阅读完需:约 20 分钟
PostgreSQL函数也称为PostgreSQL存储过程。
PostgreSQL函数或存储过程是存储在数据库服务器上并可以使用SQL界面调用的一组SQL和过程语句(声明,分配,循环,控制流程等)。 它有助于执行通常在数据库中的单个函数中进行多次查询和往返操作的操作。
可以在许多语言(如SQL,PL/pgSQL,C,Python等)中创建PostgreSQL函数。
中文文档:http://www.postgres.cn/docs/15/xfunc.html
这样用PL/pgSQL来创建自定义函数。
PL/pgSQL是一种块结构的语言,一个块被定义为:
[ <<label>> ]
[ DECLARE
declarations
BEGIN
statements
END [ label ];CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END;
LANGUAGE plpgsql;- 规定
- []表示可选
- [OR REPLACE]:替换现有函数。
- function_name:指定函数的名称。
- arguments:定义函数的参数
- 语法:
[[argmode]argname argtype [default value],[[argmode]argname argtype],[…]]; - argmode:参数的模式
- IN、OUT、INOUT,缺省值是IN。
- argname:参数名字
- argtype:参数的数据类型
- default:默认参数。
- 参数语法:
模式 名称 类型
- 语法:
- return_datatype:表示返回值类型。
- DECLARE:声明变量
- 语法:
类型 名称
- 语法:
- RETURNS:函数返回的数据类型
- 如果存在OUT或则INOUT参数,则可以省略RETURNS
- function_body:function_body包含可执行部分。
- LANGUAGE:实现该函数的语言的名称。
- 定义动态sql语句:
sql1 := 'select * from AA where id=$1'; - 传参并执行动态sql,并输出结果(结果在函数参数中用out定义):
EXECUTE sql1 using id into result;
逐步学习创建函数
创建函数(只包含函数输入参数,不包含输出参数)
CREATE OR REPLACE FUNCTION "public"."add"("a" int4, "b" numeric)
RETURNS "pg_catalog"."numeric" AS $$
SELECT a+b;
$$
LANGUAGE sql VOLATILE
COST 100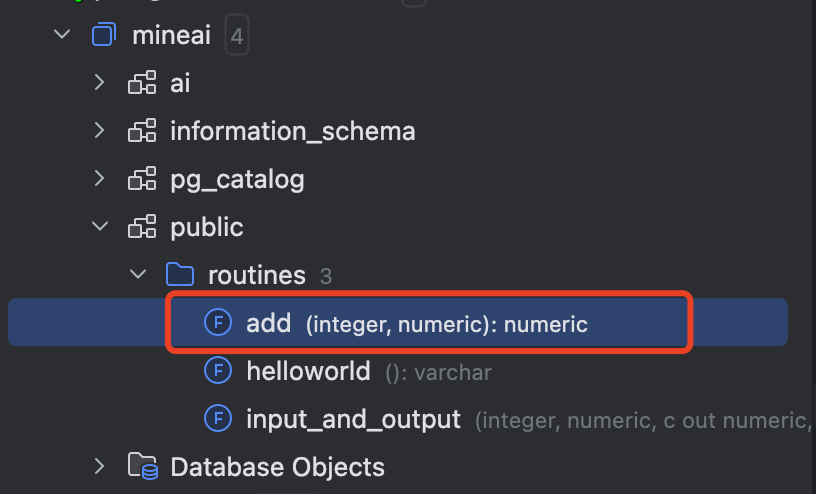
测试函数 select add(1,5);
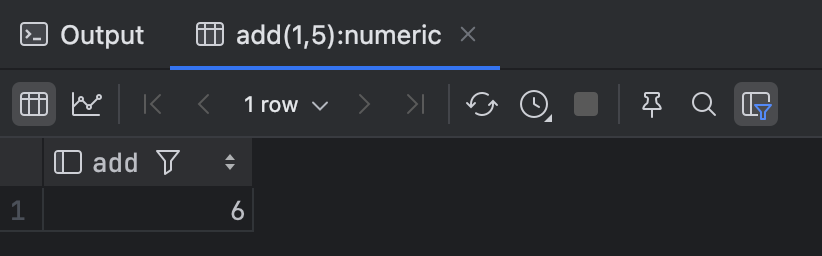
创建函数(同时包含输入参数和输出参数)
IN代表输入参数,OUT代表输出参数
CREATE OR REPLACE FUNCTION "public"."input_and_output"(IN "a" int4, IN "b" numeric, OUT "c" numeric, OUT "d" numeric)
RETURNS "pg_catalog"."record" AS $$
SELECT a+b, a-b;
$$
LANGUAGE sql VOLATILE
COST 100;测试函数 select input_and_output(1,4); 结果 (5,-3)
打印HelloWorld 函数
CREATE FUNCTION helloworld() RETURNS varchar AS $$
<< outerblock >>
DECLARE
name varchar := 'unknown';
BEGIN
RAISE NOTICE 'My Name is %', name ; -- Prints (My Name is unknown)
name := 'plpgsql';
--
-- 创建一个子块
--
DECLARE
name varchar := 'interblock';
