阅读完需:约 27 分钟
Java线程
在聊如何绑定之前,先铺垫一个相关的背景知识:Java线程的实现。
都知道 Thread 类的大部分方法都是 native 方法:
在 Java 中一个方法被声明为 native 方法,绝大部分情况下说明这个方法没有或者不能使用平台无关的手段来实现。
说明需要操作的是很底层的东西了,已经脱离了 Java 语言层面的范畴。
抛开 Java 语言这个大前提,实现线程主要是有三种方式:
- 使用内核线程实现(1:1实现)
- 使用用户线程实现(1:N实现)
- 使用用户线程加轻量级进程混合实现(N:M实现)
这三种实现方案,在《深入理解Java虚拟机》的 12.4 小节有详细的描述
你要知道的是虽然有这三种不同的线程模型,但是 Java 作为上层应用,其实是感知不到这三种模型之间的区别的。
JVM 规范里面也没有规定,必须使用哪一种模型。
因为操作系统支持是怎样的线程模型,很大程度上决定了运行在上面的 Java 虚拟机的线程怎样去映射,但是这一点在不同的平台上很难达成一致。
所以JVM 规范里面没有、也不好去规定 Java 线程需要使用哪种线程模型来实现。
类似的问题比如:
JVM中的线程模型是用户级的么?
问题:
JVM的线程模型是用户级线程,对于OS来说JVM就是一个进程,但是用户级线程的问题就是只要一个线程产生了一次系统调用,比如I/O中断,那同一进程内的其他线程都会停止,是这样的么?
首先要理解:传统的用户级线程是什么?
传统的用户级线程(User-Level Threads, ULTs)是由用户空间的线程库来实现和管理的线程模型,操作系统内核对这些线程的存在一无所知。在这种模型中,所有的线程管理工作(如线程的创建、调度、同步等)都是由用户级的线程库来处理的,而不是由操作系统内核来处理。
特点
- 用户空间管理:线程的创建、调度和管理完全在用户空间进行,不需要内核的参与。
- 轻量级:因为不涉及系统调用,用户级线程的操作(如切换、同步)非常快速,开销很小。
- 灵活性:可以根据应用需求定制调度策略,具有较大的灵活性。
优点
- 快速切换:线程切换在用户空间进行,不需要内核态和用户态的上下文切换,因此开销很小。
- 低开销:线程的创建和销毁开销很小,因为不涉及系统调用。
- 可移植性:用户级线程库可以在不同的操作系统上实现,从而提高可移植性。
缺点
- 阻塞问题:如果一个用户级线程在系统调用(如 I/O 操作)中阻塞了,整个进程会被阻塞,因为操作系统只知道这个进程在等待,而不知道进程内还有其他可运行的线程。
- 多核利用率低:操作系统无法感知用户级线程,因此无法在多核处理器上并行调度这些线程,导致无法充分利用多核优势。
