阅读完需:约 70 分钟
ZooKeeper 概览
ZooKeeper 是一个开源的分布式协调服务,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
原语: 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 数据存储+事件监听 功能
设计一个分布式系统必定会遇到一个问题—— 因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡 。这就是著名的 CAP 定理。
比如Eureka 的处理方式,它保证了 AP(可用性),而ZooKeeper 的处理方式,它保证了 CP(数据一致性)。
ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器变同步状态。(“读”多于“写”是协调服务的典型场景)。
官方文档(最新是3.9.2)
https://zookeeper.net.cn/doc/current/index.html
ZooKeeper 特点
- 集群部署:一般是3~5台机器组成一个集群,每台机器都在内存保存了zk的全部数据,机器之间互相通信同步数据,客户端连接任何一台机器都可以。
- 顺序一致性:所有的写请求都是有序的;集群中只有leader机器可以写,所有机器都可以读,所有写请求都会分配一个zk集群全局的唯一递增编号:zxid,用来保证各种客户端发起的写请求都是有顺序的。
- 原子性:要么全部机器成功,要么全部机器都不成功。
- 数据一致性:无论客户端连接到哪台节点,读取到的数据都是一致的;leader收到了写请求之后都会同步给其他机器,保证数据的强一致,你连接到任何一台zk机器看到的数据都是一致的。
- 高可用:如果某台机器宕机,会保证数据不丢失。集群中挂掉不超过一半的机器,都能保证集群可用。比如3台机器可以挂1台,5台机器可以挂2台。
- 实时性:一旦数据发生变更,其他节点会实时感知到。
- 高性能:每台zk机器都在内存维护数据,所以zk集群绝对是高并发高性能的,如果将zk部署在高配置物理机上,一个3台机器的zk集群抗下每秒几万请求是没有问题的。
- 高并发:高性能决定的,主要是基于纯内存数据结构来处理,并发能力是很高的,只有一台机器进行写,但是高配置的物理机,比如16核32G,可以支撑几万的写入QPS。所有机器都可以读,选用3台高配机器的话,可以支撑十万+的QPS。
ZooKeeper 应用场景
ZooKeeper 概览中,我们介绍到使用其通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
下面选 3 个典型的应用场景来专门说说:
- 命名服务:可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
- 数据发布/订阅:通过 Watcher 机制 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
- 分布式锁:通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 Watcher 机制。
实际上,这些功能的实现基本都得益于 ZooKeeper 可以保存数据的功能,但是 ZooKeeper 不适合保存大量数据,这一点需要注意。
开源服务的应用场景
元数据管理:Kafka、Canal,本身都是分布式架构,分布式集群在运行,本身他需要一个地方集中式的存储和管理分布式集群的核心元数据,所以他们都选择把核心元数据放在zookeeper中。
- Dubbo:使用zookeeper作为注册中心、分布式集群的集中式元数据存储
- HBase:使用zookeeper做分布式集群的集中式元数据存储
分布式协调:如果有节点对zookeeper中的数据做了变更,然后zookeeper会反过来去通知其他监听这个数据的节点,告诉它这个数据变更了。
- kafka:通过zookeeper解决controller的竞争问题。kafka有多个broker,多个broker会竞争成为一个controller的角色。如果作为controller的broker挂掉了,此时他在zk里注册的一个节点会消失,其他broker瞬间会被zookeeper反向通知这个事情,继续竞争成为新的controller,这个就是非常经典的一个分布式协调的场景。(在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构)
Master选举 -> HA架构
- Canal:通过zookeeper解决Master选举问题,来实现HA架构
- HDFS:Master选举实现HA架构,NameNode HA架构,部署主备两个NameNode,只有一个人可以通过zookeeper选举成为Master,另外一个作为backup。
ZooKeeper 部署
这里采用的是 docker-compose.yml 部署
https://registry.hub.docker.com/_/zookeeper
version: '3.1'
services:
zoo1:
image: zookeeper:3.9.2
# docker重启后自动重启容器
restart: always
hostname: zoo1
# 端口 宿主机:容器
ports:
- 2181:2181
environment:
# myid,一个集群内唯一标识一个节点
ZOO_MY_ID: 1
# 集群内节点列表
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
zoo2:
image: zookeeper:3.9.2
restart: always
hostname: zoo2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
zoo3:
image: zookeeper:3.9.2
restart: always
hostname: zoo3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181此映像包括EXPOSE 2181 2888 3888(分别为 zookeeper 客户端端口、跟随者端口、选举端口)
ZOO_MY_ID(环境变量):
- 该id在集群中必须是唯一的,并且其值应介于1和255之间;
- 请注意,如果使用已包含 myid 文件的 /data 目录启动容器,则此变量将不会产生任何影响。相当于你在zoo.cfg中指定的dataDir目录中创建文件myid,并且文件的内容就是范围为1到255的整数;
ZOO_SERVERS(环境变量):
- 此变量允许您指定Zookeeper集群的计算机列表;
- 每个条目都应该这样指定:
server.id=<address1>:<port1>:<port2>[:role];[<client port address>:]<client port>-
id是一个数字,表示集群中的服务器ID; -
address1表示这个服务器的ip地址; - 集群通信端⼝:
port1表示这个服务器与集群中的 Leader 服务器交换信息的端口; - 集群选举端⼝:
port2表示万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口; -
role: 默认是 participant,即参与过半机制的⻆⾊,选举,事务请求过半提交,还有⼀个是observer, 观察者,不参与选举以及过半机制。 -
client port address是可选的,如果未指定,则默认为 “0.0.0.0” ; -
client port位于分号的右侧。从3.5.0开始,zoo.cfg中不再使用clientPort和clientPortAddress配置参数。作为替代,client port用来表示客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个
端口,接受客户端的访问请求。
-
- 请注意,如果使用已包含zoo.cfg文件的/conf目录启动容器,则此变量不会产生任何影响。换句话说,zoo.cfg文件中包含集群的计算机列表,此时该环境变量不生效。
检查ZK的集群状态
zkServer.sh 是 Apache ZooKeeper 分布式协调服务的一部分,它是一个 shell 脚本,用于启动和停止 ZooKeeper 服务器进程。此脚本通常位于 ZooKeeper 安装目录的 bin 子目录中。
zkServer.sh 的作用
-
启动 ZooKeeper 服务:使用
./zkServer.sh start命令可以启动 ZooKeeper 服务。 -
停止 ZooKeeper 服务:使用
./zkServer.sh stop命令可以停止正在运行的 ZooKeeper 服务。 -
检查状态:使用
./zkServer.sh status命令可以检查 ZooKeeper 服务的状态。
root@zoo3:/apache-zookeeper-3.9.2-bin/bin# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkSnapshotComparer.sh zkSnapshotRecursiveSummaryToolkit.sh zkSnapShotToolkit.sh zkTxnLogToolkit.sh
zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkSnapshotComparer.cmd zkSnapshotRecursiveSummaryToolkit.cmd zkSnapShotToolkit.cmd zkTxnLogToolkit.cmd
root@zoo3:/apache-zookeeper-3.9.2-bin/bin# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
root@zoo3:/apache-zookeeper-3.9.2-bin/bin# 这里可以看出集群的状态是 Leader
Zookeeper 集群模式⼀共有三种类型的⻆⾊:
| 角色 | 职责 |
|---|---|
| Leader | 处理所有的事务请求(写请求),可以处理读请求,集群中只能有⼀个Leader |
| Follower | 只能处理读请求,同时作为 Leader的候选节点,即如果Leader宕机,Follower节点要参与到新的Leader选举中,有可能成为新的Leader节点。 |
| Observer | 只能处理读请求。不能参与选举 |
Zookeeper 常用命令
[zk: 127.0.0.1:2181(CONNECTED) 8] help
ZooKeeper -server host:port -client-configuration properties-file cmd args
addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE
addauth scheme auth
close
config [-c] [-w] [-s]
connect host:port
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
delete [-v version] path
deleteall path [-b batch size]
delquota [-n|-b|-N|-B] path
get [-s] [-w] path
getAcl [-s] path
getAllChildrenNumber path
getEphemerals path
history
listquota path
ls [-s] [-w] [-R] path
printwatches on|off
quit
reconfig [-s] [-v version] [[-file path] | [-members serverID=host:port1:port2;port3[,...]*]] | [-add serverId=host:port1:port2;port3[,...]]* [-remove serverId[,...]*]
redo cmdno
removewatches path [-c|-d|-a] [-l]
set [-s] [-v version] path data
setAcl [-s] [-v version] [-R] path acl
