master?tag_key1=value1&tag_key2=value2
- GET /leader?tag_key1=value1&tag_key2=value2
- GET /primary?tag_key1=value1&tag_key2=value2
- GET /read-write?tag_key1=value1&tag_key2=value2
- GET /standby_leader?tag_key1=value1&tag_key2=value2
- GET /standby-leader?tag_key1=value1&tag_key2=value2
- GET /read-only:与上述端点类似,但也包括主节点
- GET /synchronous 或GET /sync:仅当Patroni 节点作为同步备用节点运行时才返回HTTP 状态代码200。
- GET /asynchronous 或 GET /async:仅当 Patroni 节点作为异步备用节点运行时才返回 HTTP 状态代码 200
- GET /asynchronous?lag= 或 GET /async?lag=:异步待机 检查端点。 除了检查异步或异步之外,它还检查复制延迟并仅在低于指定值时返回状态代码 200。 出于性能原因,来自 DCS 的关键 cluster.last_leader_operation 用于 Leader wal 位置和replica上的计算延迟。 max-lag 可以以字节(整数)或人类可读的值指定,例如 16KB、64MB、1GB。
– GET /async?lag=1048576
– GET /async?lag=1024kB
– GET /async?lag=10MB
– GET /async?lag=1GB - GET /health:仅当PostgreSQL 启动并运行时才返回HTTP 状态代码200。
- GET /liveness:始终返回 HTTP 状态代码 200,它仅表示 Patroni 正在运行。 可用于 livenessProbe。
- GET /readiness:当Patroni 节点作为领导者运行或PostgreSQL 启动并运行时,返回HTTP 状态代码200。 当无法使用 Kubernetes 端点进行领导选举 (OpenShift) 时,端点可用于 readinessProbe。
监控端点
- GET /patroni 由 Patroni 在leader选举期间使用。 您的监控系统也可以使用它。此端点生成的 JSON 文档与健康检查端点生成的 JSON 具有相同的结构。
集群状态端点
- GET /cluster 端点生成描述当前集群拓扑和状态的 JSON 文档
- GET /history 端点提供了有关集群切换/故障切换历史的视图。 格式与 pg_wal 目录中的历史文件的内容非常相似。唯一的区别是显示新时间线创建时间的时间戳字段。
上述是查看集群的状态信息,其他的比如修改,重启,切换故障等接口查看API文档。
环境配置设置
可以使用系统环境变量覆盖 Patroni 配置文件中定义的一些配置参数。 通过这些变量设置的值始终优先于在 Patroni 配置文件中设置的值。
全局/通用
- PATRONI_CONFIGURATION:可以通过PATRONI_CONFIGURATION 环境变量为Patroni 设置整个配置。 在这种情况下,不会考虑任何其他环境变量!
- PATRONI_NAME:当前运行Patroni 实例的节点的名称。 对于集群必须是唯一的。
- PATRONI_NAMESPACE:Patroni保留有关集群的信息在配置存储的路径中。 默认值:“/service”
- PATRONI_SCOPE:集群名称
日志
- PATRONI_LOG_LEVEL:设置一般日志记录级别。 默认值为 INFO(请参阅 Python 日志记录文档 16.6.2)
- PATRONI_LOG_TRACEBACK_LEVEL:设置回溯可见的级别。 默认值为错误。 如果您只想在启用 PATRONI_LOG_LEVEL=DEBUG 时查看回溯,请将其设置为 DEBUG。
- PATRONI_LOG_FORMAT:设置日志格式字符串。 默认值为 %(asctime)s %(levelname)s: %(message)s(参见 LogRecord 属性)
- PATRONI_LOG_DATEFORMAT:设置日期时间格式字符串。 (请参阅 formatTime() 文档 https://docs.python.org/3.6/library/logging.html#logging.Formatter.formatTime)
- PATRONI_LOG_MAX_QUEUE_SIZE:Patroni 使用两步日志记录。 日志记录被写入内存队列,并且有一个单独的线程将它们从队列中拉出并写入 stderr 或文件。 内部队列的最大大小默认限制为 1000 条记录,足以保留过去 1h20m 的日志。
- PATRONI_LOG_DIR:应用程序日志写入的目录。 该目录必须存在并且可由执行 Patroni 的用户写入。 如果您设置此 env 变量,默认情况下应用程序将保留 4 个 25MB 的日志。 您可以使用 PATRONI_LOG_FILE_NUM 和 PATRONI_LOG_FILE_SIZE 调整这些保留值(请参见下文)。
- PATRONI_LOG_FILE_NUM:要保留的应用程序日志的数量。
- PATRONI_LOG_FILE_SIZE:触发日志滚动的patroni.log 文件的大小(以字节为单位)。
- PATRONI_LOG_LOGGERS:重新定义每个python 模块的日志记录级别。 示例 PATRONI_LOG_LOGGERS=”{patroni.postmaster: WARNING, urllib3: DEBUG}”
引导配置
可以在新集群成功初始化后立即创建新的数据库用户。 此过程由以下变量定义:
- PATRONI_<username>_PASSWORD=’<password>’
- PATRONI_<username>_OPTIONS=’list,of,options’
示例:定义 PATRONI_admin_PASSWORD=strongpasswd 和 PATRONI_admin_OPTIONS=’createrole,createdb’ 将导致使用密码 strongpasswd 创建用户 admin,允许创建其他用户和数据库。
Etcd
- PATRONI_ETCD_PROXY:etcd 的代理网址。如果您使用代理连接到 etcd,请使用此参数而不是 PATRONI_ETCD_URL
- PATRONI_ETCD_URL:etcd 的url,格式为:http(s)://(username:password@)host:port • PATRONI_ETCD_HOSTS:etcd 端点列表,格式为‘host1:port1’、‘host2:port2’等。 . .
