阅读完需:约 68 分钟
测试采用 postgres:17beta2 版本的docker images
逻辑复制与流复制的区别
PostgreSQL 支持两种主要的复制模式:物理复制(也称为流复制)和逻辑复制。这两种复制模式有着根本性的不同,主要体现在它们复制数据的方式、用途以及对系统资源的影响上。以下是它们之间的主要区别:
物理复制特点(流复制)
物理复制是一种基于 WAL(Write-Ahead Log)的日志的复制方式。当主数据库接收到事务提交时,WAL 记录会被写入磁盘,然后同步或异步地传输到一个或多个备机(standby servers)。备机使用这些WAL记录来重放事务,以保持与主机的数据一致性。
特点:
- 数据一致性:物理复制保证了在故障恢复时的数据一致性,因为备机拥有与主机完全相同的数据集。
- 实时性:物理复制可以接近实时地复制数据,尽管这取决于网络延迟和WAL应用的速度。
- 全数据库范围:物理复制影响整个数据库,而不仅仅是特定的表或模式。
- 读写能力:备机可以配置为热备机(hot standby),允许在备机上执行只读查询,从而提供负载均衡和读取扩展。
- 资源消耗:物理复制需要保留WAL日志直到所有备机确认收到并应用,这可能会占用较多的磁盘空间和网络带宽。
逻辑复制特点
逻辑复制是一种基于SQL的复制方式,它允许你选择性地复制特定的表、列或数据行的更改。逻辑复制使用发布(Publication)和订阅(Subscription)的概念,允许你精确地控制哪些更改被复制。
特点:
- 选择性复制:逻辑复制允许你选择性地复制特定的表或列,甚至可以过滤特定的数据行。
- SQL级复制:逻辑复制捕获并复制SQL语句,这意味着在目标数据库上看到的更改与源数据库上执行的更改相同。
- 低资源消耗:逻辑复制通常比物理复制消耗更少的磁盘空间和网络带宽,因为它不复制整个WAL日志。
- 数据变换:在复制过程中,可以使用SQL变换来修改数据,例如,可以调整数据格式或转换数据类型。
- 多数据库复制:逻辑复制可以跨不同的数据库或服务器,甚至可以跨不同的数据库集群。
- 不支持所有操作:逻辑复制不支持所有类型的SQL操作,例如,它可能无法处理分区表或复杂的数据类型。
总结
物理复制和逻辑复制各有优势和局限性。物理复制适合需要高可用性和灾难恢复的场景,而逻辑复制更适合于数据分发、数据整合或在不同的数据库间同步特定数据集的需求。选择哪种复制模式取决于你的业务需求、资源限制以及对数据一致性和实时性的要求。
复制标识(Replica Identity)
在看逻辑复制前,先了解一下复制标识的含义,有助于理解逻辑复制是如何工作的
复制身份的概念,服务于 逻辑复制。
逻辑复制的基本工作原理是,将逻辑发布相关表上对行的增删改事件解码,复制到逻辑订阅者上执行。
逻辑复制的工作方式有点类似于行级触发器,在事务执行后对变更的元组逐行触发。
假设您需要自己通过触发器实现逻辑复制,将一章表A上的变更复制到另一张表B中。通常情况下,这个触发器的函数逻辑通常会长这样:
-- 通知触发器
CREATE OR REPLACE FUNCTION replicate_change() RETURNS TRIGGER AS $$
BEGIN
IF (TG_OP = 'INSERT') THEN
-- INSERT INTO tbl_b VALUES (NEW.col);
ELSIF (TG_OP = 'DELETE') THEN
-- DELETE tbl_b WHERE id = OLD.id;
ELSIF (TG_OP = 'UPDATE') THEN
-- UPDATE tbl_b SET col = NEW.col,... WHERE id = OLD.id;
END IF;
END; $$ LANGUAGE plpgsql;触发器中会有两个变量OLD与NEW,分别包含了变更记录的旧值与新值。
-
INSERT操作只有NEW变量,因为它是新插入的,我们直接将其插入到另一张表即可。 -
DELETE操作只有OLD变量,因为它只是删除已有记录,我们 根据ID 在目标表B上。 -
UPDATE操作同时存在OLD变量与NEW变量,我们需要通过OLD.id定位目标表B中的记录,将其更新为新值NEW。
这样的基于触发器的“逻辑复制”可以完美达到我们的目的,在逻辑复制中与之类似,表A上带有主键字段id。那么当我们删除表A上的记录时,例如:删除id = 1的记录时,我们只需要告诉订阅方id = 1,而不是把整个被删除的元组传递给订阅方。那么这里主键列id就是逻辑复制的复制标识。
但上面的例子中隐含着一个工作假设:表A和表B模式相同,上面有一个名为 id 的主键。
对于生产级的逻辑复制方案,即PostgreSQL 10.0后提供的逻辑复制,这样的工作假设是不合理的。因为系统无法要求用户建表时一定会带有主键,也无法要求主键的名字一定叫id。
于是,就有了 复制标识(Replica Identity) 的概念。复制标识是对OLD.id这样工作假设的进一步泛化与抽象,它用来告诉逻辑复制系统,哪些信息可以被用于唯一定位表中的一条记录。
对于逻辑复制而言,INSERT 事件不需要特殊处理,但要想将DELETE|UPDATE复制到订阅者上时,必须提供一种标识行的方式,即复制标识(Replica Identity)。复制标识是一组列的集合,这些列可以唯一标识一条记录。其实这样的定义在概念上来说就是构成主键的列集,当然非空唯一索引中的列集(候选键)也可以起到同样的效果。
一个被纳入逻辑复制 发布中的表,必须配置有 复制标识(Replica Identity),只有这样才可以在订阅者一侧定位到需要更新的行,完成UPDATE与DELETE操作的复制。默认情况下,主键 (Primary Key)和 非空列上的唯一索引 (UNIQUE NOT NULL)可以用作复制标识。
注意,复制标识 和表上的主键、非空唯一索引并不是一回事。复制标识是表上的一个属性,它指明了在逻辑复制时,哪些信息会被用作身份定位标识符写入到逻辑复制的记录中,供订阅端定位并执行变更。
如PostgreSQL 13官方文档所述,表上的复制标识 共有4种配置模式,分别为:
- 默认模式(default):非系统表采用的默认模式,如果有主键,则用主键列作为身份标识,否则用完整模式。
- 索引模式(index):将某一个符合条件的索引中的列,用作身份标识
- 完整模式(full):将整行记录中的所有列作为复制标识(类似于整个表上每一列共同组成主键)
- 无身份模式(nothing):不记录任何复制标识,这意味着
UPDATE|DELETE操作无法复制到订阅者上。
复制标识查询
表上的复制标识可以通过查阅pg_class.relreplident获取。
这是一个字符类型的“枚举”,标识用于组装 “复制标识” 的列:d = default ,f = 所有的列,i 使用特定的索引,n 没有复制标识。
表上是否具有可用作复制标识的索引约束,可以通过以下查询获取:
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name,
con.ri AS keys,
CASE relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index' END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON c.relnamespace = n.oid,
LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r'
AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2, 3;解释一下这段SQL的含义
-
SELECT 语句:
-
quote_ident(nspname) || '.' || quote_ident(relname) AS name: 这里使用 PostgreSQL 的quote_ident函数来确保 schema 名称 (nspname) 和表名称 (relname) 能够正确地作为 SQL 标识符被引用,即使它们包含特殊字符或保留关键字。||是字符串连接运算符,将 schema 名和表名以点号(.)分隔组合成一个完整的表名。
-
PostgreSQL quote_ident() 函数返回适当引用的给定字符串,以用作 SQL 语句字符串中的标识符,就是将不合格的标识符转为合格的标识符
-
LATERAL JOIN:
-
LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con: 这个 LATERAL 子查询用于收集与每个表相关的约束类型(contype)。array_agg是一个聚合函数,它收集一组值并将它们组合成一个数组。这里,它收集了pg_constraint表中与当前表 (conrelid = c.oid) 相关联的所有约束类型。