setquota -n|-b|-N|-B val path
stat [-w] path
sync path
version
whoami - 启动ZK服务 :
bin/zkServer.sh start - 查看ZK服务状态 :
bin/zkServer.sh status - 停止ZK服务 :
bin/zkServer.sh stop - 重启ZK服务 :
bin/zkServer.sh restart - 连接服务器 :
zkCli.sh -server 127.0.0.1:2181 - 创建zookeeper 节点命令 :
create /test‐node some‐datacreate [‐s] [‐e] [‐c] [‐t ttl] path [data] [acl]
- -s: 顺序节点
- -e: 临时节点
- -c: 容器节点
- -t: 可以给节点添加过期时间,默认禁用,需要通过系统参数启用
- 查看节点 :
get /test‐nodeget [-s] [-w] path-
-w事件监听
- 修改数据节点 :
set /test‐node some‐data‐changedset [-s] [-v version] path data-
set -v 1 /test-v 123444: -v 可以根据状态数据中的版本号有并发修改数据实现乐观锁的功能 (dataVersion参数)
- 查看节点信息状态 :
stat /test‐node-
-w事件监听
-
- 查看节点 :
ls /ls [-s] [-w] [-R] path-
-w事件监听 -
-R递归查询子目录
- 删除节点 :
delete /test-vdelete [-v version] path- 若删除节点存在子节点,那么无法删除该节点,必须先删除子节点,再删除父节点。
针对节点的监听:一定事件触发,对应的注册立刻被移除,所以事件监听是一次性的
注册监听的同时获取数据 : get -w /test‐w
[zk: 127.0.0.1:2181(CONNECTED) 21] create /test-w
Created /test-w
[zk: 127.0.0.1:2181(CONNECTED) 22] get -w /test-w
null
[zk: 127.0.0.1:2181(CONNECTED) 23] set /test-w 123456
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/test-w zxid: 12884901916
[zk: 127.0.0.1:2181(CONNECTED) 24] 针对目录的监听,目录的变化,会触发事件,且一旦触发,对应的监听也会被移除,后续对节点的创建没有触发监听事件
单目录监听 : ls -w /test-ml
递归子目录的监听 : ls -R -w /test-ml
所有的监听都是一次性的
[zk: 127.0.0.1:2181(CONNECTED) 23] create /test-ml
Created /test-ml
[zk: 127.0.0.1:2181(CONNECTED) 24] create /test-ml/jkl
Created /test-ml/jkl
[zk: 127.0.0.1:2181(CONNECTED) 26] ls -R /test-ml
/test-ml
/test-ml/jkl
[zk: 127.0.0.1:2181(CONNECTED) 27] ls -w /test-ml
[jkl]
[zk: 127.0.0.1:2181(CONNECTED) 28] create /test-ml/jknm
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/test-ml zxid: 12884901931
Created /test-ml/jknm
[zk: 127.0.0.1:2181(CONNECTED) 29] create /test-ml/oopp
Created /test-ml/oopp
[zk: 127.0.0.1:2181(CONNECTED) 30] ls -R -w /test-ml
/test-ml
/test-ml/jkl
/test-ml/jknm
/test-ml/oopp
[zk: 127.0.0.1:2181(CONNECTED) 31] create /test-ml/oopp/bbkk
WATCHER::
Created /test-ml/oopp/bbkk
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/test-ml/oopp zxid: 12884901933
[zk: 127.0.0.1:2181(CONNECTED) 32] create /test-ml/oopp/lllp
Created /test-ml/oopp/lllpZookeeper 事件类型
-
None: 连接建立事件 -
NodeCreated: 节点创建 -
NodeDeleted: 节点删除 -
NodeDataChanged:节点数据变化 -
NodeChildrenChanged:子节点列表变化 -
DataWatchRemoved:节点监听被移除 -
ChildWatchRemoved:子节点监听被移除
ACL 权限控制
Zookeeper 的 ACL 权限控制,可以控制节点的读写操作,保证数据的安全性,Zookeeper ACL 权限设置分为 3 部分组成,分别是:权限模式(Scheme)、授权对象(ID)、权限信息(Permission)。
最终组成⼀条例如scheme:id:permission 格式的 ACL 请求信息。
ZooKeeper 可以给每个节点设置不同的权限控制。
权限 Permission
权限就是指我们可以在数据节点上执⾏的操作种类(CRUD),如下所示:在 ZooKeeper 中已经定义好的权限有 5 种:
- 数据节点(c: create)创建权限,授予权限的对象可以在数据节点下创建⼦节点;
- 数据节点(w: wirte)更新权限,授予权限的对象可以更新该数据节点;
- 数据节点(r: read)读取权限,授予权限的对象可以读取该节点的内容以及⼦节点的列表信息;
- 数据节点(d: delete)删除权限,授予权限的对象可以删除该数据节点的⼦节点;
- 数据节点(a: admin)管理者权限,授予权限的对象可以对该数据节点体进⾏ ACL 权限设置。
1 和 4 其实就对应zk命令 create 和 delete;
2 和 3 主要对应zk命令 set 和 get;
5 主要对应zk命令 setAcl 和 getAcl;
权限模式 Scheme
到底有哪些授权的模式?而授权对象(ID)其实是和权限模式(Scheme)对应使用的
- 所有人可用模式(world:anyone:perm): world模式只有一个授权对象id,anyone,表示任何一个人都有权限。
- 仅当前认证用户可用模式(auth:user:password:perm): auth模式的授权对象是当前认证用户。
- 提供此方案是为了方便用户创建znode,然后将对该znode的访问限制为仅该用户,这是一个常见的用例;
- 如果没有通过身份验证的用户,则使用身份验证方案设置ACL将失败;
- 口令认证模式(digest:user:password:perm): digest模式使用 username:password 字符串生成MD5散列,然后将其用作授权对象ID。
- 这里的 password 不是明文,而是 base64编码(SHA1摘要算法(明文密码))的结果。因此和 addauth 的使用习惯不相同;
- 这里面还有一种特殊情况,就是认证 超级管理员 的口令后,ZooKeeper客户端可以对 ZooKeeper 上的任意数据节点进⾏任意操作;
- IP认证模式:ip(ip:addr:perm 或者 ip:addr/bits:perm)模式使用客户端主机ip作为授权对象ID。
- 可以针对⼀个 IP 或者⼀段 IP 地址授予某种权限。
- ⽐如我们可以让⼀个 IP 地址为“ip:192.168.0.110”的机器对服务器上的某个数据节点具有写⼊的权限。
- 或者也可以通过“ip:192.168.0.1/24”给⼀段 IP 地址的机器赋权。
- SSL安全认证模式:x509模式,使用安全端口时,客户端将自动进行身份验证,并设置x509方案的身份验证信息。
操作命令
- getAcl:获取某个节点的acl权限信息
- setAcl:设置某个节点的acl权限信息
- addauth: 输入认证授权信息,相当于注册用户信息,注册时输入明文密码,zk将以密文的形式存储
- 可以通过系统参数
zookeeper.skipACL=yes进行配置,默认是no,可以配置为true, 则配置过的 ACL将不再进行权限检测
word方式
world 是一种默认的模式,即创建时如果不指定权限,则默认的权限就是 world。
[zk: localhost:2181(CONNECTED) 32] create /hadoop 123
Created /hadoop
[zk: localhost:2181(CONNECTED) 33] getAcl /hadoop
'world,'anyone #默认的权限
: cdrwa
[zk: localhost:2181(CONNECTED) 34] setAcl /hadoop world:anyone:cwda # 修改节点,不允许所有客户端读
....
[zk: localhost:2181(CONNECTED) 35] get /hadoop
Authentication is not valid : /hadoop # 权限不足auth模式
[zk: localhost:2181(CONNECTED) 36] addauth digest heibai:heibai # 登录
[zk: localhost:2181(CONNECTED) 37] setAcl /hadoop auth::cdrwa # 设置权限
[zk: localhost:2181(CONNECTED) 38] getAcl /hadoop # 获取权限
'digest,'heibai:sCxtVJ1gPG8UW/jzFHR0A1ZKY5s= #用户名和密码 (密码经过加密处理),注意返回的权限类型是 digest
: cdrwa
#用户名和密码都是使用登录的用户名和密码,即使你在创建权限时候进行指定也是无效的
[zk: localhost:2181(CONNECTED) 39] setAcl /hadoop auth:root:root:cdrwa #指定用户名和密码为 root
[zk: localhost:2181(CONNECTED) 40] getAcl /hadoop
'digest,'heibai:sCxtVJ1gPG8UW/jzFHR0A1ZKY5s= #无效,使用的用户名和密码依然还是 heibai
: cdrwa使用 auth 模式设置的权限和使用 digest 模式设置的权限,在最终结果上,得到的权限模式都是 digest。某种程度上,你可以把 auth 模式理解成是 digest 模式的一种简便实现。因为在 digest 模式下,每次设置都需要书写用户名和加密后的密码,这是比较繁琐的,采用 auth 模式就可以避免这种麻烦。
ip模式
[zk: localhost:2181(CONNECTED) 46] create /hive "hive" ip:192.168.0.108:cdrwa
[zk: localhost:2181(CONNECTED) 47] get /hive
Authentication is not valid : /hive # 当前主机已经不能访问这里可以看到当前主机已经不能访问,想要能够再次访问,可以使用对应 IP 的客户端,或 super 模式。
digest认证模式
需要用到 base64编码的 SHA1密码,获取密码的方式有2种
- 代码生成
<dependency
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.9.2</version>
</dependency>public class ZookeeperTest {
public static void main(String[] args) throws NoSuchAlgorithmException {
System.out.println(DigestAuthenticationProvider.generateDigest("super:super123"));