- PATRONI_ETCD_USE_PROXIES:如果此参数设置为true,Patroni将把主机视为一个代理列表,不会执行etcd集群的拓扑发现,而是坚持使用固定的主机列表。
- PATRONI_ETCD_PROTOCOL:http 或 https,如果未指定,则使用 http。如果指定了 url 或proxy – 将从他们那里获取协议。
- PATRONI_ETCD_HOST:etcd端点格式:host:port。
- PATRONI_ETCD_SRV:搜索 SRV 记录以进行集群自动发现的域。 Patroni 将尝试查询指定域的这些 SRV 服务名称(按该顺序直到第一次成功):_etcd-client-ssl、_etcd-client、_etcd-ssl、_etcd、_etcd-server-ssl、_etcd-server。如果检索到 _etcd-server-ssl 或 _etcd-server 的 SRV 记录,则使用 ETCD 对等协议查询 ETCD 以获取可用成员。否则将使用 SRV 记录中的主机。
- PATRONI_ETCD_SRV_SUFFIX:配置发现期间查询的SRV 名称的后缀。使用此标志来区分同一域下的多个 etcd 集群。仅适用 与 PATRONI_ETCD_SRV 结合使用。例如,如果设置了 PATRONI_ETCD_SRV_SUFFIX=foo 和 PATRONI_ETCD_SRV=example.org,则会进行以下 DNS SRV 查询:_etcd-client-ssl-foo._tcp.example.com(对于每个可能的 ETCD SRV 服务名称,依此类推)。
- PATRONI_ETCD_USERNAME:用于etcd 身份验证的用户名。
- PATRONI_ETCD_PASSWORD:etcd 认证的密码。
- PATRONI_ETCD_CACERT:ca 证书。如果存在,它将启用验证。
- PATRONI_ETCD_CERT:包含客户端证书的文件。
- PATRONI_ETCD_KEY:包含客户端密钥的文件。如果密钥是证书的一部分,则可以为空。
Etcdv3 的环境名称与 Etcd 类似,您只需要在变量名称中使用 ETCD3 而不是 ETCD。 示例:PATRONI_ETCD3_HOST、PATRONI_ETCD3_CACERT 等。
PostgreSQL
- PATRONI_POSTGRESQL_LISTEN:Postgres监听的IP地址+ 端口号。 允许使用多个逗号分隔的地址,只要端口组件用冒号附加到最后一个地址之后,如 listen: 127.0.0.1,127.0.0.2:5432。 Patroni 将使用此列表中的第一个地址来建立到 PostgreSQL 节点的本地连接。
- PATRONI_POSTGRESQL_CONNECT_ADDRESS:IP 地址+ 端口,通过该端口可以从其他节点和应用程序访问 Postgres。
- PATRONI_POSTGRESQL_DATA_DIR:Postgres 数据目录的位置,可以是现有的,也可以是由Patroni 初始化的。
- PATRONI_POSTGRESQL_CONFIG_DIR:Postgres 配置目录的位置,默认为数据目录。 必须可由 Patroni 写入。
- PATRONI_POSTGRESQL_BIN_DIR:PostgreSQL 二进制文件的路径。 (pg_ctl, pg_rewind, pg_basebackup,postgres) 默认值是一个空字符串,意味着 PATH 环境变量将用于查找可执行文件。
- PATRONI_POSTGRESQL_PGPASS:.pgpass 密码文件的路径。 Patroni 在执行 pg_basebackup 之前和在其他一些情况下创建这个文件。 该位置必须可由 Patroni 写入。
- PATRONI_REPLICATION_USERNAME:复制用户名; 用户将在初始化期间创建。 副本将使用此用户通过流式复制访问主服务器
- PATRONI_REPLICATION_PASSWORD:复制密码; 用户将在初始化期间创建。
- PATRONI_REPLICATION_SSLMODE:(可选)映射到sslmode连接参数,它允许客户端指定与服务器的 TLS 协商模式的类型。有关每种模式如何工作的更多信息,请访问PostgreSQL 文档。默认模式是prefer。
- PATRONI_REPLICATION_SSLKEY:(可选)映射到sslkey连接参数,该参数指定与客户端证书一起使用的密钥的位置。
- PATRONI_REPLICATION_SSLPASSWORD:(可选)映射到sslpassword连接参数,该参数指定PATRONI_REPLICATION_SSLKEY.
- PATRONI_REPLICATION_SSLCERT:(可选)映射到sslcert连接参数,该参数指定客户端证书的位置。
- PATRONI_REPLICATION_SSLROOTCERT:(可选)映射到sslrootcert连接参数,指定包含一个或多个证书颁发机构(CA)证书的文件的位置,客户端将使用该证书来验证服务器的证书。
- PATRONI_REPLICATION_SSLCRL:(可选)映射到sslcrl连接参数,该参数指定包含证书吊销列表的文件的位置。客户端将拒绝连接到此列表中存在证书的任何服务器。
- PATRONI_REPLICATION_GSSENCMODE:(可选)映射到gssencmode连接参数,该参数确定是否或以何种优先级与服务器协商安全 GSS TCP/IP 连接
- PATRONI_REPLICATION_CHANNEL_BINDING:(可选)映射到channel_binding连接参数,该参数控制客户端对通道绑定的使用。
- PATRONI_SUPERUSER_USERNAME:超级用户的名称,在初始化 (initdb) 期间设置,稍后由 Patroni 用于连接到 postgres。这个用户也被 pg_rewind 使用。
- PATRONI_SUPERUSER_PASSWORD:超级用户的密码,在初始化 (initdb) 期间设置。
- PATRONI_SUPERUSER_SSLMODE:(可选)映射到sslmode连接参数,它允许客户端指定与服务器的 TLS 协商模式的类型。有关每种模式如何工作的更多信息,请访问PostgreSQL 文档。默认模式是prefer。
- PATRONI_SUPERUSER_SSLKEY:(可选)映射到sslkey连接参数,该参数指定与客户端证书一起使用的密钥的位置。
- PATRONI_SUPERUSER_SSLPASSWORD:(可选)映射到sslpassword连接参数,该参数指定PATRONI_SUPERUSER_SSLKEY.
- PATRONI_SUPERUSER_SSLCERT:(可选)映射到sslcert连接参数,该参数指定客户端证书的位置。
- PATRONI_SUPERUSER_SSLROOTCERT:(可选)映射到sslrootcert连接参数,该参数指定包含客户端将用于验证服务器证书的一个或多个证书颁发机构 (CA) 证书的文件的位置。
- PATRONI_SUPERUSER_SSLCRL:(可选)映射到sslcrl连接参数,该参数指定包含证书吊销列表的文件的位置。客户端将拒绝连接到此列表中存在证书的任何服务器。
- PATRONI_SUPERUSER_GSSENCMODE:(可选)映射到gssencmode连接参数,该参数决定是否或以何种优先级与服务器协商安全 GSS TCP/IP 连接
- PATRONI_SUPERUSER_CHANNEL_BINDING:(可选)映射到channel_binding连接参数,该参数控制客户端对通道绑定的使用。
- PATRONI_REWIND_USERNAME : 使用pg_rewind的用户名;在 postgres 11版本以上初始化期间创建用户,并授予所有必要的权限。
- PATRONI_REWIND_PASSWORD : 使用pg_rewind的用户密码; 在初始化过程中创建用户时被创建。
- PATRONI_REWIND_SSLMODE:(可选)映射到sslmode连接参数,它允许客户端指定与服务器的 TLS 协商模式的类型。有关每种模式如何工作的更多信息,请访问PostgreSQL 文档。默认模式是prefer。
- PATRONI_REWIND_SSLKEY:(可选)映射到sslkey连接参数,该参数指定与客户端证书一起使用的密钥的位置。
- PATRONI_REWIND_SSLPASSWORD:(可选)映射到sslpassword连接参数,该参数指定PATRONI_REWIND_SSLKEY.