BEGIN
RAISE NOTICE 'My Name is %', name; -- Prints (My Name is interblock)
RAISE NOTICE 'My Name is %', outerblock.name; -- Prints (My Name is unknown)
END;
RAISE NOTICE 'My Name is %', name; -- Prints (My Name is plpgsql)
RETURN name;
END;
$$ LANGUAGE plpgsql;
测试函数 select helloworld();
测试结果:
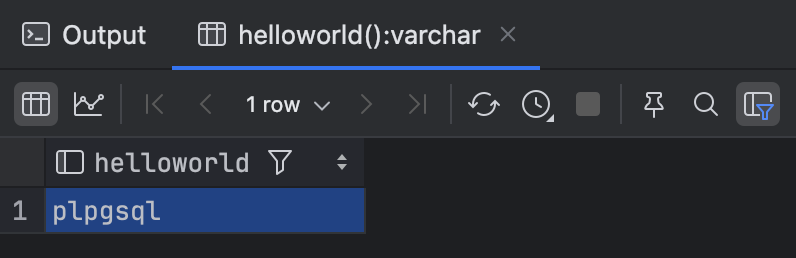
mineai.public> select helloworld()
My Name is unknown
My Name is interblock
My Name is plpgsql
My Name is plpgsql变量声明与数据类型
在一个块中用到的所有变量必须在DECLARE下进行声明。
声明变量的语法为:name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];
CREATE FUNCTION test() RETURNS void AS $$
<< outerblock >>
DECLARE
outer_name varchar; --无默认值
user_id integer := 1; --默认值1
BEGIN
-- 创建一个子块
DECLARE
inter_name varchar := '我是子块的变量';
BEGIN
END;
RETURN name;
END;
$$ LANGUAGE plpgsql;
以上在outerblock块中声明了两个变量(outer_name和user_id默认值为1),在子块中声明了一个变量(inter_name)
高级数据类型
-
复制类型
%TYPE提供了一个变量或表列的数据类型。你可以用它来声明将保持数据库值的变量。例如,如果你在users中有一个名为user_id的列。要定义一个与users.user_id具有相同数据类型的变量:
DECLARE
user_id users.user_id%TYPE;-
行类型
一个组合类型的变量被称为一个行变量(或行类型变量)。这样一个变量可以保持一个SELECT或FOR查询结果的一整行,前提是查询的列集合匹配该变量被声明的类型。该行值的各个域可以使用通常的点号标记访问,例如rowvar.field。
DECLARE
t2_row table2%ROWTYPE;--table2表的行类型-
记录类型
记录变量和行类型变量类似,但是它们没有预定义的结构。它们采用在一个SELECT或FOR命令期间为其赋值的行的真实行结构。一个记录变量的子结构能在每次它被赋值时改变。这样的结果是直到一个记录变量第一次被赋值之前,它都没有子结构,并且任何尝试访问其中一个域都会导致一个运行时错误。
DECLARE
name RECORD; --记录类型函数声明
目前CREATE FUNCTION函数体就是简单的一个字符串。通常在写函数体时,使用美元符号引用通常比使用普通单引号语法更有帮助。如果没有美元引用,函数体中的任何单引号或者反斜线必须通过双写来转义。
推荐写法如下:
CREATE FUNCTION somefunc(integer, text) RETURNS integer AS $$
DECLARE
BEGIN
END;
$$ LANGUAGE plpgsql;声明函数参数被命名为标识符$1、$2等等。可选地,能够为$n参数名声明别名来增加可读性。不管是别名还是数字标识符都能用来引用参数值。
CREATE FUNCTION hello(varchar) RETURNS varchar AS $$
DECLARE
BEGIN
RETURN '你好,' || $1;
END;
$$ LANGUAGE plpgsql;测试函数 select hello('xxxxx'); 结果为 你好,xxxxx
别名函数参数
- 创建函数时为参数给定一个名称(推荐)
CREATE FUNCTION hello(name varchar) RETURNS varchar AS $$