}
}
// 输出 : super:UdxDQl4f9v5oITwcAsO9bmWgHSI=- Linux生成
[root@VM-24-13-centos ~]# echo -n "reader:reader123" | openssl dgst -binary -sha1 | openssl base64
43kcq4QbFE1koc5pnX2vVh9sXaI=设置ACL也有两种方式
- create授权
create /test-s1 gggggffsd digest:reader:43kcq4QbFE1koc5pnX2vVh9sXaI=:cdrwa
[zk: 127.0.0.1:2181(CONNECTED) 3] create /test-s1 gggggffsd digest:reader:43kcq4QbFE1koc5pnX2vVh9sXaI=:cdrwa
Node already exists: /test-s1
[zk: 127.0.0.1:2181(CONNECTED) 4] create /test-s1-1 gggggffsd digest:reader:43kcq4QbFE1koc5pnX2vVh9sXaI=:cdrwa
Created /test-s1-1
[zk: 127.0.0.1:2181(CONNECTED) 5] get -s /test-s1-1
Insufficient permission : /test-s1-1
[zk: 127.0.0.1:2181(CONNECTED) 6] addauth digest reader:reader123
[zk: 127.0.0.1:2181(CONNECTED) 7] get -s /test-s1-1
gggggffsd
cZxid = 0x400000004
ctime = Wed Aug 28 02:55:30 UTC 2024
mZxid = 0x400000004
mtime = Wed Aug 28 02:55:30 UTC 2024
pZxid = 0x400000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 9
numChildren = 0
[zk: 127.0.0.1:2181(CONNECTED) 8] 这里要注意的是,如果你想在创建节点的同时设置权限控制,那么你就必须初始化数据。否则,就会把acl字符串当成数据存储,像这样就是错误的
[zk: 127.0.0.1:2181(CONNECTED) 0] create /test-s1 digest:reader:43kcq4QbFE1koc5pnX2vVh9sXaI=:cdrwa
Created /test-s1
[zk: 127.0.0.1:2181(CONNECTED) 1] get -s /test-s1
digest:reader:43kcq4QbFE1koc5pnX2vVh9sXaI=:cdrwa
cZxid = 0x400000002
ctime = Wed Aug 28 02:52:57 UTC 2024
mZxid = 0x400000002
mtime = Wed Aug 28 02:52:57 UTC 2024
pZxid = 0x400000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 48
numChildren = 0- setAcl授权
[zk: 127.0.0.1:2181(CONNECTED) 16] create /test-yyp
Created /test-yyp
[zk: 127.0.0.1:2181(CONNECTED) 17] setAcl /test-yyp digest:super:UdxDQl4f9v5oITwcAsO9bmWgHSI=:cdrwa
[zk: 127.0.0.1:2181(CONNECTED) 18] get /test-yyp
Insufficient permission : /test-yyp
[zk: 127.0.0.1:2181(CONNECTED) 19] addauth digest super:super123
[zk: 127.0.0.1:2181(CONNECTED) 20] get /test-yyp
null
[zk: 127.0.0.1:2181(CONNECTED) 21] - 首先,创建一个数据结点
/test-yyp - 然后,设置口令认证访问该结点
- 在 addauth 之前,是没有权限读取
/test-yyp的数据;但是在 addauth 之后,允许读操作
同一个znode不支持多个 ACL,新的权限信息覆盖了原来的权限信息
addauth 会取当前客户端认证后获取的权限合集,也就是说多个账号登陆后的权限集合会合并使用
权限受限怎么办
- 第一个方法是禁用 ACL 权限控制;
- 第二个方法是超级管理员模式。
可以通过配置文件zoo.cfg中添加skipACL=yes进⾏配置,默认是no,可以配置为true, 则配置过的 ACL 将不再进⾏权限检测,可以将zoo.cfg文件挂载出来,修改配置,或者是在Docker运行的时候添加环境变量进行修改
docker run --name=zookeeper-2 -p 2381:2181 --restart always -d -e ZOO_CFG_EXTRA="skipACL=yes" 30993cacc7c9或者
docker run --name=zookeeper-3 -p 2481:2181 --restart always -d -e JVMFLAGS="-Dzookeeper.skipACL=yes" 30993cacc7c9超级管理员super
设置zk启动时的JVM参数为 -Dzookeeper.DigestAuthenticationProvider.superDigest=super1:WqkSAJNIl+iMSE0y/0xAI3lPT5o= 指定超管账号口令为 super1:admin
docker run --name=zookeeper-4 -p 2581:2181 --restart always -d -e JVMFLAGS="-Dzookeeper.DigestAuthenticationProvider.superDigest=super1:WqkSAJNIl+iMSE0y/0xAI3lPT5o=" 30993cacc7c9修改部署文件添加环境变量
version: '3.1'
services:
zoo1:
image: zookeeper:3.9.2
restart: always
hostname: zoo1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_CFG_EXTRA: "reconfigEnabled=true"
JVMFLAGS: "-Dzookeeper.DigestAuthenticationProvider.superDigest=super:YjJhp1/a1jnzeGTDN7nAUxFcep8="
zoo2:
image: zookeeper:3.9.2
restart: always
hostname: zoo2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_CFG_EXTRA: "reconfigEnabled=true"
JVMFLAGS: "-Dzookeeper.DigestAuthenticationProvider.superDigest=super:YjJhp1/a1jnzeGTDN7nAUxFcep8="
zoo3:
image: zookeeper:3.9.2
restart: always
hostname: zoo3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_CFG_EXTRA: "reconfigEnabled=true"
JVMFLAGS: "-Dzookeeper.DigestAuthenticationProvider.superDigest=super:YjJhp1/a1jnzeGTDN7nAUxFcep8="-
ZOO_CFG_EXTRA: "reconfigEnabled=true"开启了默认关闭的客户端reconfig API -
JVMFLAGS: "-Dzookeeper.DigestAuthenticationProvider.superDigest=super:YjJhp1/a1jnzeGTDN7nAUxFcep8="设置了超级管理员账号为super,明文密码为qwer1234
reconfig 命令用于重新配置 ZooKeeper 集群。它允许管理员在运行时动态地调整集群的成员列表,例如添加或移除服务器节点。reconfig 命令是通过 ZooKeeper 的客户端 API 来使用的,而不是一个独立的命令行工具。
动态扩容和缩容
ZooKeeper 支持通过修改 zoo.cfg 并重启来改变ZooKeeper集群中的服务器,但是这种方式,不是很方便,上线一台服务器或者下线一台服务器需要对所有的服务器进行重启。
ZooKeeper 3.5.0 提供了⽀持动态扩容/缩容的 新特性。
当前的集群状态 get /zookeeper/config
[zk: 127.0.0.1:2181(CONNECTED) 2] get /zookeeper/config
server.1=zoo1:2888:3888:participant;0.0.0.0:2181
server.2=zoo2:2888:3888:participant;0.0.0.0:2181
server.3=zoo3:2888:3888:participant;0.0.0.0:2181
version=100000000认证超级管理员身份
addauth digest super:qwer1234
移除集群中的一台服务器
[zk: 127.0.0.1:2181(CONNECTED) 10] reconfig -remove 3
Committed new configuration:
server.1=zoo1:2888:3888:participant;0.0.0.0:2181
server.2=zoo2:2888:3888:participant;0.0.0.0:2181
version=100000005为集群新增一台服务器
reconfig -add server.id=<address1>:<port1>:<port2>[:role];[<client port address>:]<client port>[zk: 127.0.0.1:2181(CONNECTED) 11] reconfig -add server.3=zoo3:2888:3888;2181
Committed new configuration:
server.1=zoo1:2888:3888:participant;0.0.0.0:2181
server.2=zoo2:2888:3888:participant;0.0.0.0:2181
server.3=zoo3:2888:3888:participant;0.0.0.0:2181
version=200000001
[zk: 127.0.0.1:2181(CONNECTED) 12] get /zookeeper/config
server.1=zoo1:2888:3888:participant;0.0.0.0:2181
server.2=zoo2:2888:3888:participant;0.0.0.0:2181
server.3=zoo3:2888:3888:participant;0.0.0.0:2181
version=200000001ZooKeeper 重要概念
Data model(数据模型)
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的每个节点的数据大小上限是 1M 。
ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠”/”进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。
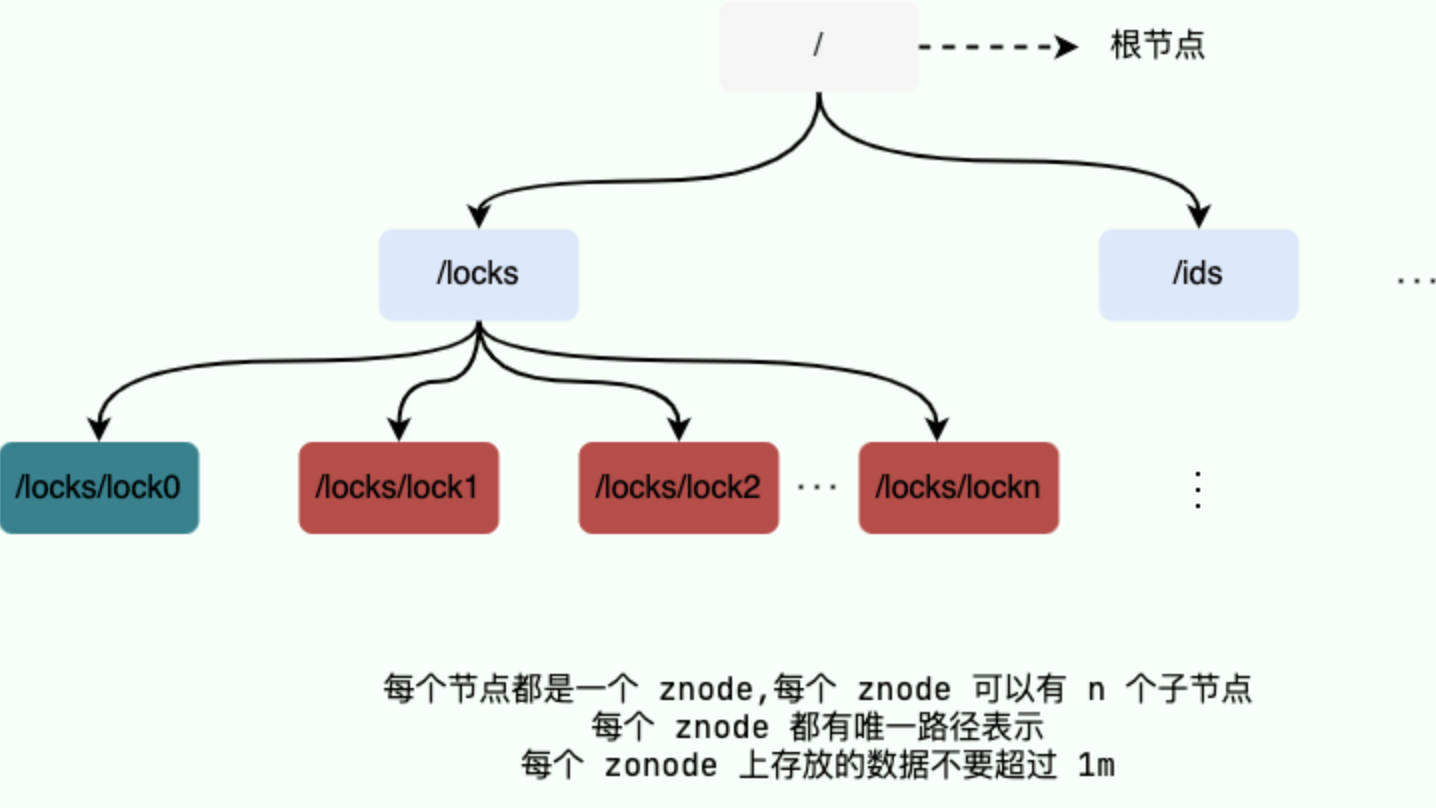
znode(数据节点)
每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。你要存放的数据就放在上面,是你使用 ZooKeeper 过程中经常需要接触到的一个概念。