-
PostgreSQL 横向子查询——LATERAL
一般来说,SQL 子查询只能引用外查询中的字段,而不能使用同一层级中其他表中的字段。
select v.*, r.*
from vehicle v
LEFT join (select * from violation_record e where e.veh_id = v.id) r;
ERROR: syntax error at end of input由于 JOIN 子句中的查询语句 r 引用了左侧 vehicle 表中的字段,因此产生了语法错误。
为了解决以上问题,我们可以使用 PostgreSQL 提供的横向子查询(LATERAL subquery)。不过在介绍 LATERAL 关键字之前,回顾一下 SELECT 和 FROM 子句的含义。例如:
select v.* from vehicle v简单来说,我们可以将以上查询看作一个循环处理语句。使用伪代码实现的以上 SQL 语句如下:
for v.*(表中的字段) in vehicle
loop
print v.*(表中的字段)
end loop对于 vehicle 中的每一条记录,都执行 SELECT 语句指定的操作,以上示例简单的输出了每行记录。
SELECT 就像一个循环语句,而 LATERAL 就像是一个嵌套循环语句,对于左侧表中的每行记录执行一次子查询操作。例如,通过增加 LATERAL 关键字,可以修改第一个示例:
select v.*, r.*
from vehicle v
CROSS join LATERAL (select * from violation_record e where e.veh_id = v.id) r;
CROSS JOIN LATERAL 右侧的查询可以引用左侧表中的字段
LATERAL 可以帮助我们实现一些有用的分析功能
-
FROM 和 JOIN:
-
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid: 这部分从pg_class表(包含了所有表的信息)和pg_namespace表(包含了 schema 的信息)中获取数据。pg_class和pg_namespace通过relnamespace字段关联,这个字段指向了pg_class表中的表所属的 schema 的 OID。
-
pg_ class 是数据字典最重要的一个表,它保存着所有表、视图、序列、索引的原数据信息,每一个DDL/DML操作都必须跟这个表发生联系
| 名字 | 类型 | 引用 | 描述 |
|---|---|---|---|
| oid | oid | 行标识符(隐藏属性; 必须明确选择) | |
| relname | name | 表、索引、视图等的名字。 | |
| relnamespace | oid | pg_namespace.oid | 包含这个关系的名字空间(模式)的 OID |
| reltype | oid | pg_type.oid | 如果有,则为对应这个表的行类型的数据类型的OID(索引为零,它们没有pg_type记录)。 |
| reloftype | oid | pg_type.oid | 对于类型表,为底层复合类型的OID,对于所有其他关系为0 |
| relowner | oid | pg_authid.oid | 关系所有者 |
| relam | oid | pg_am.oid | 如果行是索引,那么就是所用的访问模式(B-tree, hash 等等) |
| relfilenode | oid | 这个关系在磁盘上的文件的名字,0表示这是一个”映射的”关系, 它的文件名取决于行级别的状态 | |
| reltablespace | oid | pg_tablespace.oid | 这个关系存储所在的表空间。如果为零,则意味着使用该数据库的缺省表空间。 如果关系在磁盘上没有文件,则这个字段没有什么意义。 |
| relpages | int4 | 以页(大小为BLCKSZ)的此表在磁盘上的形式的大小。 它只是规划器用的一个近似值,是由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。 | |
| reltuples | float4 | 表中行的数目。只是规划器使用的一个估计值,由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。 | |
| relallvisible | int4 | 在表的可见映射中标记所有可见的页的数目。只是规划器使用的一个估计值, 由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。 | |
| reltoastrelid | oid | pg_class.oid | 与此表关联的 TOAST 表的 OID ,如果没有为 0 。TOAST 表在一个从属表里”离线”存储大字段。 |
| relhasindex | bool | 如果它是一个表而且至少有(或者最近有过)一个索引,则为真。 | |
| relisshared | bool | 如果该表在整个集群中由所有数据库共享则为真。只有某些系统表 (比如pg_database)是共享的。 | |
| relpersistence | char | p = permanent table(永久表), u = unlogged table(未加载的表), t = temporary table (临时表) | |
| relkind | char | r = ordinary table(普通表), i = index(索引), S = sequence(序列), v = view(视图), m = materialized view(物化视图), c = composite type(复合类型), t = TOAST table(TOAST 表), f = foreign table(外部表) | |
| relnatts | int2 | 关系中用户字段数目(除了系统字段以外)。在pg_attribute 里肯定有相同数目对应行。又见pg_attribute.attnum。 | |
| relchecks | int2 | 表里的CHECK约束的数目;参阅pg_constraint表 | |
| relhasoids | bool | 如果为关系中每行都生成一个 OID 则为真 | |
| relhaspkey | bool | 如果这个表有一个(或者曾经有一个)主键,则为真。 | |
| relhasrules | bool | 如表有(或曾经有)规则就为真;参阅pg_rewrite表 | |
| relhastriggers | bool | 如果表有(或者曾经有)触发器,则为真;参阅pg_trigger表 | |
| relhassubclass | bool | 如果有(或者曾经有)任何继承的子表,为真。 | |
| relispopulated | bool | 如果关系是填充的则为真(对所有关系为真,除了一些物化视图) | |
| relreplident | char | 用来形成行的”副本身份”的字段: d = 缺省 (主键,如果有), n = 空, f = 所有字段 i = 带有indisreplident集的索引,或缺省 | |
| relfrozenxid | xid | 该表中所有在这个之前的事务 ID 已经被一个固定的(“frozen”)事务 ID 替换。 这用于跟踪该表是否需要为了防止事务 ID 重叠或者允许收缩pg_clog 而进行清理。如果该关系不是表则为零(InvalidTransactionId)。 | |
| relminmxid | xid | 该表中所有在这个之前的 multixact ID 已经被一个事务 ID 替换。 这用于跟踪该表是否需要为了防止 multixact ID 重叠或者允许收缩pg_multixact 而进行清理。如果该关系不是表则为零(InvalidMultiXactId)。 | |
| relacl | aclitem[] | 访问权限。参阅GRANT和REVOKE获取详细信息。 | |
| reloptions | text[] | 访问方法特定的选项,使用”keyword=value”格式的字符串 |
pg_namespace 存储命名空间。命名空间是 SQL 模式的基础结构:每个命名空间都可以有单独的关系、类型等集合,而不会出现名称冲突。
| 名字 | 类型 | 引用 | 描述 |
|---|---|---|---|
| oid | oid | 行标识符(隐藏属性; 必须明确选择) | |
| nspname | name | 名字空间的名字 | |
| nspowner | oid | pg_authid.oid | 名字空间的所有者 |