DECLARE
BEGIN
RETURN '你好,' || name ;
END;
$$ LANGUAGE plpgsql;
- 显式地使用声明语法声明一个别名
CREATE FUNCTION hello(varchar) RETURNS varchar AS $$
DECLARE
name ALIAS FOR $1;
BEGIN
RETURN '你好,' || name ;
END;
$$ LANGUAGE plpgsql;
函数返回
-
returns返回
示例函数就使用returns返回了一个varchar类型的值。
CREATE FUNCTION hello(name varchar) RETURNS varchar AS $$
DECLARE
BEGIN
RETURN '你好,' || name ;
END;
$$ LANGUAGE plpgsql;
-
输出参数返回
输出参数在返回多个值时很有用。在定义函数时使用OUT关键字标识返回参数。示例如下:
CREATE FUNCTION sum_n_product(x int, y int, OUT sum int, OUT prod int) AS $$
BEGIN
sum := x + y;
prod := x * y;
END;
$$ LANGUAGE plpgsql;
测试函数 select * from sum_n_product(12,34);
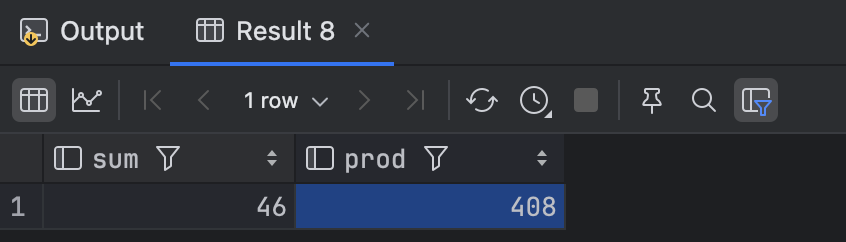
示例函数的结果实际上创建了一个匿名记录类型。如果使用RETURNS返回,它必须是RETURNS record。使用RETURNS record返回写法如下:
CREATE or replace FUNCTION sum_n_product(x int, y int) returns record AS $$
DECLARE
r_data record;
sum int;
prod int;
BEGIN
sum := x + y;
prod := x * y;
r_data = (sum , prod );
return r_data;
END;
$$ LANGUAGE plpgsql;
返回数据类型
组合数据类型
组合数据类型就是将多个数据类型组合为一个数据类型,然后可以用于函数返回中,例如写一个函数模拟HTTP请求返回结果,即同时返回status和body(status int, body varchar)。这时可以使用组合数据类型类返回,示例如下:
创建组合数据类型
由于该函数的返回结果依赖于数据类型,想删除该数据类型前需要先删除函数
create type http_result as (
http_status int,
body varchar
)
-- drop TYPE if EXISTS http_result
函数示例
create or replace function http(param int) returns http_result as $$
declare
code int;
msg varchar;
begin
if param < 100 then
code = 200;
msg = '请求成功';
else
code = 500;
msg = '请求失败';
end if;
return (code, msg);
end;
$$ language plpgsql;
测试函数 select * from http(20);
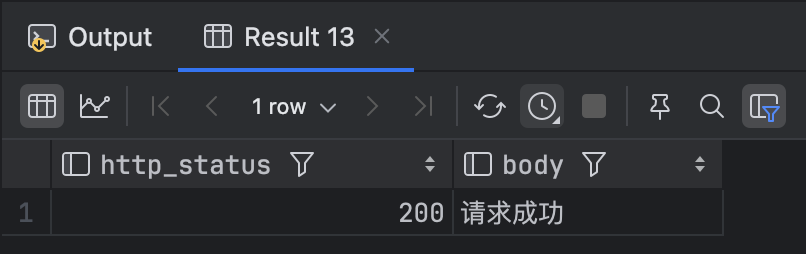
行数据类型
在写函数时除了组合数据类型外,还可以返回行数据类型,即返回某个表的一条行记录类型。如在GIS行业对某个数据进行抽稀时,则可以使用返回行数据类型,对某个表的数据进行处理后,返回同样数据格式。
一个组合类型的变量被称为一个行变量(或行类型变量)。这样一个变量可以保持一个SELECT或FOR查询结果的一整行,前提是查询的列集合匹配该变量被声明的类型。该行值的各个域可以使用通常的点号标记访问,例如rowvar.field。
