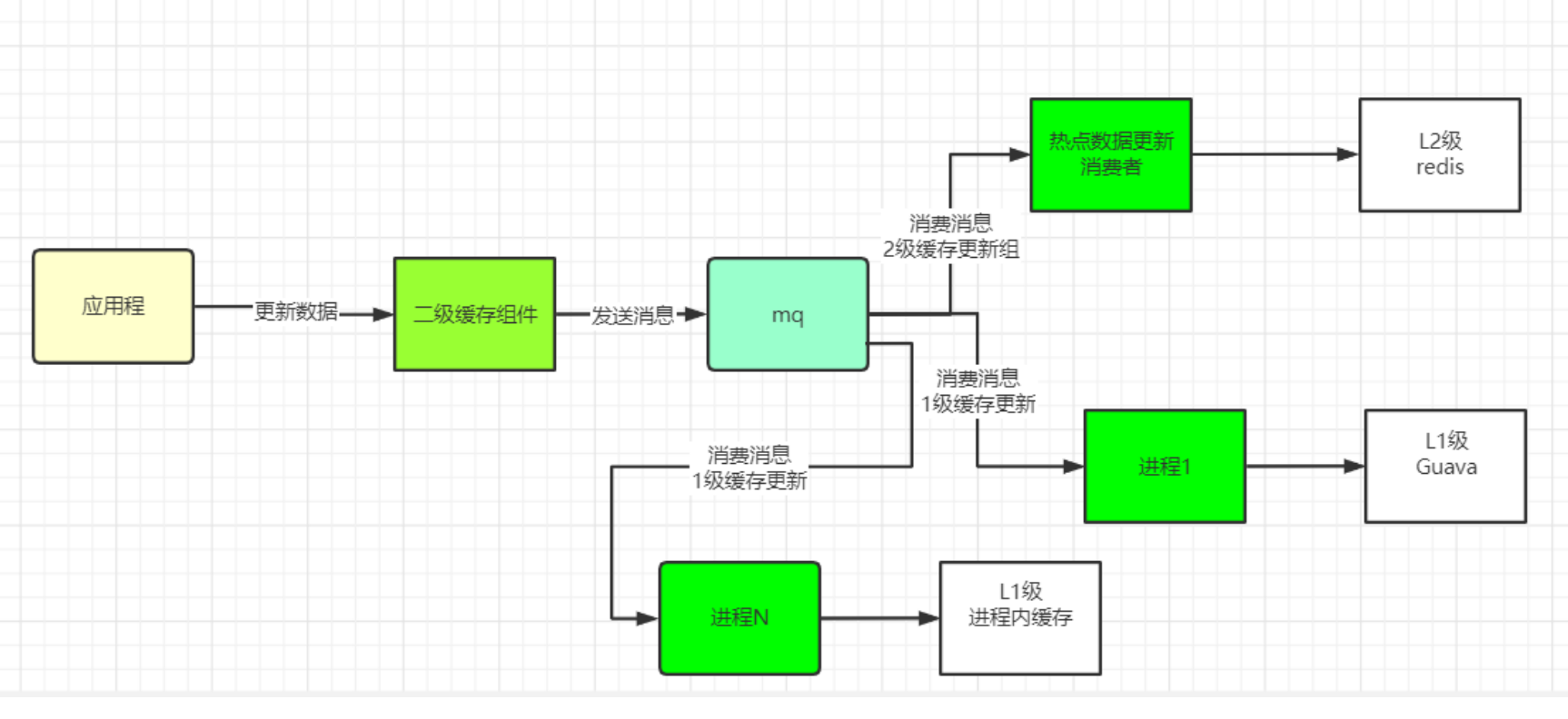
阅读完需:约 267 分钟
集群高可用常见的方式
- Replication-Sentinel模式
- Redis-Cluster模式
- 中心化代理模式(proxy模式)
Replication-Sentinel模式
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。
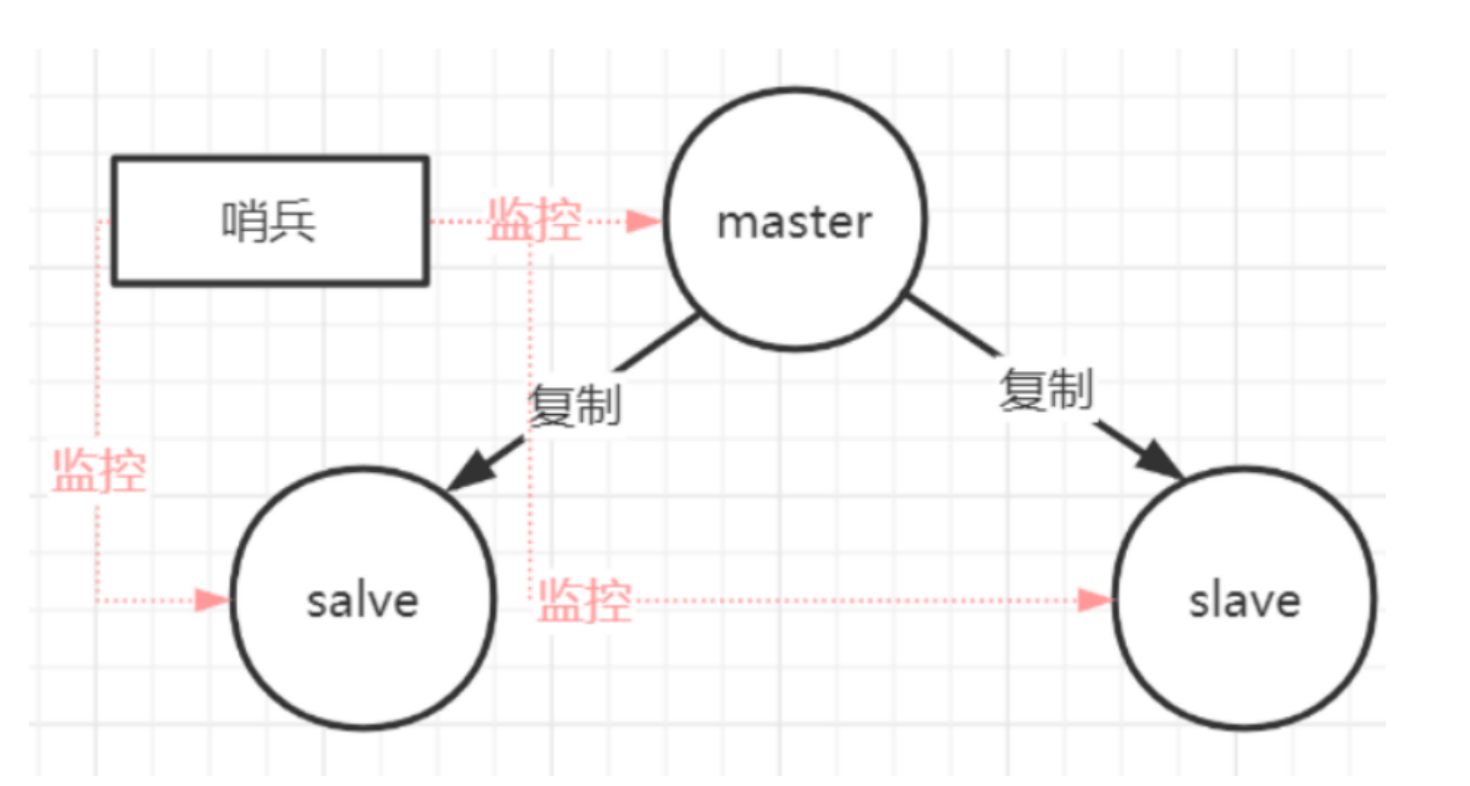
Redis sentinel 其中三个特性:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通 知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
哨兵本身也有单点故障的问题,可以使用多个哨兵进行监控,哨兵不仅会监控redis集群,哨兵之间也会相互监控。
每一个哨兵都是一个独立的进程,作为进程,它会独立运行
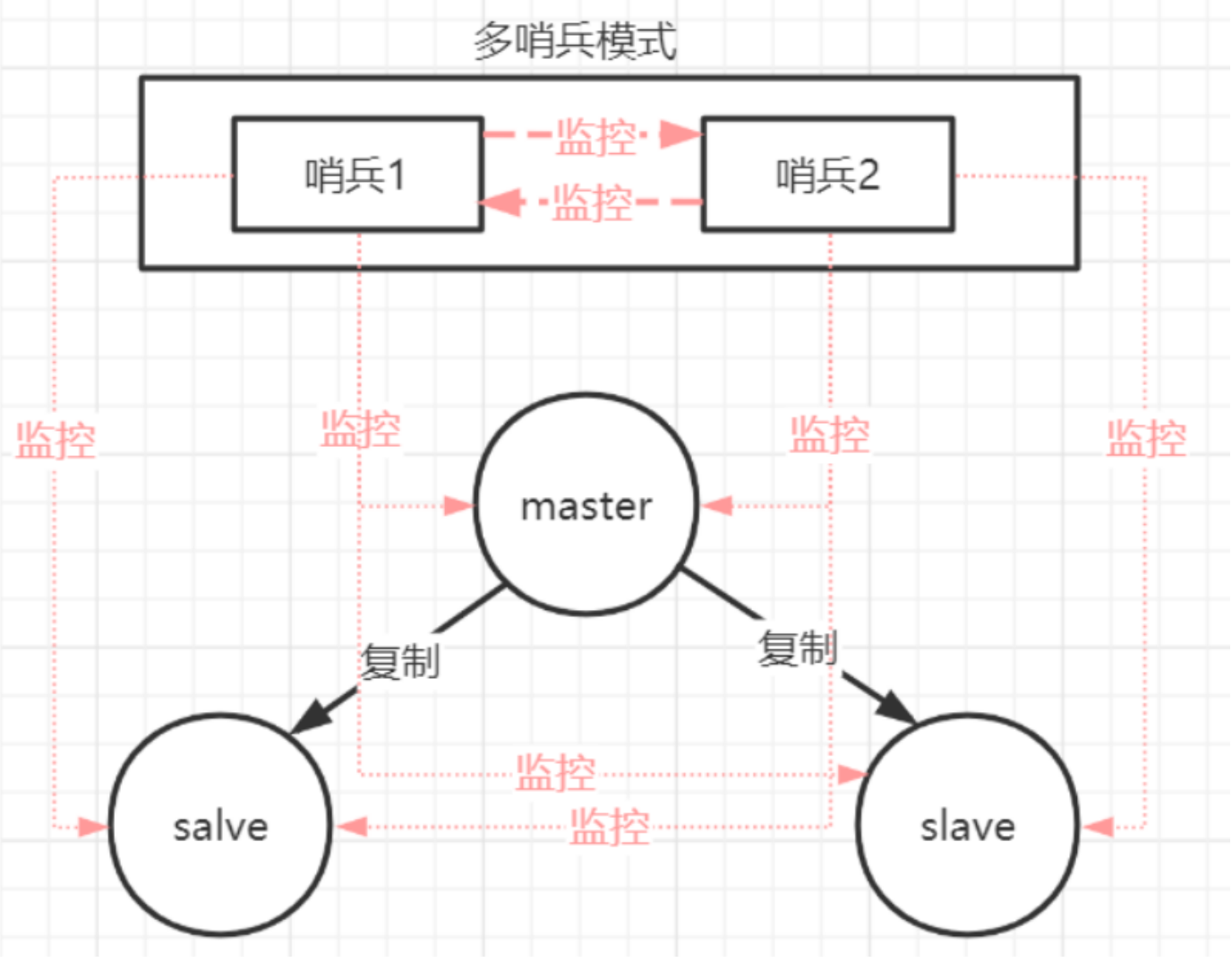
特点: 1、保证高可用 2、监控各个节点 3、自动故障迁移
缺点: 主从模式,切换需要时间丢数据,没有解决 master 写的压力
Redis-Cluster模式
redis在3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。
cluster模式为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受 限于单机,可受益于分布式集群高扩展性。
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。 相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成, 每个节点负责整个 集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相 互连接组成一个对等的集群, 它们之间通过一种特殊的二进制协议相互交互集群信息。
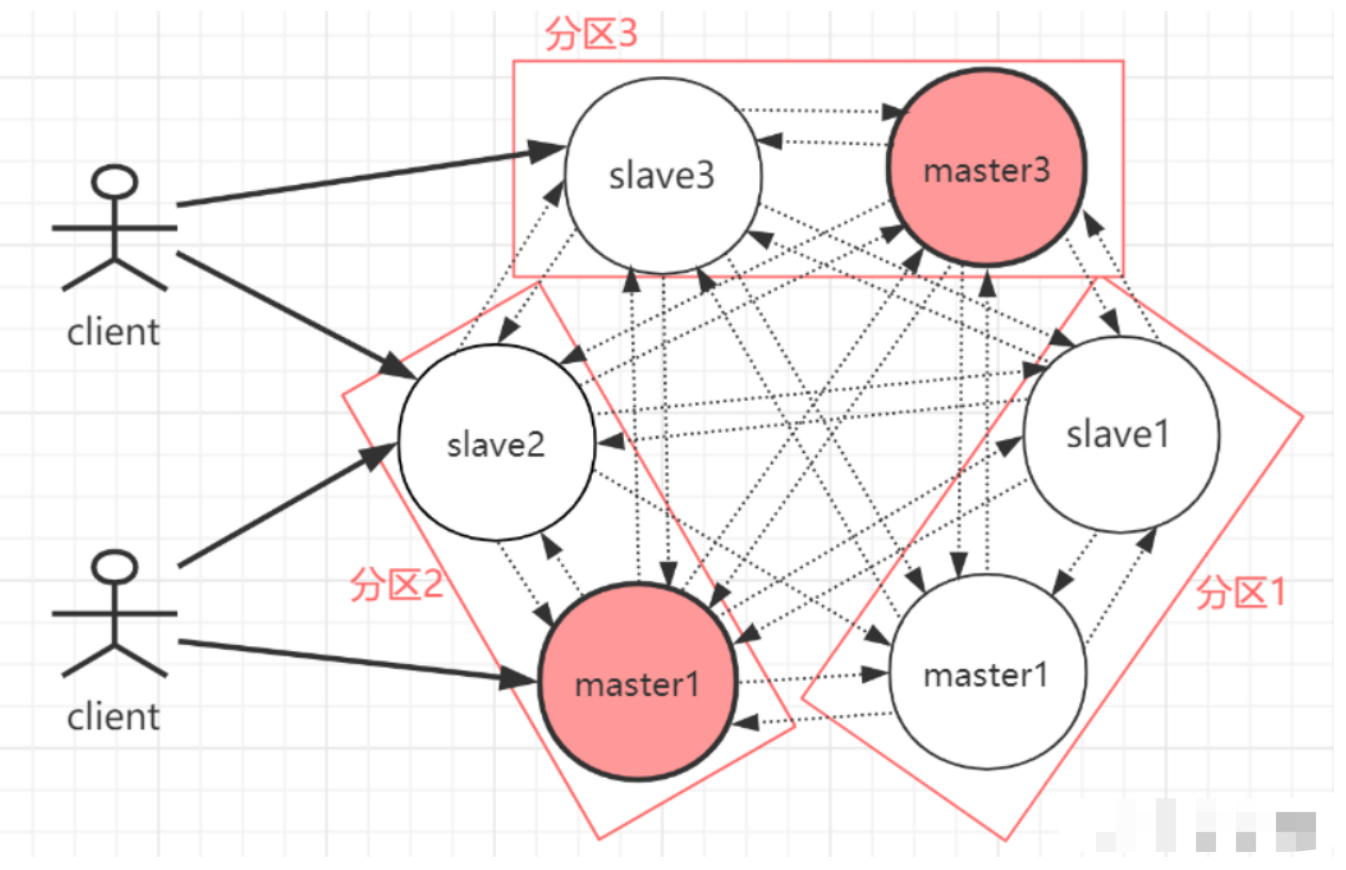
如上图,官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。
Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分得更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不需要另外的分布式存储来存储节点槽位信息。
Redis Cluster是一种服务器Sharding技术(分片和路由都是在服务端实现),采用多主多从,每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。 Redis Cluster集群采用了P2P的模式,完全去中心化。
3 主 3 从六个节点的Redis集群(Redis-Cluster)
Redis 集群是一个提供在多个Redis节点间共享数据的程序集。
下图以三个master节点和三个slave节点作为示例。
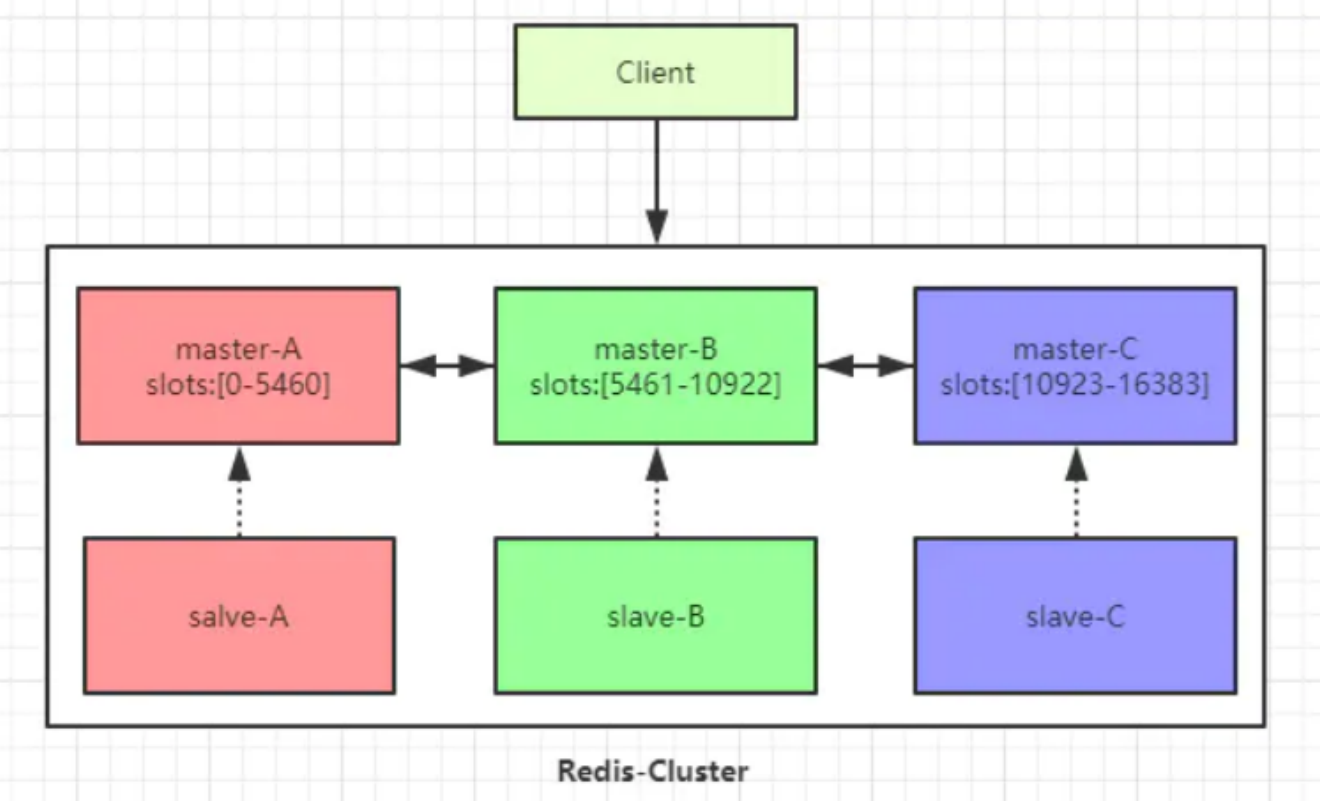
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。
集群的每个节点负责一部分hash槽,如图中slots所示。
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模 型,每个节点都会有1-n个从节点。
例如master-A节点不可用了,集群便会选举slave-A节点作为新的主节点继续服务。
中心化代理模式(proxy模式)
这种方案,将分片工作交给专门的代理程序来做。
代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的 Redis 实例并返回给业务程序。
其基本原理是:通过中间件的形式,Redis客户端把请求发送到代理 proxy,代理 proxy 根据路由 规则发送到正确的Redis实例,最后 代理 proxy 把结果汇集返回给客户端。
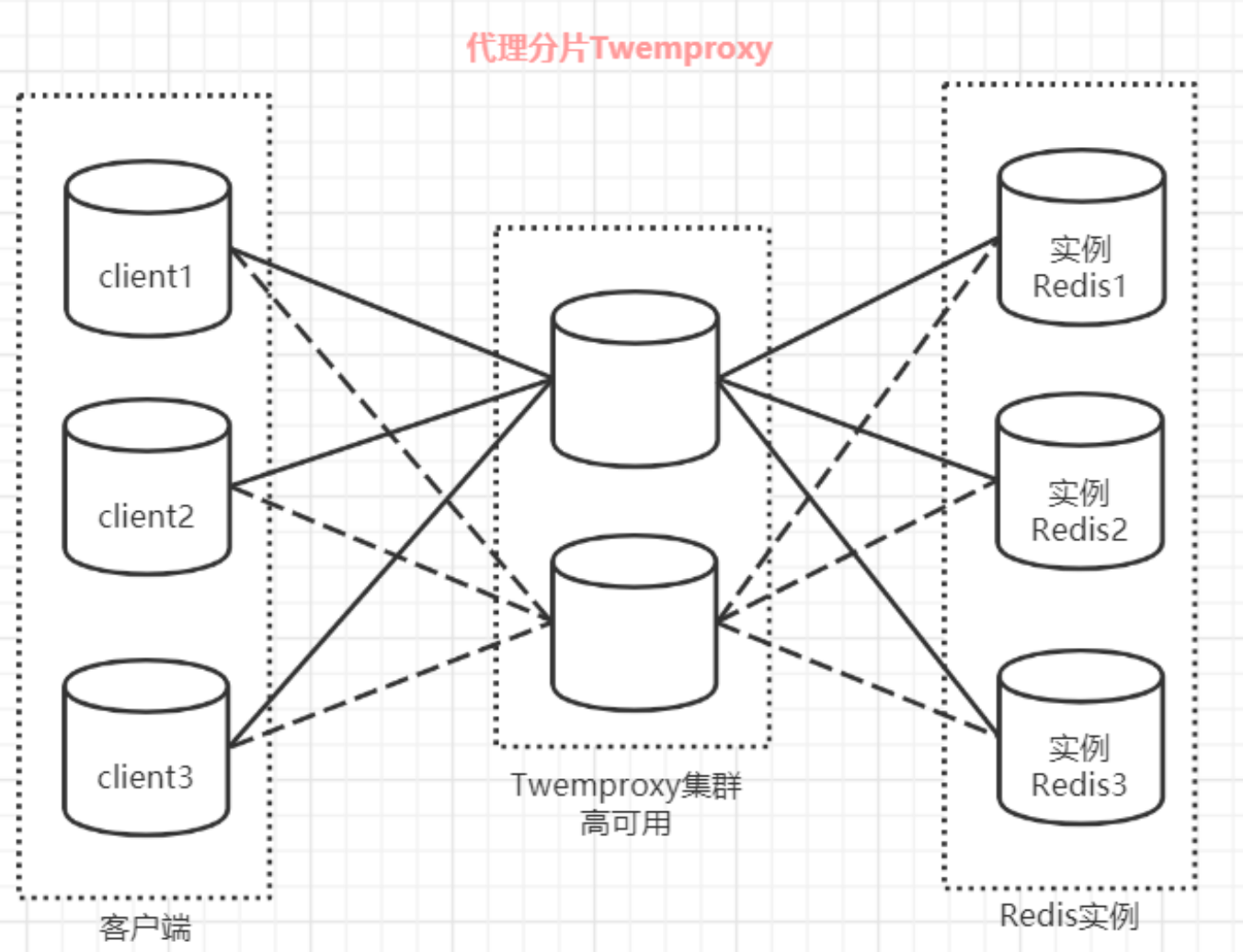
redis代理分片用得最多的就是Twemproxy,由Twitter开源的Redis代理,其基本原理是:通过中间件的 形式,Redis客户端把请求发送到Twemproxy,Twemproxy根据路由规则发送到正确的Redis实例,最后Twemproxy把结果汇集返回给客户端。
这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个 Redis 实例,所以这类 程序又称为分布式中间件。 这样的好处是,业务程序不用关心后端 Redis 实例,运维起来也方便。虽然会因此带来些性能损耗,但对于 Redis 这种内存读写型应用,相对而言是能容忍的。
Twemproxy 代理分片
Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
Twemproxy是由Twitter开源的集群化方案,它既可以做Redis Proxy,还可以做Memcached Proxy。
它的功能比较单一,只实现了请求路由转发,没有像Codis那么全面有在线扩容的功能,它解决的重点就 是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理。
Tweproxy推出的时间最久,在早期没有好的服务端分片集群方案时,应用范围很广,而且性能也极其稳 定。 但它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便,而且也没有友好的运维UI可以使用。
Codis代理分片
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别 (有一些命令不支持), 上层应用可以像 使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事 情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务, 现在美团、阿里等大厂已经开始用codis的集群功能了
什么是Codis?
Twemproxy不能平滑增加Redis实例的问题带来了很大的不便,于是豌豆荚自主研发了Codis,一 个支持平滑增加Redis实例的Redis代理软件,其基于Go和C语言开发,并于2014年11月在GitHub 上开源 codis开源地址 。
Codis的架构图:
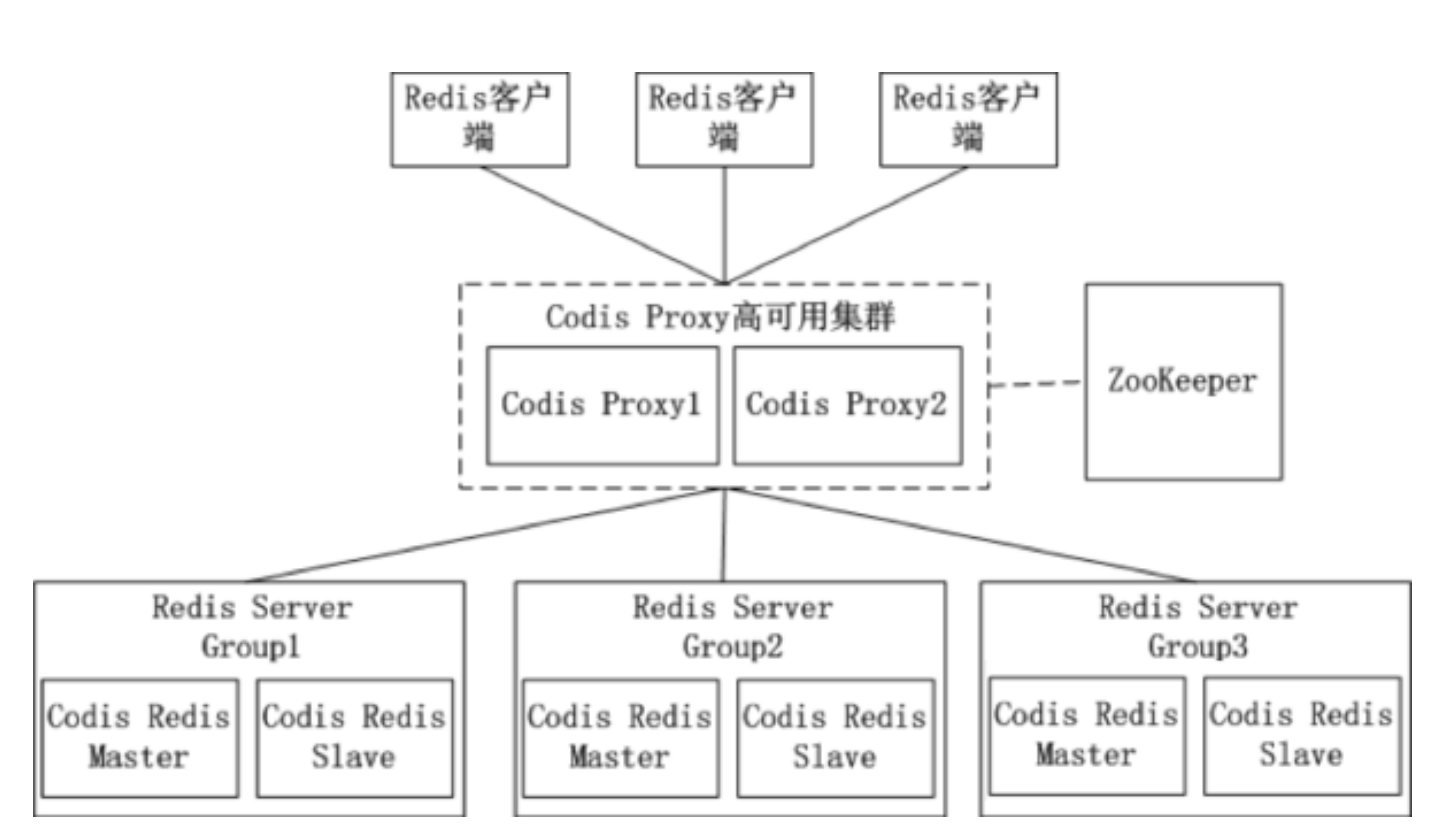
在Codis的架构图中,Codis引入了Redis Server Group,其通过指定一个主CodisRedis和一个或多个从 CodisRedis,实现了Redis集群的高可用。
当一个主CodisRedis挂掉时,Codis不会自动把一个从CodisRedis提升为主CodisRedis,这涉及数据的 一致性问题(Redis本身的数据同步是采用主从异步复制,当数据在主CodisRedis写入成功时,从 CodisRedis是否已读入这个数据是没法保证的),需要管理员在管理界面上手动把从CodisRedis提升为 主CodisRedis。
如果手动处理觉得麻烦,豌豆荚也提供了一个工具Codis-ha,这个工具会在检测到主CodisRedis挂掉的 时候将其下线并提升一个从CodisRedis为主CodisRedis。
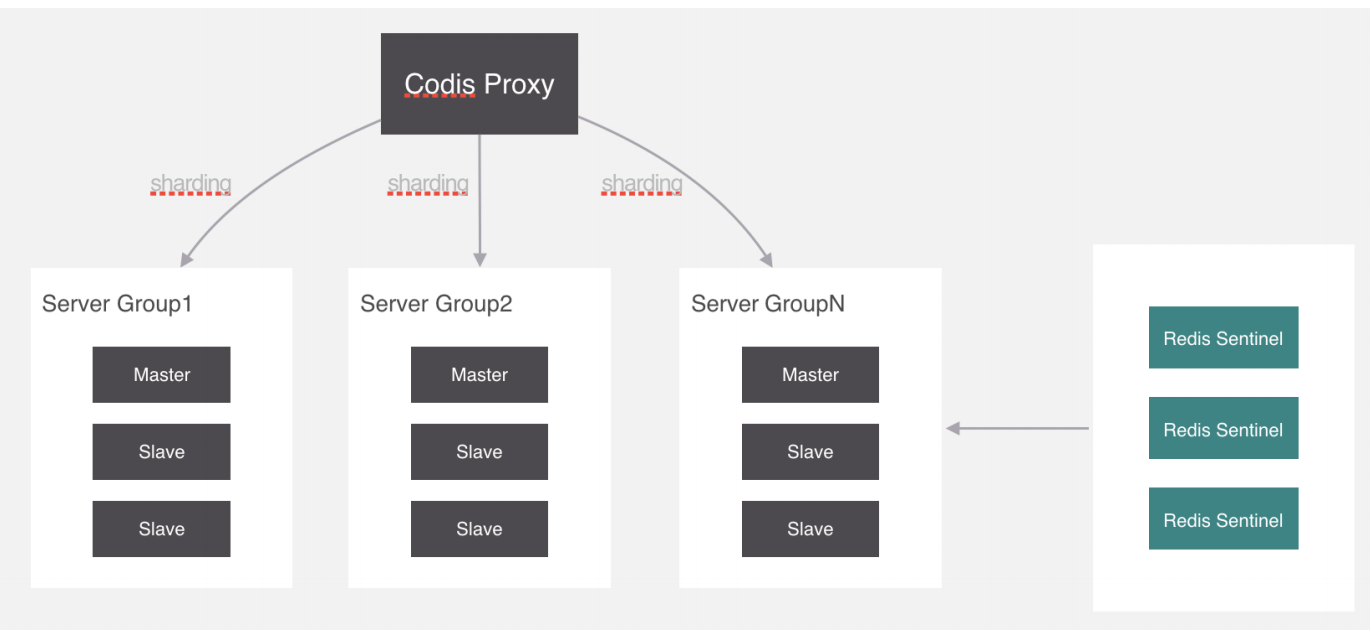
Codis的预分片
Codis中采用预分片的形式,启动的时候就创建了1024个slot,1个slot相当于1个箱子,每个箱子有固定 的编号,范围是1~1024。
Codis的分片算法
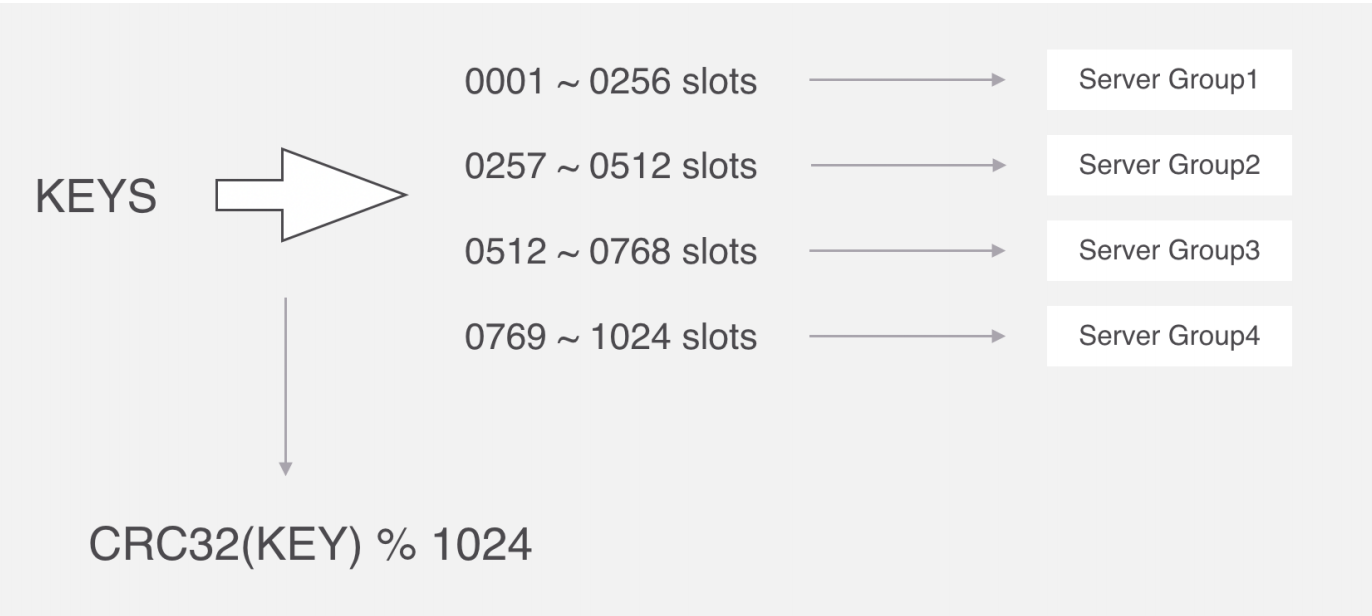
Codis proxy 代理通过一种算法把要操作的key经过计算后分配到各个组中,这个过程叫做分片。
在Codis里面,它把所有的key分为1024个槽,每一个槽位都对应了一个分组,具体槽位的分配,可以 进行自定义,现在如果有一个key进来,首先要根据CRC32算法,针对key算出32位的哈希值,然后除以 1024取余,然后就能算出这个KEY属于哪个槽,然后根据槽与分组的映射关系,就能去对应的分组当中 处理数据了。
CRC全称是循环冗余校验,主要在数据存储和通信领域保证数据正确性的校验手段,CRC校验(循 环冗余校验)是数据通讯中最常采用的校验方式。
slot这个箱子用作存放Key,至于Key存放到哪个箱子,可以通过算法“crc32(key)%1024”获得一个数字, 这个数字的范围一定是1~1024之间,Key就放到这个数字对应的slot。
例如,如果某个Key通过算法“crc32(key)%1024”得到的数字是5,就放到编码为5的slot(箱子)。
slot和Server Group的关系
1个slot只能放1个Redis Server Group,不能把1个slot放到多个Redis Server Group中。1个Redis Server Group最少可以存放1个slot,最大可以存放1024个slot。
因此,Codis中最多可以指定1024个Redis Server Group。
槽位和分组的映射关系就保存在codis proxy当中
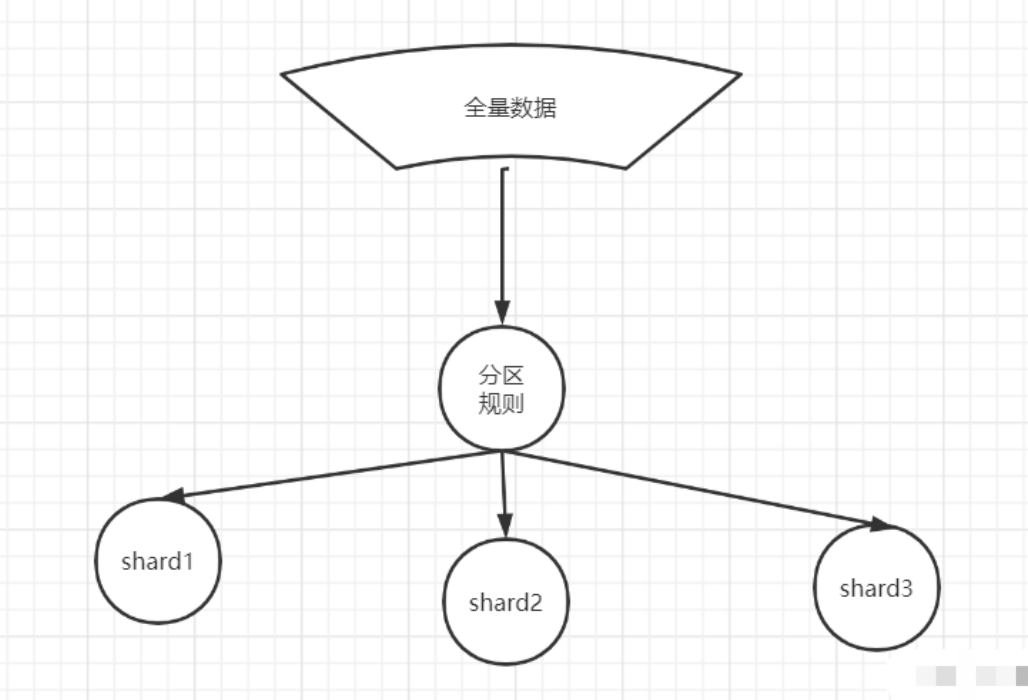
数据分片(sharding)的基本原理
什么是数据分片?
名词说明: 数据分片(sharding)也叫数据分区
为什么要做数据分片?
全量数据较大的场景下,单节点无法满足要求,需要数据分片
什么是数据分片?
按照分片规则把数据分到若干个shard、partition当中
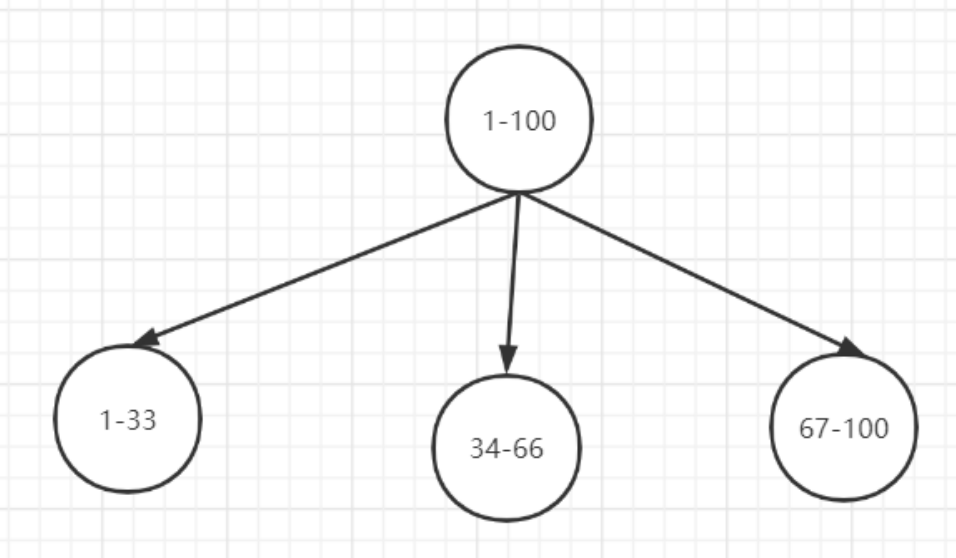
range 范围分片
一种是按照 range 来分,就是每个片,一段连续的数据,这个一般是按比如时间范围/数据范围来的, 但是这种一般较少用,因为很容易发生数据倾斜,大量的流量都打在最新的数据上了。
比如,安装数据范围分片,把1到100个数字,要保存在3个节点上 按照顺序分片,把数据平均分配三个节点上
- 1号到33号数据保存到节点1上
- 34号到66号数据保存到节点2上
- 67号到100号数据保存到节点3上
ID(key)取模分片
此种分片规则将数据分成n份(通常dn节点也为n),从而将数据均匀的分布于各个表中,或者各节点 上。 扩容方便。
ID取模分片常用在关系型数据库的设计
hash 哈希分片
使用hash 算法,获取key的哈希结果,再按照规则进行分片,这样可以保证数据被打散,同时保证数据分布的比较均匀
哈希分布方式分为三个分片方式:
- 哈希取模分片
- 一致性哈希分片
- 虚拟槽分片
哈希取余模分片
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为 1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上
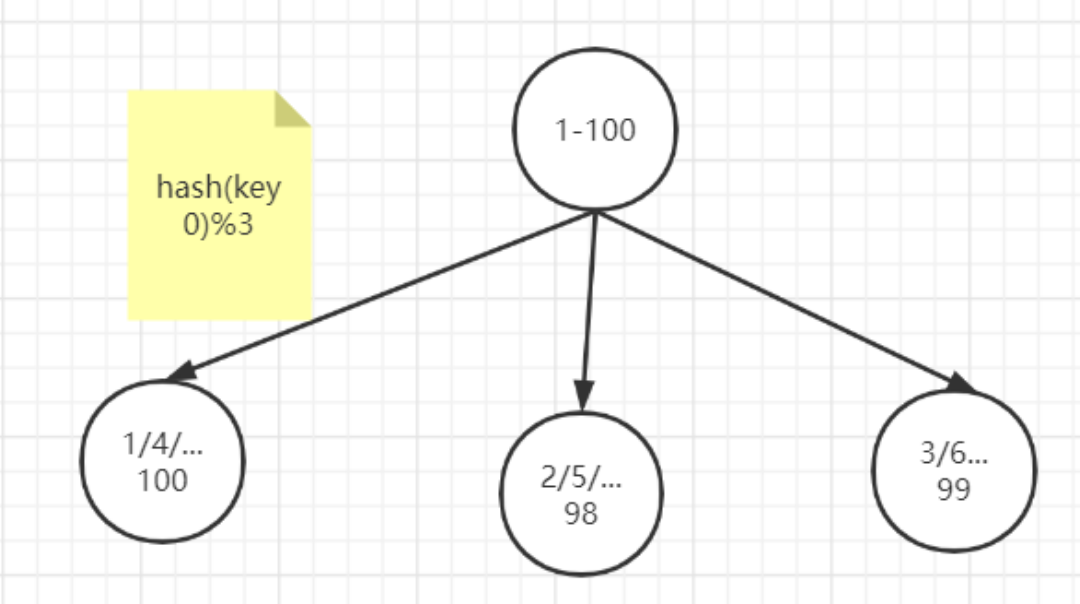
哈希取余分片是非常简单的一种分片方式
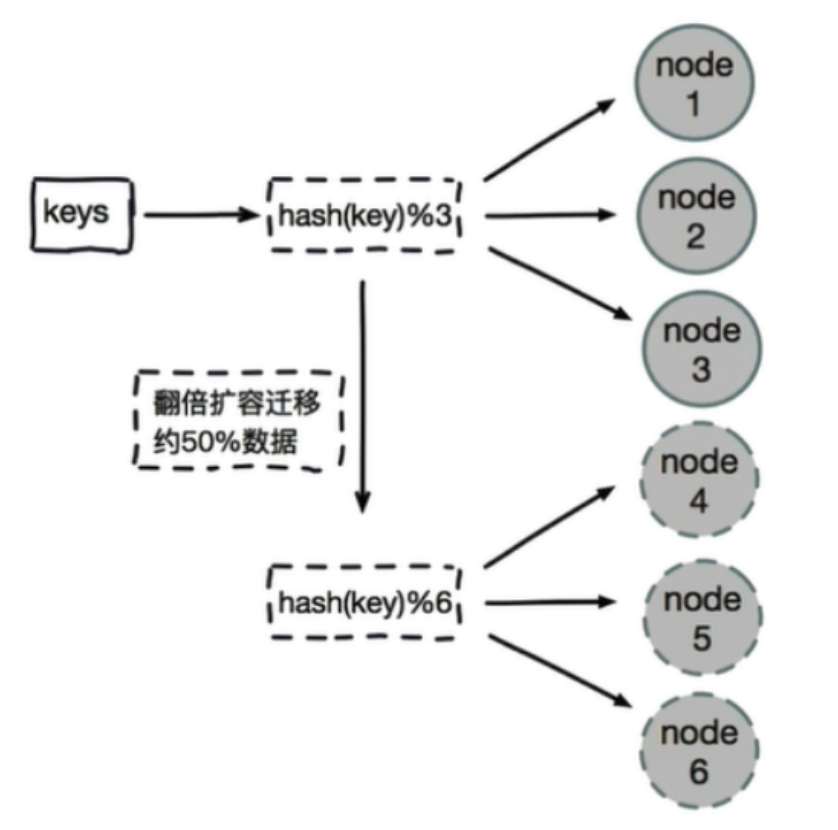
哈希取模分片有一个问题
即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分布
哈希取余分片,建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即 6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据
哈希取余分片优点:
- 配置简单:对数据进行哈希,然后取余
哈希取余分片缺点:
- 数据节点伸缩时,导致数据迁移
- 迁移数量和添加节点数据有关,建议翻倍扩容
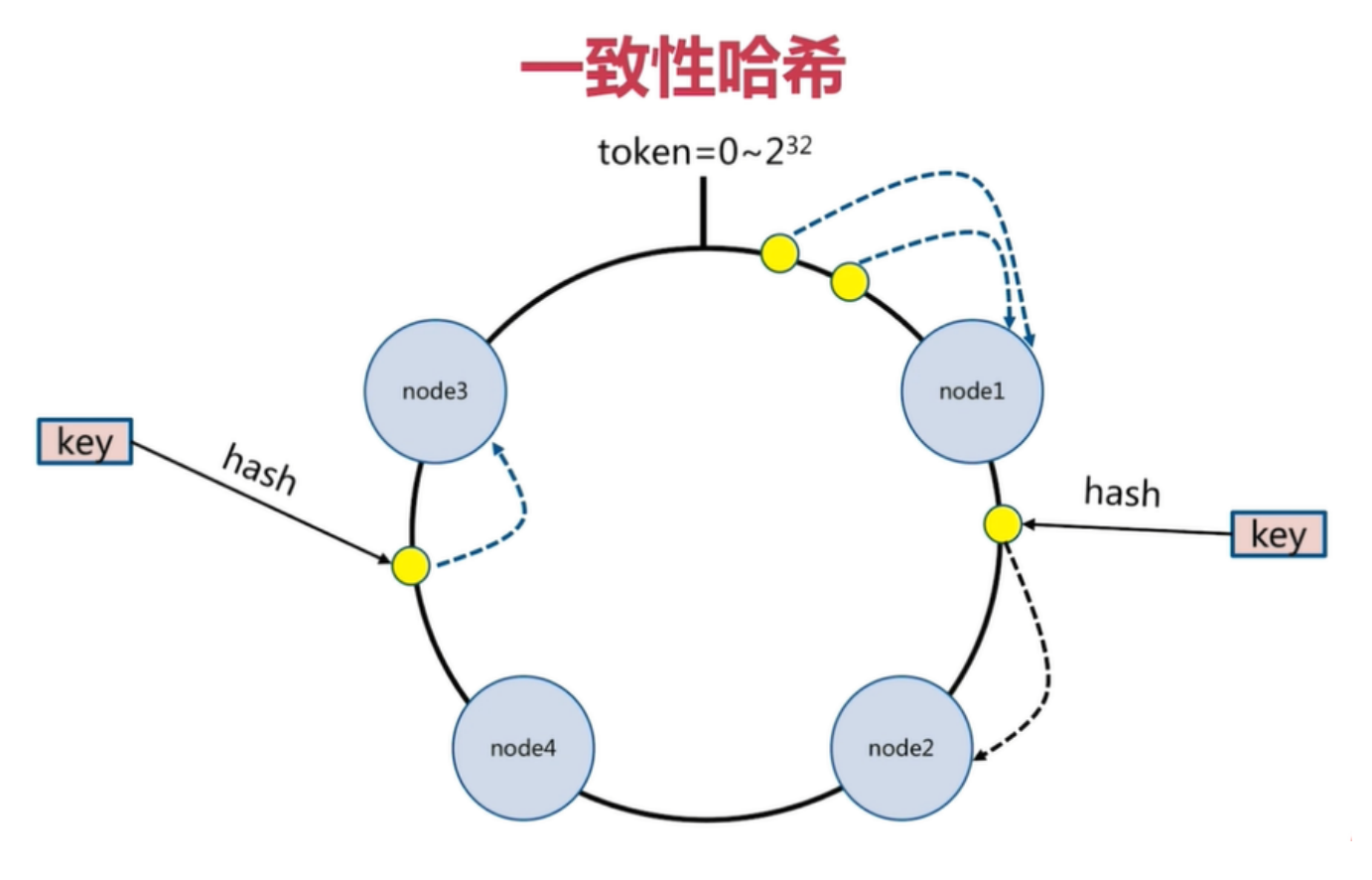
一致性哈希分片
一致性哈希原理:
将所有的数据当做一个token环, token环中的数据范围是0到2的32次方。 然后为每一个数据节点分配一个token范围值,这个节点就负责保存这个范围内的数据。
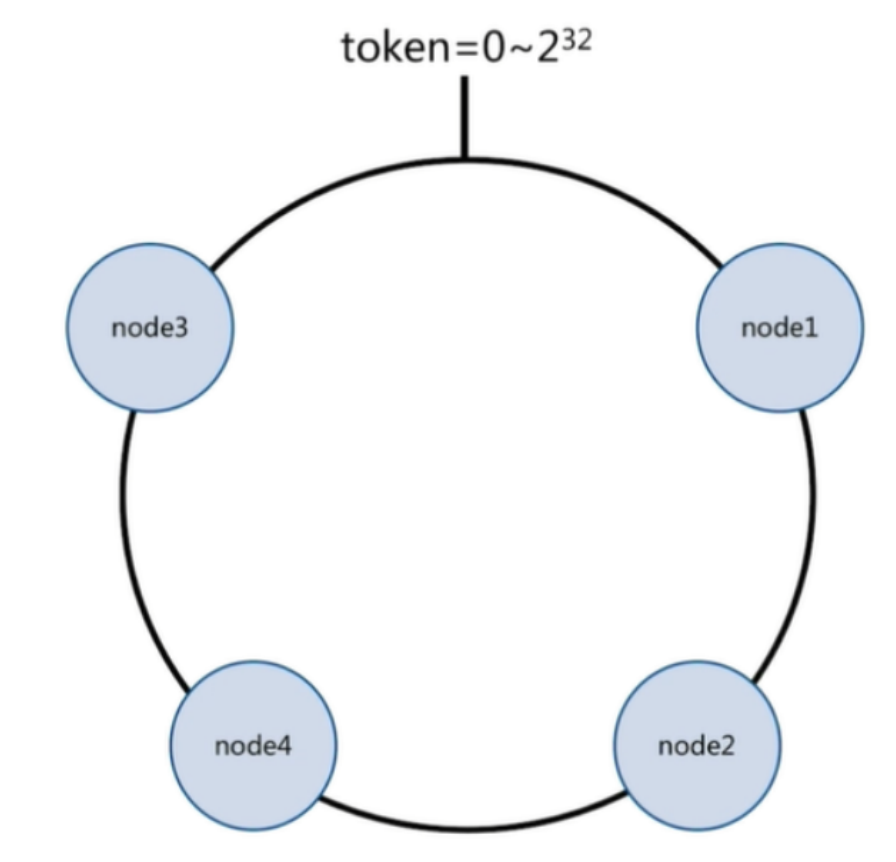
对每一个key进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个 key将会被保存在这个节点上。
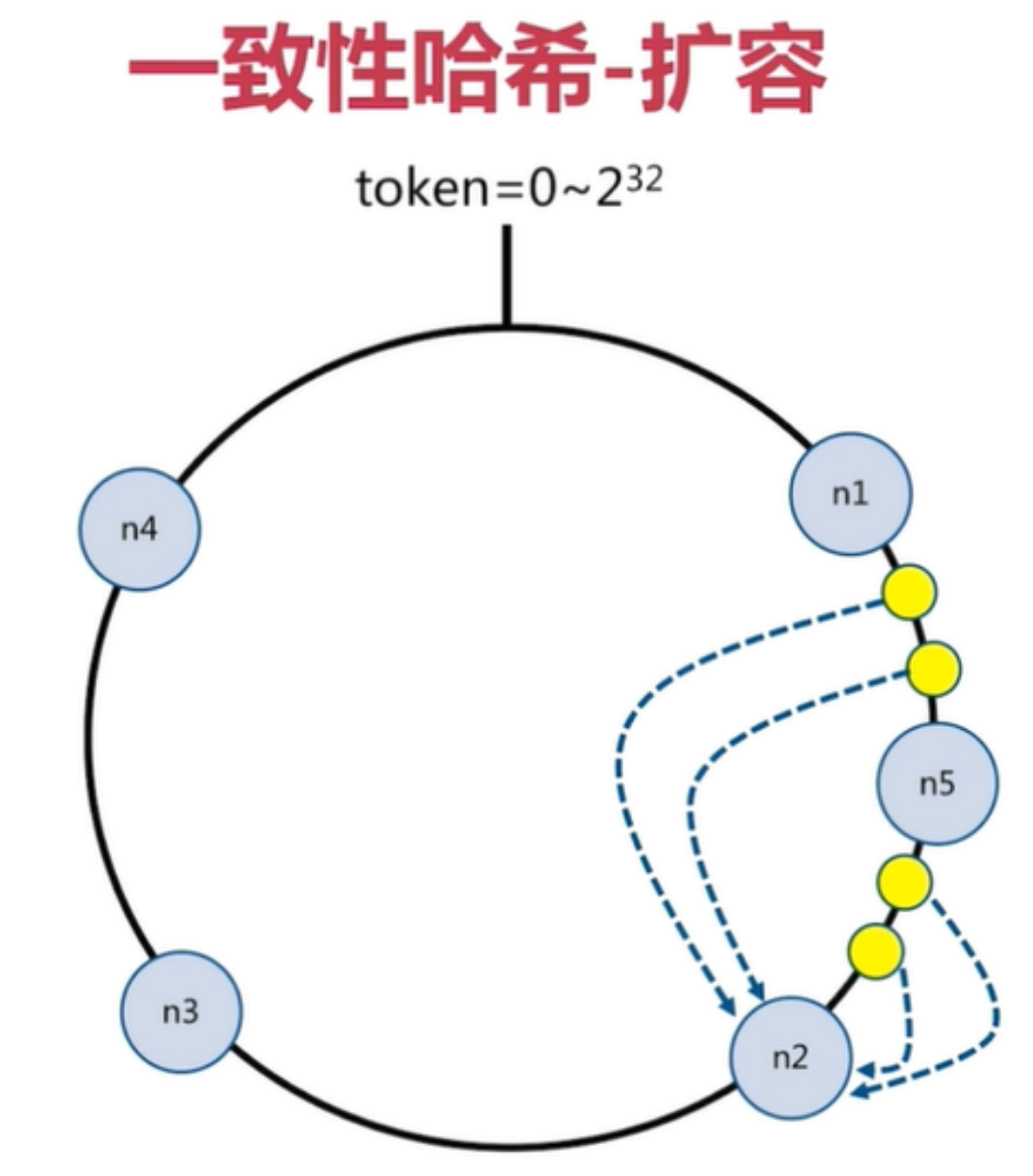
一致性哈希分片的节点扩容
在下面的图中:
- 有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2 节点上
- 如果在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间, 这些key就会被保存在n5节点上面了
下图的例子里,添加n5节点之后: 数据迁移会在n1节点和n2节点之间进行 n3节点和n4节点不受影响 数据迁移范围被缩小很多
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2。所以,一致性哈 希一般用在节点比较多的时候,节点越多,扩容时受影响的节点范围越少
分片方式:哈希 + 顺时针(优化取余)
一致性哈希分片优点:
- 一致性哈希算法解决了分布式下数据分布问题。比如在缓存系统中,通过一致性哈希算法把缓存键 映射到不同的节点上,由于算法中虚拟节点的存在,哈希结果一般情况下比较均匀。
- 节点伸缩时,只影响邻近节点,但是还是有数据迁移
一致性哈希分片缺点:
一致性哈希在大批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内
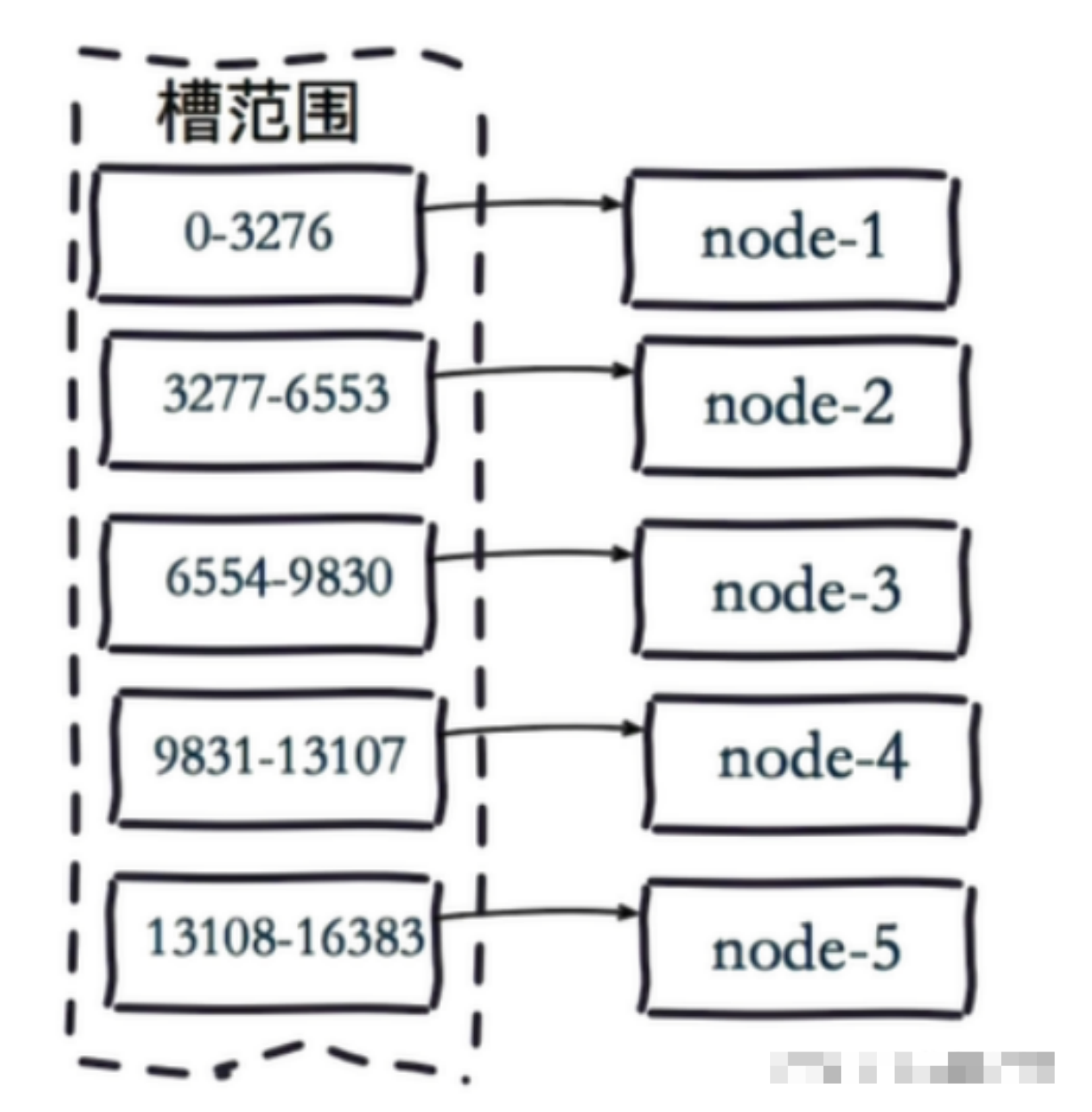
虚拟槽分片 (范围分片的变种)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈 希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式. 虚拟槽分片 ,可以理解为范围分片的变种, hash取模分片+范围分片, 把hash值取余数分为n段,一个段给一个节点负责某个节点完全空闲的情况出现。
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式. 在该分片方式中:
- 首先预设虚拟槽,每个槽为一个hash值,每个node负责一定槽范围。
- 每一个值都是key的hash值取余,每个槽映射一个数据子集,一般比节点数大
Redis Cluster中预设虚拟槽的范围为0到16383
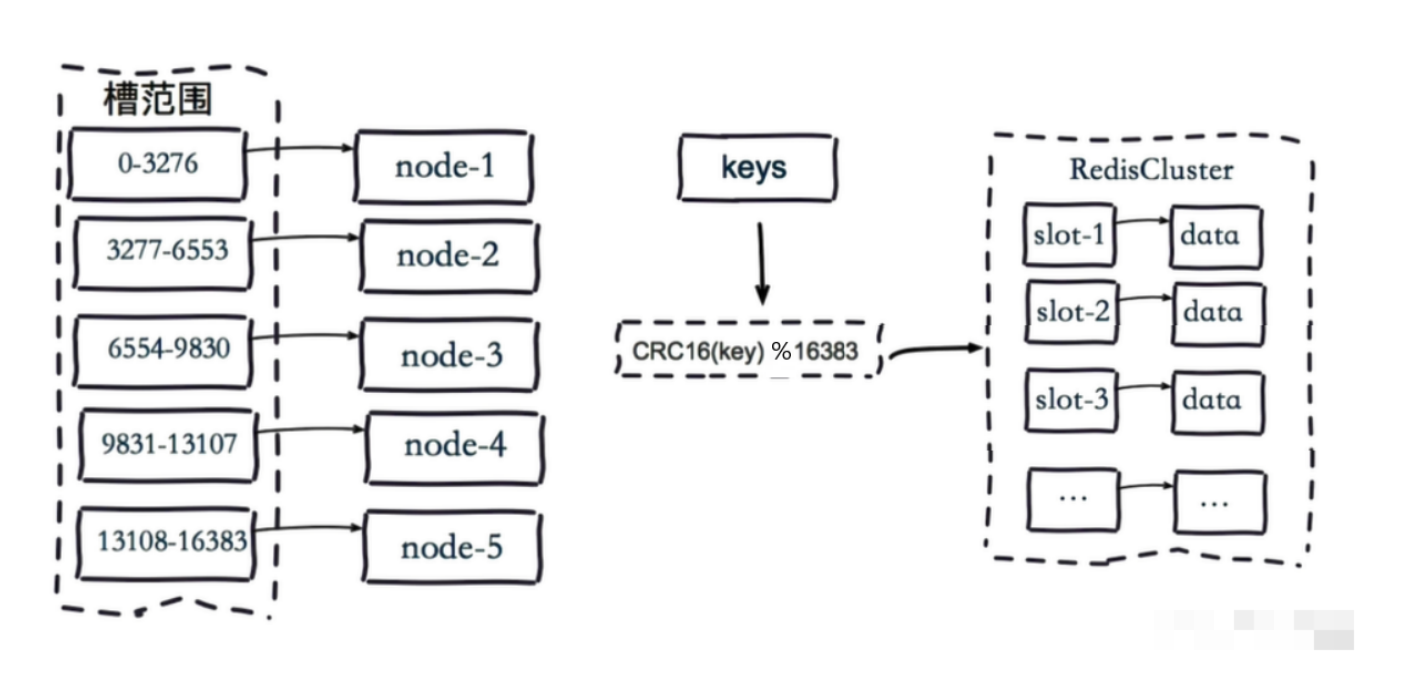
虚拟槽分片的映射步骤:
- 把16384槽按照节点数量进行平均分配,由节点进行管理
- 对每个key按照CRC16规则进行hash运算
- 把hash结果对16383进行取余
- 把余数发送给Redis节点
- 节点接收到数据,验证是否在自己管理的槽编号的范围
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。
当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失
虚拟槽分片特点: 虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数 集合中,整数定义为槽(slot)。槽是集群内数据管理和迁移的基本单位。
槽的范围一般远远大于节点数,比如Redis Cluster槽范围是0~16383。 采用大范围槽的主要目的是为了方便数据拆分和集群扩展,每个节点会负责一定数量的槽。
Redis虚拟槽分区的优点:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
- 支持节点、槽、键之间的映射查询,用于数据路由,在线伸缩等场景。
- 无论数据规模大,还是小,Redis虚拟槽分区各个节点的负载,都会比较均衡 。而一致性哈希在大 批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内某个节点完全空 闲的情况出现。
Redis集群如何高可用
要实现Redis高可用,前提条件之一,是需要进行Redis的节点集群
集群的必要性
所谓的集群,就是通过添加服务节点的数量,不同的节点提供相同的服务,从而让服务器达到高可 用、自动failover的状态。
面试题:单个redis节点,面临哪些问题?
- 单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
- 单个redis的读写能力是有限的。单机的 redis,能够承载的 QPS 大概就在上万到几万不等。
对于缓存来说,一般都是用来支撑读高并发、高可用。 单个redis节点,二者都做不到。
Redis集群模式的分类,可以从下面角度来分
- 客户端分片
- 代理分片
- 服务端分片
- 代理模式和服务端分片相结合的模式
客户端分片包括:
ShardedJedisPool
ShardedJedisPool是redis没有集群功能之前客户端实现的一个数据分布式方案, 使用shardedJedisPool实现redis集群部署,由于shardedJedisPool的原理是通过一致性哈希进行切片实现的,不同点key被分别分配到不同的redis实例上。
代理分片包括:
CodisTwemproxy
服务端分片包括:
Redis Cluster
从否中心化来划分
它们还可以用是否中心化来划分
- 无中心化的集群方案
其中客户端分片、Redis Cluster属于无中心化的集群方案
- 中心化的集群方案
Codis、Tweproxy属于中心化的集群方案。
是否中心化是指客户端访问多个Redis节点时,是直接访问还是通过一个中间层Proxy来进行操作,直接访问的就属于无中心化的方案,通过中间层Proxy访问的就属于中心化的方案,它们有各自的优劣,下面分别来介绍。
Docker方式部署redis-cluster集群搭建
这里引用了别人的一个镜像publicisworldwide/redis-cluster 还有一个是 nien/redis-trib
-
publicisworldwide/redis-clusterredis-cluster镜像 -
nien/redis-trib集群管理工具:自动执行节点握手,自动操作节点主从配置,自动给主节点分配 槽
redis-cluster的节点端口共分为2种
- 一种是节点提供服务的端口,如6379、6001;
- 一种是节点间通信的端口,固定格式为:10000+6379/10000+6001。
目前测试使用的是7001端口,那么对应的节点间通信的端口为17001
节点规划(三主三从)