我们通常是将 znode 分为 4 大类:
- 持久(PERSISTENT)节点:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
- 临时(EPHEMERAL)节点:临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失。并且,临时节点只能做叶子节点 ,不能创建子节点。
-
持久顺序(PERSISTENT_SEQUENTIAL)节点:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如
/node1/app0000000001、/node1/app0000000002。 - 临时顺序(EPHEMERAL_SEQUENTIAL)节点:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
每个 znode 由 2 部分组成:
- stat:状态信息
- data:节点存放的数据的具体内容
[zk: 127.0.0.1:2181(CONNECTED) 2] create /zk-testr
[zk: 127.0.0.1:2181(CONNECTED) 6] get -s /zk-testr
# 该数据节点关联的数据内容为空
null
# 下面是该数据节点的一些状态信息,其实就是 Stat 对象的格式化输出
cZxid = 0x200000007
ctime = Fri Aug 23 07:40:37 UTC 2024
mZxid = 0x200000007
mtime = Fri Aug 23 07:40:37 UTC 2024
pZxid = 0x200000007
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务 ID(cZxid)、节点创建时间(ctime) 和子节点个数(numChildren) 等等。
比较复杂的是事务ID和版本号。事务ID记录着节点的状态,ZooKeeper状态的每一次改变,都对应着一个递增的事务ID(Transaction id),该ID称为Zxid,它是全局有序的,每次ZooKeeper的更新操作,都会产生一个新的Zxid。Zxid不仅仅是一个唯一的事务ID,它还 具有递增性。比如,有两个Zxid存在着 Zxid1< Zxid2,那么说明Zxid1变化事件发生在Zxid2 变化之前。
一个Znode的建立或者更新,都会产生一个新的Zxid值,所以在节点信息中,保存了 3 个Zxid事务ID值,cZxid / mZxid / pZxid
| znode 状态信息 | 解释 |
|---|---|
| cZxid | create ZXID,即该数据节点被创建时的事务 id |
| ctime | create time,即该节点的创建时间 |
| mZxid | modified ZXID,即该节点最终一次更新时的事务 id |
| mtime | modified time,即该节点最后一次的更新时间 |
| pZxid | 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响pZxid的值,但是修改子节点的数据内容则不影响该ID |
| cversion | 子节点版本号,当前节点的子节点每次变化时值增加 1 |
| dataVersion | 数据节点内容版本号,节点创建时为 0,每更新一次节点内容(不管内容有无变化)该版本号的值增加 1 |
| aclVersion | 节点的 ACL 版本号,表示该节点 ACL 信息变更次数(权限版本号,权限每次修改该版本号加1) |
| ephemeralOwner | 创建该临时节点的会话的 sessionId;如果当前节点为持久节点,则 ephemeralOwner=0 |
| dataLength | 数据节点内容长度 |
| numChildren | 当前节点的子节点个数 |
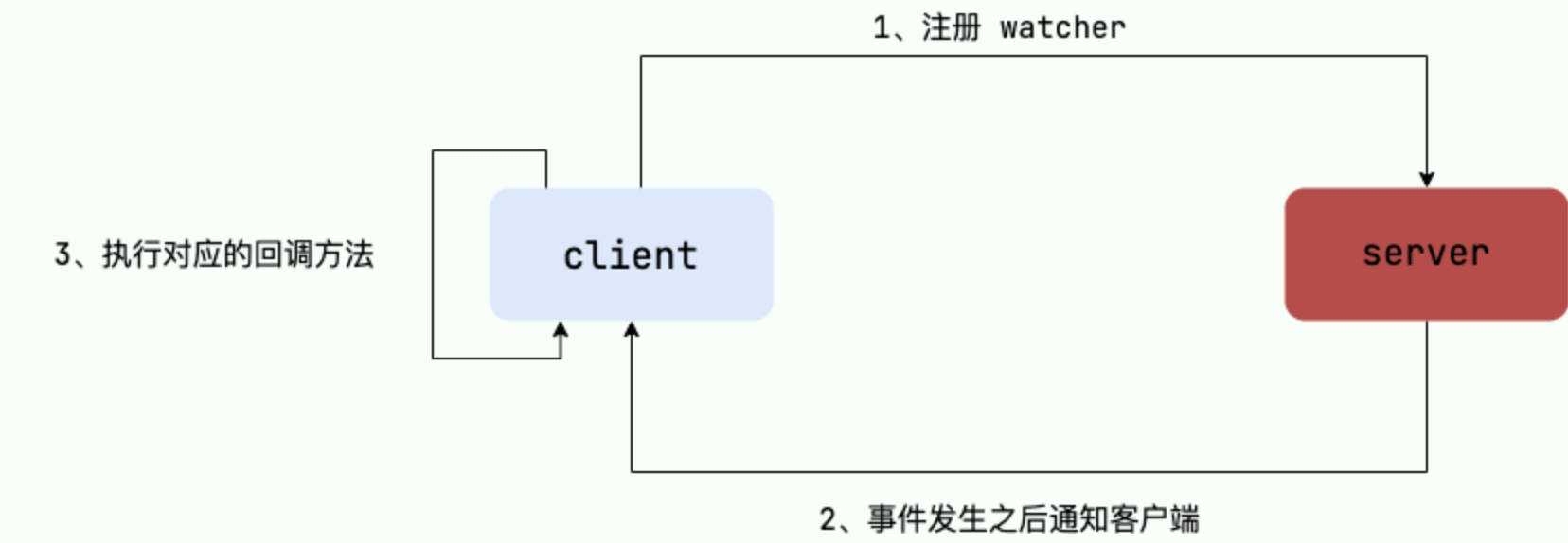
Watcher(事件监听器)
Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
会话(Session)
Session 可以看作是 ZooKeeper 服务器与客户端的之间的一个 TCP 长连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watcher 事件通知。
Session 有一个属性叫做:sessionTimeout ,sessionTimeout 代表会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在sessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
另外,在为客户端创建会话之前,服务端首先会为每个客户端都分配一个 sessionID。由于 sessionID是 ZooKeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的,因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一。
ZooKeeper 集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
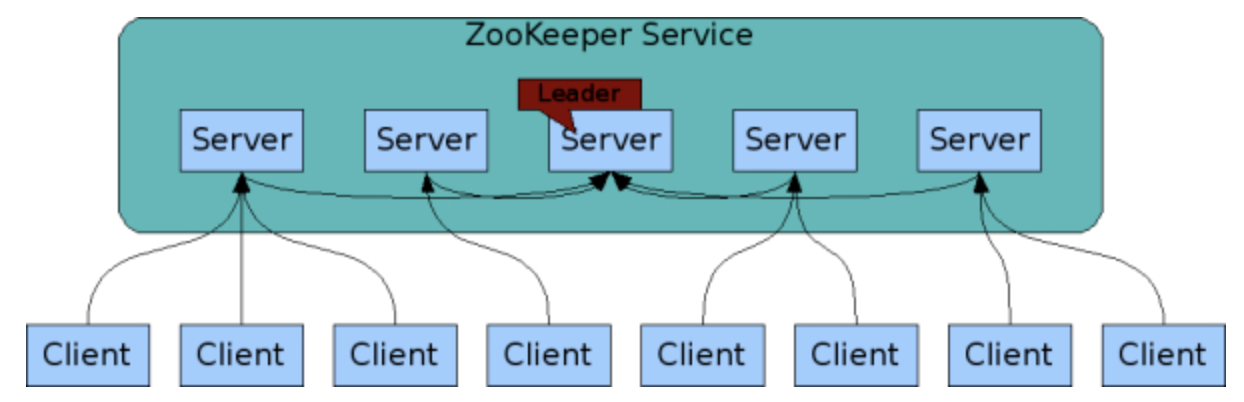
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
最典型集群模式:Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种
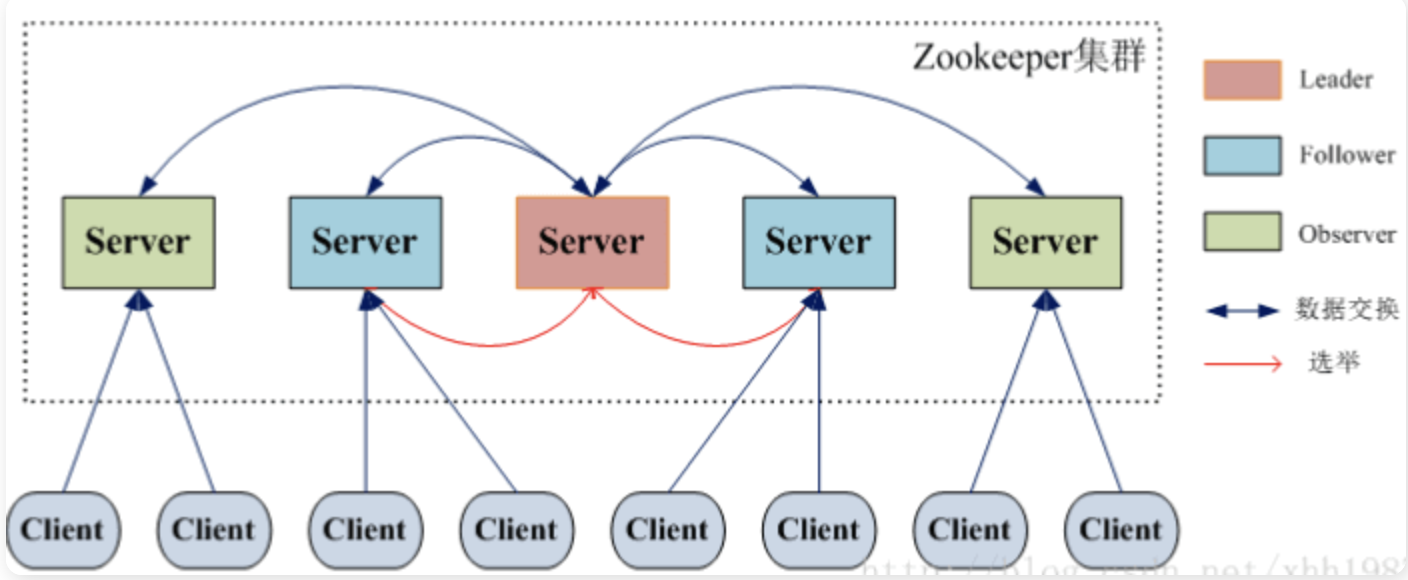
| 角色 | 说明 |
|---|---|
| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
ZooKeeper 集群 Leader 选举过程
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
这个过程大致是这样的:
- Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
- Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
- Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
- Broadcast(广播阶段):到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZooKeeper 集群中的服务器状态有下面几种:
- LOOKING:寻找 Leader。
- LEADING:Leader 状态,对应的节点为 Leader。
- FOLLOWING:Follower 状态,对应的节点为 Follower。
- OBSERVING:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
ZooKeeper 集群为啥最好奇数台?
ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。
假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
ZAB 协议和 Paxos 算法
Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos 算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在 ZooKeeper 的官方文档中也指出,ZAB 协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为 Zookeeper 设计的崩溃可恢复的原子消息广播算法。
ZAB 协议包括两种基本的模式,分别是
- 崩溃恢复:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致。
- 消息广播:当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
典型应用场景
选主节点
因为 Zookeeper 的强一致性,能够很好地在保证 在高并发的情况下保证节点创建的全局唯一性 (即无法重复创建同样的节点)。
利用这个特性,我们可以 让多个客户端创建一个指定的节点 ,创建成功的就是 master。
但是,如果这个 master 挂了怎么办???
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?master 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 watcher 吗?我们是不是可以 让其他不是 master 的节点监听节点的状态 ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 master 挂了,这个时候我们 触发回调函数进行重新选举 ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 master 是否挂了等等。
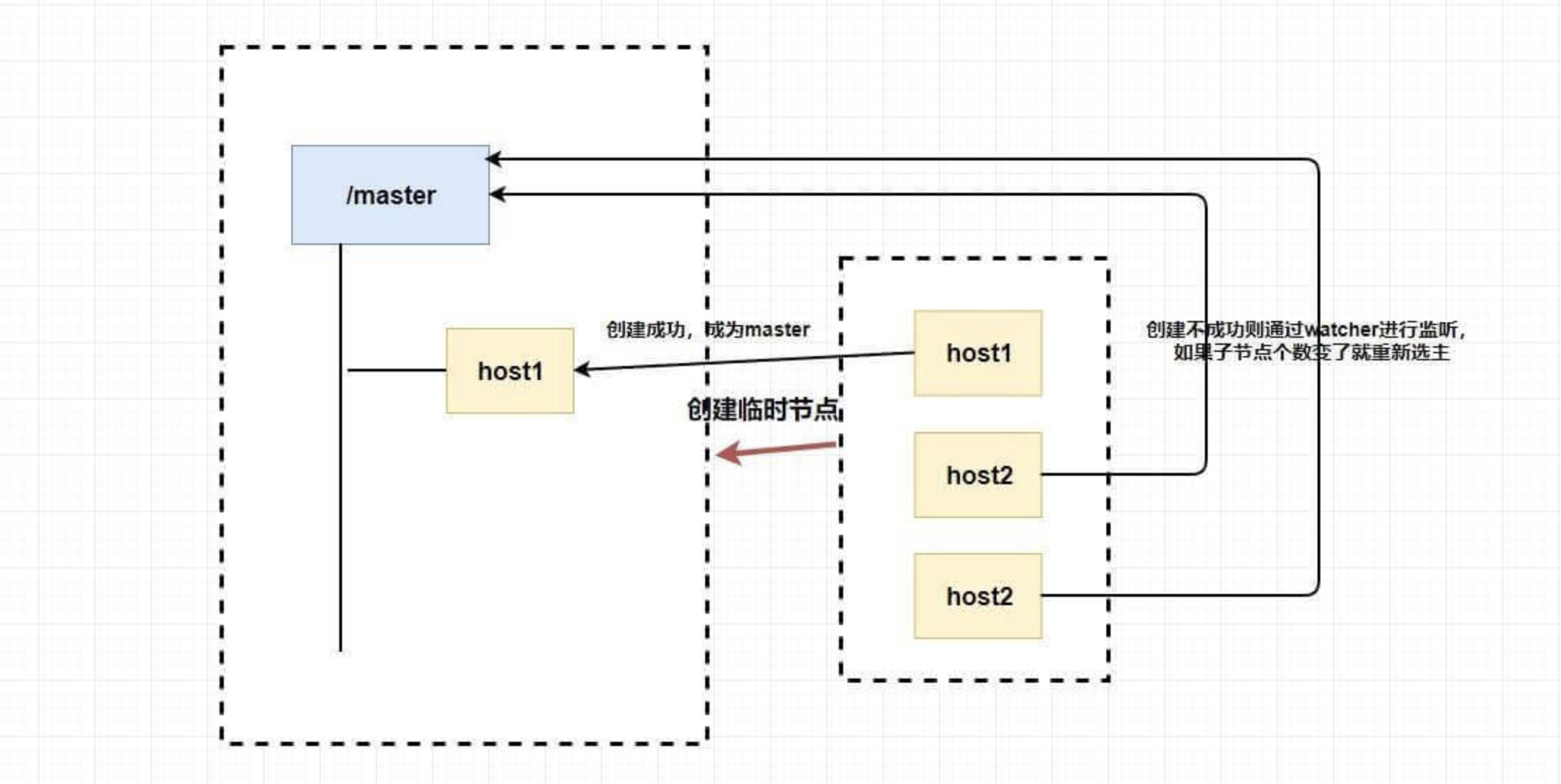
我们可以完全 利用 临时节点、节点状态 和 watcher 来实现选主的功能,临时节点主要用来选举,节点状态和watcher 可以用来判断 master 的活性和进行重新选举。
数据发布/订阅
Zookeeper 的 Watcher 机制, Zookeeper 通过这种推拉相结合的方式实现客户端与服务端的交互:客户端向服务端注册节点,一旦相应节点的数据变更,服务端就会向“监听”该节点的客户端发送 Watcher 事件通知,客户端接收到通知后需要 主动 到服务端获取最新的数据。基于这种方式,Zookeeper 实现了 数据发布/订阅 功能。
一个典型的应用场景为 全局配置信息的集中管理。 客户端在启动时会主动到 Zookeeper 服务端获取配置信息,同时 在指定节点注册一个 Watcher 监听。当配置信息发生变更,服务端通知所有订阅的客户端重新获取配置信息,实现配置信息的实时更新。
上面所提到的全局配置信息通常包括机器列表信息、运行时的开关配置、数据库配置信息等。需要注意的是,这类全局配置信息通常具备以下特性:
- 数据量较小
- 数据内容在运行时动态变化
- 集群中机器共享一致配置
负载均衡
可以通过 Zookeeper 的 临时节点 实现负载均衡。回顾一下临时节点的特性:当创建节点的客户端与服务端之间断开连接,即客户端会话(session)消失时,对应节点也会自动消失。因此,我们可以使用临时节点来维护 Server 的地址列表,从而保证请求不会被分配到已停机的服务上。
具体地,我们需要在集群的每一个 Server 中都使用 Zookeeper 客户端连接 Zookeeper 服务端,同时用 Server 自身的地址信息在服务端指定目录下创建临时节点。当客户端请求调用集群服务时,首先通过 Zookeeper 获取该目录下的节点列表 (即所有可用的 Server),随后根据不同的负载均衡策略将请求转发到某一具体的 Server。
分布式锁
分布式锁的实现方式有很多种,比如 Redis、数据库、zookeeper 等
已经提到过了 zk 在高并发的情况下保证节点创建的全局唯一性,可以实现互斥锁,又因为能在分布式的情况下,所以能实现分布式锁
如何实现呢?其实跟选主基本一样,我们也可以利用临时节点的创建来实现。
首先肯定是如何获取锁,因为创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,创建成功的就说明获取到了锁 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 watcher 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
zk 中不需要向 redis 那样考虑锁得不到释放的问题了,因为当客户端挂了,节点也挂了,锁也释放了。
那能不能使用 zookeeper 同时实现 共享锁和独占锁 呢?答案是可以的,不过稍微有点复杂而已。
还记得 有序的节点 吗?