通过使用table_name%ROWTYPE标记,一个行变量可以被声明为具有和一个现有表或视图的行相同的类型。它也可以通过给定一个组合类型名称来声明(因为每一个表都有一个相关联的具有相同名称的组合类型,所以在PostgreSQL中实际上写不写%ROWTYPE都没有关系。但是带有%ROWTYPE的形式可移植性更好)。
-- return next
create or replace function jcb_cddm_filter(code int) returns SETOF camera as $$
declare
r camera%rowtype;
begin
for r in select * from camera where vendor = code loop
return next r;
end loop;
return;
end;
$$ language plpgsql;
-- return next
create or replace function jcb_cddm_filter(code int) returns SETOF camera as $$
declare
r camera%rowtype;
begin
return query select * from camera where vendor = code ;
IF NOT FOUND THEN
RAISE EXCEPTION '未找到数据';
END IF;
return;
end;
$$ language plpgsql;测试函数 select * from jcb_cddm_filter(2);

记录数据类型
使用方法与行数据类型相似
记录变量和行类型变量类似,但是它们没有预定义的结构。它们采用在一个SELECT或FOR命令期间为其赋值的行的真实行结构。一个记录变量的子结构能在每次它被赋值时改变。这样的结果是直到一个记录变量第一次被赋值之前,它都没有子结构,并且任何尝试访问其中一个域都会导致一个运行时错误。
注意RECORD并非一个真正的数据类型,只是一个占位符。我们也应该认识到当一个PL/pgSQL函数被声明为返回类型record,这与一个记录变量并不是完全相同的概念,即便这样一个函数可能会用一个记录变量来保持其结果。在两种情况下,编写函数时都不知道真实的行结构,但是对于一个返回record的函数,当调用查询被解析时就已经决定了真正的结构,而一个行变量能够随时改变它的行结构。
-- return next
create or replace function record_test(table_name varchar) returns SETOF record as $$
declare
r record;
begin
for r in EXECUTE 'select vendor from ' || table_name loop
return next r;
end loop;
return;
end;
$$ language plpgsql;
-- return query
create or replace function record_test(table_name varchar) returns SETOF record as $$
declare
begin
return query EXECUTE 'select vendor from ' || table_name ;
IF NOT FOUND THEN
RAISE EXCEPTION '未找到数据';
END IF;
return;
end;
$$ language plpgsql;测试函数 select * from record_test('camera') as t(vendor int);
后面一定要跟上 as t(vendor int); 用于指定具体的列名和类型不然会报错
复制数据类型
%TYPE提供了一个变量或表列的数据类型。你可以用它来声明将保持数据库值的变量。例如,如果你在users中有一个名为user_id的列。
要定义一个与users.user_id具有相同数据类型的变量:
user_id users.user_id%TYPE;
通过使用%TYPE,你不需要知道你要引用的结构的实际数据类型,而且最重要地,如果被引用项的数据类型在未来被改变(例如你把user_id的类型从integer改为real),你不需要改变你的函数定义。