创建内部网络
注意,首先创建 内部网络 创建普通的网络,即可
#创建网络,指定网段
docker network create ha-network-overlay
#查看网络
docker inspect ha-network-overlay配置redis的配置文件
daemonize no
port 7002
pidfile /var/run/redis.pid
dir "/data"
logfile "/data/redis.log"
#启动集群模式
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
#bind 192.168.56.121
#关闭保护模式
protected-mode no
#开启aof
appendonly yes
#默认60
repl-timeout 600
#默认10
repl-ping-replica-period 100
#如果要设置密码需要增加如下配置:
#requirepass 123321 #设置redis访问密码
#masterauth 123321 #设置集群节点间访问密码,跟上面一致后面需要创建6个redis实例,所以需要需要创建6份文件挂载到镜像中,这6份文件的端口号依次是7001 —— 7006,除了端口其他的不需要改变
- port:节点端口;
- requirepass:添加访问认证;
- masterauth:如果主节点开启了访问认证,从节点访问主节点需要认证;
- protected-mode:保护模式,默认值 yes,即开启。开启保护模式以后,需配置 bind ip 或者设置 访问密码;关闭保护模式,外部网络可以直接访问;
- daemonize:是否以守护线程的方式启动(后台启动),默认 no; 当redis.conf配置文件中daemonize参数设置的yes,这使得redis是以后台启动的方式运行的, 由于docker容器在启动时,需要任务在前台运行,否则会启动后立即退出, 因此导致redis容器启动后立即退出问题。 所以redis.conf中daemonize必须是no
- appendonly:是否开启 AOF 持久化模式,默认 no;
- logfile “/data/redis.log” 指定日志文件路径,默认值为 logfile ’ ‘, 默认为控制台打印,并没有日志文件生成
- bind 192.168.56.121(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许 客户端通 过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
- cluster-enabled:是否开启集群模式,默认 no;
- cluster-config-file:集群节点信息文件;
- cluster-node-timeout:集群节点连接超时时间;
- cluster-announce-ip:集群节点 IP,填写宿主机的 IP;
- cluster-announce-port:集群节点映射端口;
- cluster-announce-bus-port:集群节点总线端口。
每个 Redis 集群节点都需要打开两个 TCP 连接。一个用于为客户端提供服务的正常 Redis TCP 端口,例如 6379。还有一个基于 6379 端口加 10000 的端口,比如 16379。
第二个端口用于集群总线,这是一个使用二进制协议的节点到节点通信通道。节点使用集群总线进行故障检测、配置更新、故障转移授权等等。客户端永远不要尝试与集群总线端口通信,与正常的 Redis 命令端口通信即可,但是请确保防火墙中的这两个端口都已经打开,否则 Redis 集群节点将无法通信。
配置好redis文件后,需要再进行配置docker-compose文件来编排容器
version: '3'
services:
redis-cluster-01:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-01
restart: always
environment:
- REDIS_PORT=7001
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7001:7001
- 17001:17001
volumes:
- /root/data/7001/data:/data
- /root/data/7001/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis-cluster-02:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-02
restart: always
environment:
- REDIS_PORT=7002
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7002:7002
- 17002:17002
volumes:
- /root/data/7002/data:/data
- /root/data/7002/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis-cluster-03:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-03
restart: always
environment:
- REDIS_PORT=7003
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7003:7003
- 17003:17003
volumes:
- /root/data/7003/data:/data
- /root/data/7003/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis-cluster-04:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-04
restart: always
environment:
- REDIS_PORT=7004
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7004:7004
- 17004:17004
volumes:
- /root/data/7004/data:/data
- /root/data/7004/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis-cluster-05:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-05
restart: always
environment:
- REDIS_PORT=7005
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7005:7005
- 17005:17005
volumes:
- /root/data/7005/data:/data
- /root/data/7005/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis-cluster-06:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-06
restart: always
environment:
- REDIS_PORT=7006
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7006:7006
- 17006:17006
volumes:
- /root/data/7006/data:/data
- /root/data/7006/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
networks:
default:
external:
name: ha-network-overlay
最后在服务器上的文件配置
值得注意的是7001——7006的文件夹里是redis的配置文件,需要与docker-compose里的挂载路径对应才行
启动服务redis集群
docker-compose up -d
建立redis集群
当redis的6个实例启动后,它们之间目前是独立的,需要将6个实例组成一个集群
使用redis-trib.rb创建redis 集群
上面只是启动了6个redis容器,并没有设置集群,通过下面的命令可以设置集群。 使用 redis-trib.rb create 命令完成节点握手和槽分配过程
这里是通过这个容器去创建而已,创建完成后这个容器就会被删除
docker run --rm -it nien/redis-trib create --replicas 1 hostip:6001 hostip:6002
hostip:6003 hostip:6004 hostip:6005 hostip:6006
#hostip 换成 主机的ip
docker run --rm -it nien/redis-trib create --replicas 1 82.157.173.74:7001 82.157.173.74:7002 82.157.173.74:7003 82.157.173.74:7004 82.157.173.74:7005 82.157.173.74:7006- docker run: 运行一个新的容器。
- –rm: 容器停止后自动删除容器。
- -it: 使用交互式终端模式运行容器。
- nien/redis-trib: Redis 集群管理工具的镜像。
- create: 创建 Redis 集群。
- –replicas 1: 设置每个主节点的副本数量为 1。你可以根据需要调整这个值。
- 192.168.56.121:7001 192.168.56.121:7002 192.168.56.121:7003 192.168.56.121:7004 192.168.56.121:7005 192.168.56.121:7006: 指定 Redis 集群中的节点地址和端口。
redis-trib.rb 会尽可能保证主从节点不分配在同一机器下,因此会重新排序节点列表顺序。 节点列表顺序用于确定主从角色,先主节点之后是从节点。
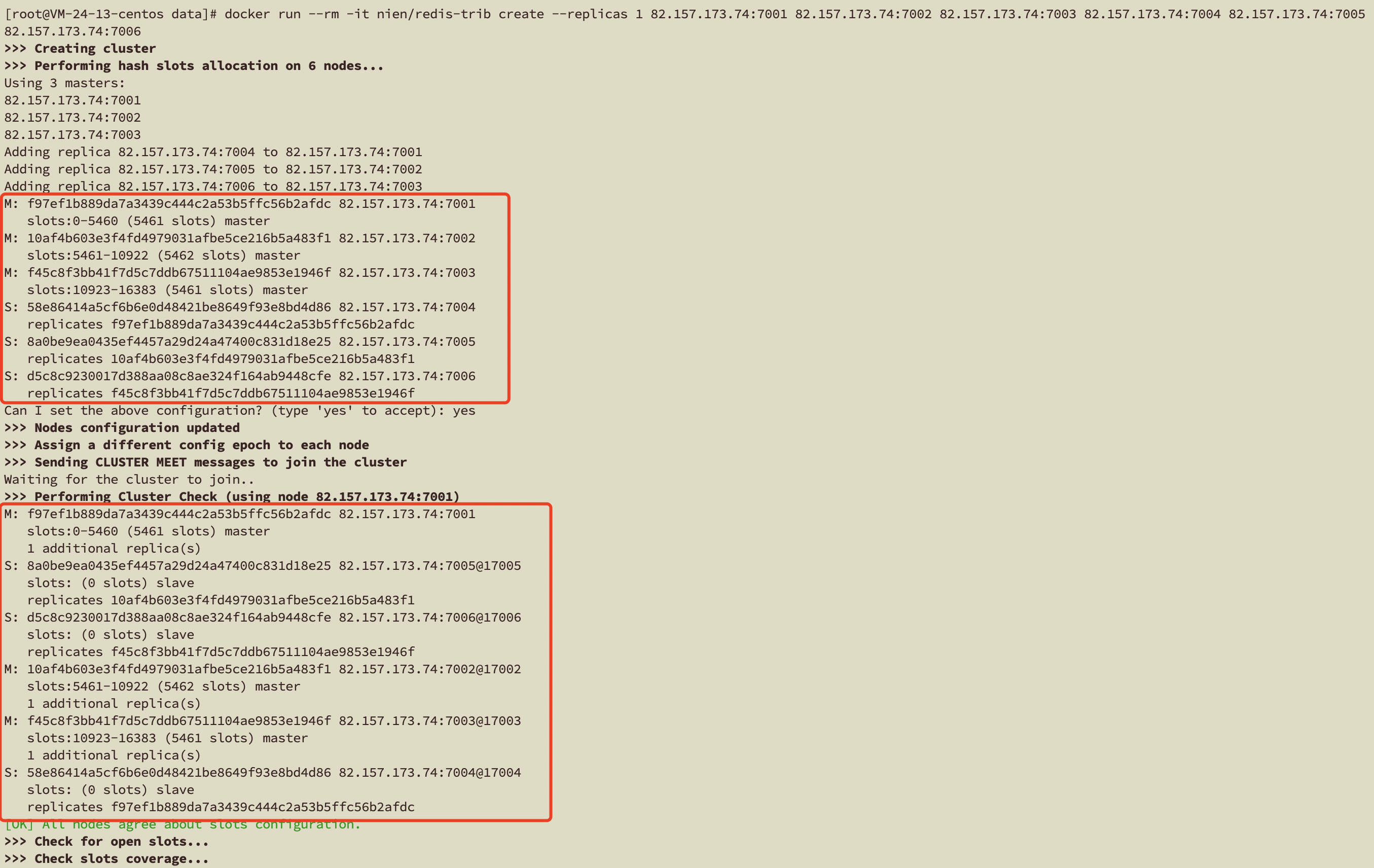
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib create --replicas 1 82.157.173.74:7001 82.157.173.74:7002 82.157.173.74:7003 82.157.173.74:7004 82.157.173.74:7005 82.157.173.74:7006
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
82.157.173.74:7001
82.157.173.74:7002
82.157.173.74:7003
Adding replica 82.157.173.74:7004 to 82.157.173.74:7001
Adding replica 82.157.173.74:7005 to 82.157.173.74:7002
Adding replica 82.157.173.74:7006 to 82.157.173.74:7003
M: f97ef1b889da7a3439c444c2a53b5ffc56b2afdc 82.157.173.74:7001
slots:0-5460 (5461 slots) master
M: 10af4b603e3f4fd4979031afbe5ce216b5a483f1 82.157.173.74:7002
slots:5461-10922 (5462 slots) master
M: f45c8f3bb41f7d5c7ddb67511104ae9853e1946f 82.157.173.74:7003
slots:10923-16383 (5461 slots) master
S: 58e86414a5cf6b6e0d48421be8649f93e8bd4d86 82.157.173.74:7004
replicates f97ef1b889da7a3439c444c2a53b5ffc56b2afdc
S: 8a0be9ea0435ef4457a29d24a47400c831d18e25 82.157.173.74:7005
replicates 10af4b603e3f4fd4979031afbe5ce216b5a483f1
S: d5c8c9230017d388aa08c8ae324f164ab9448cfe 82.157.173.74:7006
replicates f45c8f3bb41f7d5c7ddb67511104ae9853e1946f
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join..
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: f97ef1b889da7a3439c444c2a53b5ffc56b2afdc 82.157.173.74:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 8a0be9ea0435ef4457a29d24a47400c831d18e25 82.157.173.74:7005@17005
slots: (0 slots) slave
replicates 10af4b603e3f4fd4979031afbe5ce216b5a483f1
S: d5c8c9230017d388aa08c8ae324f164ab9448cfe 82.157.173.74:7006@17006
slots: (0 slots) slave
replicates f45c8f3bb41f7d5c7ddb67511104ae9853e1946f
M: 10af4b603e3f4fd4979031afbe5ce216b5a483f1 82.157.173.74:7002@17002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: f45c8f3bb41f7d5c7ddb67511104ae9853e1946f 82.157.173.74:7003@17003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 58e86414a5cf6b6e0d48421be8649f93e8bd4d86 82.157.173.74:7004@17004
slots: (0 slots) slave
replicates f97ef1b889da7a3439c444c2a53b5ffc56b2afdc
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.这里可以很明显的看出来3个主3个从节点已经搭建完毕
Adding replica 82.157.173.74:7004 to 82.157.173.74:7001
Adding replica 82.157.173.74:7005 to 82.157.173.74:7002
Adding replica 82.157.173.74:7006 to 82.157.173.74:7003
这里是各个主节点与从节点的对应关系,其中7001是对外可以连接的节点
这里在组成集群的时候就会去分配各个主节点的槽位
详解redis-trib.rb 的命令
# redis-trib.rb help
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN #创建集群
--replicas <arg> #从节点个数
check host:port #检查集群
info host:port #查看集群状态
fix host:port #修复集群
--timeout <arg>
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--from <arg>. #源节点id,如果有多个源节点,使用逗号分隔,如果是all,则源节点为集群内出目标节点外的其它所有主节点。
--to <arg> #目标节点id,只能填写一个。
--slots <arg> #需要迁移槽的总数量。
--yes #迁移无需用户手动确认。
--timeout <arg> #控制每次migrate操作的超时时间,默认为60000毫秒。
--pipeline <arg> #控制每次批量迁移键的数量,默认为10。
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--weight <arg> #节点的权重,格式为node_id=weight,如果需要为多个节点分配权重的话,需要添加多个--weight <arg>参数,即--weight b31e3a2e=5 --weight 60b8e3a1=5,node_id可为节点名称的前缀,只要保证前缀位数能唯一区分该节点即可。没有传递–weight的节点的权重默认为1。
--auto-weights #自动将每个节点的权重默认为1。如果--weight和--auto-weights同时指定,则--auto-weights会覆盖前者。
--use-empty-masters #默认没有分配slot节点的master是不参与rebalance的。如果要让其参与rebalance,需添加该参数。
--timeout <arg> #设置migrate命令的超时时间。
--simulate #设置该参数,只会提示用户会迁移哪些slots,而不会执行真正的迁移操作。
--pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
--threshold <arg> #只有节点需要迁移的slot阈值超过threshold,才会执行rebalance操作。
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--slave
--master-id <arg>
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
set-timeout host:port milliseconds #设置clusternode-timeout
call host:port command arg arg .. arg。 #在集群的所有节点执
行相关命令
import host:port #将外部redis数据导入集群
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.- create:创建集群
- check:检查集群
- info:查看集群信息
- fix:修复集群(可以修复的异常)
- 节点中存在处于迁移中(importing或migrating状态)的slot。
- 节点中存在未分配的slot。
- reshard:在线迁移slot
- rebalance:平衡集群节点slot数量
- add-node:添加新节点
- del-node:删除节点
- set-timeout:设置节点的超时时间
- call:在集群所有节点上执行命令
- import:将外部redis数据导入集群
进入容器内
docker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 7001
我们可以去测试基本的redis命令,比如获取 key1 的值

因为key1的槽值不在7001的节点里,会自动跳转到7002上去查询,所以当我们组成一个集群的时候,各自的节点会负责各自槽位值的内容
在容器内输入 info 可以查看该节点具体的信息
82.157.173.74:7002> info
# Server
redis_version:5.0.0
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:9a5fa86bdce33ad2
redis_mode:cluster
os:Linux 3.10.0-1160.11.1.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:6.3.0
process_id:1
run_id:b539f4cf9b7f7a536fa50614a94161f618b212e8
tcp_port:7002
uptime_in_seconds:79716
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:6308899
executable:/data/redis-server
config_file:/usr/local/etc/redis/redis.conf
# Clients
connected_clients:1
client_recent_max_input_buffer:2
client_recent_max_output_buffer:0
blocked_clients:0
# Memory
used_memory:2690792
used_memory_human:2.57M
used_memory_rss:3784704
used_memory_rss_human:3.61M
used_memory_peak:2690792
used_memory_peak_human:2.57M
used_memory_peak_perc:100.01%
used_memory_overhead:2597164
used_memory_startup:1449216
used_memory_dataset:93628
used_memory_dataset_perc:7.54%
allocator_allocated:2660232
allocator_active:2883584
allocator_resident:5443584
total_system_memory:3972997120
total_system_memory_human:3.70G
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.08
allocator_frag_bytes:223352
allocator_rss_ratio:1.89
allocator_rss_bytes:2560000
rss_overhead_ratio:0.70
rss_overhead_bytes:18446744073707892736
mem_fragmentation_ratio:1.45
mem_fragmentation_bytes:1176864
mem_not_counted_for_evict:0
mem_replication_backlog:1048576
mem_clients_slaves:49686
mem_clients_normal:49686
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1700733435
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:249856
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
aof_current_size:0
aof_base_size:0
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:0
# Stats
total_connections_received:13
total_commands_processed:74170
instantaneous_ops_per_sec:0
total_net_input_bytes:2794683
total_net_output_bytes:28982
instantaneous_input_kbps:0.02
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:1
sync_partial_ok:0
sync_partial_err:1
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
evicted_keys:0
keyspace_hits:0
keyspace_misses:1
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:161
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
# Replication
role:master
connected_slaves:1
slave0:ip=82.157.173.74,port=7005,state=online,offset=10374,lag=0
master_replid:e569a053b363d6814d893b17bfda0c5f890eb408
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:10374
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:10374
# CPU
used_cpu_sys:35.762987
used_cpu_user:35.631811
used_cpu_sys_children:0.002579
used_cpu_user_children:0.001809
# Cluster
cluster_enabled:1
# Keyspace通过客户端命令使用集群
检查集群状态
docker run --rm -it nien/redis-trib info 82.157.173.74:7001
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib info 82.157.173.74:7001
82.157.173.74:7001 (f97ef1b8...) -> 0 keys | 5461 slots | 1 slaves.
82.157.173.74:7002@17002 (10af4b60...) -> 0 keys | 5462 slots | 1 slaves.
82.157.173.74:7003@17003 (f45c8f3b...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.docker run --rm -it nien/redis-trib check 82.157.173.74:7001
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib check 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: f97ef1b889da7a3439c444c2a53b5ffc56b2afdc 82.157.173.74:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 8a0be9ea0435ef4457a29d24a47400c831d18e25 82.157.173.74:7005@17005
slots: (0 slots) slave
replicates 10af4b603e3f4fd4979031afbe5ce216b5a483f1
S: d5c8c9230017d388aa08c8ae324f164ab9448cfe 82.157.173.74:7006@17006
slots: (0 slots) slave
replicates f45c8f3bb41f7d5c7ddb67511104ae9853e1946f
M: 10af4b603e3f4fd4979031afbe5ce216b5a483f1 82.157.173.74:7002@17002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: f45c8f3bb41f7d5c7ddb67511104ae9853e1946f 82.157.173.74:7003@17003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: 58e86414a5cf6b6e0d48421be8649f93e8bd4d86 82.157.173.74:7004@17004
slots: (0 slots) slave
replicates f97ef1b889da7a3439c444c2a53b5ffc56b2afdc
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.平衡集群节点slot数量
docker run --rm -it nien/redis-trib rebalance 82.157.173.74:7001
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib rebalance 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.0% threshold.上面有关于客户端的其他命令使用方式
同时也可以进入容器内进行操作和查看
# 查看集群信息
cluster info
# 查看集群结点信息
cluster nodesdocker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 7001
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 7001
82.157.173.74:7001> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:437156
cluster_stats_messages_pong_sent:397535
cluster_stats_messages_sent:834691
cluster_stats_messages_ping_received:397530
cluster_stats_messages_pong_received:437156
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:834691cluster info 与之前的 info 所查看的信息是不一样的,前者是集群信息,后者是redis信息
查看redis节点信息,下面可以清晰的展示每个主节点对应的从节点
82.157.173.74:7001> cluster nodes
8a0be9ea0435ef4457a29d24a47400c831d18e25 82.157.173.74:7005@17005 slave 10af4b603e3f4fd4979031afbe5ce216b5a483f1 0 1701171967425 5 connected
d5c8c9230017d388aa08c8ae324f164ab9448cfe 82.157.173.74:7006@17006 slave f45c8f3bb41f7d5c7ddb67511104ae9853e1946f 0 1701171967000 6 connected
10af4b603e3f4fd4979031afbe5ce216b5a483f1 82.157.173.74:7002@17002 master - 0 1701171968427 2 connected 5461-10922
f45c8f3bb41f7d5c7ddb67511104ae9853e1946f 82.157.173.74:7003@17003 master - 0 1701171966425 3 connected 10923-16383
58e86414a5cf6b6e0d48421be8649f93e8bd4d86 82.157.173.74:7004@17004 slave f97ef1b889da7a3439c444c2a53b5ffc56b2afdc 0 1701171965000 4 connected
f97ef1b889da7a3439c444c2a53b5ffc56b2afdc 172.22.0.5:7001@17001 myself,master - 0 1701171966000 1 connected 0-5460在节点中执行写入和读取
节点上读写之前也操作过,首先就是进入其中一个节点内
第一个命令:set key1 1111
82.157.173.74:7001> set key1 1111
-> Redirected to slot [9189] located at 82.157.173.74:7002
OK
82.157.173.74:7002> set 命令 set key1 1111 , key1 键根据哈希函数运算以后得到的值为 [9189] 。 当前集群环境的槽分配情况为: [0-5460] 7001节点 , [5461-10922] 7002节点 , [10923-16383] 7003节点 , 该键的存储就被分配到了 7002节点上;
第二个 set 命令 set aaa 111
82.157.173.74:7002> set aaa 1111
OK
82.157.173.74:7002> 再来看第二个 set 命令 set aaa ,这里大家可能会有一些疑问,为什么看不到 aaa 键根据哈希函数运算以后得到的值? 因为刚才重定向至 7002节点插入了数据,此时如果还有数据插入,正好键根据哈希函数运算以后得到的值也还在该节点的范围内,那么直接插入数据即可;
第三个 set 命令 set bbb 222
82.157.173.74:7002> set bbb 1111
-> Redirected to slot [5287] located at 82.157.173.74:7001
OK
82.157.173.74:7001> 接着是第三个 set 命令 set bbb , bbb 键根据哈希函数运算以后得到的值为 [5287] ,所以该键的存 储就被分配到了 7001 节点上;
第四个命令 get name
82.157.173.74:7001> get name
-> Redirected to slot [5798] located at 82.157.173.74:7002
"helloworld"
82.157.173.74:7002> 第四个命令 get name , name 键根据哈希函数运算以后得到的值为 [5798] ,被重定向至7002节点读取;
第五个命令 get aaa
82.157.173.74:7002> get aaa
"1111"
82.157.173.74:7002> 第六个命令 get bbb
82.157.173.74:7002> get bbb
-> Redirected to slot [5287] located at 82.157.173.74:7001
"1111"
82.157.173.74:7001> 第六个命令 get bbb , bbb 键根据哈希函数运算以后得到的值为 [5287] ,被重定向至 7001 节点读 取。
redis cluster配置
redis cluster状态
82.157.173.74:7001> cluster info
cluster_state:ok ## 如果当前redis发现有failed的slots,默认为把自己cluster_state从ok个性为fail, 写入命令会失败。如果设置cluster-require-full-coverage为no,则无此限制。
cluster_slots_assigned:16384 #已分配的槽
cluster_slots_ok:16384 #槽的状态是ok的数目
cluster_slots_pfail:0 #可能失效的槽的数目
cluster_slots_fail:0 #已经失效的槽的数目
cluster_known_nodes:6 #集群中节点个数
cluster_size:3 #集群中设置的分片个数
cluster_current_epoch:6 #集群中的currentEpoch总是一致的,currentEpoch越高,代表节点的配置或者操作越新,集群中最大的那个node epoch
cluster_my_epoch:1 #当前节点的config epoch,每个主节点都不同,一直递增, 其表示某节点最后一次变成主节点或获取新slot所有权的逻辑时间
cluster_stats_messages_ping_sent:440035
cluster_stats_messages_pong_sent:400139
cluster_stats_messages_sent:840174
cluster_stats_messages_ping_received:400134
cluster_stats_messages_pong_received:440035
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:840174
82.157.173.74:7001> maxmemory 10485760000
redis默认内存: 如果不设置最大内存大小或者设置最大内存大小为0, 在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存。 生产上内存设置: 一般推荐redis设置内存为最大物理内存的四分之三。 但是不建议单个节点内存太大,建议在15G以内。
cluster-enabled yes
如果配置yes则开启集群功能,此redis实例作为集群的一个节点, 否则,它是一个普通的单一的redis实例。
cluster-config-file nodes-6379.conf
虽然此配置的名字叫”集群配置文件”,但是此配置文件不能人工编辑,它是集群节点自动维护的文件, 主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。 通常是在收到请求之后这个文件就会被更新。
cluster-node-timeout 15000
这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。 如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。 注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请 求。 一般设置为15秒即可。
一个ping的最长不能容忍的时间的二分之一,是指超时时间为15秒除以2=7.5秒? 也就是cluster-node-timeout=15000,ping的超时时间是7.5秒?
cluster-slave-validity-factor 10
如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。 如果设置成正数,则cluster-node-timeout乘以cluster-slave-validity-factor得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。 假设cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50 秒,此从节点不能成为主节点。
注意,如果此参数配置为非0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。
cluster-migration-barrier 1
主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。
cluster-require-full-coverage yes
在部分key所在的节点不可用时,如果此参数设置为”yes”(默认值), 则整个集群停止接受操作; 如果此参数设置为”no”,则集群依然为可达节点上的key提供读操作。
replicaof <masterip> <masterport>
通过设置 master 的 ip 和 port ,可以使当前的 Redis 实例成为另一台 Redis 实例的副本。 在Redis启动时,它会自动从 master 进行数据同步。
- Redis 复制是异步的,可以通过修改 master 的配置,在 master 没有与给定数量的 replica 连接 时,主机停止接收写入;
- 如果复制链路丢失的时间相对较短,Redis replica 可以与 master 执行部分重新同步,可以使用合 理的 backlog 值来进行配置;
- 复制是自动的,不需要用户干预。在网络分区后,replica 会自动尝试重新连接到 master 并与 master 重新同步;
主从复制,从 5.0.0 版本开始,Redis 正式将 SLAVEOF 命令改名成了 REPLICAOF 命令并逐渐废弃原 来的 SLAVEOF 命令
Redis使用默认的异步复制,其特点是低延迟和高性能,是绝大多数 Redis 用例的自然复制模式。但是, replica 会异步地确认它从主 master 周期接收到的数据量。
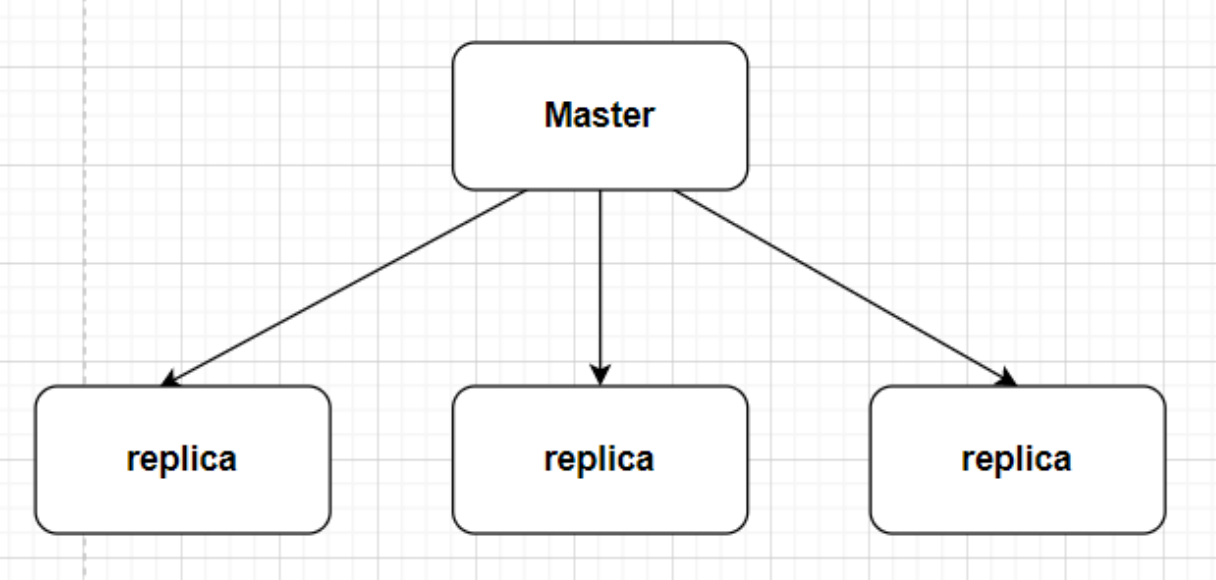
master 用来写操作,replicas 用来读取数据,适用于读多写少的场景。而对于写并发量较高的场景,多个从节点会导致主节点写命令的多次发送从而过度消耗网络带宽,同时也加重了 master 的负载影响服务稳定性。
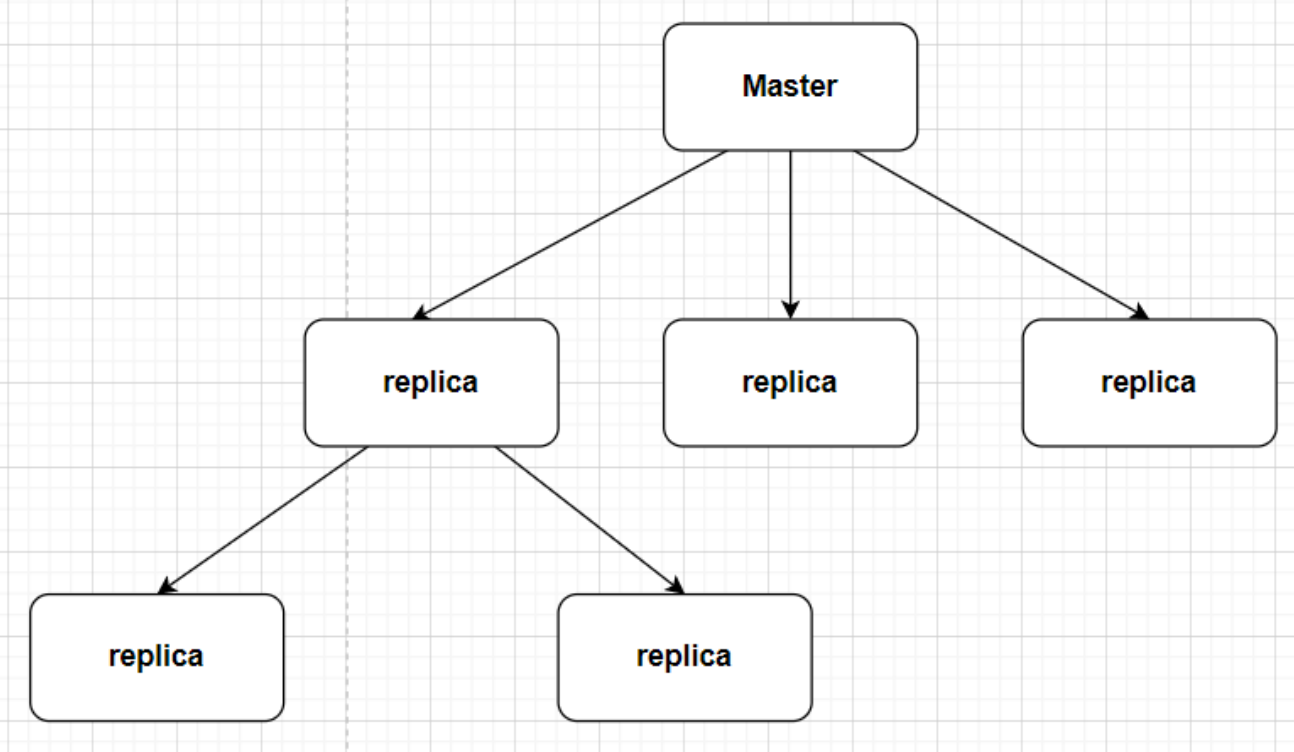
replica 可以接受其它 replica 的连接。 除了多个 replica 可以连接到同一个 master 之外, replica 之间也可以像层叠状的结构(cascading-like structure)连接到其他 replica 。 自 Redis 4.0 起,所有的 sub-replica 将会从 master 收到完全一样的复制流。 当 master 需要多个 replica 时,为了避免对 master 的性能干扰,可以采用树状主从结构降低主节点的压力。
replica-read-only
可以将 replica 配置为是否只读,yes 代表为只读状态,将会拒绝所有写入命令;no 表示可以写入。从 Redis 2.6 之后, replica 支持只读模式且默认开启。可以在运行时使用 CONFIG SET 来随时开启或者关闭。
对 replica 进行写入可能有助于存储一些临时数据(因为写入 replica 的数据在与 master 重新同步后很 容易被删除),计算慢速集或排序集操作并将其存储到本地密钥是多次观察到的可写副本的一个用例。 但如果客户端由于配置错误而向其写入数据,则也可能会导致问题。
在级联结构中即使 replica B 节点是可写的,Sub-replica C 也不会看到 B 的写入,而是将拥有和 master A 相同的数据集。
设置为 yes 并不表示客户端用集群方式以 replica 为入口连入集群时,不可以进行 set 操作,且 set 操作 的数据不会被放在 replica 的槽上,会被放到某 master 的槽上。
注意:只读 replica 设计的目的不是为了暴露于互联网上不受信任的客户端,它只是一个防止实例误用的保护层。默认情况下,只读副本仍会导出所有管理命令,如CONFIG、DEBUG 等。在一定程度上,可以使用 rename-command 来隐藏所有管理/危险命令,从而提高只读副本的安全性。
repl-diskless-sync
复制同步策略:磁盘(disk)或套接字(socket),默认为 no 使用 disk 。
新的 replicas 和重新连接的 replicas 如果因为接收到差异而无法继续复制过程,则需要执行“完全同 步”。RDB 文件从 master 传送到 replicas,传输可以通过两种不同的方式进行:
- Disk-backed:Redis master 节点创建一个新的进程并将 RDB 文件写入磁盘,然后文件通过父进 程增量传输给 replicas 节点;
- Diskless:Redis master 节点创建一个新的进程并直接将 RDB 文件写入到 replicas 的 sockets 中,不写到磁盘。
- 当进行 disk-backed 复制时, RDB 文件生成完毕,多个 replicas 通过排队来同步 RDB 文件。
- 当进行 diskless 复制时,master 节点会等待一段时间(下边的repl-diskless-sync-delay 配置)再传输以期望会有多个 replicas 连接进来,这样 master 节点就可以同时同步到多个 replicas 节点。 如果超出了等待时间,则需要排队,等当前的 replica 处理完成之后在进行下一个 replica 的处理。
硬盘性能差,网络性能好的情况下 diskless 效果更佳 警告:无盘复制目前处于试验阶段
repl-diskless-sync-delay
当启用 diskless 复制后,可以通过此选项设置 master 节点创建子进程前等待的时间,即延迟启动数据 传输,目的可以在第一个 replica 就绪后,等待更多的 replica 就绪。单位为秒,默认为5秒。
repl-ping-replica-period
Replica 发送 PING 到 master 的间隔,默认值为 10 秒。
repl-timeout
默认值60秒,此选项用于设置以下情形的 timeout 判断:
- 从 replica 节点的角度来看的 SYNC 过程中的 I/O 传输 —— 没有收到 master SYNC 传输的 rdb snapshot 数据;
- 从 replica 节点的角度来看的 master 的 timeout(如 data,pings)—— replica 没有收到master 发送的数据包或者ping;
- 从 master 节点角度来看的 replica 的 timeout(如 REPLCONF ACK pings)—— master 没有收 到 REPLCONF ACK 的确认信息;
需要注意的是,此选项必须大于 repl-ping-replica-period,否则在 master 和 replica 之间存在低业务量的情况下会经常发生 timeout。
repl-disable-tcp-nodelay
master 和 replicas 节点的连接是否关掉 TCP_NODELAY 选项。
- 如果选择“yes”,Redis 将使用更少的 TCP 数据包和更少的带宽向 replicas 发送数据。但这会增加 数据在 replicas 端显示的延迟,对于使用默认配置的 Linux 内核,延迟可达40毫秒。
- 如果选择“no”,则数据出现在 replicas 端的延迟将减少,但复制将使用更多带宽。
这个实际影响的是 TCP 层的选项,里面会用 setsockopt 设置,默认为 no,表示 TCP 层会禁用 Nagle 算法,尽快将数据发出, 设置为 yes 表示 TCP 层启用 Nagle 算法,数据累积到一定程度,或者经过一定时间 TCP 层才会将其发出。
默认情况下,我们会针对低延迟进行优化,但在流量非常高的情况下,或者当 master 和 replicas 距离多个 hops 时,将此选项改为“yes”可能会更好。
repl-backlog-size
设置复制的 backlog 缓冲大小,默认 1mb。backlog 是一个缓冲区,当 replica 断开一段时间连接时, 它会累积 replica 数据,所以当 replica 想要再次重新连接时,一般不需要全量同步,只需要进行部分同步即可,只传递 replica 在断开连接时丢失的部分数据。
更大的 backlog 缓冲大小,意味着 replicas 断开重连后,依然可以进行续传的时间越长(支持断开更长 时间)。
backlog 缓冲只有在至少一个 replica 节点连过来的时候 master 节点才需要创建。
repl-backlog-ttl
当 replicas 节点断开连接后,master 节点会在一段时间后释放 backlog 缓冲区。这个选项设置的是当 最后一个 replica 断开链接后,master 需要等待多少秒再释放缓冲区。默认3600 秒,0表示永远不释放。
replicas 节点永远都不会释放这个缓冲区,因为它有可能再次连接到 master 节点, 然后尝试进行 “增量同步”。
replica-priority
replica-priority 是 Redis 通过 INFO 接口发布的整数,默认值为 100。
当 master 节点无法正常工作后 Redis Sentinel 通过这个值来决定将哪个 replica 节点提升为 master 节点。
这个数值越小表示越优先进行提升。
如有三个 replica 节点其 priority 值分别为 10,100,25, Sentinel 会选择 priority 为 10 的节点进行 提升。这个值为 0 表示 replica 节点永远不能被提升为 master 节点。
repl-ping-slave-period和repl-ping-replica-period
repl-ping-slave-period和repl-ping-replica-period这两个重要参数,意思差不多, 即:SLAVE周期性的ping MASTER间隔,可直接理解成SLAVE -> MASTER间的心跳间隔(注意箭头方 向)。
实际上因为一些非技术原因,很多软件将slave改成了replica,Redis也同样如此,所以replica和slave 是完全相同的。
常用命令变化,但5.0仍然兼容的配置项(实际上所有的slave都改成了replica,包括一些官方网站的文 档,不过代码中的变量名保持未变,仍就为slave):
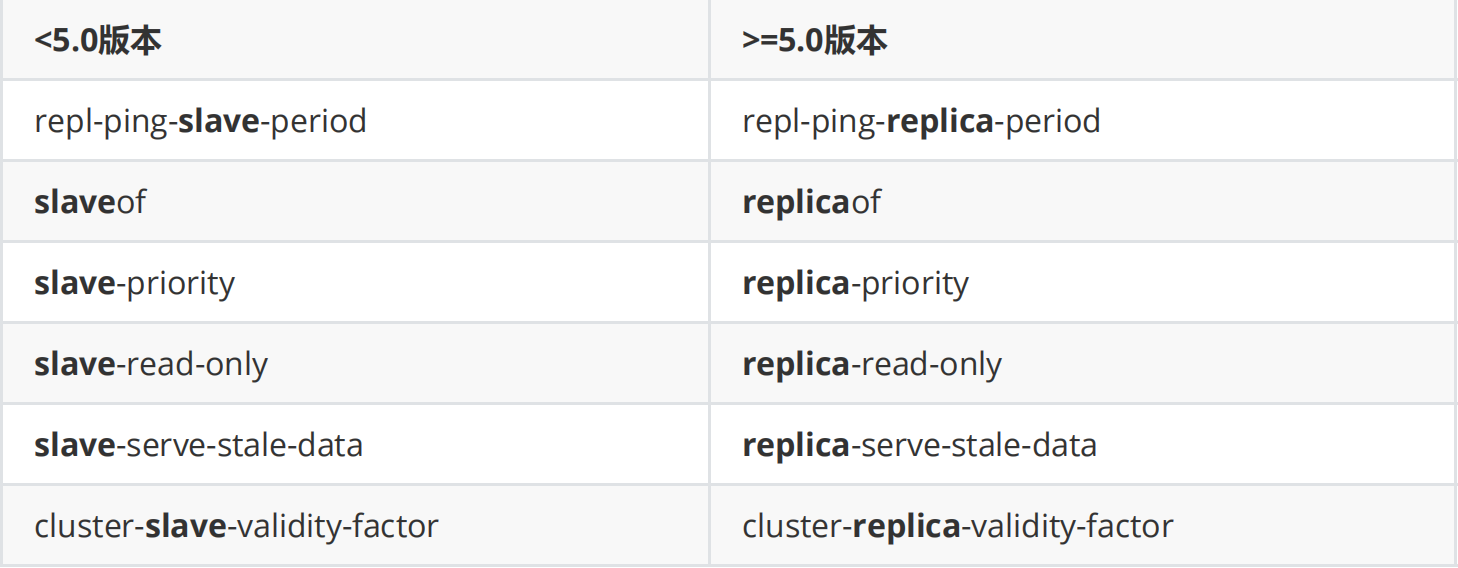
repl-timeout和repl-ping-replica-period的区别