- 缺乏操作系统支持:无法利用操作系统提供的一些高级特性,如优先级调度、负载均衡等。
知道什么是传统的用户级线程了,那么再开看看JVM的线程,都知道在JVM中线程是可以利用多核处理器的,可以实现并发操作的,那么这是与用户级线程相违背的。
这里只能针对具体JVM实现来回答,在JVM规范里是没有规定的——具体实现用1:1(内核线程)、N:1(用户态线程)、M:N(混合)模型的任何一种都完全OK。
Java并不暴露出不同线程模型的区别,上层应用是感知不到差异的(只是性能特性会不太一样…)
Java SE最常用的JVM是Oracle/Sun研发的HotSpot VM。在这个JVM的较新版本所支持的所有平台上,它都是使用1:1线程模型的(即每个 Java 线程对应一个操作系统线程,模型实际上是内核级线程模型)——除了Solaris之外
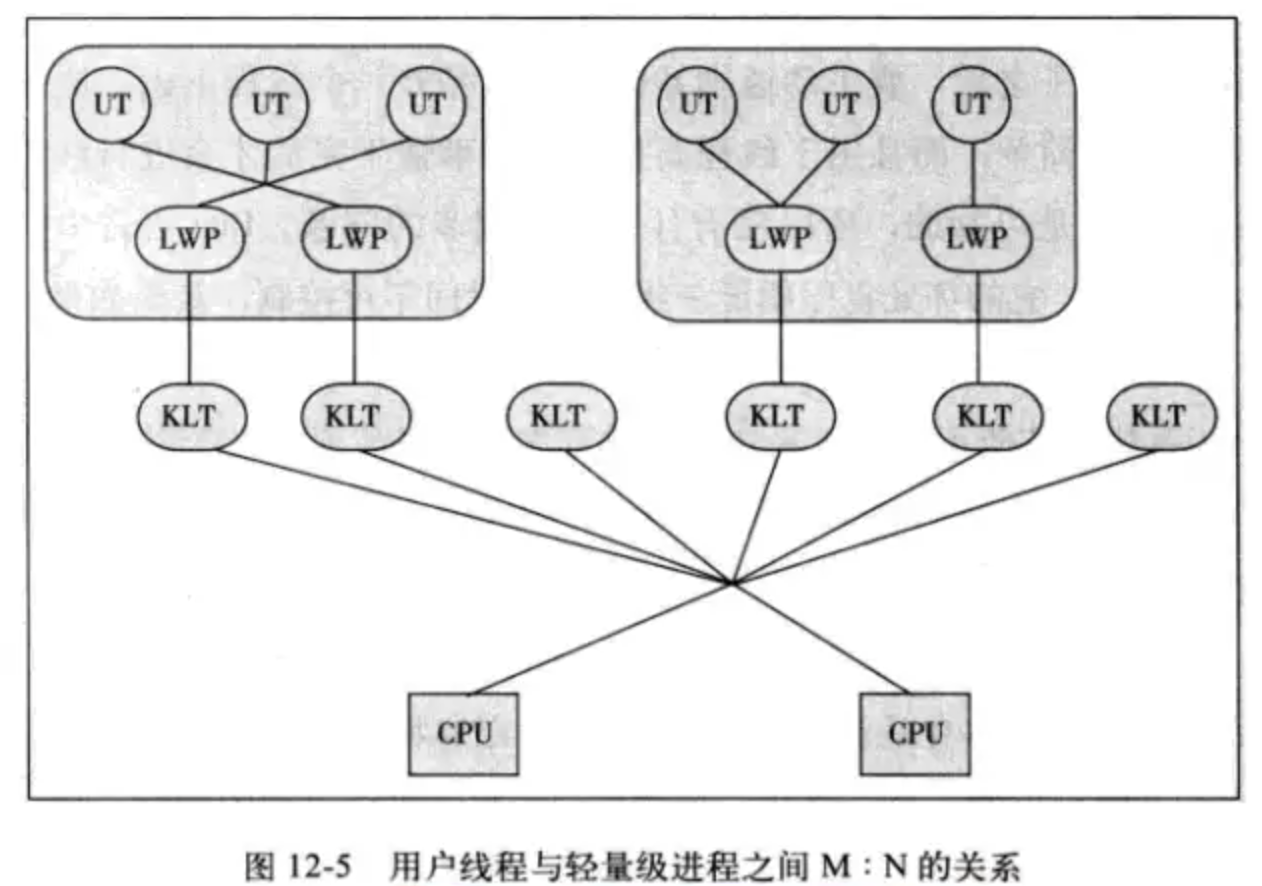
HotSpot VM在Solaris上支持M:N和1:1模型。当前默认是用1:1模型
很多人说“肯定不是用户态线程,不然怎么利用多核”、“多线程优势何在”,这些问题在使用N:1、M:N模型的JVM实现上确实存在
Oracle/Sun的另一个JVM实现,用于Java ME CLDC的CLDC HotSpot Implementation(CLDC-HI)。它支持两种线程模型,默认使用N:1线程模型,所有Java线程都映射到一个内核线程上,是典型的用户态线程模型;它也可以使用一种特殊的混合模型,Java线程仍然全部映射到一个内核线程上,但当Java线程要执行一个阻塞调用时,CLDC-HI会为该调用单独开一个内核线程,并且调度执行其它Java线程,等到那个阻塞调用完成之后再重新调度之前的Java线程继续执行。
所以Java语言的线程,从规范的角度来说是不强制要求任何具体的实现方式的。采用1:1、N:1、M:N模型都可以
平时常用的JVM实现,Oracle/Sun的HotSpot VM,它是用1:1模型来实现Java线程的,也就是说一个Java线程是直接通过一个OS线程来实现的,中间并没有额外的间接结构。而且HotSpot VM自己也不干涉线程的调度,全权交给底下的OS去处理。所以如果OS想把某个线程调度到某个CPU/核上,它就自己弄了。
这个意义上说Java程序跑在HotSpot VM上开多个Java线程,就跟一个C/C++程序开了多线程来跑没有任何两样。
结论是:并不是所有JVM都像HotSpot VM这样总是用1:1模型的,提一下免得给人留下“Java线程就肯定是OS线程”的误解。