这个时候规定所有创建节点必须有序,当你是读请求(要获取共享锁)的话,如果 没有比自己更小的节点,或比自己小的节点都是读请求 ,则可以获取到读锁,然后就可以开始读了。若比自己小的节点中有写请求 ,则当前客户端无法获取到读锁,只能等待前面的写请求完成。
如果你是写请求(获取独占锁),若 没有比自己更小的节点 ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若发现 有比自己更小的节点,无论是读操作还是写操作,当前客户端都无法获取到写锁 ,等待所有前面的操作完成。
这就很好地同时实现了共享锁和独占锁,当然还有优化的地方,比如当一个锁得到释放它会通知所有等待的客户端从而造成 羊群效应 。此时你可以通过让等待的节点只监听他们前面的节点。
具体怎么做呢?你可以让 读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点
命名服务
如何给一个对象设置 ID,大家可能都会想到 UUID,但是 UUID 最大的问题就在于它太长了(太长不一定是好事)。那么在条件允许的情况下,我们能不能使用 zookeeper 来实现呢?
之前提到过 zookeeper 是通过 树形结构 来存储数据节点的,那也就是说,对于每个节点的 全路径,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的 ID 设置可以更加便于理解。
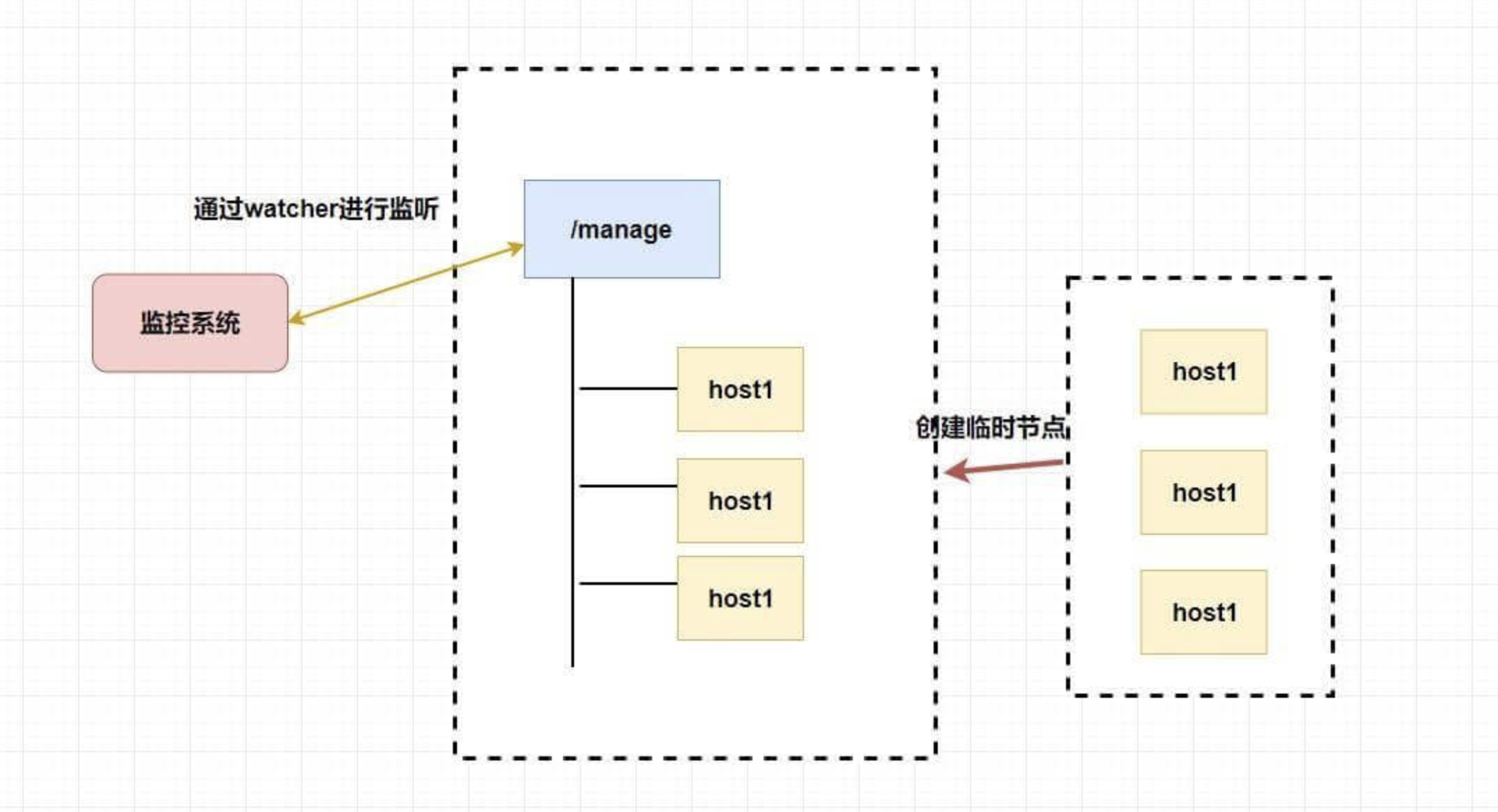
集群管理和注册中心
我们需要了解整个集群中有多少机器在工作,我们想对集群中的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。
而 zookeeper 天然支持的 watcher 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 watcher 进行状态监控和回调。
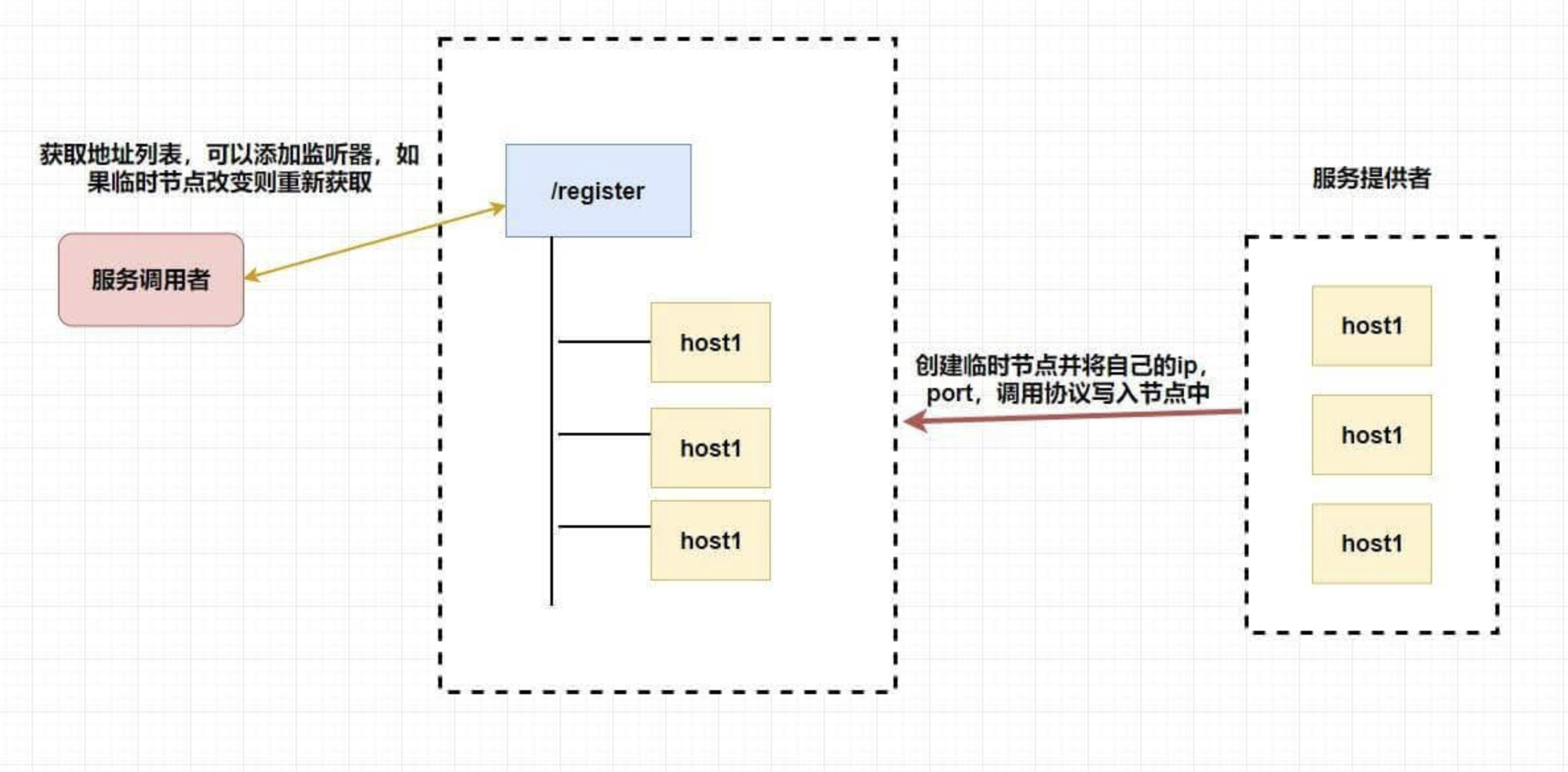
至于注册中心也很简单,我们同样也是让 服务提供者 在 zookeeper 中创建一个临时节点并且将自己的 ip、port、调用方式 写入节点,当 服务消费者 需要进行调用的时候会 通过注册中心找到相应的服务的地址列表(IP 端口什么的) ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,记得 Eureka 会先试错,然后再更新)。
ZooKeeper来实现高可用案例
如果使用zookeeper来实现系统的高可用时,一般需要考虑4个问题,或者理解为4个步骤:
- 如何设计znode的path
- znode的类型如何选择?比如是临时节点,还是顺序节点?
- znode中存储什么数据?如何表达自己的业务含义
- 如何设计watch,客户端需要关注什么事件,事件发生后需要如何处理?
主备切换
主备切换在我们日常用到的分布式系统很常见,那我们自己如何通过zookeeper的接口来实现呢?