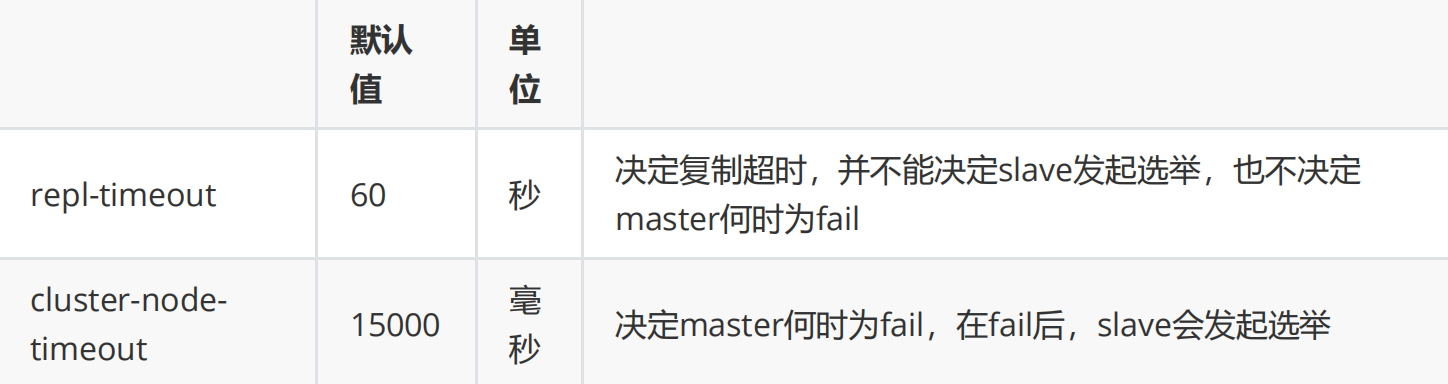
repl-timeout和cluster-node-timeout的区别
redis集群管理实操
现在重新创建redis集群,从零开始测试,这里要特别注意的是,如果按照上述步骤去重新创建集群,那么这里我们要先删除挂载出来的data文件,因为之前创建集群的信息都是保存在这里的,如果不删除,我们重新docker-compose创建节点,那么这几个节点会自动成为集群,因为之前的集群信息还存在。
[root@VM-24-13-centos data]# docker-compose up -d
Creating redis-cluster-04 ... done
Creating redis-cluster-05 ... done
Creating redis-cluster-02 ... done
Creating redis-cluster-03 ... done
Creating redis-cluster-01 ... done
Creating redis-cluster-06 ... done现在就重新创建了6个节点,目前这6个节点是没有组成集群的
docker run --rm -it nien/redis-trib check 82.157.173.74:7001
查看节点信息
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib check 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots: (0 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[ERR] Not all 16384 slots are covered by nodes.
[root@VM-24-13-centos data]#
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib check 82.157.173.74:7002
>>> Performing Cluster Check (using node 82.157.173.74:7002)
M: 7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002
slots: (0 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[ERR] Not all 16384 slots are covered by nodes.
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib check 82.157.173.74:7003
>>> Performing Cluster Check (using node 82.157.173.74:7003)
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003
slots: (0 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[ERR] Not all 16384 slots are covered by nodes.
[root@VM-24-13-centos data]# 现在创建的节点是没有分配槽位的,每一个节点都是主节点,证明节点没有组成集群
添加新节点
现在开始一步一步操作创建集群,首先创建一个3个节点的集群,为什么三个节点?因为4个节点用上述的命令会报错
docker run --rm -it nien/redis-trib create --replicas 1 82.157.173.74:7001 82.157.173.74:7003 82.157.173.74:7004 82.157.173.74:7006
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib create --replicas 1 82.157.173.74:7001 82.157.173.74:7003 82.157.173.74:7004 82.157.173.74:7006
>>> Creating cluster
*** ERROR: Invalid configuration for cluster creation.
*** Redis Cluster requires at least 3 master nodes.
*** This is not possible with 4 nodes and 1 replicas per node.
*** At least 6 nodes are required.
------------
***错误:创建群集的配置无效。
***Redis Cluster至少需要3个主节点。
***对于4个节点和每个节点1个副本,这是不可能的。
***至少需要6个节点。这里的报错就很明显的提示我们了,主节点至少3个,并且 –replicas 1 代表副本至少 1个 ,也就是每个主节点都有一个从节点,也就是一个要6个节点,但是我们只有4个节点就会报错。
所以这里我们改一下配置方式,改为3个节点,并且 –replicas 0 ,不需要配置从节点。
docker run --rm -it nien/redis-trib create --replicas 0 82.157.173.74:7001 82.157.173.74:7003 82.157.173.74:7004
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib create --replicas 0 82.157.173.74:7001 82.157.173.74:7003 82.157.173.74:7004
>>> Creating cluster
>>> Performing hash slots allocation on 3 nodes...
Using 3 masters:
82.157.173.74:7001
82.157.173.74:7003
82.157.173.74:7004
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:0-5460 (5461 slots) master
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003
slots:5461-10922 (5462 slots) master
M: 601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004
slots:10923-16383 (5461 slots) master
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:0-5460 (5461 slots) master
0 additional replica(s)
M: 601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004
slots:10923-16383 (5461 slots) master
0 additional replica(s)
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003
slots:5461-10922 (5462 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@VM-24-13-centos data]# 这样3个主节点就组成了集群,并且各自分配了槽位
但是只有3个主节点的集群是不高可用的,每个主节点至少需要一个从节点,我们可以使用命令添加从节点
docker run --rm -it nien/redis-trib add-node 82.157.173.74:7002 82.157.173.74:7001
添加节点信息 前面是要添加的节点,后面是跟的主节点
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib add-node 82.157.173.74:7002 82.157.173.74:7001
>>> Adding node 82.157.173.74:7002 to cluster 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:0-5460 (5461 slots) master
0 additional replica(s)
M: 601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004
slots:10923-16383 (5461 slots) master
0 additional replica(s)
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003
slots:5461-10922 (5462 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 82.157.173.74:7002 to make it join the cluster.
[OK] New node added correctly.
[root@VM-24-13-centos data]# 现在我们来看看节点信息
docker run --rm -it nien/redis-trib check 82.157.173.74:7001
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib check 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:0-5460 (5461 slots) master
0 additional replica(s)
M: 601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004
slots:10923-16383 (5461 slots) master
0 additional replica(s)
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003
slots:5461-10922 (5462 slots) master
0 additional replica(s)
M: 7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002
slots: (0 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@VM-24-13-centos data]# 现在4个节点都是主节点,包括了刚刚添加的7002
进入容器内也可以看节点信息,随便一个节点容器
docker exec -it redis-cluster-01 redis-cli -c -p 7001
[root@VM-24-13-centos data]# docker exec -it redis-cluster-01 redis-cli -c -p 7001
127.0.0.1:7001> cluster nodes
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1702886912984 3 connected 10923-16383
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1702886912000 2 connected 5461-10922
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 172.22.0.6:7001@17001 myself,master - 0 1702886910000 1 connected 0-5460
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1702886913985 0 connected
127.0.0.1:7001> 虽然7002成功添加进去了,但是没有分配槽位
重新分配节点槽位
docker exec -it redis-cluster-01 redis-cli --cluster reshard 82.157.173.74:7001
现在从7001上迁移1000个槽位到7002上
[root@VM-24-13-centos data]# docker exec -it redis-cluster-01 redis-cli --cluster reshard 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:[0-5460] (5461 slots) master
M: 601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004
slots:[10923-16383] (5461 slots) master
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003
slots:[5461-10922] (5462 slots) master
M: 7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002
slots: (0 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1000
What is the receiving node ID? 7dabb3d56ba3c3187de39f2da122edca3d535334
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Source node #2: done
Ready to move 1000 slots.
Source nodes:
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:[0-5460] (5461 slots) master
Destination node:
M: 7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002
slots: (0 slots) master
Resharding plan:
Moving slot 0 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 1 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 2 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 3 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 4 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 5 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
………
Moving slot 996 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 997 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 998 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Moving slot 999 from 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Do you want to proceed with the proposed reshard plan (yes/no)? yes
Moving slot 0 from 82.157.173.74:7001 to 82.157.173.74:7002:
Moving slot 1 from 82.157.173.74:7001 to 82.157.173.74:7002:
Moving slot 2 from 82.157.173.74:7001 to 82.157.173.74:7002:
Moving slot 3 from 82.157.173.74:7001 to 82.157.173.74:7002:
………
Moving slot 996 from 82.157.173.74:7001 to 82.157.173.74:7002:
Moving slot 997 from 82.157.173.74:7001 to 82.157.173.74:7002:
Moving slot 998 from 82.157.173.74:7001 to 82.157.173.74:7002:
Moving slot 999 from 82.157.173.74:7001 to 82.157.173.74:7002: 迁移的时候,会先让你输入要迁移几个槽位,这里写1000个
What is the receiving node ID? 是迁移到哪里去这里是7002节点的ID
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e
Source node #2: done这里写来源节点7001的ID,然后done就行了
最后看一下迁移好的节点信息
[root@VM-24-13-centos data]# docker exec -it redis-cluster-01 redis-cli -c -p 7001
127.0.0.1:7001> cluster nodes
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1702887369777 3 connected 10923-16383
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1702887368775 2 connected 5461-10922
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 172.22.0.6:7001@17001 myself,master - 0 1702887367000 1 connected 1000-5460
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1702887368000 4 connected 0-999
127.0.0.1:7001> 设置主从关系
刚刚是将7002节点加入集群,然后为它分配槽位,但是现在每个主节点都没有从节点,我们可以为主节点添加从节点
还是上面的操作,将7005添加到集群
docker run --rm -it nien/redis-trib add-node 82.157.173.74:7005 82.157.173.74:7001
[root@VM-24-13-centos data]# docker run --rm -it nien/redis-trib add-node 82.157.173.74:7005 82.157.173.74:7001
>>> Adding node 82.157.173.74:7005 to cluster 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001
slots:1000-5460 (4461 slots) master
0 additional replica(s)
M: 601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004
slots:10923-16383 (5461 slots) master
0 additional replica(s)
M: 7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003
slots:5461-10922 (5462 slots) master
0 additional replica(s)
M: 7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002
slots:0-999 (1000 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 82.157.173.74:7005 to make it join the cluster.
[OK] New node added correctly.
[root@VM-24-13-centos data]# 看看7005的信息,现在还是主节点
[root@VM-24-13-centos data]# docker exec -it redis-cluster-01 redis-cli -c -p 7001
127.0.0.1:7001> cluster nodes
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1702888764251 3 connected 10923-16383
6a09ae3a8c6fbadcf88839c7557446eecd6412aa 82.157.173.74:7005@17005 master - 0 1702888763250 0 connected
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 172.22.0.6:7001@17001 myself,master - 0 1702888763000 1 connected 1000-5460
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1702888763000 2 connected 5461-10922
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1702888762247 4 connected 0-999
127.0.0.1:7001> 现在先进入7005的reids内
docker exec -it redis-cluster-05 redis-cli -c -p 7005
然后用命令将该节点变为7002的从节点
cluster replicate 7dabb3d56ba3c3187de39f2da122edca3d535334(节点ID是7002的ID)
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-01 redis-cli -c -p 7001
127.0.0.1:7001> cluster nodes
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1703053484897 3 connected 10923-16383
6a09ae3a8c6fbadcf88839c7557446eecd6412aa 82.157.173.74:7005@17005 master - 0 1703053485898 0 connected
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 172.22.0.6:7001@17001 myself,master - 0 1703053482000 1 connected 1000-5460
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1703053485000 2 connected 5461-10922
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1703053484000 4 connected 0-999
127.0.0.1:7001> exit
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-05 redis-cli -c -p 7005
127.0.0.1:7005> cluster replicate 7dabb3d56ba3c3187de39f2da122edca3d535334
OK
127.0.0.1:7005> cluster nodes
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1703053750449 4 connected 0-999
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1703053749446 3 connected 10923-16383
6a09ae3a8c6fbadcf88839c7557446eecd6412aa 172.22.0.4:7005@17005 myself,slave 7dabb3d56ba3c3187de39f2da122edca3d535334 0 1703053749000 0 connected
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001@17001 master - 0 1703053748441 1 connected 1000-5460
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1703053748000 2 connected 5461-10922
127.0.0.1:7005> 现在7005就已经是7002的从节点了
redis cluster 报文抓包
抓包是一个很基础的操作,当我们需要排查问题的时候就要去抓包去排查,在win上我们可以使用wireshark,在linux上我们可以使用 tcpdump
这里我们使用 tcpdump 来抓包,查看redis之间的数据传输内容
在抓包前,首先要看看我们的网卡IP地址
[root@VM-24-13-centos ~]# ifconfig
br-090c5bcb4732: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.20.0.1 netmask 255.255.0.0 broadcast 172.20.255.255
ether 02:42:df:2f:5a:38 txqueuelen 0 (Ethernet)
RX packets 2207800 bytes 1885448588 (1.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1740307 bytes 1859507507 (1.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
br-14016fdb6f85: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.22.0.1 netmask 255.255.0.0 broadcast 172.22.255.255
inet6 fe80::42:bdff:fefe:d927 prefixlen 64 scopeid 0x20<link>
ether 02:42:bd:fe:d9:27 txqueuelen 0 (Ethernet)
RX packets 298 bytes 38224 (37.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 298 bytes 38224 (37.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
br-25561dc97e2e: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.18.0.1 netmask 255.255.0.0 broadcast 172.18.255.255
ether 02:42:27:b4:cb:85 txqueuelen 0 (Ethernet)
RX packets 28418392 bytes 2199175809 (2.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25852362 bytes 2169713733 (2.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
br-ea48919314db: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.1 netmask 255.255.0.0 broadcast 172.21.255.255
inet6 fe80::42:dcff:fe54:88a1 prefixlen 64 scopeid 0x20<link>
ether 02:42:dc:54:88:a1 txqueuelen 0 (Ethernet)
RX packets 28418392 bytes 2199175809 (2.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25852362 bytes 2169713733 (2.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
br-f336dfe00cae: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.19.0.1 netmask 255.255.0.0 broadcast 172.19.255.255
ether 02:42:54:ce:d7:a0 txqueuelen 0 (Ethernet)
RX packets 277367130 bytes 26770145156 (24.9 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 279520984 bytes 26918051011 (25.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:69ff:fe85:97b2 prefixlen 64 scopeid 0x20<link>
ether 02:42:69:85:97:b2 txqueuelen 0 (Ethernet)
RX packets 2399349 bytes 640060451 (610.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2751787 bytes 711954068 (678.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.24.13 netmask 255.255.252.0 broadcast 10.0.27.255
inet6 fe80::5054:ff:fe1e:446f prefixlen 64 scopeid 0x20<link>
ether 52:54:00:1e:44:6f txqueuelen 1000 (Ethernet)
RX packets 677692427 bytes 438722843191 (408.5 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 669907764 bytes 434837399434 (404.9 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 298 bytes 38224 (37.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 298 bytes 38224 (37.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth8407623: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::843f:e4ff:fe81:6de2 prefixlen 64 scopeid 0x20<link>
ether 86:3f:e4:81:6d:e2 txqueuelen 0 (Ethernet)
RX packets 28418392 bytes 2199175809 (2.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25852362 bytes 2169713733 (2.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth2529ebc: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::a066:b7ff:fe38:21ed prefixlen 64 scopeid 0x20<link>
ether a2:66:b7:38:21:ed txqueuelen 0 (Ethernet)
RX packets 1951412 bytes 1814668818 (1.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1497178 bytes 1780580195 (1.6 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth3f46922: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::fccc:48ff:fee1:5200 prefixlen 64 scopeid 0x20<link>
ether fe:cc:48:e1:52:00 txqueuelen 0 (Ethernet)
RX packets 2076354 bytes 1733822190 (1.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1566665 bytes 1690129275 (1.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth49c6cc7: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::c83c:4aff:fe24:f3fb prefixlen 64 scopeid 0x20<link>
ether ca:3c:4a:24:f3:fb txqueuelen 0 (Ethernet)
RX packets 1940698 bytes 1771889480 (1.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1473606 bytes 1742256429 (1.6 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth4b3aa3e: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::c40f:beff:fe1d:328e prefixlen 64 scopeid 0x20<link>
ether c6:0f:be:1d:32:8e txqueuelen 0 (Ethernet)
RX packets 466240866 bytes 45307691970 (42.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 459730929 bytes 44762759476 (41.6 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth532106f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::404e:f7ff:fe63:43fe prefixlen 64 scopeid 0x20<link>
ether 42:4e:f7:63:43:fe txqueuelen 0 (Ethernet)
RX packets 689031 bytes 146423893 (139.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 856933 bytes 79815071 (76.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth5e14e82: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::6c66:f9ff:fea1:b00f prefixlen 64 scopeid 0x20<link>
ether 6e:66:f9:a1:b0:0f txqueuelen 0 (Ethernet)
RX packets 2207800 bytes 1885448588 (1.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1740307 bytes 1859507507 (1.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth79a3d05: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::420:14ff:fe7a:8ac2 prefixlen 64 scopeid 0x20<link>
ether 06:20:14:7a:8a:c2 txqueuelen 0 (Ethernet)
RX packets 690 bytes 45761 (44.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 787 bytes 43799 (42.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth7d55e8f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::81f:feff:fed1:af38 prefixlen 64 scopeid 0x20<link>
ether 0a:1f:fe:d1:af:38 txqueuelen 0 (Ethernet)
RX packets 43156 bytes 106244268 (101.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 33620 bytes 6229324 (5.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth80dcbc5: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::9c20:82ff:fe38:9418 prefixlen 64 scopeid 0x20<link>
ether 9e:20:82:38:94:18 txqueuelen 0 (Ethernet)
RX packets 29652450 bytes 2562784098 (2.3 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 28751366 bytes 2533388200 (2.3 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth90a548b: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::c47a:aff:fee5:fe58 prefixlen 64 scopeid 0x20<link>
ether c6:7a:0a:e5:fe:58 txqueuelen 0 (Ethernet)
RX packets 28741814 bytes 2211663078 (2.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 26675463 bytes 2209288156 (2.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethc589370: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::44c1:3aff:feb8:27e2 prefixlen 64 scopeid 0x20<link>
ether 46:c1:3a:b8:27:e2 txqueuelen 0 (Ethernet)
RX packets 277367130 bytes 26770145156 (24.9 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 279520984 bytes 26918051011 (25.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethc554f38: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::849c:9aff:feb4:57db prefixlen 64 scopeid 0x20<link>
ether 86:9c:9a:b4:57:db txqueuelen 0 (Ethernet)
RX packets 64379282 bytes 5407059525 (5.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 71290407 bytes 6215437914 (5.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethcc50de1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::88a3:edff:fe29:35ac prefixlen 64 scopeid 0x20<link>
ether 8a:a3:ed:29:35:ac txqueuelen 0 (Ethernet)
RX packets 298665 bytes 25163717 (23.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 343910 bytes 50449972 (48.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethd60e14d: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::1018:41ff:fe7b:fb7b prefixlen 64 scopeid 0x20<link>
ether 12:18:41:7b:fb:7b txqueuelen 0 (Ethernet)
RX packets 2085409 bytes 1859639266 (1.7 GiB)namespace RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1562974 bytes 1829595266 (1.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethdd31bb7: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::10f6:89ff:fe35:a502 prefixlen 64 scopeid 0x20<link>
ether 12:f6:89:35:a5:02 txqueuelen 0 (Ethernet)
RX packets 283093244 bytes 28122712806 (26.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 286142600 bytes 27649087651 (25.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0这个是我们宿主机的网卡信息,我们要切换到我们容器里的网卡地址
这个时候就要讲 namespace 的命名空间了,因为在命名空间里做了隔离
namespace是Linux中一些进程的属性的作用域,使用命名空间,可以隔离不同的进程。 Linux在不断的添加命名空间,目前有
mount:挂载命名空间,使进程有一个独立的挂载文件系统,始于Linux 2.4.19
ipc:ipc命名空间,使进程有一个独立的ipc,包括消息队列,共享内存和信号量,始于Linux 2.6.19
uts:uts命名空间,使进程有一个独立的hostname和domainname,始于Linux 2.6.19
net:network命令空间,使进程有一个独立的网络栈,始于Linux 2.6.24
pid:pid命名空间,使进程有一个独立的pid空间,始于Linux 2.6.24
user:user命名空间,是进程有一个独立的user空间,始于Linux 2.6.23,结束于Linux 3.8
cgroup:cgroup命名空间,使进程有一个独立的cgroup控制组,始于Linux 4.6Linux的每个进程都具有命名空间,可以在/proc/PID/ns目录中看到命名空间的文件描述符。
获取PID可以通过docker命令(获取容器进程id,即PID)
docker inspect --format "{{.State.Pid}}" redis-cluster-01 27943
不筛选信息可以看所有的信息
docker inspect redis-cluster-01
这个命令也可以查看pid
ps -ef | grep redis
[root@VM-24-13-centos ~]# ps -ef |grep redis
polkitd 13649 13628 0 Sep13 ? 02:13:51 redis-server *:6379
root 16053 7034 0 11:56 pts/0 00:00:00 grep --color=auto redis
polkitd 27699 27657 0 Dec18 ? 00:04:42 redis-server *:7004 [cluster]
polkitd 27704 27660 0 Dec18 ? 00:03:44 redis-server *:7006 [cluster]
polkitd 27740 27718 0 Dec18 ? 00:05:10 redis-server *:7005 [cluster]
polkitd 27817 27796 0 Dec18 ? 00:04:37 redis-server *:7003 [cluster]
polkitd 27943 27874 0 Dec18 ? 00:04:39 redis-server *:7001 [cluster]
polkitd 27949 27893 0 Dec18 ? 00:04:49 redis-server *:7002 [cluster] echo $BASHPID , 可以查看当前用户登录的进程PID
然后在/proc/PID/ns目录中看到命名空间的文件描述符
[root@VM-24-13-centos ~]# ls -l /proc/27943/ns
total 0
lrwxrwxrwx 1 polkitd input 0 Dec 22 11:58 ipc -> ipc:[4026532431]
lrwxrwxrwx 1 polkitd input 0 Dec 22 11:58 mnt -> mnt:[4026532429]
lrwxrwxrwx 1 polkitd input 0 Dec 21 16:19 net -> net:[4026532434]
lrwxrwxrwx 1 polkitd input 0 Dec 21 16:19 pid -> pid:[4026532432]
lrwxrwxrwx 1 polkitd input 0 Dec 22 11:58 user -> user:[4026531837]
lrwxrwxrwx 1 polkitd input 0 Dec 22 11:58 uts -> uts:[4026532430]网络命名空间的编号为 4026532434
最后我们做容器命名空间的切换 nsenter
nsenter相当于在setns的示例程序之上做了一层封装,使我们无需指定命名空间的文件描述符,而是指定进程号即可。
nsenter -n -t27943
现在看看网卡地址
[root@VM-24-13-centos ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.22.0.6 netmask 255.255.0.0 broadcast 172.22.255.255
ether 02:42:ac:16:00:06 txqueuelen 0 (Ethernet)
RX packets 1531391 bytes 1810308254 (1.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2019438 bytes 1841208396 (1.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 886 bytes 94237 (92.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 886 bytes 94237 (92.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@VM-24-13-centos ~]# 发现和原来的不一样了
现在就已进入容器的网络命名空间,就可以使用宿主机上的tcpdump来对容器进行抓包了如果宿主机上已安装了tcpdump抓包工具,那我们就可以通过宿主机上的nsenter工具来对docker容器进行抓包。
nsenter 包含在绝大部分 Linux 发行版预置的 util-linux 工具包中。使用它可以进入指定进程的关联命名空间。包括文件命名空间(mount namespace)、主机名命名空间(UTS namespace)、IPC 命名空间 (IPC namespace)、网络命名空间(network namespace)、进程命名空间(pid namespace)和用户命名空间(user namespace)。
nsenter命令是一个可以在指定进程的命令空间下运行指定程序的命令。它位于util-linux包中。
一个最典型的用途就是进入容器的网络命令空间。
相当多的容器为了轻量级,是不包含较为基础的 命令的,比如说ip address,ping,telnet,ss,tcpdump等等命令,这就给调试容器网络带来相 当大的困扰:只能通过docker inspect ContainerID命令获取到容器IP,以及无法测试和其他网络 的连通性。这时就可以使用nsenter命令仅进入该容器的网络命名空间,使用宿主机的命令调试容 器网络。
此外,nsenter也可以进入mnt, uts, ipc, pid, user命令空间,以及指定根目录和工作目录。
tcpdump
tcpdump 是Linux系统下的一个强大的命令,可以将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
命令行参数介绍:
- -A 以ASCII格式打印出所有分组,并将链路层的头最小化。
- -c 在收到指定的数量的分组后,tcpdump就会停止。
- -C 在将一个原始分组写入文件之前,检查文件当前的大小是否超过了参数file_size
- 中指定的大小。如果超过了指定大小,则关闭当前文件,然后在打开一个新的文件。参数 file_size
- 的单位是兆字节(是1,000,000字节,而不是1,048,576字节)。
- -d 将匹配信息包的代码以人们能够理解的汇编格式给出。
- -dd 将匹配信息包的代码以c语言程序段的格式给出。
- -ddd 将匹配信息包的代码以十进制的形式给出。
- -D 打印出系统中所有可以用tcpdump截包的网络接口。
- -e 在输出行打印出数据链路层的头部信息。
- -E 用spi@ipaddr algo:secret解密那些以addr作为地址,并且包含了安全参数索引值spi的IPsec ESP分组。
- -f 将外部的Internet地址以数字的形式打印出来。
- -F 从指定的文件中读取表达式,忽略命令行中给出的表达式。
- -i 指定监听的网络接口。
- -l 使标准输出变为缓冲行形式。
- -L 列出网络接口的已知数据链路。
- -m 从文件module中导入SMI MIB模块定义。该参数可以被使用多次,以导入多个MIB模块。
- -M 如果tcp报文中存在TCP-MD5选项,则需要用secret作为共享的验证码用于验证TCP-MD5选选项摘要(详情可参考RFC 2385)。
- -n 不把网络地址转换成名字。
- -N 不输出主机名中的域名部分。例如,
link.linux265.com只输出link。 - -t 在输出的每一行不打印时间戳。
- -O 不运行分组分组匹配(packet-matching)代码优化程序。
- -P 不将网络接口设置成混杂模式。
- -q 快速输出。只输出较少的协议信息。
- -r 从指定的文件中读取包(这些包一般通过-w选项产生)。
- -S 将tcp的序列号以绝对值形式输出,而不是相对值。
- -s 从每个分组中读取最开始的snaplen个字节,而不是默认的68个字节。
- -T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc远程过程调用)和snmp(简单网络管理协议;)。
- -t 不在每一行中输出时间戳。
- -tt 在每一行中输出非格式化的时间戳。
- -ttt 输出本行和前面一行之间的时间差。
- -tttt 在每一行中输出由date处理的默认格式的时间戳。
- -u 输出未解码的NFS句柄。
- -v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息。
- -vv 输出详细的报文信息。
- -w 直接将分组写入文件中,而不是不分析并打印出来。
- -x 以16进制数形式显示每一个报文 (去掉链路层报头) . 可以显示较小的完整报文, 否则只显示snaplen个字节.
- -xx 以16进制数形式显示每一个报文(包含链路层包头)。
- -X 以16进制和ASCII码形式显示每个报文(去掉链路层报头)。
- -XX 以16进制和ASCII吗形式显示每个报文(包含链路层报头)。
- -y 设置tcpdump 捕获数据链路层协议类型
- -Z 使tcpdump 放弃自己的超级权限(如果以root用户启动tcpdump, tcpdump将会有超级用户权限), 并把当前tcpdump的用户ID设置为user, 组ID设置为user首要所属组的ID
tcpdump -i eth0 -n -XX -nn -s0 tcp and port 7001
[root@VM-24-13-centos ~]# tcpdump -i eth0 -n -XX -nn -s0 tcp and port 7001
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
15:09:52.350036 IP 45.79.181.223.45860 > 172.22.0.6.7001: Flags [.], ack 2741349299, win 64240, options [nop,nop,TS val 3199227199 ecr 4174936507], length 0
0x0000: 0242 ac16 0006 0242 bdfe d927 0800 45b8 .B.....B...'..E.
0x0010: 0034 5d00 4000 fa06 93c0 2d4f b5df ac16 .4].@.....-O....
0x0020: 0006 b324 1b59 50a2 821d a365 abb3 8010 ...$.YP....e....
0x0030: faf0 75a6 0000 0101 080a beb0 553f f8d8 ..u.........U?..
0x0040: 79bb y.
15:09:52.350062 IP 172.22.0.6.7001 > 45.79.181.223.45860: Flags [.], ack 1, win 30016, options [nop,nop,TS val 4174951760 ecr 3199181123], length 0
0x0000: 0242 bdfe d927 0242 ac16 0006 0800 4500 .B...'.B......E.
0x0010: 0034 a9d7 4000 4006 01a2 ac16 0006 2d4f .4..@.@.......-O
0x0020: b5df 1b59 b324 a365 abb3 50a2 821e 8010 ...Y.$.e..P.....
0x0030: 7540 8f71 0000 0101 080a f8d8 b550 beaf u@.q.........P..
0x0040: a143 .C
15:10:07.618207 IP 45.79.181.223.45860 > 172.22.0.6.7001: Flags [.], ack 1, win 64240, options [nop,nop,TS val 3199242455 ecr 4174951760], length 0
0x0000: 0242 ac16 0006 0242 bdfe d927 0800 45b8 .B.....B...'..E.
0x0010: 0034 5d01 4000 fa06 93bf 2d4f b5df ac16 .4].@.....-O....
0x0020: 0006 b324 1b59 50a2 821d a365 abb3 8010 ...$.YP....e....
0x0030: faf0 fe78 0000 0101 080a beb0 90d7 f8d8 ...x............
0x0040: b550 .P
15:10:07.618231 IP 172.22.0.6.7001 > 45.79.181.223.45860: Flags [.], ack 1, win 30016, options [nop,nop,TS val 4174967028 ecr 3199181123], length 0
0x0000: 0242 bdfe d927 0242 ac16 0006 0800 4500 .B...'.B......E.
0x0010: 0034 a9d8 4000 4006 01a1 ac16 0006 2d4f .4..@.@.......-O
0x0020: b5df 1b59 b324 a365 abb3 50a2 821e 8010 ...Y.$.e..P.....
0x0030: 7540 8f71 0000 0101 080a f8d8 f0f4 beaf u@.q............
0x0040: a143 可以看到7001与其他节点的通信
理解 tcpdump 的输出
17:06:36.318595 IP 82.157.173.74.55812 > 172.22.0.7.7002: Flags [P.], seq 38:76, ack 1, win 237, options [nop,nop,TS val 146188433 ecr 146187431], length 38
0x0000: 0242 ac16 0007 0242 bdfe d927 0800 4500 .B.....B...'..E.
0x0010: 005a 9407 4000 3d06 fd91 529d ad4a ac16 .Z..@.=...R..J..
0x0020: 0007 da04 1b5a c74f aa7a bc1c 3ec3 8018 .....Z.O.z..>...
0x0030: 00ed e0d0 0000 0101 080a 08b6 a891 08b6 ................
0x0040: a4a7 2a33 0d0a 2438 0d0a 5245 504c 434f ..*3..$8..REPLCO
0x0050: 4e46 0d0a 2433 0d0a 4143 4b0d 0a24 350d NF..$3..ACK..$5.
0x0060: 0a36 3136 3938 0d0a .61698..tcpdump 输出的内容虽然多,却很规律
从上面的输出来看,可以总结出:
- 第一列:时分秒毫秒 17:06:36.318595
- 第二列:网络协议 IP
- 第三列:发送方的ip地址+端口号,其中82.157.173.74是 ip,而55812是端口号
- 第四列:箭头 >, 表示数据流向
- 第五列:接收方的ip地址+端口号,其中 172.22.0.7 是 ip,而7002是端口号
- 第六列:冒号
- 第七列:数据包内容,包括Flags 标识符,seq 号,ack 号,win 窗口,数据长度 length,其中 [P.] 表示 PUSH 标志位为 1
后面很多的都是数据内容
开始正式抓取主从节点的信息,先来看看目前节点的信息
82.157.173.74:7001> cluster nodes
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1703229242428 3 connected 10923-16383
6a09ae3a8c6fbadcf88839c7557446eecd6412aa 82.157.173.74:7005@17005 slave 7dabb3d56ba3c3187de39f2da122edca3d535334 0 1703229239000 4 connected
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 172.22.0.6:7001@17001 myself,master - 0 1703229243000 1 connected 1000-5460
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1703229243430 2 connected 5461-10922
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1703229241427 4 connected 0-999目前7005是7002的从节点,那么就来抓取这两个节点的信息
首先需要按照刚刚的操作切换到指定的命名空间,开两个窗口分别切换到7002和7005的空间
还是通过ps -ef |grep redis来查看命名空间
[root@VM-24-13-centos 7002]# ps -ef |grep redis
polkitd 13649 13628 0 Sep13 ? 02:18:24 redis-server *:6379
root 26816 17808 0 17:10 pts/2 00:00:00 docker exec -it redis-cluster-02 redis-cli -c -h 82.157.173.74 -p 7002
root 26832 27893 0 17:10 pts/0 00:00:00 redis-cli -c -h 82.157.173.74 -p 7002
polkitd 27699 27657 0 Dec18 ? 00:08:39 redis-server *:7004 [cluster]
polkitd 27704 27660 0 Dec18 ? 00:06:53 redis-server *:7006 [cluster]
polkitd 27740 27718 0 Dec18 ? 00:10:02 redis-server *:7005 [cluster]
polkitd 27817 27796 0 Dec18 ? 00:08:34 redis-server *:7003 [cluster]
polkitd 27943 27874 0 Dec18 ? 00:08:34 redis-server *:7001 [cluster]
polkitd 27949 27893 0 Dec18 ? 00:09:04 redis-server *:7002 [cluster]
root 28739 27874 0 Dec22 pts/0 00:00:00 redis-cli -c -h 82.157.173.74 -p 7001
root 32655 18139 0 17:25 pts/3 00:00:00 grep --color=auto redis然后开始抓包
tcpdump -i eth0 -n -XX -nn -s0 tcp -w /root/data/7002/7002-1.cap
[root@VM-24-13-centos ~]# tcpdump -i eth0 -n -XX -nn -s0 tcp -w /root/data/7002/7002-1.cap
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C504 packets captured
516 packets received by filter
0 packets dropped by kernel
[root@VM-24-13-centos ~]# tcpdump -i eth0 -n -XX -nn -s0 tcp -w /root/data/7005/7005-1.cap
[root@VM-24-13-centos ~]# tcpdump -i eth0 -n -XX -nn -s0 tcp -w /root/data/7005/7005-1.cap
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C299 packets captured
303 packets received by filter
0 packets dropped by kernel
[root@VM-24-13-centos ~]# 在抓包的同时,可以向7002节点发送数据,数据会在数据包里体现出来
82.157.173.74:7002> set vfgr 999999999999999999999999jjjjjjjjjjjjjjjjjjjjjj
OK
82.157.173.74:7002> set vfgr 999999999999999999999999jjjjjjjjjjjjjjjjjjjjjj
OK
82.157.173.74:7002> set vfgr 999999999999999999999999jjjjjjjjjjjjjjjjjjjjjj
OK
82.157.173.74:7002> set vfgr 999999999999999999999999jjjjjjjjjjjjjjjjjjjjjj
OK
82.157.173.74:7002> set vfgr 999999999999999999999999jjjjjjjjjjjjjjjjjjjjjj
OK
82.157.173.74:7002> 通过抓包分析工具wireshark可以看到,7002的通信数据就是我们发送的数据,其他的很多数据都是redis节点的同步数据报文
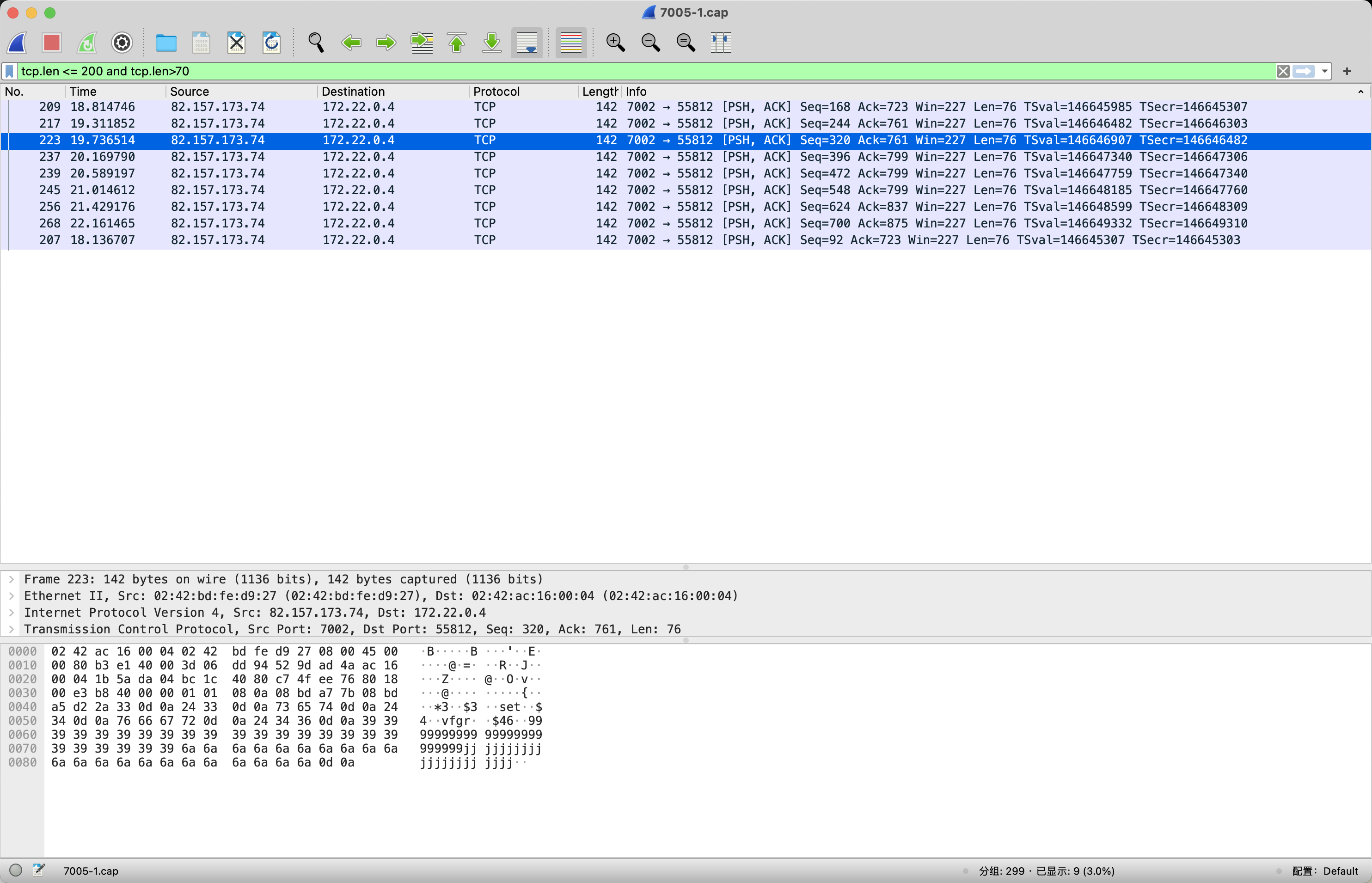
我们可以通过过滤规则来筛选
tcp.len <= 200 and tcp.len>70
wireshark过滤规则:
- IP过滤,包括来源IP或者目标IP等于某个IP;
- 端口过滤;
- 协议过滤tcp;
- 包长度过滤;
- http模式过滤。
一、IP过滤:包括来源IP或者目标IP等于某个IP
比如:ip.src addr==192.168.0.208 or ip.src addr eq 192.168.0.208 显示来源IP ip.dst addr==192.168.0.208 or ip.dst addr eq 192.168.0.208 显示目标IP
二、端口过滤:
比如:tcp.port eq 80 // 不管端口是来源的还是目标的都显示
tcp.port == 80
tcp.port eq 2722
tcp.port eq 80 or udp.port eq 80
tcp.dstport == 80 // 只显tcp协议的目标端口80
tcp.srcport == 80 // 只显tcp协议的来源端口80
过滤端口范围
tcp.port >= 1 and tcp.port <= 80
三、协议过滤:tcp
- udp
- arp
- icmp
- http
- smtp
- ftp
- dns
- msnms
- ip
- ssl
- 等等 排除ssl包,如!ssl 或者 not ssl
四、包长度过滤:
比如:
udp.length == 26 这个长度是指udp本身固定长度8加上udp下面那块数据包之和
tcp.len >= 7 指的是ip数据包(tcp下面那块数据),不包括tcp本身
ip.len == 94 除了以太网头固定长度14,其它都算是ip.len,即从ip本身到最后
frame.len == 119 整个数据包长度,从eth开始到最后
五、http模式过滤:
案例
- http.request.method == “GET”
- http.request.method == “POST”
- http.request.uri == “/img/logo-edu.gif”
- http contains “GET”
- http contains “HTTP/1.” // GET包包含某 头字段
- http.request.method == “GET” && http contains “Host:”
- http.request.method == “GET” && http contains “User-Agent: ”// POST包包含某头字段
- http.request.method == “POST” && http contains “Host:”
- http.request.method == “POST” && http contains “User-Agent: ”// 响应包包含某头字段
- http contains “HTTP/1.1 200 OK” && http contains “Content-Type: ”
- http contains “HTTP/1.0 200 OK” && http contains “Content-Type: ”
六、连接符
and / or
七、表达式
!(arp.src==192.168.1.1) and !(arp.dst.proto_ipv4==192.168.1.243)
TCP协议中的tcp push标志位
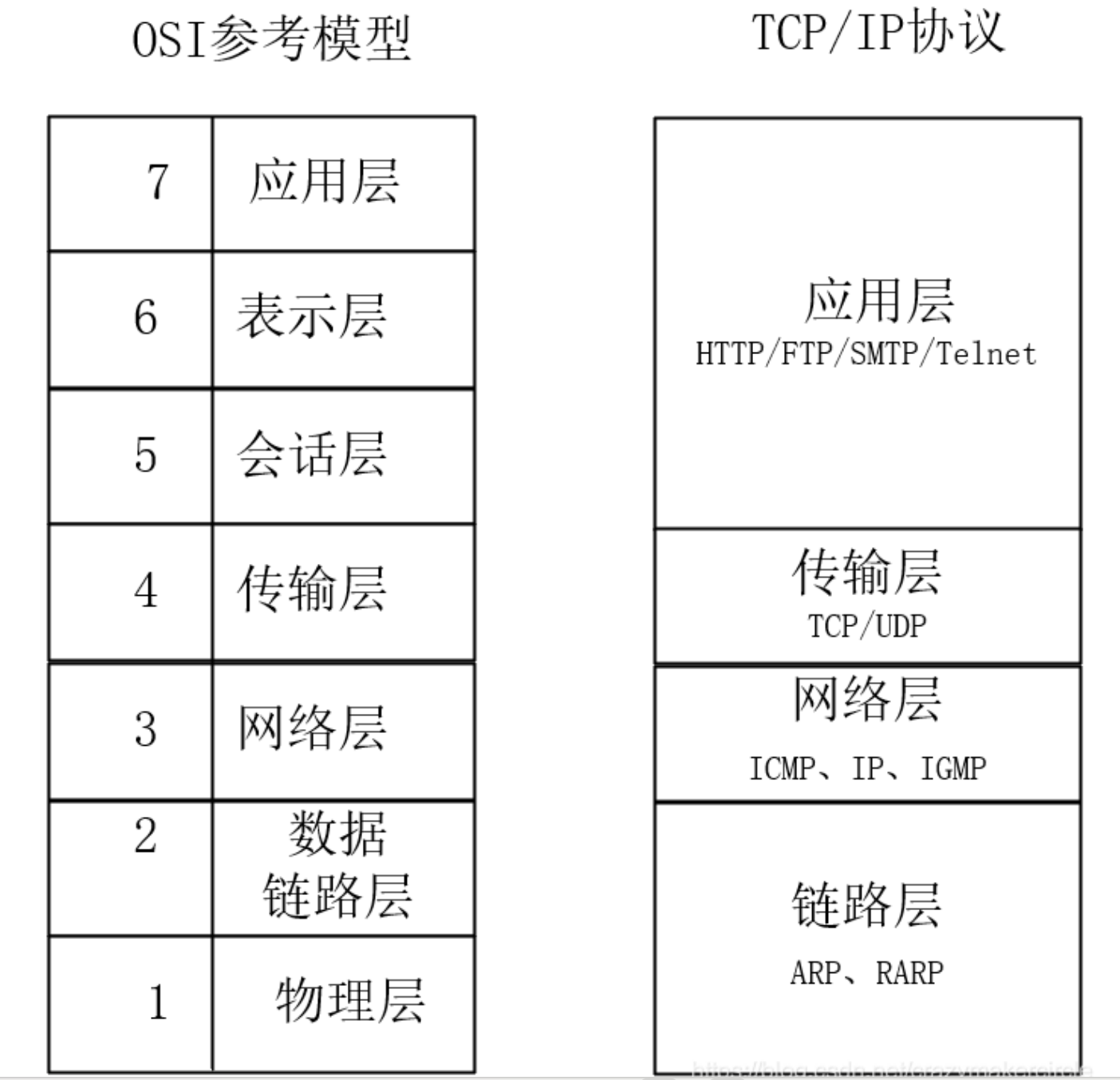
TCP/IP协议与七层ISO模型的对应关系,大致如下图所示:
TCP报文段首部的前20个字节是固定的(下图),后面有4n字节是根据需要而增加的选项(n是整 数)。因此TCP首部的最小长度是20字节。
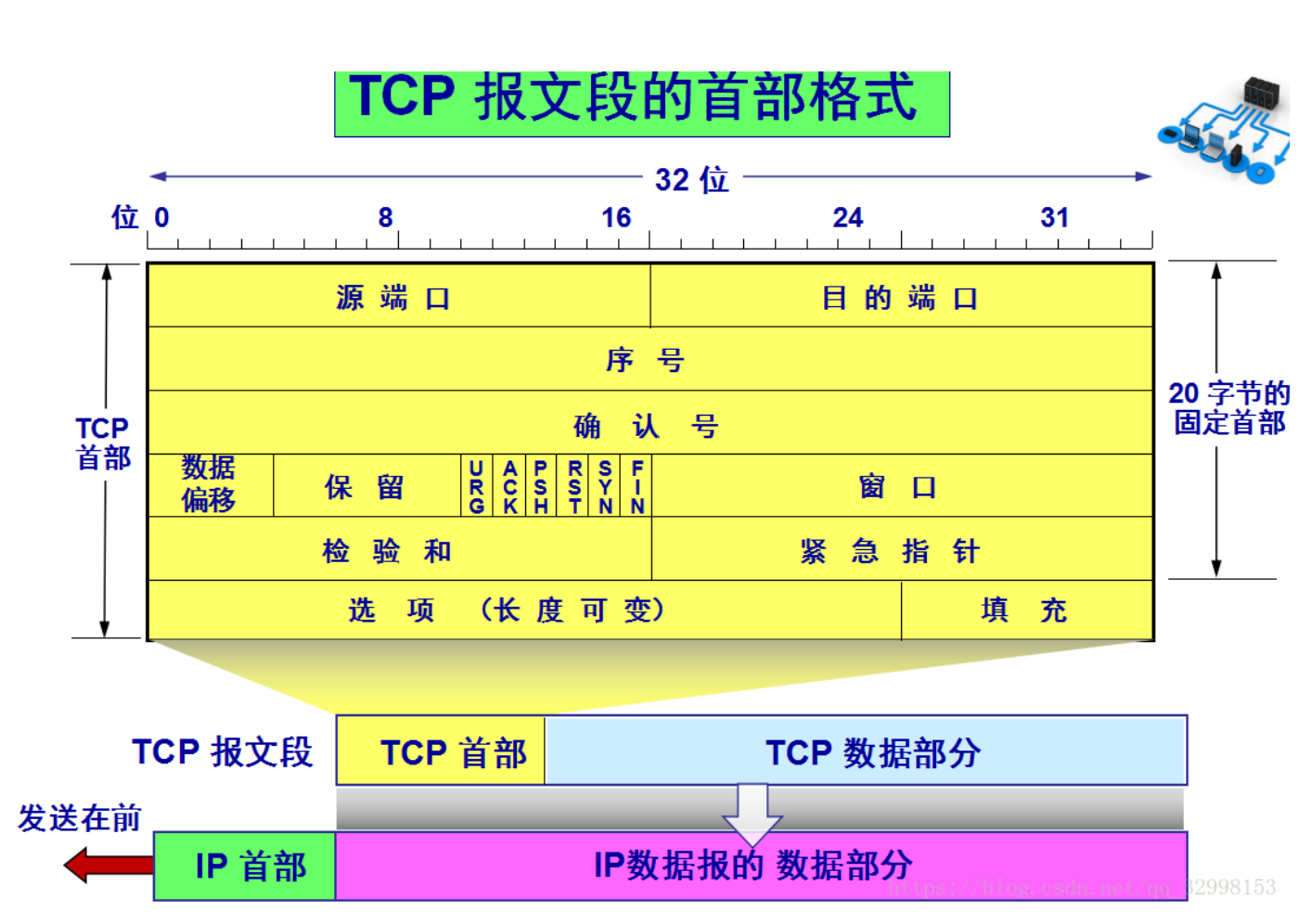
在TCP层,有个FLAGS字段,FLAGS字段中有6个标志位,五个字段的含义是:
- SYN表示建立连接,
- FIN表示关闭连接,
- ACK表示响应,
- PSH表示有 DATA数据传输,
- RST表示连接重
- URG表示紧急
TCP(Transmission Control Protocol)传输控制协议,是主机对主机层的传输控制协议,提供可靠的连 接服务,采用三次握手确认建立一个连接。
位码,即tcp标志位,有6种标示:SYN(synchronous 建立联机)、ACK(acknowledgement 确认)、 PSH(push 传送)、FIN(finish 结束)、RST(reset 重置)、URG(urgent 紧急)、Sequence number(顺序 号码)、Acknowledge number(确认号码)。
- 第一次握手:主机A发送位码为syn=1,随机产生seq number=1234567的数据包到服务器,主机 B由SYN=1知道,A要求建立联机;
- 第二次握手:主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1), syn=1,ack=1,随机产生seq=7654321的包;
- 第三次握手:主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码 ack是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ack=1,主机B收到后确认seq值 与ack=1则连接建立成功。
- 完成三次握手,主机A与主机B开始传送数据。
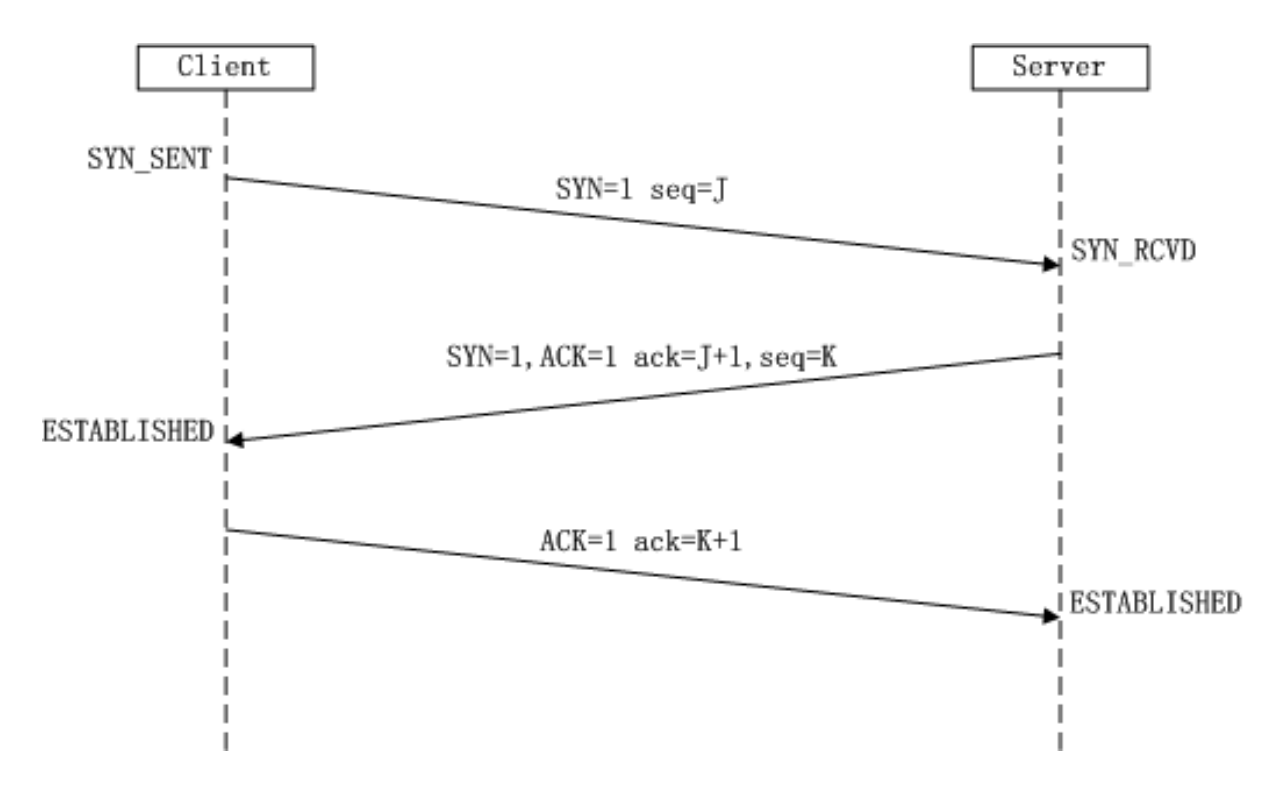
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包 (syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕, 客户端和服务器进入ESTABLISHED状态,完成三次握手。
但是PUSH这个标志位表示的是什么含义呢? 在什么时候用呢?
PUSH标志位所表达的是发送方通知接收方传输层应该尽快的将这个报文段交给应用层。
传输层及以下的数据往往是由系统所带的协议栈进行处理的,客户端在收到一个个报文之后,经由协议 栈解封装之后会立马把数据交给应用层去处理吗?
如果说在收到报文之后立马就交给上层,这时候应用层由于数据不全,可能也不会进行处理。而且每来一个报文就交一次,效率很低。因此传输层一般会是隔几个报文,统一上交数据。什么时候上交数据呢,就是在发送方将PUSH标志位置1的时候。那么什么 时候标志位会置1呢,通常是发送端觉得传输的数据应用层可以进行处理了的时候。
举个例子来说,TLS 协议中的的证书交换部分,通常证书链的大小在3K-4K左右,一般分三个报文来进行传输。只有当这3K-4K的报文传输完毕之后,那么数据形成完整的证书链,这个时候对于接收方才是有意义的(可以进行证书链的验证),单纯的一个报文无异于乱码。因此在TLS连接中,通常会发现证书的第三个报文同上设置了push位,是发送方来告知接收方,可以把数据送往tcp的上层了,因为这些报文已经组成了有意义的内容了。同样接收方在解析了TCP的PUSH字段后,也会清空自己的缓冲区,向上 层交数据。
图1是使用百度搜索”CSDN 村中少年”关键词同时抓取报文中的一条数据流,表示的就是上述所述的场景:
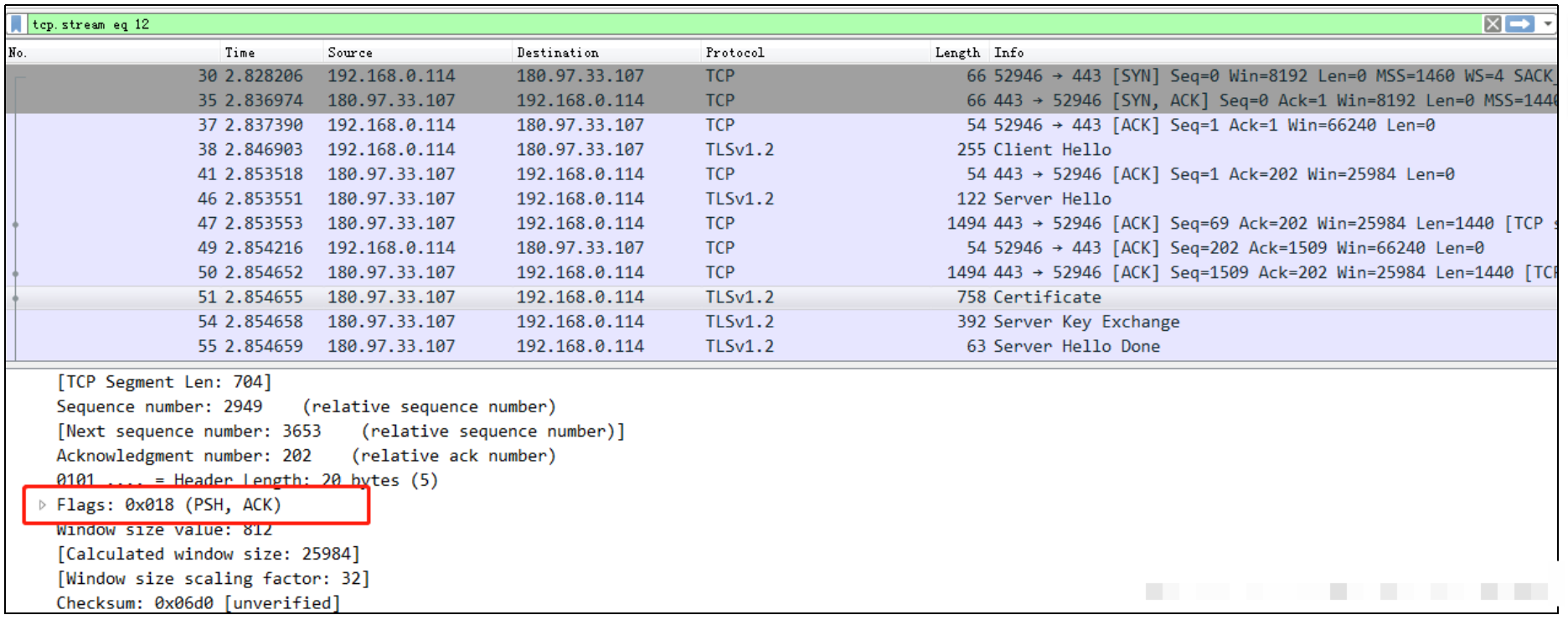
下面再以一个HTTP报文为例说明PUSH的作用。
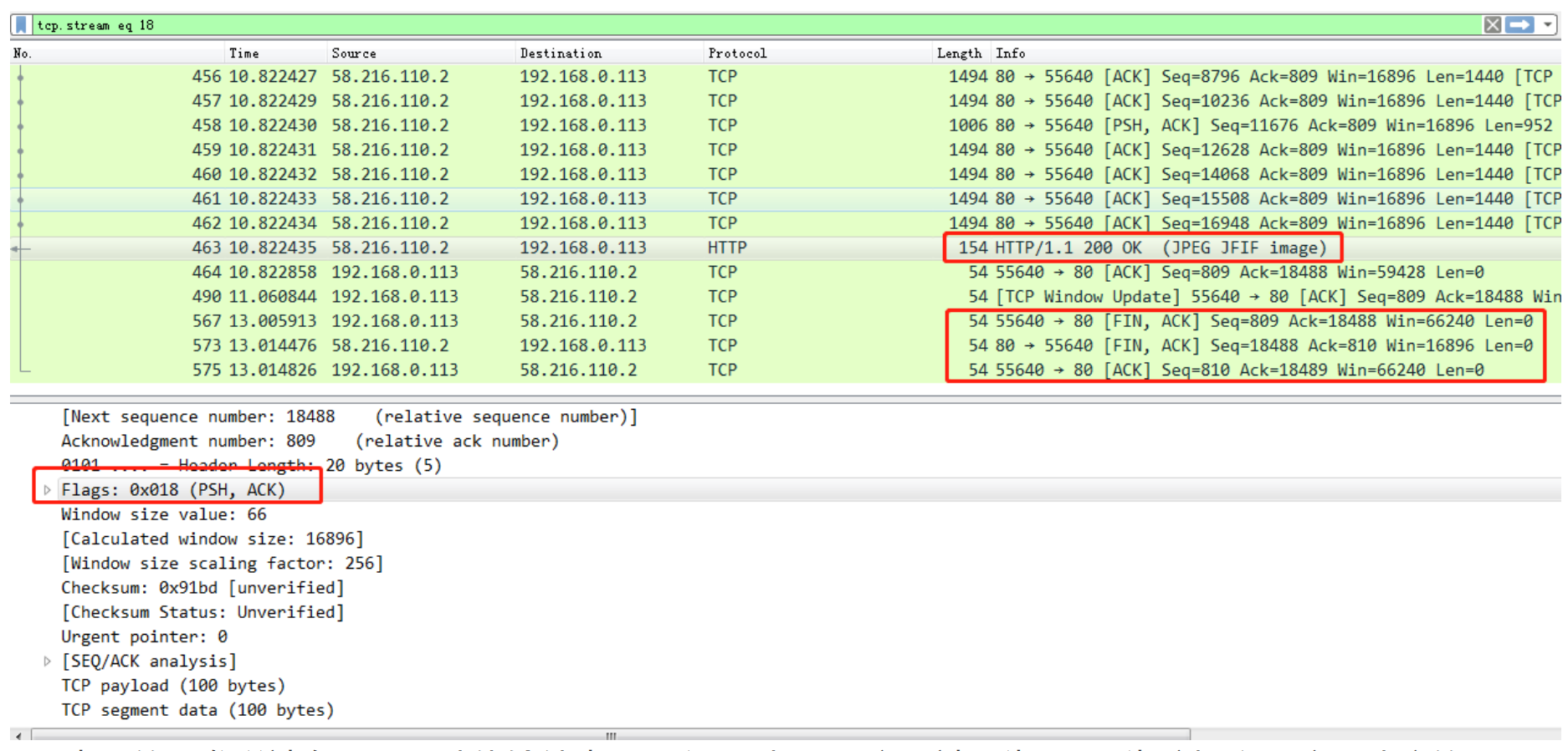
图2表示的是发送端在一个图片传输结束,可以看到PUSH字段被置为1,因为该报文是该图片流的最后 一个报文,接下来就是四次挥手结束该流了。因此这个时候就需要将该报文交给应用层,让应用层进行 显示等处理。
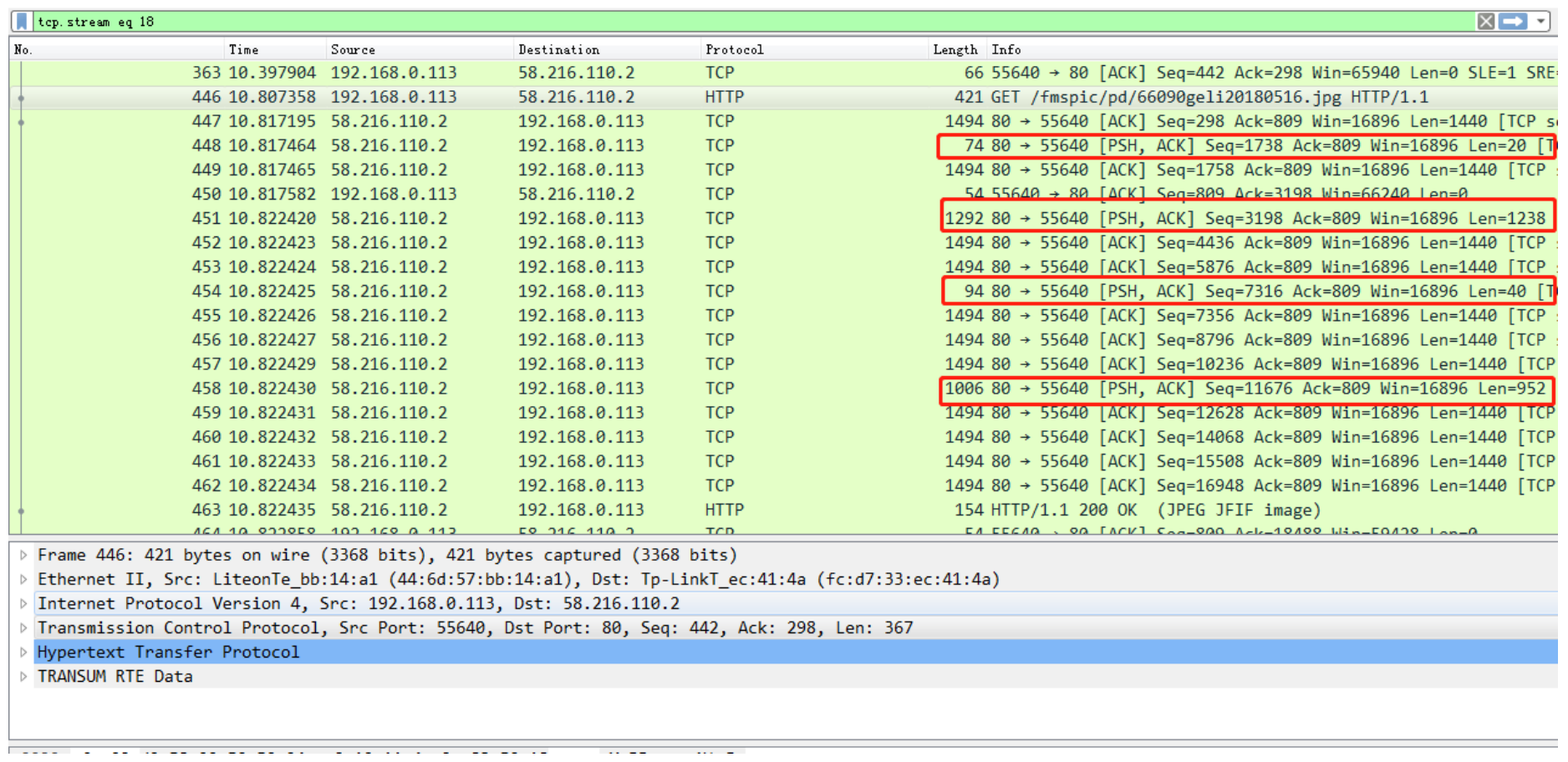
看一下图片流传输过程中哪些报文PUSH字段被设置为1了。 对于http来说,多媒体文件,像图片等一般来说比较大,不可能像证书链完全传输完成之后,仅仅在最 后一个报文在再通知接收方向上层扔数据。因此我们看到传输过程中每隔一些报文,PUSH字段就设置上了。
由于通常网络较好的时候,数据会以满包状态进行传输,当然这里面是1494个字节,通常当一段数据传 输完毕就会出现包长度下降,这时候PUSH就置1,提示传输层尽快刷新数据交由应用层处理。 上述就是对于PUSH标志位的理解,有可能在看TCP/IP协议的时候并不是对此很清晰,但是结合实际的 传输过程,理解起来应该很容易。
抓取特定状态的包