- PATRONI_REWIND_SSLCERT:(可选)映射到sslcert连接参数,该参数指定客户端证书的位置。
- PATRONI_REWIND_SSLROOTCERT: (可选) 映射sslrootcert连接参数,指定包含一个或多个证书颁发机构(CA)证书的文件的位置,客户端将使用这些证书验证服务器的证书。
- PATRONI_REWIND_SSLCRL:(可选)映射到sslcrl连接参数,该参数指定包含证书吊销列表的文件的位置。客户端将拒绝连接到此列表中存在证书的任何服务器。
- PATRONI_REWIND_GSSENCMODE:(可选)映射到gssencmode连接参数,该参数确定是否或以何种优先级与服务器协商安全 GSS TCP/IP 连接
- PATRONI_REWIND_CHANNEL_BINDING:(可选)映射到channel_binding连接参数,该参数控制客户端对通道绑定的使用。
REST API
- PATRONI_RESTAPI_CONNECT_ADDRESS:访问 REST API 的 IP 地址和端口。
- PATRONI_RESTAPI_LISTEN:Patroni 将侦听的 IP 地址和端口,为 HAProxy 提供健康检查信息。
- PATRONI_RESTAPI_USERNAME:用于保护不安全 REST API 端点的基本身份验证用户名。
- PATRONI_RESTAPI_PASSWORD:用于保护不安全 REST API 端点的基本身份验证密码。
- PATRONI_RESTAPI_CERTFILE:指定带有 PEM 格式证书的文件。如果未指定 certfile 或将其留空,则 API 服务器将在没有 SSL 的情况下工作。
- PATRONI_RESTAPI_KEYFILE:指定具有 PEM 格式的密钥的文件。
- PATRONI_RESTAPI_KEYFILE_PASSWORD:指定用于解密密钥文件的密码。
- PATRONI_RESTAPI_CAFILE:指定带有 CA_BUNDLE 的文件,其中包含在验证客户端证书时要使用的受信任 CA 的证书。
- PATRONI_RESTAPI_CIPHERS:(可选)指定允许的密码套件(例如“ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES128-GCM -SHA256:!SSLv1:!SSLv2:!SSLv3:!TLSv1:!TLSv1.1”)
- PATRONI_RESTAPI_VERIFY_CLIENT:(none默认),optional或required。当设置为none 时,REST API 不会检查客户端证书时。当required所有 REST API 调用都需要客户端证书时。当optional所有不安全的 REST API 端点都需要客户端证书时。当required使用时,如果证书签名验证成功,则客户端验证成功。对于optional客户端证书将只检查PUT,POST,PATCH,和DELETE请求。
- PATRONI_RESTAPI_ALLOWLIST:(可选):指定允许调用不安全REST API端点的主机集。单个元素可以是主机名、IP地址或使用CIDR表示法的网络地址。默认情况下,将使用allow all。如果设置了allowlist 或 allowlist_include_members,则拒绝未包含的任何内容。
- PATRONI_RESTAPI_ALLOWLIST_INCLUDE_MEMBERS:(可选):如果设置为true它允许从在 DCS 中注册的其他集群成员访问不安全的 REST API 端点(IP 地址或主机名取自成员api_url)。请注意,操作系统可能会使用不同的 IP 进行传出连接。
- PATRONI_RESTAPI_HTTP_EXTRA_HEADERS:(可选)HTTP 标头让 REST API 服务器通过 HTTP 响应传递附加信息。
- PATRONI_RESTAPI_HTTPS_EXTRA_HEADERS:(可选)HTTPS 标头让 REST API 服务器在启用 TLS 时通过 HTTP 响应传递附加信息。这也将传递设置在http_extra_headers.
CTL
- PATRONICTL_CONFIG_FILE:配置文件的位置。
- PATRONI_CTL_INSECURE:允许连接到 REST API 而无需验证 SSL 证书。
- PATRONI_CTL_CACERT:指定带有 CA_BUNDLE 文件的文件或带有可信 CA 证书的目录,以在验证 REST API SSL 证书时使用。如果没有提供,pavictl 将使用为 REST API“cafile”参数提供的值。
- PATRONI_CTL_CERTFILE:指定具有 PEM 格式的客户端证书的文件。如果没有提供,pavictl 将使用为 REST API“certfile”参数提供的值。
- PATRONI_CTL_KEYFILE:指定具有 PEM 格式的客户端密钥的文件。如果没有提供,pavictl 将使用为 REST API “keyfile”参数提供的值。
这些是基本的环境变量配置,这里只记录Etcd的环境变量,其余的可以查看官方文档。
YAML 配置设置
动态配置设置
动态配置存储在DCS中(分布式配置存储)并应用到所有集群中的节点上。一些参数,例如像 loop_wait, ttl, postgresql.parameters.max_connections, postgresql.parameters.max_worker_processes 等等仅能通过动态配置被设置。一些其他参数像postgresql.listen, postgresql.data_dir 仅能在本地被设置,如在Patroni配置文件或者通过配置变量。在大多数情况下,本地配置将覆盖动态配置。 为了更改动态配置,您可以使用patronictl edit-config工具或Patroni REST API
- loop_wait:循环将休眠的秒数。默认值:10
- ttl:获取leader key的TTL(以秒为单位)。可以将其视为启动自动故障转移过程之前的时间长度。默认值:30
- retry_timeout:DCS和PostgreSQL操作重试超时(秒)。在低于此值时,不会因为DCS或网络问题不会导致Patroni降级。默认值: 10
- maximum_lag_on_failover:跟随者可以延迟的最大字节数,以便能够参加领导人选举。
- maximum_lag_on_syncnode:同步节点在被认为是不健康的候选者并被健康的异步节点交换之前可能滞后的最大字节数。如果有多个从库,Patroni将使用max replica lsn,否则它将使用leader的当前wal lsn。默认值为-1,当该值设置为0或更低时,用户不会采取操作来交换不健康的同步节点。请设置足够高的值,以便在高交易量期间,Patroni不会频繁地交换同步节点。
- max_timelines_history : DCS 中保存的最大时间线历史项目数。默认值:0。当设置为 0 时,它会在 DCS 中保留完整的历史记录。
- master_start_timeout:在触发故障转移之前允许主服务器从故障中恢复的时间(以秒为单位)。默认值为 300 秒。如果可能,设置为 0 时故障转移会在检测到崩溃后立即完成。使用异步复制时,故障转移可能会导致事务丢失。master 故障的最坏情况故障转移时间是:loop_wait + master_start_timeout + loop_wait,除非 master_start_timeout 为零,在这种情况下它只是 loop_wait。根据您的持久性/可用性权衡设置值。
- master_stop_timeout : Patroni 停止 Postgres 时允许等待的秒数,仅在启用 synchronous_mode 时有效。当设置为 > 0 并且启用了 synchronous_mode 时,如果停止操作的运行时间超过了 master_stop_timeout 设置的值,则 Patroni 会向 postmaster 发送 SIGKILL。根据您的持久性/可用性权衡设置值。如果该参数未设置或设置 <= 0,则 master_stop_timeout 不适用。