回过头来,主要说一下使用内核线程实现(1:1实现)的这个模型。
因为我们用的最多的 HotSpot 虚拟机,就是采用 1:1 模型来实现 Java 线程的。
就是一个 Java 线程是直接映射为一个操作系统原生线程的,中间没有额外的间接结构。HotSpot 虚拟机也不干涉线程的调度,这事全权交给底下的操作系统去做。
顶多就是设置一个线程优先级,操作系统来调度的时候给个建议。
但是何时挂起、唤醒、分配时间片、让那个处理器核心去执行等等这些关于线程生命周期、执行的东西都是操作系统干的。

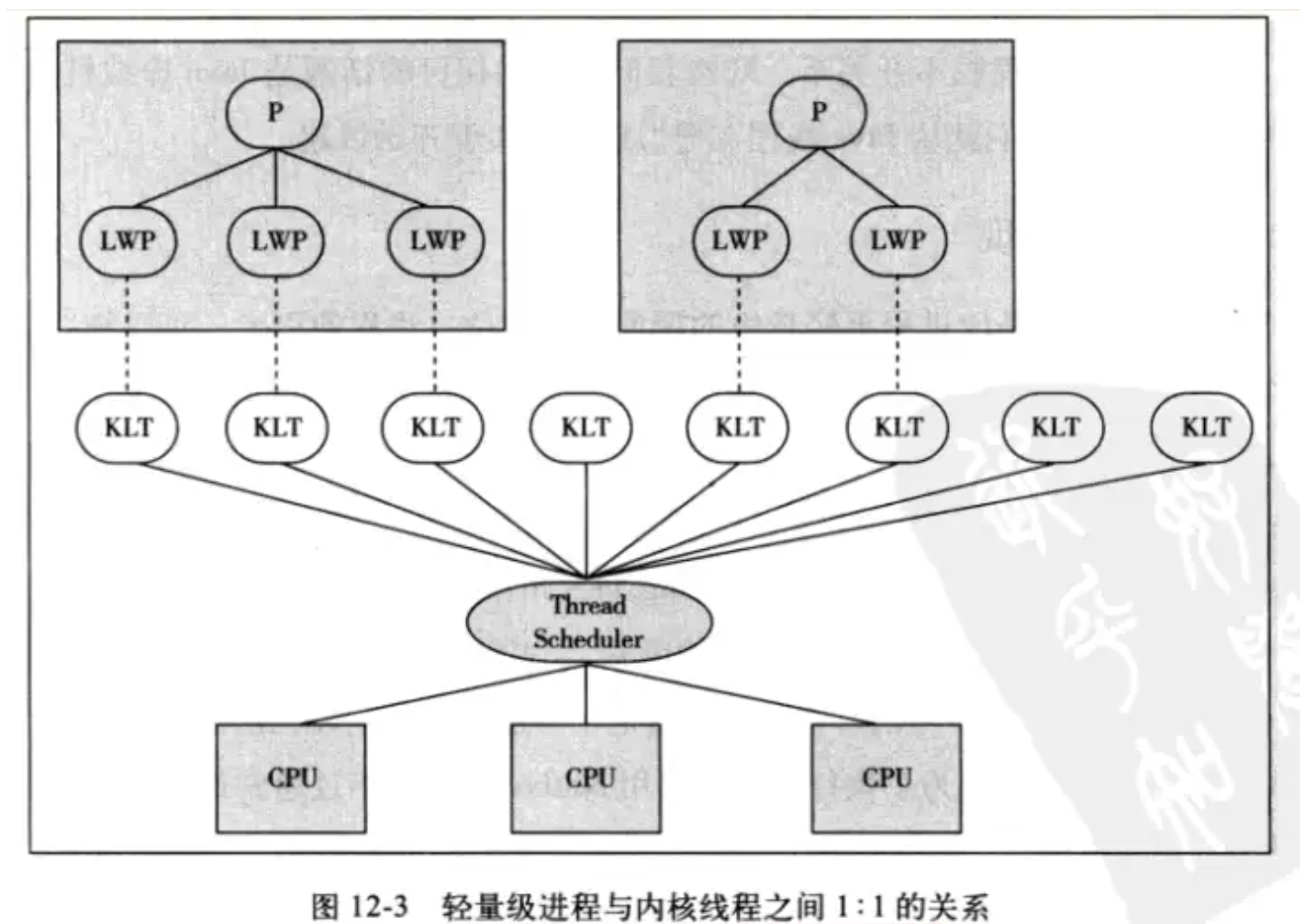
关于 1:1 的线程模型,记住书上的这幅图就行:
- LWP:Light Weight Process 轻量级进程
- KLT:Kernal-Level Thread 内核线程
- UT:User Thread 用户线程
JVM多线程在Linux上是基于LWP(轻量级进程)实现的,如果你代码里用了多线程,用top可以看到多个进程以及每一个进程的CPU消耗,内存消耗等,既然线程是进程,那自然是交给OS去调度的,Linux会把多个线程放到能共享二级缓存的物理核上运行,并进行负载均衡,对应的算法叫SMP,虽然Linux提供CPU绑定的接口,但通常应用程序不会去绑定,交给OS做更高效合理,因为他更了解硬件信息和其他进程信息,能做到更合理的负载均衡,所以在java这种偏应用的上层开发语言谈内核负载均衡没什么意义。
KLT 线程上面都有一个 LWP 与之对应。
LWP 呢?程序一般来说不会直接使用内核线程,而是使用内核线程的一种高级接口,即轻量级进程(LWP),轻量级进程就是我们通常意义上说的线程。
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使其中某一个轻量级进程在系统调用中被阻塞了,也不会影响整个进程继续工作。
但是,轻量级进程也具有它的局限性。
首先,由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。
其次,每个轻量级进程都需要一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
Java-Thread-Affinity
不论从什么角度来说,绑定线程到某个 CPU 上去执行都像是操作系统层面干的事儿。Java 作为高级开发语言,肯定是直接干不了的。需要更加底层的开发语言,Java 通过 JNA 技术去调用。
- 在Linux上的话,可以用taskset来把线程绑在某个指定的核上。