抓取 tcp 端口为80的tcp-syn的状态包
tcpdump -i eth1 tcp and port 80 and 'tcp[tcpflags] == tcp-syn'
failover故障转移
在计算机术语中,故障转移(英语:failover)
当集群里边的正常服务的节点,出现异常不能服务的时候, 备用的节点,能接替他们的工作。
即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工 作。 故障转移(failover)与交换转移操作基本相同,只是故障转移通常是自动完成的,没有警告提醒手动完成,而交换转移需要手动进行。
auto-failover自动故障转移
首先我们先删除之前的所有节点,然后重新部署节点
82.157.173.74:7002> cluster nodes
75a2171583c382346d3025bfa40309dbc999c573 172.22.0.2:7002@17002 myself,master - 0 1703647185000 2 connected 5461-10922
acdef21116be46b823b1fe7137c06ec97f3541ec 82.157.173.74:7006@17006 slave b30013511d71b8a4c3f20725a30edb5b4d8ccec0 0 1703647185817 6 connected
ad2a7b59c81911a9adc2a612e65311f30efd2366 82.157.173.74:7001@17001 master - 0 1703647187000 1 connected 0-5460
b30013511d71b8a4c3f20725a30edb5b4d8ccec0 82.157.173.74:7003@17003 master - 0 1703647183000 3 connected 10923-16383
bc95144a0fe1192e0741860c299707c99a6e02c3 82.157.173.74:7005@17005 slave 75a2171583c382346d3025bfa40309dbc999c573 0 1703647186000 5 connected
1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 82.157.173.74:7004@17004 slave ad2a7b59c81911a9adc2a612e65311f30efd2366 0 1703647187819 4 connected现在7001是主节点,7004是从节点
然后将7001节点手动关闭
[root@VM-24-13-centos data]# docker-compose stop redis-cluster-01
Stopping redis-cluster-01 ... done随便进入一个节点容器,再来看节点信息
82.157.173.74:7002> cluster nodes
75a2171583c382346d3025bfa40309dbc999c573 172.22.0.2:7002@17002 myself,master - 0 1703650184000 2 connected 5461-10922
acdef21116be46b823b1fe7137c06ec97f3541ec 82.157.173.74:7006@17006 slave b30013511d71b8a4c3f20725a30edb5b4d8ccec0 0 1703650182957 6 connected
ad2a7b59c81911a9adc2a612e65311f30efd2366 82.157.173.74:7001@17001 master,fail - 1703650089845 1703650088743 1 disconnected
b30013511d71b8a4c3f20725a30edb5b4d8ccec0 82.157.173.74:7003@17003 master - 0 1703650182000 3 connected 10923-16383
bc95144a0fe1192e0741860c299707c99a6e02c3 82.157.173.74:7005@17005 slave 75a2171583c382346d3025bfa40309dbc999c573 0 1703650184960 5 connected
1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 82.157.173.74:7004@17004 master - 0 1703650183959 8 connected 0-5460此时可以看到7001已经变成了fail状态,7004变成了主节点
这时候将7001恢复
[root@VM-24-13-centos data]# docker-compose up -d redis-cluster-01
Starting redis-cluster-01 ... done再去看节点信息
[root@VM-24-13-centos data]# docker exec -it redis-cluster-02 redis-cli -c -h 82.157.173.74 -p 7002
82.157.173.74:7002> cluster nodes
75a2171583c382346d3025bfa40309dbc999c573 172.22.0.2:7002@17002 myself,master - 0 1703650223000 2 connected 5461-10922
acdef21116be46b823b1fe7137c06ec97f3541ec 82.157.173.74:7006@17006 slave b30013511d71b8a4c3f20725a30edb5b4d8ccec0 0 1703650224055 6 connected
ad2a7b59c81911a9adc2a612e65311f30efd2366 82.157.173.74:7001@17001 slave 1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 0 1703650223054 8 connected
b30013511d71b8a4c3f20725a30edb5b4d8ccec0 82.157.173.74:7003@17003 master - 0 1703650220000 3 connected 10923-16383
bc95144a0fe1192e0741860c299707c99a6e02c3 82.157.173.74:7005@17005 slave 75a2171583c382346d3025bfa40309dbc999c573 0 1703650222000 5 connected
1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 82.157.173.74:7004@17004 master - 0 1703650222052 8 connected 0-5460发现7001变成了7004的从节点,完成了一次故障的转移
故障转移时间
可以估算出故障转移时间:
1、主观下线状态消息传播时间 <=cluster-node-timeout/2。
消息通信机制对超过cluster-node-timeout/2未通信节点会发起ping消息,消息体在选择包含哪些节点 时会优先选取下线状态节点
2、主观下线(pfail)识别时间 = cluster-node-timeout
所以通常这段时间内能够收集到半数以上主节点的pfail报告从而完成故障发现。
3、从节点转移时间<=1000毫秒
由于存在延迟发起选举机制,偏移量最大的从节点会最多延迟一秒发起选举。通常第一次选举就会成 功,所以从节点执行转移时间在1秒以内。
根据以上分析可以预估出故障转移时间,如下
failover-time(毫秒) <= cluster-node-timeout/2 + cluster-node-timeout + 1000
因此,故障转移时间跟cluster-node-timeout参数息息相关,默认15秒。
配置时可以根据业务容忍度做出适当调整,但不是越小越好
manu-failover手动故障转移
有的时候在主节点没有任何问题的情况下,强制手动故障转移也是很有必要的
比如想要升级主节点的 Redis进程,我们可以通过故障转移 将master其转为slave,再进行升级操作来 避免对集群的可用性造成很大的影响。
Redis集群使用 cluster failover 命令来进行故障转移,不过要在被转移的主节点的slave从节点上,执行 该 cluster failover 命令
也就是说,使用redis-cli连接slave节点并执行 cluster failover命令进行转移。
现在的集群节点信息
[root@VM-24-13-centos data]# docker exec -it redis-cluster-02 redis-cli -c -h 82.157.173.74 -p 7002
82.157.173.74:7002> cluster nodes
75a2171583c382346d3025bfa40309dbc999c573 172.22.0.2:7002@17002 myself,master - 0 1703650223000 2 connected 5461-10922
acdef21116be46b823b1fe7137c06ec97f3541ec 82.157.173.74:7006@17006 slave b30013511d71b8a4c3f20725a30edb5b4d8ccec0 0 1703650224055 6 connected
ad2a7b59c81911a9adc2a612e65311f30efd2366 82.157.173.74:7001@17001 slave 1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 0 1703650223054 8 connected
b30013511d71b8a4c3f20725a30edb5b4d8ccec0 82.157.173.74:7003@17003 master - 0 1703650220000 3 connected 10923-16383
bc95144a0fe1192e0741860c299707c99a6e02c3 82.157.173.74:7005@17005 slave 75a2171583c382346d3025bfa40309dbc999c573 0 1703650222000 5 connected
1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 82.157.173.74:7004@17004 master - 0 1703650222052 8 connected 0-54607001是从节点,7004是主节点,进行转移
首先需要进入从节点的容器内,然后执行cluster failover
[root@VM-24-13-centos data]# docker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 7001
82.157.173.74:7001> cluster failover
OK
82.157.173.74:7001> cluster nodes
bc95144a0fe1192e0741860c299707c99a6e02c3 82.157.173.74:7005@17005 slave 75a2171583c382346d3025bfa40309dbc999c573 0 1703651425169 5 connected
acdef21116be46b823b1fe7137c06ec97f3541ec 82.157.173.74:7006@17006 slave b30013511d71b8a4c3f20725a30edb5b4d8ccec0 0 1703651424000 6 connected
ad2a7b59c81911a9adc2a612e65311f30efd2366 172.22.0.4:7001@17001 myself,master - 0 1703651422000 9 connected 0-5460
1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d 82.157.173.74:7004@17004 slave ad2a7b59c81911a9adc2a612e65311f30efd2366 0 1703651424167 9 connected
b30013511d71b8a4c3f20725a30edb5b4d8ccec0 82.157.173.74:7003@17003 master - 0 1703651423000 3 connected 10923-16383
75a2171583c382346d3025bfa40309dbc999c573 82.157.173.74:7002@17002 master - 0 1703651426171 2 connected 5461-10922发现7001变成的了主节点,7004变成了从节点,当我我们想再次执行时会发现报错
82.157.173.74:7001> cluster failover
(error) ERR You should send CLUSTER FAILOVER to a replica说明这个命令只能在从节点使用
节点的移除
比如我们将7004变成从节点后,需要将这个节点删除,可以使用下面的命令
docker exec -it redis-cluster-01 redis-cli --cluster del-node 82.157.173.74:7004 1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d
后面跟着的是ID,7004节点的ID
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-01 redis-cli --cluster del-node 82.157.173.74:7004 1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d
>>> Removing node 1dbb7e2d85eb1cb9257e02bb69a42ea8d66d4d6d from cluster 82.157.173.74:7004
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 7001
82.157.173.74:7001> cluster nodes
bc95144a0fe1192e0741860c299707c99a6e02c3 82.157.173.74:7005@17005 slave 75a2171583c382346d3025bfa40309dbc999c573 0 1703660806260 5 connected
acdef21116be46b823b1fe7137c06ec97f3541ec 82.157.173.74:7006@17006 slave b30013511d71b8a4c3f20725a30edb5b4d8ccec0 0 1703660804000 6 connected
ad2a7b59c81911a9adc2a612e65311f30efd2366 172.22.0.4:7001@17001 myself,master - 0 1703660805000 9 connected 0-5460
b30013511d71b8a4c3f20725a30edb5b4d8ccec0 82.157.173.74:7003@17003 master - 0 1703660805257 3 connected 10923-16383
75a2171583c382346d3025bfa40309dbc999c573 82.157.173.74:7002@17002 master - 0 1703660805000 2 connected 5461-10922
82.157.173.74:7001> 再次进入容器内看节点信息,就会发现7004节点已经被删除了
redis-cluster动态扩容实操
其实这里的扩容操作就是上面的命令操作的一次整合实践
节点规划
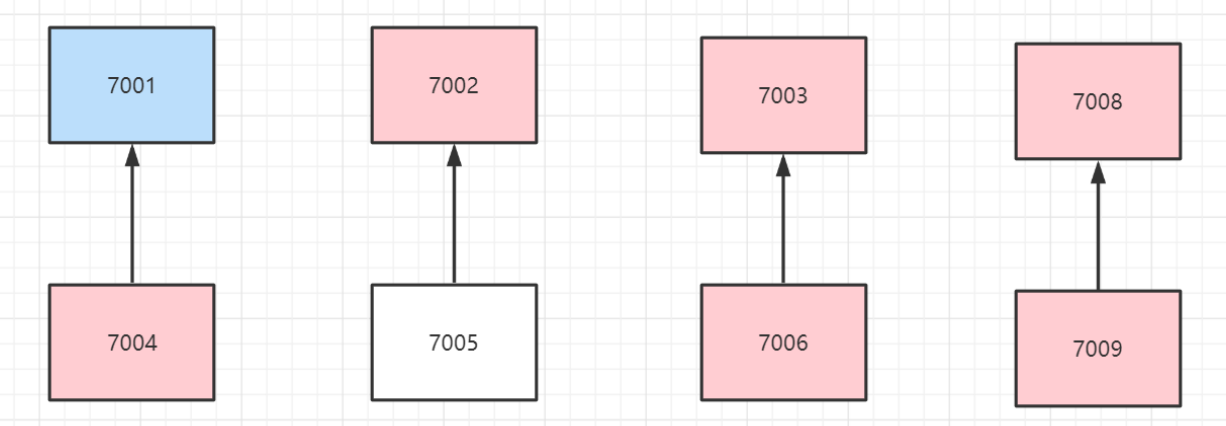
首先回归最原始的状态,将6个节点重新删除并新建完后的节点信息
[root@VM-24-13-centos data]# docker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 700182.157.173.74:7001> cluster nodes
b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005@17005 slave 0785e273258c3598c632e2ca2b5fc435993d685e 0 1703666669000 5 connected
bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004@17004 slave 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 0 1703666672000 4 connected
38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003@17003 master - 0 1703666671412 3 connected 10923-16383
1a7c3c6eb914d02267ba0c5f467924c99736ad8a 172.22.0.4:7001@17001 myself,master - 0 1703666671000 1 connected 0-5460
0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002@17002 master - 0 1703666672413 2 connected 5461-10922
257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006@17006 slave 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 0 1703666670000 6 connected
82.157.173.74:7001> 然后我们新增2个节点7008和7009,分别配置它们的redis.conf和docker-compose.yml,内容与之前的配置一样,换一下端口就行
daemonize no
port 7008
pidfile /var/run/redis.pid
dir "/data"
logfile "/data/redis.log"
#启动集群模式
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
#bind 192.168.56.121
#关闭保护模式
protected-mode no
#开启aof
appendonly yes
#默认60
repl-timeout 600
#默认10
repl-ping-replica-period 100
#如果要设置密码需要增加如下配置:
#requirepass 123321 #设置redis访问密码
#masterauth 123321 #设置集群节点间访问密码,跟上面一致daemonize no
port 7009
pidfile /var/run/redis.pid
dir "/data"
logfile "/data/redis.log"
#启动集群模式
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
#bind 192.168.56.121
#关闭保护模式
protected-mode no
#开启aof
appendonly yes
#默认60
repl-timeout 600
#默认10
repl-ping-replica-period 100
#如果要设置密码需要增加如下配置:
#requirepass 123321 #设置redis访问密码
#masterauth 123321 #设置集群节点间访问密码,跟上面一致docker-compose要特别注意一下,一定要保证这两个新节点和之前的集群要在同一个网络下才能建立连接
version: '3'
services:
redis-cluster-08:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-08
restart: always
environment:
- REDIS_PORT=7008
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7008:7008
- 17008:17008
volumes:
- /root/data/ext/7008/data:/data
- /root/data/ext/7008/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
redis-cluster-09:
image: publicisworldwide/redis-cluster
container_name: redis-cluster-09
restart: always
environment:
- REDIS_PORT=7009
- TZ=Asia/Shanghai
networks:
- default
ports:
- 7009:7009
- 17009:17009
volumes:
- /root/data/ext/7009/data:/data
- /root/data/ext/7009/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server","/usr/local/etc/redis/redis.conf"]
networks:
default:
external:
name: ha-network-overlay
然后启动两个节点
[root@VM-24-13-centos ext]# docker-compose up -d
Creating redis-cluster-08 ... done
Creating redis-cluster-09 ... done
[root@VM-24-13-centos ext]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fb2f6e3d6a50 publicisworldwide/redis-cluster "/usr/local/bin/entr…" 2 seconds ago Up 1 second 6379/tcp, 0.0.0.0:7009->7009/tcp, :::7009->7009/tcp, 7000/tcp, 0.0.0.0:17009->17009/tcp, :::17009->17009/tcp redis-cluster-09
6bbf26401610 publicisworldwide/redis-cluster "/usr/local/bin/entr…" 2 seconds ago Up 1 second 6379/tcp, 0.0.0.0:7008->7008/tcp, :::7008->7008/tcp, 7000/tcp, 0.0.0.0:17008->17008/tcp, :::17008->17008/tcp redis-cluster-08
1e45a3bc5570 publicisworldwide/redis-cluster "/usr/local/bin/entr…" About a minute ago Up About a minute 6379/tcp, 0.0.0.0:7002->7002/tcp, :::7002->7002/tcp, 7000/tcp, 0.0.0.0:17002->17002/tcp, :::17002->17002/tcp redis-cluster-02
932580b5222d publicisworldwide/redis-cluster "/usr/local/bin/entr…" About a minute ago Up About a minute 6379/tcp, 0.0.0.0:7001->7001/tcp, :::7001->7001/tcp, 7000/tcp, 0.0.0.0:17001->17001/tcp, :::17001->17001/tcp redis-cluster-01
b10162f2cde5 publicisworldwide/redis-cluster "/usr/local/bin/entr…" About a minute ago Up About a minute 6379/tcp, 0.0.0.0:7006->7006/tcp, :::7006->7006/tcp, 7000/tcp, 0.0.0.0:17006->17006/tcp, :::17006->17006/tcp redis-cluster-06
156f4cb144ca publicisworldwide/redis-cluster "/usr/local/bin/entr…" About a minute ago Up About a minute 6379/tcp, 0.0.0.0:7004->7004/tcp, :::7004->7004/tcp, 7000/tcp, 0.0.0.0:17004->17004/tcp, :::17004->17004/tcp redis-cluster-04
32a3c4a804a0 publicisworldwide/redis-cluster "/usr/local/bin/entr…" About a minute ago Up About a minute 6379/tcp, 0.0.0.0:7005->7005/tcp, :::7005->7005/tcp, 7000/tcp, 0.0.0.0:17005->17005/tcp, :::17005->17005/tcp redis-cluster-05
31562ba5ed7b publicisworldwide/redis-cluster "/usr/local/bin/entr…" About a minute ago Up About a minute 6379/tcp, 0.0.0.0:7003->7003/tcp, :::7003->7003/tcp, 7000/tcp, 0.0.0.0:17003->17003/tcp, :::17003->17003/tcp redis-cluster-03启动完成后,添加两个节点到集群
docker run --rm -it nien/redis-trib add-node 82.157.173.74:7008 82.157.173.74:7001
docker run --rm -it nien/redis-trib add-node 82.157.173.74:7009 82.157.173.74:7001
[root@VM-24-13-centos ext]# docker run --rm -it nien/redis-trib add-node 82.157.173.74:7008 82.157.173.74:7001
>>> Adding node 82.157.173.74:7008 to cluster 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 82.157.173.74:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005@17005
slots: (0 slots) slave
replicates 0785e273258c3598c632e2ca2b5fc435993d685e
S: bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004@17004
slots: (0 slots) slave
replicates 1a7c3c6eb914d02267ba0c5f467924c99736ad8a
M: 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003@17003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
M: 0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002@17002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006@17006
slots: (0 slots) slave
replicates 38843dfc2d9a65d75294cc831e8e0c0caa4406a6
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 82.157.173.74:7008 to make it join the cluster.
[OK] New node added correctly.
[root@VM-24-13-centos ext]# docker run --rm -it nien/redis-trib add-node 82.157.173.74:7009 82.157.173.74:7001
>>> Adding node 82.157.173.74:7009 to cluster 82.157.173.74:7001
>>> Performing Cluster Check (using node 82.157.173.74:7001)
M: 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 82.157.173.74:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005@17005
slots: (0 slots) slave
replicates 0785e273258c3598c632e2ca2b5fc435993d685e
S: bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004@17004
slots: (0 slots) slave
replicates 1a7c3c6eb914d02267ba0c5f467924c99736ad8a
M: 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003@17003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
M: b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 82.157.173.74:7008@17008
slots: (0 slots) master
0 additional replica(s)
M: 0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002@17002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006@17006
slots: (0 slots) slave
replicates 38843dfc2d9a65d75294cc831e8e0c0caa4406a6
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 82.157.173.74:7009 to make it join the cluster.
[OK] New node added correctly.
[root@VM-24-13-centos ext]# docker exec -it redis-cluster-01 redis-cli -c -h 82.157.173.74 -p 7001
82.157.173.74:7001> cluster nodes
b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005@17005 slave 0785e273258c3598c632e2ca2b5fc435993d685e 0 1703667949000 5 connected
bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004@17004 slave 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 0 1703667951573 4 connected
38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003@17003 master - 0 1703667948000 3 connected 10923-16383
b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 82.157.173.74:7008@17008 master - 0 1703667950571 7 connected
1a7c3c6eb914d02267ba0c5f467924c99736ad8a 172.22.0.4:7001@17001 myself,master - 0 1703667948000 1 connected 0-5460
f51a2a7fd5045aa821eb97f10a77562d07fb5d84 82.157.173.74:7009@17009 master - 0 1703667952575 0 connected
0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002@17002 master - 0 1703667951000 2 connected 5461-10922
257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006@17006 slave 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 0 1703667950000 6 connected
82.157.173.74:7001> 此时添加完成后,7008与7009都是主节点,没有分配槽位
然后配置主从关系,7008是7009的主节点,先进入7009,然后使用命令
cluster replicate b8f35ac2ef62cd175f049940dbf7be6f0e335ca4
[root@VM-24-13-centos ext]# docker exec -it redis-cluster-09 redis-cli -c -p 7009
127.0.0.1:7009> cluster replicate b8f35ac2ef62cd175f049940dbf7be6f0e335ca4
OK
127.0.0.1:7009> cluster nodes
b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005@17005 slave 0785e273258c3598c632e2ca2b5fc435993d685e 0 1703668179000 2 connected
bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004@17004 slave 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 0 1703668179000 1 connected
0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002@17002 master - 0 1703668180000 2 connected 5461-10922
38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003@17003 master - 0 1703668182034 3 connected 10923-16383
f51a2a7fd5045aa821eb97f10a77562d07fb5d84 172.22.0.8:7009@17009 myself,slave b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 0 1703668181000 0 connected
1a7c3c6eb914d02267ba0c5f467924c99736ad8a 82.157.173.74:7001@17001 master - 0 1703668180000 1 connected 0-5460
b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 82.157.173.74:7008@17008 master - 0 1703668180034 7 connected
257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006@17006 slave 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 0 1703668181032 3 connected设置完主从关系后,我们再去分配主节点的槽位
总哈希槽是16384,平均分给3组,每组是5461,
现在加多一组到集群,变成4组,平均每组 16384/4=4096,
那么每组要抽取多少哈希槽给7008呢?
5461- 4096=1365
执行reshard进行从3组中抽取1365哈希缓存分配给7008
docker exec -it redis-cluster-08 redis-cli --cluster reshard 82.157.173.74:7008
[root@VM-24-13-centos ext]# docker exec -it redis-cluster-08 redis-cli --cluster reshard 82.157.173.74:7008
>>> Performing Cluster Check (using node 82.157.173.74:7008)
M: b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 82.157.173.74:7008
slots: (0 slots) master
1 additional replica(s)
S: f51a2a7fd5045aa821eb97f10a77562d07fb5d84 82.157.173.74:7009
slots: (0 slots) slave
replicates b8f35ac2ef62cd175f049940dbf7be6f0e335ca4
S: b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005
slots: (0 slots) slave
replicates 0785e273258c3598c632e2ca2b5fc435993d685e
M: 0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 82.157.173.74:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006
slots: (0 slots) slave
replicates 38843dfc2d9a65d75294cc831e8e0c0caa4406a6
M: 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004
slots: (0 slots) slave
replicates 1a7c3c6eb914d02267ba0c5f467924c99736ad8a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? b8f35ac2ef62cd175f049940dbf7be6f0e335ca4
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
Ready to move 4096 slots.
Source nodes:
M: 0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 82.157.173.74:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
Destination node:
M: b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 82.157.173.74:7008
slots: (0 slots) master
1 additional replica(s)
Resharding plan:
Moving slot 5461 from 0785e273258c3598c632e2ca2b5fc435993d685e
…………
[root@VM-24-13-centos ext]# docker exec -it redis-cluster-08 redis-cli -c -p 7008
127.0.0.1:7008> cluster nodes
f51a2a7fd5045aa821eb97f10a77562d07fb5d84 82.157.173.74:7009@17009 slave b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 0 1703671159074 7 connected
b50aa104b4c4d9d97bb9786636a741799f006654 82.157.173.74:7005@17005 slave 0785e273258c3598c632e2ca2b5fc435993d685e 0 1703671160000 2 connected
0785e273258c3598c632e2ca2b5fc435993d685e 82.157.173.74:7002@17002 master - 0 1703671160000 2 connected 6827-10922
1a7c3c6eb914d02267ba0c5f467924c99736ad8a 82.157.173.74:7001@17001 master - 0 1703671161076 1 connected 1365-5460
257afa737866c399963376d98c823a5a58c5d2d2 82.157.173.74:7006@17006 slave 38843dfc2d9a65d75294cc831e8e0c0caa4406a6 0 1703671159000 3 connected
38843dfc2d9a65d75294cc831e8e0c0caa4406a6 82.157.173.74:7003@17003 master - 0 1703671159000 3 connected 12288-16383
bea57f7524fb0cb3f9bd4874d5babc0853149cb0 82.157.173.74:7004@17004 slave 1a7c3c6eb914d02267ba0c5f467924c99736ad8a 0 1703671160076 1 connected
b8f35ac2ef62cd175f049940dbf7be6f0e335ca4 172.22.0.9:7008@17008 myself,master - 0 1703671158000 7 connected 0-1364 5461-6826 10923-12287
127.0.0.1:7008> 上面的节点我们可以输入 all ,就从所有的节点上获取槽位,平均的获取,之后我们再次查看节点信息,会发现7008获取的了槽位,是分段的槽位,因为是从其他主节点平均获取的
主从复制的核心原理
主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。
- 前者称为主节点(master),后者称为从节点(slave);
- 数据的复制是单向的,只能由主节点到从节点。
- 默认情况下,每台Redis服务器都是主节点;
- 且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服 务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是 在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用、高并发基石:主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用 的基础。
开启主从复制的方式
需要注意,主从复制的开启,完全是在从节点发起的;不需要我们在主节点做任何事情
从节点开启主从复制,有3种方式:
- 在从服务器的配置文件中加入:slaveof
- redis-server启动命令后加入 –slaveof
- Redis服务器启动后,直接通过客户端执行命令:slaveof ,则该Redis实例成为从节点。
Redis Slaveof 命令可以将当前服务器转变为指定服务器的从属服务器(slave server)。
如果当前服务器已经是某个主服务器(master server)的从属服务器,那么执行 SLAVEOF host port 将使当前服务器停止对旧主服务器的同步,丢弃旧数据集,转而开始对新主服务器进行同步。
另外,对一个从属服务器执行命令 SLAVEOF NO ONE 将使得这个从属服务器关闭复制功能,并从从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃。
利用『 SLAVEOF NO ONE 不会丢弃同步所得数据集』这个特性,可以在主服务器失败的时候,将从属服务器用作新的主服务器,从而实现无间断运行。
redis 127.0.0.1:6379> SLAVEOF host port主从复制的大致流程
1、当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
2、如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制
master node 怎么进行 full resynchronization 全量复制?
此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件,同时还会将从客户端 client 新 收到的所有写命令缓存在内存中。
RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave
slave node 接收到RDB ,干啥呢?
会先写入本地磁盘,然后再从本地磁盘加载到内存中
3、数据同步阶段完成后,主从节点进入命令传播阶段;
在这个阶段master 将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据 的一致性。
4、部分复制
如果slave node跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会 复制给 slave 部分缺少的数据。
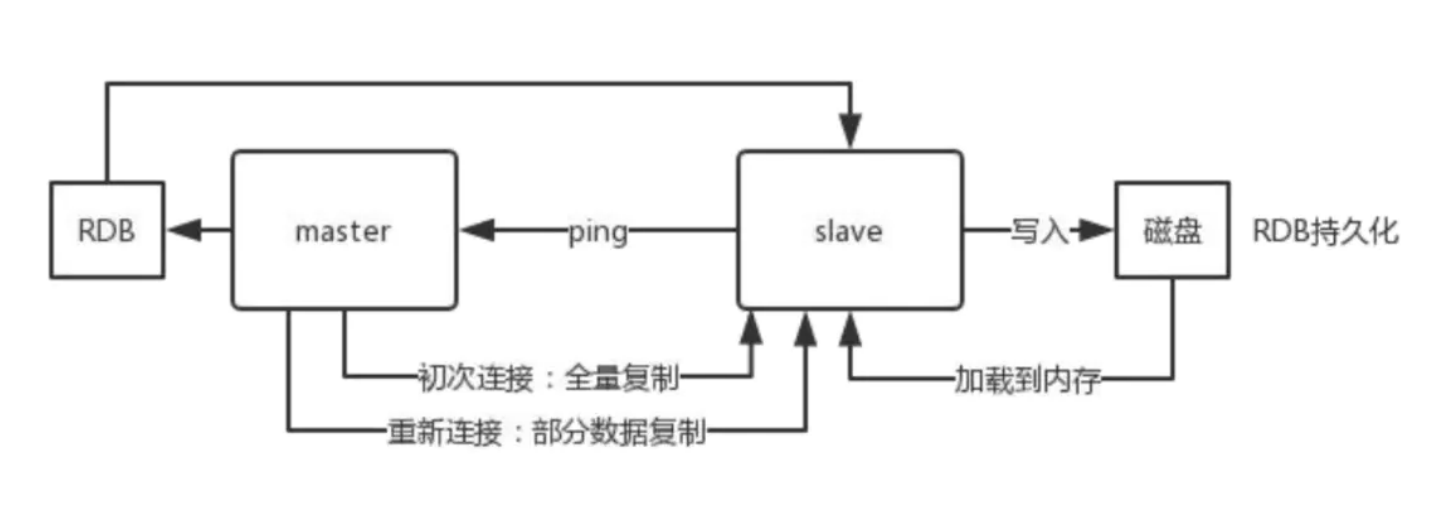
主从复制过程大体可以分为3个阶段:
- 连接建立阶段(即准备阶段)
- 数据同步阶段
- 命令传播阶段;
下面分别进行介绍。
连接建立阶段
该阶段的主要作用是在主从节点之间建立连接,为数据同步做好准备。
步骤1:保存主节点信息
从节点服务器内部维护了两个字段,即masterhost和masterport字段,用于存储主节点的ip和port信息。
需要注意的是,slaveof是异步命令,从节点完成主节点ip和port的保存后,向发送slaveof命令的客户端直接返回OK,实际的复制操作在这之后才开始进行。
这个过程中,可以看到从节点打印日志如下:

步骤2:建立socket连接
slave 从节点每秒1次调用复制定时函数replicationCron(),如果发现了有主节点可以连接,便会根据主 节点的ip和port,创建socket连接。
如果连接成功,则:
从节点:
为该socket建立一个专门处理复制工作的文件事件处理器,负责后续的复制工作,如接收RDB文件、接收命令传播等。
主节点:
接收到从节点的socket连接后(即accept之后),为该socket创建相应的客户端状态,并将从节点看做是连接到主节点的一个客户端,后面的步骤会以从节点向主节点发送命令请求的形式来进行。
这个过程中,从节点打印日志如下:

步骤3:发送ping命令
从节点成为主节点的客户端之后,发送ping命令进行首次请求,目的是:检查socket连接是否可用,以 及主节点当前是否能够处理请求。
从节点发送ping命令后,可能出现3种情况:
- 返回pong:说明socket连接正常,且主节点当前可以处理请求,复制过程继续。
- 超时:一定时间后从节点仍未收到主节点的回复,说明socket连接不可用,则从节点断开socket连 接,并重连。
- 返回pong以外的结果:如果主节点返回其他结果,如正在处理超时运行的脚本,说明主节点当前 无法处理命令,则从节点断开socket连接,并重连。
在主节点返回pong情况下,从节点打印日志如下:

步骤4:身份验证
如果从节点中设置了master auth选项,则从节点需要向主节点进行身份验证;没有设置该选项,则不需要验证。
从节点进行身份验证是通过向主节点发送auth命令进行的,auth命令的参数即为配置文件中的master auth的值。
- 则身份验证通过,复制过程继续;
- 如果不一致,则从节点断开socket连接,并重连。
步骤5:发送从节点端口信息
身份验证之后,从节点会向主节点发送其监听的端口号(前述例子中为6380),主节点将该信息保存到 该从节点对应的客户端的slave_listening_port字段中;
该端口信息除了在主节点中执行info Replication时显示以外,没有其他作用。
数据同步阶段
主从节点之间的连接建立以后,便可以开始进行数据同步,该阶段可以理解为从节点数据的初始化。
具体执行的方式是:从节点向主节点发送psync命令(Redis2.8以前是sync命令),开始同步。
数据同步阶段是主从复制最核心的阶段,根据主从节点当前状态的不同,可以分为全量复制和部分复制。
在Redis2.8以前,从节点向主节点发送sync命令请求同步数据,此时的同步方式是全量复制;
在Redis2.8及以后,从节点可以发送psync命令请求同步数据,此时根据主从节点当前状态的不同,同步 方式可能是全量复制或部分复制。后文介绍以Redis2.8及以后版本为例。
- 全量复制:用于初次复制或其他无法进行部分复制的情况,将主节点中的所有数据都发送给从节 点,是一个非常重型的操作。
- 部分复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全 量复制相比更加高效。需要注意的是,如果网络中断时间过长,导致主节点没有能够完整地保存中 断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
全量复制的过程
Redis通过psync命令进行全量复制的过程如下:
- 从节点判断无法进行部分复制,向主节点发送全量复制的请求;或从节点发送部分复制的请求,但 主节点判断无法进行部分复制;
- 主节点收到全量复制的命令后,执行bgsave,在后台生成RDB文件,并使用一个缓冲区(称为复 制缓冲区)记录从现在开始执行的所有写命令
- 主节点的bgsave执行完成后,将RDB文件发送给从节点;从节点接收完成之后,首先清除自己的 旧数据,然后载入接收的RDB文件,将数据库状态更新至主节点执行bgsave时的数据库状态
- 主节点将前述复制缓冲区中的所有写命令发送给从节点,从节点执行这些写命令,将数据库状态更 新至主节点的最新状态
- 如果从节点开启了AOF,则会触发 bgrewriteaof 的执行,从而保证AOF文件更新至主节点的最新 状态 下面是执行全量复制时,主从节点打印的日志;可以看出日志内容与上述步骤是完全对应的。
主节点的打印日志如下:

从节点打印日志如下图所示:
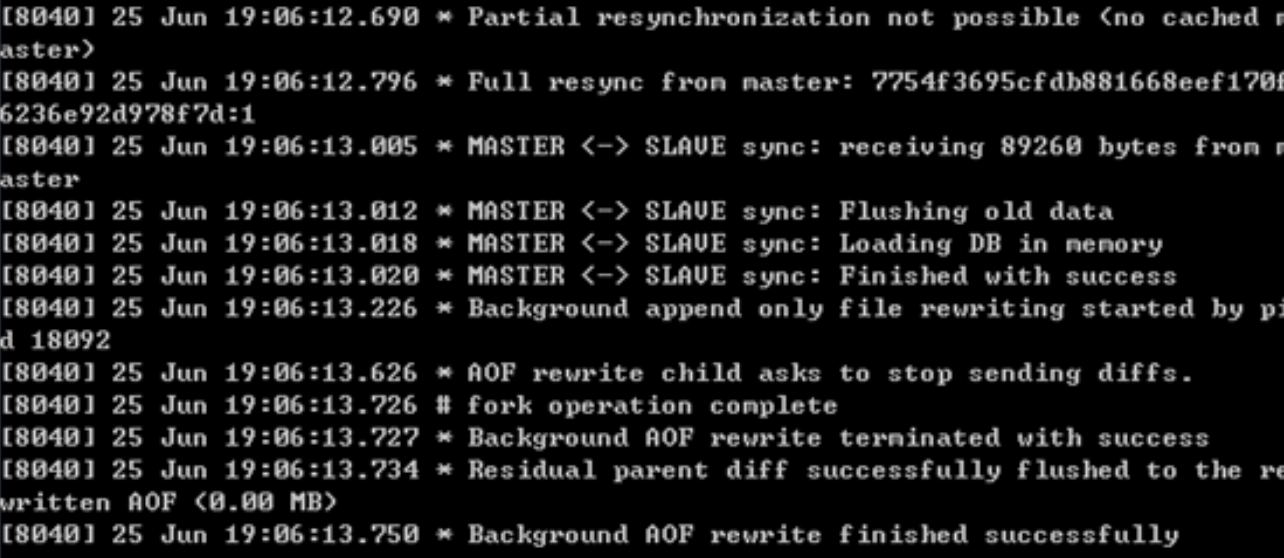
其中,有几点需要注意:
- 从节点接收了来自主节点的89260个字节的数据;
- 从节点在载入主节点的数据之前要先将老数据清除;
- 从节点在同步完数据后,调用了bgrewriteaof。
通过全量复制的过程可以看出,全量复制是非常重型的操作:
- 性能损耗:主节点通过bgsave命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页 表复制)、硬盘IO的;
- 带宽占用:主节点通过网络将RDB文件发送给从节点,对主从节点的带宽都会带来很大的消耗
- 停服载入:从节点清空老数据、载入新RDB文件的过程是阻塞的,无法响应客户端的命令;如果从 节点执行bgrewriteaof,也会带来额外的消耗
题外话:什么是Redis Bgrewriteaof ?
Redis Bgrewriteaof 命令用于异步执行一个 AOF(AppendOnly File) 文件重写操作。
Bgrewriteaof 重写会创建一个当前 AOF 文件的体积优化版本。
即使 Bgrewriteaof 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 Bgrewriteaof 成功之前不 会被修改。
注意:从 Redis 2.4 开始, AOF 重写由 Redis 自行触发, BGREWRITEAOF 仅仅用于手动触发重写操 作。
redis Bgrewriteaof 命令基本语法如下:
redis 192.168.56.121:6379> BGREWRITEAOFredis2.8 版本之前主从复制流程
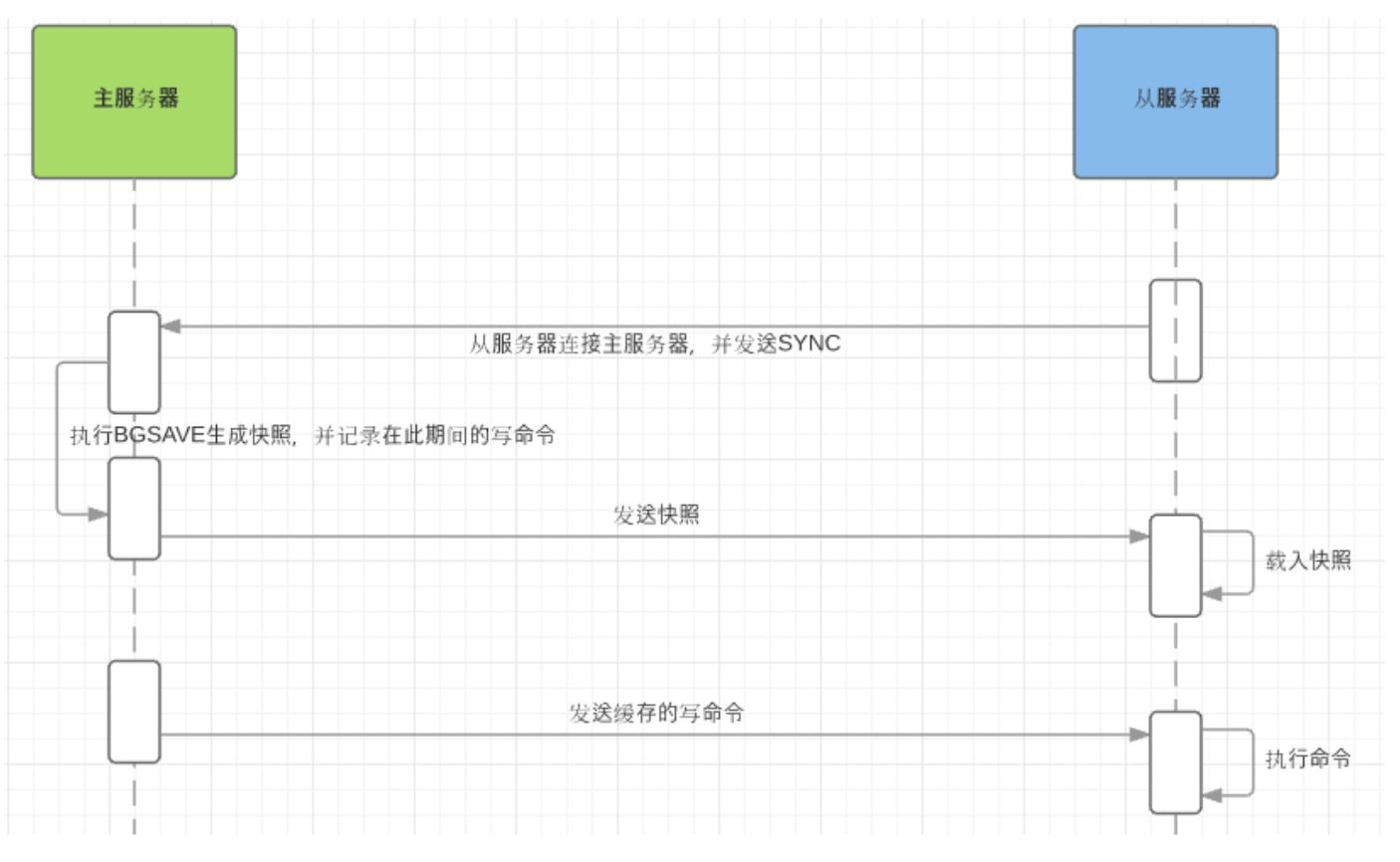
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所 有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命 令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
全量复制的弊端:
场景:(1)新创建的slave,从主机master同步数据。(2)刚宕机一小会的slave,从主机master同步数据。
前者新建的slave则从主机master全量同步数据,这没啥问题。但是后者slave可能只与主机 master存在小量的数据差异,要是全量同步肯定没有只同步差异(部分复制)的那点数据性能高
部分复制
由于全量复制在主节点数据量较大时效率太低,因此Redis2.8开始提供部分复制,用于处理网络中断时的数据同步。
部分复制的实现,依赖于三个重要的概念:
offset复制偏移量
- 主节点和从节点分别维护一个复制偏移量(offset),代表的是主节点向从节点传递的字节数;
- 主节点每次向从节点传播N个字节数据时,主节点的offset增加N;
- 从节点每次收到主节点传来的N个字节数据时,从节点的offset增加N。
offset复制偏移量的用途
offset用于判断主从节点的数据库状态是否一致:如果二者offset相同,则一致;如果offset不同,则不一致,此时可以根据两个offset找出从节点缺少的那部分数据。
例如,如果主节点的offset是1000,而从节点的offset是500,那么部分复制就需要将offset为501-1000 的数据传递给从节点。
而offset为501-1000的数据存储的位置,就是下面要介绍的复制积压缓冲区。
复制积压缓冲区( repl-backlog-buffer )
复制积压缓冲区是由主节点维护的、固定长度的、先进先出(FIFO)队列,默认大小1MB; 当主节点开始有从节点时, master创建一个积压缓冲区,其作用是备份主节点最近收到的redis命令,后 续会发送给从节点的数据。
注意,无论主节点有一个还是多个从节点,都只需要一个复制积压缓冲区。
在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;
除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset)。
由于复制积压缓冲区定长且是先进先出,所以它保存的是主节点最复制积压缓冲区近执行的写命令;时间较早的写命令会被挤出缓冲区。
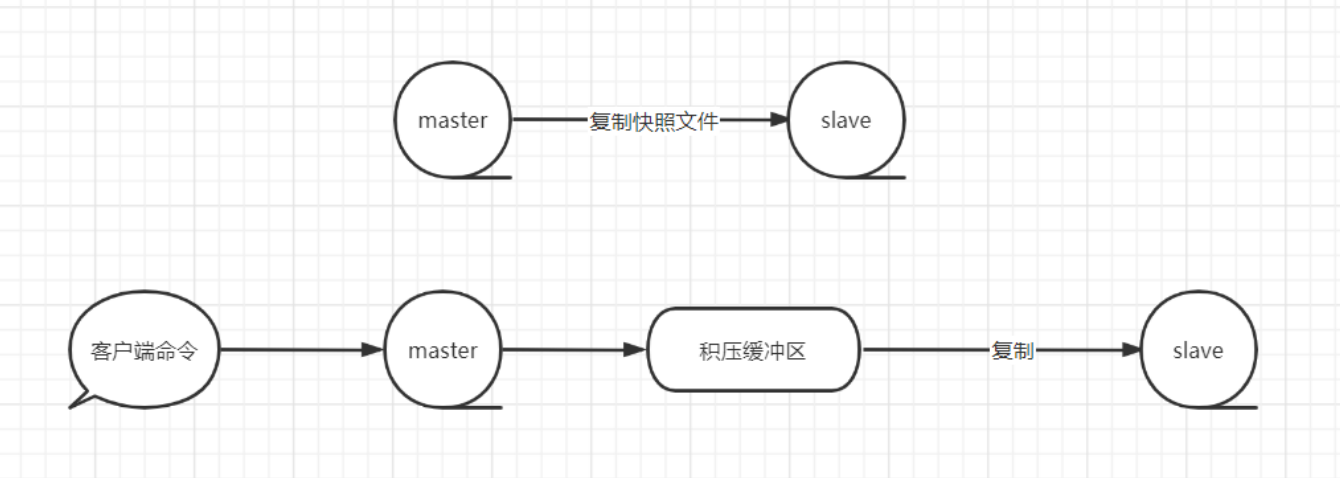
由于该缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲 区长度时,将无法执行部分复制,只能执行全量复制。
反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配 置repl-backlog-size);
例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为 100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情 况都可以使用部分复制。
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:
- 如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;
- 如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六 进制字符组成;runid用来唯一识别一个Redis节点。 通过info Server命令,可以查看节点的runid:
主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连 时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制:
- 如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试 使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况);
- 如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是 当前的主节点,只能进行全量复制
slavof命令的执行流程
在了解了复制偏移量、复制积压缓冲区、节点运行id之后
接下来,看看slavof命令的执行流程
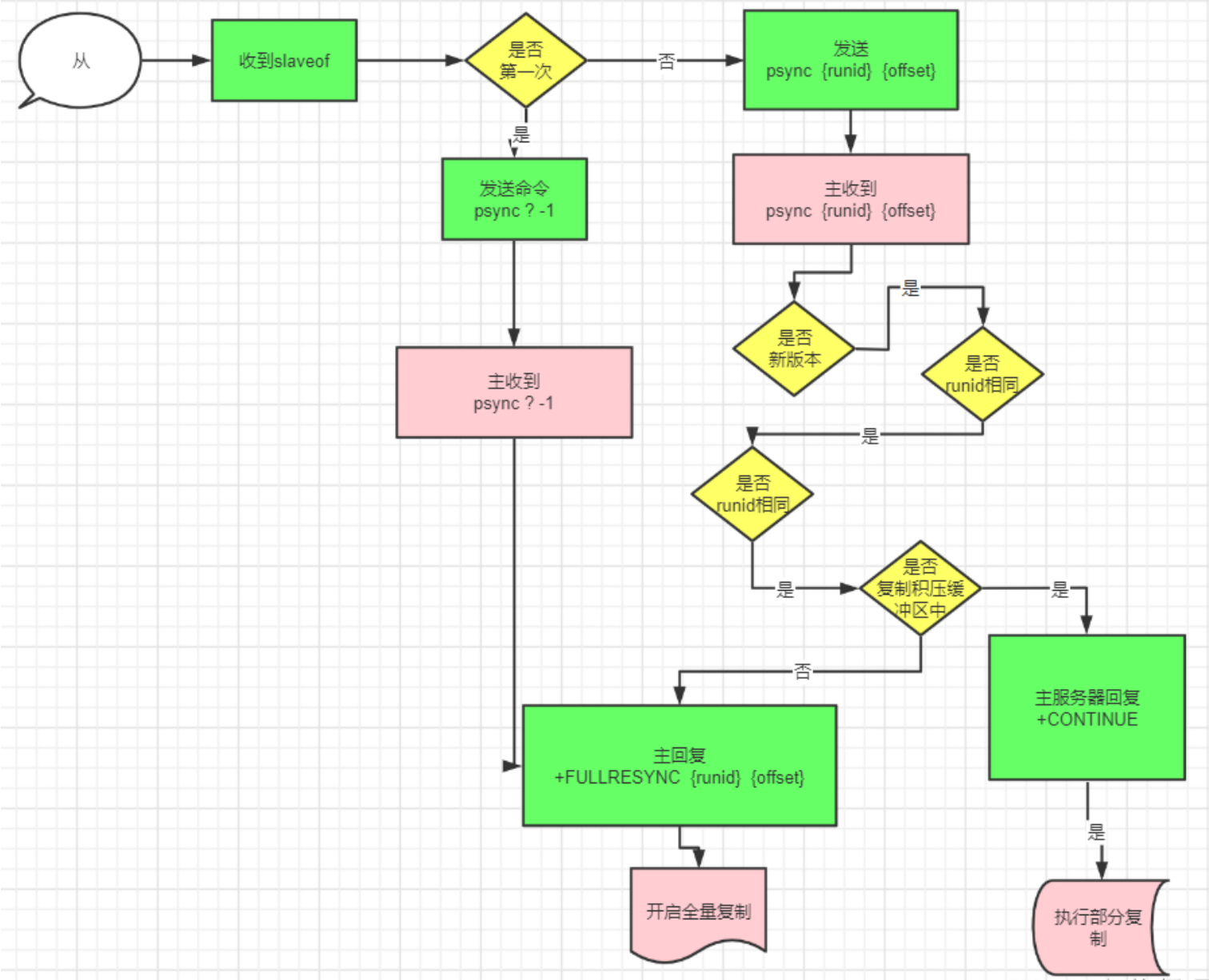
从节点收到slaveof命令之后,首先决定是使用全量复制还是部分复制:
- 首先,从节点根据当前状态,决定如何调用psync命令:
- 如果从节点之前未执行过slaveof或最近执行了slaveof no one,则从节点发送命令为psync ? -1, 向主节点请求全量复制;
- 如果从节点之前执行了slaveof,则发送命令为psync {runid} {offset},其中runid为上次复制的主 节点的runid,offset为上次复制截止时从节点保存的复制偏移量。
- 主节点根据收到的psync命令,及当前服务器状态,决定执行全量复制还是部分复制:
- 如果主节点版本低于Redis2.8,则返回-ERR回复,此时从节点重新发送sync命令执行全量复制;
- 如果主节点版本够新,且runid与从节点发送的runid相同,且从节点发送的offset之后的数据在复 制积压缓冲区中都存在,则回复+CONTINUE,表示将进行部分复制,从节点等待主节点发送其缺 少的数据即可;
- 如果主节点版本够新,但是runid与从节点发送的runid不同,或从节点发送的offset之后的数据已 不在复制积压缓冲区中(在队列中被挤出了),则回复+FULLRESYNC {runid} {offset},表示要进行 全量复制,其中runid表示主节点当前的runid,offset表示主节点当前的offset,从节点保存这两 个值,以备使用。
重新连接之后的部分复制
部分复制主要是 Redis 针对全量复制的过高开销做出的一种优化措施,使用 psync {runId} {offset} 命令 实现。
当从节点正在复制主节点时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补 发丢失的命令数据,如果主节点的复制积压缓冲区存在这部分数据,则直接发送给从节点,这样就保证了主从节点复制的一致性。
补发的这部分数据一般远远小于全量数据,所以开销很小。
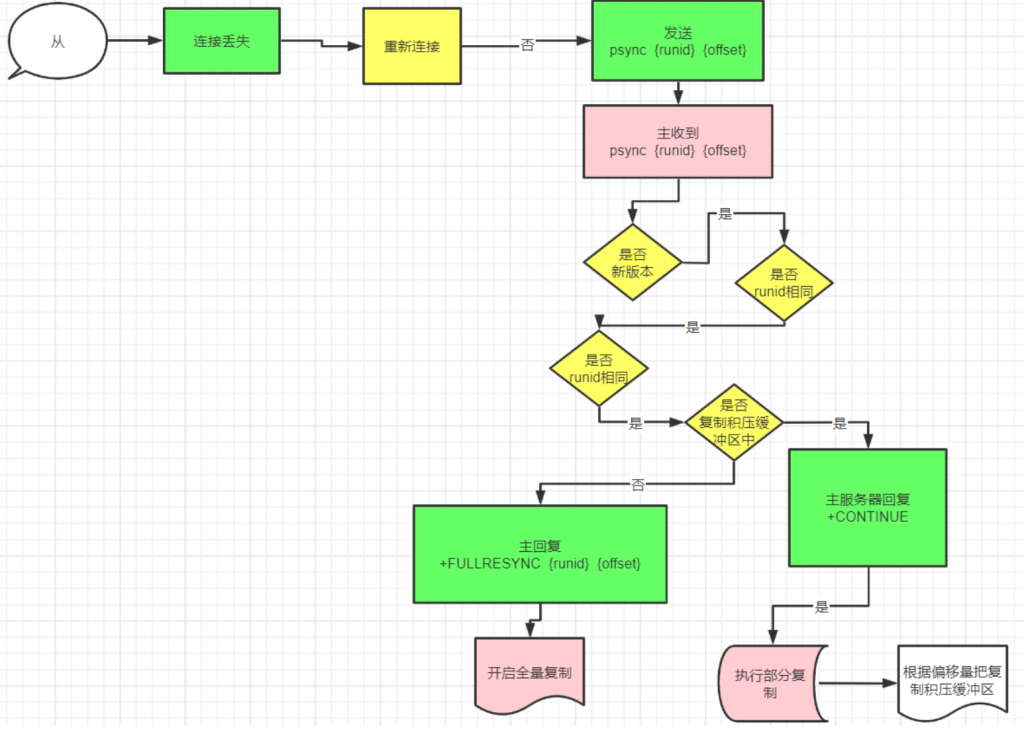
- 当主从节点之间网络出现中断时,如果超过了 repl-timeout 时间,主节点会认为从节点故障并中断复 制连接。
- 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部 存在复制积压缓冲区( repl-backlog-buffer ),依然可以保存最近一段时间的写命令数据,默认最大缓存 1MB。
- 当主从节点网络恢复后,从节点会再次连上主节点。
- 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们作 为 psync 参数发送给主节点,要求进行补发复制操作。
- 主节点接到 psync 命令后首先核对参数 runId 是否与自身一致,如果一致,说明之前复制的是当前主 节点;之后根据参数 offset 在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从 节点发送 +CONTINUE 响应,表示可以进行部分复制。
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
命令传播阶段
数据同步阶段完成后,主从节点进入命令传播阶段;
在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据 的一致性。
在命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING和REPLCONF ACK。
心跳机制对于主从复制的超时判断、数据安全等有作用。
主->从:PING
每隔指定的时间,主节点会向从节点发送PING命令
这个PING命令的作用,主要是为了让从节点进行超时判断。
PING发送的频率由 repl-ping-slave-period 参数控制,单位是秒,默认值是10s。
关于该PING命令究竟是由主节点发给从节点,还是相反,有一些争议;
因为在Redis的官方文档中,对该参数的注释中说明是从节点向主节点发送PING命令,如下图所示:

但是通过源码可以看到, PING命令是主节点会向从节点发送
可能的原因是:代码的迭代和注释的迭代,没有完全同步。 可能早期是从发给主,后面改成了主发从,而并没有配套修改注释
从->主:REPLCONF ACK
在命令传播阶段,从节点会向主节点发送REPLCONF ACK命令,频率是每秒1次;
命令格式为:REPLCONF ACK {offset},其中offset指从节点保存的复制偏移量。
REPLCONF ACK命令的作用包括:
1、实时监测主从节点网络状态:
该命令会被主节点用于复制超时的判断。
此外,在主节点中使用info Replication,可以看到其从节点的 状态中的lag值,代表的是主节点上次收到该REPLCONF ACK命令的时间间隔,在正常情况下,该值应该 是0或1,如下图所示:
127.0.0.1:7008> info Replication
# Replication
role:master
connected_slaves:1
slave0:ip=82.157.173.74,port=7009,state=online,offset=83482,lag=02、检测命令丢失:
从节点发送了自身的offset,主节点会与自己的offset对比,如果从节点数据缺失(如网络丢包),主节点会推送缺失的数据(这里也会利用复制积压缓冲区)。
注意,offset和复制积压缓冲区,不仅可以用于部分复制,也可以用于处理命令丢失等情形;
区别在于前者是在断线重连后进行的,而后者是在主从节点没有断线的情况下进行的。
3、辅助保证从节点的数量和延迟:
Redis主节点中使用min-slaves-to-write和min-slaves-max-lag参数,来保证主节点在不安全的情况下不 会执行写命令;所谓不安全,是指从节点数量太少,或延迟过高。
例如min-slaves-to-write和min-slaves-max-lag分别是3和10,含义是如果从节点数量小于3个, 或所有从节点的延迟值都大于10s,则主节点拒绝执行写命令。而这里从节点延迟值的获取,就是 通过主节点接收到REPLCONF ACK命令的时间来判断的,即前面所说的info Replication中的lag 值。
Redis Cluster基本架构
数据分片架构
在单个的 redis节点中,我们都知道redis把数据已 k-v 结构存储在内存中,使得 redis 对数据的读写非常之快。
Redis Cluster 是去中心化的,它将所有数据分区存储。也就是说当多个 Redis 节点搭建成集群后,每 个节点只负责自己应该管理的那部分数据,相互之间存储的数据是不同的。
Redis Cluster 将全部的键空间划分为16384块,每一块空间称之为槽(slot),又将这些槽及槽所对应 的 k-v 划分给集群中的每个主节点负责。
3个节点的Redis集群虚拟槽如下图:
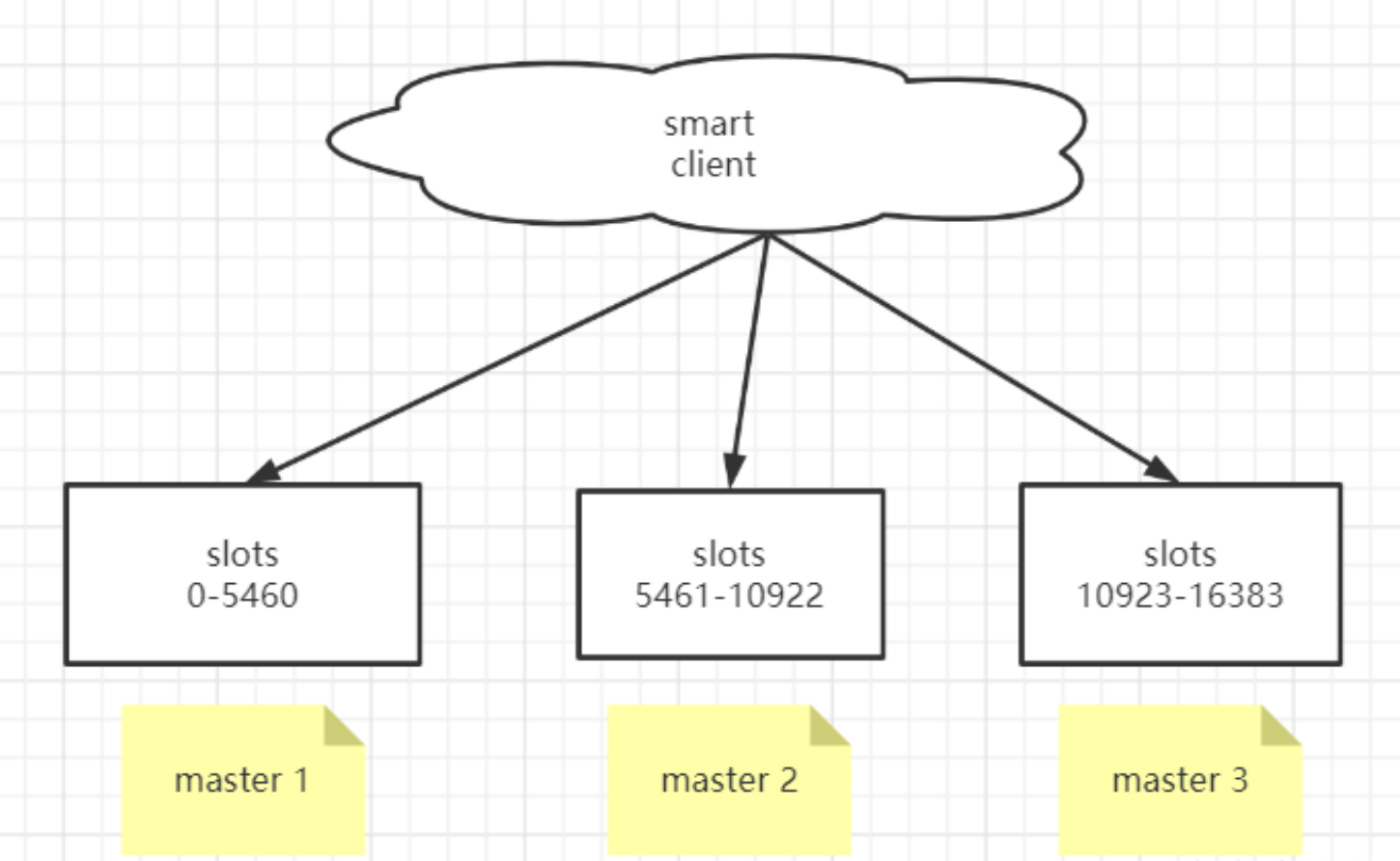
key -> slot 的算法选择
key -> slot 的算法选择上,Redis Cluster 选择的算法是 hash(key) mod 16383,即使用CRC16算法对 key进行hash,然后再对16383取模,结果便是对应的slot。
hash(key) mod 16383
1 keyhash= hash(key)
2 slot= keyhash % 16383把16384个槽平均分配给节点进行管理,每个节点只能对自己负责的槽进行读写操作
由于每个节点之间都彼此通信,每个节点都知道另外节点负责管理的槽范围
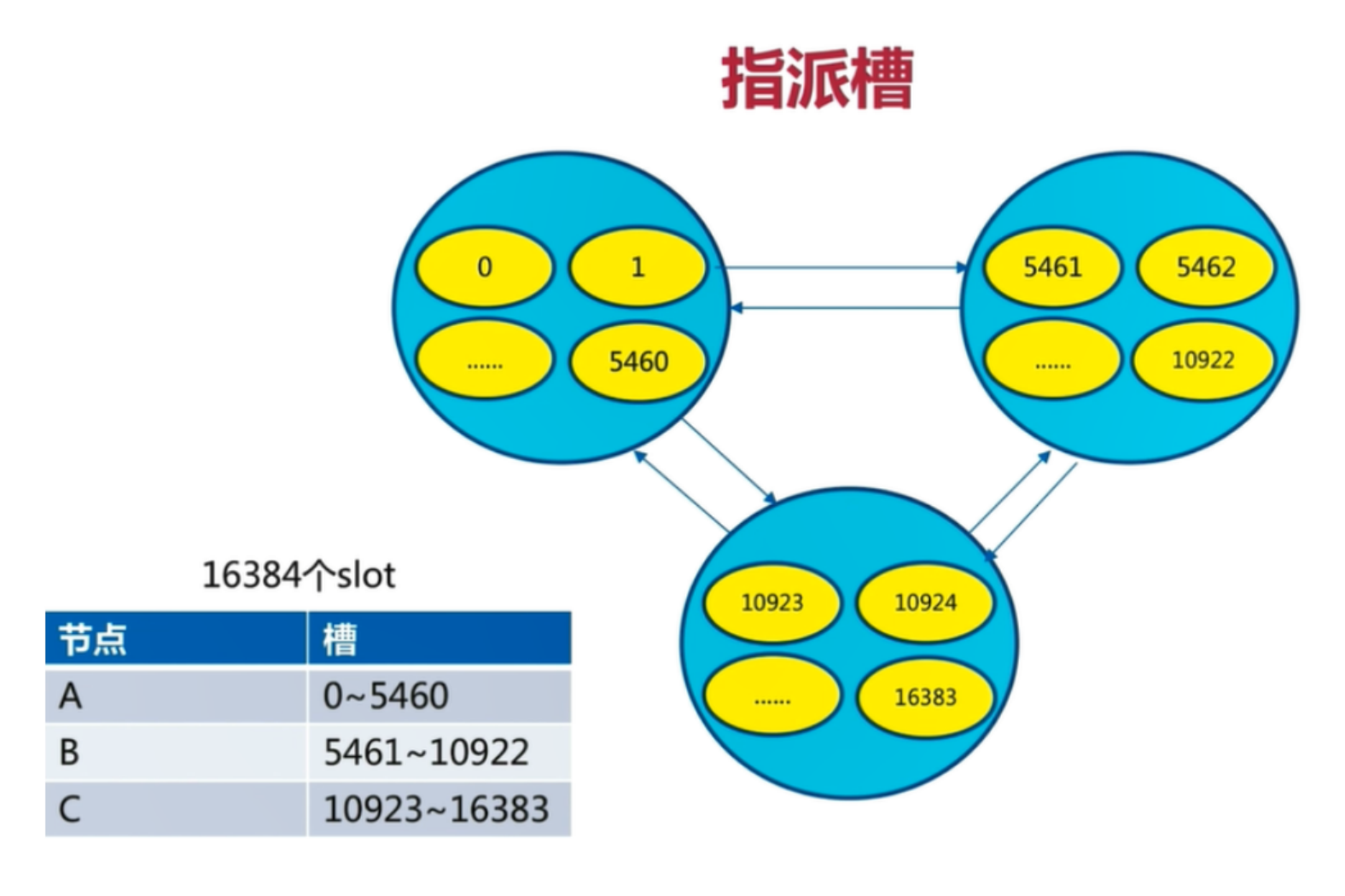
客户端访问任意节点时,对数据key按照CRC16规则进行hash运算,然后对运算结果对16383进行取 作,如果余数在当前访问的节点管理的槽范围内,则直接返回对应的数据
节点之间的漫游
如果不在当前节点负责管理的槽范围内,则会告诉客户端去哪个节点获取数据,由客户端去正确的节点获取数据
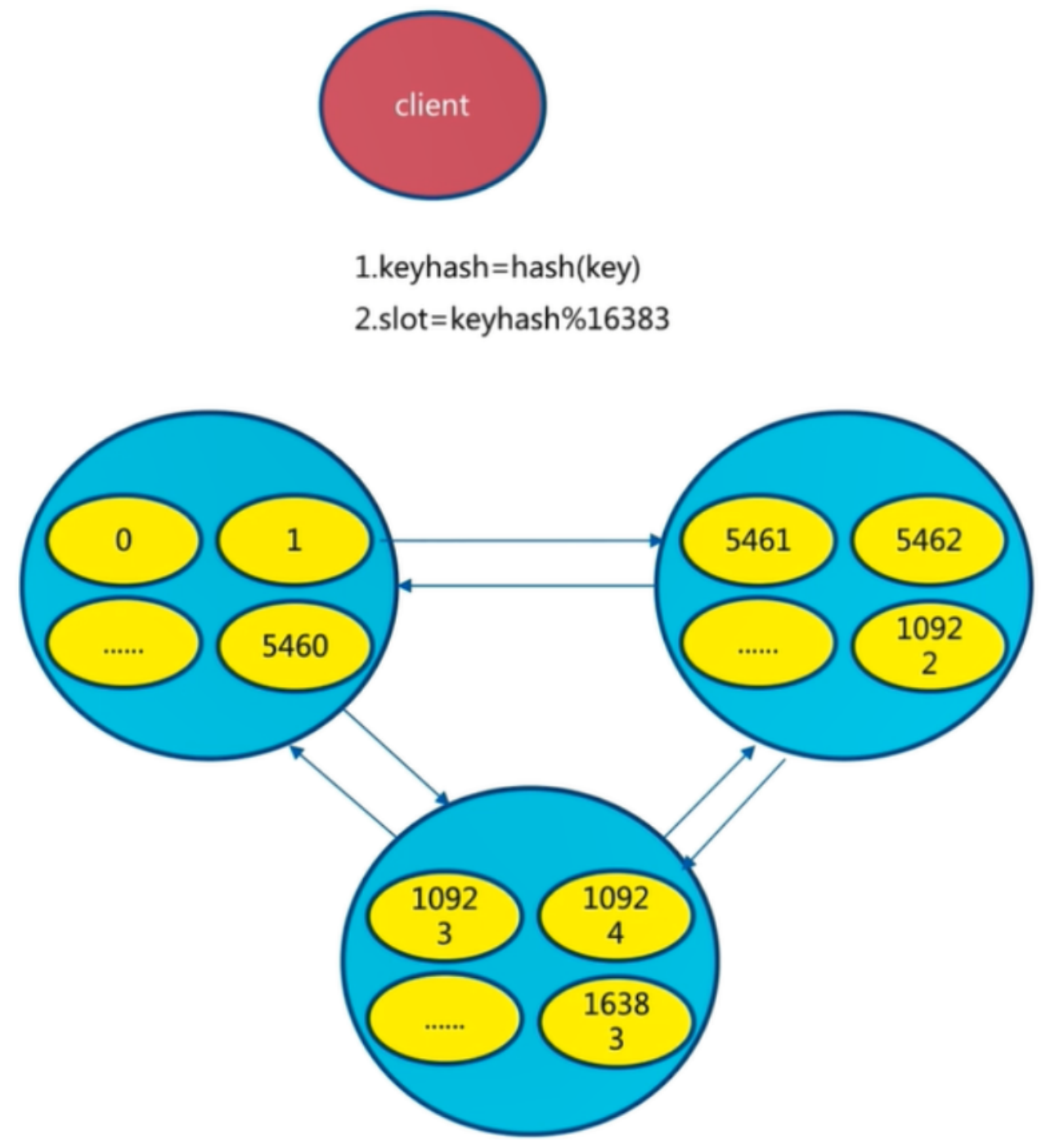
节点间的通信架构
集群中会有多个节点,每个节点负责一部分slot以及对应的k-v数据,并且通过直连具体节点的方式与客 户端通信。
那么问题来了,你向我这里请求一个key的value,这个key对应的slot并不归我负责,但我又要需要告诉 你MOVED到目标节点,我如何知道这个目标节点是谁呢?
Redis Cluster使用Gossip协议维护节点的元数据信息,这种协议是P2P模式的,主要指责就是信息交 换。
节点间不停地去交换彼此的元数据信息,那么总会在一段时间后,大家都知道彼此是谁,负责哪些数 据,是否正常工作等等。
节点间信息交换是依赖于彼此发出的Gossip消息的。
集群的元数据
Cluster中的每个节点都维护一份在自己看来当前整个集群的元数据,主要包括:
- 当前集群状态
- 集群中各节点所负责的slots信息,及其migrate状态
- 集群中各节点的master-slave状态
- 集群中各节点的存活状态及不可达投票
P2P方式模式的元数据交互协议
Redis集群内采用的是P2P方式模式,没有主节点。并且采用的是Gossip协议
Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整 的信息,这种方式类似流言传播。
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。
gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦· 德默斯(Alan Demers)于1987年创造的。
从 gossip 单词就可以看到,其中文意思是八卦、流言等意思,我们可以想象下绯闻的传播(或者流行病 的传播); gossip 协议的工作原理就类似于这个。
Goosip 协议的信息传播和扩散通常需要由种子节点发起。
整个传播过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有 节点都会收到消息,因此它是一个最终一致性协议。
Gossip协议的特点
Gossip协议是一个P2P协议,所有写操作可以由不同节点发起,并且同步给其他副本。
Gossip内组成的网络节点都是对等节点,是非结构化网络。
gossip 协议利用一种随机的方式将信息传播到整个网络中,并在一定时间内使得系统内的所有节点数据 一致。
Gossip 其实是一种去中心化思路的分布式协议,解决状态在集群中的传播和状态一致性的保证两个问题。
节点间的通讯消息
Redis集群的Gossip消息
Redis集群使用二进制协议进行节点到节点的数据交换,这更适合于使用很少的带宽和处理时间在节点之间交换信息。
Gossip协议的主要职责就是信息交换。
信息交换的载体就是节点彼此发送的Gossip消息。
Redis集群中每个redis实例(可能一台机部署多个实例)会使用两个Tcp端口,
- 一个用于给客户端(redis-cli或应用程序等)使用的端口,
- 另一个是用于集群中实例相互通信的内部总线端口,且第二个端口比第一个端口一定大10000。
内部总线端口通信使用特殊Gossip协议,以便实现集群内部高带宽低时延的数据交换。 所以配置redis实例时只需要指明第一个端口就可以了。
所以,每一个Redis群集的节点都需要打开两个TCP连接,由于这两个连接就需要两个端口,分别是用于为客户端提供服务的常规RedisTCP命令端口(例如6379)以及通过将10000和命令端口相 加(10000+6379)而获得的端口,就是集群端口(例如16379)。
命令端口和集群总线端口偏移量是固定的,始终为10000。第二个大号端口用于群集总线,即使用 二进制协议的节点到节点通信通道。
节点使用群集总线进行故障检测,配置更新,故障转移授权 等。 客户端不应尝试与群集总线端口通信,为了保证Redis命令端口的正常使用,请确保在防火墙中打 开这两个端口,否则Redis群集节点将无法通信。
请注意,为了让Redis群集正常工作,您需要为每个节点:
- 用于与客户端进行通信的普通客户端通信端口(通常为6379)对所有需要到达群集的客户端以 及所有其他群集节点(使用客户端端口进行密钥迁移)都是开放的。
- 集群总线端口(客户端端口+10000)必须可从所有其他集群节点访问。
Redis集群常用的Gossip消息可分为:ping消息、pong消息、meet消息、fail消息:
- meet消息 会通知接收该消息的节点,发送节点要加入当前集群,接收者进行响应。
- ping消息 是集群中的节点定期向集群中其他节点(部分或全部)发送的连接检测以及信息交换请 求,消息包含发送节点信息以及发送节点知道的其他节点信息。
- pong消息 是在节点接收到meet、ping消息后回复给发送节点的响应消息,告诉发送方本次通信正 常,消息包含当前节点状态。
- fail消息 是在节点认为集群内另外某一节点下线后向集群内所有节点广播的消息。
节点的握手消息
在集群启动的过程中,有一个重要的步骤是 节点握手 ,其本质就是在一个节点上向其他所有节点发送 meet消息,消息中包含当前节点的信息(节点id,负责槽位,节点标识等等),接收方会将发送节点信 息存储至本地的节点列表中。
当发送者接到客户端发送的CLUSTER MEET命令时,发送者会向接收者 发送MEET消息,请求接收 者加入到发送者当前所处的集群里面
消息体中还会包含与发送节点通信的其他节点信息(节点标识、节点id、节点ip、port等),接收方也会 解析这部分内容,如果本地节点列表中不存在,则会主动向新节点发送meet消息。
接收方处理完消息后,也会回复pong消息给发送者节点,发送者也会解析pong消息更新本地存储节点信息。
因此,虽然只是在一个节点向其他所有节点发送meet消息,最后所有节点都会有其他所有节点的信息。
节点之间会相互通信,meet操作是节点之间完成相互通信的基础,meet操作有一定的频率和规则
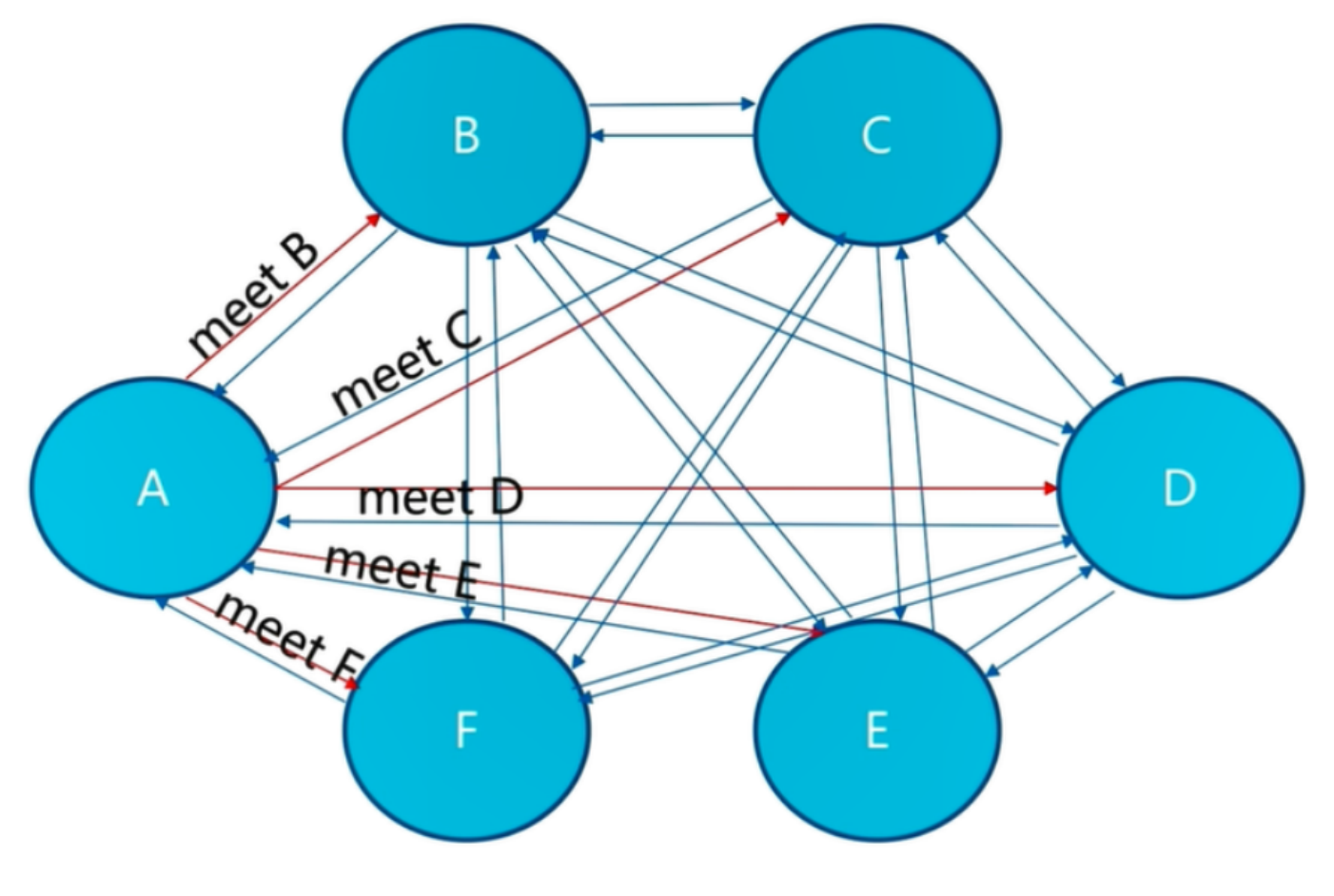
集群内的心跳消息
集群启动后,集群中各节点也会定时往 其他部分节点 发送ping消息,用来检测:
- 目标节点是否正常
- 以此来检测被选中的节点是否在线
- 以及发送自己最新的节点负槽位信息。
接收方同样响应pong消息,由发送方更新本地节点信息。
心跳时机:
Redis节点会记录其向每一个节点上一次发出ping和收到pong的时间,心跳发送时机与这两个值有关。
通过下面的方式既能保证及时更新集群状态,又不至于使心跳数过多,集群的周期性执行clusterCron函 数,每秒执行10次,100ms执行一次:
- 每次clusterCron向所有未建立链接的节点发送ping或meet
- 每1秒(10次当中某次)从所有已知节点中随机选取5个,向其中上次收到pong最久远的一个发送 ping
- 每次Cron向收到pong超过timeout/2的节点发送ping
- 收到ping或meet,立即回复pong
集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节点,然后对这五个节点中最长 时间没有发送过PING消息的节点发送PING消息。
除此之外,如果节点A最后一次收到节点B发送的PONG消息的时间,距离当前时间已经超过了节点A的 cluster-node-timeout选项设置时长的一半,那么节点A也会向节点B发送PING消息,这可以防止节点A 因为长时间没有随机选中节点B作为PING消息的发送对象而导致对节点B的信息更新滞后
serverCron源码如下


心跳数据
Header,发送者自己的信息
- 所负责slots的信息
- 主从信息
- ip port信息
- 状态信息
Gossip,发送者所了解的部分其他节点的信息
- ping_sent, pong_received
- ip, port信息
- 状态信息,比如发送者认为该节点已经不可达,会在状态信息中标记其为PFAIL或FAIL
考虑到频繁地交换信息会加重带宽(集群节点越多越明显)和计算的负担
Redis Cluster内部的定时任务每秒执行10次,每100毫秒一次,每次遍历本地节点列表,对最近一次接受到pong消息时间大于cluster_node_timeout/2的节点立马发送ping消息,此外每秒随机找5个节点, 选里面最久没有通信的节点发送ping消息。
同时 ping 消息的消息投携带自身节点信息,消息体只会携带1/10的其他节点信息,避免消息过大导致 通信成本过高。
cluster_node_timeout 参数影响发送消息的节点数量,调整要综合考虑故障转移、槽信息更新、新节点 发现速度等方面。
一般带宽资源特别紧张时,可以适当调大一点这个参数,降低通信成本。
fail消息
当集群里的节点A将节点B标记为已下线(FAIL)时,节点A将向集群广播一条关于节点B的FAIL消息, 所有接收到这条FAIL消息的节点都会将节点B标记为已下线
fail消息演示案例
举个例子,对于包含7000、7001、7002、7003四个主节点的集群来说:
- 如果主节点7001发现主节点7000已下线,那么主节点7001将向主节点7002和主节点7003 发送FAIL消息,其中FAIL消息中包含的节点名字为主节点7000的名字,以此来表示主节点 7000已下线
- 当主节点7002和主节点7003都接收到主节点7001发送的FAIL消息时,它们也会将主节 点 7000标记为已下线
- 因为这时集群已经有超过一半的主节点认为主节点7000已下线,所以集群剩下的几个主节点 可以判断是否需要将该节点标记为下线,又或者开始对主节点7000进行故障转移
下图展示了节点发送和接收FAIL消息的整个过程
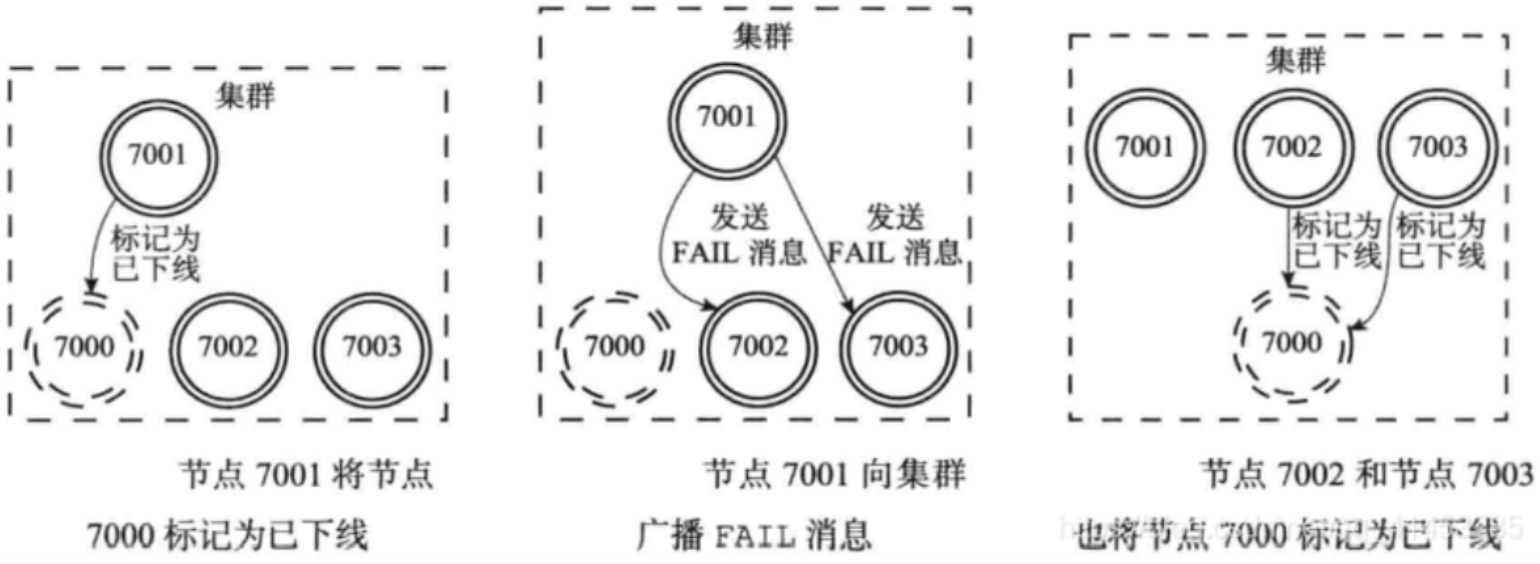
在集群的节点数量比较大的情况下,单纯使用Gossip协议来传播节点的已下线信息会给节点的信息更新 带来一定延迟,因为Gossip协议消息通常需要一段时间才能传播至整个集群,
而发送FAIL消息可以让集群里的所有节点立即知道某个主节点已下线,从而尽快判断是 否需要将集群标 记为下线,又或者对下线主节点进行故障转移 (slave提升为新Master)
ping 时的节点选择
Redis集群的Gossip协议需要兼顾信息交换实时性和成本开销。
- ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。因此,Redis集群内节点通信采用 固定频率(定时任务每秒执行10次),一般每个节点每秒会执行 10 次 ping,每次会选择 5 个最久 没有通信的其它节点。
- 当然如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据 交换延时过长导致信息严重滞后。
比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的 情况,就会有问题。所以 cluster_node_timeout 可以调节,如果调得比较大,那么会降低 ping 的频率。
- 每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。 至少包含 3 个其它节点的信息,最多包含 总节点数减 2 个其它节点的信息。
因此节点每次选择需要通信的节点列表变得非常重要。通信节点选择过多虽然可以做到信息及时交换但 是成本过高。节点选择过少会降低集群内所有节点彼此信息交互频率,从而影响故障判定、新节点发现 等需求的速度。
ping 时,通信节点选择的规则如图所示:
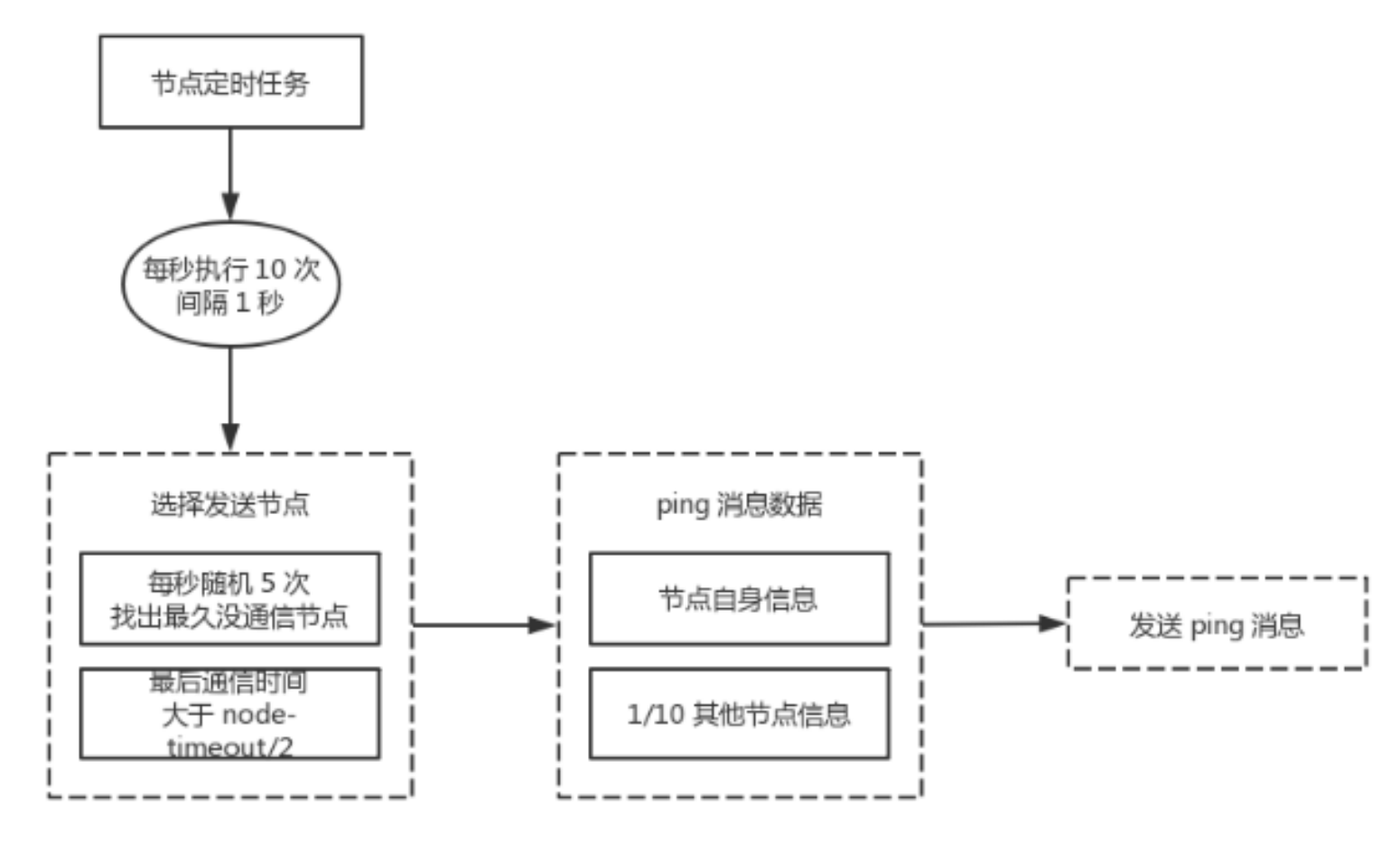
根据通信节点选择的流程可以看出: 消息交换的成本主要体现在单位时间选择发送消息的节点数量和每个消息携带的数据量。
选择发送消息的节点数量:
- 集群内每个节点维护定时任务默认每秒执行10次,每秒会随机选取5个节点找出最久没有通信的节 点发送ping消息,用于保证Gossip信息交换的随机性。每100毫秒都会扫描本地节点列表,如果发 现节点最近一次接受pong消息的时间大于 cluster_node_timeout / 2,则立刻发送ping消息,防止 该节点信息太长时间未更新。
根据以上规则得出每个节点每秒需要发送ping消息的数量,由此,根据以上规则得出每个节点/每秒需 要发送ping消息的数量:
5 + 10*num(num=node.pong_received>cluster_node_timeout/2 的节点数)
所以: cluster_node_timeout参数对消息发送的节点数量影响非常大。
- 当我们的带宽资源紧张时,可以适当调大这个参数,如从默认15秒改为30秒来降低带宽占用率。
- 过度调大cluster_node_timeout会影响消息交换的频率从而影响故障转移、槽信息更新、新节点发 现的速度。
- 需要根据业务容忍度和资源消耗进行平衡,同时整个集群消息总交换量也跟节点数成正比。
消息数据量:
- 每个ping消息的数据量体现在消息头和消息体中,其中消息头主要占用 空间的字段是 myslots[CLUSTER_SLOTS/8],占用2KB,这块空间占用相对固定。 消息体会携带一定数量的其他节点信息用于信息交换。
- 消息体携带数据量跟集群的节点数息息相 关,更大的集群每次消息通信的成本也就更高,因此对于Redis集群来说并不是大而全的集群更 好。
redis虚拟槽位为什么是16384(2^14)个?
问题1:redis虚拟槽位为什么是16384(2^14)个?而不是 65535 (2^16)个?
问题2:CRC16算法产生的hash值有16bit,该算法可以产生2^16-=65536个值。换句话说,值是分布在 0~65535之间。那在做mod运算的时候,为什么不mod 65536,而选择 mod 16384?
分片SLOT的计算公式
SLOT=CRC16.crc16(key.getBytes()) % MAX_SLOT
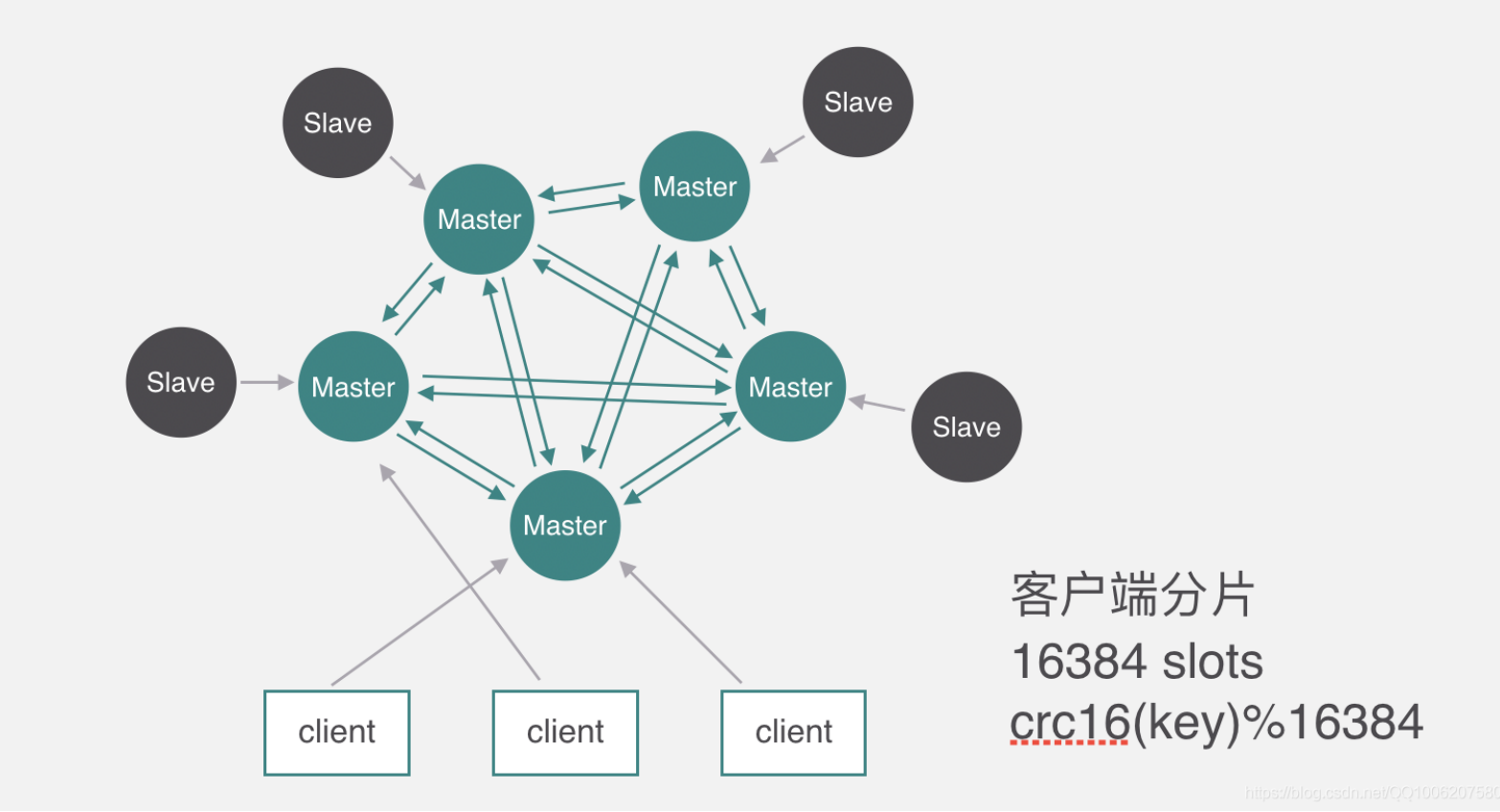
对于客户端请求的key,根据公式 HASH_SLOT=CRC16(key) mod 16384 ,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作!
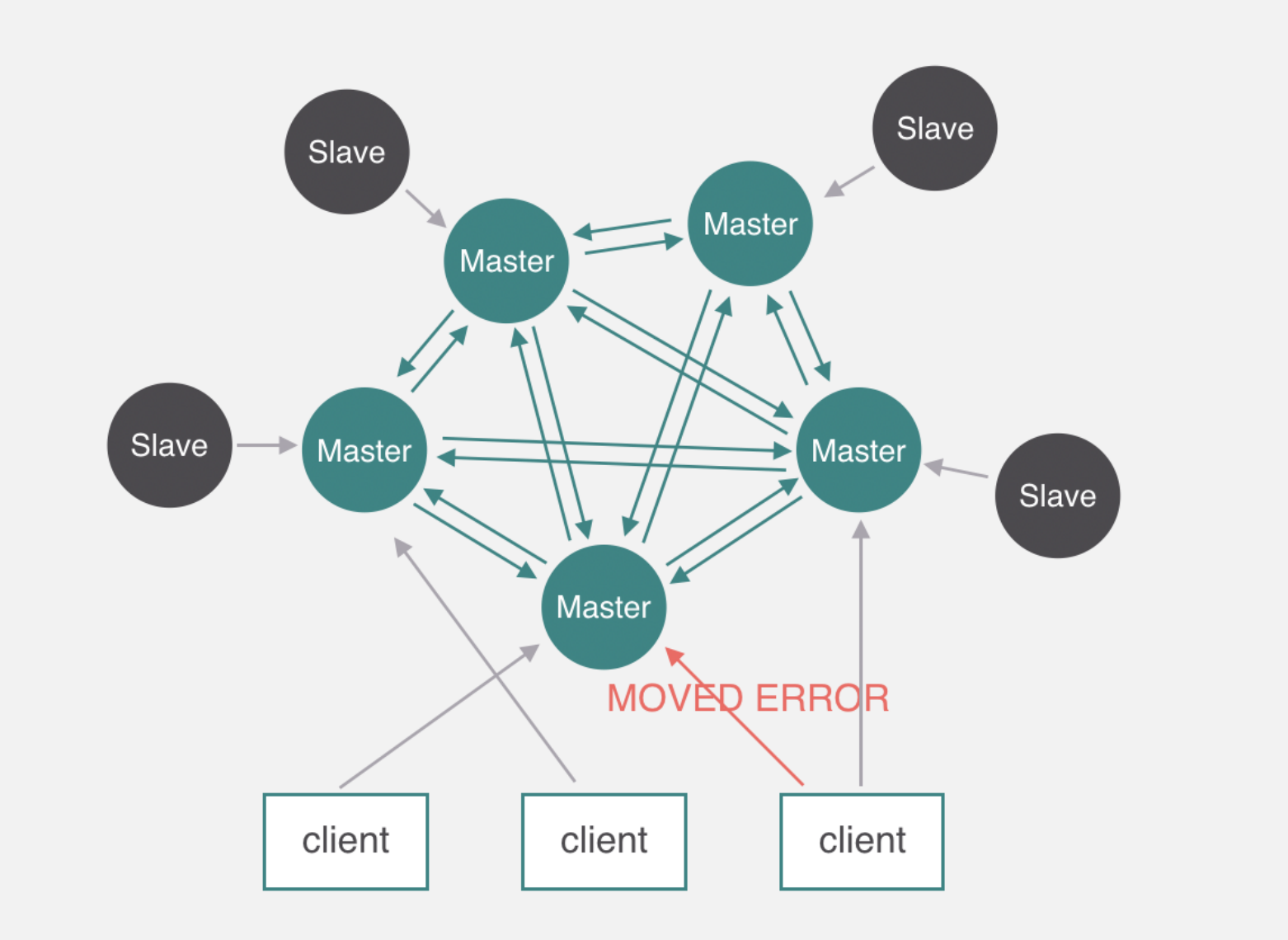
但是可能这个槽并不归随机找的这个节点管,节点如果发现不归自己管,就会返回一个MOVED ERROR 通知,引导客户端去正确的节点访问,这个时候客户端就会去正确的节点操作数据。
CRC16算法产生的hash值有16bit,该算法可以产生2^16-=65536个值。换句话说,值是分布在 0~65535之间。那在做mod运算的时候,为什么不mod 65536,而选择 mod 16384?
redis节点发送心跳包
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息
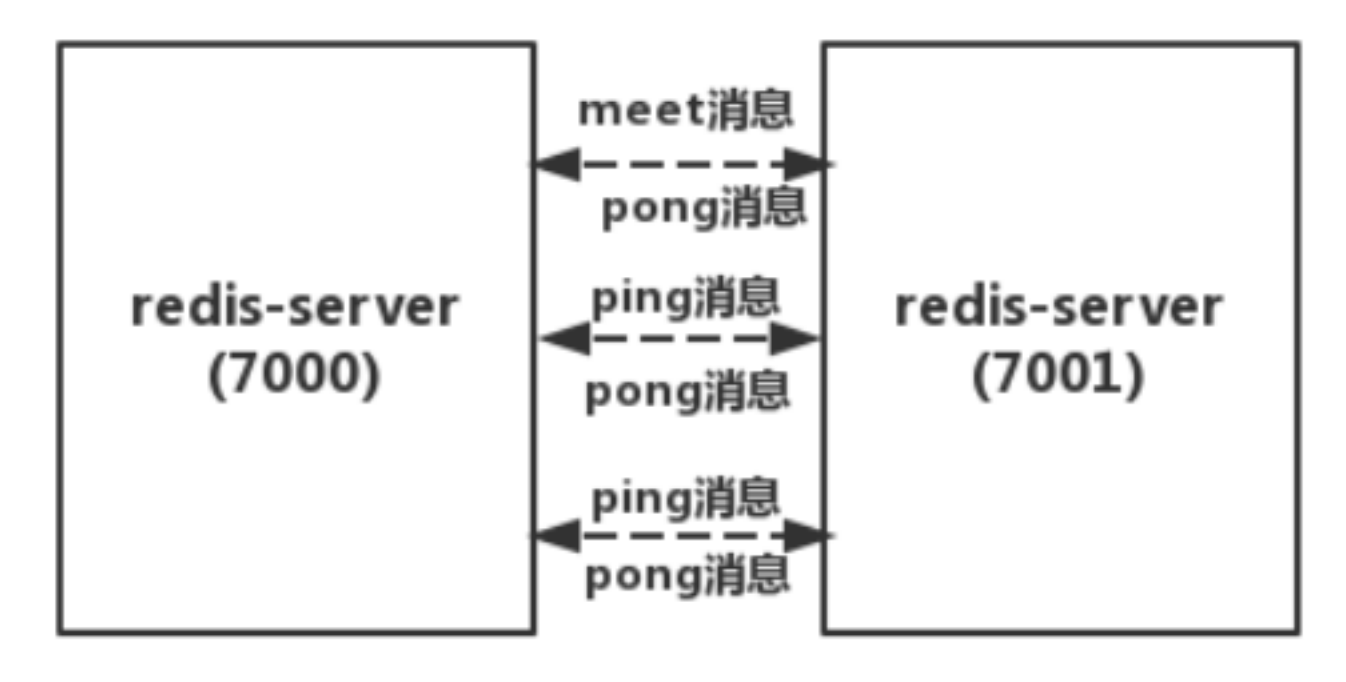
交换的数据信息,由消息体和消息头组成。消息体无外乎是一些节点标识啊,IP啊,端口号啊,发送时间啊。 这里不做展开,我们来看消息头,结构如下
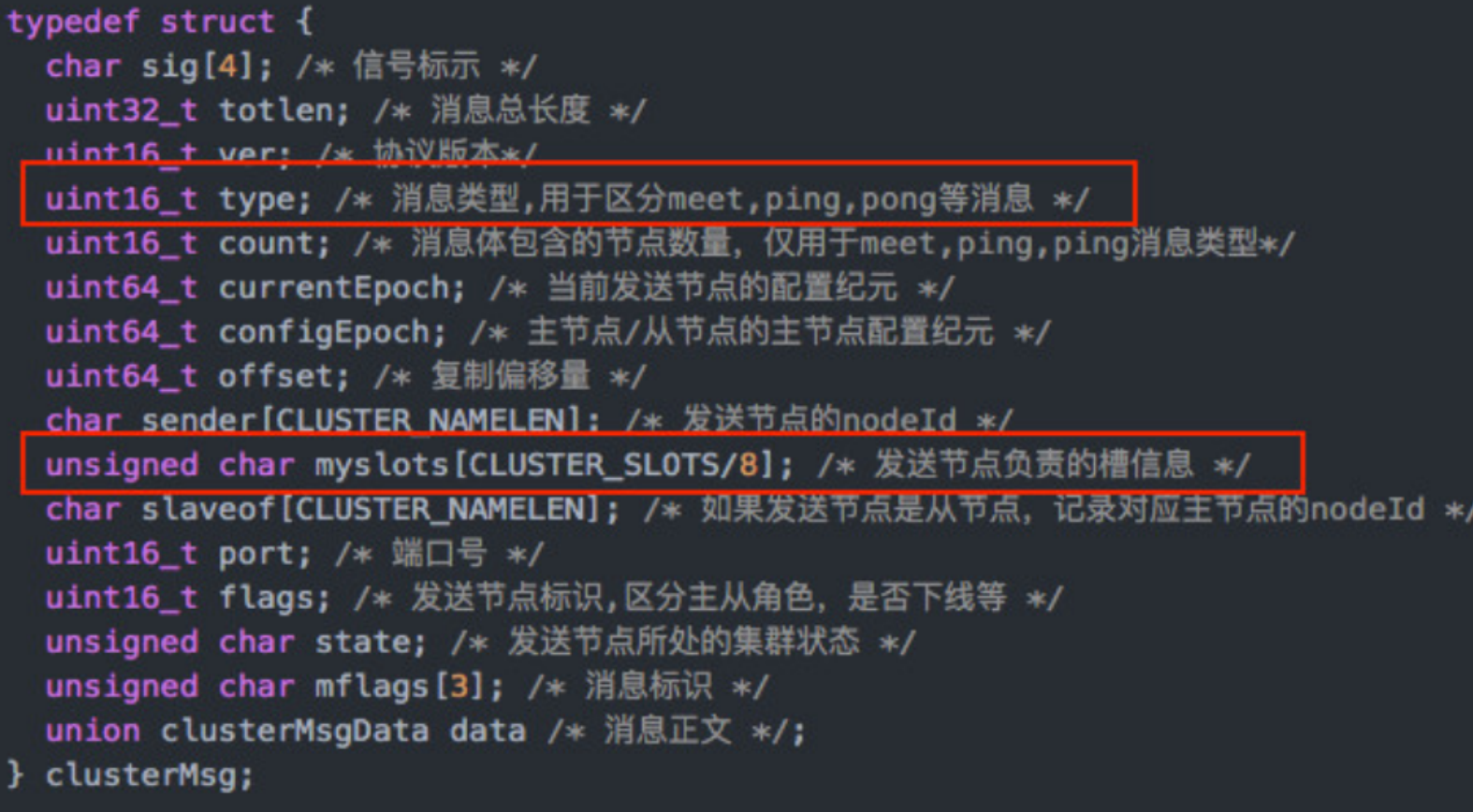
消息头里面有个myslots的char数组,长度为16383/8,这其实是一个bitmap,每一个位代表一个槽,如 果该位为1,表示这个槽是属于这个节点的。在消息头中,最占空间的是 myslots[CLUSTER_SLOTS/8] 。
这块(2的十四次方)的大小是: 16384÷8÷1024=2kb
16384=16k, 在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K)个char,也就 是说使用2k个char的空间,能表达16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k, 压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要需要8k的心跳包, 作者认为这样做不太值得; 集群节点越多,心跳包的消息体内携带的数据越多。 如果节点过1000个,也会导致网络拥堵。
因此redis作者,不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。 没有必要拓展到65536个。 并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
Redis Cluster的高可用架构
要保证高可用的前提是离不开从节点的,一旦某个主节点因为某种原因不可用后,就需要一个一直默默 当备胎的从节点顶上来了。
一般在集群搭建时最少都需要6个实例,其中3个实例做主节点,各自负责一部分槽位,另外3个实例各自对应一个主节点做其从节点,对主节点的操作进行复制(对于主从复制的细节,前面已经进行详细说明)。
集群中指定主从关系
集群中指定主从关系不再使用slaveof命令,而是使用cluster replicate命令,参数使用节点id。 Redis Cluster在给主节点添加从节点时,不是使用 slaveof 命令,而是通过在从节点上执行命令 :
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-01 redis-cli -c -p 7001
127.0.0.1:7001> cluster nodes
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1703053484897 3 connected 10923-16383
6a09ae3a8c6fbadcf88839c7557446eecd6412aa 82.157.173.74:7005@17005 master - 0 1703053485898 0 connected
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 172.22.0.6:7001@17001 myself,master - 0 1703053482000 1 connected 1000-5460
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1703053485000 2 connected 5461-10922
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1703053484000 4 connected 0-999
127.0.0.1:7001> exit
[root@VM-24-13-centos ~]# docker exec -it redis-cluster-05 redis-cli -c -p 7005
127.0.0.1:7005> cluster replicate 7dabb3d56ba3c3187de39f2da122edca3d535334
OK
127.0.0.1:7005> cluster nodes
7dabb3d56ba3c3187de39f2da122edca3d535334 82.157.173.74:7002@17002 master - 0 1703053750449 4 connected 0-999
601a5b7671a7108f848ee724fed67151f13d1b54 82.157.173.74:7004@17004 master - 0 1703053749446 3 connected 10923-16383
6a09ae3a8c6fbadcf88839c7557446eecd6412aa 172.22.0.4:7005@17005 myself,slave 7dabb3d56ba3c3187de39f2da122edca3d535334 0 1703053749000 0 connected
4c357e4f7d883d0a80362ed70a430c7a59c9d58e 82.157.173.74:7001@17001 master - 0 1703053748441 1 connected 1000-5460
7e15f6702c4f4d35157291f6d91f6e7ac8507f20 82.157.173.74:7003@17003 master - 0 1703053748000 2 connected 5461-10922
127.0.0.1:7005> failover故障发现与转移
当集群内少量节点出现故障时,通过自动故障转移保证集群可以正常对外提供服务。
作为一个完整的集群,每个负责处理槽的节点应该具有从节点,保证当它出现故障时可以自动进行故障 转移。
redis集群自身实现了高可用,Redis Cluster通过ping/pong消息实现故障发现:不需要sentinel 首次启动的节点和被分配槽的节点都是主节点,从节点负责复制主节点槽信息和相关的数据。
Redis Cluster通过ping/pong消息不仅能传递节点与槽的对应消息,也能传递其他状态,比如:节点主 从状态,节点故障等
failover故障发现与转移总体过程
Cluster的故障发现也是基于节点通信的