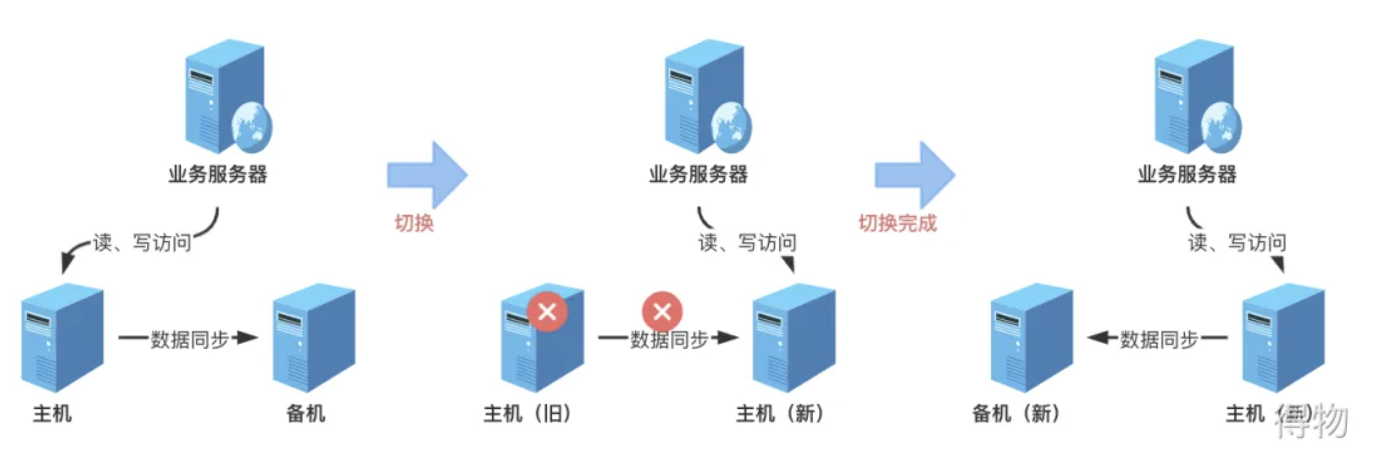
主备架构的工作流程:
正常阶段的话,业务数据读写在主机,数据会复制到备机。当主机故障了,数据没办法复制到备机,原来的备机自动升级为主机,业务请求到新的主机。原来的主机恢复后,成为新的备机,将数据从新的主机同步到备机上
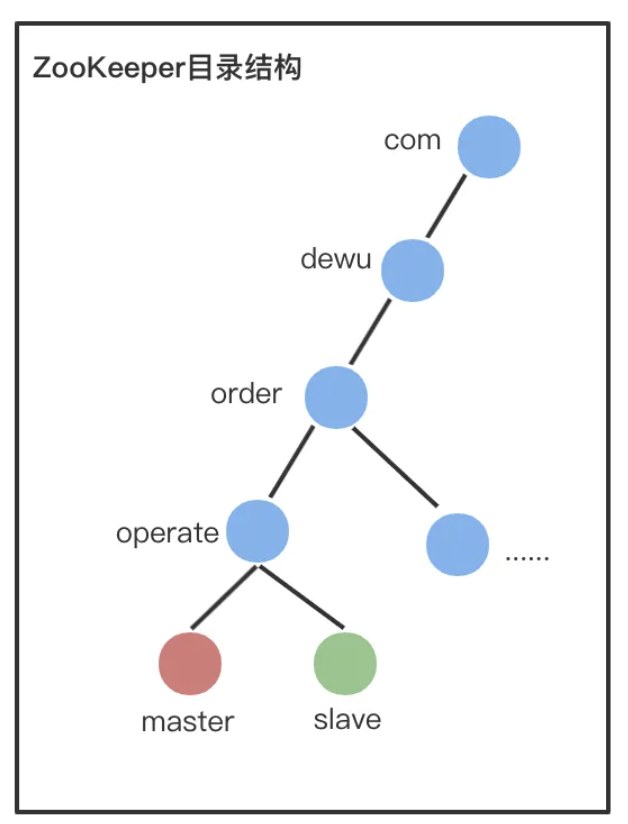
1、设计Path
由于只有2个角色,因此直接设置两个 znode 即可,master和slave,样例:
- /com/dewu/order/operate/master
- /com/dewu/order/operate/slave。
2、选择节点类型
当 master 节点挂掉的时候,原来的 slave 升级为 master 节点,因此用 ephemeral (临时节点) 类型的 znode
因为当一个节点成为master时,需要zk创建master节点,一旦这台主机挂掉了,它到zk的连接就断掉了,这个master节点会在超时之后,被zk自动删除,这样的话,就知道原来的主机宕机了,所以选择使用ephemeral类型的节点
3、设计节点数据
由于 slave 成为 master 后,会成为新的复制源,可能出现数据冲突,因此 slave 成为 master 后,节点需要写入成为 master 的时间,这样方便修复冲突数据。还可以写入slave上最新的事务id,这里可以根据自己的业务灵活设计,znode节点中应该写入什么数据
4、设计 Watch
节点启动的时候,尝试创建 master znode,创建成功则切换为master,否则创建 slave znode,成为 slave,并监听master节点; 如果 slave 节点收到 master znode 删除的事件,就自己去尝试创建 master znode,创建成功,则自己成为 master,删除自己创建的slave znode
实现集群选举
集群选举的方式比较多,主要是根据自己的业务场景
最小节点获胜
就是在共同的父节点下创建znode,谁的编号最小,谁是leader
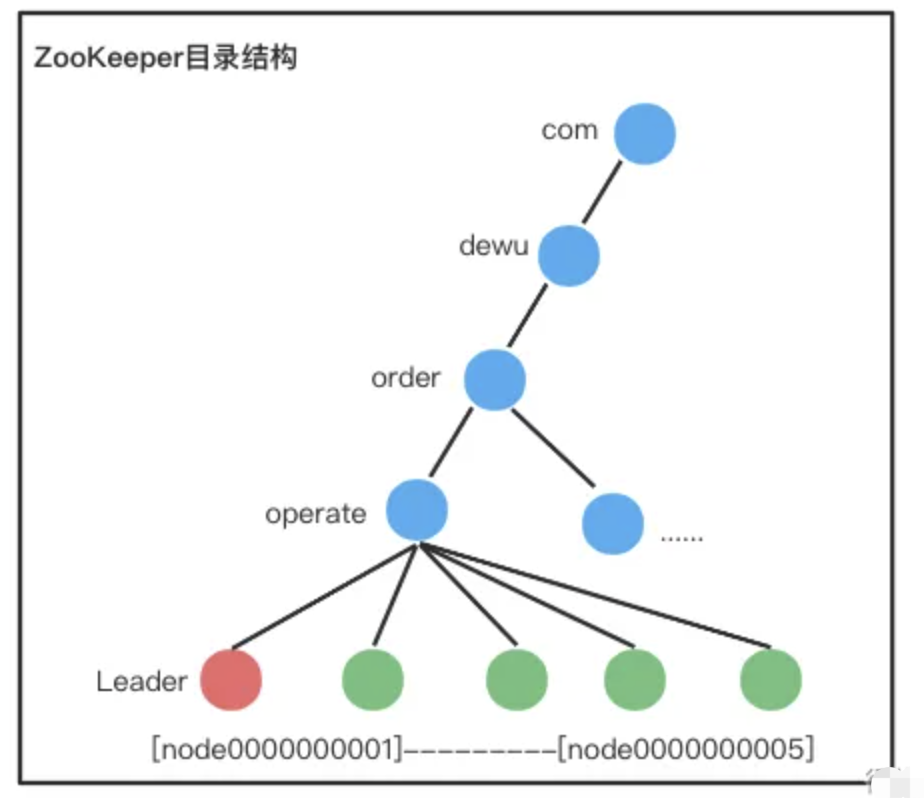
1、设计 Path
集群共用父节点 parent znode,也就是上图中的operate,集群中的每个节点在 parent 目录下创建自己的 znode。如上图中,假如有5个节点,编号是从node0000000001~node0000000005。
2、选择节点类型
当 Leader 节点挂掉的时候,持有最小编号 znode 的集群节点成为新的 Leader,因此用ephemeral_sequential 类型 znode。使用ephemeral类型的目的是,leader挂掉的时候,节点能自动删除,使用sequential类型的目的是,让这些节点都是有序的,我们选择最小节点的时候就比较简单。
3、设计节点数据
可以根据业务需要灵活写入各种数据。
4、设计 Watch
- 节点启动或者重连后,在 parent 目录下创建自己的 ephemeral_sequntial znode;
- 创建成功后扫描 parent 目录下所有 znode,如果自己的 znode 编号是最小的,则成为 Leader,否则 监听 parent整个目录;
- 当 parent 目录有节点删除的时候,首先判断其是否是 Leader 节点,然后再看其编号是否正好比自己小1,如果是则自己成为 Leader,如果不是继续 watch。
抢建唯一节点
集群共用父节点 parent znode,也就是operate,集群中的每个节点在 parent 目录下创建自己的 znode。也就是集群中只有一个节点,谁创建成功谁就是leader。
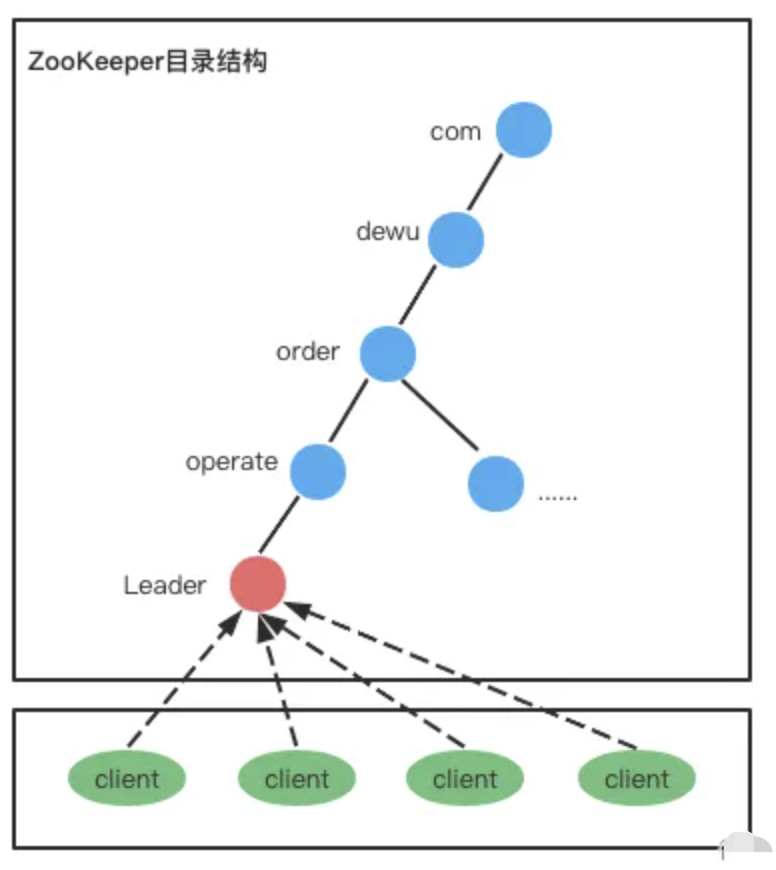
1、设计 Path
集群所有节点只有一个 leader znode,其实本质上就是一个分布式锁。
2、选择 znode 类型
当 Leader 节点挂掉的时候,剩余节点都来创建 leader znode,看谁能最终抢到 leader znode,因此用ephemeral 类型。
3、设计节点数据
可以根据业务需要灵活写入各种数据。
4、设计 Watch
- 节点启动或者重连后,尝试创建 leader znode,尝试失败则监听 leader znode;
- 当收到 leader znode 被删除的事件通知后,再次尝试创建leader znode,尝试成功则成为leader ,失败则继续监听leader znode。
法官判决
整体实现比较复杂的一个方案,通过创建节点,判断谁是法官节点。法官节点可以根据一定的逻辑算法来判断谁是leader,比如看谁的数据最新等等。
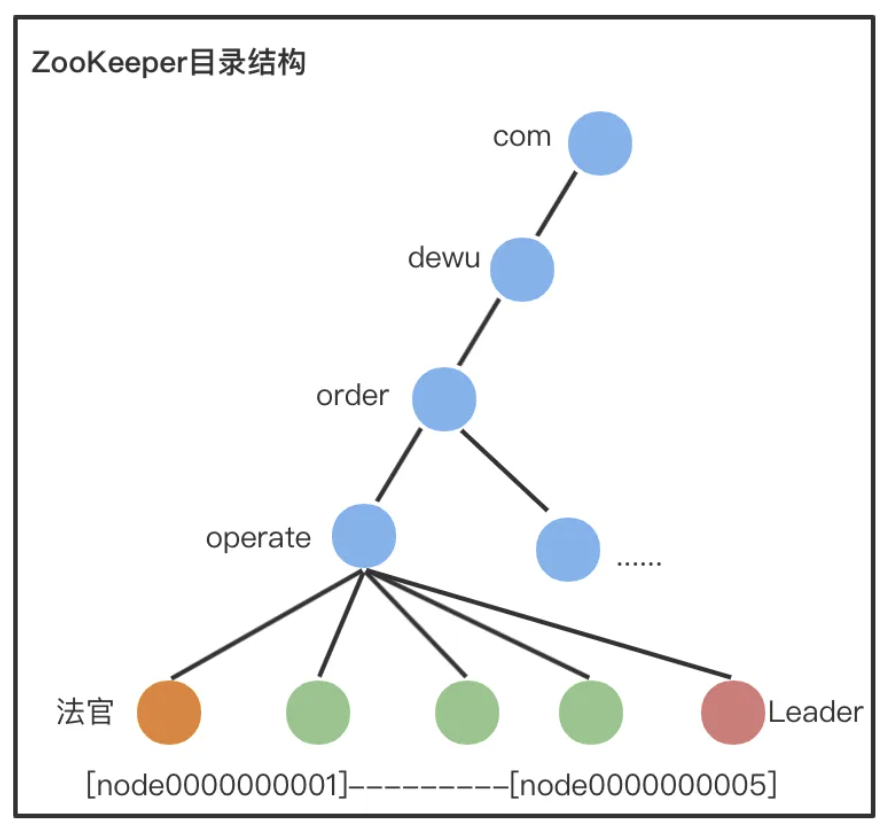
1、设计Path
集群共用父节点 parent znode,集群中的每个节点在 parent 目录下创建自己的 znode。
- parent znode:图中的 operate,代表一个集群,选举结果写入到operate节点,比如写入的内容可以是:leader=server6。
- 法官 znode:图中的橙色 znode,最小的 znode,持有这个 znode 的节点负责选举算法/规则。
- 例如:实现Redis 存储集群的选举,各个 slave 节点可以将自己存储的数据最新的 trxId写入到 znode,然后法官节点将 trxID 最大的节点选为新的 Leader。
- 成员 znode:图中的绿色 znode,每个集群节点对应一个,在选举期间将选举需要的信息写入到自己的 znode。
- Leader znode:图中的红色 znode,集群里面只有一个,由法官选出来。
2、选择节点类型
当 Leader 节点挂掉的时候,持有最小编号 znode 的集群节点成为“法官”,因此用 ephemeral_sequential (临时顺序节点)类型 znode。
3、设计节点数据
可以根据业务需要灵活写入各种数据,比如写入当前存储的最新的数据对应的事务 ID。
4、设计Watch
- 节点启动或者重连后,在 parent 目录下创建自己的 ephemeral_sequntial znode,并 监听 parent 目录;
- 当 parent 目录有节点删除的时候,所有节点更新自己的 znode 里面和选举相关的数据;
- “法官”节点读取所有 znode的数据,根据规则或者算法选举新的 Leader,将选举结果写入parent znode;
- 所有节点监听 parent znode,收到变更通知的时候读取 parent znode 的数据,判断自己是否成为 Leader。
Zookeeper客户端
Zookeeper官方依赖
目前,Zookeeper服务器有三种Java客户端: Zookeeper、Zkclient和Curator
- Zookeeper: Zookeeper是官方提供的原生java客户端
- Zkclient: 是在原生zookeeper客户端基础上进行扩展的开源第三方Java客户端(很久不更新了,不考虑)
- Curator: Netflix公司在原生zookeeper客户端基础上开源的第三方Java客户端
该客户端是zookeeper官方自带的,编程不是那么方便:
- 会话超时异常时,不支持自动重连,需要手动重新连接,编程繁琐
- watcher 是一次性的,注册一次后会失效
- 节点数据是二进制,对象数据都需要转换为二进制保存
- 不支持递归创建节点,需要先创建父节点再创建子节点
- 不支持递归删除节点,需要先删除子节点再删除父节点
- 原生zookeeper客户端和服务器端会话的建立是一个异步的过程,也就是说在程序中,我们程序方法在处理完客户端初始化后,立即返回(程序往下执行代码,这样,大多数情况下我们并没有真正构建好一个可用会话,在会话的声明周期处于”CONNECTED”时才算真正建立完毕,所以我们需要使用多线程中的一个工具类CountDownLatch来控制,真正的连接上zk客户端后,才可以继续操作zNode节点)
使用Java客户端Zookeeper,首先需要添加zookeeper的官方客户端jar包依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.9.2</version>
</dependency>
完整案例
public class ZookeeperTest {
private static ZooKeeper zookeeper;
private static final String ZK_ADDRESS="82.157.xxx.xx:2181";
private static final int SESSION_TIMEOUT = 5000;
private static final String ZK_NODE="/zk‐node11111";
public static void main(String[] args) throws InterruptedException, KeeperException {
initConnect(ZK_ADDRESS,SESSION_TIMEOUT);
createNode(ZK_NODE,"hello world");
createNodeRecursion(ZK_NODE+"/wwwwww","hello world");
queryNode(ZK_NODE);
updateNodeData(ZK_NODE,"kkklopoksjdfcdsfds");
queryNode(ZK_NODE);
deleteRecursion(ZK_NODE);
}
/**
* <p>
* 初始化zookeeper,创建zookeeper客户端对象
* <p/>
*
* @param connectAddress
* @param sessionTimeout
* @return void
*/
private static void initConnect(String connectAddress, int sessionTimeout) {
try {
final CountDownLatch countDownLatch=new CountDownLatch(1);
//创建zookeeper客户端对象
//zookeeper = new ZooKeeper(connectAddress, sessionTimeout, null);
//以上这种方式,由于zookeeper连接是异步的,如果new ZooKeeper(connectStr, sessionTimeout, null)完之后马上使用,有可能会报错。
//解决办法:增加watcher监听事件,如果为SyncConnected,那么才做其他的操作。(这里利用CountDownLatch倒数器来控制)
zookeeper = new ZooKeeper(connectAddress, sessionTimeout, watchedEvent -> {
//获取监听事件的状态