| nspacl | aclitem[] | 访问权限;参阅GRANT和REVOKE获取细节。 |
-
CASE 表达式:
-
CASE relreplident WHEN ... END AS replica_identity: 这个CASE表达式用于将relreplident字段的值转换为人类可读的描述。relreplident字段指示了表的复制标识类型,这对于流复制或逻辑复制非常重要。根据不同的值,它会返回 ‘default’, ‘nothing’, ‘full’, 或 ‘index’,这些值描述了在复制过程中如何标识行。
-
-
WHERE 子句:
-
WHERE relkind = 'r': 这个条件确保只选择常规表(relkind = 'r')。 -
AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast'): 这个条件排除了一些系统 schema,这些 schema 通常包含内部使用或管理信息的表,它们可能不适用于常规的复制或查询。
-
-
ORDER BY 子句:
-
ORDER BY 2, 3: 最后,结果按照第二列(keys,即约束类型数组)和第三列(replica_identity,即复制标识)排序。
-
复制标识配置
表到复制标识可以通过ALTER TABLE进行修改。
ALTER TABLE tbl REPLICA IDENTITY { DEFAULT | USING INDEX index_name | FULL | NOTHING };
-- 具体有四种形式
ALTER TABLE t_normal REPLICA IDENTITY DEFAULT; -- 使用主键,如果没有主键则为FULL
ALTER TABLE t_normal REPLICA IDENTITY FULL; -- 使用整行作为标识
ALTER TABLE t_normal REPLICA IDENTITY USING INDEX t_normal_v_key; -- 使用唯一索引
ALTER TABLE t_normal REPLICA IDENTITY NOTHING; -- 不设置复制标识复制标识实例
下面用一个具体的例子来说明复制标识的效果:
CREATE TABLE test(k text primary key, v int not null unique);现在有一个表test,上面有两列k和v。
INSERT INTO test VALUES('Alice', '1'), ('Bob', '2');
UPDATE test SET v = '3' WHERE k = 'Alice'; -- update Alice value to 3
UPDATE test SET k = 'Oscar' WHERE k = 'Bob'; -- rename Bob to Oscaar
DELETE FROM test WHERE k = 'Alice'; -- delete Alice在这个例子中,我们对表test执行了增删改操作,与之对应的逻辑解码结果为:
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: old-key: k[text]:'Bob' new-tuple: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: k[text]:'Alice'默认情况下,PostgreSQL会使用表的主键作为复制标识,因此在UPDATE|DELETE操作中,都通过k列来定位需要修改的记录。
如果我们手动修改表的复制标识,使用非空且唯一的列v作为复制标识,也是可以的:
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key; -- 基于UNIQUE索引的复制身份同样的变更现在产生如下的逻辑解码结果,这里v作为身份标识,出现在所有的UPDATE|DELETE事件中。
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: old-key: v[integer]:1 new-tuple: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: v[integer]:3如果使用完整身份模式(full)
ALTER TABLE test REPLICA IDENTITY FULL; -- 表test现在使用所有列作为表的复制身份这里,k和v同时作为身份标识,记录到UPDATE|DELETE的日志中。对于没有主键的表,这是一种保底方案。
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: old-key: k[text]:'Alice' v[integer]:1 new-tuple: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: old-key: k[text]:'Bob' v[integer]:2 new-tuple: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: k[text]:'Alice' v[integer]:3
如果使用无身份模式(nothing)
ALTER TABLE test REPLICA IDENTITY NOTHING; -- 表test现在没有复制标识
那么逻辑解码的记录中,UPDATE操作中只有新记录,没有包含旧记录中的唯一身份标识,而DELETE操作中则完全没有信息。
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: (no-tuple-data)
这样的逻辑变更日志对于订阅端来说完全没用,在实际使用中,对逻辑复制中的无复制标识的表执行DELETE|UPDATE会直接报错。
复制标识详解
表上的复制标识配置,与表上有没有索引,是相对正交的两个因素。
尽管各种排列组合都是可能的,然而在实际使用中,只有三种可行的情况。
- 表上有主键,使用默认的
default复制标识 - 表上没有主键,但是有非空唯一索引,显式配置
index复制标识 - 表上既没有主键,也没有非空唯一索引,显式配置
full复制标识(运行效率非常低,仅能作为兜底方案) - 其他所有情况,都无法正常完成逻辑复制功能
| 复制身份模式\表上的约束 | 主键(p) | 非空唯一索引(u) | 两者皆无(n) |
|---|---|---|---|
| default | 有效 | x | x |
| index | x | 有效 | x |
| full | 低效 | 低效 | 低效 |
| nothing | x | x | x |
下面,我们来考虑几个边界条件。
重建主键
假设因为索引膨胀,我们希望重建表上的主键索引回收空间。
CREATE TABLE test(k text primary key, v int);
CREATE UNIQUE INDEX test_pkey2 ON test(k);
BEGIN;
ALTER TABLE test DROP CONSTRAINT test_pkey;
ALTER TABLE test ADD PRIMARY KEY USING INDEX test_pkey2;
COMMIT;在default模式下,重建并替换主键约束与索引并不会影响复制标识。
重建唯一索引
假设因为索引膨胀,我们希望重建表上的非空唯一索引回收空间。
CREATE TABLE test(k text, v int not null unique);
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key;
CREATE UNIQUE INDEX test_v_key2 ON test(v);
-- 使用新的test_v_key2索引替换老的Unique索引
BEGIN;
ALTER TABLE test ADD UNIQUE USING INDEX test_v_key2;
ALTER TABLE test DROP CONSTRAINT test_v_key;
COMMIT;
与default模式不同,index模式下,复制标识是与具体的索引绑定的
这意味着如果采用偷天换日的方式替换UNIQUE索引会导致复制身份的丢失。
解决方案有两种:
- 使用
REINDEX INDEX (CONCURRENTLY)的方式重建该索引,不会丢失复制标识信息。 - 在替换索引时,一并刷新表的默认复制身份:
BEGIN;
ALTER TABLE test ADD UNIQUE USING INDEX test_v_key2;
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key2;