每个节点在本地存储有一个节点列表(其他节点信息),列表中每个 节点元素除了存储其ID、ip、 port、状态标识(主从角色、是否下线等等)外,还有最后一次向该节点发送ping消息的时间、最后一次接收到该节点的pong消息的时间以及一个保存其他节点对该节点下线传播的报告链表 。
节点与节点间会定时发送ping消息,彼此响应pong消息,成功后都会更新这个时间。
同时每个节点都有定时任务扫描本地节点列表里这两个消息时间,若发现pong响应时间减去ping发送时 间超过cluster-node-timeout配置时间后,便会将本地列表中对应节点的状态标识为PFAIL,认为其有可能下线。
cluster-node-timeout默认15秒,该参数用来设置节点间通信的超时时间
节点间通信(ping)时会携带本地节点列表中部分节点信息,如果其中包括标记为PFAIL的节点.
那么在消息接收方解析到该节点时,会找自己本地的节点列表中该节点元素的下线报告链表,看是否已经存在发送节点对于该故障节点的报告,如果有,就更新接收到发送ping消息节点对于故障节点的报告 的时间,如果没有,则将本次报告添加进链表。
下线报告链表的每个元素结构只有两部分内容,一个是报告本地这个故障节点的发送节点信息,一个是 本地接收到该报告的时间 (存储该时间是因为故障报告是有有效期的,避免误报) 。
由于每个节点的下线报告链表都存在于各自的信息结构中,所以在浏览本地节点列表中每个节点元素 时,可以清晰地知道,有其他哪些节点跟我说,兄弟,你正在看的这个节点,我觉的pfail了。
故障报告的有效期是 cluster-node-timeout * 2
消息接收方解析到PFAIL节点,并且更新本地列表中对应节点的故障报告链表后,会去查看该节点的故障 报告链表中有效的报告节点是否超过所有主节点数的一半。
- 如果没超过,便继续解析ping消息;
- 如果超过,代表 超过半数的节点认为这个节点可能下线了,当前节点就会将PFAIL节点本地的节点 信息中的状态标识标记为FAIL ,然后向集群内广播一条fail消息,集群内的所有节点接收到该fail消息 后,会把各自本地节点列表中该节点的状态标识修改为FAIL。
在所有节点对其标记为FAIL后,开始故障转移:该FAIL节点对应的从节点就会发起转正流程。
在转正流程完成后,这个节点就会正式下线,等到其恢复后,发现自己的槽已经被分给某个节点,便会 将自己转换成这个节点的从节点并且ping集群内其他节点,其他节点接到恢复节点的ping消息后,便会 更新其状态标识。
此外,恢复的节点若发现自己的槽还是由自己负责,就会跟其他节点通信,其他主节点发现该节点恢复 后,就会拒绝其从节点的选举,最终清除自己的FAIL状态。
故障发现
故障发现就是通过这种模式来实现,分为:
- 主观下线
- 客观下线
故障发现也是通过消息传播机制实现的,主要环节包括:
主观下线 (pfail)
集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。
如果在clusternode-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线 (pfail)状态。
相当于自己认为,别人下线了
某个节点认为另一个节点不可用,’偏见’,只代表一个节点对另一个节点的判断,不代表所有节点的认知
主观下线流程:
- 节点1定期发送ping消息给节点2
- 如果发送成功,代表节点2正常运行,节点2会响应PONG消息给节点1,节点1更新与节点2的最后通信时间
- 如果发送失败,则节点1与节点2之间的通信异常判断连接,在下一个定时任务周期时,仍然会与节点2发送ping消息
- 如果节点1发现与节点2最后通信时间超过node-timeout,则把节点2标识为pfail状态
客观下线 (fail)
当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。
当接受节点发现消息体中含有主观下线的节点状态,且发送节点是主节点时,会在本地找到故障节点的 ClusterNode结构,更新下线报告链表。
相当于大家认为,别人下线了
当半数以上持有槽的主节点都标记某节点主观下线时,可以保证判断的公平性集群模式下,只有主节点(master)才有读写权限和集群槽的维护权限,从节点(slave)只有复制的权限
客观下线流程:
- 某个节点接收到其他节点发送的ping消息
- 如果接收到的ping消息中包含了其他pfail节点,这个节点会将主观下线的消息内容添加到自身的故障列 表中,故障列表中包含了当前节点接收到的每一个节点对其他节点的状态信息
- 当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。
- 当接受节点发现消息体中含有主观下线的节点状态且发送节点是主节点时,会在本地找到故障节点的 ClusterNode结构,更新下线报告链表。
- 集群中的节点每次接收到其他节点的pfail状态,都会尝试触发客观下线。
- 首先统计有效的下线报告数量,当下线报告数量大于槽主节点数量一半时,标记对应故障节点为客 观下线状态。
- 向集群广播一条fail消息,通知所有的节点将故障节点标记为客观下线,fail消息的消息体只包含故 障节点的ID。通知故障节点的从节点触发故障转移流程。
只有负责槽的主节点(master节点,而非slave)参与故障发现决策, 因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护, 而从节点只进行master 主节点数据和状态信息的复制。
故障列表的检查周期为: 集群的 node-timeout * 2,保证以前的故障消息不会对周期内的故障消息造成影响,保证客观下线的公平性和有效性
Redis节点failover(故障转移、故障恢复)流程
故障节点变为客观下线后,如果下线节点是持有槽的主节点, 则需要在它的slave 从节点中选出一 个替换它,从而保证集群的高可用
谁来承担故障恢复的职责: 下线主节点的所有从节点
下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入 客观下线时,将会触发故障恢复流程:
(1) 资格检查
每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。
如果从节点与主节点断线时间超过cluster-node-time * cluster-slave-validity-factor,则当前从节点不 具备故障转移资格。
(2)准备选举时间
当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程。
这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。
复制偏移量越大,说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。
复制偏移量越小,说明从节点延迟越高,那么它应该具有更低的优先级来替换故障主节点。
(3)发起选举
当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:会先更新配置纪元,再在集群内广播选举消息,并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。
(4)选举投票
只有持有槽的主节点才会处理故障选举消息,因为每个持有槽的节点在一个配置纪元内都有唯一的一张 选票,当接到第一个请求投票的从节点消息时回复FAILOVER_AUTH_ACK消息作为投票,之后相同配置 纪元内其他从节点的选举消息将忽略。当从节点收集到N/2+1个持有槽的主节点投票时,从节点可以执 行替换主机点操作。
(5)替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
- 当前从节点取消复制变为主节点。
- 执行clusterDelSlot操作撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽委派给自己。
- 向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点 的槽信息。
资格检查
每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。如果从节点与主节点 断线时间超过cluster-node-time * cluster-slave-validity-factor,则当前从节点不具备故障转移资格。
- 对从节点的资格进行检查,只有通过检查的从节点才可以开始进行故障恢复
- 每个从节点检查与故障主节点的断线时间
- 超过cluster-node-timeout * cluster-slave-validity-factor数字,则取消资格
- cluster-node-timeout默认为15秒,cluster-slave-validity-factor默认值为10
- 如果这两个参数都使用默认值,则每个节点都检查与故障主节点的断线时间,如果超过150秒,则这个节点就没有成为替换主节点的可能性
准备选举时间
当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程。
这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。
复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。
- 复制偏移量越大,说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。
- 复制偏移量越小,说明从节点延迟越高,那么它应该具有更低的优先级来替换故障主节点。
使偏移量最大的从节点具备优先级成为主节点的条件
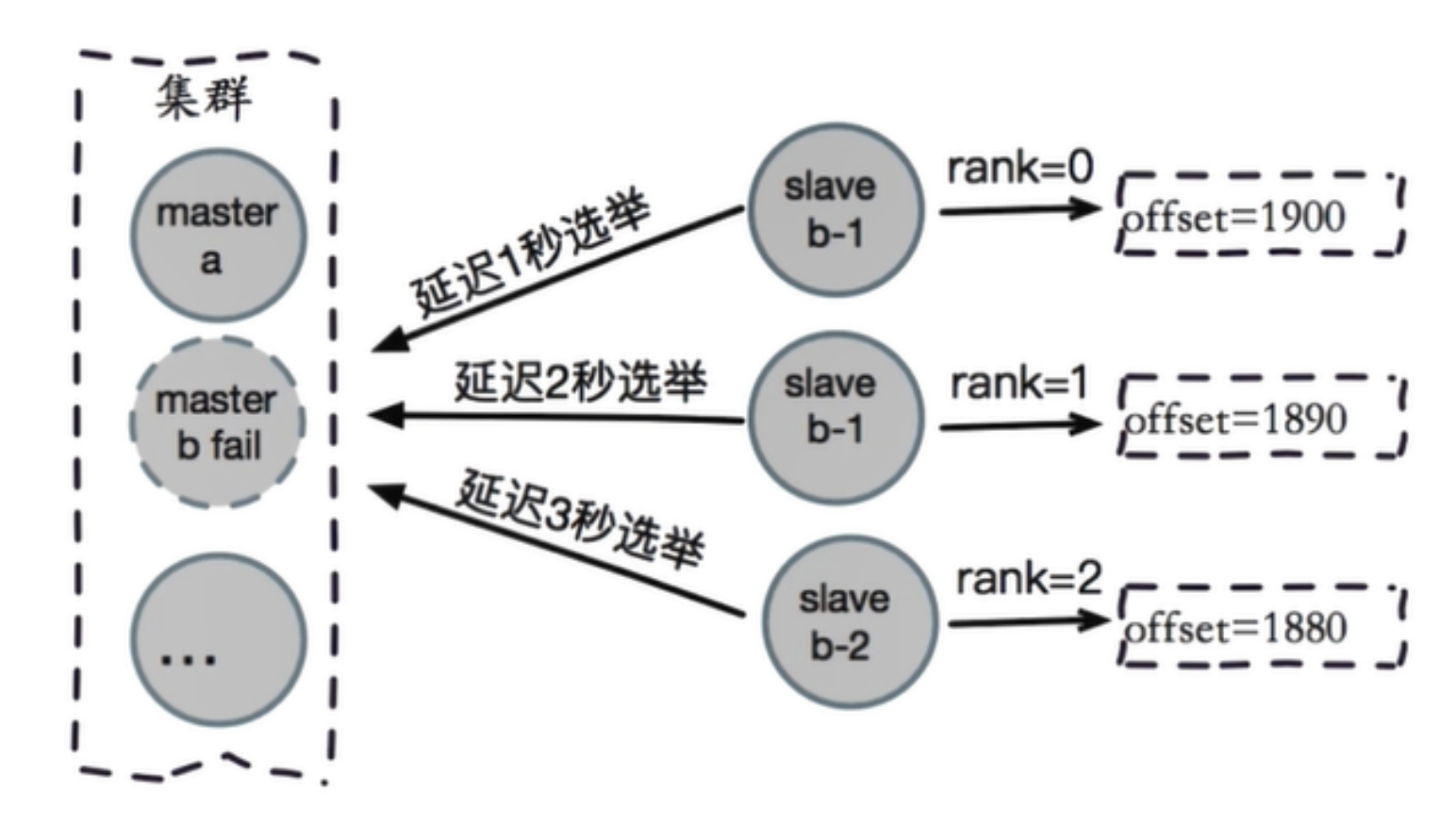
发起选举
当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程如下:
更新配置纪元:
配置纪元是一个只增不减的整数,每个主节点自身维护一个配置纪元 (clusterNode.configEpoch)标示当前主节点的版本,所有主节点的配置纪元都不相等,从节点会复制主节点的配置纪元。
整个集群又维护一个全局的配置纪元(clusterState.current Epoch),用于记录集群内所有主节点配置纪元的最大版本。
执行cluster info命令可以查看配置纪元信息。 只要集群发生重要的关键事件,纪元数就会增加,所以在选从的时候需要选择一个纪元数最大的从。
广播选举消息:
在集群内广播选举消息(FAILOVER_AUTH_REQUEST),并记录已发送过消息的状态,保证该从节点在一个配置纪元内只能发起一次选举。
消息内容如同ping消息只是将type类型变为FAILOVER_AUTH_REQUEST。
配置纪元的主要作用:
- 标示集群内每个主节点的不同版本和当前集群最大的版本。
- 每次集群发生重要事件时,这里的重要事件指出现新的主节点(新加入的或者由从节点转换而 来),从节点竞争选举。都会递增集群全局的配置纪元并赋值给相关主节点,用于记录这一关键事 件。
- 主节点具有更大的配置纪元代表了更新的集群状态,因此当节点间进行ping/pong消息交换时,如 出现slots等关键信息不一致时,以配置纪元更大的一方为准,防止过时的消息状态污染集群。
配置纪元的应用场景有:新节点加入、槽节点映射冲突检测、从节点投票选举冲突检测。
选举投票
只有持有哈希槽的主节点才能参与投票,每个主节点有一票的权利,如集群内有N个主节点,那么只要 有一个从节点获得了N/2+1的选票即认为胜出。
故障主节点也算在投票数内,假设集群内节点规模是3主3从,其中有2个主节点部署在一台机器 上,当这台机器宕机时,由于从节点无法收集到 3/2+1个主节点选票将导致故障转移失败。
这个问题也适用于故障发现环节。因此部署集群时所有主节点最少需要部署在3台物理机上才能避 免单点问题。
投票作废:每个配置纪元代表了一次选举周期,如果在开始投票之后的 cluster-node-timeout*2时间内 从节点没有获取足够数量的投票,则本次选举作废。
从节点对配置纪元自增并发起下一轮投票,直到选举成功为止。
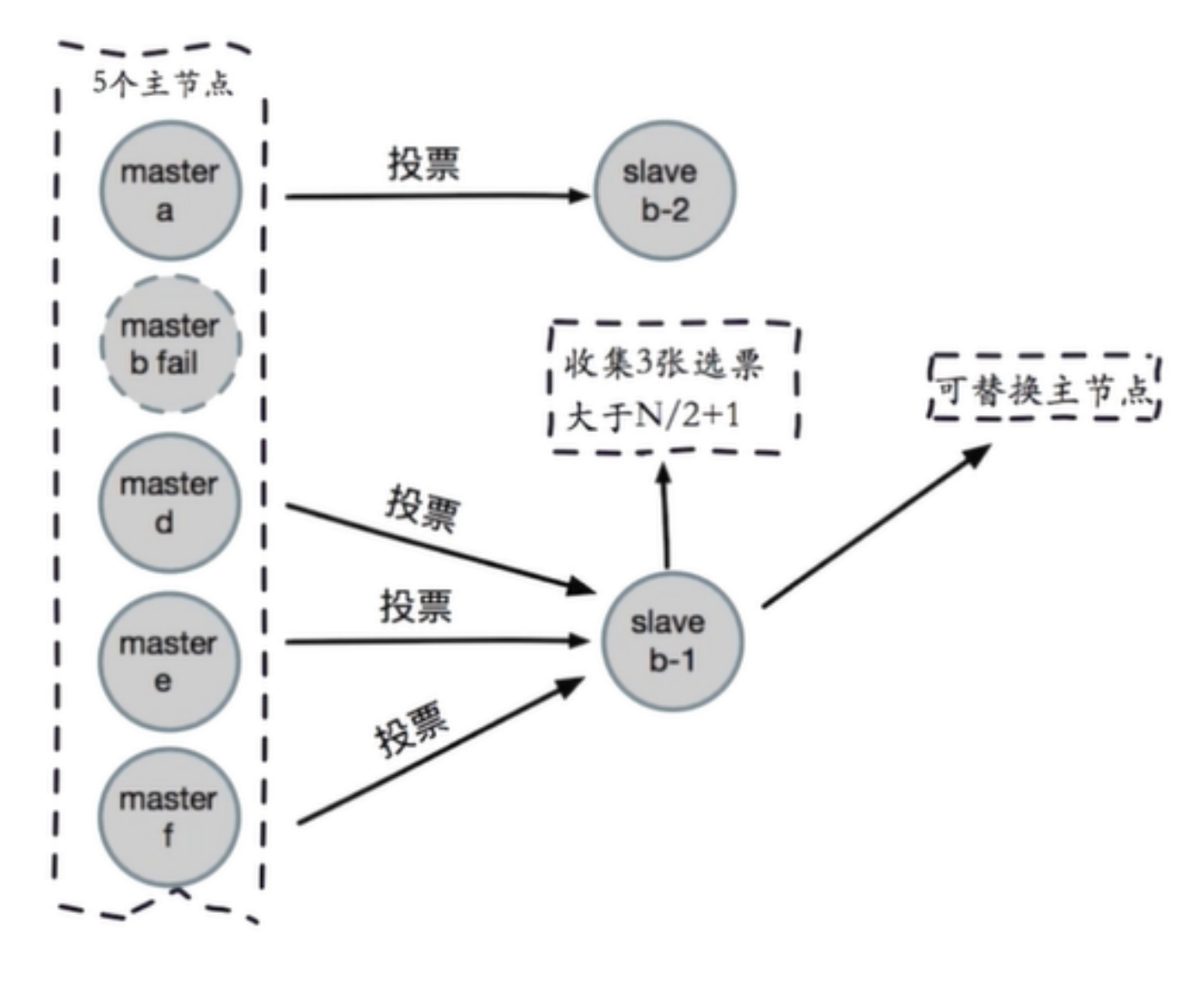
替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
- 当前从节点取消复制, 变为主节点。
- 执行clusterDelSlot操作, 撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽委派给自己。
- 向集群广播自己的pong消息,通知集群内所有的节点当前,从节点变为主节点并接管了故障主节点 的槽信息。
客户端高可用
客户端高可用方案,包含: 客户端moved重定向和ask重定向 smart智能客户端
客户端moved重定向和ask重定向
moved重定向
- 每个节点通过通信都会共享Redis Cluster中槽和集群中对应节点的关系
- 客户端向Redis Cluster的任意节点发送命令,接收命令的节点会根据CRC16规则进行hash运算与 16383取余,计算自己的槽和对应节点
- 如果保存数据的槽被分配给当前节点,则去槽中执行命令,并把命令执行结果返回给客户端
- 如果保存数据的槽不在当前节点的管理范围内,则向客户端返回moved重定向异常
- 客户端接收到节点返回的结果,如果是moved异常,则从moved异常中获取目标节点的信息
- 客户端向目标节点发送命令,获取命令执行结果
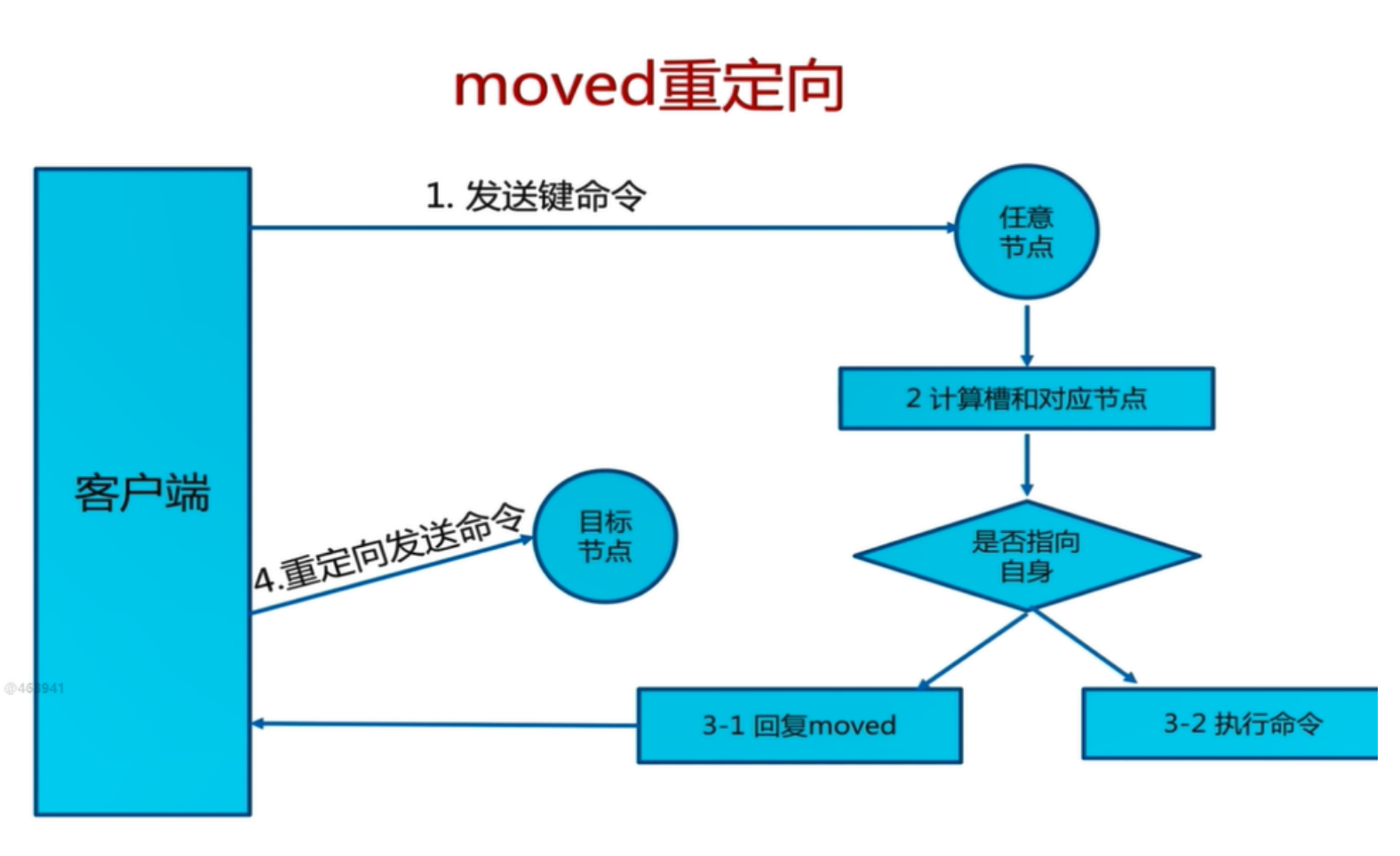
需要注意的是:客户端不会自动找到目标节点执行命令
槽命中:直接返回
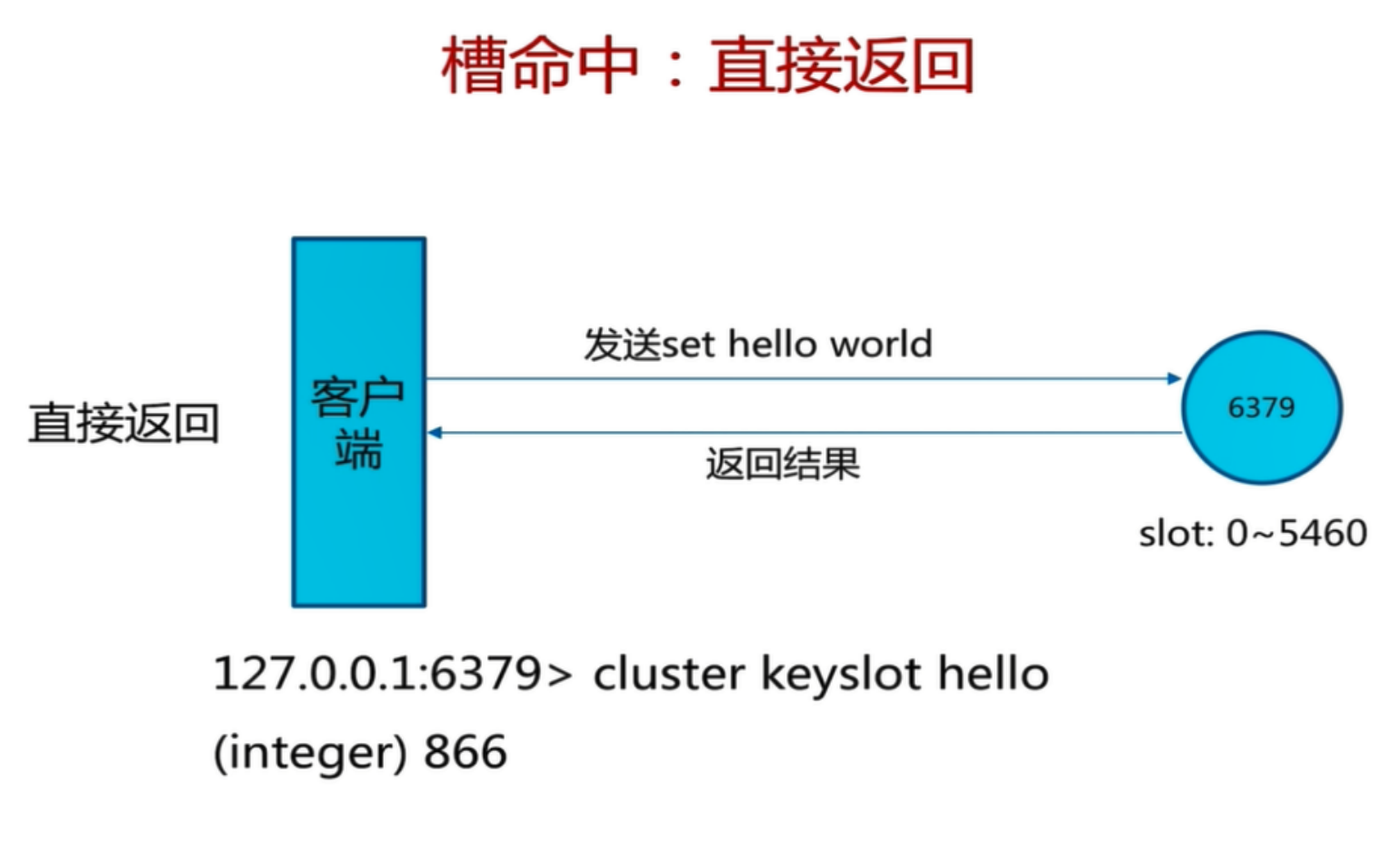
槽不命中:moved异常
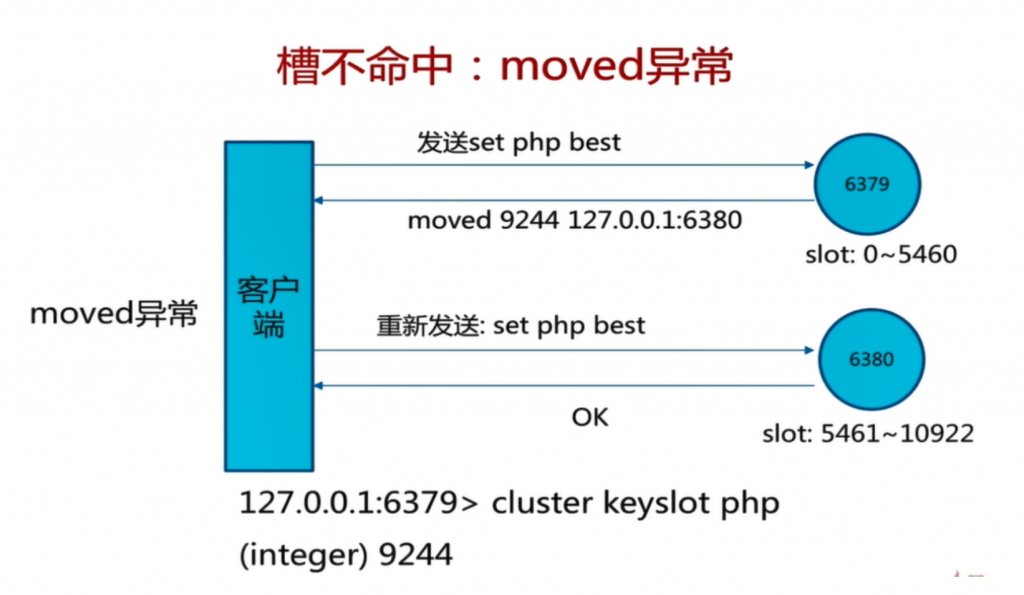
ask重定向
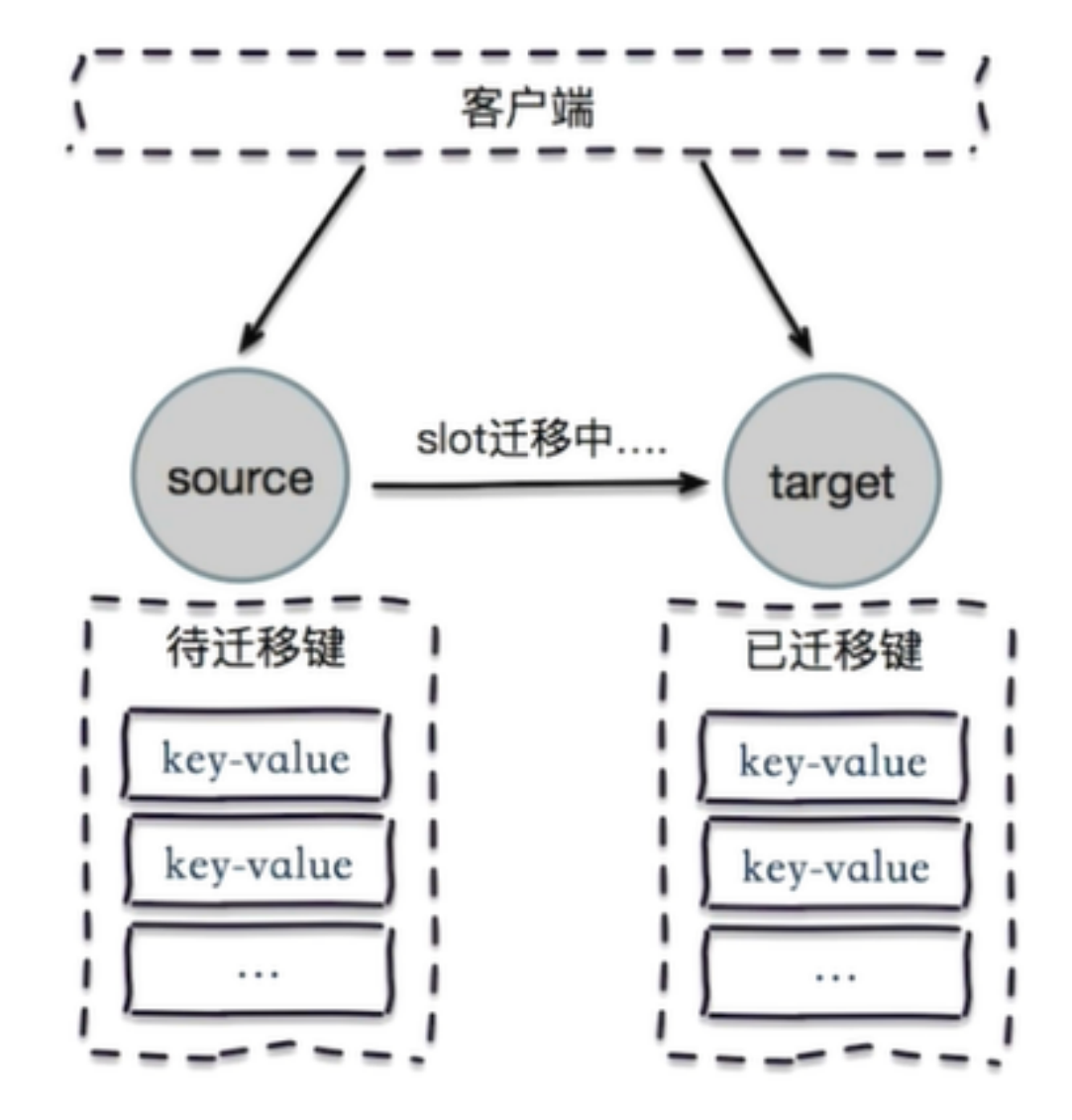
在对集群进行扩容和缩容时,需要对槽及槽中数据进行迁移
当客户端向某个节点发送命令,节点向客户端返回moved异常,告诉客户端数据对应的槽的节点信息
如果此时正在进行集群扩展或者缩空操作,当客户端向正确的节点发送命令时,槽及槽中数据已经被迁 移到别的节点了,就会返回ask,这就是ask重定向机制
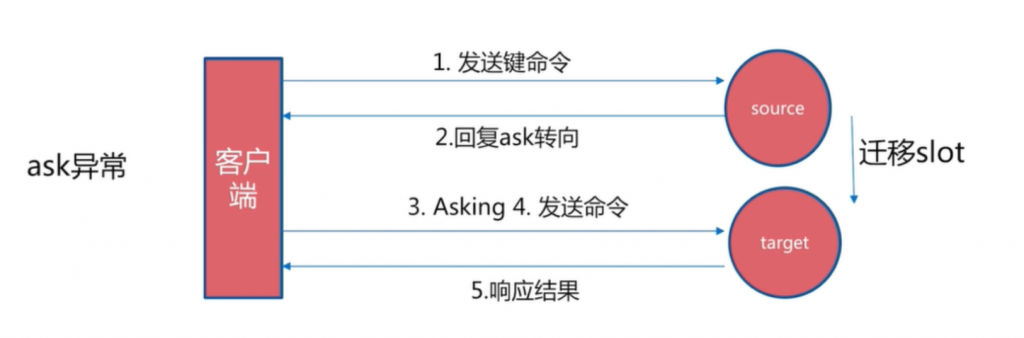
步骤:
- 客户端向目标节点发送命令,目标节点中的槽已经迁移支别的节点上了,此时目标节点会返回ask转向 给客户端
- 客户端向新的节点发送Asking命令给新的节点,然后再次向新节点发送命令
- 新节点执行命令,把命令执行结果返回给客户端
moved异常与ask异常的相同点和不同点
两者都是客户端重定向
moved异常:槽已经确定迁移,即槽已经不在当前节点
ask异常:槽还在迁移中
smart智能客户端
使用智能客户端的首要目标:追求性能
从集群中选一个可运行节点,使用Cluster slots初始化槽和节点映射
将Cluster slots的结果映射在本地,为每个节点创建JedisPool,相当于为每个redis节点都设置一个 JedisPool,然后就可以进行数据读写操作
读写数据时的注意事项:
- 每个JedisPool中缓存了slot和节点node的关系
- key和slot的关系:对key进行CRC16规则进行hash后与16383取余得到的结果就是槽
- JedisCluster启动时,已经知道key,slot和node之间的关系,可以找到目标节点
- JedisCluster对目标节点发送命令,目标节点直接响应给JedisCluster
- 如果JedisCluster与目标节点连接出错,则JedisCluster会知道连接的节点是一个错误的节点
- 此时JedisCluster会随机节点发送命令,随机节点返回moved异常给JedisCluster
- JedisCluster会重新初始化slot与node节点的缓存关系,然后向新的目标节点发送命令,目标命令
- 执行命令并向JedisCluster响应
- 如果命令发送次数超过5次,则抛出异常”Too many cluster redirection!”
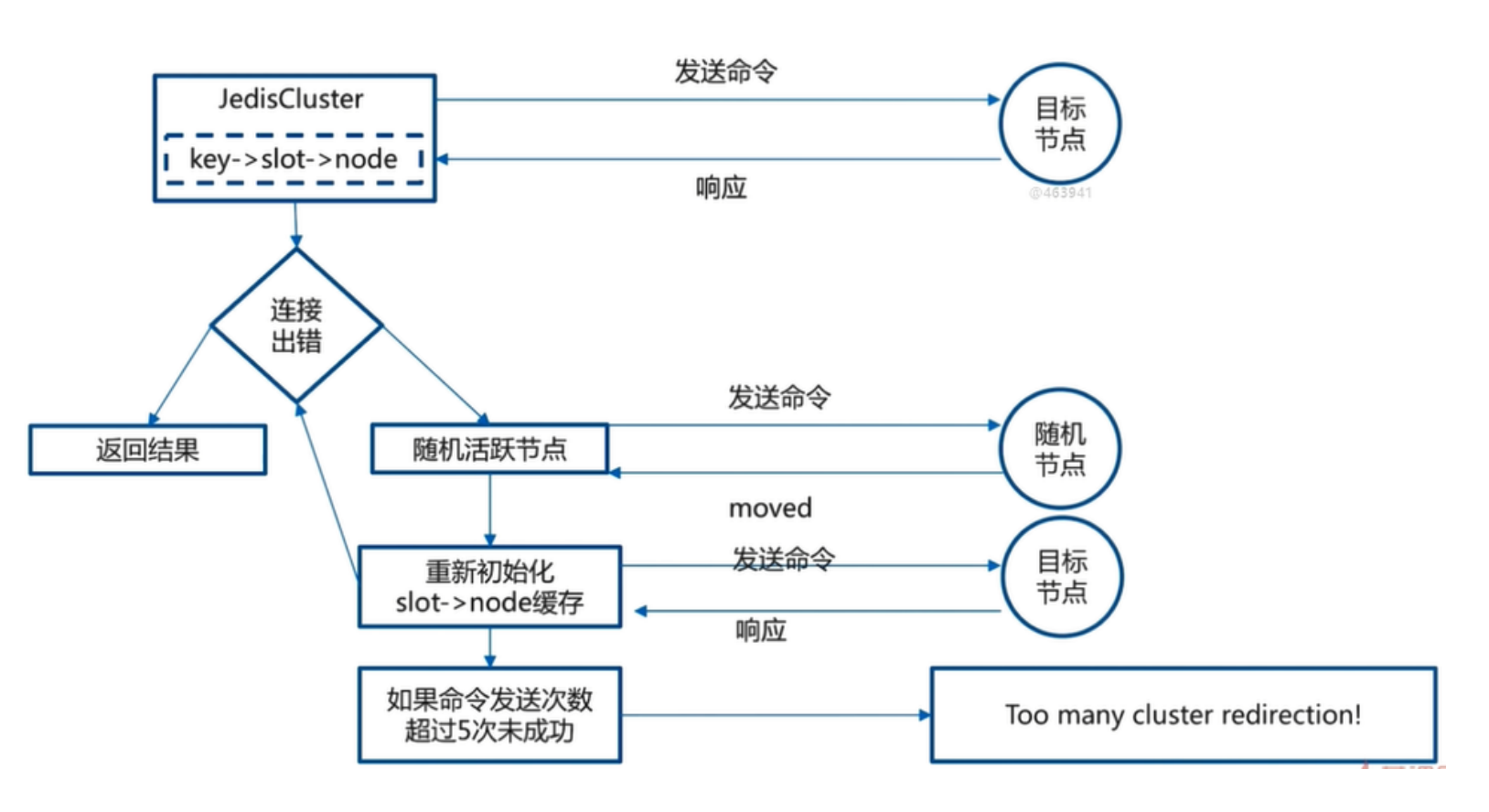
开发运维常见的高可用问题
集群完整性
cluster-require-full-coverage默认为yes
即是否集群中的所有节点都是在线状态且16384个槽都处于服务状态时,集群才会提供服务
集群中16384个槽全部处于服务状态,保证集群完整性
当某个节点故障或者正在故障转移时获取数据会提示:(error)CLUSTERDOWN The cluster is down
建议把cluster-require-full-coverage设置为no
带宽消耗
Redis Cluster节点之间会定期交换Gossip消息,以及做一些心跳检测
官方建议Redis Cluster节点数量不要超过1000个,当集群中节点数量过多时,会产生不容忽视的带宽消耗
消息发送频率:节点发现与其他节点最后通信时间超过cluster-node-timeout /2时,会直接发送PING消息
消息数据量:slots槽数组(2kb空间)和整个集群1/10的状态数据(10个节点状态数据约为1kb)
节点部署的机器规模:集群分布的机器越多且每台机器划分的节点数越均匀,则集群内整体的可用带宽越高
带宽优化:
- 避免使用’大’集群:避免多业务使用一个集群,大业务可以多集群
- cluster-node-timeout:带宽和故障转移速度的均衡
- 尽量均匀分配到多机器上:保证高可用和带宽
Pub/Sub广播
在任意一个cluster节点执行publish,则发布的消息会在集群中传播
集群中的其他节点都会订阅到消息,这样节点的带宽的开销会很大
publish在集群每个节点广播,加重带宽
解决办法:
需要使用Pub/Sub时,为了保证高可用,可以单独开启一套Redis cluster
Redis集群的一致性保证
Redis集群不能保证强一致性。
一些已经向客户端确认写成功的操作,会在某些不确定的情况下丢失。
- 主从节点切换导致的不一致性
- 集群脑裂、网络问题导致的不一致性
主从节点切换导致的不一致性原因
产生写操作丢失的第一个原因,是因为主从节点之间使用了异步的方式来同步数据。
一个写操作是这样一个流程:
- 客户端向主节点B发起写的操作
- 主节点B回应客户端写操作成功
- 主节点B向它的从节点B1,同步该写操作
从上面的流程可以看出来,主节点B并没有等从节点B1,写完之后再回复客户端这次操作的结果。
所以,如果主节点B在通知客户端写操作成功之后,但同步给从节点之前,主节点B故障了,其中一个 没有收到该写操作的从节点会晋升成主节点,该写操作就这样永远丢失了。
就像传统的数据库,在不涉及到分布式的情况下,它每秒写回磁盘。
为了提高一致性,可以在写盘完成之后再回复客户端,但这样就要损失性能。
这种方式就等于Redis集群使用同步复制的方式。
基本上,在性能和一致性之间,需要一个权衡。
如果真的需要,Redis集群支持同步复制的方式,通过WAIT指令来实现,这可以让丢失写操作的可能性 降到很低。
但就算使用了同步复制的方式,Redis集群依然不是强一致性的:
在某些复杂的情况下,比如从节点在与主节点失去连接之后被选为主节点,不一致性还是会发生。
WAIT numslaves timeout
起始版本:3.0.0 ,时间复杂度:O(1)
此命令阻塞当前客户端,直到所有以前的写命令都成功的传输和指定的slaves确认。如果超时,指定以毫秒为单位,即使指定的slaves还没有到达,命令任然返回。
命令始终返回之前写命令发送的slaves的数量,无论是在指定slaves的情况还是达到超时。
注意点:
- 当’WAIT’返回时,所有之前的写命令保证接收由 WAIT 返回的slaves的数量。
- 如果命令呗当做事务的一部分发送,该命令不阻塞,而是只尽快返回先前写命令的slaves的数量。
- 如果timeout是0那意味着永远阻塞。
- 由于 WAIT 返回的是在失败和成功的情况下的slaves的数量。客户端应该检查返回的slaves的数量是 等于或更大的复制水平。
一致性(Consistency and WAIT)
WAIT 不能保证Redis强一致:尽管同步复制是复制状态机的一个部分,但是还需要其他条件。
不过,在sentinel和Redis群集故障转移中, WAIT 能够增强数据的安全性。
如果写操作已经被传送给一个或多个slave节点,当master发生故障我们极大概率(不保证100%)提升一 个受到写命令的slave节点为master:不管是Sentinel还是Redis Cluster 都会尝试选slave节点中最优(日 志最新)的节点,提升为master。
尽管是选择最优节点,但是仍然会有丢失一个同步写操作可能行。
实现细节
因为引入了部分同步,Redis slave节点在ping主节点时会携带已经处理的复制偏移量。
这被用在多个地方:
- 检测超时的slaves
- 断开连接后的部分复制
- 实现 WAIT
在 WAIT 实现的案例中,当客户端执行完一个写命令后,针对每一个复制客户端,Redis会为其记录写命令产生的复制偏移量。当执行命令 WAIT 时,Redis会检测 slaves节点是否已确认完成该操作或更新的操 作。
返回值
integer-reply: 当前连接的写操作会产生日志偏移,该命令会返回已处理至该偏移量的slaves的个数。
> SET foo bar
OK
> WAIT 1 0
(integer) 1
> WAIT 2 1000
(integer) 1在例子中,第一次调用 WAIT 并没有使用超时设置,并且设置写命令传输到一个slave节点,返回成功。
第二次使用时,我们设置了超时值并要求写命令传输到两个节点。
因为只有一个slave节点有效,1秒后 WAIT 解除阻塞并返回1–传输成功的slave节点数。
集群脑裂、网络问题导致的不一致性
什么是redis的集群脑裂?
redis的集群脑裂是指因为网络问题,导致redis master节点跟redis slave节点和sentinel集群处于不同 的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。
此时存在两个不同的master节点,就像一个大脑分裂成了两个。
集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的master节点将无法同步这些数据, 当网络问题解决之后,集群将原先的master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
具体来说,这种不一致性发生的情况是这样的:
当客户端与少数的节点(至少含有一个主节点)网络联通,但他们与其他大多数节点网络不通。
比如6个节点,A,B,C是主节点,A1,B1,C1分别是他们的从节点,一个客户端称之为Z。
当网络出问题时,他们被分成2组网络,组内网络联通,但2组之间的网络不通,假设A,C,A1,B1,C1彼 此之间是联通的,另一边,B和Z的网络是联通的。
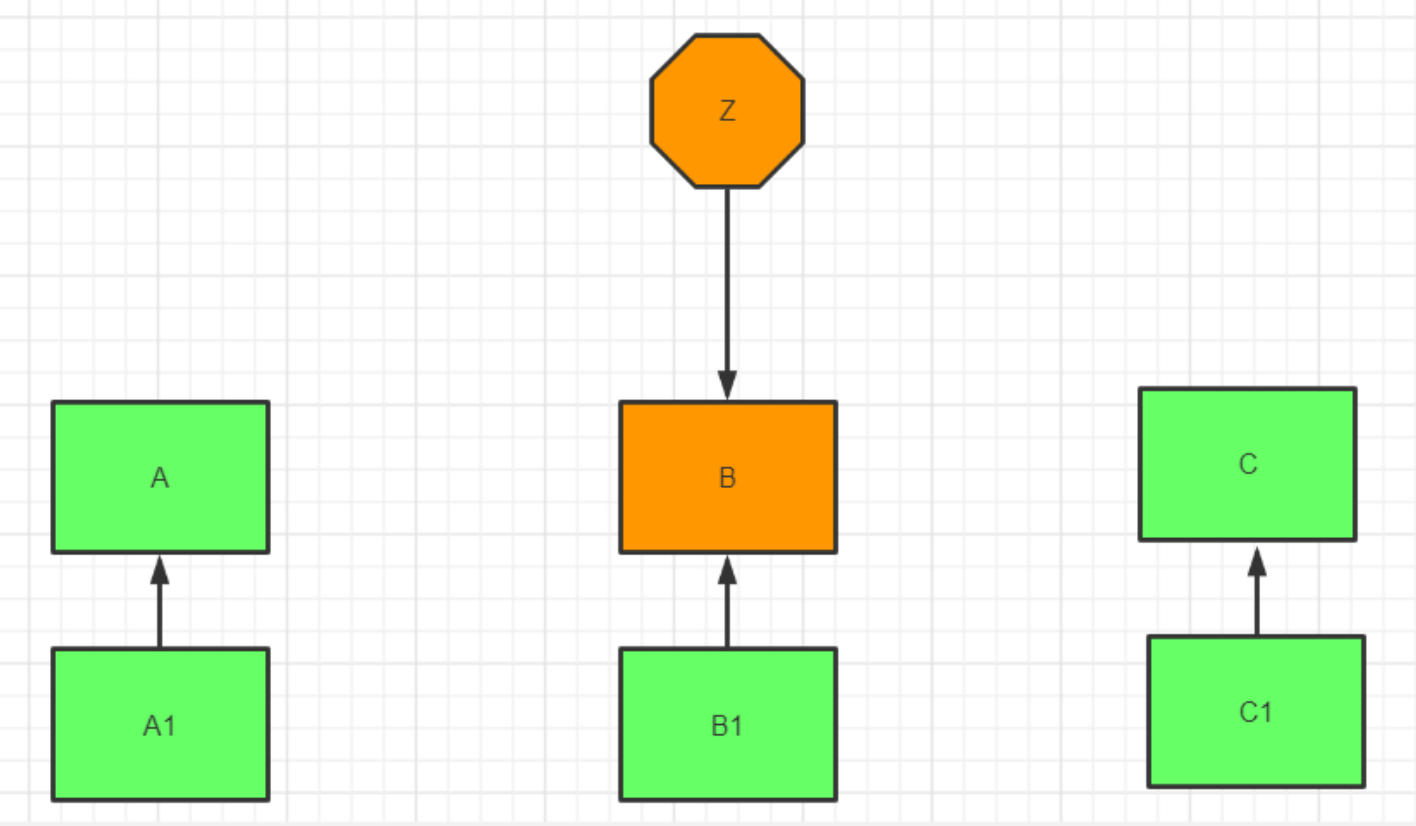
Z可以继续往B发起写操作,B也接受Z的写操作。
当网络恢复时,如果这个时间间隔足够短,集群仍然能继续正常工作。
如果时间比较长,以致B1在大多 数的这边被选为主节点,那刚才Z1发给B的写操作都将丢失。
注意,Z1给B发送写操作是有一个限制的,如果时间长度达到了大多数节点那边可以选出一个新的主节 点时,少数这边的所有主节点都不接受写操作。
这个时间的配置,称之为节点超时(node timeout)。
节点超时(node timeout)设置:
对集群来说非常重要:
- 当达到了这个节点超时的时间之后,主节点被认为已经宕机,可以用它的一个从节点来代替。
- 同样,在节点超时时,如果主节点依然不能联系到其他主节点,它将进入错误状态,不再接受写操 作。
在redis.conf中的参数说明:
cluster-node-timeout : 这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。
如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。
注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请求。
cluster-node-timeout默认15s。这个参数建议不要设置太小或者太大 。
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个主节点对外提供写服务, 一旦网络分区恢复,会将其中一个主节点变为从节点,这时会有大量数据丢失。
如果发生了脑裂,就会有cluster-node-timeout 的数据丢失。
Redis集群故障恢复的几个场景
问题1:如果主节点下线?从节点能否自动升为主节点?
答:主节点下线,从节点自动升为主节点。