- 在Java层面上,有大佬写了个现成的库来利用taskset绑核:
OpenHFT/Java-Thread-Affinity
https://github.com/OpenHFT/Java-Thread-Affinity
Java-Thread-Affinity 要求首先隔离一些 CPU。
修改内核启动参数isolcpus(如:grub.conf中增加isolcpus=)
打开 grub.conf 文件:sudo nano /boot/grub2/grub.cfg
找到内核启动行:
找到包含 linux 或 linux16 的行,这一行指定了内核启动参数。例如:
linux /vmlinuz-4.18.0-240.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet
添加 isolcpus 参数:
在该行的末尾添加 isolcpus=<cpu-list> 参数,其中 <cpu-list> 是要隔离的 CPU 列表。例如,若要隔离 CPU 0 和 CPU 1,添加如下内容:
linux /vmlinuz-4.18.0-240.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet isolcpus=0,1
保存并退出,更新 GRUB 配置:sudo grub2-mkconfig -o /boot/grub2/grub.cfg
重启系统:sudo reboot
验证 isolcpus 参数:dmesg | grep isolcpus
结合 taskset 使用:在隔离 CPU 后,可以使用 taskset 命令将特定进程绑定到这些 CPU。例如,将进程绑定到 CPU 0 和 CPU 1:
taskset -c 0,1
一旦 CPU 核心被隔离,Linux 调度程序将不会使用该 CPU 核心运行任何用户空间进程。隔离的 CPU 将不会参与负载平衡,也不会在其上运行任何任务,除非明确分配。
要隔离系统上的第 1 和第 3 个 CPU 核心(CPU 编号从 0 开始),请在启动期间将以下内容添加到内核命令行:
isolcpus=1,3
这个项目对应的 Maven 版本还是有好多个的,选择一个兼容系统的依赖
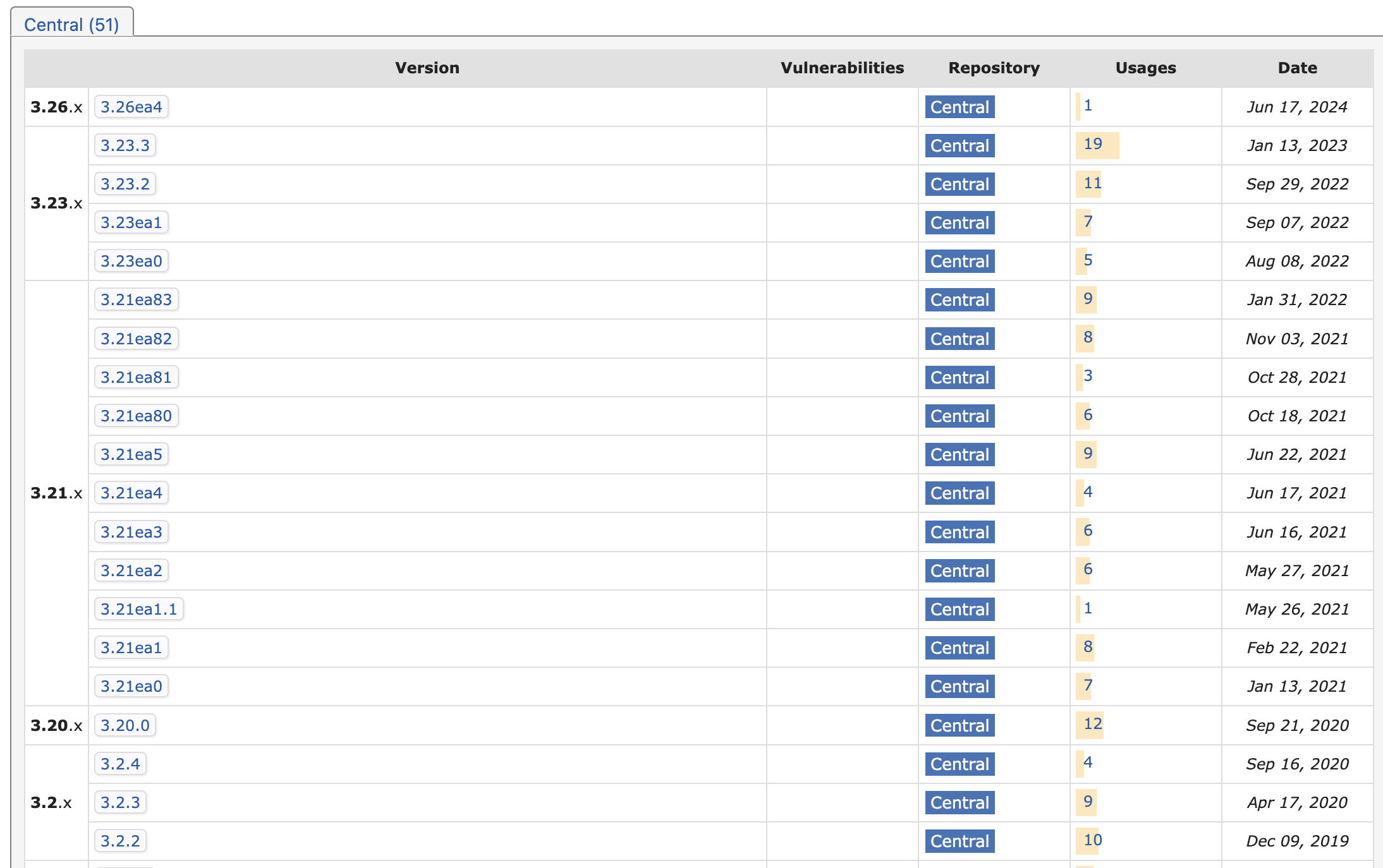
<dependency>
<groupId>net.openhft</groupId>
<artifactId>affinity</artifactId>
<version>3.26ea4</version>
</dependency>