ALTER TABLE test DROP CONSTRAINT test_v_key;
COMMIT;
顺带一提,移除作为身份标识的索引。尽管在表的配置信息中仍然为index模式,但效果与nothing相同。所以不要随意折腾作为身份的索引。
使用不合格的索引作为复制标识
复制标识需要一个 唯一,不可延迟,整表范围的,建立在非空列集上的索引。
最经典的例子就是主键索引,以及通过col type NOT NULL UNIQUE声明的单列非空索引。
之所以要求 NOT NULL,是因为NULL值无法进行等值判断,所以表中允许UNIQE的列上存在多条取值为NULL的记录,允许列为空说明这个列无法起到唯一标识记录的效果。如果尝试使用一个普通的UNIQUE索引(列上没有非空约束)作为复制标识,则会报错。
[42809] ERROR: index "t_normal_v_key" cannot be used as replica identity because column "v" is nullable使用FULL复制标识
如果没有任何复制标识,可以将复制标识设置为FULL,也就是把整个行当作复制标识。
使用FULL模式的复制标识效率很低,所以这种配置只能是保底方案,或者用于很小的表。因为每一行修改都需要在订阅者上执行全表扫描,很容易把订阅者拖垮。
FULL模式限制
使用FULL模式的复制标识还有一个限制,订阅端的表上的复制身份所包含的列,要么与发布者一致,要么比发布者更少,否则也无法保证的正确性,下面具体来看一个例子。
假如发布订阅两侧的表都采用FULL复制标识,但是订阅侧的表要比发布侧多了一列(是的,逻辑复制允许订阅端的表带有发布端表不具有的列)。这样的话,订阅端的表上的复制身份所包含的列要比发布端多了。假设在发布端上删除(f1=a, f2=a)的记录,却会导致在订阅端删除两条满足身份标识等值条件的记录。
(Publication) ------> (Subscription)
|--- f1 ---|--- f2 ---| |--- f1 ---|--- f2 ---|--- f3 ---|
| a | a | | a | a | b |
| a | a | c |FULL模式如何应对重复行问题
PostgreSQL的逻辑复制可以“正确”处理FULL模式下完全相同行的场景。假设有这样一张设计糟糕的表,表中存在多条一模一样的记录。
CREATE TABLE shitty_table(
f1 TEXT,
f2 TEXT,
f3 TEXT
);
INSERT INTO shitty_table VALUES ('a', 'a', 'a'), ('a', 'a', 'a'), ('a', 'a', 'a');在FULL模式下,整行将作为复制标识使用。假设我们在shitty_table上通过ctid扫描作弊,删除了3条一模一样记录中的其中一条。
# SELECT ctid,* FROM shitty_table;
ctid | a | b | c
-------+---+---+---
(0,1) | a | a | a
(0,2) | a | a | a
(0,3) | a | a | a
# DELETE FROM shitty_table WHERE ctid = '(0,1)';
DELETE 1
# SELECT ctid,* FROM shitty_table;
ctid | a | b | c
-------+---+---+---
(0,2) | a | a | a
(0,3) | a | a | a
从逻辑上讲,使用整行作为身份标识,那么订阅端执行以下逻辑,会导致全部3条记录被删除。
DELETE FROM shitty_table WHERE f1 = 'a' AND f2 = 'a' AND f3 = 'a'
但实际情况是,因为PostgreSQL的变更记录以行为单位,这条变更仅会对第一条匹配的记录生效,所以在订阅侧的行为也是删除3行中的1行。在逻辑上与发布端等效。
逻辑复制
逻辑复制(Logical Replication),是一种根据数据对象的 复制标识(Replica Identity)(通常是主键)复制数据对象及其变化的方法。
逻辑复制 这个术语与 物理复制相对应,物理复制使用精确的块地址与逐字节复制,而逻辑复制则允许对复制过程进行精细的控制。
逻辑复制基于 发布(Publication) 与 订阅(Subscription)模型:
- 一个 发布者(Publisher) 上可以有多个发布,一个 订阅者(Subscriber) 上可以有多个 订阅 。
- 一个发布可被多个订阅者订阅,一个订阅只能订阅一个发布者,但可订阅同发布者上的多个不同发布。
针对一张表的逻辑复制通常是这样的:订阅者获取发布者数据库上的一个快照,并拷贝表中的存量数据。一旦完成数据拷贝,发布者上的变更(增删改清)就会实时发送到订阅者上。订阅者会按照相同的顺序应用这些变更,因此可以保证逻辑复制的事务一致性。这种方式有时候又称为 事务性复制(transactional replication)。
逻辑复制的典型用途是:
- 迁移,跨PostgreSQL大版本,跨操作系统平台进行复制。
- CDC,收集数据库(或数据库的一个子集)中的增量变更,在订阅者上为增量变更触发触发器执行定制逻辑。
- 分拆,将多个数据库集成为一个,或者将一个数据库拆分为多个,进行精细的分拆集成与访问控制。
逻辑订阅者的行为就是一个普通的PostgreSQL实例(主库),逻辑订阅者也可以创建自己的发布,拥有自己的订阅者。
如果逻辑订阅者只读,那么不会有冲突。如果会写入逻辑订阅者的订阅集,那么就可能会出现冲突。
发布
一个 发布(Publication) 可以在物理复制主库 上定义。创建发布的节点被称为 发布者(Publisher) 。
一个 发布 是 由一组表构成的变更集合。也可以被视作一个 变更集(change set) 或 复制集(Replication Set) 。每个发布都只能在一个 数据库(Database) 中存在。
发布不同于模式(Schema),不会影响表的访问方式。(表纳不纳入发布,自身访问不受影响)
发布目前只能包含表(即:索引,序列号,物化视图这些不会被发布),每个表可以添加到多个发布中。
除非针对ALL TABLES创建发布,否则发布中的对象(表)只能(通过ALTER PUBLICATION ADD TABLE)被显式添加。
发布可以筛选所需的变更类型:包括INSERT、UPDATE、DELETE 和TRUNCATE的任意组合,类似触发器事件,默认所有变更都会被发布。
一个被纳入发布中的表,必须带有 复制标识(Replica Identity),只有这样才可以在订阅者一侧定位到需要更新的行,完成UPDATE与DELETE操作的复制。
默认情况下,主键 (Primary Key)是表的复制标识,非空列上的唯一索引 (UNIQUE NOT NULL)也可以用作复制标识。
如果没有任何复制标识,可以将复制标识设置为FULL,也就是把整个行当作复制标识。(一种有趣的情况,表中存在多条完全相同的记录,也可以被正确处理)使用FULL模式的复制标识效率很低(因为每一行修改都需要在订阅者上执行全表扫描,很容易把订阅者拖垮),所以这种配置只能是保底方案。使用FULL模式的复制标识还有一个限制,订阅端的表上的复制身份所包含的列,要么与发布者一致,要么比发布者更少。
INSERT操作总是可以无视 复制标识 直接进行(因为插入一条新记录,在订阅者上并不需要定位任何现有记录;而删除和更新则需要通过复制标识 定位到需要操作的记录)。如果一个没有 复制标识 的表被加入到带有UPDATE和DELETE的发布中,后续的UPDATE和DELETE会导致发布者上报错。
表的复制标识模式可以查阅pg_class.relreplident获取,可以通过ALTER TABLE进行修改。
ALTER TABLE tbl REPLICA IDENTITY
{ DEFAULT | USING INDEX index_name | FULL | NOTHING };
管理发布
CREATE PUBLICATION用于创建发布,DROP PUBLICATION用于移除发布,ALTER PUBLICATION用于修改发布。
发布创建之后,可以通过ALTER PUBLICATION动态地向发布中添加或移除表,这些操作都是事务性的。
CREATE PUBLICATION "pg_meta_pub_test_3" FOR TABLE violation_record;
---
CREATE PUBLICATION mypublication FOR TABLE users, departments;
---
CREATE PUBLICATION alltables FOR ALL TABLES;
---
CREATE PUBLICATION insert_only FOR TABLE mydata
WITH (publish = 'insert');CREATE PUBLICATION name