%TYPE在多态函数中特别有价值,因为内部变量所需的数据类型能在两次调用时改变。可以把%TYPE应用在函数的参数或结果占位符上来创建合适的变量。
create or replace function test_copy(vendor camera.vendor%TYPE) returns camera.vendor%TYPE as $$
declare
begin
return vendor;
end;
$$ language plpgsql;测试函数:select test_copy(1)
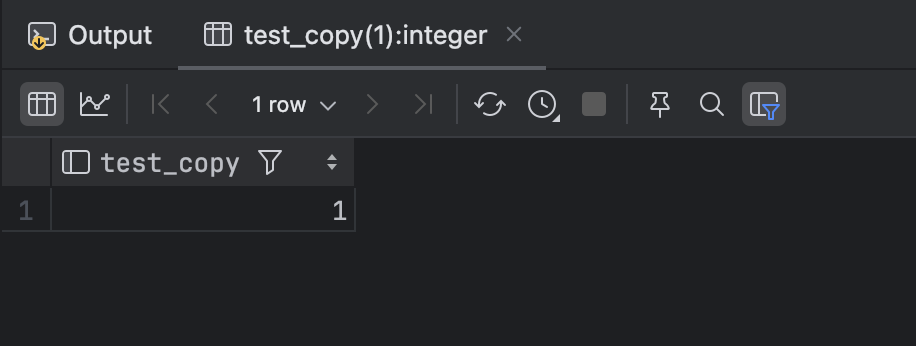
条件语句
PL/pgSQL中有两种条件语句分别为if与case语句。
if语句形式包含以下几种:
- IF … THEN … END IF
- IF … THEN … ELSE … END IF
- IF … THEN … ELSIF … THEN … ELSE … END IF
关键词ELSIF也可以写成ELSEIF。elsif可以写多个
示例函数 test_if,将下方示例语句复制到对应位置即可进行测试
create or replace function test_if(i int) returns void as $$
DECLARE
BEGIN
-- 替换对应if语句
END;
$$ LANGUAGE plpgsql;
IF … THEN … END IF
该示例当输入值i大于10时会打印i的值为:%
if i > 10 then
raise notice 'i的值为:%', i;
end if;
IF … THEN … ELSE … END IF
该示例当输入值i大于10时会打印i的值大于10否则会打印i的值小于等于10
if i > 10 then
raise notice 'i的值大于10';
else
raise notice 'i的值小于等于10';
end if;
IF … THEN … ELSIF … THEN … ELSE … END IF
该示例当输入值i大于10时会打印i的值大于10,当输入值为5时会打印'i的值为5',否则会打印i的值小于等于10
if i > 10 then
raise notice 'i的值大于10';
elsif i = 5 then
raise notice 'i的值为5';
else
raise notice 'i的值小于等于10';
end if;
case
CASE … WHEN … THEN … ELSE … END CASE
CASE WHEN … THEN … ELSE … END CASE
示例
示例函数 test_case,将下方示例语句复制到对应位置即可进行测试
create or replace function test_case(i int) returns void as $$
DECLARE
BEGIN
-- 替换对应case语句
END;
$$ LANGUAGE plpgsql;CASE … WHEN … THEN … ELSE … END CASE
如果没有找到匹配,ELSE 语句会被执行如果ELSE不存在,将会抛出一个CASE_NOT_FOUND异常
该示例当输入值i为1时会打印i的值为1,当输入值为2时会打印'i的值为2',否则会打印i的值既不为1也不为2
case i
when 1,3 then
raise notice 'i的值为1';
when 2 then
raise notice 'i的值为2';
else
raise notice 'i的值既不为1也不为2';
end case;CASE WHEN … THEN … ELSE … END CASE
如果没有找到匹配,ELSE 语句会被执行如果ELSE不存在,将会抛出一个CASE_NOT_FOUND异常
case when是基于布尔表达式真假来执行
该示例当输入值i为0-10之间时会打印i的值在0-10之间,当输入值为11-20之间时会打印i的值在11-20之间',否则会打印i的值不在0-20之间
CASE
WHEN i BETWEEN 0 AND 10 THEN
raise notice 'i的值在0-10之间';
WHEN i BETWEEN 11 AND 20 THEN
raise notice 'i的值在11-20之间';