- synchronous_mode : 打开同步复制模式。在这种模式下,将选择一个副本作为同步副本,只有最新的领导者和同步副本才能参与领导人选举。同步模式确保成功提交的事务不会在故障转移时丢失,代价是在用户无法确保事务持久性的情况下失去写入可用性。有关详细信息,请参阅复制模式文档。
- synchronous_mode_strict:如果没有可用的同步副本,则防止禁用同步复制,从而阻止所有客户端写入主服务器。有关详细信息,请参阅复制模式文档。
- PostgreSQL:
–use_pg_rewind : 是否使用 pg_rewind。默认为false。
–use_slots : 是否使用复制槽。在 PostgreSQL 9.4+ 上默认为true。
–recovery_conf:配置follower写入recovery.conf 的附加配置设置。PostgreSQL 12 中不再有 recovery.conf,但您可以继续使用此部分,因为 Patroni 透明地处理它。
–parameters:Postgres 的配置设置列表。 - Standby_cluster:如果定义了这个部分,我们想要引导一个备用集群。
–host : 远程主机的地址
–port : 远程主机的端口
–primary_slot_name:远程主服务器上用于复制的插槽。此参数是可选的,默认值来自实例名称(请参阅函数slot_name_from_member_name)。
–create_replica_methods:可用于从远程主机引导备用leader的有序方法列表可能与PostgreSQL中定义的列表不同。
–restore_command:将WAL记录从远程主机还原到备用leader的命令,可以与PostgreSQL中定义的列表不同。
–archive_cleanup_command : standby leader的清理命令
–recovery_min_apply_delay : 等待多长时间将WAL记录应用到备用leader上 - slots:定义永久复制槽。这些插槽将在切换/故障切换期间保留。逻辑槽通过重启从主节点复制到备用节点,之后它们的位置每隔loop_wait秒(如有必要)前进。通过libpq连接并使用倒带或超级用户凭据复制逻辑插槽文件(请参阅postgresql.authentication部分)。副本上的逻辑槽位置总是有可能比以前的主位置稍晚,因此应用程序应该准备好在故障转移后第二次可以接收到一些消息。最简单的方法是跟踪confirmed_flush_lsn。启用永久逻辑复制槽需要postgresql.use_slots进行设置,并且还将自动启用hot_standby_feedback. 由于逻辑复制槽的故障转移在 PostgreSQL 9.6 及更早版本上是不安全的,并且 PostgreSQL 10 版缺少一些重要功能,因此该功能仅适用于 PostgreSQL 11及以上版本。
– my_slot_name:复制槽的名称。 如果永久插槽名称与当前主插槽的名称匹配,则不会创建该插槽。操作员有责任确保由Patroni 自动为成员创建的复制槽和永久复制槽之间的名称没有冲突
— type:插槽类型。可能是physical或logical。如果插槽是合乎逻辑的,则必须另外定义database和plugin。
— database:应在其中创建逻辑槽的数据库名称。
— plugin : 逻辑插槽的插件名称。 - ignore_slots:Patroni 应忽略匹配插槽的复制插槽属性集列表。此配置/功能/等。当某些复制槽在 Patroni 之外管理时非常有用。匹配属性的任何子集都会导致插槽被忽略。
– name:复制槽的名称。
– type:插槽类型。可以physical或logical。如果插槽是逻辑的,您可以另外定义database和/或plugin.
– database:数据库名称(匹配logical插槽时)。
– plugin : 逻辑解码插件(匹配logical插槽时)。
全局/通用
- name : 主机名。对于集群必须是唯一的。
- namespace:配置存储区内的路径,Patroni 将保存有关群集的信息。默认值:“/service”
- scope:集群名称
Log
- level:设置一般日志记录级别。默认值为INFO(请参阅Python 日志记录文档)
- traceback_level:设置回溯可见的级别。默认是 ERROR。如果只想在启用时查看回溯,请将其设置为DEBUG,同时log.level=DEBUG。
- format:设置日志格式字符串。默认值为%(asctime)s %(levelname)s: %(message)s(参见LogRecord 属性)
- dateformat : 设置日期时间格式字符串。(请参阅formatTime() 文档)
- max_queue_size:Patroni 使用两步日志记录。日志记录被写入内存队列,并且有一个单独的线程将它们从队列中拉出并写入 stderr 或文件。内部队列的最大大小默认限制为1000条记录,足以保留过去 1h20m 的日志。
- dir : 将应用程序日志写入的目录。该目录必须存在并且可由执行 Patroni 的用户写入。如果设置此值,默认情况下应用程序将保留 4 个 25MB 的日志。您可以使用file_num和file_size调整这些保留值(见下文)。
- file_num:要保留的应用程序日志的数量。
- file_size:触发日志滚动的patoni.log 文件的大小(以字节为单位)。
- loggers:此部分允许重新定义每个 python 模块的日志记录级别
- Patroni.postmaster: WARNING
- urllib3:DEBUG
Etcd
大多数参数是可选的,但您必须指定host、hosts、url、proxy或srv 之一
- host:etcd的端点,host:port。
- hosts : etcd 端点的列表,格式为 host1:port1,host2:port2,etc… 可以是逗号分隔的字符串或实际的 yaml 列表。
- use_proxies:如果此参数设置为true,Patroni 会将主机视为代理列表,并且不会执行etcd 集群的拓扑发现。
- url : etcd 的 url。
- proxy : etcd 的代理 url。如果您使用代理连接到 etcd,请使用此参数而不是url。
- srv:用于搜索 SRV 记录以进行集群自动发现的域。Patroni 将尝试查询指定域的这些 SRV 服务名称(按此顺序直到第一次成功):_etcd-client-ssl, _etcd-client, _etcd-ssl, _etcd, _etcd-server-ssl, _etcd-server。如果检索到_etcd-server-ssl或 的SRV 记录,_etcd-server则使用 ETCD 对等协议查询 ETCD 以获取可用成员。否则将使用 SRV 记录中的主机。
- srv_suffix:为查找期间查询的SRV名称配置后缀。使用此标志区分同一域下的多个etcd群集。仅与srv配合使用。例如,如果设置了srv_suffix:foo和srv:example.org,则会进行以下DNS srv查询:_etcd-client-ssl-foo._tcp.example.com(对于每个可能的etcd srv服务名称,依此类推)。
- protocol:(可选)http 或 https,如果未指定,则使用 http。如果指定了url或proxy -将从他们那里获取协议。
- username:(可选)用于 etcd 身份验证的用户名。
- password:(可选)用于 etcd 身份验证的密码。
- cacert:(可选)ca 证书。如果存在,它将启用验证。
- cert:(可选)带有客户端证书的文件。
- key:(可选)带有客户端密钥的文件。如果密钥是cert 的一部分,则可以为空。
PostgreSQL
- PostgreSQL:
-uthentication:
— superuser:
—username:超级用户的名称,在初始化(initdb)期间设置,稍后由 Patroni 用于连接到 postgres。
—password : 超级用户的密码,在初始化 (initdb) 时设置。
—sslmode:(可选)映射为sslmode连接参数,它允许客户端指定与服务器的 TLS 协商模式的类型。有关每种模式如何工作的更多信息,请访问PostgreSQL 文档。默认模式是prefer。
—sslkey:(可选)映射为sslkey连接参数,该参数指定与客户端证书一起使用的密钥的位置。
—sslpassword:(可选)映射为sslpassword连接参数, 它指定sslkey中指定的密钥密码。
—sslcert:(可选)映射为sslcert连接参数,该参数指定客户端证书的位置。
—sslrootcert:(可选)映射为sslrootcert连接参数,该参数指定包含客户端将用于验证服务器证书的一个或多个证书颁发机构 (CA) 证书的文件的位置。
—sslcrl:(可选)映射为sslcrl连接参数,该参数指定包含证书吊销列表的文件的位置。客户端将拒绝连接到此列表中存在证书的任何服务器。
—gssencmode:(可选)映射为gssencmode连接参数, 它决定是否以什么优先级与服务器协商安全的GSS TCP/IP连接。
—channel_binding:(可选)映射为channel_binding连接参数,它控制客户端对通道绑定的使用。
–replication:
—username:复制用户名;用户将在初始化期间创建。副本将使用此用户通过流式复制访问主服务器
—password:复制用户密码;用户将在初始化期间创建。
—sslmode:(可选)映射为sslmode连接参数,它允许客户端指定与服务器的 TLS 协商模式的类型。有关每种模式如何工作的更多信息,请访问PostgreSQL 文档。默认模式是prefer。
—sslkey:(可选)映射为sslkey连接参数,该参数指定与客户端证书一起使用的密钥的位置。
—sslpassword:(可选)映射为sslpassword连接参数,指定sslkey中指定的密钥密码。
—sslcert:(可选)映射为sslcert连接参数,该参数指定客户端证书的位置。
—sslrootcert:(可选)映射为sslrootcert连接参数,该参数指定包含客户端将用于验证服务器证书的一个或多个证书颁发机构 (CA) 证书的文件的位置。
—sslcrl:(可选)映射为sslcrl连接参数,该参数指定包含证书吊销列表的文件的位置。客户端将拒绝连接到此列表中存在证书的任何服务器。
—gssencmode:(可选)映射为gssencmode连接参数,它决定是否以什么优先级与服务器协商安全的GSS TCP/IP连接。
—channel_binding:(可选)映射为channel_binding连接参数,它控制客户端对通道绑定的使用。
–rewind
—username:使用pg_rewind的用户的用户名; 在postgres 11及以上版本初始化时创建用户,并授予所有必要的权限。
—password:使用pg_rewind的用户的用户密码; 初始化时创建用户
—sslmode:(可选)映射为sslmode连接参数,它允许客户端指定与服务器的 TLS 协商模式的类型。有关每种模式如何工作的更多信息,请访问PostgreSQL 文档。默认模式是prefer。
—sslkey:(可选)映射为sslkey连接参数,该参数指定与客户端证书一起使用的密钥的位置。
—sslpassword:(可选)映射为sslpassword连接参数,指定sslkey中指定密钥的密码
—sslcert:(可选)映射为sslcert连接参数,该参数指定客户端证书的位置。
—sslrootcert:(可选)映射为sslrootcert连接参数,该参数指定包含客户端将用于验证服务器证书的一个或多个证书颁发机构 (CA) 证书的文件的位置。
—sslcrl:(可选)映射为sslcrl连接参数,该参数指定包含证书吊销列表的文件的位置。客户端将拒绝连接到此列表中存在证书的任何服务器。
—gssencmode:(可选)映射为gssencmode连接参数,它决定是否以什么优先级与服务器协商安全的GSS TCP/IP连接
—channel_binding:(可选)映射为channel_binding连接参数,它控制客户端对通道绑定的使用。
-callbacks : 在某些操作上运行的回调脚本。Patroni 将传递操作、角色和集群名称。(请参阅 scripts/aws.py 作为如何编写它们的示例。)
–on_reload:在触发配置重新加载时运行此脚本。
–on_restart:当 postgres 重新启动时运行这个脚本(不改变角色)。
–on_role_change:当 postgres 被提升或降级时运行这个脚本。
–on_start:在 postgres 启动时运行此脚本。
–on_stop:当 postgres 停止时运行这个脚本。
-connect_address:IP 地址 + 端口,通过该端口可以从其他节点和应用程序访问 Postgres。 - create_replica_methods:将Patroni节点转换为新副本的创建方法的有序列表。“basebackup”是默认方法;假定其他方法引用脚本,每个脚本都配置为自己的配置项。有关更多说明,请参见自定义副本创建方法文档。
-data_dir : Postgres 数据目录的位置,可以是现有的,也可以是由 Patroni 初始化的。
-config_dir : Postgres 配置目录的位置,默认为数据目录。必须可由 Patroni 写入。
-bin_dir:PostgreSQL 二进制文件的路径(pg_ctl、pg_rewind、pg_basebackup、postgres)。默认值是一个空字符串,这意味着 PATH 环境变量将用于查找可执行文件。
-listen:Postgres 监听的IP地址+ 端口号; 如果您正在使用流复制,则必须可以从群集中的其他节点进行访问。只要将端口号附加在最后一个冒号后面,即可使用多个逗号分隔的地址,即监听:127.0.0.1,127.0.0.2:5432。Patroni将使用此列表中的第一个地址建立与PostgreSQL节点的本地连接。
-use_unix_socket:指定Patroni使用unix套接字连接到集群。默认为false。如果unix_socket_directories 被定义,如果Patroni将使用其中的第一个合适的值连接到集群,没有合适的选项,回退到tcp。如果 unix_socket_directories没有定义在 postgresql.parameters中, Patroni将假定应使用默认值,并从连接参数中省略host。
-use_unix_socket_repl:指定 Patroni 应首选使用unix套接字进行复制用户集群连接。默认值为false。如果unix_socket_directories已定义,Patroni 将使用其中的第一个合适的值连接到集群,如果没有合适的值,则回退到 tcp。如果postgresql.parameters中没有指定unix_socket_directories,那么Patroni将假定应该使用默认值,并从连接参数中省略host。
-pgpass : .pgpass密码文件的路径。Patroni 在执行 pg_basebackup、post_init 脚本之前以及在其他一些情况下创建这个文件。该位置必须可由 Patroni 写入。
-recovery_conf:配置follower时写入recovery.conf 的附加配置设置。
-custom_conf:可选定制的postgresql.conf 文件路径, 将用于代替postgresql.base.conf。该文件必须存在于所有群集节点上,并且可由PostgreSQL读取,并将包含在实际的postgresql.conf中。请注意,Patroni不会监视此文件的更改,也不会备份它。但是Patroni自己的配置工具仍然可以覆盖其设置-有关详细信息,请参见动态配置。