问题2:主节点恢复后,主从关系会如何?
主节点恢复后,主节点变为从节点!

问题3:如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
答:服务是否继续, 可以通过redis.conf中的cluster-require-full-coverage参数(默认关闭)进行控制。
主从都宕掉,意味着有一片数据,会变成真空,没法再访问了!
如果无法访问的数据,是连续的业务数据,我们需要停止集群,避免缺少此部分数据,造成整个业 务的异常。
此时可以通过配置cluster-require-full-coverage为yes.
当cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行 故障恢复时,集群不可用
如果无法访问的数据,是相对独立的,对于其他业务的访问,并不影响,那么可以继续开启集群体提供服务。此时,可以配置cluster-require-full-coverage为no。
当cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行 故障恢复时,集群仍然可用
数据倾斜与流量倾斜
对于分布式数据库来说,存在倾斜问题是比较常见的
集群倾斜也就是各个节点使用的内存不一致
数据倾斜与流量倾斜原因
1.节点和槽分配不均,如果使用redis-trib.rb工具构建集群,则出现这种情况的机会不多
redis-trib.rb info ip:port查看节点,槽,键值分布
redis-trib.rb rebalance ip:port进行均衡(谨慎使用)2.不同槽对应键值数量差异比较大
CRC16算法正常情况下比较均匀
可能存在hash_tag
cluster countkeysinslot {slot}获取槽对应键值个数3.包含bigkey:例如大字符串,几百万的元素的hash,set等
在从节点:redis-cli --bigkeys
优化:优化数据结构4.内存相关配置不一致
hash-max-ziplist-value:满足一定条件情况下,hash可以使用ziplist
set-max-intset-entries:满足一定条件情况下,set可以使用intset
在一个集群内有若干个节点,当其中一些节点配置上面两项优化,另外一部分节点没有配置上面两项优化
当集群中保存hash或者set时,就会造成节点数据不均匀
优化:定期检查配置一致性5.请求倾斜:热点key
重要的key或者bigkey
Redis Cluster某个节点有一个非常重要的key,就会存在热点问题集群倾斜优化:
避免bigkey
避免hot keyhot key出现造成集群访问量倾斜
Hot key,即热点 key,指的是在一段时间内,该 key 的访问量远远高于其他的 redis key, 导致大部分 的访问流量在经过 proxy 分片之后,都集中访问到某一个 redis 实例上。
hot key 通常在不同业务中,存储着不同的热点信息。
- 新闻应用中的热点新闻内容;
- 活动系统中某个用户疯狂参与的活动的活动配置;
- 商城秒杀系统中,最吸引用户眼球,性价比最高的商品信息;
解决方案一:使用本地缓存
在 client 端使用本地缓存,从而降低了redis集群对hot key的访问量,但是同时带来两个问题:
- 如果对可能成为 hot key 的 key 都进行本地缓存,那么本地缓存是否会过大,从而影响应用程序本 身所需的缓存开销。
- 如何保证本地缓存和redis集群数据的有效期的一致性。
解决方案二: 利用分片算法的特性,对key进行打散处理
我们知道 hot key 之所以是 hot key,是因为它只有一个key,落地到一个实例上。
所以我们可以给hot key加上前缀或者后缀,把一个hotkey 的数量变成 redis 实例个数N的倍数M, 从而由访问一个 redis key 变成访问 N * M 个redis key。
N*M 个 redis key 经过分片分布到不同的实例上,将访问量均摊到所有实例。
big key 造成集群数据量倾斜
big key ,即数据量大的 key ,由于其数据大小远大于其他key,导致经过分片之后,某个具体存储这个 big key 的实例内存使用量远大于其他实例,造成,内存不足,拖累整个集群的使用。
big key 在不同业务上,通常体现为不同的数据,比如:
- 论坛中的大型持久盖楼活动;
- 聊天室系统中热门聊天室的消息列表;
解决方案:对 big key 进行拆分
对 big key 存储的数据 (big value)进行拆分,变成value1,value2… valueN
大厂使用什么样的redis集群:
redis 集群方案主要有3类
第一是使用类 codis 的代理模式架构,按组划分,实例之间互相独立;
第二是基于官方的 redis cluster 的服务端分片方案;
第三是:代理模式和服务端分片相结合的模式
- 基于官方 redis cluster 的服务端分片方案
- 类 codis 的代理模式架构
- 代理模式和服务端分片相结合的模式
类 codis 的代理模式架构
这套架构的特点:
- 分片算法:基于 slot hash桶;
- 分片实例之间相互独立,每组 一个master 实例和多个slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或etcd
- 旁路组件探活
使用这套方案的公司: 阿里云: ApsaraCache, RedisLabs、京东、百度等
阿里云
AparaCache 的单机版已开源(开源版本中不包含slot等实现),集群方案细节未知;ApsaraCache
百度 BDRP 2.0
主要组件:
- proxy,基于twemproxy 改造,实现了动态路由表;
- redis内核: 基于2.x 实现的slots 方案;
- metaserver:基于redis实现,包含的功能:拓扑信息的存储 & 探活;
- 最多支持1000个节点;
slot 方案:
redis 内核中对db划分,做了16384个db; 每个请求到来,首先做db选择;
数据迁移实现: 数据迁移的时候,最小迁移单位是slot,迁移中整个slot 处于阻塞状态,只支持读请求,不支持写请求;
对比官方 redis cluster/ codis 的按key粒度进行迁移的方案:按key迁移对用户请求更为友好,但迁移 速度较慢;这个按slot进行迁移的方案速度更快;
京东proxy
主要组件:
- proxy: 自主实现,基于 golang 开发;
- redis内核:基于 redis 2.8
- configServer(cfs)组件:配置信息存放;
- scala组件:用于触发部署、新建、扩容等请求;
- mysql:最终所有的元信息及配置的存储;
- sentinal(golang实现):哨兵,用于监控proxy和redis实例,redis实例失败后触发切换;
slot 方案实现: 在内存中维护了slots的map映射表;
数据迁移:
- 基于 slots 粒度进行迁移;
- scala组件向dst实例发送命令告知会接受某个slot;
- dst 向 src 发送命令请求迁移,src开启一个线程来做数据的dump,将这个slot的数据整块dump发送到 dst(未加锁,只读操作)
- 写请求会开辟一块缓冲区,所有的写请求除了写原有数据区域,同时双写到缓冲区中。
- 当一个slot迁移完成后,把这个缓冲区的数据都传到dst,当缓冲区为空时,更改本分片slot规则,不再拥有该slot,后续再请求这个slot的key返回moved;
- 上层proxy会保存两份路由表,当该slot 请求目标实例得到 move 结果后,更新拓扑;
跨机房:跨机房使用主从部署结构;没有多活,异地机房作为slave;
基于官方 redis cluster 的服务端分片方案
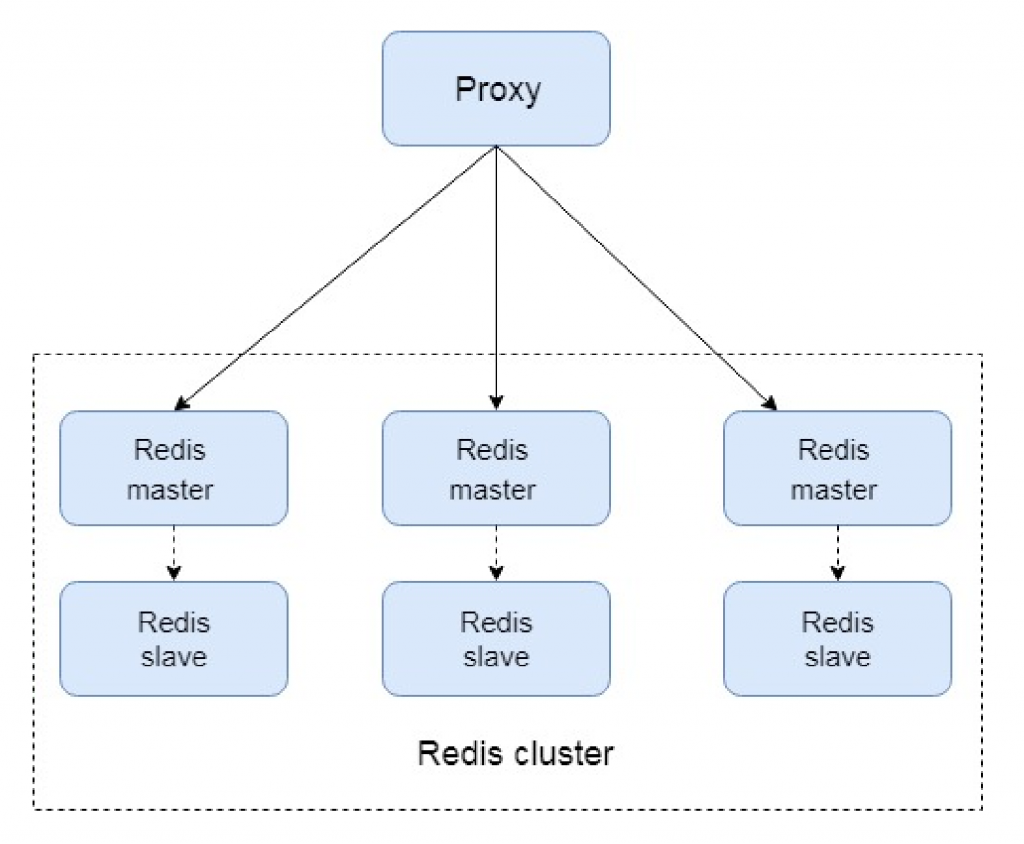
和上一套方案比,所有功能都集成在 redis cluster 中,路由分片、拓扑信息的存储、探活都在redis cluster中实现;各实例间通过 gossip 通信;这样的好处是简单,依赖的组件少,应对200个节点以内的 场景没有问题(按单实例8w read qps来计算,能够支持 200 * 8 = 1600w 的读多写少的场景);但当 需要支持更大的规模时,由于使用 gossip协议导致协议之间的通信消耗太大,redis cluster 不再合适;
使用这套方案的有:AWS, 百度贴吧
官方 redis cluster
数据迁移过程:
- 基于 key粒度的数据迁移;
- 迁移过程的读写冲突处理:
- 从A 迁移到 B;
- 访问的 key 所属slot 不在节点 A 上时,返回 MOVED 转向,client 再次请求B;
- 访问的 key 所属 slot 在节点 A 上,但 key 不在 A上, 返回 ASK 转向,client再次请求B;
- 访问的 key 所属slot 在A上,且key在 A上,直接处理;(同步迁移场景:该 key正在迁移,则阻塞)
AWS ElasticCache
ElasticCache 支持主从和集群版、支持读写分离;
集群版用的是开源的Redis Cluster,未做深度定制;
代理模式和服务端分片相结合的模式
p2p和代理的混合模式: 基于redis cluster + twemproxy混合模式
百度贴吧的ksarch-saas
基于redis cluster + twemproxy 实现;后被 BDRP 吞并;
twemproxy 实现了 smart client 功能;
使用 redis cluster后还加一层 proxy的好处:
- 对client友好,不需要client都升级为smart client;(否则,所有语言client 都需要支持一遍)
- 加一层proxy可以做更多平台策略;比如在proxy可做 大key、热key的监控、慢查询的请求监控、 以及接入控制、请求过滤等;
redis 5.0 中有个 feature,作者计划给 redis cluster加一个proxy
总之,大厂使用代理分片的方案,还是更加广泛一些。虽然,代理分片,中间增加一层Proxy进行转 发,必然会有一定的性能损耗(理论值20ms),但是那也是非常有限。
知乎为什么没有使用官方 Redis 集群方案
在 2015 年调研过多种集群方案,综合评估多种方案后,最终选择了看起来较为陈旧的 Twemproxy 而 不是官方 Redis 集群方案与 Codis,具体原因如下:
MIGRATE 造成的阻塞问题:
Redis 官方集群方案使用 CRC16 算法计算哈希值并将 Key 分散到 16384 个 Slot 中,由使用方自行分配 Slot 对应到每个分片中,扩容时由使用方自行选择 Slot 并对其进行遍历,对 Slot 中每一个 Key 执行 MIGRATE 命令进行迁移。
调研后发现,MIGRATE 命令实现分为三个阶段:
- DUMP 阶段:由源实例遍历对应 Key 的内存空间,将 Key 对应的 Redis Object 序列化,序列化协议 跟 Redis RDB 过程一致;
- RESTORE 阶段:由源实例建立 TCP 连接到对端实例,并将 DUMP 出来的内容使用 RESTORE 命令 到对端进行重建,新版本的 Redis 会缓存对端实例的连接;
- DEL 阶段(可选):如果发生迁移失败,可能会造成同名的 Key 同时存在于两个节点,此时 MIGRATE 的 REPLACE 参数决定是是否覆盖对端的同名 Key,如果覆盖,对端的 Key 会进行一次删除操 作,4.0 版本之后删除可以异步进行,不会阻塞主进程。
经过调研,认为这种模式MIGRATE 并不适合知乎的生产环境。
Redis 为了保证迁移的一致性, MIGRATE 所有操作都是同步操作,执行 MIGRATE 时,两端的 Redis 均会进入时长不等的 BLOCK 状态。
对于小 Key,该时间可以忽略不计,但如果一旦 Key 的 内存使用过大,一个 MIGRATE 命令轻则导致尖刺,重则直接触发集群内的 Failover,造成不必要的切换
同时,迁移过程中访问到处于迁移中间状态的 Slot 的 Key 时,根据进度可能会产生 ASK 转向,此时需 要客户端发送 ASKING 命令到 Slot 所在的另一个分片重新请求,请求时延则会变为原来的两倍。
同样,方案调研期间的 Codis 采用的是相同的 MIGRATE 方案,但是使用 Proxy 控制 Redis 进行 迁移操作而非第三方脚本(如 redis-trib.rb),基于同步的类似 MIGRATE 的命令,实际跟 Redis 官方集群方案存在同样的问题。
缓存模式下高可用方案不够灵活:
还有,官方集群方案的高可用策略仅有主从一种,高可用级别跟 Slave 的数量成正相关,如果只有一个 Slave,则只能允许一台物理机器宕机, Redis 4.2 roadmap 提到了 cache-only mode,提供类似于 Twemproxy 的自动剔除后重分片策略,但是截至目前仍未实现。
内置 Sentinel 造成额外流量负载:
另外,官方 Redis 集群方案将 Sentinel 功能内置到 Redis 内,这导致在节点数较多(大于 100)时在 Gossip 阶段会产生大量的 PING/INFO/CLUSTER INFO 流量,根据 issue 中提到的情况,200 个使用 3.2.8 版本节点搭建的 Redis 集群,在没有任何客户端请求的情况下,每个节点仍然会产生 40Mb/s 的 流量,虽然到后期 Redis 官方尝试对其进行压缩修复,但按照 Redis 集群机制,节点较多的情况下无论 如何都会产生这部分流量,对于使用大内存机器但是使用千兆网卡的用户这是一个值得注意的地方。
slot 存储开销:
最后,每个 Key 对应的 Slot 的存储开销,在规模较大的时候会占用较多内存,4.x 版本以前甚至会达到 实际使用内存的数倍,虽然 4.x 版本使用 rax 结构进行存储,但是仍然占据了大量内存,从非官方集群 方案迁移到官方集群方案时,需要注意这部分多出来的内存。
总之,官方 Redis 集群方案与 Codis 方案对于绝大多数场景来说都是非常优秀的解决方案,但是仔细调 研发现并不是很适合集群数量较多且使用方式多样化的知乎
总之,场景不同侧重点也会不一样,方案也需要调整,没有最有,只有最适合。
中小厂使用什么样的redis集群
既然大厂倾向于选择代理分片模式的集群如Codis,那么中小厂子该如何选择呢?
Codis与Redis Cluster集群方案对比
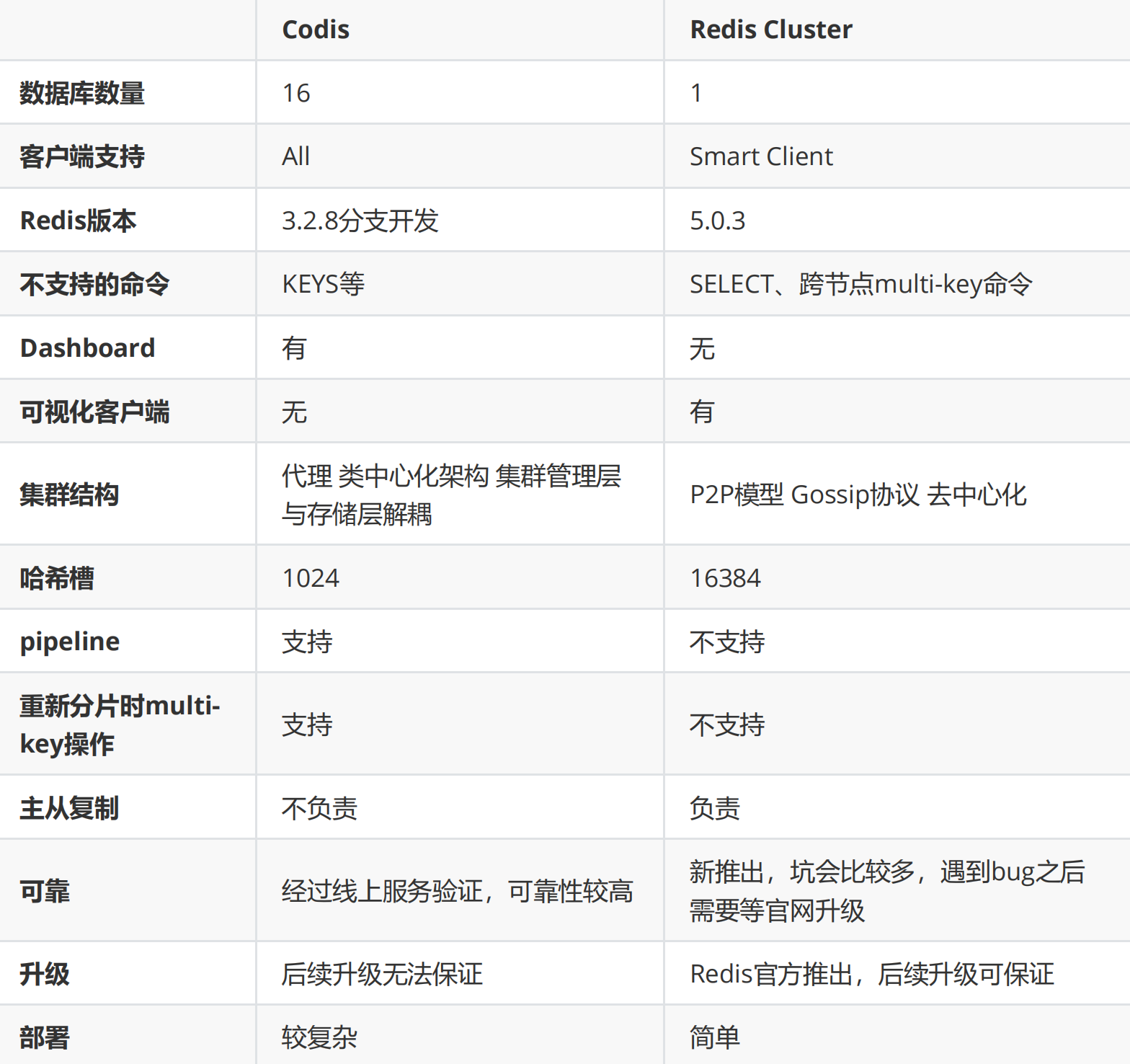
通过以上表格对比,发现Codis和Redis Cluster各有特点,可以根据项目实际需要进行选择。
选择Redis Cluster的场景:
- 需要redis的新特性,例如:Stream
- 需要更丰富的命令支持
- 资源紧张
选择Codis的场景:
- Codis支持的命令可满足需求
- 资源充裕
- 强调可靠性
Redis Cluster没有采用中心化模式的Proxy方案,而是把请求转发逻辑一部分放在客户端,一部分放在了服务端,它们之间互相配合完成请求的处理。
Redis Cluster是在Redis 3.0推出的,但随着Redis的版本迭代,Redis官方的Cluster也越来越稳定,更多人开始采用官方的集群化方案。
Redis Cluster没有了中间的Proxy代理层,那么是如何进行请求的转发呢?
Smart Client客户端路由转发
Redis把请求转发的逻辑放在了Smart Client中,要想使用Redis Cluster,必须升级Client SDK,这个 SDK中内置了请求转发的逻辑,所以业务开发人员同样不需要自己编写转发规则,Redis Cluster采用 16384个槽位进行路由规则的转发。
总之,对于中小项目来说,选择 Redis Cluster 会更加合理。 对于大型集群来说, 由于200 个使用 3.2.8 版本节点搭建的 Redis 集群,在没有任何客户端请求的情况 下,每个节点仍然会产生 40Mb/s 的流量, 所以不建议使用官方的 Redis Cluster ,建议采用 codis、 twenproxy 等代理方案。
高可用Redis集群的架构
集群的性能和数据量参考指标
单节点redis推荐的容量 10-20G
单节点redis推荐的并发量 4-5WQPS
选型:哨兵模式
如果系统的缓存大小<10G
建议使用一主多从的哨兵模式。
从节点的数量,根据qps来扩展,比如10WQPS,可以有3-4个从节点。
选型: Redis Cluster模式
如果系统的缓存大小<2000G, 主节点数<200个,建议使用Redis Cluster模式
选型:proxy模式
对于大型集群来说, 由于200 个使用 3.2.8 版本节点搭建的 Redis 集群,在没有任何客户端请求的情况 下,每个节点仍然会产生 40Mb/s 的流量, 所以不建议使用官方的 Redis Cluster ,建议采用 codis、 twenproxy 等代理方案。
缓存穿透
什么是缓存穿透
缓存穿透指的查询缓存和数据库中都不存在的数据,这样每次请求直接打到数据库,就好像缓存不存在一样。
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
要点:访问一个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。
此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被 “穿透”了一样,起不到任何作用。
对于系统A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
举个栗子。 数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。 这样的话,缓存中不会有,请求每次都“绕过缓存”,直接查询数据库。 这种恶意攻击场景的缓存穿透就会直接把数据库给打死。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透可能会使后端存储负载加大,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
缓存穿透可能有两种原因:
- 自身业务代码问题
- 恶意攻击,爬虫造成空命中
缓存穿透解决方案
1、缓存空值
当访问缓存和DB都没有查询到值时,可以将空值写进缓存, 但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
2、接口校验
在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。 可以在最外层先做一层校验: 用户鉴权、数据合法性校验等,例如sku单品查询中,sku单品的ID是正整数,则可以直接对非正整数直接过滤等等。
3、访问者黑名单
进行实时监控,对于redis缓存中命中率急速下降时,迅速排查访问对象和访问数据,将其设置为黑名单。 使用bitmaps类型定义一个访问黑名单,名单id作为bitmaps的偏移量,每次访问时与bitmaps中的id进行比较,如果访问id在bitmaps中,则进行拦截,不给其访问。
4、bitSet/hashmap 记录存在性
存在去查redis,不存在直接返回
5、布隆过滤器
使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
布隆过滤器由一个 bitSet 和 一组 Hash 函数(算法)组成, 是一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。
缓存空值/默认值
一种方式是在数据库不命中之后,把一个空对象或者默认值保存到缓存,之后再访问这个数据,就会从 缓存中获取,这样就保护了数据库。
缓存空值有两大问题:
1. 空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严 重), 比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
2. 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。 例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储 层数据的不一致。这时候可以利用消息队列或者其它异步方式清理缓存中的空对象。
适用于数据变化频繁的场景。
布隆过滤器方案
除了缓存空对象,我们还可以在存储和缓存之前,加一个布隆过滤器,做一层过滤。 布隆过滤器里会保存数据是否存在,如果判断数据不存在,就不会访问存储。
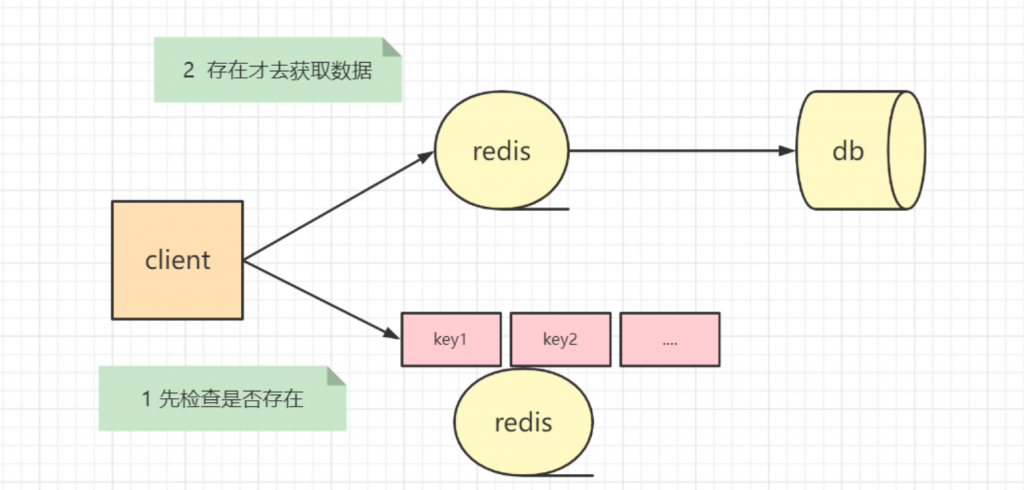
适用于数据相对固定的场景。
什么是布隆过滤器
当你遇到数据量大,又需要去重的时候就可以考虑布隆过滤器,如下场景:
- 解决 Redis 缓存穿透问题(面试重点);
- 邮件过滤,使用布隆过滤器实现邮件黑名单过滤;
- 爬虫爬过的网站过滤,爬过的网站不再爬取;
- 推荐过的新闻不再推荐;
布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,它是一种 space efficient 的 概率型数据结构,用于判断一个元素是否在集合中。
当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么 这个数据一定不存在。
哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的 1/8 或 1/4 的空间复杂度就能 完成同样的问题。
布隆过滤器可以插入元素,但不可以删除已有元素。
其中的元素越多,false positive rate(误报率)越大,但是 false negative (漏报)是不可能的。
布隆过滤器原理
BloomFilter 的算法是,首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
加入元素的方法:
加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
如下图所示:
删除元素的方法:
为什么不允许删除元素呢?
删除意味着需要将对应的 k 个 bits 位置设置为 0,其中有可能是其他元素对应的位。
因此 remove 会引入 false negative,这是绝对不被允许的。
False Positive:把合法的判断成非法的,译为“误报”。(相当于医学上的假阳性)
检测 key 是否存在的方法:
仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
布隆过滤器判断存在不一定真的存在。 哈希函数会出现碰撞,所以布隆过滤器会存在误判。
这里的误判率是指,BloomFilter 判断某个 key 存在,但它实际不存在的概率,因为它存的是 key 的 Hash 值,而非 key 的值。
所以有概率存在这样的 key,它们内容不同,但多次 Hash 后的 Hash 值都相同。
对于 BloomFilter 判断不存在的 key ,则是 100% 不存在的,反证法,如果这个 key 存在,那它每次 Hash 后对应的 Hash 值位置肯定是 1,而不会是 0。
缓存击穿
一个并发访问量比较大的key在某个时间过期,导致所有的请求直接打在DB上。
具体来是,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况, 当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
结果是: 请求会直接访问数据库,并回设到缓存中,高并发访问数据库会导致数据库崩溃。
缓存击穿的原因:
- 缓存不高可用, 缓存部分节点崩溃,导致部分槽位不可以
- 高并发并发场景下,key过期了
缓存击穿解决方案:
缓存击穿是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过 来,从而大量的请求打到db。
描述:某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了, 所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
1、实时调整key过期时间,越是热门数据过期时间越长:
在redis高峰访问时期,提前设置热门数据到缓存中,或适当延长缓存中key过期时间。
实时监控哪些数据热门,实时调整key过期时间。
2、对于热点key设置永不过期。
设置热点数据永远不过期。
如有变化,主动刷新缓存数据,同时也能保障数据一致性
3、缓存过期后,进行加锁控制缓存设置
⽐如请求查询A,发现缓存中没有,对A这个key加锁,同时去数据库查询数据,写⼊缓存,再返回给⽤户,这样后⾯的请求就可以从缓存中拿到数据了。
4、多级缓存,每一次缓存,过期时间不一样。
jvm进程内的缓存,nginx 进程内的缓存,都可以使用。
缓存雪崩
某⼀时刻发⽣⼤规模的缓存失效的情况,例如缓存服务宕机、大量key在同一时间过期,这样的后果就是 ⼤量的请求进来直接打到DB上,db无响应,最后可能导致整个系统的崩溃,称为雪崩。
对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求
但是缓存机器意外发生了:
- 缓存全盘宕机,缓存挂了
- 大量key在同一时间过期
此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后db无响应,最后导致整 个系统的崩溃。
此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被 新的流量给打死了。
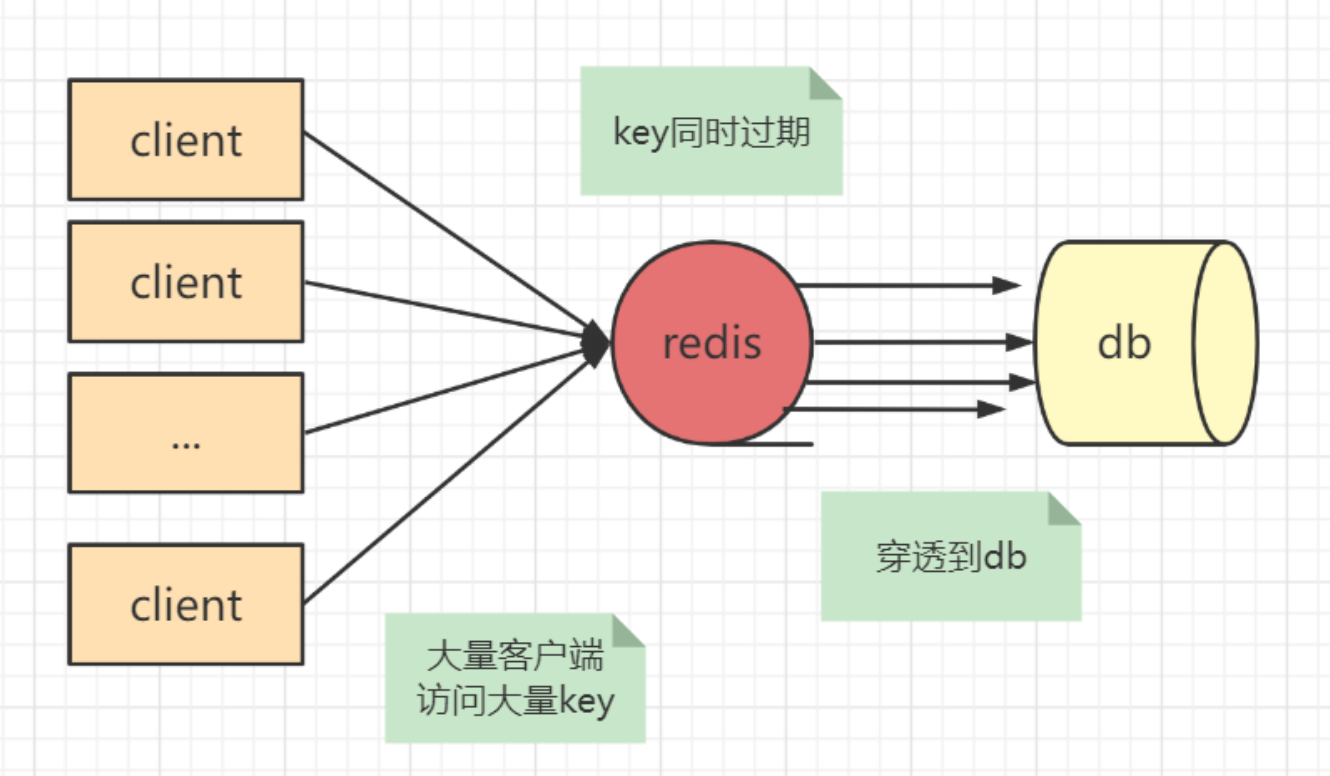
缓存雪崩解决方案:
缓存雪崩是三大缓存问题里最严重的一种,我们来看看怎么预防和处理。
- 提高缓存可用性
1、集群部署
通过集群来提升缓存的可用性,可以利用Redis本身的Redis Cluster或者第三方集群方案如Codis 等。
2、多级缓存
设置多级缓存,设置一级缓存本地 guava 缓存,第一级缓存失效的基础上再访问二级缓存 redis, 每一级缓存的失效时间都不同。
- 过期时间
1、过期时间打散
为了避免大量的缓存在同一时间过期,可以把不同的 key 过期时间随机生成,避免过期时间太过集中。
既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。
可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同 一时刻失效。
在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个 随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的 商品缓存时间短一些,也能节省缓存服务的资源。
2. 热点数据永不过期
该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
- 熔断降级
1. 服务熔断
当缓存服务器宕机或超时响应时,为了防止整个系统出现雪崩,可以使用hystrix 类似的熔断,暂 时停止业务服务访问db, 或者其他被依赖的服务,避免 MySQL 被打死。
2. 服务降级
当出现大量缓存失效,而且处在高并发高负荷的情况下,在业务系统内部暂时舍弃对一些非核心的 接口和数据的请求,而直接返回一个提前准备好的 fallback(退路)错误处理信息。
Redis持久化导致的高可用问题分析及解决
Redis的持久化配置
redis的 rdb 和 aof 持久化的区别 aof,rdb是两种 redis持久化的机制。用于crash后,redis的恢复。
redis将数据保存在内存中,一旦Redis服务器被关闭,或者运行Redis服务的主机本身被关闭的话,储存 在内存里面的数据就会丢失
如果仅仅将redis用作缓存的话,那么这种数据丢失带来的问题并不是非常大,只需要重启机器,然后再 次将数据同步到缓存中就可以了
但如果将redis用作DB的话,那么因为一些原因导致数据丢失的情况就不能接受
Redis的持久化就是将储存在内存里面的数据以文件形式保存硬盘里面,这样即使Redis服务端被关闭, 已经同步到硬盘里面的数据也不会丢失
除此之外,持久化也可以使Redis服务器重启时,通过载入同步的持久文件来还原之前的数据,或者使用 持久化文件来进行数据备份和数据迁移等工作
RDB持久化功能
RDB持久化功能可以将Redis中所有数据生成快照并以二进行文件的形式保存到硬盘里,文件名为.RDB 文件
在Redis启动时载入RDB文件,Redis读取RDB文件内容,还原服务器原有的数据库数据
过程如下图所示:
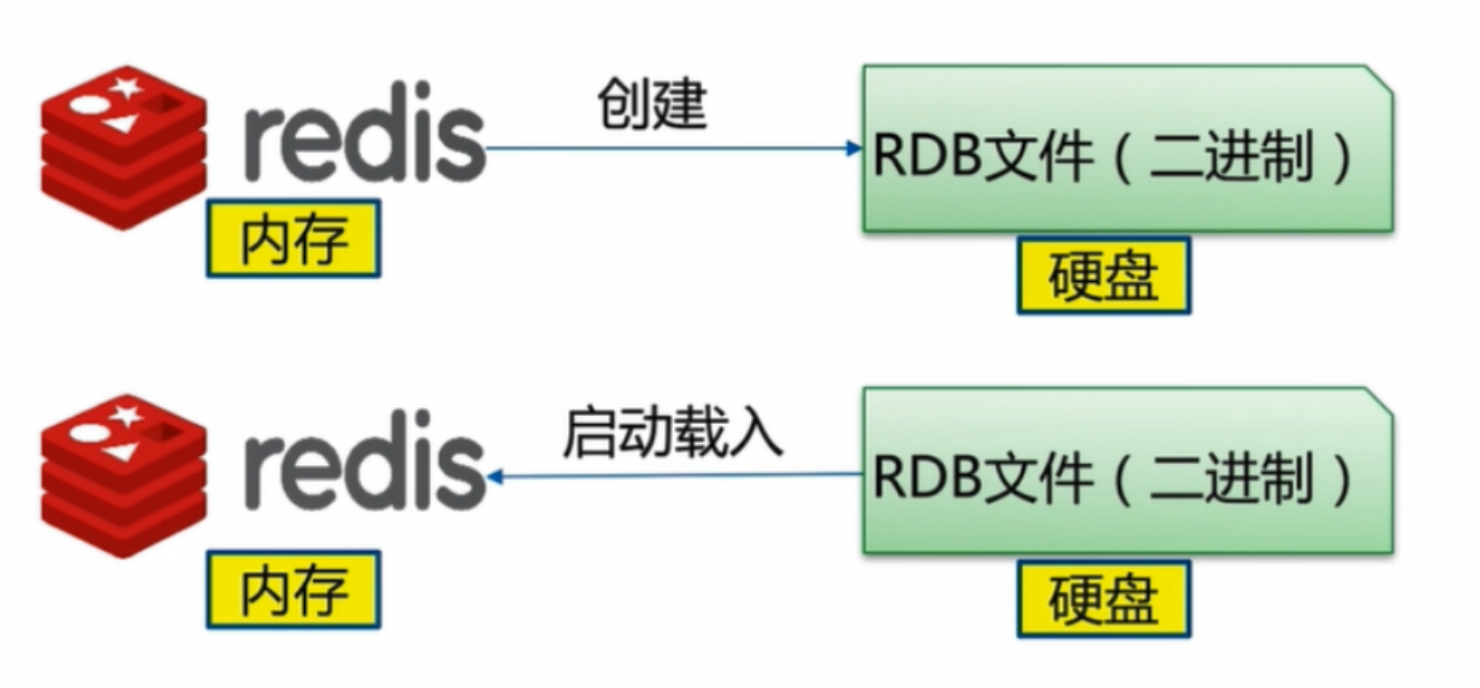
Redis服务端创建RDB文件,有三种方式
- 使用SAVE命令手动同步创建RDB文件
- 使用BGSAVE命令异步创建RDB文件
- 自动创建RDB文件
使用SAVE命令手动同步创建RDB文件
客户端向Redis服务端发送SAVE命令,服务端把当前所有的数据同步保存为一个RDB文件
使用BGSAVE命令异步创建RDB文件
执行BGSAVE命令也会创建一个新的RDB文件
BGSAVE不会造成redis服务器阻塞:在执行BGSAVE命令的过程中,Redis服务端仍然可以正常的处理其他的命令请求
BGSAVE命令执行步骤:
自动创建RDB文件
打开Redis的配置文件/etc/redis.conf
save 900 1save 300 10save 60 10000
自动持久化配置解释:
- save 900 1表示:如果距离上一次创建RDB文件已经过去的900秒时间内,Redis中的数据发生了1 次改动,则自动执行BGSAVE命令
- save 300 10表示:如果距离上一次创建RDB文件已经过去的300秒时间内,Redis中的数据发生了 10次改动,则自动执行BGSAVE命令
- save 60 10000表示:如果距离上一次创建RDB文件已经过去了60秒时间内,Redis中的数据发生了 10000次改动,则自动执行BGSAVE命令
当三个条件中的任意一个条件被满足时,Redis就会自动执行BGSAVE命令
rdb持久化的特性如下:
fork一个进程,遍历hash table,利用copy on write,把整个db dump保存下来。
save, shutdown, slave 命令会触发这个操作。
粒度比较大,如果save, shutdown, slave 之前crash了,则中间的操作没办法恢复。
AOF的功能
AOF持久化保存数据库的方法是:每当有修改的数据库的命令被执行时,服务器就会将执行的命令写入到AOF文件的末尾。
因为AOF文件里面储存了服务器执行过的所有数据库修改的命令,所以Redis只要重新执行一遍AOF文件 里面保存的命令,就可以达到还原数据库的目的
AOF安全性问题
虽然服务器执行一次修改数据库的命令,执行的命令就会被写入到AOF文件,但这并不意味着AOF持久化方式不会丢失任何数据
在linux系统中,系统调用write函数,将一些数据保存到某文件时,为了提高效率,系统通常不会直接将内容写入硬盘里面,而是先把数据保存到硬盘的缓冲区之中。
等到缓冲区被填满,或者用户执行fsync调用和fdatasync调用时,操作系统才会将储存在缓冲区里的内容真正的写入到硬盘里 对于AOF持久化来说,当一条命令真正的被写入到硬盘时,这条命令才不会因为停机而意外丢失
因此,AOF持久化在遭遇停机时丢失命令的数量,取决于命令被写入硬盘的时间 越早将命令写入到硬盘,发生意外停机时丢失的数据就越少,而越迟将命令写入硬盘,发生意外停机时丢失的数据就越多
AOF三种策略
为了控制Redis服务器在遇到意外停机时丢失的数据量,Redis为AOF持久化提供了appendfsync选项, 这个选项的值可以是always,everysec或者no
- appendfsync always:
- 总是写入aof文件,并通过事件循环磁盘同步,即使Redis遭遇意外停机时,最多只丢失一事件循环 内的执行的数据
- appendfsync everysec:
- 每一秒写入aof文件,并完成磁盘同步,即使Redis遭遇意外停机时,最多只丢失一秒钟内的执行的 数据
- appendfsync no:
- 服务器不主动调用fdatasync,由操作系统决定任何将缓冲区里面的命令写入到硬盘里,这种模式 下,服务器遭遇意外停机时,丢失的命令的数量是不确定的
AOF三种方式比较
运行速度:
- always的速度慢,everysec和no都很快, always丢失的数据最少,但是硬盘IO开销很多,一般的 SATA硬盘一秒种只能写入几百次数据
- everysec每秒同步一次数据,如果Redis发生故障,可能会丢失1秒钟的数据
- no则系统控制,不可控,不知道会丢失多少数据
可见,从持久化角度讲,always是最安全的。 从效率上讲,no是最快的。而redis默认设置进行了折中,选择了everysec。合情合理。
配置文件中AOF相关选项
appendonly yes # 改为yes,开启AOF功能
appendfilename "appendonly.aof" # 生成的AOF的文件名
appendfsync everysec # AOF同步的策略
no-appendfsync-on-rewrite yes # AOF重写时,是否做append的操作,yes是不做,在
`rewrite`期间的`AOF`有丢失的风险。配置文件中AOF相关选项
- 建议把appendfsync选项设定为everysec,进行持久化,这种情况下Redis宕机最多只会丢失一秒钟的数据
- 如果使用Redis做为缓存时,即使数据丢失也不会造成任何影响,只需要在下次加载时重新从数据源加载就可以了
- 不要占用100%的内存。一般分配服务器60%到70%的内存给Redis使用,剩余的内存分留给类似 fork的操作
aof与rdb持久化的区别
把写操作指令,持续的写到一个类似日志文件里。(类似于从postgresql等数据库导出sql一样,只记录写操作)
粒度较小,crash之后,只有crash之前没有来得及做日志的操作没办法恢复。
两种区别就是:
- 一个是持续的用日志记录写操作,crash后利用日志恢复;
- 一个是平时写操作的时候不触发写,只有手动提交save命令,或者是关闭命令时,才触发备份操 作。
选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的 时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。
rdb这个就更有些 eventually consistent的意思了。
AOF重写出现Redis主进程阻塞,应用端响应超时的问题
问题背景
某个业务线使用Redis集群保存用户session数据,数据量大约在4千万-5千万,每天发生3-4次AOF 重写,每次时间持续30-40秒,AOF重写期间出现Redis主进程阻塞,应用端响应超时的问题。
环境:Redis 2.8,一主一从。
什么是AOF重写
AOF重写是AOF持久化的一个机制,用来压缩AOF文件。
随着服务器的不断运行,为了记录Redis中数据的变化,Redis会将越来越多的命令写入到AOF文件 中,使得AOF文件的体积来断增大
为了让AOF文件的大小控制在合理的范围,redis提供了AOF重写功能,通过这个功能,服务器可以产生 一个新的AOF文件:
- 新的AOF文件记录的数据库数据和原有AOF文件记录的数据库数据完全一样
- 新的AOF文件会使用尽可能少的命令来记录数据库数据,因此新的AOF文件的体积通常会比原有AOF文件的体积要小得多
- AOF重写期间,服务器不会被阻塞,可以正常处理客户端发送的命令请求
AOF重写功能就是把Redis中过期的,不再使用的,重复的以及一些可以优化的命令进行优化,重新生成一个新的AOF文件,从而达到减少硬盘占用量和加速Redis恢复速度的目的
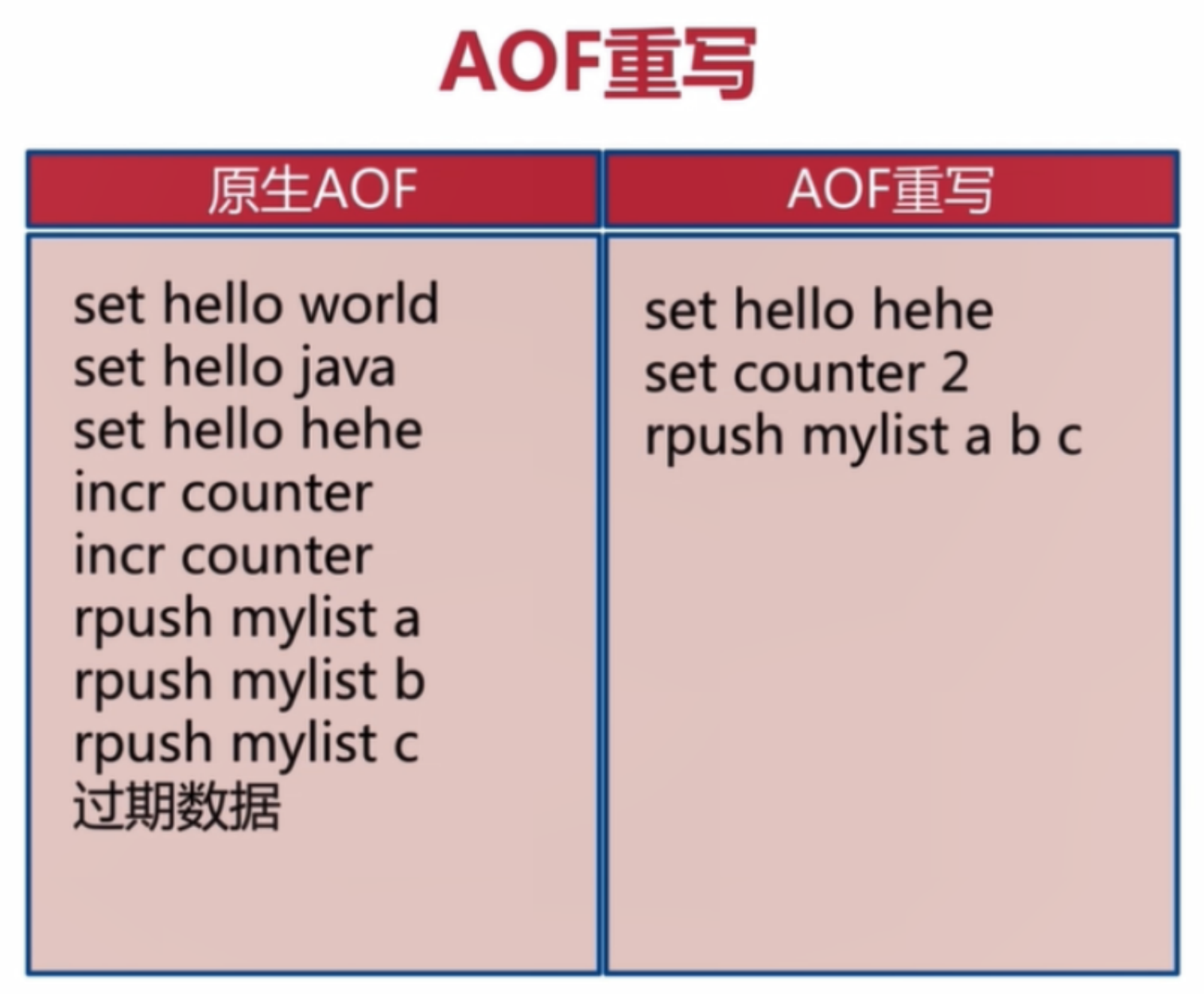
AOF重写的目的
Redis 的rewrite策略,实现AOF文件的减肥,但是结果是幂等的
AOF重写的流程
Redis通过fork一个子进程,重新写一个新的AOF文件,该次重写不是读取旧的AOF文件进行复制,而是读取内存中的Redis数据库,重写一份AOF文件,有点类似于RDB的快照方式。
在子进程进行AOF重写期间,Redis主进程执行的命令会被保存在AOF重写缓冲区里面,这个缓冲区在服务器创建子进程之后开始使用,当Redis执行完一个写命令之后,它会同时将这个写命令发送给 AOF缓 冲区和AOF重写缓冲区。
如下图:
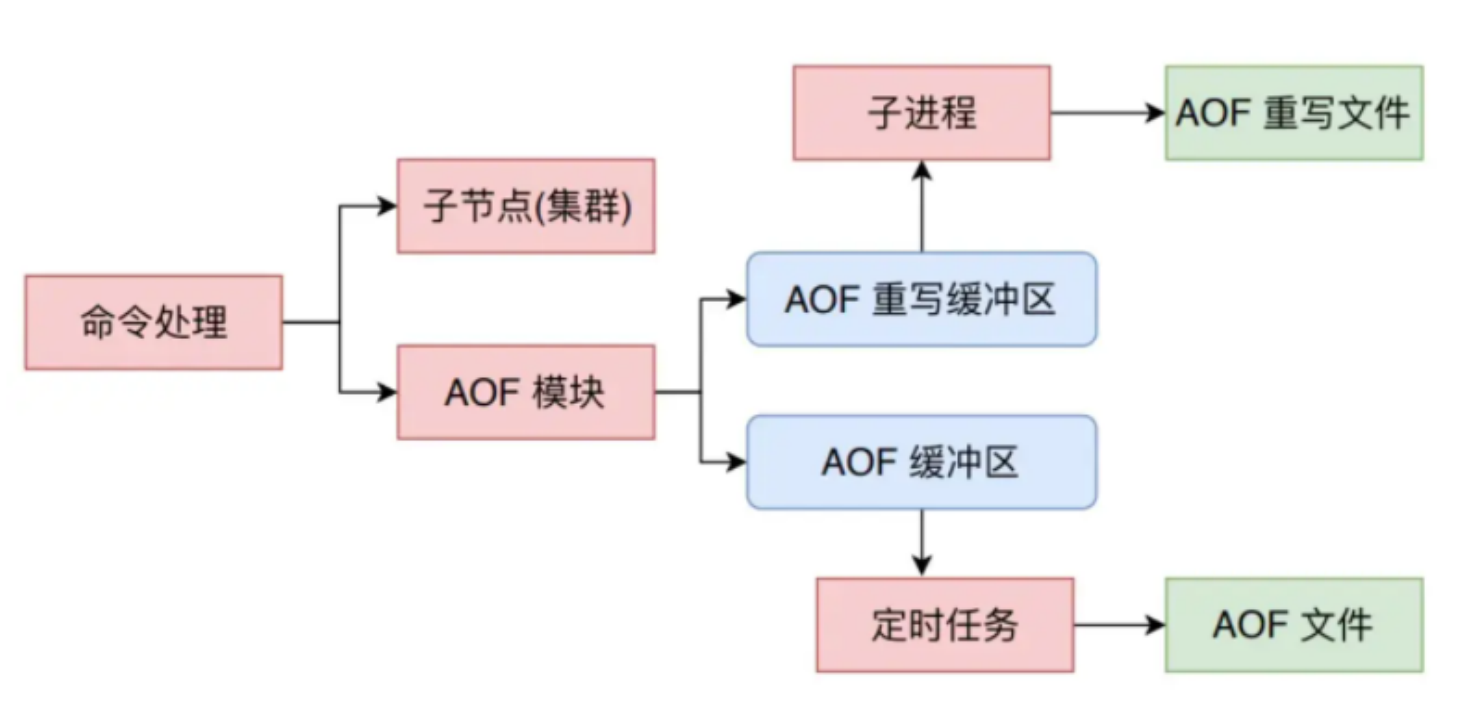
具体的步骤如下:
- 无论是执行bgrewriteaof命令手动开启重写,还是自动进行AOF重写,实际上都是执行 BGREWRITEAOF命令
- 执行bgrewriteaof命令,Redis会fork一个子进程,
- 子进程对内存中的Redis数据进行回溯,生成新的AOF文件
- Redis主进程会处理正常的命令操作
- 同时Redis把会新的命令写入到aof_rewrite_buf当中,当bgrewriteaof命令执行完成,新的AOF文件生 成完毕,Redis主进程会把aof_rewrite_buf中的命令追加到新的AOF文件中
- 用新生成的AOF文件替换旧的AOF文件
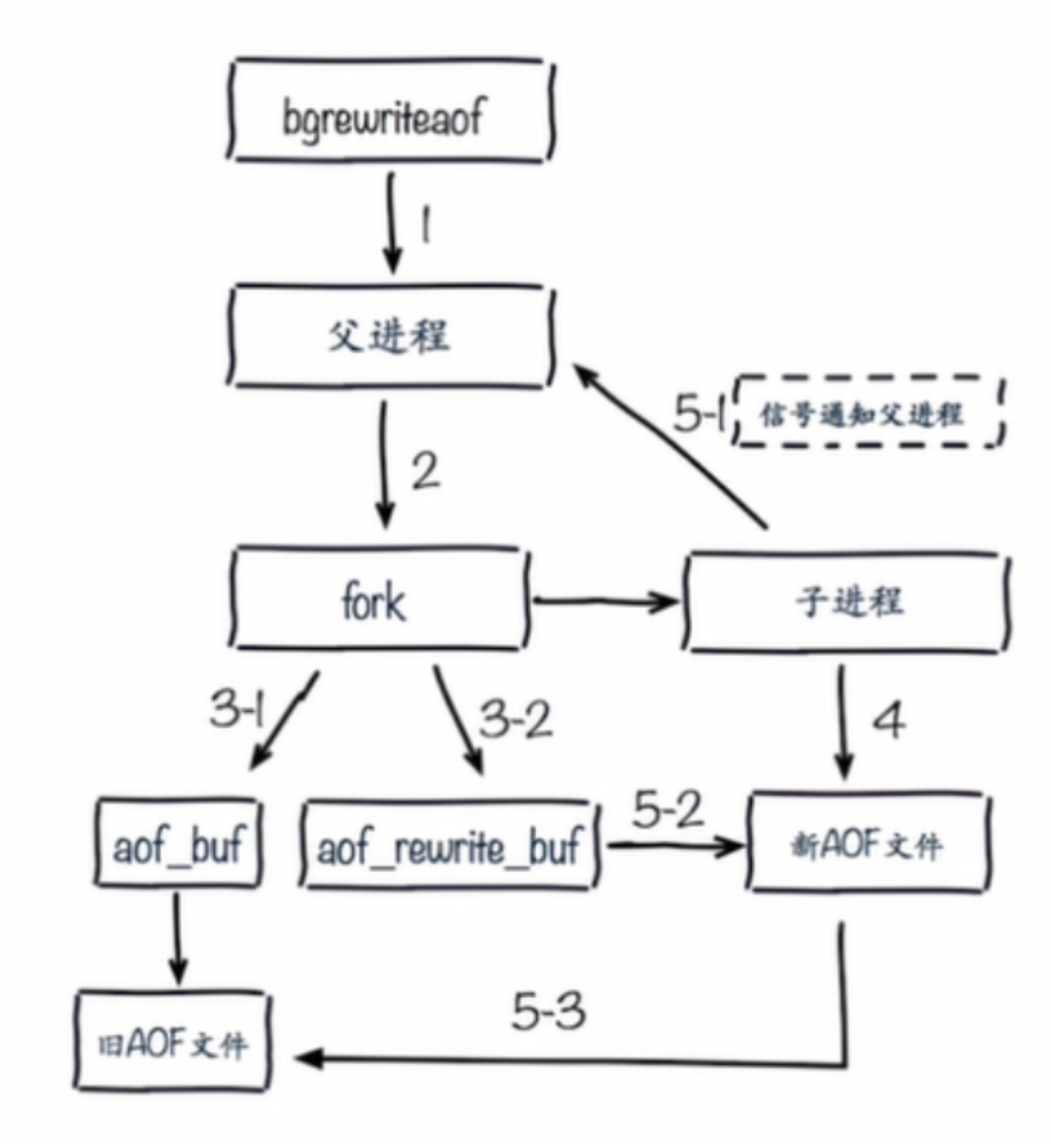
AOF重写导致主进程阻塞原因分析
当AOF重写子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接收到该信号之后, 会调用一个信号处理函数,并执行以下工作:
- 将AOF重写缓冲区中的所有内容写入到新的AOF文件中,保证新 AOF文件保存的数据库状态和服务器当前状态一致。
- 对新的AOF文件进行改名,原子地覆盖现有AOF文件,完成新旧文件的替换
- 继续处理客户端请求命令。
现在问题出现了,同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘, 特别需要注意的是: bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候,出现阻塞的情形,导致主进程阻塞。
根因分析与解决方案
这是当时的Redis配置:
192.168.56.121:6379> config get *append*
1) "no-appendfsync-on-rewrite"
2) "no"
3) "appendonly"
4) "yes"
5) "appendfsync"
6) "everysec"从配置看,原因理论上就很清楚了:
- 我们的这个Redis实例使用AOF进行持久化(appendonly)
- appendfsync策略采用的是everysec刷盘。
但是AOF随着时间推移,文件会越来越大,因此,Redis自动启动一个rewrite策略,实现AOF文件的减 肥,但是结果是幂等的
- no-appendfsync-on-rewrite的策略是 no,这就会导致在进行rewrite操作时,appendfsync会写 入aof文件而可能被阻塞。
这不是什么新问题,很多开启AOF的业务场景都会遇到这个问题。
解决的办法有这么几个:
- 将no-appendfsync-on-rewrite设置为yes.
yes表示在日志AOF重写时,不进行aof文件命令追加操作,而只是将命令放在重写缓冲区里,避免与命令的追加造成磁盘IO造成的阻塞。但是在rewrite期间的AOF有丢失的风险。
- 给当前Redis实例添加slave节点,当前节点设置为master, 然后master节点关闭AOF,slave节点开启AOF。
这样的方式的风险是如果master挂掉,尚没有同步到slave的数据会丢失。
比较折中的方式:
- 在master节点设置将no-appendfsync-on-rewrite设置为yes,注意,还有后手,就是停止自动aof 重写,如何停止,将auto-aof-rewrite-percentage参数设置为0,关闭主动重写
auto-aof-rewrite-percentage 参数说明 aof文件增长比例,指当前aof文件比上次重写的增长比例大小。aof重写即在aof文件在一定 大小之后,重新将整个内存写到aof文件当中,以反映最新的状态(相当于bgsave)。这样就避免了,aof文件过大而实际内存数据小的问题(频繁修改数据问题).
- 为了防止AOF文件越来越大,在任务调度配置在凌晨低峰期定时手动执行bgrewriteaof命令完成每 日一次的AOF重写
- 在重写时为了避免硬盘空间不足或者IO使用率高影响重写功能添加了硬盘空间报警和IO使用率报警 保障重写的正常进行
Redis不能保证100%数据不丢失
Redis能否保证100%数据不丢失,答案是no。
哪怕是在要求最高的持久化配置场景,将appendfsync值设置为always,其实也会产生数据丢失。
图解:redis的事件循环
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}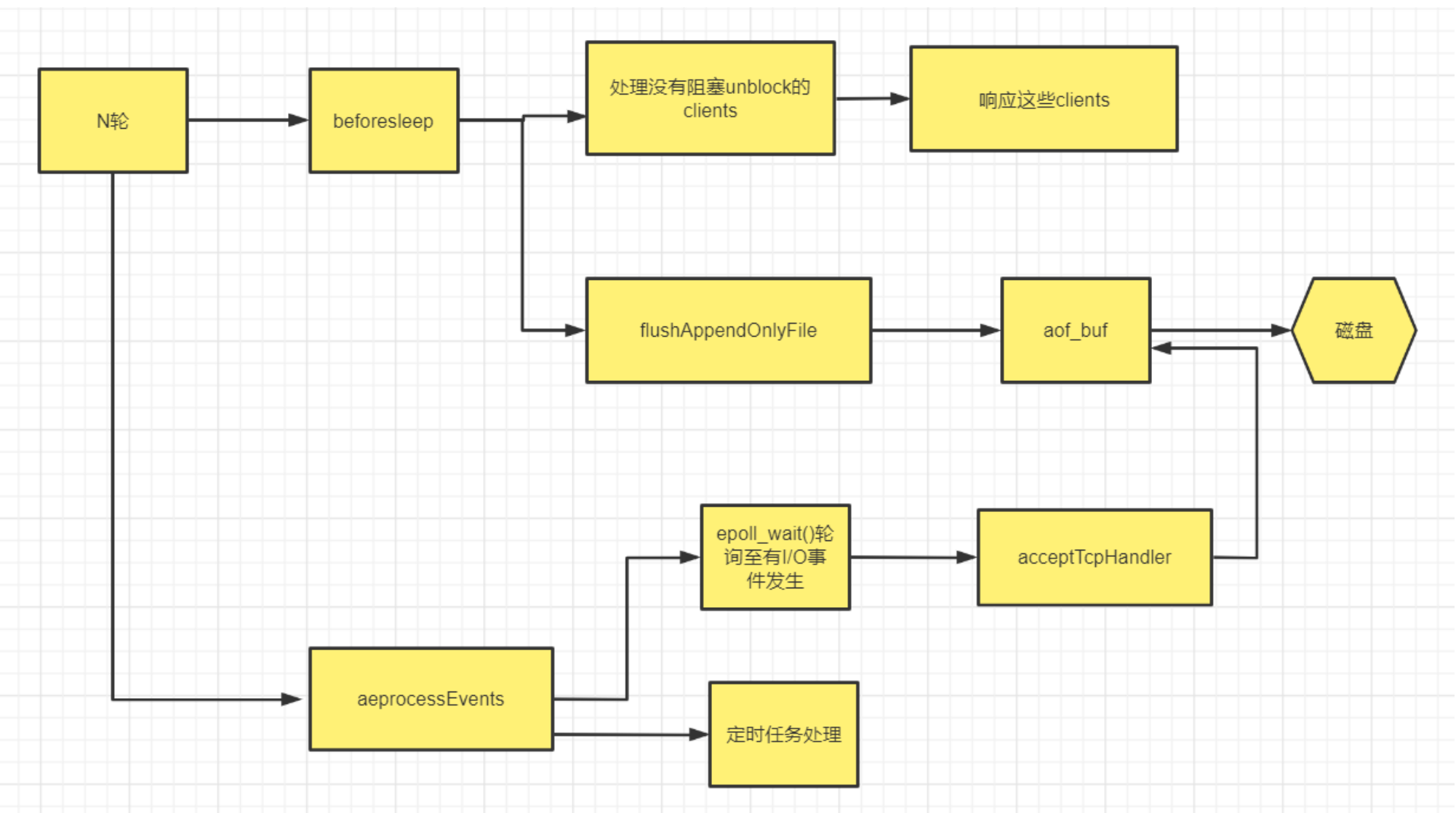
flushAppendOnlyFile 的时机分析
一个while循环,我们把这个循环叫做 事件循环 , 从写盘的角度来说:
第N+1轮循环的第一阶段,调用flushAppendOnlyFile 的,会将aof buffer写到磁盘上。
第N轮循环的第二阶段,将读取到的命令,写入aof buffer,而不是直接落盘
所以: redis即使在配制appendfsync=always的策略下,还是会可能丢失一个事件循环的aof_buf数据
异步复制导致的数据丢失
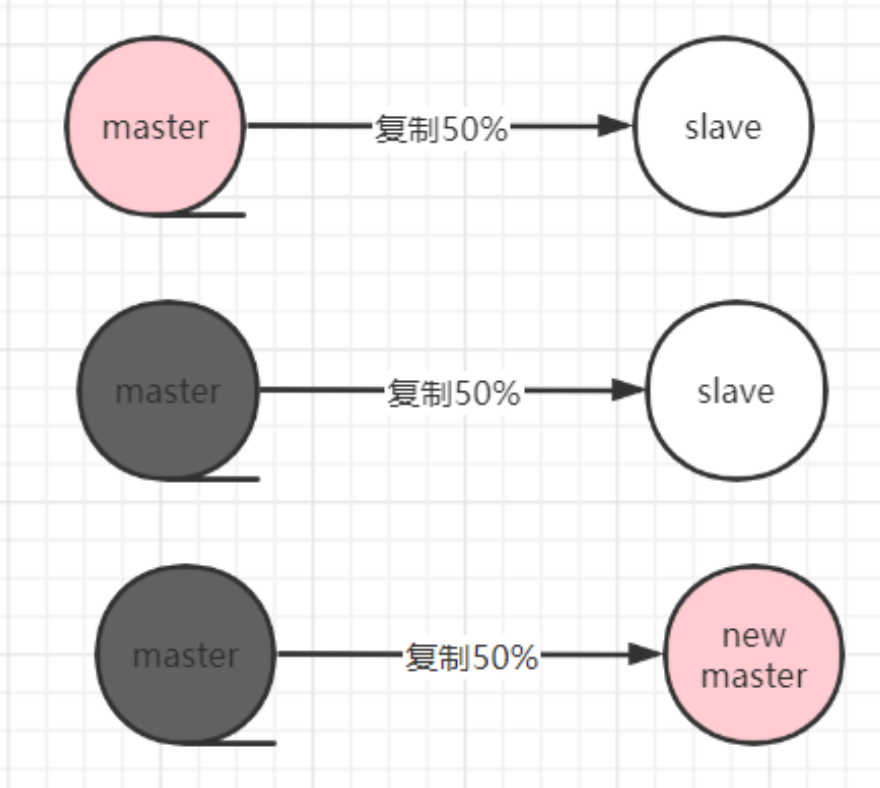
因为master->slave的数据同步是异步的,所以可能存在部分数据还没有同步到slave,master就宕机 了,此时这部分数据就丢失了。
脑裂导致的数据丢失
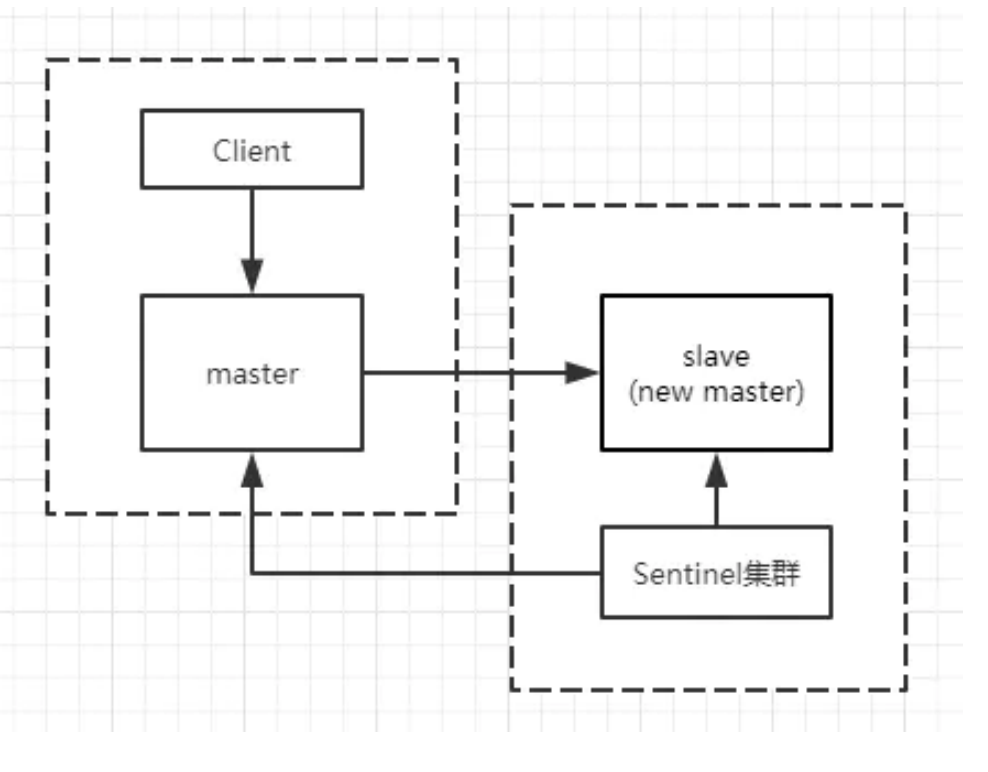
当master所在的机器突然脱离的正常的网络,与其他slave、sentinel失去了连接,但是master还在运行着。
此时sentinel就会认为master宕机了,会开始选举把slave提升为新的master,这个时候集群中就会出现两个master,也就是所谓的脑裂。
此时虽然产生了新的master节点,但是客户端可能还没来得及切换到新的master,会继续向旧的 master写入数据。
当网络恢复正常时,旧的master会变成新的master的从节点,自己的数据会清空,重新从新的master 上复制数据。
解决方案
Redis提供了这两个配置用来降低数据丢失的可能性
min-slaves-to-write 1
min-slaves-max-lag 10
上面两行配置的意思是,要求至少有1个slave,数据复制和同步的延迟不能超过10秒,如果不符合这个 条件,那么master将不会接收任何请求。
(1)减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保,一旦slave复制数据和ack延时太长,就认为master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低到可控范围内。
(2)减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保,如果不能继续给指 数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求 这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失。
Redis并不能保证数据的强一致性,看官方文档的说明