else
raise notice 'i的值不在0-20之间';
END CASE;
循环语句
LOOP循环
[ <<label>> ]
LOOP
statements
END LOOP [ label ];
LOOP定义一个无条件的循环,它会无限重复直到被EXIT或RETURN语句终止。可选的label可以被EXIT和CONTINUE语句用在嵌套循环中指定这些语句引用的是哪一层循环
示例
示例函数 test_loop,将下方示例语句复制到对应位置即可进行测试
create or replace function test_loop(i int) returns int as $$
DECLARE
BEGIN
-- 替换对应loop语句
END;
$$ LANGUAGE plpgsql;
exit 退出
该示例首先对i的值加1,如果i的值大于10则退出循环,执行return语句返回结果。输入i的值为0时,返回结果11,输入i的值为20时,返回结果21。
exit when 退出
该示例与上方示例效果一样。
LOOP
-- 一些计算
i = i + 1;
EXIT WHEN i > 10; -- 和前一个例子相同的结果
END LOOP;
return i;
exit [lable]
该示例执行select test_loop(0)时输出结果为11,而不是100。当exit指定退出标签时,会退出整个块语句继续执行,以下示例退出twoblock,执行return语句,所以该值为11;
create or replace function test_loop(i int) returns int as $$
<<oneblock>>
DECLARE
BEGIN
<<twoblock>>
DECLARE
BEGIN
<<threeblock>>
DECLARE
begin
LOOP
-- 一些计算
i = i + 1;
IF i > 10 THEN
EXIT twoblock; -- 退出循环
END IF;
END LOOP;
END;
i = 100;
END;
return i;
END;
$$ LANGUAGE plpgsql;
continue
CONTINUE [ label ] [ WHEN boolean-expression ];
CONTINUE可以被用在所有类型的循环中,它并不限于在LOOP中使用。
该示例会打印输出i的值,其中当i的值为5时,不会打印。
LOOP
i = i + 1;
EXIT WHEN i > 10;
CONTINUE WHEN i = 5;
raise notice 'i的值为:%',i;
END LOOP;
WHILE循环
[ <<label>> ]
WHILE boolean-expression LOOP
statements
END LOOP [ label ];示例
示例函数 test_,将下方示例语句复制到对应位置即可进行测试,下方所有循环都可以使用此函数测试。
create or replace function test_(i int) returns int as $$
DECLARE
BEGIN
-- 替换对应循环语句
END;
$$ LANGUAGE plpgsql;
该示例输入值为0,判断i的值是否小于10,小于10则执行+1,否则return。
WHILE i < 10 LOOP
i = i + 1;
END LOOP;
return i;FOR循环
这种形式的FOR会创建一个在一个整数范围上迭代的循环。变量name会自动定义为类型integer并且只在循环内存在(任何该变量名的现有定义在此循环内都将被忽略)。给出范围上下界的两个表达式在进入循环的时候计算一次。如果没有指定BY子句,迭代步长为 1,否则步长是BY中指定的值,该值也只在循环进入时计算一次。如果指定了REVERSE,那么在每次迭代后步长值会被减除而不是增加。
[ <<label>> ]
FOR name IN [ REVERSE ] expression .. expression [ BY expression ] LOOP
statements
END LOOP [ label ];
示例
FOR i IN 1..10 LOOP
-- 我在循环中将取值 1,2,3,4,5,6,7,8,9,10