-parameters:Postgres 的配置设置列表。其中许多是复制工作所必需的。
-pg_hba:Patroni 将用于生成pg_hba.conf. 此参数的优先级高于bootstrap.pg_hba。与动态配置一起,它简化了pg_hba.conf.
— host all all 0.0.0.0/0 md5.
— host replication replicator 127.0.0.1/32 md5: 复制需要这样一行代码。
-pg_ident:Patroni 将用于生成pg_ident.conf. 与动态配置一起,它简化了pg_ident.conf.
— mapname1 systemname1 pguser1。
— mapname1 systemname2 pguser2。
-pg_ctl_timeout : pg_ctl在启动,停止或重新启动时应等待多长时间。 默认值为60秒。
-use_pg_rewind:尝试在先前领导者作为副本加入群集时在先前领导者上使用pg_rewind。
-remove_data_directory_on_rewind_failure:如果这个选项打开,Patroni将移除PostgreSQL数据目录并重新创建副本。否则将尽量跟随一个新领导者,默认为false。
-remove_data_directory_on_diverged_timelines:如果Patroni注意到时间线不同并且以前的主服务器无法从新的主服务器开始流式传输,则Patroni将删除PostgreSQL数据目录并重新创建副本。当无法使用pg_rewind时,此选项很有用。默认值是false。
-replica_method:对于除 basebackup 之外的每个 create_replica_methods,您将添加一个同名的配置部分。至少,这应该包括“命令”以及要执行的实际脚本的完整路径。其他配置参数将以“parameter=value”的形式传递给脚本。
-pre_promote:在获得领导锁之后,但在副本提升之前,在故障转移期间执行的围栏脚本。如果脚本以非零代码退出,那么Patroni不会升级复制副本并从DCS中删除领导密钥
REST API
- restapi
-connect_address:IP 地址(或主机名)和端口,用于访问 Patroni 的REST API. 集群的所有成员都必须能够连接到这个地址,所以除非 Patroni 设置是用于本地主机内部的演示,否则这个地址必须是非“localhost”或环回地址(即:“localhost”或“127.0 .0.1”)。它可以作为 HTTP 健康检查的端点(阅读下面关于“listen”REST API 参数的内容),也可以作为用户查询(直接或通过 REST API),以及领导人选举中集群成员进行的健康检查(例如,确定主节点是否仍在运行,或者是否有一个节点的 WAL 位置在执行查询的节点之前;等等)将connect_address放入DCS的成员键中,从而可以将成员名称转换为地址以连接到其REST API。
-listen:Patroni 将为 REST API监听的IP 地址(或主机名)和端口 – 如上所述,还在参与节点之间提供相同的健康检查和集群消息传递。为 HAProxy(或任何其他能够执行 HTTP“OPTION”或“GET”检查的负载均衡器)提供健康检查信息。
-authentication: (可选)
–username : 基本验证的用户名,用于保护不安全的 REST API 端点。
–password : 基本验证的密码,用于保护不安全的 REST API 端点。
-certfile:(可选):指定带有 PEM 格式证书的文件。如果未指定 certfile 或将其留空,则 API 服务器将在没有 SSL 的情况下工作。
-keyfile:(可选):指定具有 PEM 格式的密钥的文件。
-keyfile_password:(可选):指定用于解密密钥文件的密码。
-cafile:(可选):指定带有 CA_BUNDLE 的文件,其中包含在验证客户端证书时要使用的受信任 CA 的证书。
-ciphers:(可选):指定允许的密码套件(例如“ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES128-GCM-SHA256:!SSLv1:!SSLv2:!SSLv3:!TLSv1:!TLSv1.1”)
-verify_client : (可选): none(默认),optional或required. 当noneREST API 不会检查客户端证书时。当required所有 REST API 调用都需要客户端证书时。当optional所有不安全的 REST API 端点都需要客户端证书时。当required使用时,如果证书签名验证成功,则客户端验证成功。对于optional客户端证书将只检查PUT,POST,PATCH,和DELETE请求。
-allowlist:(可选):指定允许调用不安全REST API端点的主机集。单个元素可以是主机名、IP地址或使用CIDR表示法的网络地址。默认情况下,将使用allow all。如果设置了allowlist或allowlist_include_members,则拒绝未包含的任何内容。
-allowlist_include_members:(可选):如果设置为true它允许从在 DCS 中注册的其他集群成员访问不安全的 REST API 端点(IP 地址或主机名取自成员api_url)。请注意,操作系统可能会使用不同的 IP 进行传出连接。
-http_extra_headers:(可选):HTTP 标头让 REST API 服务器通过 HTTP 响应传递附加信息。
-https_extra_headers:(可选):启用TLS后,HTTPS headers可以让REST API服务器通过HTTP响应传递其他信息。这还将传递http_extra_headers中设置的其他信息
这是常用的配置其余的可以查看文档
YML官方的模版示例
scope: batman
#namespace: /service/
name: postgresql0
restapi:
listen: 127.0.0.1:8008
connect_address: 127.0.0.1:8008
# certfile: /etc/ssl/certs/ssl-cert-snakeoil.pem
# keyfile: /etc/ssl/private/ssl-cert-snakeoil.key
# authentication:
# username: username
# password: password
# ctl:
# insecure: false # Allow connections to SSL sites without certs
# certfile: /etc/ssl/certs/ssl-cert-snakeoil.pem
# cacert: /etc/ssl/certs/ssl-cacert-snakeoil.pem
etcd:
#Provide host to do the initial discovery of the cluster topology:
host: 127.0.0.1:2379
#Or use "hosts" to provide multiple endpoints
#Could be a comma separated string:
#hosts: host1:port1,host2:port2
#or an actual yaml list:
#hosts:
#- host1:port1
#- host2:port2
#Once discovery is complete Patroni will use the list of advertised clientURLs
#It is possible to change this behavior through by setting:
#use_proxies: true
#raft:
# data_dir: .
# self_addr: 127.0.0.1:2222
# partner_addrs:
# - 127.0.0.1:2223
# - 127.0.0.1:2224
bootstrap:
# this section will be written into Etcd:/<namespace>/<scope>/config after initializing new cluster
# and all other cluster members will use it as a `global configuration`
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
# master_start_timeout: 300
# synchronous_mode: false
#standby_cluster:
#host: 127.0.0.1
#port: 1111
#primary_slot_name: patroni
postgresql:
use_pg_rewind: true
# use_slots: true
parameters:
# wal_level: hot_standby
# hot_standby: "on"
max_connections: 2000
max_worker_processes: 16
# wal_keep_segments: 8
# max_wal_senders: 10
# max_replication_slots: 10
# max_prepared_transactions: 0
max_locks_per_transaction: 512
# wal_log_hints: "on"
# track_commit_timestamp: "off"
# archive_mode: "on"
# archive_timeout: 1800s
# archive_command: mkdir -p ../wal_archive && test ! -f ../wal_archive/%f && cp %p ../wal_archive/%f
# recovery_conf:
# restore_command: cp ../wal_archive/%f %p
# some desired options for 'initdb'
initdb: # Note: It needs to be a list (some options need values, others are switches)
- encoding: UTF8
- data-checksums
pg_hba: # Add following lines to pg_hba.conf after running 'initdb'
# For kerberos gss based connectivity (discard @.*$)
#- host replication replicator 127.0.0.1/32 gss include_realm=0
#- host all all 0.0.0.0/0 gss include_realm=0
- host replication replicator 127.0.0.1/32 md5
- host all all 0.0.0.0/0 md5
# - hostssl all all 0.0.0.0/0 md5
# Additional script to be launched after initial cluster creation (will be passed the connection URL as parameter)
# post_init: /usr/local/bin/setup_cluster.sh
# Some additional users users which needs to be created after initializing new cluster
users:
admin:
password: admin%
options:
- createrole
- createdb
postgresql:
listen: 127.0.0.1:5432
connect_address: 127.0.0.1:5432
data_dir: data/postgresql0
# bin_dir:
# config_dir:
pgpass: /tmp/pgpass0
authentication:
replication:
username: replicator
password: rep-pass
superuser:
username: postgres
password: zalando
rewind: # Has no effect on postgres 10 and lower
username: rewind_user
password: rewind_password
# Server side kerberos spn
# krbsrvname: postgres
parameters:
# Fully qualified kerberos ticket file for the running user
# same as KRB5CCNAME used by the GSS
# krb_server_keyfile: /var/spool/keytabs/postgres
unix_socket_directories: '..' # parent directory of data_dir
# Additional fencing script executed after acquiring the leader lock but before promoting the replica
#pre_promote: /path/to/pre_promote.sh
#watchdog:
# mode: automatic # Allowed values: off, automatic, required
# device: /dev/watchdog
# safety_margin: 5
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
前面的Patroni连接Etcd都是通过环境变量来这是Etcd的host地址的,当前也可以用配置文件来设置。
所以到目前的数据连接就是,Patroni连接Etcd,HAproxy通过Etcd里的信息来配置Patroni地址,通过HAproxy来进行反向代理连接数据库。
到这里一套PG高可用集群就已经搭建完成了。
扩展—Keepalived
尽管HAProxy非常稳定,但仍然无法规避操作系统故障、主机硬件故障、网络故障甚至断电带来的风险。所以必须对HAProxy实施高可用方案。
Keekpalived工作原理:通过vrrp协议(虚拟路由冗余协议)实现。
在两台HAProxy的主机上分别运行着一个Keepalived实例,这两个Keepalived争抢同一个虚IP地址,两个HAProxy也尝试去绑定这同一个虚IP地址上的端口。显然,同时只能有一个Keepalived抢到这个虚IP,抢到了这个虚IP的Keepalived主机上的HAProxy便是当前的MASTER。Keepalived内部维护一个权重值,权重值最高的Keepalived实例能够抢到虚IP。同时Keepalived会定期check本主机上的HAProxy状态,状态OK时权重值增加。
主要从一个整体方案的角度来描述什么要这样做,以及这样做所解决的问题。
所有的系统,都是先经历一个单台机器搞所有业务的时代,一个程序+一个mysql数据库,就可以满足开发及第一个版本上线的要求。随着,数据的增加以及业务的增长,这些应用就面临一个访问量的扩大以及扩展的问题。最简单的扩展就是水平扩展,原来由一个mysql增加为2个或多个,形成一个集群,这样最简单的能力就是提供更强的服务能力。如原来的访问量支持每秒1000,现在可以支持2000(理想值),相当于将服务能力分散到多个节点。这里面涉及到多个问题,首先就是数据的相互备份,然后就是如何分配计算能力,外部如何来访问等。引入HaProxy和KeepAlived主要处理的就是一个外部访问问题。
在后面的介绍当中,假定有2个mysql,分别为mysqlA和mysqlB.