[ FOR TABLE [ ONLY ] table_name [ * ] [, ...]
| FOR ALL TABLES ]
[ WITH ( publication_parameter [= value] [, ... ] ) ]
ALTER PUBLICATION name ADD TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name SET TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name DROP TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name SET ( publication_parameter [= value] [, ... ] )
ALTER PUBLICATION name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
ALTER PUBLICATION name RENAME TO new_name
DROP PUBLICATION [ IF EXISTS ] name [, ...];
publication_parameter 主要包括两个选项:
-
publish:定义要发布的变更操作类型,逗号分隔的字符串,默认为insert, update, delete, truncate。 -
publish_via_partition_root:13后的新选项,如果为真,分区表将使用根分区的复制标识进行逻辑复制。
查询发布
发布可以使用psql元命令\dRp查询。

pg_publication 发布定义表
“pg_publication` 包含了发布的原始定义,每一条记录对应一个发布。

-
puballtables:是否包含所有的表 -
pubinsert|update|delete|truncate是否发布这些操作 -
pubviaroot:如果设置了该选项,任何分区表(叶表)都会使用最顶层的(被)分区表的复制身份。所以可以把整个分区表当成一个表,而不是一系列表进行发布。
pg_publication_tables 发布内容表
postgres=# table pg_publication_tables;pg_publication_tables是由pg_publication,pg_class和pg_namespace拼合而成的视图,记录了发布中包含的表信息。

使用pg_get_publication_tables可以根据订阅的名字获取订阅表的OID
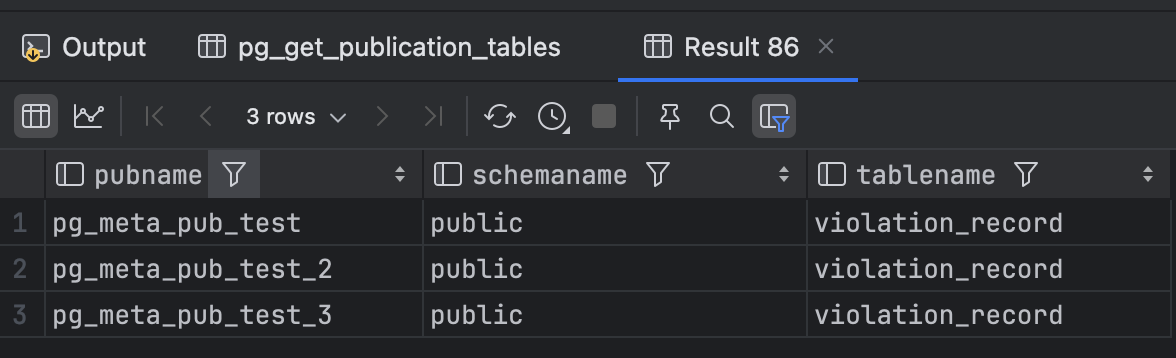
SELECT * FROM pg_get_publication_tables('pg_meta_pub_test_3');
SELECT p.pubname,
n.nspname AS schemaname,
c.relname AS tablename
FROM pg_publication p
JOIN LATERAL (
SELECT relid
FROM pg_get_publication_tables(p.pubname::text)
) gpt ON true
JOIN pg_class c ON c.oid = gpt.relid
JOIN pg_namespace n ON n.oid = c.relnamespace;获取所有表的逻辑复制信息
pg_publication_rel 发布内容表
同时,pg_publication_rel 也提供类似的信息,但采用的是多对多的OID对应视角,包含的是原始数据。
select * from pg_publication_rel;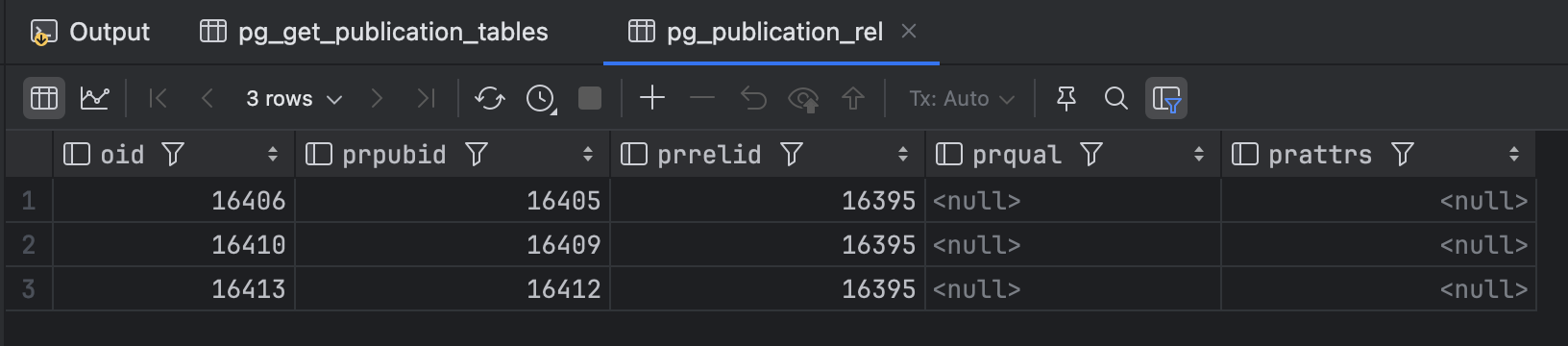
这两者的区别特别需要注意:当针对ALL TABLES发布时,pg_publication_rel中不会有具体表的OID,但是在pg_publication_tables中可以查询到实际纳入逻辑复制的表列表。所以通常应当以pg_publication_tables为准。
创建订阅时,数据库会先修改pg_publication目录,然后将发布表的信息填入pg_publication_rel。
订阅
订阅(Subscription) 是逻辑复制的下游。定义订阅的节点被称为 订阅者(Subscriber) 。
订阅定义了:如何连接到另一个数据库,以及需要订阅目标发布者上的哪些发布。
逻辑订阅者的行为与一个普通的PostgreSQL实例(主库)无异,逻辑订阅者也可以创建自己的发布,拥有自己的订阅者。
每个订阅者,都会通过一个 复制槽(Replication) 来接收变更,在初始数据复制阶段,可能会需要更多的临时复制槽。
逻辑复制订阅可以作为同步复制的备库,备库的名字默认就是订阅的名字,也可以通过在连接信息中设置application_name来使用别的名字。
只有超级用户才可以用pg_dump转储订阅的定义,因为只有超级用户才可以访问pg_subscription视图,普通用户尝试转储时会跳过并打印警告信息。
逻辑复制不会复制DDL变更,因此发布集中的表必须已经存在于订阅端上。只有普通表上的变更会被复制,视图、物化视图、序列号,索引这些都不会被复制。
发布与订阅端的表是通过完整限定名(如public.table)进行匹配的,不支持把变更复制到一个名称不同的表上。
发布与订阅端的表的列也是通过名称匹配的。列的顺序无关紧要,数据类型也不一定非得一致,只要两个列的文本表示兼容即可,即数据的文本表示可以转换为目标列的类型。订阅端的表可以包含有发布端没有的列,这些新列都会使用默认值填充。
管理订阅
CREATE SUBSCRIPTION用于创建订阅,DROP SUBSCRIPTION用于移除订阅,ALTER SUBSCRIPTION用于修改订阅。
订阅创建之后,可以通过ALTER SUBSCRIPTION 随时暂停与恢复订阅。
移除并重建订阅会导致同步信息丢失,这意味着相关数据需要重新进行同步。
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name CONNECTION 'conninfo'
ALTER SUBSCRIPTION name SET PUBLICATION publication_name [, ...] [ WITH ( set_publication_option [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name REFRESH PUBLICATION [ WITH ( refresh_option [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name ENABLE
ALTER SUBSCRIPTION name DISABLE
ALTER SUBSCRIPTION name SET ( subscription_parameter [= value] [, ... ] )
ALTER SUBSCRIPTION name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
ALTER SUBSCRIPTION name RENAME TO new_name
DROP SUBSCRIPTION [ IF EXISTS ] name;
subscription_parameter定义了订阅的一些选项,包括:
-
copy_data(bool):复制开始后,是否拷贝数据,默认为真 -
create_slot(bool):是否在发布者上创建复制槽,默认为真 -
enabled(bool):是否启用该订阅,默认为真 -
connect(bool):是否尝试连接到发布者,默认为真,置为假会把上面几个选项强制设置为假。 -
synchronous_commit(bool):是否启用同步提交,向主库上报自己的进度信息。 -
slot_name:订阅所关联的复制槽名称,设置为空会取消订阅与复制槽的关联。
管理复制槽
每个活跃的订阅都会通过复制槽 从远程发布者接受变更。
通常这个远端的复制槽是自动管理的,在CREATE SUBSCRIPTION时自动创建,在DROP SUBSCRIPTION时自动删除。
在特定场景下,可能需要分别操作订阅与底层的复制槽:
- 创建订阅时,所需的复制槽已经存在。则可以通过
create_slot = false关联已有复制槽。 - 创建订阅时,远端不可达或状态不明朗,则可以通过
connect = false不访问远程主机,pg_dump就是这么做的。这种情况下,您必须在远端手工创建复制槽后,才能在本地启用该订阅。 -