END LOOP;
FOR i IN REVERSE 10..1 LOOP
-- 我在循环中将取值 10,9,8,7,6,5,4,3,2,1
END LOOP;
FOR i IN REVERSE 10..1 BY 2 LOOP
-- 我在循环中将取值 10,8,6,4,2
END LOOP;
查询结果循环(FOR…IN…)
FOR…IN
通过一个查询的结果进行迭代并且操纵相应的数据。语法是:
[ <<label>> ]
FOR target IN query LOOP
statements
END LOOP [ label ];
target是一个记录变量、行变量或者逗号分隔的标量变量列表。target被连续不断被赋予来自query的每一行,并且循环体将为每一行执行一次。下面是一个例子:
create or replace function test_for_in() returns int as $$
DECLARE
cddm record;
BEGIN
RAISE NOTICE 'reading camera...';
FOR cddm IN SELECT * FROM camera limit 5 LOOP
RAISE NOTICE 'id:%,场地名称为 %', cddm.id, quote_ident(cddm.name);
END LOOP;
return 1;
END;
$$ LANGUAGE plpgsql;输出信息
FOR…IN…EXECUTE
FOR-IN-EXECUTE语句是在行上迭代的另一种方式,示例如下:
该示例将代码作为参数传入,使用using动态替换
create or replace function test_for_in2(dm int) returns int as $$
DECLARE
cddm record;
BEGIN
RAISE NOTICE 'reading camera...';
FOR cddm IN execute 'SELECT * FROM camera where vendor = $1 limit 5' using dm LOOP
RAISE NOTICE 'id:%,场地名称为 %', cddm.id, quote_ident(cddm.name);
END LOOP;
return 1;
END;
$$ LANGUAGE plpgsql;测试函数:select test_for_in2(1);

数组循环(FOREACH)
FOREACH语法结构如下:
[ <<label>> ]
FOREACH target [ SLICE number ] IN ARRAY expression LOOP
statements
END LOOP [ label ];示例
- 不使用slice
该示例使用select test_sum(array[1,2,3])语句测试会返回和为6
CREATE FUNCTION test_sum(int[]) RETURNS int8 AS $$
DECLARE
s int8 := 0;
x int;
BEGIN
FOREACH x IN ARRAY $1
LOOP
s := s + x;
END LOOP;
RETURN s;
END;
$$ LANGUAGE plpgsql;测试函数 select test_sum(array[1,2,3]) 结果为 6
- slice示例
通过一个正SLICE值,FOREACH通过数组的切片而不是单一元素迭代。SLICE值必须是一个不大于数组维度数的整数常量。target变量必须是一个数组,并且它接收数组值的连续切片,其中每一个切片都有SLICE指定的维度数。这里是一个通过一维切片迭代的例子:
CREATE FUNCTION scan_rows(int[]) RETURNS void AS $$
DECLARE
x int[];
BEGIN
FOREACH x SLICE 1 IN ARRAY $1
LOOP
RAISE NOTICE 'row = %', x;
END LOOP;
END;
$$ LANGUAGE plpgsql;测试函数 select scan_rows(array[[1,2,3],[2,3,4],[11,22,33],[6,6,8]]);