try (final AffinityLock al = AffinityLock.acquireLock()) {
System.out.println("Main locked");
Thread t = new Thread(new Runnable() {
@Override
public void run() {
try (AffinityLock al2 = al.acquireLock(AffinityStrategies.SAME_SOCKET,
AffinityStrategies.ANY)) {
System.out.println("Thread-0 locked");
}
}
});
t.start();
}在这个例子中,库将优先选择与第一个线程位于同一 Socket 上的空闲 CPU,否则它将选择任何空闲的 CPU
// lock one of the last CPUs
try (AffinityLock lock = AffinityLock.acquireLockLastMinus(n)) {
}其中 n 是您想要在其上运行线程的 CPU。
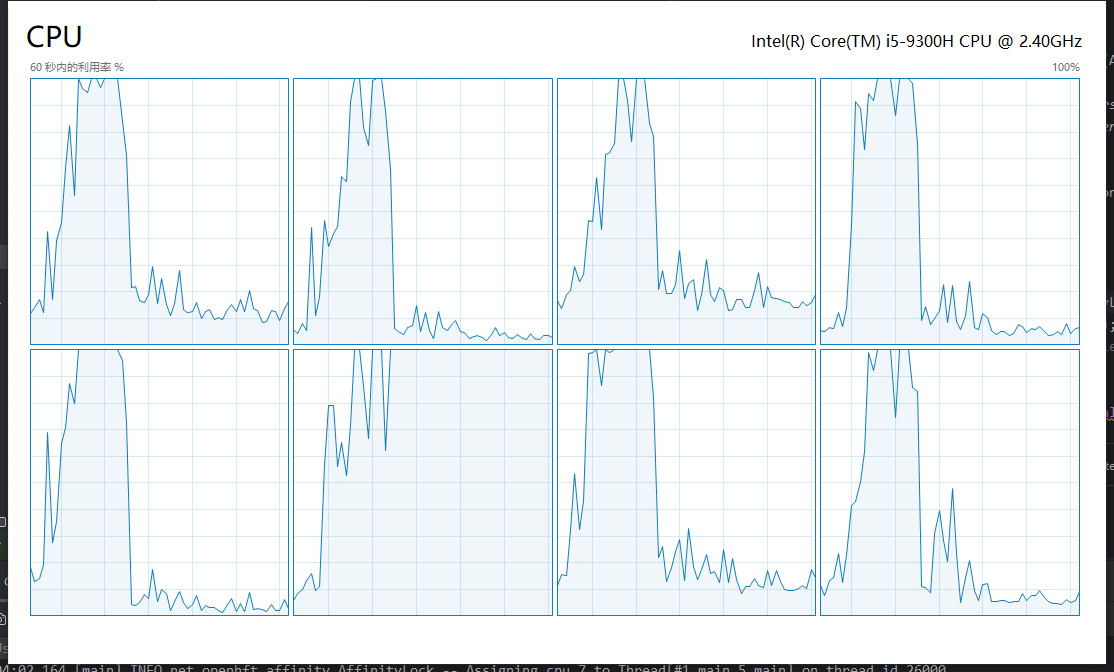
main方法测试程序,在CPU-5上运行,意思就是我要在第 5 个 CPU 线程执行死循环,把 CPU 利用率打到 100%。
public class Affinity {
public static void main(String[] args) {
try (final AffinityLock al = AffinityLock.acquireLock()) {
System.out.println("Main locked");
Thread t = new Thread(new Runnable() {
@Override
public void run() {
try (AffinityLock al2 = al.acquireLock(5)) {
while (true){
}
}
}
});
t.start();
}
}
}
运行的结果,CPU-5果然被打满了
该功能也是有实际应用场景的,属于一直非常极致的性能优化手段吧。
绑定核心之后就可以更好的利用缓存以及减少线程的上下文切换。
很多的库都有这样的绑核操作
disruptor 这个框架的时候,看到它有一个这样的等待策略:
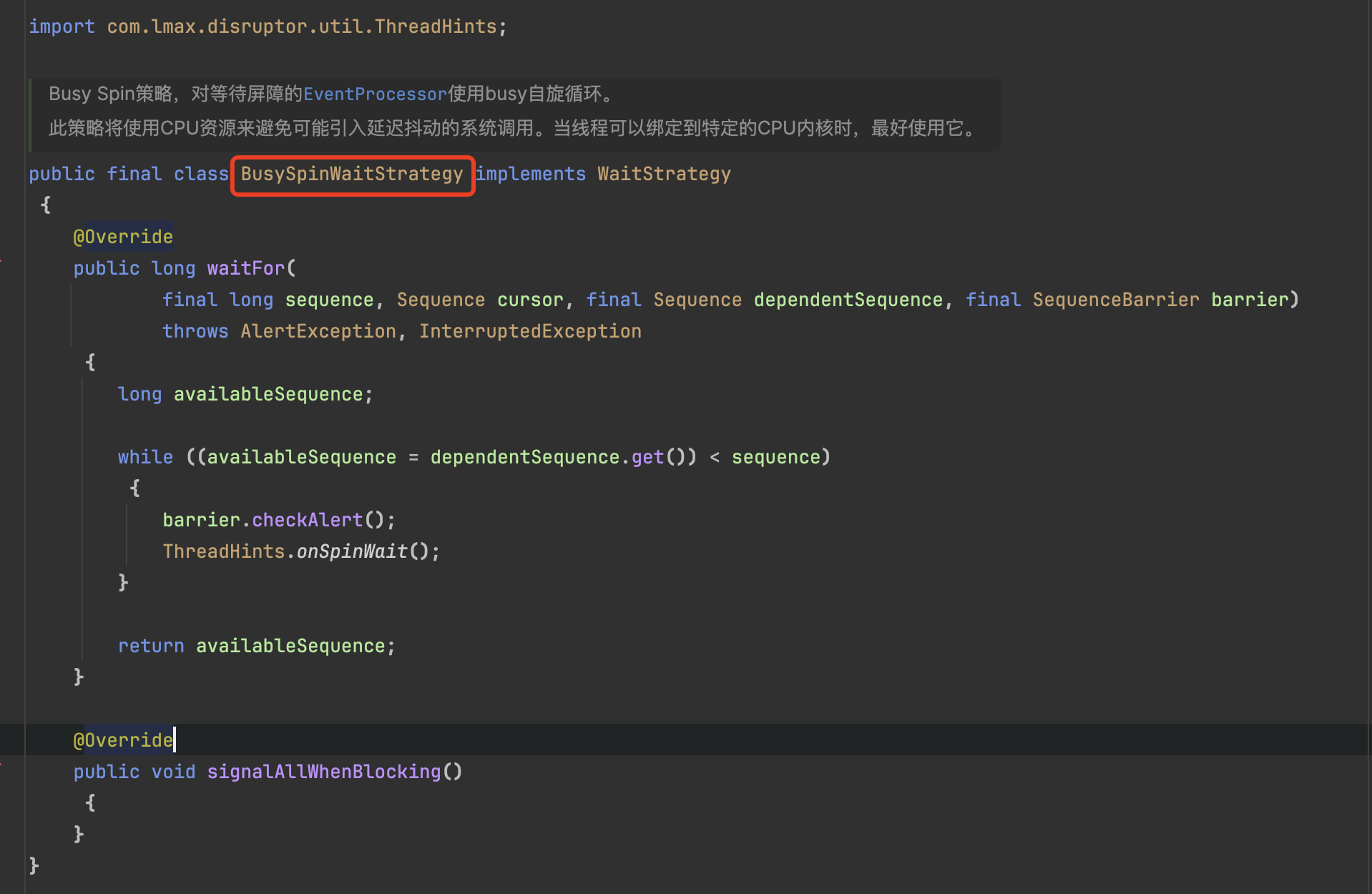
Netty 里面用到了这个库