移除订阅时,需要保留复制槽。这种情况通常是订阅者要搬到另一台机器上去,希望在那里重新开始订阅。这种情况下需要先通过
ALTER SUBSCRIPTION解除订阅与复制槽点关联 -
移除订阅时,远端不可达。这种情况下,需要在删除订阅之前使用
ALTER SUBSCRIPTION解除复制槽与订阅的关联。如果远端实例不再使用那么没事,然而如果远端实例只是暂时不可达,那就应该手动删除其上的复制槽;否则它将继续保留WAL,并可能导致磁盘撑爆。
订阅查询
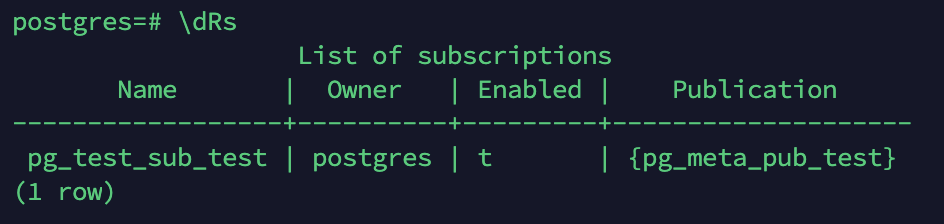
订阅可以使用psql元命令\dRs查询。
pg_subscription 订阅定义表
每一个逻辑订阅都会有一条记录,注意这个视图是跨数据库集簇范畴的,每个数据库中都可以看到整个集簇中的订阅信息。
只有超级用户才可以访问此视图,因为里面包含有明文密码(连接信息)。
SELECT * FROM pg_subscription;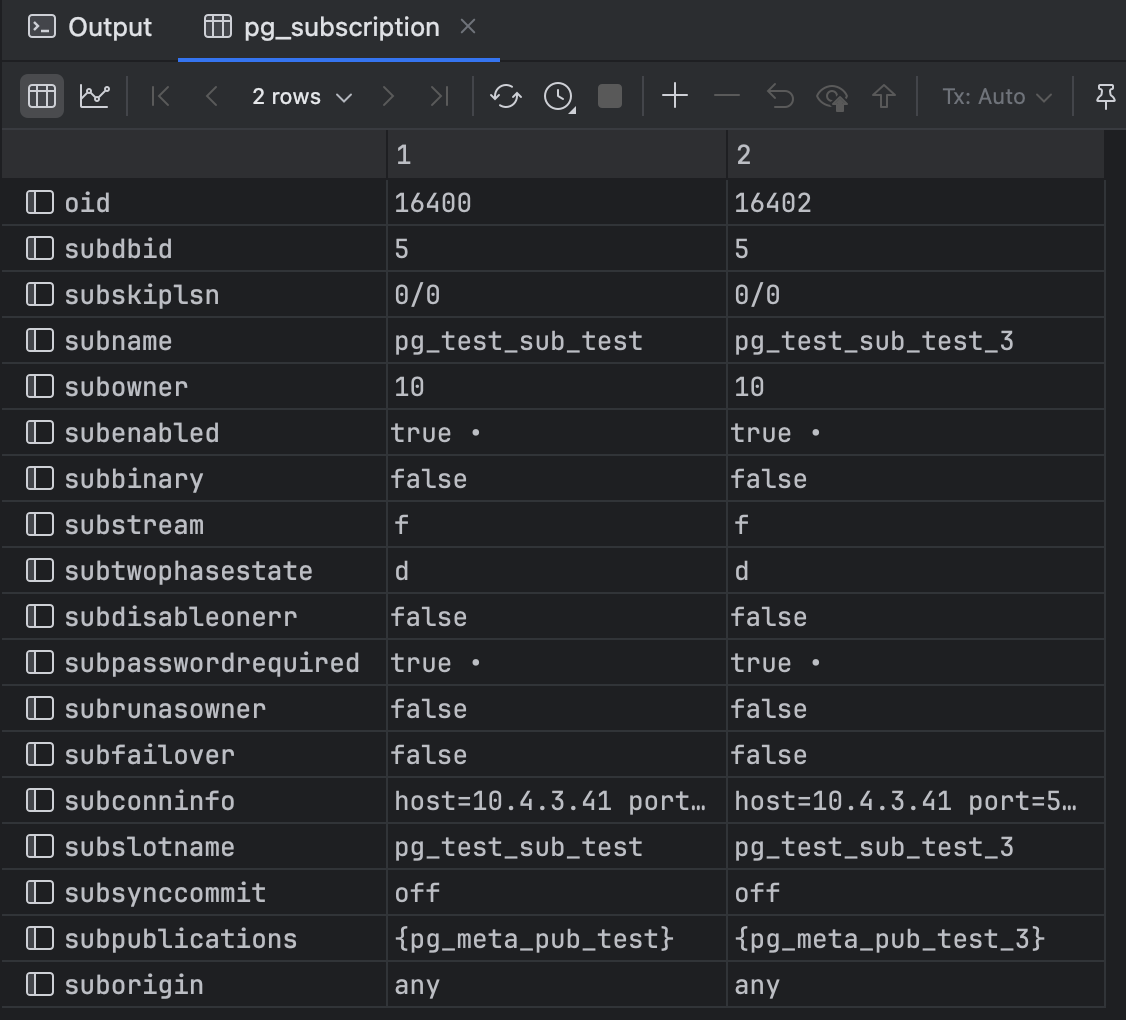
这将返回所有订阅的详细信息,包括但不限于:
-
subname:订阅的名称。 -
subenabled:订阅是否启用。 -
subconninfo:连接到发布者的连接字符串。 -
subslotname:用于复制的复制槽名称。 -
subpublications:发布者上订阅的发布列表。 -
suboptions:订阅的选项列表。
pg_subscription_rel 订阅内容表
pg_subscription_rel 记录了每张处于订阅中的表的相关信息,包括状态与进度。
-
srrelid订阅中关系的OID -
srsubstate,订阅中关系的状态:i初始化中,d拷贝数据中,s同步已完成,r正常复制中。 -
srsublsn,当处于i|d状态时为空,当处于s|r状态时,远端的LSN位置。
SELECT * FROM pg_subscription_rel;
创建订阅时
当一个新的订阅创建时,会依次执行以下操作:
- 将发布的信息存入
pg_subscription目录中,包括连接信息,复制槽,发布名称,一些配置选项等。 - 连接至发布者,检查复制权限,(注意这里不会检查对应发布是否存在),
- 创建逻辑复制槽:
pg_create_logical_replication_slot(name, 'pgoutput') - 将复制集中的表注册到订阅端的
pg_subscription_rel目录中。 - 执行初始快照同步,注意订阅测表中的原有数据不会被删除。
复制冲突
逻辑复制的行为类似于正常的DML操作,即使数据在用户节点上的本地发生了变化,数据也会被更新。如果复制来的数据违反了任何约束,复制就会停止,这种现象被称为 冲突(Conflict) 。
当复制UPDATE或DELETE操作时,缺失数据(即要更新/删除的数据已经不存在)不会产生冲突,此类操作直接跳过。
冲突会导致错误,并中止逻辑复制,逻辑复制管理进程会以5秒为间隔不断重试。冲突不会阻塞订阅端对复制集中表上的SQL。关于冲突的细节可以在用户的服务器日志中找到,冲突必须由用户手动解决。
日志中可能出现的冲突
| 冲突模式 | 复制进程 | 输出日志 |
|---|---|---|
| 缺少UPDATE/DELETE对象 | 继续 | 不输出 |
| 表/行锁等待 | 等待 | 不输出 |
| 违背主键/唯一/Check约束 | 中止 | 输出 |
| 目标表不存在/目标列不存在 | 中止 | 输出 |
| 无法将数据转换为目标列类型 | 中止 | 输出 |
解决冲突的方法,可以是改变订阅侧的数据,使其不与进入的变更相冲突,或者跳过与现有数据冲突的事务。
使用订阅对应的node_name与LSN位置调用函数pg_replication_origin_advance()可以跳过事务,pg_replication_origin_status系统视图中可以看到当前ORIGIN的位置。
局限性
逻辑复制目前有以下限制,或者说功能缺失。这些问题可能会在未来的版本中解决。
数据库模式和DDL命令不会被复制。存量模式可以通过pg_dump --schema-only手动复制,增量模式变更需要手动保持同步(发布订阅两边的模式不需要绝对相同不需要两边的模式绝对相同)。逻辑复制对于对在线DDL变更仍然可靠:在发布数据库中执行DDL变更后,复制的数据到达订阅者但因为表模式不匹配而导致复制出错停止,订阅者的模式更新后复制会继续。在许多情况下,先在订阅者上执行变更可以避免中间的错误。
序列号数据不会被复制。序列号所服务的标识列与SERIAL类型里面的数据作为表的一部分当然会被复制,但序列号本身仍会在订阅者上保持为初始值。如果订阅者被当成只读库使用,那么通常没事。然而如果打算进行某种形式的切换或Failover到订阅者数据库,那么需要将序列号更新为最新的值,要么通过从发布者复制当前数据(也许可以使用pg_dump -t *seq*),要么从表本身的数据内容确定一个足够高的值(例如max(id)+1000000)。否则如果在新库执行获取序列号作为身份的操作时,很可能会产生冲突。
逻辑复制支持复制TRUNCATE命令,但是在TRUNCATE由外键关联的一组表时需要特别小心。当执行TRUNCATE操作时,发布者上与之关联的一组表(通过显式列举或级连关联)都会被TRUNCATE,但是在订阅者上,不在订阅集中的表不会被TRUNCATE。这样的操作在逻辑上是合理的,因为逻辑复制不应该影响到复制集之外的表。但如果有一些不在订阅集中的表通过外键引用订阅集中被TRUNCATE的表,那么TRUNCATE操作就会失败。
大对象不会被复制
只有表能被复制(包括分区表),尝试复制其他类型的表会导致错误(视图,物化视图,外部表,Unlogged表)。具体来说,只有在pg_class.relkind = 'r'的表才可以参与逻辑复制。
复制分区表时默认按子表进行复制。默认情况下,变更是按照分区表的叶子分区触发的,这意味着发布上的每一个分区子表都需要在订阅上存在(当然,订阅者上的这个分区子表不一定是一个分区子表,也可能本身就是一个分区母表,或者一个普通表)。发布可以声明要不要使用分区根表上的复制标识取代分区叶表上的复制标识,这是PG13提供的新功能,可以在创建发布时通过publish_via_partition_root 选项指定。
触发器的行为表现有所不同。行级触发器会触发,但UPDATE OF cols类型的触发器不触发。而语句级触发器只会在初始数据拷贝时触发。
日志行为不同。即使设置log_statement = 'all',日志中也不会记录由复制产生的SQL语句。
双向复制需要极其小心:互为发布与订阅是可行的,只要两遍的表集合不相交即可。但一旦出现表的交集,就会出现WAL无限循环。
同一实例内的复制:同一个实例内的逻辑复制需要特别小心,必须手工创建逻辑复制槽,并在创建订阅时使用已有的逻辑复制槽,否则会卡死。
只能在主库上进行:目前不支持从物理复制的从库上进行逻辑解码,也无法在从库上创建复制槽,所以从库无法作为发布者。但这个问题可能会在未来解决。
架构
逻辑复制始于获取发布者数据库上的快照,基于此快照拷贝表上的存量数据。一旦拷贝完成,发布者上的变更(增删改等)就会实时发送到订阅者上。
逻辑复制采用与物理复制类似的架构,是通过一个walsender和apply进程实现的。发布端端walsender进程会加载逻辑解码插件(pgoutput),并开始逻辑解码WAL日志。逻辑解码插件(Logical Decoding Plugin) 会读取WAL中的变更,按照发布的定义筛选变更,将变更转变为特定的形式,以逻辑复制协议传输出去。数据会按照流复制协议传输至订阅者一侧的apply进程,该进程会在接收到变更时,将变更映射至本地表上,然后按照事务顺序重新应用这些变更。
订阅侧的表在初始化与拷贝数据期间,会由一种特殊的apply进程负责。这个进程会创建它自己的临时复制槽,并拷贝表中的存量数据。
一旦数据拷贝完成,这张表会进入到同步模式(pg_subscription_rel.srsubstate = 's'),同步模式确保了 主apply进程 可以使用标准的逻辑复制方式应用拷贝数据期间发生的变更。一旦完成同步,表复制的控制权会转交回 主apply进程,恢复正常的复制模式。
逻辑复制的发布端会针对来自订阅端端每一条连接,创建一个对应的 walsender 进程,发送解码的WAL日志。
逻辑复制的同步提交是通过Backend与Walsender之间的SIGUSR1通信完成的。
逻辑解码的临时数据会落盘为本地日志快照。当walsender接收到walwriter发送的SIGUSR1信号时,就会读取WAL日志并生成相应的逻辑解码快照。当传输结束时会删除这些快照。
文件地址为:$PGDATA/pg_logical/snapshots/{LSN Upper}-{LSN Lower}.snap
监控
逻辑复制采用与物理流复制类似的架构,所以监控一个逻辑复制的发布者节点与监控一个物理复制主库差别不大。