集群与数据库的数据一致性保障方案
方案1:biglog同步保障数据一致性
方案2:使用程序方式发送更新消息,保障数据一致性
一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
- 强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用 户体验好,但实现起来往往对系统的性能影响大
- 弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多 久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一 致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一 致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模 型,也是业界在大型分布式系统的数据一致性上比较推崇的模型
方案1:biglog同步保障数据一致性的架构
方案1,可以通过biglog同步,来保障二级缓存的数据一致性,具体的架构如下
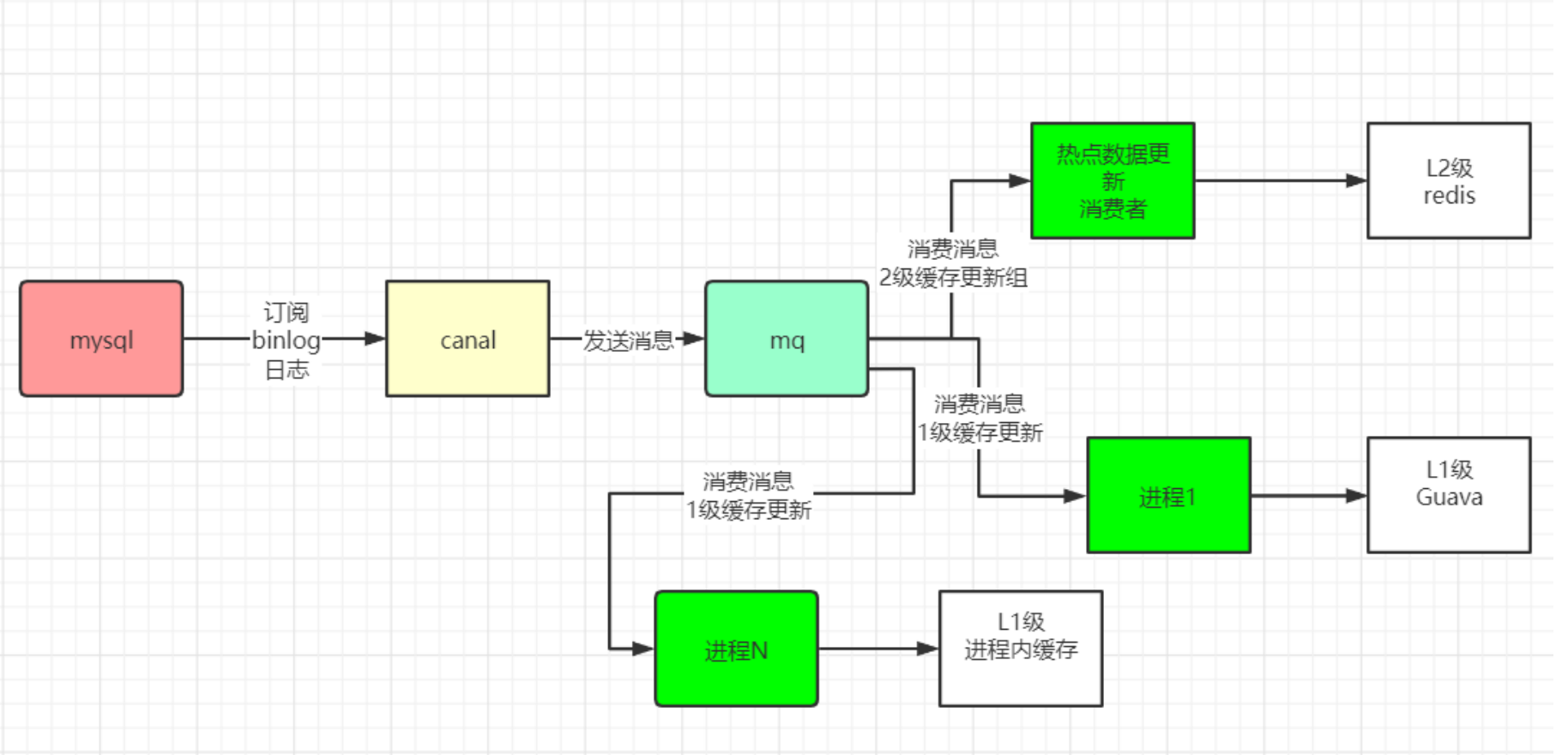
利用 rocketMQ 是支持广播消费的,增加消费端即可。
所以,必须设置 rocketMQ 客户端的消费模式,为 广播模式;
@RocketMQMessageListener(topic = "seckillgood", consumerGroup = "UpdateGuava",
messageModel = MessageModel.BROADCASTING)增加一个更新redis缓存的实力,完成redis的更新。 对于更新Guava或者其他1级缓存来说,增加一个实例消费消息,就可以了。
方案2:使用程序方式保障数据一致性的架构
使用程序方式保障数据一致性的架构,可以编写一个通用的2级缓存通用组件,当数据更新的时候,去发 送消息,具体的架构如下:
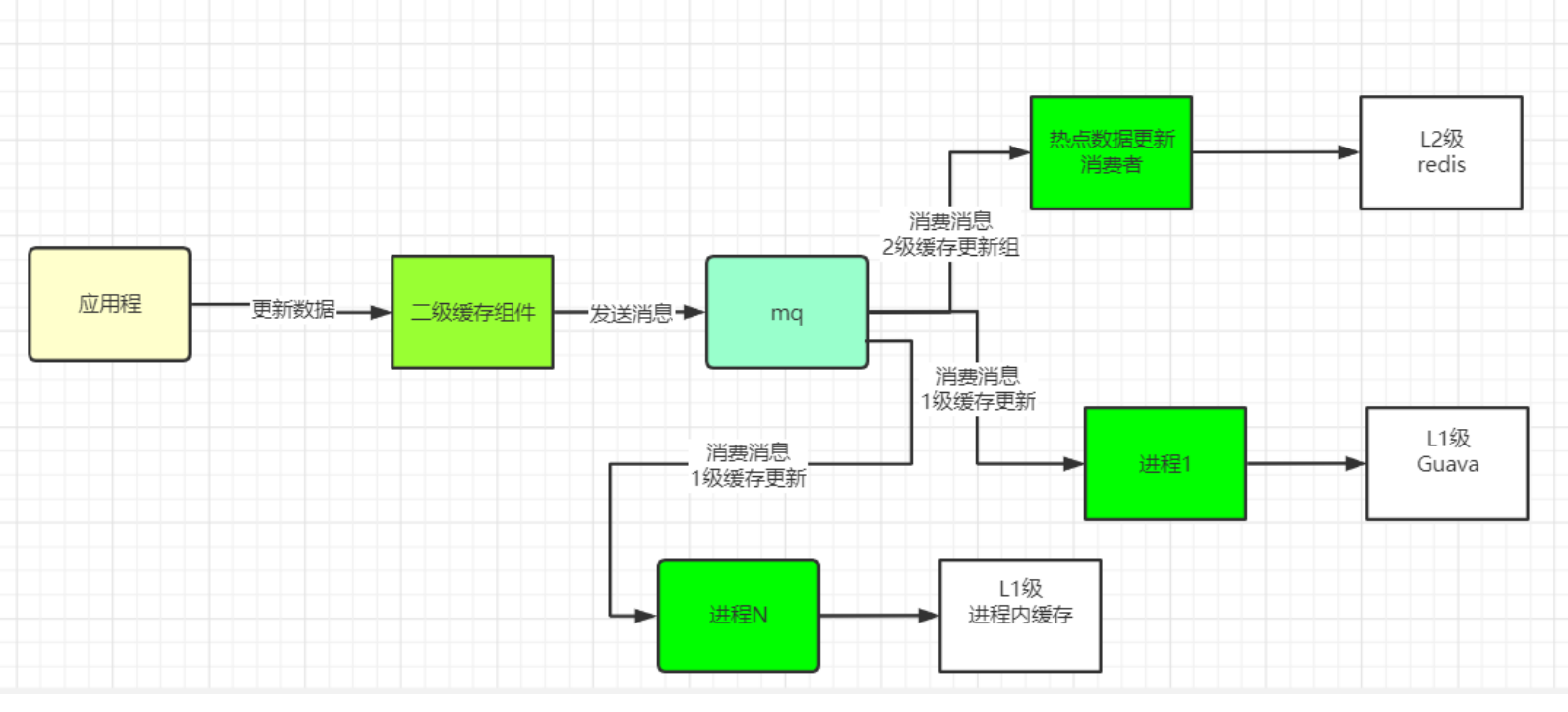
方案2和方案1 的区别
方案2和方案1 的整体区别不大,只不过 方案2 需要自己写代码(或者中间组件)发送数据的变化通知。 并且可以进行延迟双删的操作,首先删除一次,再发送到延迟队列,再删一次缓存。
方案1 的一个优势:可以和 建立索引等其他的消费者,共用binlog的消息队列。 其他的区别,大家可以自行探索。
集中式redis缓存的三个经典的缓存模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。一般我们是如何使用缓存呢?有三种经典的缓存模式:
- Cache-Aside Pattern
- Read-Through/Write through
- Write behind
Cache-Aside Pattern (旁路缓存)
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
Cache-Aside的读流程
Cache-Aside Pattern的读请求流程如下:
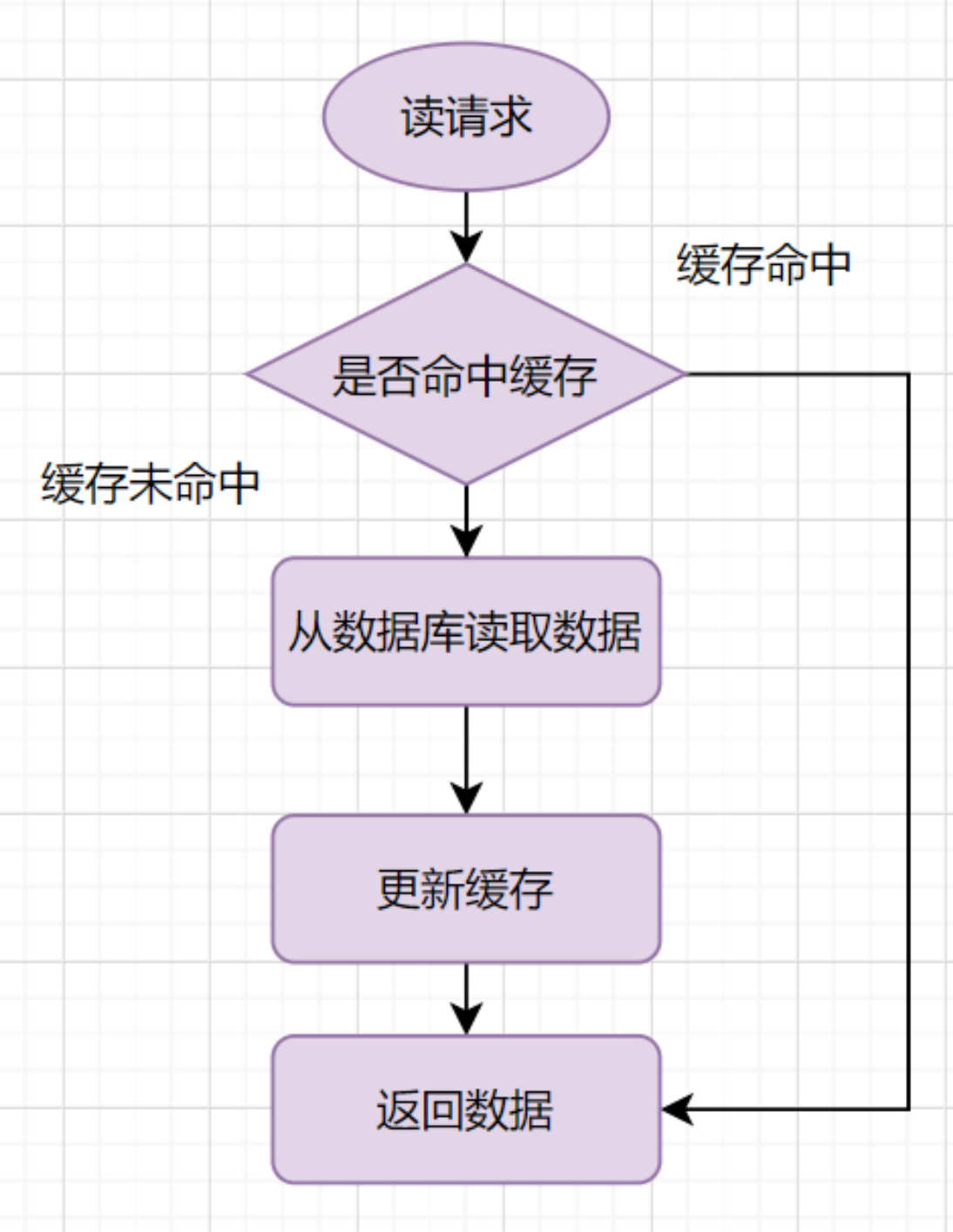
读的时候,先读缓存,缓存命中的话,直接返回数据;
缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
Cache-Aside 写流程
Cache-Aside Pattern的写请求流程如下:
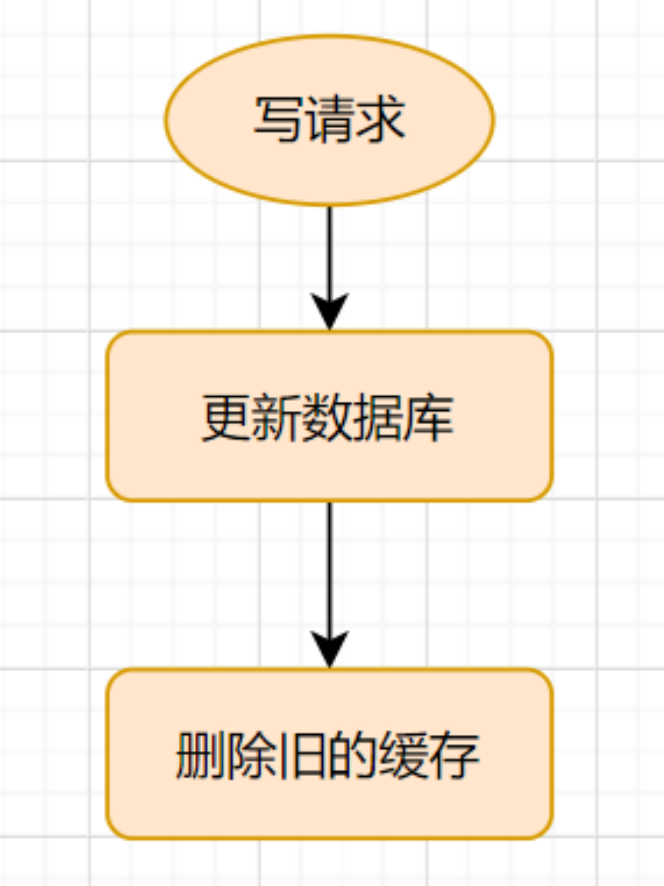
更新的时候,先更新数据库,然后再删除缓存。
Read-Through/Write-Through (读写穿透)
Read/Write Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过 抽象缓存层完成的。
Read-Through读流程
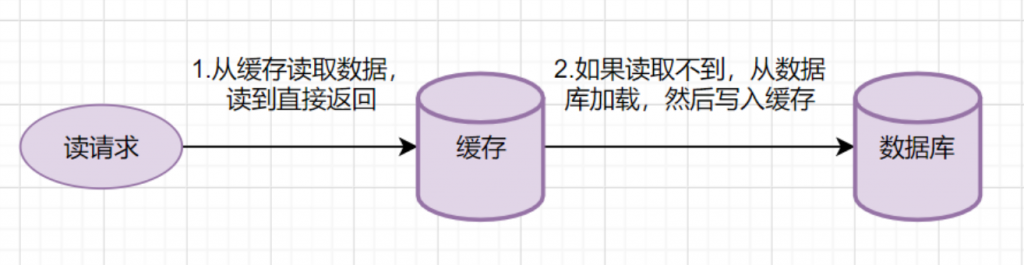
从缓存读取数据,读到直接返回 如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
这个简要流程是不是跟Cache-Aside很像呢?
其实Read-Through就是多了一层Cache-Provider,流程如下:
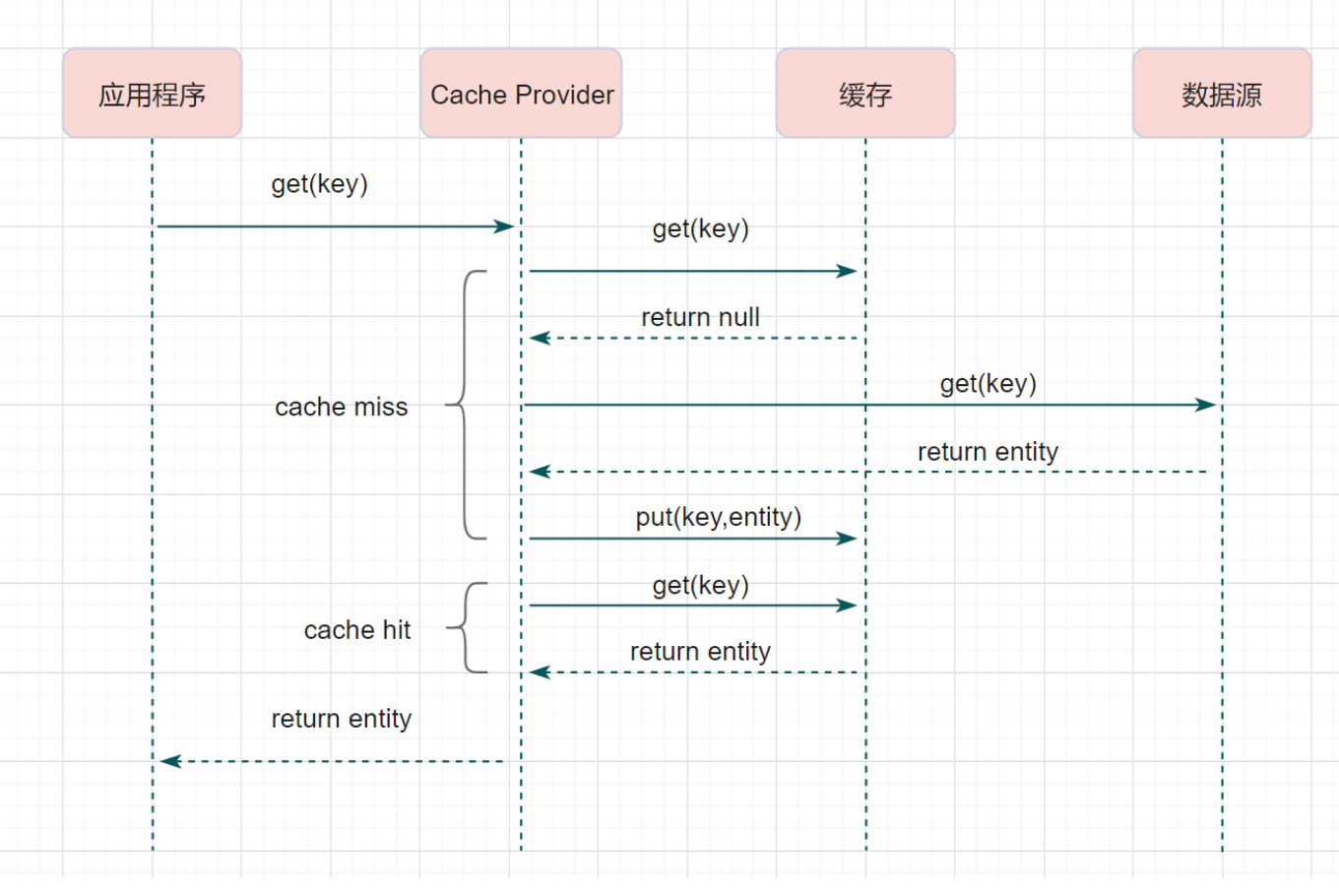
Read-Through的优点
Read-Through实际只是在Cache-Aside之上进行了一层封装,它会让程序代码变得更简洁,同时也减少 数据源上的负载。
Write-Through写流程
Write-Through模式下,当发生写请求时,也是由缓存抽象层完成数据源和缓存数据的更新,流程如下:
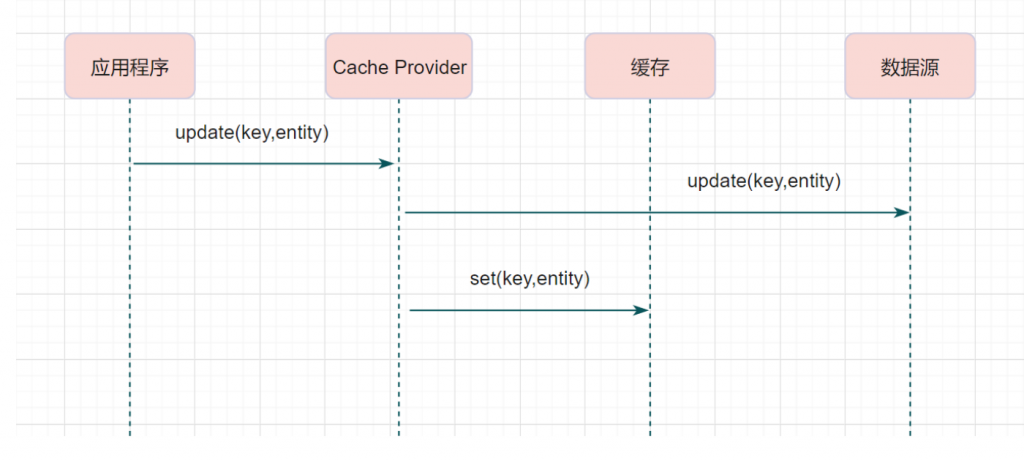
Write behind (异步缓存写入)
Write behind跟Read-Through/Write-Through有相似的地方,都是由Cache Provider来负责缓存和数据库的读写。
它两又有个很大的不同:Read/Write Through是同步更新缓存和数据的,Write Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库。
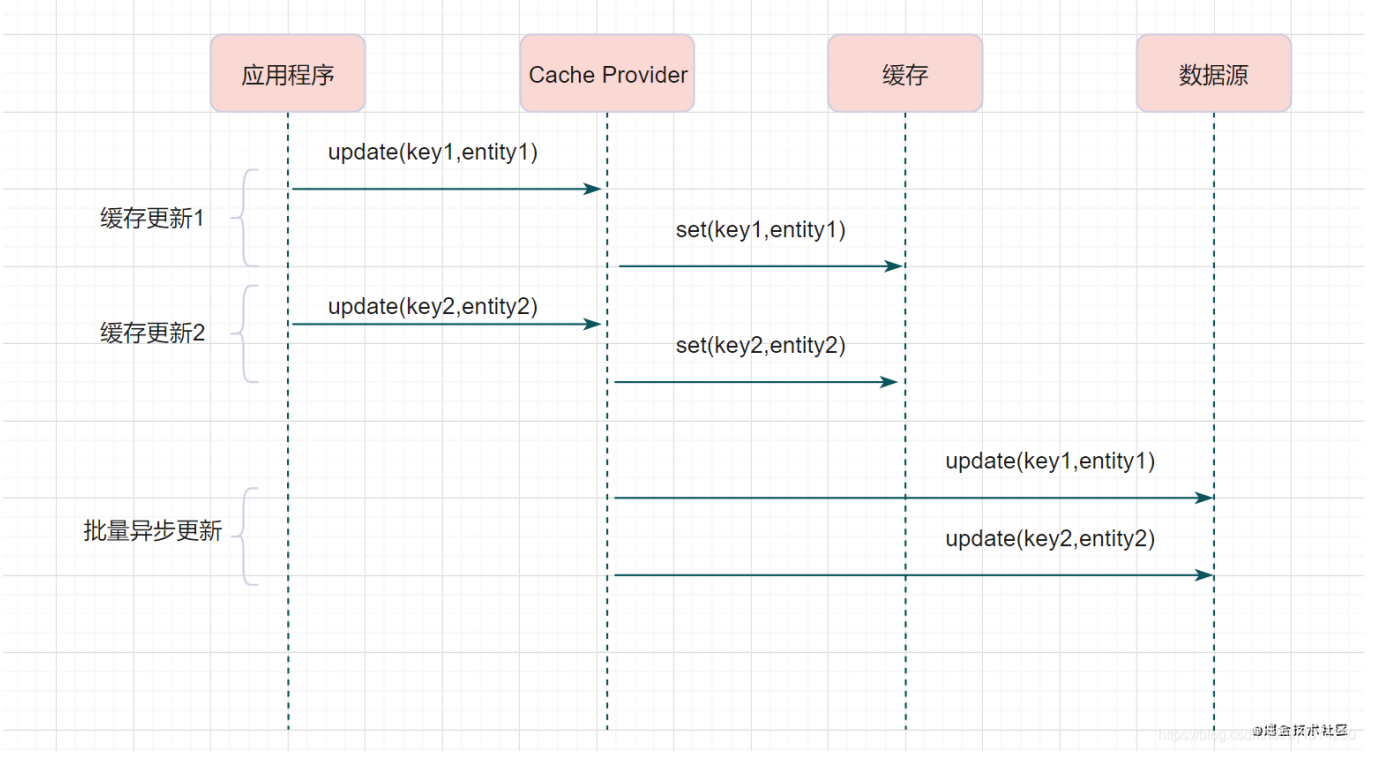
这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。
但是它适合频繁写的场景,MySQL的InnoDB Buffer Pool机制就使用到这种模式。
三种模式的比较
Cache Aside 更新模式实现起来比较简单,但是需要维护两个数据存储:
- 一个是缓存(Cache)
- 一个是数据库(Repository)。
Read/Write Through 的写模式需要维护一个数据存储(缓存),实现起来要复杂一些。
Write Behind Caching 更新模式和Read/Write Through 更新模式类似,区别是Write Behind Caching 更新模式的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步 的。
Write Behind Caching 的优点是直接操作内存速度快,多次操作可以合并持久化到数据库。缺点是数据可能会丢失,例如系统断电等。
Cache-Aside的问题
更新数据的时候,Cache-Aside是删除缓存呢,还是应该更新缓存?
Cache-Aside在写入请求的时候,为什么是删除缓存而不是更新缓存呢?
我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?我们先来看个例子:
操作的次序如下:
- 线程A先发起一个写操作,第一步先更新数据库
- 线程B再发起一个写操作,第二步更新了数据库
现在,由于网络等原因,线程B先更新了缓存, 线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数 据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
更新缓存相对于删除缓存,还有两点劣势:
- 如果你写入的缓存值,是经过复杂计算才得到的话。 更新缓存频率高的话,就浪费性能啦。
- 在写多读少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了性能呢(实际上, 写多的场景,用缓存也不是很划算了)
任何的措施,也不是绝对的好, 只有分场景看是不是适合,更新缓存的措施,也是有用的: 在读多写少的场景,价值大。
双写的情况下,先操作数据库还是先操作缓存?
美团二面:Redis与MySQL双写一致性如何保证?
Cache-Aside缓存模式中,在写入请求的时候,为什么是先操作数据库呢?为什么不先操作缓存呢?
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
A、B两个请求的操作流程如下:
- 线程A发起一个写操作,第一步del cache
- 此时线程B发起一个读操作,cache miss
- 线程B继续读DB,读出来一个老数据
- 然后线程B把老数据设置入cache
- 线程A写入DB最新的数据
酱紫就有问题啦,缓存和数据库的数据不一致了。 缓存保存的是老数据,数据库保存的是新数据。
因此,Cache-Aside缓存模式,选择了先操作数据库而不是先操作缓存。
redis分布式缓存与数据库的数据一致性
重要:缓存是通过牺牲强一致性来提高性能的。
这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。
强一致性还是弱一致性
CAP理论,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、 Partition tolerance(分区容错性),三者不可得兼。
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
最多满足其中的两个特性。也就是下图所描述的。分布式系统要么满足CA,要么CP,要么AP。无法同时 满足CAP。
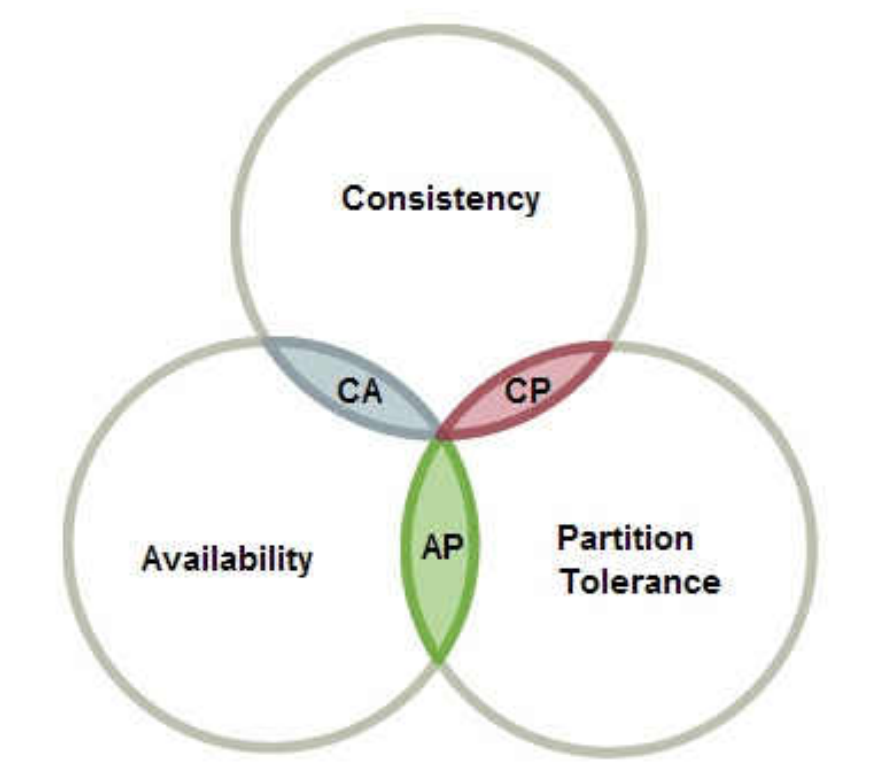
什么是 一致性、可用性和分区容错性
分区容错性:指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供 满足一致性和可用性的服务。也就是说部分故障不影响整体使用。
事实上我们在设计分布式系统是都会考虑到bug,硬件,网络等各种原因造成的故障,所以即使部分节点 或者网络出现故障,我们要求整个系统还是要继续使用的
(不继续使用,相当于只有一个分区,那么也就没有后续的一致性和可用性了)
可用性: 一直可以正常的做读写操作。简单而言就是客户端一直可以正常访问并得到系统的正常响应。 用户角度来看就是不会出现系统操作失败或者访问超时等问题。
一致性:在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值。相当 于要求分布式系统中的各节点时时刻刻保持数据的一致性。
所以,如果需要数据库和缓存数据保持强一致,就不适合使用缓存。
所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用 缓存。然后缓存一定要设置过期时间,这个时间太短、或者太长都不好:
- 太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。
- 太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数 据一直存在内存中不过期,浪费内存。
但是,通过一些方案优化处理,是可以保证弱一致性,最终一致性的。
3种方案保证数据库与缓存的一致性
- 延时双删策略
- 删除缓存重试机制
- 读取biglog异步删除缓存
缓存延时双删
有些人可能会说,不一定要先操作数据库呀,采用缓存延时双删策略就好啦? 什么是延时双删呢?
延时双删的步骤:
- 先删除缓存
- 再更新数据库
- 休眠一会(比如1秒),再次删除缓存。
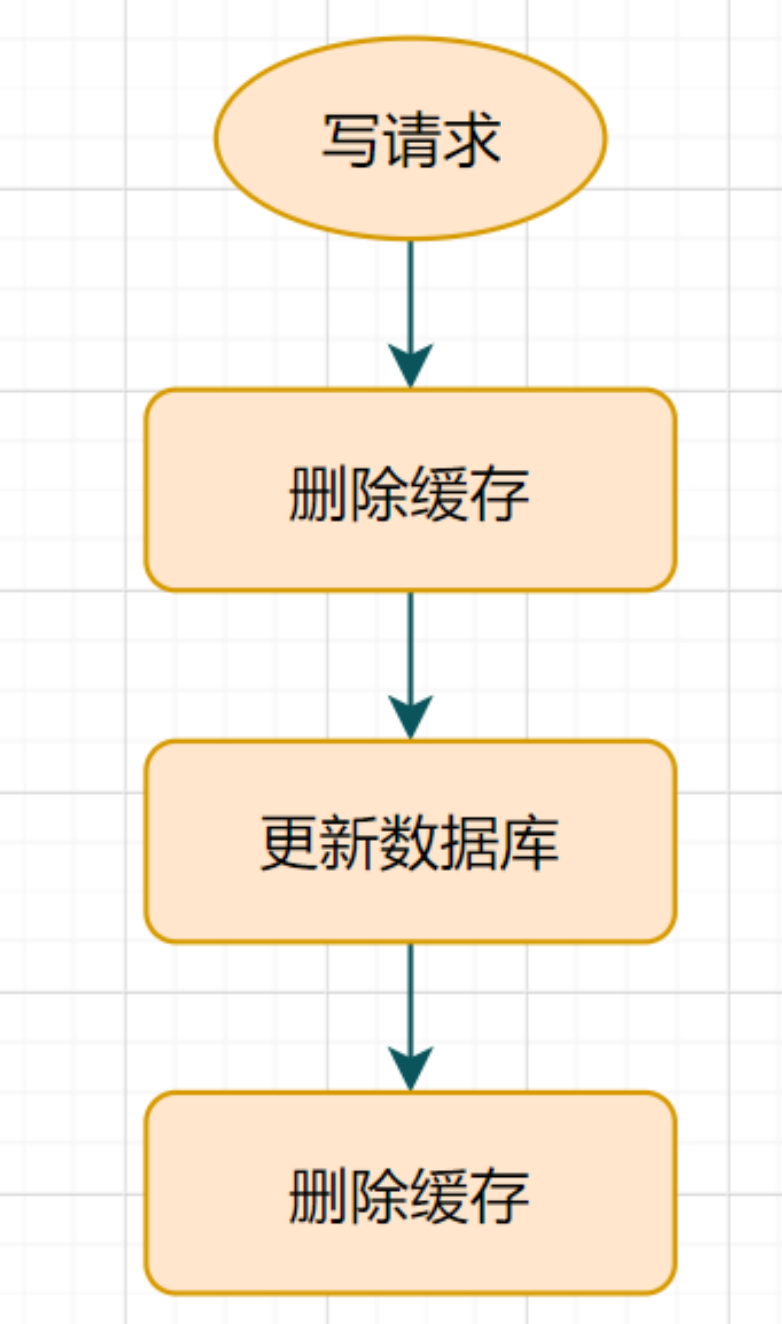
代码示例:

这个休眠一会,一般多久呢?都是1秒?
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。
为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
删除缓存重试机制
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存,如果第二步的删除缓存失败呢?
删除失败会导致脏数据哦~ 删除失败就多删除几次呀,保证删除缓存成功呀~ 所以可以引入删除缓存重试机制
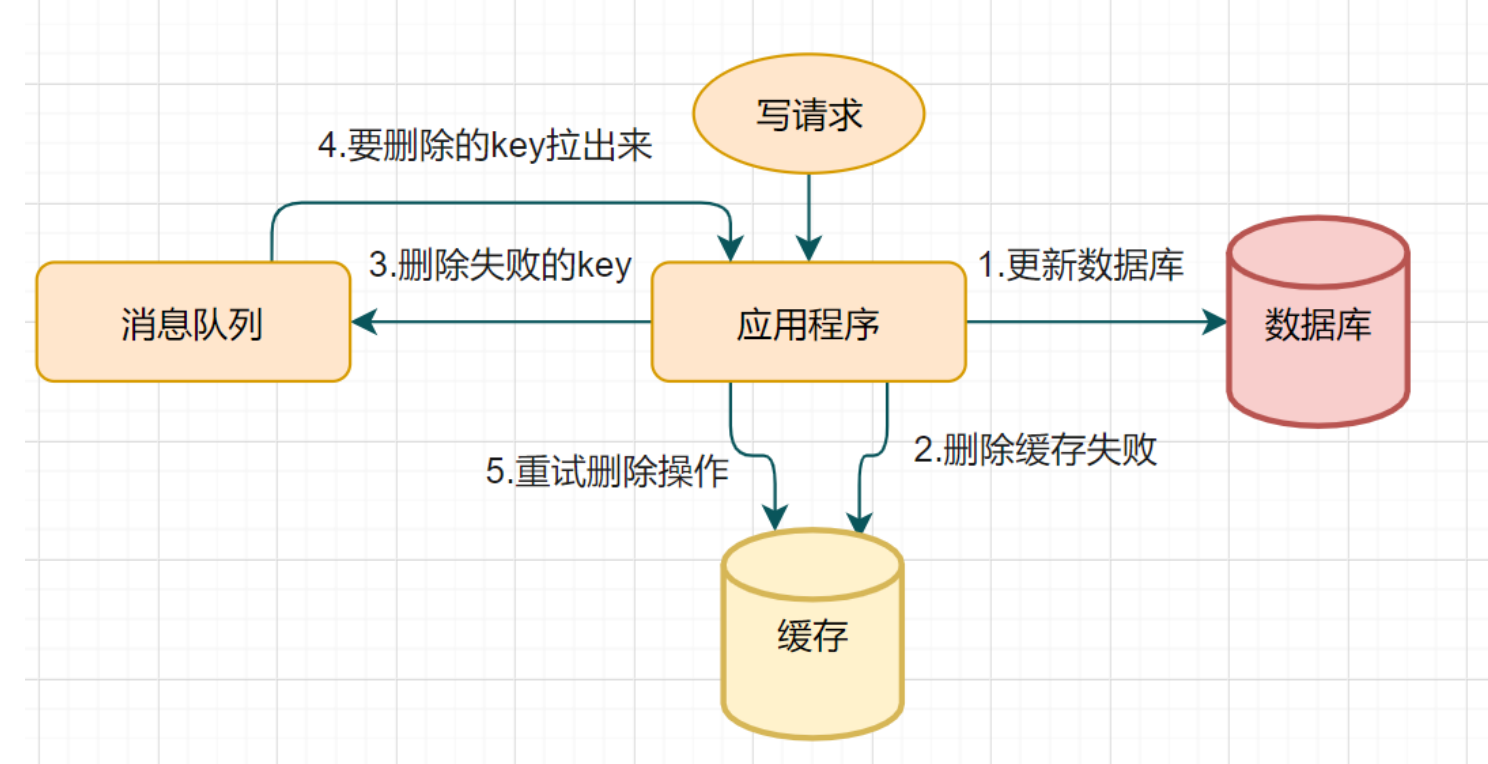
删除缓存重试机制的大致步骤:
- 写请求更新数据库
- 缓存因为某些原因,删除失败
- 把删除失败的key放到消息队列
- 消费消息队列的消息,获取要删除的key
- 重试删除缓存操作
同步biglog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。
其实,还可以通过数据库的binlog来异步淘汰key。
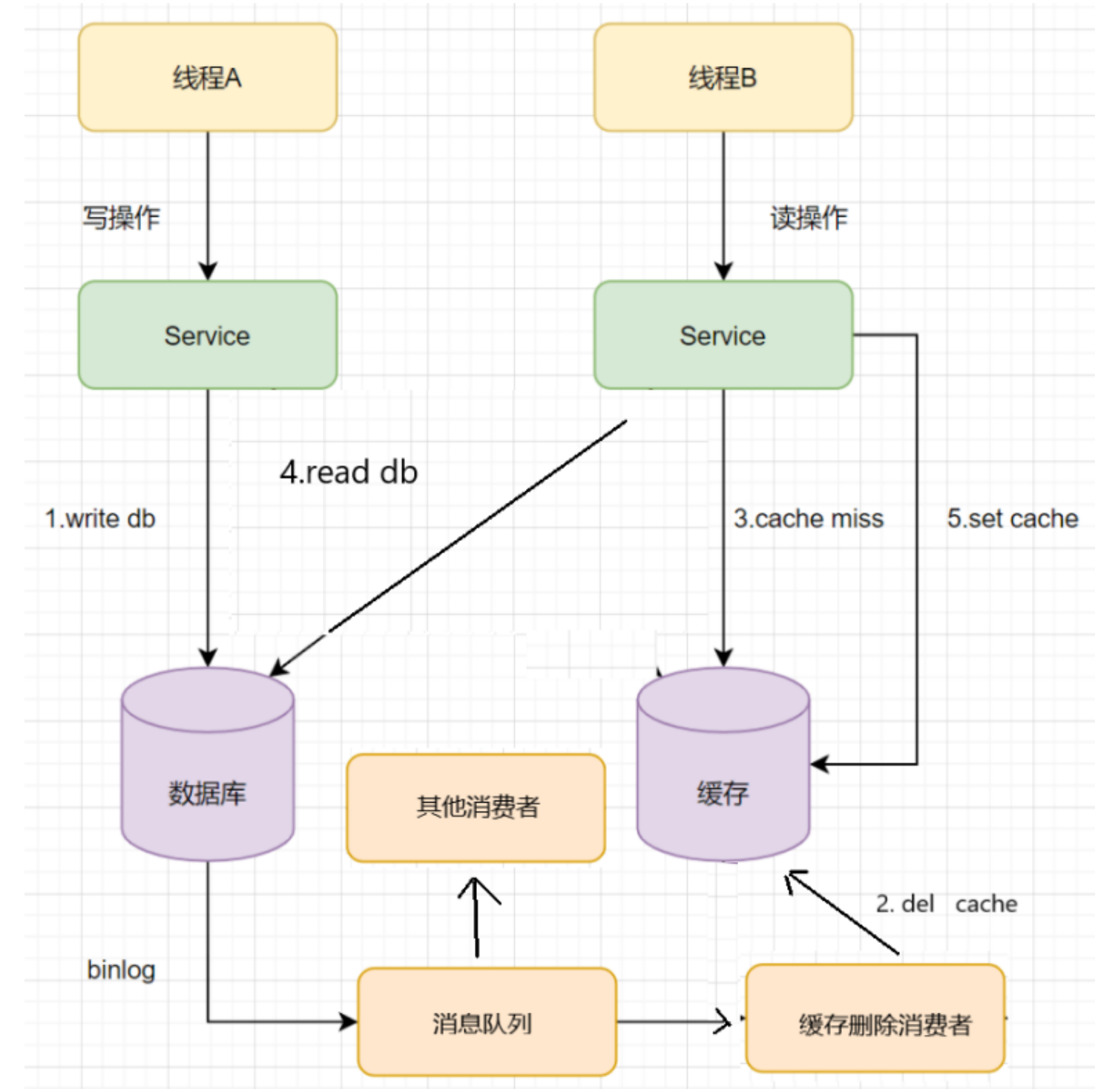
以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后编写一个简单的缓存删除消息者订阅binlog日志,根据更新log删除缓存,并且通过ACK机制确认处理这条更新log,保证数据缓存一致性
如何确保消费成功
PushConsumer为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。首先,消费的时候,我们需要注入一个消费回调,具体sample代码如下:
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.println(Thread.currentThread().getName() + " Receive New
Messages: " + msgs);
delcache(key);//执行真正删除
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;//返回消费成功
}
});业务实现消费回调的时候,当且仅当此回调函数返回 ConsumeConcurrentlyStatus.CONSUME_SUCCESS ,RocketMQ才会认为这批消息(默认是1条)是消 费完成的。
如果这时候消息消费失败,例如数据库异常,余额不足扣款失败等一切业务认为消息需要重试的场景, 只要返回ConsumeConcurrentlyStatus.RECONSUME_LATER,RocketMQ就会认为这批消息消费失败了。
为了保证消息是肯定被至少消费成功一次,RocketMQ会把这批消费失败的消息重发回Broker(topic 不是原topic而是这个消费租的RETRY topic),在延迟的某个时间点(默认是10秒,业务可设置)后, 再次投递到这个ConsumerGroup。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。应用可以监控死信队列来做人工干预。
pub/sub的订阅实现
Pub/Sub功能(means Publish, Subscribe)即发布及订阅功能。
Pub/Sub是目前广泛使用的通信模型,它采用事件作为基本的通信机制,提供大规模系统所要求的松散耦合的交互模式:
订阅者(如客户端) 以事件订阅的方式表达出它有兴趣接收的一个事件或一类事件;发布者(如服务器)可将订阅者感兴趣的事件随时通知相关订阅者。
熟悉设计模式的朋友应该了解这与23种设计模式中的观察者模式极为相似。
Redis 的 pub/sub订阅实现
Redis通过publish和subscribe命令实现订阅和发布的功能。
订阅者可以通过subscribe向redis server订阅自己感兴趣的消息类型。
redis将信息类型称为通道(channel)。当发布者通过publish命令向redis server发送特定类型的信息时,订阅该消息类型的全部订阅者都会收到此消息。
主从数据库通过biglog异步删除
但是呢还有个问题, 「如果是主从数据库呢」? 因为主从DB同步存在延时时间。如果删除缓存之后,数据同步到备库之前已经有请求过来时, 「会从备库中读到脏数据」,如何解决呢?解决方案如下流程图:
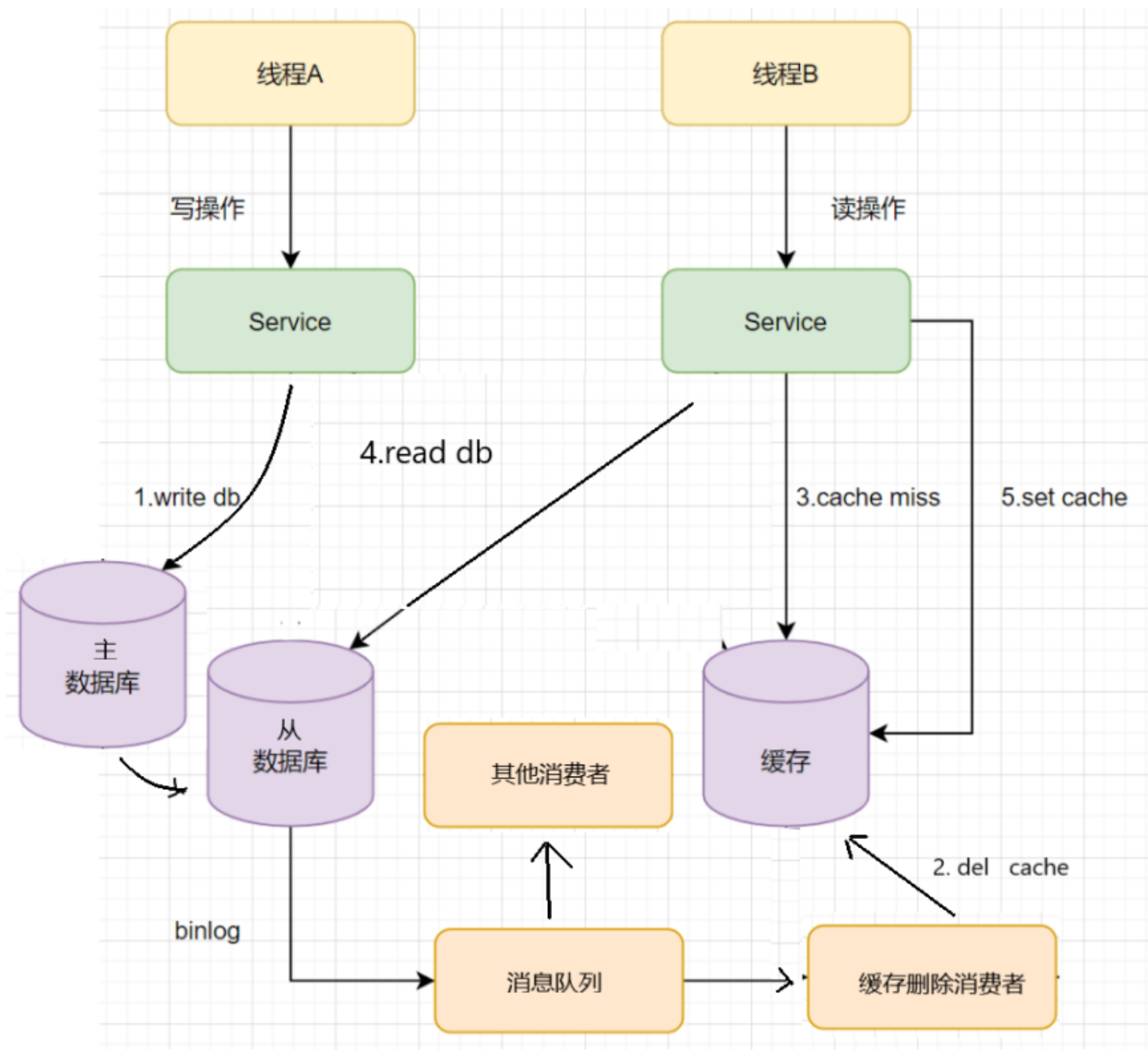
缓存与数据的一致性的保障策略总结
综上所述,在分布式系统中,缓存和数据库同时存在时,如果有写操作的时候,「先操作数据库,再操作缓存」。如下:
- 读取缓存中是否有相关数据
- 如果缓存中有相关数据value,则返回
- 如果缓存中没有相关数据,则从数据库读取相关数据放入缓存中key->value,再返回
- 如果有更新数据,则先更新数据库,再删除缓存
- 为了保证第四步删除缓存成功,使用binlog异步删除
- 如果是主从数据库,binglog取自于从库
- 如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存,或者为了简单,收到一次更新log,删除一次缓存
Canal+RocketMQ同步MySQL到Redis/ES
在很多业务情况下,我们都会在系统中加入redis缓存做查询优化, 使用es 做全文检索。
如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。这种数据同步的代 码跟业务代码糅合在一起会不太优雅,能不能把这些数据同步的代码抽出来形成一个独立的模块呢,答案是可以的。
biglog同步保障数据一致性的架构
canal工作原理
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数 据订阅和消费.。
canal工作原理 canal是一个伪装成slave订阅mysql的binlog,实现数据同步的中间件。

- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
canal架构
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1…n个instance)
instance模块:
- eventParser (数据源接入,模拟db的slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
L2级缓存与数据库的数据一致性
集中式缓存需要考虑的问题
了解到了我们为什么要使用缓存,以及缓存能解决我们什么样的问题。但是使用缓存时也需要注意一些 问题:
如果只是单纯的整合Redis缓存,那么可能出现如下的问题
- 热点数据的大量访问,能对系统造成各种网络开销,影响系统的性能
- 一旦集中式缓存发生雪崩了,或者缓存被击穿了,能造成数据库的压力增大,可能会被打死,造成 数据库挂机状态,进而造成服务宕机
- 缓存雪崩,访问全部打在数据库上,数据库也可能会被打死
为了解决以上可能出现的问题,让缓存层更稳定,健壮,我们使用二级缓存架构
- 1级为本地缓存,或者进程内的缓存(如 Ehcache) —— 速度快,进程内可用
- 2级为集中式缓存(如 Redis)—— 可同时为多节点提供服务
二级缓存架构图:
为什么要引入本地缓存
相对于IO操作 速度快,效率高 相对于Redis Redis是一种优秀的分布式缓存实现,受限于网卡等原因,远水救不了近火
所以: DB + Redis + LocalCache = 高效存储,高效访问
本地缓存的适用场景
本地缓存一般适合于缓存只读、量少、高频率访问的数据。如秒杀商品数据。
或者每个部署节点独立的数据,如长连接服务中,每个部署节点由于都是维护了不同的连接,每个连接 的数据都是独立的,并且随着连接的断开而删除。
如果数据在集群的不同部署节点需要共享和保持一 致,则需要使用分布式缓存来统一存储,实现应用集群的所有应用进程都在该统一的分布式缓存中进行 数据存取即可。
本地缓存的优缺点
1. 访问速度快,但无法进行大数据存储
本地缓存位于同一个JVM的堆中,相对于分布式缓存的好处是,故性能更好,减少了跨网络传输, 但是本地缓存由于占用 JVM 内存空间 (或者进程的内存空间),故不能进行大数据量的数据存 储。
2. 数据一致性问题
本地缓存只支持被该应用进程访问,一般无法被其他应用进程访问,如果对应的数据库数据,存在数据 更新,则需要同步更新不同节点的本地缓存副本,来保证数据一致性
本地缓存的更新,复杂度较高并且容易出错,如基于 Redis 的发布订阅机制、或者消息队列MQ来同步 更新各个部署节点。
数据库、本地缓存及分布式缓存的区别
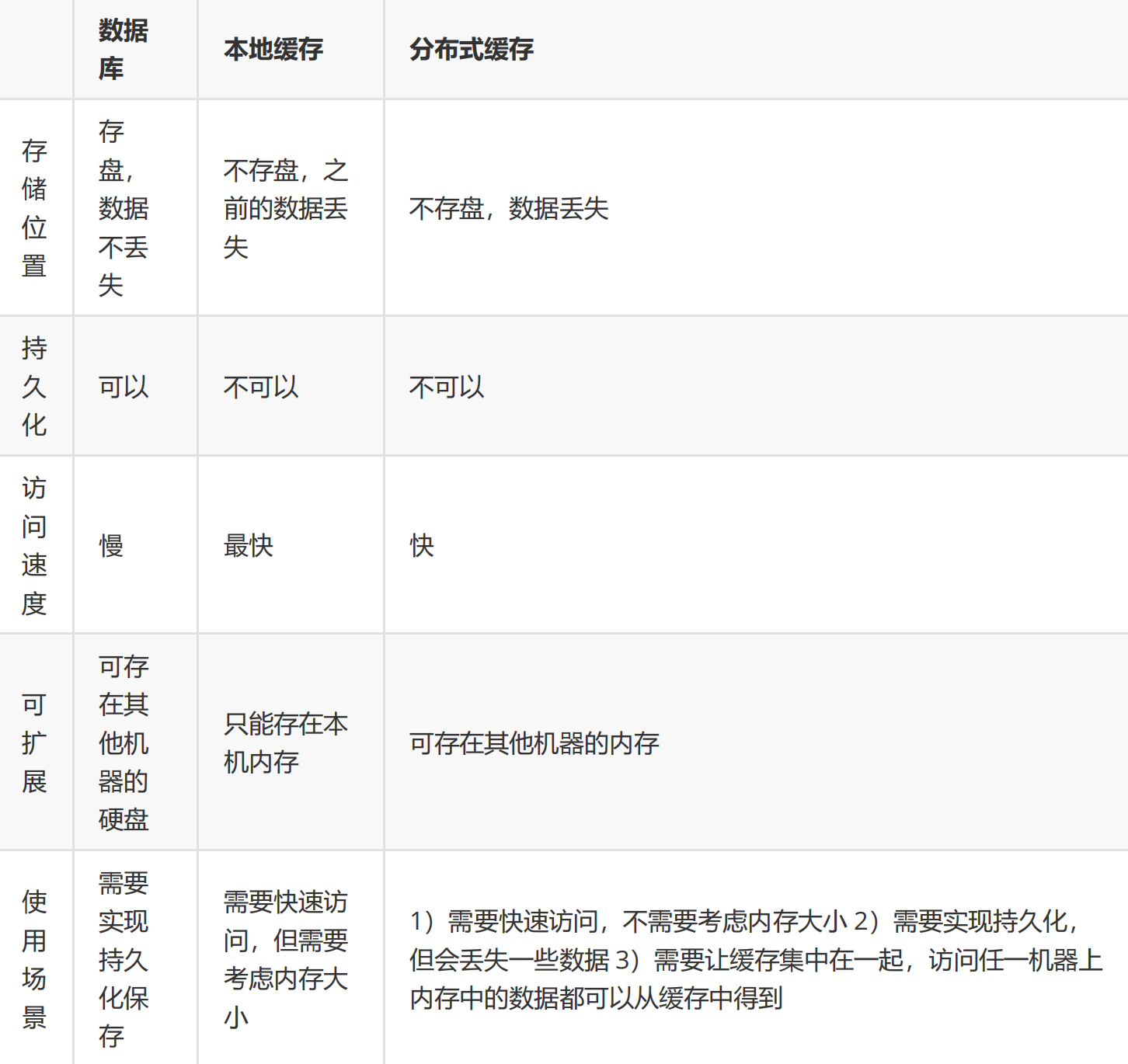
本地缓存与集中式缓存的结合的需求场景
单独使用本地缓存与集中式缓存,都会有各自的短板。
- 使用本地缓存时,一旦应用重启后,由于缓存数据丢失,缓存雪崩,给数据库造成巨大压力,导致 应用堵塞
- 使用本地缓存时,多个应用节点无法共享缓存数据
- 使用集中式缓存,由于大量的数据通过缓存获取,导致缓存服务的数据吞吐量太大,带宽跑满。现 象就是 Redis 服务负载不高,但是由于机器网卡带宽跑满,导致数据读取非常慢
有这么一个网站,某个页面每天的访问量是 1000万,每个页面从缓存读取的数据是 50K。缓存数据存放 在一个 Redis 服务,机器使用千兆网卡。那么这个 Redis 一天要承受 500G 的数据流,相当于平均每秒 钟是 5.78M 的数据。而网站一般都会有高峰期和低峰期,两个时间流量的差异可能是百倍以上。我们假设高峰期每秒要承受的流量比平均值高 50 倍,也就是说高峰期 Redis 服务每秒要传输超过 250 兆的数 据。请注意这个 250 兆的单位是 byte,而千兆网卡的单位是“bit” ,你懂了吗? 这已经远远超过 Redis 服务的网卡带宽。
所以如果你能发现这样的问题,一般你会这么做:
1. 升级到万兆网卡 —— 这个有多麻烦,相信很多人知道,特别是一些云主机根本没有万兆网卡给你 使用(有些运维工程师会给这样的建议)
2. 多个 Redis 搭建集群,将流量分摊多多台机器上
如果你采用第2种方法来解决上述的场景中碰到的问题,那么你最好准备 5 个 Redis 服务来支撑。
在缓存服务这块成本直接攀升了 5 倍。你有钱当然没任何问题,但是结构就变得非常复杂了,而且可能你缓存的数据量其实不大,1000 万高频次的缓存读写 Redis 也能轻松应付,可是因为带宽的问题,你不得不付出 5 倍的成本。
按照80/20原则,如果我们把20%的热点数据,放在本地缓存,如果我们不用每次页面访问的时候 都去 Redis 读取数据,那么 Redis 上的数据流量至少降低 80%的带宽流量,甚至于一个很小的 Redis 集群可以轻松应付。
本地缓存与集中式缓存的结合的使用案例
秒杀的商品数据
作为需要超高并发的访问数据,属于 20% 的热点数据 这属于提前预测静态热点数据类型。
亿级IM系统中用户路由数据
这属于提前预测静态热点数据类型。
通过流计算识别出来的热点数据
还有的是提前不能识别出来的,如电商系统中的热点商品那就完美了。
通过流计算识别出来的热点数据,能够动态地实时发现热点。
这属于实时预测动态热点数据类型。由于数据量大,可以通过流计算框架 storm 或者 fink 实现, 不够,此项工作,一般属于大数据团队的工作。
本地缓存与集中式缓存的2级缓存架构
第一级缓存使用内存(同时支持 Ehcache 2.x、Ehcache 3.x 、Guava、 Caffeine),第二级缓存使用 Redis(推荐)/Memcached 本地缓存与集中式缓存的结合架构,大致的架构图,如下:
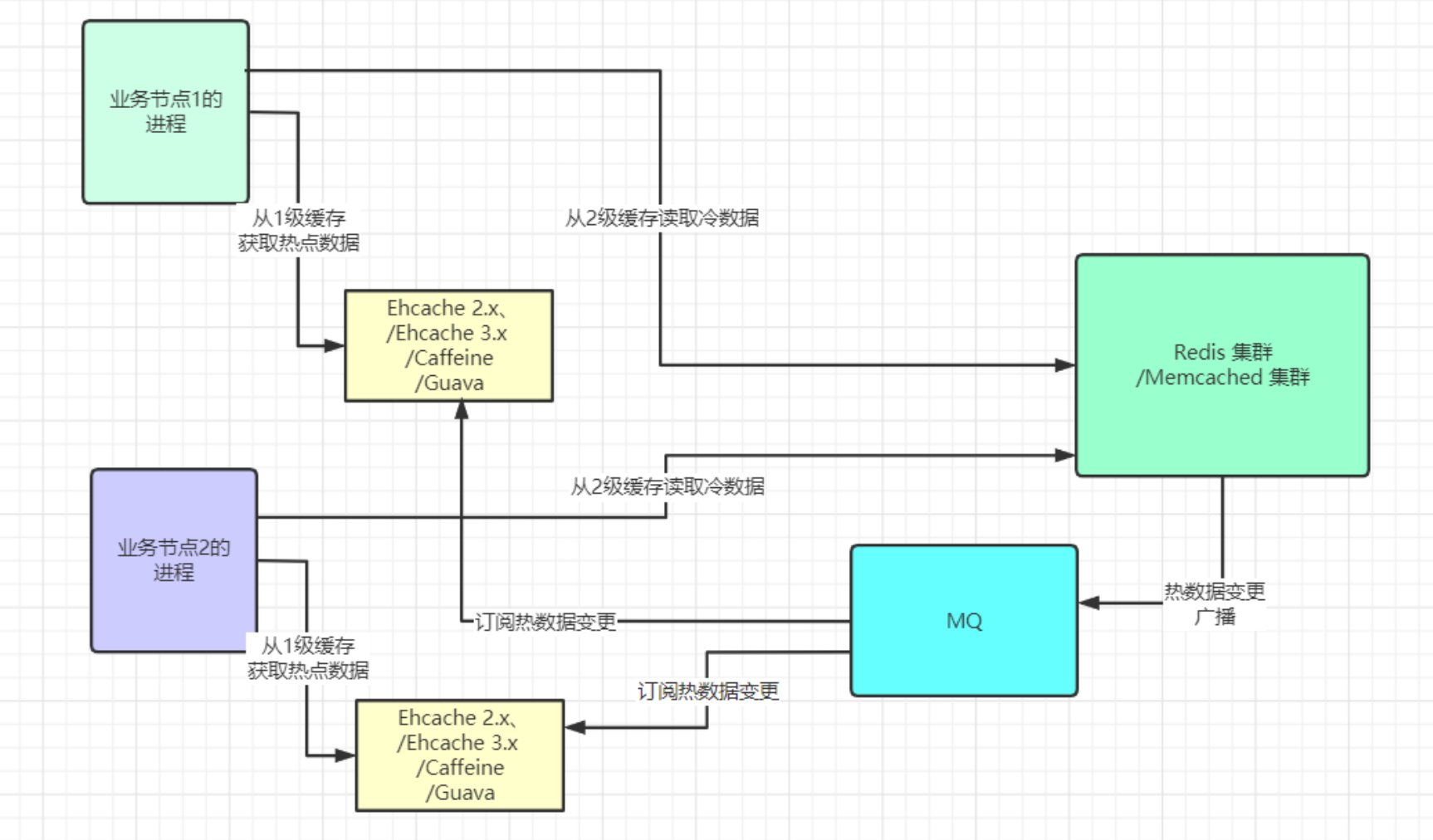
L2级缓存的数据读取和更新
读取流程
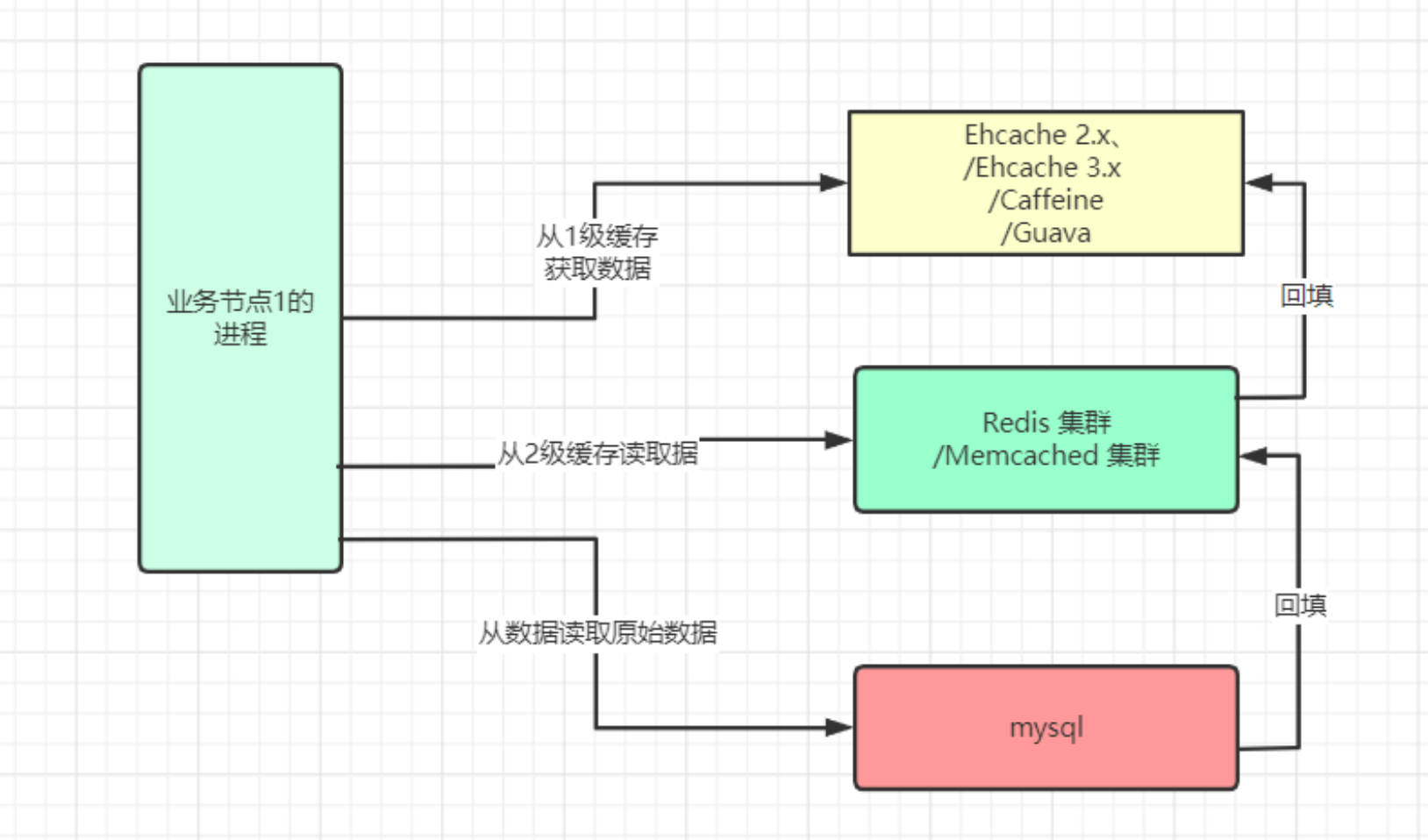
数据更新
通过消息队列,或者其他广播模式的发布订阅,保持各个一级缓存的数据一致性。
这一点,与Cache-Aside模式不同,Cache-Aside只是删除缓存即可。
但是热点数据,如果删除, 很容易导致缓存击穿。 对于秒杀这样的场景,瞬间有十几万甚至上百万的请求要同时读取商品。
如果没有缓存,每一个请求连带的数据操作都需要应用与数据库生成connection,而数据库的最大连接数是有限的,一旦超过数据库会直接宕机。这就是缓存击穿。
缓存击穿与缓存穿透的简单区别:
- 缓存击穿是指数据库中有数据,但是缓存中没有,大量的请求打到数据库;
- 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
二级缓存缓存击穿解决方案
- 设置热点数据永远不过期。
- 如果过期则或者在快过期之前更新,如有变化,主动刷新缓存数据,同时也能保障数据一致性
- 加互斥锁,保障缓存中的数据,被第一次请求回填。此方案不适用于超高并发场景
L2级缓存与数据库的数据一致性保障方案
- 方案1:biglog同步保障数据一致性
- 方案2:使用程序方式发送更新消息,保障数据一致性
biglog同步保障数据一致性的架构
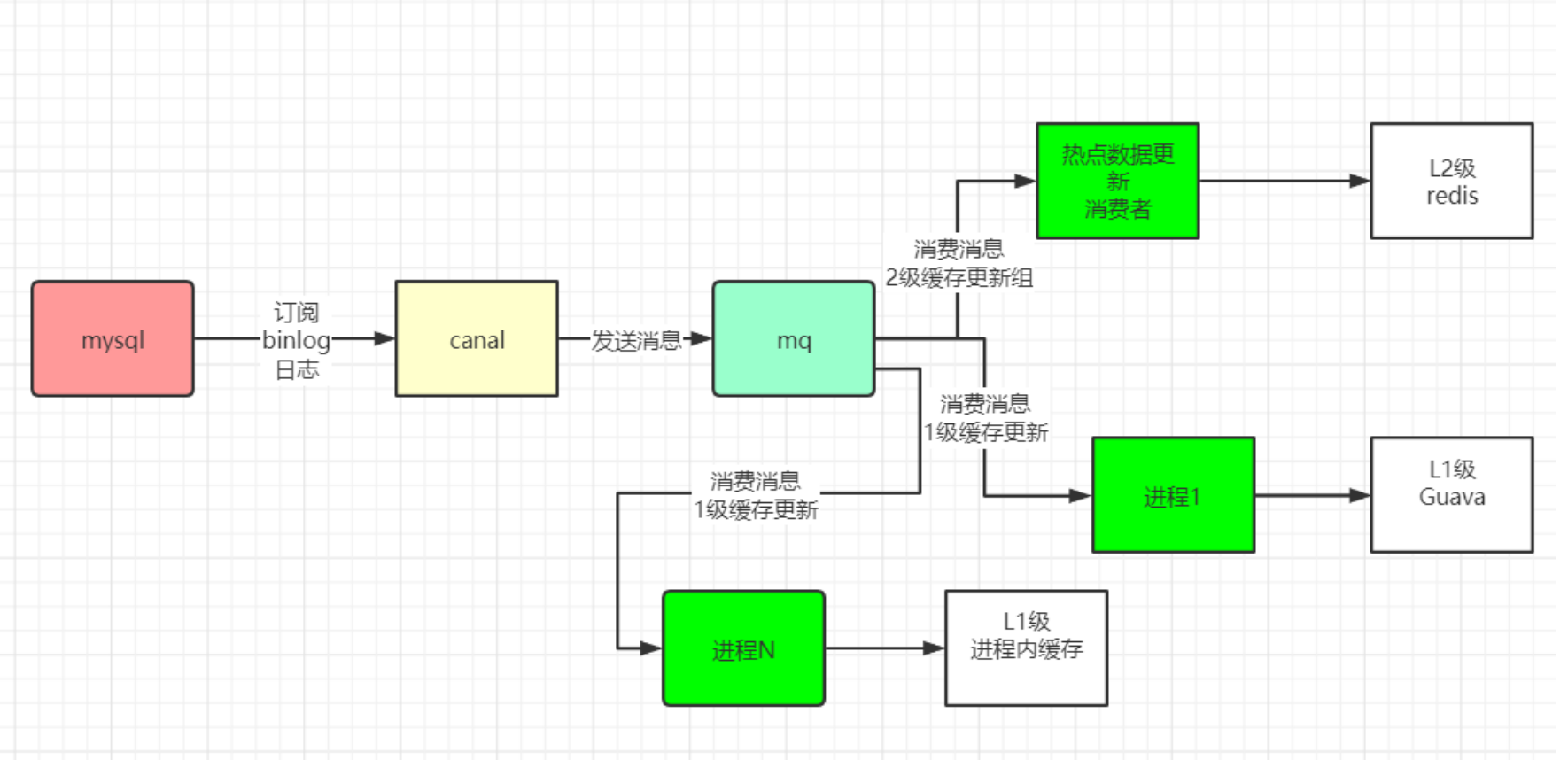
使用程序方式保障数据一致性的架构