如果正在开发低延迟的网络应用,那应该对线程亲和性(Thread affinity)有所了解。线程亲和性能够强制使你的应用线程运行在特定的一个或多个cpu上。通过这种方式,可以消除操作系统进行调度过程导致线程迁移所造成的影响。
其次,创建一个特定策略的AffinityThreadFactory,并传入包含延迟敏感(latency-sensitive)线程的EventLoopGroup中。示例如下:
final int acceptorThreads = 1;
final int workerThreads = 10;
EventLoopGroup acceptorGroup = new NioEventLoopGroup(acceptorThreads);
ThreadFactory threadFactory = new AffinityThreadFactory("atf_wrk", AffinityStrategies.DIFFERENT_CORE);
EventLoopGroup workerGroup = new NioEventLoopGroup(workerThreads, threadFactory);
ServerBootstrap serverBootstrap = new ServerBootstrap().group(acceptorGroup, workerGroup);可以说其实 Java-Thread-Affinity 就是套了个 Java 皮,这种应该让操作系统来做的事,其实编写更加底层的 C++ 或者 C 语言来实现的。
所以这个项目实质上是基于 JNA 调用了 DLL 文件,从而实现绑核的需求。
具体对应的代码是这样的:
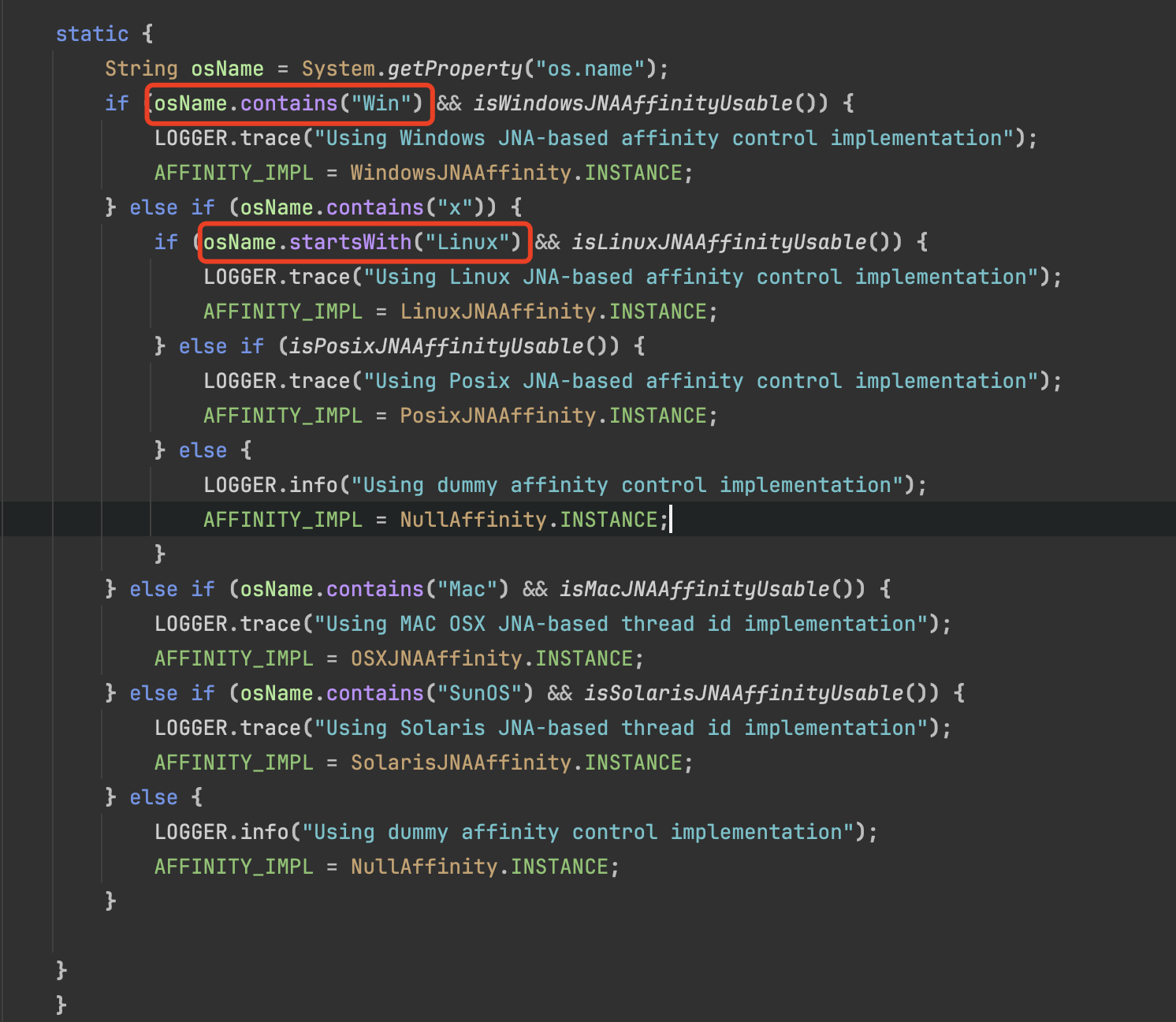
net.openhft.affinity.Affinity
首先在这个类的静态代码块判断操作系统的类型:
net.openhft.affinity.IAffinity
是一个接口,有各个平台的线程亲和性实现:
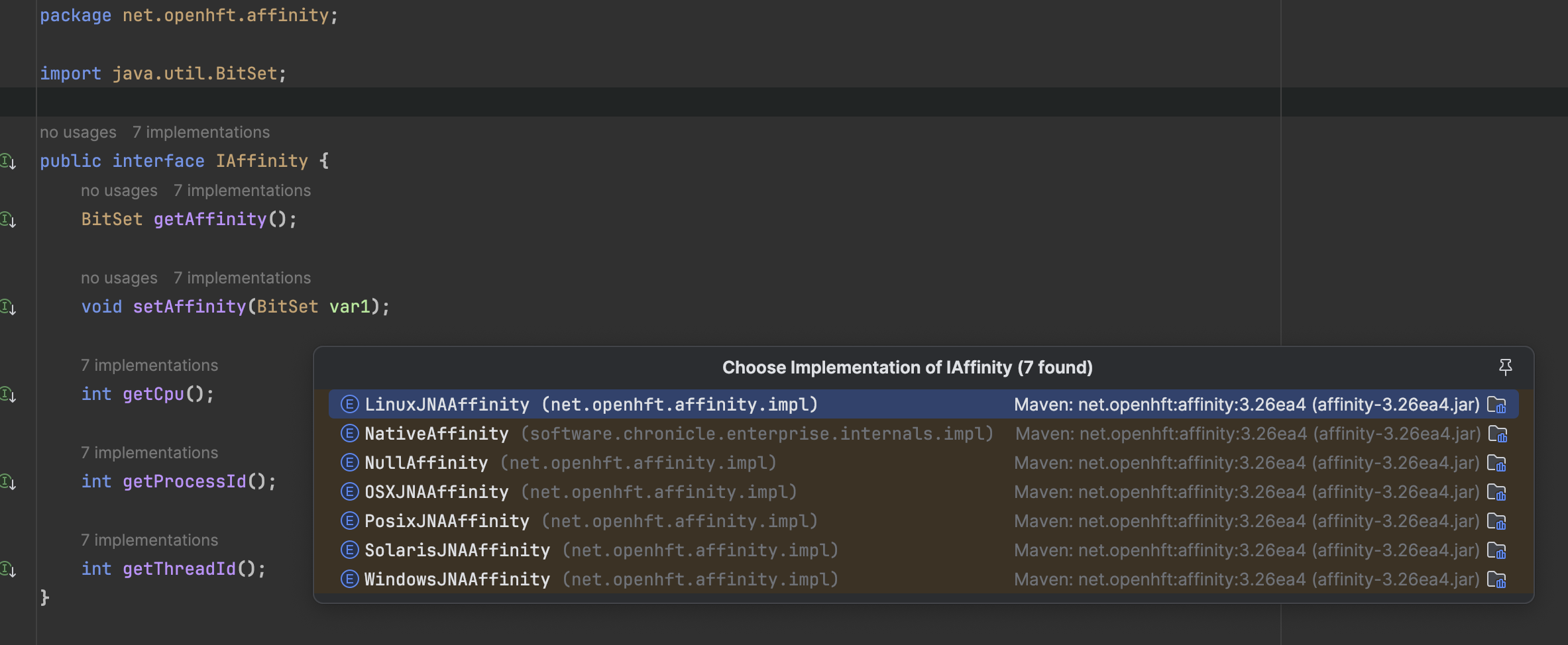
比如,在实现类 WindowsJNAAffinity 里面,你可以看到在它的静态代码块里面调用了这样的逻辑:
net.openhft.affinity.impl.WindowsJNAAffinity.CLibrary
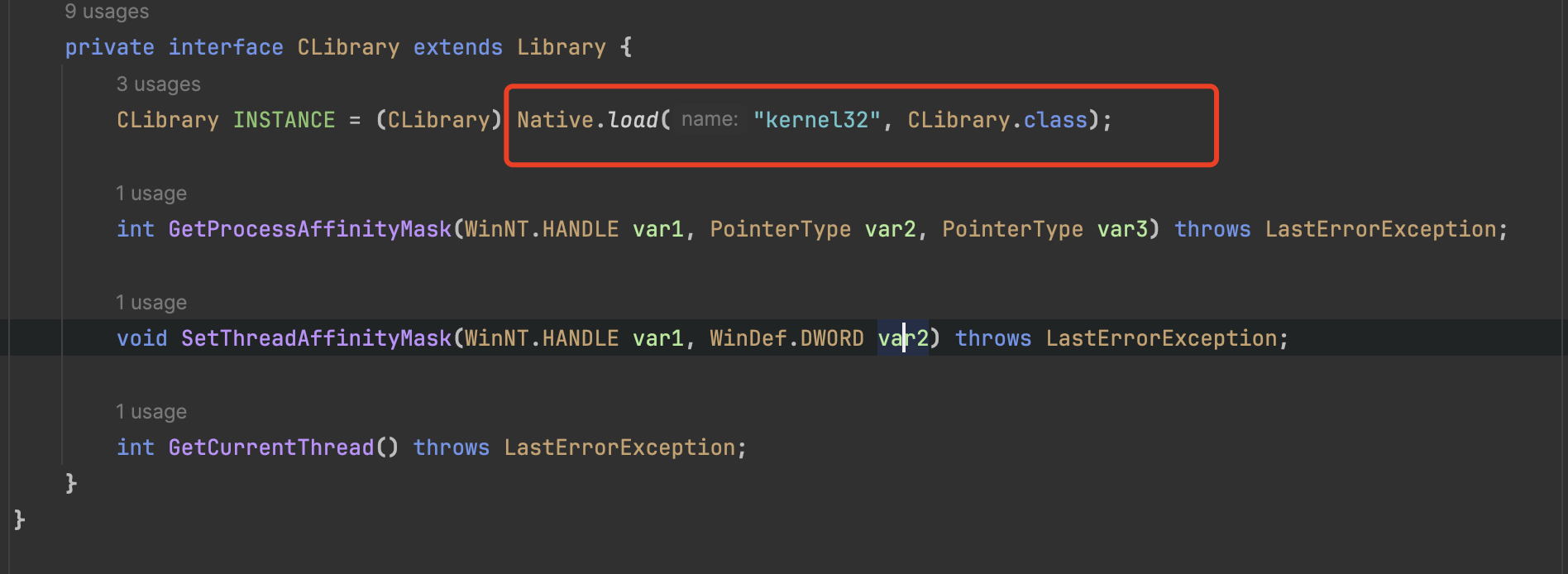
这里就是通过前面说的,通过 JNA 调用 kernel32.dll 文件。
在 windows 平台上能使用该功能的一些的基石就是在此。
第二个点:怎么绑定到指定核心上?