订阅者的监控信息可以通过pg_stat_subscription视图获取。
pg_stat_subscription 订阅统计表
每个活跃订阅都会在这个视图中有至少一条 记录,即Main Worker(负责应用逻辑日志)。
Main Worker的relid = NULL,如果有负责初始数据拷贝的进程,也会在这里有一行记录,relid为负责拷贝数据的表。
SELECT * FROM pg_stat_subscription;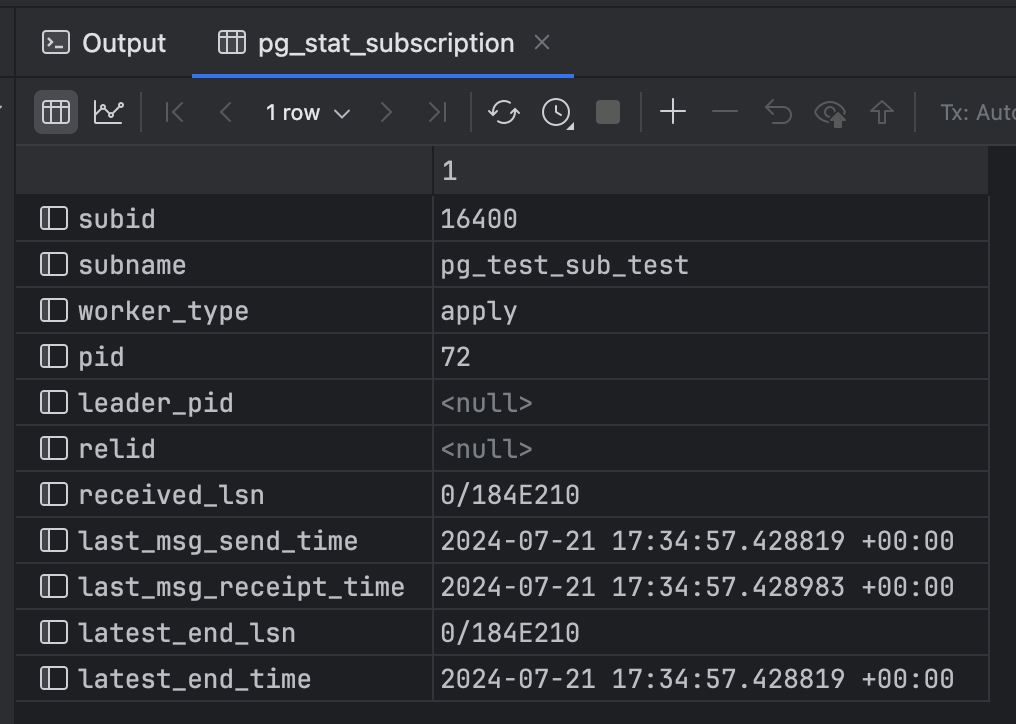
-
received_lsn:最近收到的日志位置。 -
lastest_end_lsn:最后向walsender回报的LSN位置,即主库上的confirmed_flush_lsn。不过这个值更新不太勤快,
通常情况下一个活跃的订阅会有一个apply进程在运行,被禁用的订阅或崩溃的订阅则在此视图中没有记录。在初始同步期间,被同步的表会有额外的工作进程记录。
pg_replication_slot 复制槽

复制槽视图中同时包含了逻辑复制槽与物理复制槽。逻辑复制槽点主要特点是:
-
plugin字段不为空,标识了使用的逻辑解码插件,逻辑复制默认使用pgoutput插件。 -
slot_type = logical,物理复制的槽类型为physical。 -
datoid与database字段不为空,因为物理复制与集簇关联,而逻辑复制与数据库关联。
逻辑订阅者也会作为一个标准的 复制从库 ,出现于 pg_stat_replication 视图中。
pg_replication_origin 复制源
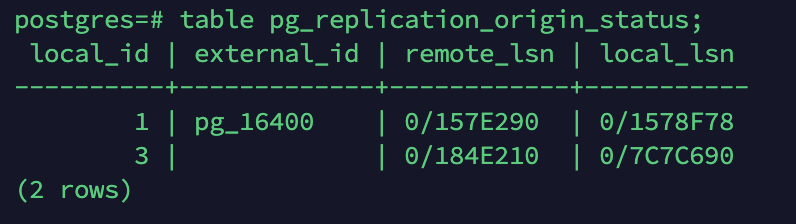
-
local_id:复制源在本地的ID,2字节高效表示。 -
external_id:复制源的ID,可以跨节点引用。 -
remote_lsn:源端最近的提交位点。 -
local_lsn:本地已经持久化提交记录的LSN
检测复制冲突
最稳妥的检测方法总是从发布与订阅两侧的日志中检测。当出现复制冲突时,发布测上可以看见复制连接中断
LOG: terminating walsender process due to replication timeout
LOG: starting logical decoding for slot "pg_test_sub"
DETAIL: streaming transactions committing after 0/xxxxx, reading WAL from 0/xxxx
而订阅端则可以看到复制冲突的具体原因,例如:
logical replication worker PID 4585 exited with exit code 1
ERROR: duplicate key value violates unique constraint "pgbench_tellers_pkey","Key (tid)=(9) already exists.",,,,"COPY pgbench_tellers, line 31",,,,"","logical replication worker"
此外,一些监控指标也可以反映逻辑复制的状态:
例如:pg_replication_slots.confirmed_flush_lsn 长期落后于pg_cureent_wal_lsn。或者pg_stat_replication.flush_ag/write_lag 有显著增长。
安全
参与订阅的表,其Ownership与Trigger权限必须控制在超级用户所信任的角色手中(否则修改这些表可能导致逻辑复制中断)。
在发布节点上,如果不受信任的用户具有建表权限,那么创建发布时应当显式指定表名而非通配ALL TABLES。也就是说,只有当超级用户信任所有 可以在发布或订阅侧具有建表(非临时表)权限的用户时,才可以使用FOR ALL TABLES。
用于复制连接的用户必须具有REPLICATION权限(或者为SUPERUSER)。如果该角色缺少SUPERUSER与BYPASSRLS,发布者上的行安全策略可能会被执行。如果表的属主在复制启动之后设置了行级安全策略,这个配置可能会导致复制直接中断,而不是策略生效。该用户必须拥有LOGIN权限,而且HBA规则允许其访问。
为了能够复制初始表数据,用于复制连接的角色必须在已发布的表上拥有SELECT权限(或者属于超级用户)。
创建发布,需要在数据库中的CREATE权限,创建一个FOR ALL TABLES的发布,需要超级用户权限。
将表加入到发布中,用户需要具有表的属主权限。
创建订阅需要超级用户权限,因为订阅的apply进程在本地数据库中以超级用户的权限运行。
权限只会在建立复制连接时检查,不会在发布端读取每条变更记录时重复检查,也不会在订阅端应用每条记录时检查。
配置选项
逻辑复制需要一些配置选项才能正常工作。
在发布者一侧,wal_level 必须设置为logical,max_replication_slots最少需要设为 订阅的数量+用于表数据同步的数量。max_wal_senders最少需要设置为max_replication_slots + 为物理复制保留的数量,
在订阅者一侧,也需要设置max_replication_slots,max_replication_slots,最少需要设为订阅数。
max_logical_replication_workers最少需要配置为订阅的数量,再加上一些用于数据同步的工作进程数。
此外,max_worker_processes需要相应调整,至少应当为max_logical_replication_worker + 1。注意一些扩展插件和并行查询也会从工作进程的池子中获取连接使用。
配置参数样例
64核机器,1~2个发布与订阅,最多6个同步工作进程,最多8个物理从库的场景,一种样例配置如下所示:
首先决定Slot数量,2个订阅,6个同步工作进程,8个物理从库,所以配置为16。Sender = Slot + Physical Replica = 24。
同步工作进程限制为6,2个订阅,所以逻辑复制的总工作进程设置为8。
wal_level: logical # logical
max_worker_processes: 64 # default 8 -> 64, set to CPU CORE 64
max_parallel_workers: 32 # default 8 -> 32, limit by max_worker_processes
max_parallel_maintenance_workers: 16 # default 2 -> 16, limit by parallel worker
max_parallel_workers_per_gather: 0 # default 2 -> 0, disable parallel query on OLTP instance
# max_parallel_workers_per_gather: 16 # default 2 -> 16, enable parallel query on OLAP instance
max_wal_senders: 24 # 10 -> 24
max_replication_slots: 16 # 10 -> 16
max_logical_replication_workers: 8 # 4 -> 8, 6 sync worker + 1~2 apply worker
max_sync_workers_per_subscription: 6 # 2 -> 6, 6 sync worker逻辑复制示例
首先设置发布侧的配置选项 wal_level = logical,该参数需要重启方可生效,其他参数的默认值都不影响使用。
逻辑复制的用户需要具有SELECT权限,可以单独创建一个用户来测试
-- 创建一个名为 readonly_replicator 的新用户,密码为 '123456',
CREATE USER readonly_replicator WITH REPLICATION ENCRYPTED PASSWORD '123456';
-- 授予 USAGE 权限在 public schema 上
GRANT USAGE ON SCHEMA public TO readonly_replicator;
-- 授予 SELECT 权限在 public schema 下的所有表上
GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly_replicator;
-- 为 future tables 设置默认 SELECT 权限
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO readonly_replicator;然后在发布侧的数据库中执行:
CREATE PUBLICATION "pg_meta_pub_test_3" FOR TABLE violation_record;然后在订阅测数据库中执行:
CREATE SUBSCRIPTION pg_test_sub_test_3
CONNECTION 'host=10.4.3.41 port=54312 dbname=postgres user=readonly_replicator password=123456pp1'
PUBLICATION pg_meta_pub_test_3;以上配置即会开始复制,首先复制表的初始数据,然后开始同步增量变更。
复制流程
逻辑复制的订阅创建后,如果一切正常,逻辑复制会自动开始,针对每张订阅中的表执行复制状态机逻辑。
stateDiagram-v2 [*] –> init : 表被加入到订阅集中 init –> data : 开始同步表的初始快照 data –> sync : 存量数据同步完成 sync –> ready : 同步期间的增量变更应用完毕,进入就绪状态
当所有的表都完成复制,进入r(ready)状态时,逻辑复制的存量同步阶段便完成了,发布端与订阅端整体进入同步状态。
因此从逻辑上讲,存在两种状态机:表级复制小状态机与全局复制大状态机。每一个Sync Worker负责一张表上的小状态机,而一个Apply Worker负责一条逻辑复制的大状态机。
逻辑复制状态机
逻辑复制有两种Worker:Sync与Apply。
逻辑复制在逻辑上分为两个部分:每张表独自进行复制,当复制进度追赶至最新位置时,由当创建或刷新订阅时,表会被加入到 订阅集 中,每一张订阅集中的表都会在pg_subscription_rel视图中有一条对应纪录,展示这张表当前的复制状态。刚加入订阅集的表初始状态为i,即initialize,初始状态。
如果订阅的copy_data选项为真(默认情况),且工作进程池中有空闲的Worker,PostgreSQL会为这张表分配一个同步工作进程,同步这张表上的存量数据,此时表的状态进入d,即拷贝数据中。对表做数据同步类似于对数据库集群进行basebackup,Sync Worker会在发布端创建临时的复制槽,获取表上的快照并通过COPY完成基础数据同步。
当表上的基础数据拷贝完成后,表会进入sync模式,即数据同步,同步进程会追赶同步过程中发生的增量变更。当追赶完成时,同步进程会将这张表标记为r(ready)状态,转交逻辑复制主Apply进程管理变更,表示这张表已经处于正常复制中。
创建订阅后,首先必须监控 发布端与订阅端两侧的数据库日志,确保没有错误产生。
数据同步(d)阶段可能需要花费一些时间,取决于网卡,网络,磁盘,表的大小与分布,逻辑复制的同步worker数量等因素。
作为参考,1TB的数据库,20张表,包含有250GB的大表,双万兆网卡,在6个数据同步worker的负责下大约需要6~8小时完成复制。
在数据同步过程中,每个表同步任务都会源端库上创建临时的复制槽。请确保逻辑复制初始同步期间不要给源端主库施加过大的不必要写入压力,以免WAL撑爆磁盘。
发布侧的 pg_stat_replication,pg_replication_slots,订阅端的pg_stat_subscription,pg_subscription_rel提供了逻辑复制状态的相关信息,需要关注。
SELECT subname, json_object_agg(srsubstate, cnt) FROM
pg_subscription s JOIN
(SELECT srsubid, srsubstate, count(*) AS cnt FROM pg_subscription_rel
GROUP BY srsubid, srsubstate) sr
ON s.oid = sr.srsubid GROUP BY subname;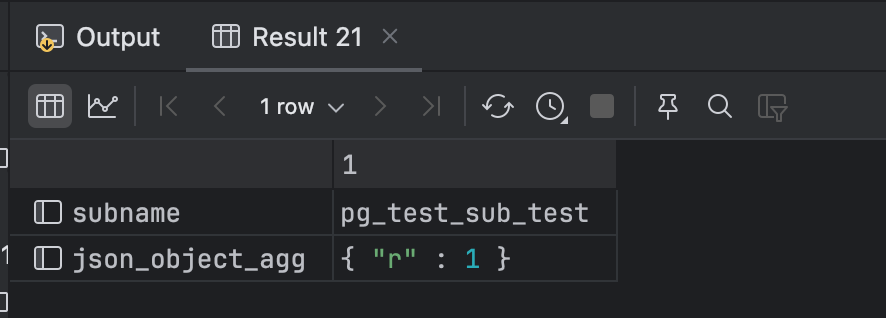
可以使用以下SQL确认订阅中表的状态,如果所有表的状态都显示为r,则表示逻辑复制已经成功建立,订阅端可以用于切换。
当然,最好的方式始终是通过监控系统来跟踪复制状态。
可能遇到的问题
将表加入已有发布
CREATE TABLE t_normal(id BIGSERIAL PRIMARY KEY,v TIMESTAMP); -- 常规表,带有主键
ALTER PUBLICATION pg_meta_pub ADD TABLE t_normal; -- 将新创建的表加入到发布中
如果这张表在订阅端已经存在,那么即可进入正常的逻辑复制流程:i -> d -> s -> r。
如果向发布加入一张订阅端不存在的表?那么新订阅将会无法创建。已有订阅无法刷新,但可以保持原有复制继续进行。
如果订阅还不存在,那么创建的时候会报错无法进行:在订阅端找不到这张表。如果订阅已经存在,无法执行刷新命令:
ALTER SUBSCRIPTION pg_test_sub REFRESH PUBLICATION;如果新加入的表没有任何写入,已有的复制关系不会发生变化,一旦新加入的表发生变更,会立即产生复制冲突。
将表从发布中移除
ALTER PUBLICATION pg_meta_pub ADD TABLE t_normal;从发布移除后,订阅端不会有影响。效果上就是这张表的变更似乎消失了。执行订阅刷新后,这张表会从订阅集中被移除。
另一种情况是重命名发布/订阅中的表,在发布端执行表重命名时,发布端的发布集会立刻随之更新。尽管订阅集中的表名不会立刻更新,但只要重命名后的表发生任何变更,而订阅端没有对应的表,那么会立刻出现复制冲突。
同理,在订阅端重命名表时,订阅的关系集也会刷新,但因为发布端的表没有对应物了。如果这张表没有变更,那么一切照旧,一旦发生变更,立刻出现复制冲突。
直接在发布端DROP此表,会顺带将该表从发布中移除,不会有报错或影响。但直接在订阅端DROP表则可能出现问题,DROP TABLE时该表也会从订阅集中被移除。如果发布端此时这张表上仍有变更产生,则会导致复制冲突。
所以,删表应当先在发布端进行,再在订阅端进行。
两端列定义不一致
发布与订阅端的表的列通过名称匹配,列的顺序无关紧要。
订阅端表的列更多,通常不会有什么影响。多出来的列会被填充为默认值(通常是NULL)。
特别需要注意的是,如果要为多出来的列添加NOT NULL约束,那么一定要配置一个默认值,否则变更发生时违反约束会导致复制冲突。
订阅端如果列要比发布端更少,会产生复制冲突。在发布端添加一个新列并不会立刻导致复制冲突,随后的第一条变更将导致复制冲突。
所以在执行加列DDL变更时,可以先在订阅者上先执行,然后在发布端进行。
列的数据类型不需要完全一致,只要两个列的文本表示兼容即可,即数据的文本表示可以转换为目标列的类型。
这意味着任何类型都能转换成TEXT类型,BIGINT 只要不出错,也可以转换成INT,不过一旦溢出,还是会出现复制冲突。
复制身份与索引的正确配置
表上的复制标识配置,与表上有没有索引是两件独立的事。尽管各种排列组合都是可能的,然而在实际使用中只有三种可行的情况,其他情况都无法正常完成逻辑复制的功能(如果不报错,通常也是侥幸)
- 表上有主键,使用默认的
default复制标识,不需要额外配置。 - 表上没有主键,但是有非空唯一索引,显式配置
index复制标识。 - 表上既没有主键也没有非空唯一索引,显式配置
full复制标识(运行效率低,仅作为兜底方案)
| 复制身份模式\表上的约束 | 主键(p) | 非空唯一索引(u) | 两者皆无(n) |
|---|---|---|---|
| default | 有效 | x | x |
| index | x | 有效 | x |
| full | 低效 | 低效 | 低效 |
| nothing | x | x | x |
在所有情况下,INSERT都可以被正常复制。x代表DELETE|UPDATE所需关键信息缺失无法正常完成。
最好的方式当然是事前修复,为所有的表指定主键,以下查询可以用于找出缺失主键或非空唯一索引的表:
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name,
con.ri AS keys,
CASE relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index' END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON c.relnamespace = n.oid,
LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r'
AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2, 3;
复制身份为nothing的表可以加入到发布中,但在发布者上对其执行UPDATE|DELETE会直接导致报错。