Watcher.Event.KeeperState state = watchedEvent.getState();
//获取监听事件类型
Watcher.Event.EventType type = watchedEvent.getType();
//如果已经建立上了连接
if (Watcher.Event.KeeperState.SyncConnected == state) {
if (Watcher.Event.EventType.None == type) {
System.out.println("zookeeper连接成功......");
countDownLatch.countDown();
}
}
if (Watcher.Event.EventType.NodeCreated == type) {
System.out.println("zookeeper有新节点【" + watchedEvent.getPath() + "】创建!");
}
if (Watcher.Event.EventType.NodeDataChanged == type) {
System.out.println("zookeeper有节点【" + watchedEvent.getPath() + "】数据变化!");
}
if (Watcher.Event.EventType.NodeDeleted == type) {
System.out.println("zookeeper有节点【" + watchedEvent.getPath() + "】被删除!");
}
if (Watcher.Event.EventType.NodeChildrenChanged == type) {
System.out.println("zookeeper有子节点【" + watchedEvent.getPath() + "】变化!");
}
});
//倒计数器没有倒数完成,不能执行下面的代码,因为需要等zookeeper连上了,才可以进行node的操作,否则可能会报错
countDownLatch.await();
System.out.println("init connect success:" + zookeeper);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* <p>
* 根据指定路径,创建zNode节点,并赋值数据
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void createNode(String nodePath, String data) throws KeeperException, InterruptedException {
if (StringUtils.isEmpty(nodePath)) {
System.out.println("节点【" + nodePath + "】不能为空");
return;
}
//对节点是否存在进行判断,否则会报错:【NodeExistsException: KeeperErrorCode = NodeExists for /root】
Stat exists = zookeeper.exists(nodePath, true);
if (null != exists) {
System.out.println("节点【" + nodePath + "】已存在,不能新增");
return;
}
String result = zookeeper.create(nodePath, data.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create:" + "【" + nodePath + "-->" + data + "】,result:" + result);
}
/**
* <p>
* 根据指定路径,递归创建zNode节点,并赋值数据
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void createNodeRecursion(String nodePath, String data) throws KeeperException, InterruptedException {
if (StringUtils.isEmpty(nodePath)) {
System.out.println("节点【" + nodePath + "】不能为空");
return;
}
String paths[] = nodePath.substring(1).split("/");
for (int i = 0; i < paths.length; i++) {
String childPath = "";
for (int j = 0; j <= i; j++) {
childPath += "/" + paths[j];
}
createNode(childPath, data);
}
}
/**
* <p>
* 查询节点
* <p/>
*
* @param nodePath
* @return void
*/
private static void queryNode(String nodePath) throws KeeperException, InterruptedException {
System.out.println("--------------------华丽的分割线-------------------------");
byte[] bytes = zookeeper.getData(nodePath, false, null);
System.out.println(new String(bytes));
Stat stat = new Stat();
byte[] data = zookeeper.getData(nodePath, true, stat);
System.out.println("queryNode:" + "【" + nodePath + "】,result:" + new String(data) + ",stat:" + stat);
}
/**
* <p>
* 更新指定节点的数据
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void updateNodeData(String nodePath, String data) throws KeeperException, InterruptedException {
//version = -1代表不指定版本
Stat stat = zookeeper.setData(nodePath, data.getBytes(), -1);
System.out.println("setData:" + "【" + nodePath + "】,stat:" + stat);
}
/**
* <p>
* 根据某个节点,删除节点
* <p/>
*
* @param nodePath
* @return void
*/
private static void deleteNode(String nodePath) throws KeeperException, InterruptedException {
System.out.println("--------------------华丽的分割线-------------------------");
Stat exists = zookeeper.exists(nodePath, true);
if (null == exists) {
System.out.println(nodePath + "不存在,请核实后在进行相关操作!");
return;
}
zookeeper.delete(nodePath, -1);//version:-1表示删除节点时,不指定版本
System.out.println("delete node:" + "【" + nodePath + "】");
}
/**
* <p>
* 根据某个路径,递归删除节点(该方式会删除父节点)
* <p/>
*
* @param nodePath
* @return void
* @Date 2020/6/20 15:29
*/
private static void deleteRecursion(String nodePath) throws KeeperException, InterruptedException {
System.out.println("--------------------华丽的分割线-------------------------");
Stat exists = zookeeper.exists(nodePath, true);
if (null == exists) {
System.out.println(nodePath + "不存在,请核实后在进行相关操作!");
return;
}
//获取当前nodePath下,子节点的数据
List<String> list = zookeeper.getChildren(nodePath, true);
if (CollectionUtils.isEmpty(list)) {
deleteNode(nodePath);
String parentPath = nodePath.substring(0, nodePath.lastIndexOf("/"));
System.out.println("parentPath=" + parentPath);
//如果当前节点存在父节点,连带的删除父节点,以及父节点下所有的子节点
if (StringUtils.isNotBlank(parentPath)) {
deleteRecursion(parentPath);
}
} else {
for (String child : list) {
deleteRecursion(nodePath + "/" + child);
}
}
}
}
Curator客户端
官网:https://curator.apache.org/docs/about
Curator是Netflix公司在原生zookeeper基础上开源的一个Zookeeper Java客户端,目前Curator捐献给了Apache,现在是Apache下的一个开源项目,与Zookeeper提供的原生客户端相比,Curator的进行了高度的抽象和封装,简化了Zookeeper客户端的开发操作。
Curator与ZkClient相比,功能更加的强大,不仅除了解决原生的zk Api的遗留问题,还提供了很多常用的工具类,也提供了很多解决方案,比如分布式锁。Curator API的使用更简洁方便,提供了流式的操作,可以点.点.点.的方式进行方法的调用,所以Curator是目前比较主流的zk客户端。
通过查看官方文档,可以发现Curator主要解决了三类问题:
- 封装ZooKeeper client与ZooKeeper server之间的连接处理
- 提供了一套Fluent风格的操作API(点.点.点.)
