阅读完需:约 25 分钟
PostgreSQL的监控方案很多,功能强悍的包括zabbix、prometheus等,再搭配上grafana和echarts等可视化工具,逼格杠杠。还有针对PostgreSQL特定的监控如pg_top、pgwatch、pg_cluu、pgbadger、pigsty(这个很牛掰),当然有些不能算是严格意义上的监控,如pgbadger,更多的是帮我们分析日志。因为PostreSQL自带的统计视图很多(pg_stat*开头,所以可以很方便的集成到各种各样的监控方案里),再加上各种各样的Extension,也可以监控到底层诸如缓冲区使用率等。
- pg_top:一个用于监视PostgreSQL数据库性能的工具,可以实时查看数据库的运行状态、连接数、查询等信息。
- pgwatch:一个用于监控PostgreSQL数据库性能的工具,可以收集和分析数据库的性能数据,并提供可视化的报表。
- pg_cluu:一个用于管理PostgreSQL集群的工具,可以自动化地创建和管理多个PostgreSQL实例。
- pgbadger:一个用于分析PostgreSQL日志文件的工具,可以生成详细的报告,帮助诊断数据库性能问题。
- pigsty:一个用于管理和监控PostgreSQL集群的Web应用程序,提供了实时监控、报警、备份等功能。
PostgreSQL中以pg_stat_开头的自带的统计视图包括了多个用于展示数据库系统状态和性能信息的视图。以下是一些常见的pg_stat_开头的视图:
- pg_stat_activity: 这是最常用的视图之一,它为每个服务器进程显示一行数据,提供了与当前活动进程相关的信息,如进程ID、连接信息、当前正在执行的查询等。
- pg_stat_replication: 显示复制相关的状态信息,包括复制的角色(主节点或备份节点)、连接信息、复制进度等。
- pg_stat_bgwriter: 提供后台写入进程的统计信息,如缓冲区中脏页的数量、检查点的信息等。
- pg_stat_database: 显示每个数据库的统计信息,包括大小、连接数、事务状态等。
- pg_stat_user: 提供用户的统计信息,如用户的连接数、已执行的查询数量等。
- pg_stat_table: 显示表的统计信息,包括行数、磁盘空间使用情况、索引状态等。
- pg_stat_index: 提供索引的统计信息,如索引的大小、扫描次数等。
-
pg_stat_all_tables: 显示所有表的统计信息,类似于
pg_stat_table,但范围更广。 -
pg_stat_all_indexes: 显示所有索引的统计信息,类似于
pg_stat_index,但范围更广。 - pg_stat_statements: (需要额外配置)提供SQL语句的执行统计信息,如执行次数、平均执行时间等。
- pg_stat_progress_vacuum: 显示自动清理进程的进度信息。
- pg_stat_progress_autovacuum: 显示自动清理的详细进度信息。
- pg_stat_buffers: 提供缓冲区管理器的统计信息,如缓冲区的使用情况、空闲缓冲区的数量等。
- pg_stat_prepared_xacts: 显示准备好的事务的状态信息。
- pg_stat_heap: 提供堆的统计信息,包括元组的数量和大小等。
- pg_stat_tuple_count: 显示表的行数统计信息。
- pg_stat_bloat: 提供表膨胀的统计信息,帮助识别可能的膨胀问题。
中文文档:
http://www.postgres.cn/docs/14/monitoring-stats.html#MONITORING-PG-STAT-ACTIVITY-VIEW