在其核心类里面有这样的一个方法:
net.openhft.affinity.AffinityLock#acquireLock(int)

这里的入参,就是第几个 CPU 的意思,CPU 编号是从 0 开始,但 0 不建议使用
所以程序里面也控制了不能绑定到 0 号 CPU 上。
最终会走到这个方法中:
net.openhft.affinity.AffinityLock#bind(boolean)
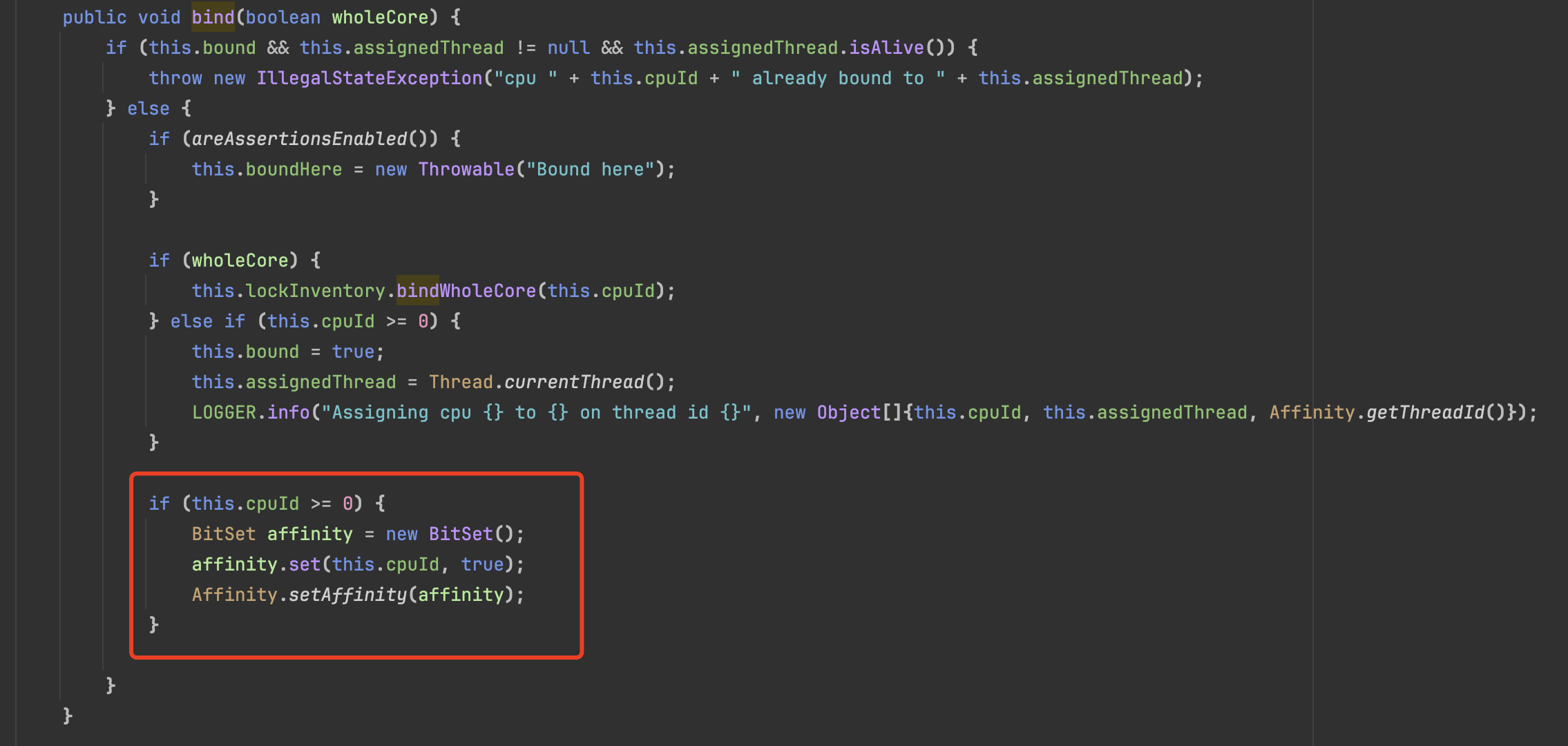
这里采用的是 BitSet,想绑定到第几个 CPU 就把第几个 CPU 的位置设置为 true
在 win 平台上会调用这个方法:
net.openhft.affinity.impl.WindowsJNAAffinity.CLibrary#SetThreadAffinityMask
这个方法,就是限制线程在哪个 CPU 上运行的 API
win 文档:
https://learn.microsoft.com/zh-cn/windows/win32/api/winbase/nf-winbase-setthreadaffinitymask?redirectedfrom=MSDN
上面的就结束啦,后续补充内容,GPT4o回答的
用户级线程 vs 内核级线程
用户级线程(User-Level Threads, ULTs):
- 线程的管理(如创建、调度、同步等)完全在用户空间进行。
- 操作系统只感知到进程,不感知线程。
- 一旦某个用户级线程进行阻塞操作(如 I/O 操作),整个进程都会被阻塞。
内核级线程(Kernel-Level Threads, KLTs):
- 线程的管理由操作系统内核负责。
- 操作系统感知到每个线程,并可以独立调度和管理线程。
- 如果一个内核级线程进行阻塞操作,操作系统可以调度同一进程中的其他线程继续运行。
JVM 的线程模型
JVM 中的线程模型采用的是内核级线程模型。每个 Java 线程对应一个操作系统线程,这意味着:
- 独立调度:操作系统可以独立调度每个线程。如果一个线程阻塞(例如进行 I/O 操作),操作系统可以调度同一进程中的其他线程继续执行。
- 并行执行:在多核处理器上,多个线程可以真正并行执行,因为操作系统可以将不同的线程分配给不同的 CPU 核心。
- 原生线程支持:Java 线程直接映射到操作系统的原生线程(如 POSIX 线程或 Windows 线程),利用操作系统提供的线程管理和调度功能。
Java 线程模型的优势
- 性能:由于操作系统负责线程管理和调度,JVM 可以利用操作系统的优化和多核处理能力,从而实现高性能的并发处理。
- 简单性:编写并发程序更简单,因为 JVM 线程模型和操作系统线程模型一致,开发者不需要考虑用户级线程模型带来的复杂性。
- 阻塞操作处理:如果一个线程进行阻塞操作,不会影响同一进程中的其他线程,操作系统会继续调度其他线程执行。
错误理解的澄清
- 用户级线程问题:在用户级线程模型中,如果一个线程进行阻塞操作(如 I/O 操作),整个进程都会被阻塞,这是因为操作系统只感知到进程的阻塞状态,而不知道进程内的线程状态。
- JVM 的内核级线程:JVM 使用内核级线程,因此,一个线程的阻塞操作不会导致同一进程内其他线程的停止。操作系统可以继续调度其他线程执行,从而避免了用户级线程模型的问题。
小结
JVM 的线程模型是基于操作系统的内核级线程模型,而不是用户级线程模型。每个 Java 线程对应一个操作系统线程,因此,Java 线程在进行阻塞操作时,不会阻塞同一进程中的其他线程。操作系统会独立管理和调度这些线程,充分利用多核处理器的并行执行能力。
JDK21的虚拟线程与用户级线程
Java 21 引入了虚拟线程(Virtual Threads),这是 Project Loom 的一部分,旨在简化并发编程,并使开发者能够轻松创建和管理大量线程。虚拟线程确实引入了一些用户级线程的特点,但它们与传统的用户级线程有显著的区别和改进。
虚拟线程简介
虚拟线程是轻量级的线程实现,每个虚拟线程由 JVM 管理,但它们在操作系统级别并不直接对应一个线程。这意味着虚拟线程可以大量创建而不会像传统线程那样产生高昂的资源开销。
虚拟线程的特点
- 轻量级:虚拟线程的创建和销毁成本非常低,可以在应用程序中创建成千上万甚至数百万个虚拟线程,而不会对系统资源造成过大压力。
- 用户级线程管理:虚拟线程的调度和管理主要在用户空间进行,但与传统用户级线程不同,虚拟线程的阻塞不会导致整个应用程序的阻塞。