haproxy请求分发
可以理解为通过nginx来作后端的负载均衡,HaProxy可以通过监听一个统一的端口对外提供能力,然后内部进行分发。除支持http7层处理外,还顺便为mysql支持4层转发。(更高级的可以考虑采用lvs) 在这里,将两个mysql分别配置在backend当中,并且通过option mysql-check进行相应服务的检查。
程序进行访问时,就不再访问具体的mysql机器,而是访问这个HaProxy所在的机器。这里就提到需要一个额外的机器来提供服务,但是由于只为HaProxy使用,其根据很低,一个最低配机器即可,费用不大。同时,相应的端口也填写HaProxy所暴露的端口即可。对外即认为也只仍然只有一个mysql,即对外是透明的。
HaProxy在进行处理时,将自己根据相应的策略进行转发,最简单的策略就是轮询(ribbon),当然其它加权或者是随机等,需要具体进行配置。同时,根据设定的具体时间间隔,对后端服务进行有效性检测,当mysqlA或B不能工作时,将自动从可用列表中移除。
在加上HaProxy之后,负载的问题被解决,但另一个问题又来了,即服务单点的问题。如果一旦这个HaProxy机器挂掉(或网络原因)。虽然,mysql服务器没挂,但整个服务也是不可用了。前端程序不会自动退回到去访问原始的mysql(甚至由于防火墙的问题,它也不能访问)。这时候就要用到另一个东西,保证HaProxy不会成为单点,即KeepAlived。
KeepAlived高可用
保证服务不会单点的作法就是加机器,但加机器就会出现多个ip,如何保证前端程序使用单个ip又能保证后端的实际处理机器为多台,这就是KeepAlived的作用。
我们为了保证HaProxy的高可用,已经又加了一个机器,即为HaProxyA和HaProxyB(相当于原来的2个mysql机器,又加了2台HaProxy机器)。
通过KeepAlived,我们可以创造出第3个IP,由ip3来对外提供服务,但是与HaProxy的转发性质不同,这里的ip3实际上就是HaProxyA和HaProxyB的一个同名映射。可以理解为HaProxyA和HaProxyB都在争抢这个ip,哪个争抢到了,就由哪个来提供服务。
因为KeepAlived不提供任何处理能力,实际上最终的处理能落在能够处理信息的程序上。因此,我们需要将KeepAlived和HaProxy部署在一起,即KeepAlived负责抢ip,接收前端的请求,在接收到了请求之后,由系统自动将请求分发到同一个机器上的HaProxy上进行处理。即一个机器有2个IP,ip1负责接收请求,ip2负责实际的信息处理(比喻而已,就是如何监听请求和端口处理程序)
在前面的处理模型当中,因为KeepAlived不处理请求,因此如果它所在机器上的HaProxy如果不可用,实际上这个模型也是有问题的。因此KeepAlived又要来监听自己机器上的HaProxy是否有效。在配置中,通过track_script指令可以达到这个效果,与HaProxy的工作模式差不多,它可以定时执行监控脚本来查看HaProxy是否可用。如果不可用,有2种处理办法,一种就是强行再启动HaProxy,另一种就是取消自己的抢占ip位(如将自己给kill掉),将相应的ip3的位置给让出来。这样IP2就能自动与IP3进行绑定(比喻),即由IP2来提供处理能力了。
在KeepAlived的配置之上,在单个时刻只有1台机器在进行工作,另一个机器在进行准备,可以理解为这里的服务能力只有1半。好在KeepAlived和HaProxy所占用资源都较小,费用不高。
// ubuntu安装keepalived
apt-get install keepalived配置Keepalived例子
global_defs {
router_id LVS_DEVEL #虚拟路由名称
}
#HAProxy健康检查配置
vrrp_script chk_haproxy {
script "killall -0 haproxy" #使用killall -0检查haproxy实例是否存在,性能高于ps命令
interval 2 #脚本运行周期
weight 2 #每次检查的加权权重值
}
#虚拟路由配置
vrrp_instance VI_1 {
state MASTER #本机实例状态,MASTER/BACKUP,备机配置文件中请写BACKUP
interface enp0s25 #本机网卡名称,使用ifconfig命令查看
virtual_router_id 51 #虚拟路由编号,主备机保持一致
priority 101 #本机初始权重,备机请填写小于主机的值(例如100)
advert_int 1 #争抢虚地址的周期,秒
virtual_ipaddress {
192.168.8.201 #虚地址IP,主备机保持一致
}
track_script {
chk_haproxy #对应的健康检查配置
}
}脚本检测并非一定要使用killall这个命令,可以自定义一个shell脚本去检测,这样可以更加灵活地处理。
比如在检测到haproxy这个进程不存在时,执行启动haproxy的命令,如果启动失败再切换VIP,而不是检测失败就直接切换VIP。
创建脚本vi /etc/keepalived/chk_haproxy.sh
#!/bin/bash
A=`ps -C haproxy --no-header |wc -l`
if [ $A -eq 0 ];then
su - haproxy -c "/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg"
sleep 10
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
/etc/init.d/keepalived stop
fi
fi更改健康检查配置
# HAProxy健康检查配置
vrrp_script chk_haproxy {
script "/etc/keepalived/chk_haproxy.sh" # 执行自定义脚本
interval 2 # 脚本运行周期,秒
}如果主机没有killall命令,则需要安装psmisc包:
apt-get install psmisc分别启动两个Keepalived
service keepalived startPatroni集群问题
在实际的生产过程中需要了一个PostgreSQL节点需要的日志损坏的情况,采用了很多的办法来修复,当然最快捷的就是删除该节点,然后添加一个新的节点,但是会比较繁琐,逃避问题,同时也尝试过了pg_resetwal命令来重制WAL日志,也失败了,最后采取的方式是patronictl工具来重制Patroni节点
patronictl reinit [集群名称] [节点名称]其实就是删除PATRONI_RAFT_DATA_DIR的目录
它是存放Raft 日志和快照的目录。 如果未指定,则使用当前工作目录。
Patroni维护模式
Patroni没有start和stop,但它有维护模式啊
Patroni 为什么没有停止的功能
说实话,这个问题我也是比较纳闷的。很多高可用程序都拥有startup/stop的选项,但是Patroni没有这些选项。
因为开发软件的人认为Patroni 的主要目的和任务是运行高可用集群,停止和启动它是非常奇怪的事。而且从技术上来说,因为它通过在Patroni节点上运行的REST API进行通信,所以无法停止。
还有一个点Patroni他要和Etcd和watchdog进行通信,所以停止它确实不推荐。
Patroni的维护模式
在某一些情况下,我们需要退出集群管理,但是我们仍然想要保留Patroni与DCS的状态和通信,所以我们需要把Patroni与正在运行的集群进行“分离”,从而实现像Pacemaker一样的维护模式。
而Patroni使用paused选项就可以进入维护模式
patronictl paused此时我们就可以对Patroni进行升级等一系列维护操作,不会影响集群的使用,但是如果接下来出现问题,就需要你手工进行故障转移了。(手工转移这个在文档上有)