- 提供ZooKeeper各种应用场景(recipe)的抽象封装,比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等
创建Curator连接对象
主要有以下几种方式:
public static CuratorFramework newClient(String connectString, RetryPolicy retryPolicy)
public static CuratorFramework newClient(String connectString, int sessionTimeoutMs, int connectionTimeoutMs, RetryPolicy retryPolicy)方法参数说明:
-
connectString:指的是需要连接的zookeeperAddress ip -
retryPolicy:指的是连接zk时使用哪种重试策略 -
sessionTimeoutMs:指的是会话超时时间 -
connectionTimeoutMs:指的是连接超时时间
public class ZookeeperTest2 {
private static final String ZK_ADDRESS="82.157.173.74:2181,82.157.173.74:2182,82.157.173.74:2183";
private static final int SESSION_TIMEOUT = 5000;
private static final String ZK_NODE="/zk‐node-556";
private static CuratorFramework client;
/**
* 重试策略
* n:最多重试次数
* sleepMsBetweenRetries:重试时间间隔,单位毫秒
*/
private static final RetryPolicy retry = new RetryNTimes(3, 2000);
public static void main(String[] args) {
connectCuratorClient();
}
/**
* <p>
* 创建Curator连接对象
* <p/>
*
* @param
* @return
* @Date 2020/6/21 12:29
*/
public static void connectCuratorClient() {
//老版本的方式,创建zookeeper连接客户端
/**
client = CuratorFrameworkFactory.builder().
connectString(ZK_ADDRESS).
sessionTimeoutMs(5000).
connectionTimeoutMs(10000).
retryPolicy(retry).
build();
*/
//创建zookeeper连接,新版本
client = CuratorFrameworkFactory.newClient(ZK_ADDRESS, retry);
//启动客户端(Start the client. Most mutator methods will not work until the client is started)
client.start();
System.out.println("zookeeper初始化连接成功:" + client);
}
}
在Curator中,首先需要通过CuratorFrameworkFactory创建zookeeperClient连接实例,然后才能继续进行各种基本操作。需要说明的是,关于连接重试策略RetryPolicy,Curator客户端默认提供了以下几种:
-
RetryNTimes:重试N次 -
ExponentialBackoffRetry:重试一定次数,每次重试时间依次递增 -
RetryOneTime:重试一次 -
RetryUntilElapsed:重试一定时间
创建zNode节点
主要有以下几种方法:
public T forPath(String path)
//创建节点,并赋值内容
public T forPath(String path, byte[] data)
//判断节点是否存在,节点存在了,创建时仍然会报错
public ExistsBuilder checkExists() /**
* <p>
* 创建节点,并支持赋值数据内容
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void createNode(String nodePath, String data) throws Exception {
if (StringUtils.isEmpty(nodePath)) {
System.out.println("节点【" + nodePath + "】不能为空");
return;
}
//1、对节点是否存在进行判断,否则会报错:【NodeExistsException: KeeperErrorCode = NodeExists for /root】
Stat exists = client.checkExists().forPath(nodePath);
if (null != exists) {
System.out.println("节点【" + nodePath + "】已存在,不能新增");
return;
} else {
System.out.println("节点【"+ nodePath+"】不存在,可以新增节点!");
}
//2、创建节点, curator客户端开发提供了Fluent风格的API,是一种流式编码方式,可以不断地点.点.调用api方法
//创建永久节点(默认就是持久化的)
client.create().forPath(nodePath);
//3、手动指定节点的类型
client.create()
.withMode(CreateMode.PERSISTENT)
.forPath(nodePath);
//4、如果父节点不存在,创建当前节点的父节点
String node = client.create()
.creatingParentsIfNeeded()
.forPath(nodePath);
System.out.println(node);
//创建节点,并为当前节点赋值内容
if (StringUtils.isEmpty(data)) {
//5、创建永久节点,并为当前节点赋值内容
client.create()
.forPath(nodePath, data.getBytes());
//6、创建永久有序节点
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(nodePath, data.getBytes());
//7、创建临时节点
client.create()
.withMode(CreateMode.EPHEMERAL)
.forPath(nodePath, data.getBytes());
}
//8、创建临时有序节点
client.create()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(nodePath, data.getBytes());
}
获取节点列表
//获取某个节点数据
client.getData().forPath(nodePath)
//读取zookeeper的数据,并放到Stat中
client.getData().storingStatIn(stat1).forPath(nodePath)
参数说明:
- path:指定要读取的节点
- stat:指定数据节点的节点状态信息
/**
* <p>
* 获取节点数据
* <p/>
*
* @param nodePath
* @return void
*/
private static void getNode(String nodePath) throws Exception {
//获取某个节点数据
byte[] bytes = client.getData().forPath(nodePath);
System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes)));
//读取zookeeper的数据,并放到Stat中
Stat stat1 = new Stat();
byte[] bytes2 = client.getData().storingStatIn(stat1).forPath(nodePath);
System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes2)));
System.out.println(stat1);
}
获取子节点列表
//获取某个节点的所有子节点
client.getChildren().forPath(nodePath)
/**
* <p>
* 获取节点数据
* <p/>
*
* @param nodePath
* @return void
*/
private static void getNode(String nodePath) throws Exception {
//获取某个节点的所有子节点
List<String> stringList = client.getChildren().forPath(nodePath);
if (CollectionUtils.isEmpty(stringList)) {
return;
}
//遍历节点
stringList.forEach(System.out::println);
}
设置和修改节点内容
//更新节点
client.setData().forPath(nodePath, data.getBytes())
//指定版本号,更新节点
client.setData().withVersion(-1).forPath(nodePath, data.getBytes())
//异步设置某个节点数据
client.setData().inBackground().forPath(nodePath, data.getBytes())
/**
* <p>
* 设置(修改)节点数据
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void updateNode(String nodePath, String data) throws Exception {
//更新节点
Stat stat = client.setData().forPath(nodePath, data.getBytes());
//指定版本号,更新节点,更新的时候如果指定数据版本的话,那么需要和zookeeper中当前数据的版本要一致,-1表示匹配任何版本
//Stat stat = client.setData().withVersion(-1).forPath(nodePath, data.getBytes());
System.out.println(stat);
//异步设置某个节点数据
Stat stat1 = client.setData().inBackground().forPath(nodePath, data.getBytes());
System.out.println(stat1.toString());
}
删除zNode节点
//删除节点
client.delete().forPath(nodePath);
//删除节点,即使出现网络故障,zookeeper也可以保证删除该节点
client.delete().guaranteed().forPath(nodePath);
//级联删除节点(如果当前节点有子节点,子节点也可以一同删除)
client.delete().deletingChildrenIfNeeded().forPath(nodePath);
Curator客户端使用起来非常方便,而且有好多builder对象,比如CreateBuilder、DeleteBuilder、ExistsBuilder、GetDataBuilder、SetDataBuilder等等。
完整代码示例
/**
* <p>
* Curator客户端基础使用
* <p/>
*
*/
public class ZookeeperCuratorClient {
/**
* 客户端连接地址
*/
private static final String ZK_ADDRESS = "ip:2181";
/**
* 客户端根节点
*/
private static final String ROOT_NODE = "/root";
/**
* 客户端子节点
*/
private static final String ROOT_NODE_CHILDREN = "/root/children";
/**
* 会话超时时间
*/
private final int SESSION_TIMEOUT = 20 * 1000;
/**
* 连接超时时间
*/
private final int CONNECTION_TIMEOUT = 5 * 1000;
/**
* 创建zookeeper连接实例
*/
private static CuratorFramework client = null;
/**
* 重试策略
* baseSleepTimeMs:初始的重试等待时间,单位毫秒
* maxRetries:最多重试次数
*/
private static final RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
/**
* 重试策略
* n:最多重试次数
* sleepMsBetweenRetries:重试时间间隔,单位毫秒
*/
private static final RetryPolicy retry = new RetryNTimes(3, 2000);
static {
// 创建Curator连接对象
connectCuratorClient();
}
/**
* <p>
* 创建Curator连接对象
* <p/>
*
* @param
* @return
*/
public static void connectCuratorClient() {
//老版本的方式,创建zookeeper连接客户端
/*client = CuratorFrameworkFactory.builder().
connectString(ZK_ADDRESS).
sessionTimeoutMs(5000).
connectionTimeoutMs(10000).
retryPolicy(retry).
build();*/
//创建zookeeper连接,新版本
client = CuratorFrameworkFactory.newClient(ZK_ADDRESS, retry);
//启动客户端(Start the client. Most mutator methods will not work until the client is started)
client.start();
System.out.println("zookeeper初始化连接成功:" + client);
}
public static void main(String[] args) throws Exception {
//创建节点
//createNode(ROOT_NODE, null);
//createNode(ROOT_NODE_CHILDREN, "child data");
//获取节点数据
getNode(ROOT_NODE);
//设置(修改)节点数据
updateNode(ROOT_NODE, "update curator data");
//异步设置某个节点数据
updateNode(ROOT_NODE, "update curator data with Async");
//删除指定节点(这个在原生zk里面,是不能直接删除有子节点的数据的)
deleteNode(ROOT_NODE);
}
/**
* <p>
* 创建节点,并支持赋值数据内容
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void createNode(String nodePath, String data) throws Exception {
if (StringUtils.isEmpty(nodePath)) {
System.out.println("节点【" + nodePath + "】不能为空");
return;
}
//1、对节点是否存在进行判断,否则会报错:【NodeExistsException: KeeperErrorCode = NodeExists for /root】
Stat exists = client.checkExists().forPath(nodePath);
if (null != exists) {
System.out.println("节点【" + nodePath + "】已存在,不能新增");
return;
} else {
System.out.println(StringUtils.join("节点【", nodePath, "】不存在,可以新增节点!"));
}
//2、创建节点, curator客户端开发提供了Fluent风格的API,是一种流式编码方式,可以不断地点.点.调用api方法
//创建永久节点(默认就是持久化的)
//client.create().forPath(nodePath);
//3、手动指定节点的类型
/*client.create()
.withMode(CreateMode.PERSISTENT)
.forPath(nodePath);*/
//4、如果父节点不存在,创建当前节点的父节点
/*String node = client.create()
.creatingParentsIfNeeded()
.forPath(nodePath);
System.out.println(node);*/
//创建节点,并为当前节点赋值内容
if (StringUtils.isNotBlank(data)) {
//5、创建永久节点,并为当前节点赋值内容
/*client.create()
.forPath(nodePath, data.getBytes());*/
String node = client.create()
.creatingParentsIfNeeded()
.forPath(nodePath, data.getBytes());
System.out.println(node);
//6、创建永久有序节点
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(nodePath + "-sequential", data.getBytes());
//7、创建临时节点
client.create()
.withMode(CreateMode.EPHEMERAL)
.forPath(nodePath + "/temp", data.getBytes());
//8、创建临时有序节点
client.create()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(nodePath + "/temp-sequential", data.getBytes());
}
}
/**
* <p>
* 获取节点数据
* <p/>
*
* @param nodePath
* @return void
*/
private static void getNode(String nodePath) throws Exception {
//获取某个节点数据
byte[] bytes = client.getData().forPath(nodePath);
System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes)));
//读取zookeeper的数据,并放到Stat中
Stat stat1 = new Stat();
byte[] bytes2 = client.getData().storingStatIn(stat1).forPath(nodePath);
System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes2)));
System.out.println(stat1);
//获取某个节点的所有子节点
List<String> stringList = client.getChildren().forPath(nodePath);
if (CollectionUtils.isEmpty(stringList)) {
return;
}
//遍历节点
stringList.forEach(System.out::println);
}
/**
* <p>
* 设置(修改)节点数据
* <p/>
*
* @param nodePath
* @param data
* @return void
*/
private static void updateNode(String nodePath, String data) throws Exception {
//更新节点
Stat stat = client.setData().forPath(nodePath, data.getBytes());
//指定版本号,更新节点,更新的时候如果指定数据版本的话,那么需要和zookeeper中当前数据的版本要一致,-1表示匹配任何版本
//Stat stat = client.setData().withVersion(-1).forPath(nodePath, data.getBytes());
System.out.println(stat);
//异步设置某个节点数据
Stat stat1 = client.setData().inBackground().forPath(nodePath, data.getBytes());
if (null != stat1) {
System.out.println(stat1);
}
}
/**
* <p>
* 删除指定节点
* <p/>
*
* @param nodePath
* @return void
*/
private static void deleteNode(String nodePath) throws Exception {
//删除节点
//client.delete().forPath(nodePath);
//删除节点,即使出现网络故障,zookeeper也可以保证删除该节点
//client.delete().guaranteed().forPath(nodePath);
//级联删除节点(如果当前节点有子节点,子节点也可以一同删除)
client.delete().deletingChildrenIfNeeded().forPath(nodePath);
}
}