- 合作与内核线程结合:虚拟线程由 JVM 调度,而底层仍然依赖于操作系统的内核线程来实际执行任务。这意味着虚拟线程的阻塞操作(如 I/O 操作)不会阻塞操作系统线程。
传统线程与虚拟线程的区别
-
资源利用:
- 传统线程:每个 Java 线程对应一个操作系统线程,创建和管理的开销较大,且数量受到系统资源的限制。
- 虚拟线程:虚拟线程由 JVM 管理,资源开销小,可以创建大量虚拟线程。
-
阻塞处理:
- 传统线程:阻塞操作(如 I/O)会阻塞底层的操作系统线程,从而影响性能。
- 虚拟线程:阻塞操作不会阻塞底层操作系统线程,JVM 会将虚拟线程挂起,并允许操作系统线程执行其他任务。
-
调度模型:
- 传统线程:调度由操作系统管理。
- 虚拟线程:调度由 JVM 管理,但实际执行仍依赖于操作系统的内核线程。
虚拟线程的优点
- 高并发处理:可以轻松创建大量虚拟线程,从而更好地处理高并发任务。
- 简化编程模型:虚拟线程允许开发者以阻塞代码风格编写异步逻辑,简化了编程复杂度。
- 性能提升:由于虚拟线程的轻量级特性和有效的阻塞处理,应用程序的整体性能和响应能力得以提升。
总结
Java 21 引入的虚拟线程虽然具备用户级线程的一些特性(如轻量级、低开销的创建和管理),但它们与传统的用户级线程有显著区别。虚拟线程结合了用户级线程的轻量特性和内核级线程的调度优势,解决了传统用户级线程的一些问题,如阻塞操作导致整个进程阻塞的问题。虚拟线程的引入使得 Java 在处理高并发任务时更加高效和易用。
kotlin的协程与传统的用户级线程
Kotlin 的协程并不是传统的用户级线程(ULTs),尽管它们在某些方面有相似之处。Kotlin 的协程是一种更高级的并发编程模型,主要通过语言和库支持来实现,以简化异步编程和管理并发任务。
Kotlin 协程简介
Kotlin 协程是一种轻量级的协程实现,设计用来简化异步编程。协程允许你在不阻塞线程的情况下执行异步代码,它们可以挂起和恢复执行,而不需要切换线程。
特点和实现方式
- 轻量级:协程比传统的线程要轻量得多。创建和切换协程的开销非常小,因此可以在一个程序中使用大量协程。
- 挂起函数:协程通过挂起函数(suspend functions)实现异步操作。挂起函数可以在需要的时候挂起协程的执行,并在稍后恢复执行,而不阻塞线程。
-
调度器:Kotlin 协程库提供了各种调度器(Dispatchers),如
Dispatchers.IO、Dispatchers.Main、Dispatchers.Default等,用于指定协程在哪些线程或线程池上运行。 - 非阻塞:协程的挂起和恢复是非阻塞的。即使协程在执行 I/O 操作时挂起,也不会阻塞底层的操作系统线程。
- 上下文切换:协程的上下文切换发生在用户空间,由协程库管理,而不是依赖于操作系统的线程调度。
与传统用户级线程的比较
相似之处:
- 用户空间管理:与传统用户级线程一样,Kotlin 的协程在用户空间管理,不需要操作系统的直接参与。
- 轻量级:都比操作系统线程更轻量,可以创建和管理大量实例。
不同之处:
- 非阻塞 I/O:Kotlin 协程的一个关键特性是它们在执行挂起操作时不会阻塞底层操作系统线程。这通过语言和库的支持实现,而传统用户级线程在执行阻塞操作时会阻塞整个进程。
- 调度模型:传统用户级线程通常依赖用户级线程库的调度算法,而 Kotlin 的协程利用了调度器,可以在不同的线程池或调度器之间切换,以实现高效的并发处理。
- 挂起和恢复:Kotlin 协程通过挂起和恢复函数调用栈的方式实现异步操作,而不是通过线程上下文切换。这种方式更高效,也更符合现代异步编程的需求。
总结
Kotlin 的协程提供了一种高级的并发模型,它们结合了用户级线程的一些优点(如轻量级和用户空间管理),但通过语言和库的支持解决了传统用户级线程的一些关键问题,如阻塞操作的处理。相比传统的用户级线程,Kotlin 协程更适合现代异步编程需求,提供了更高效的并发处理能力。
无论是虚拟线程还是协程看似是用户态线程,其实与用户态线程不同,我认为最大的区别在于线程的阻塞不会导致整个应用程序的阻塞
还有一句,大佬说过,Java 的虚拟线程也是有用户态的挂起和恢复逻辑的,跟 Kotlin 协程是同一个层面的东西。只不过它有 jvm 加持,可以做到跟内核线程一样的 api,你甚至可以在 Java 虚拟线程的代码里面看到一个叫 Continuation 的类。