这些视图都是以pg_stat_为前缀的,它们为数据库管理员提供了丰富的信息,以便于监控和管理数据库的性能和健康状况。其中pg_stat_activity是最为常用的,因为它提供了关于当前数据库活动的实时信息。其他视图则提供了更多细节上的统计数据,有助于分析特定的性能问题或监控特定的数据库行为。
这里采用的是一个使用go编写的轻量化监控工具Sampler,它自己的介绍就是:No servers, no databases, no deploy – you specify shell commands, and it just works.,不需要单独的服务器,不需要数据库,也不需要像zabbix一样在需要监控的服务器上安装agent采集端,十分轻量,另外基于go本身的优点,Sampler极容易部署。
其实这个工具就是利用了PG自带的SQL来监控数据库,然后使用图表来展示
Sampler监控
github:官方地址
https://github.com/sqshq/sampler?tab=readme-ov-file
安装方式
这里是在Docker环境下进行的安装
进入PostgreSQL的Docker容器内(数据库版本为 PostgreSQL:14.1)
sudo wget https://github.com/sqshq/sampler/releases/download/v1.1.0/sampler-1.1.0-linux-amd64 -O /usr/local/bin/samplersudo chmod +x /usr/local/bin/sampler主要就是下载工具包,作为可执行的工具
其次就是需要我们自己编写config.yml配置文件来展示需要监控的内容,可以分三步
- 在 YAML 配置文件中定义 shell 命令
- 运行
sampler -c config.yml - 调整组件大小和 UI 上的位置
先来展示一下官方的案例

工具的图表不多但是基本满足要求
图表展示
Runchart(折线图)
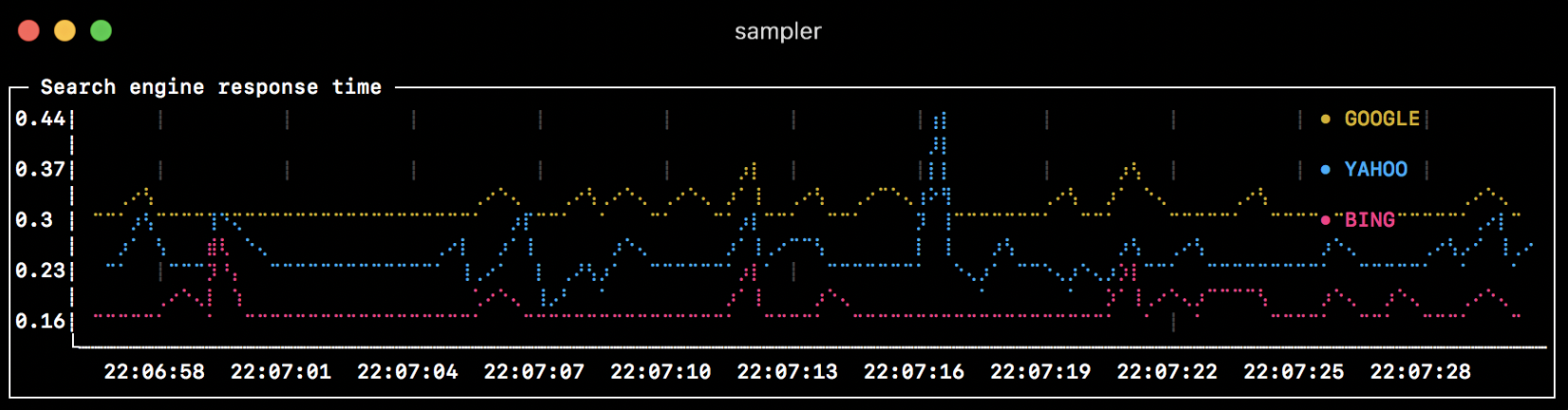
runcharts:
- title: Search engine response time
rate-ms: 500 # sampling rate, default = 1000
scale: 2 # number of digits after sample decimal point, default = 1
legend:
enabled: true # enables item labels, default = true
details: false # enables item statistics: cur/min/max/dlt values, default = true
items:
- label: GOOGLE
sample: curl -o /dev/null -s -w '%{time_total}' https://www.google.com
color: 178 # 8-bit color number, default one is chosen from a pre-defined palette
- label: YAHOO
sample: curl -o /dev/null -s -w '%{time_total}' https://search.yahoo.com
- label: BING
sample: curl -o /dev/null -s -w '%{time_total}' https://www.bing.comSparkline(趋势图)
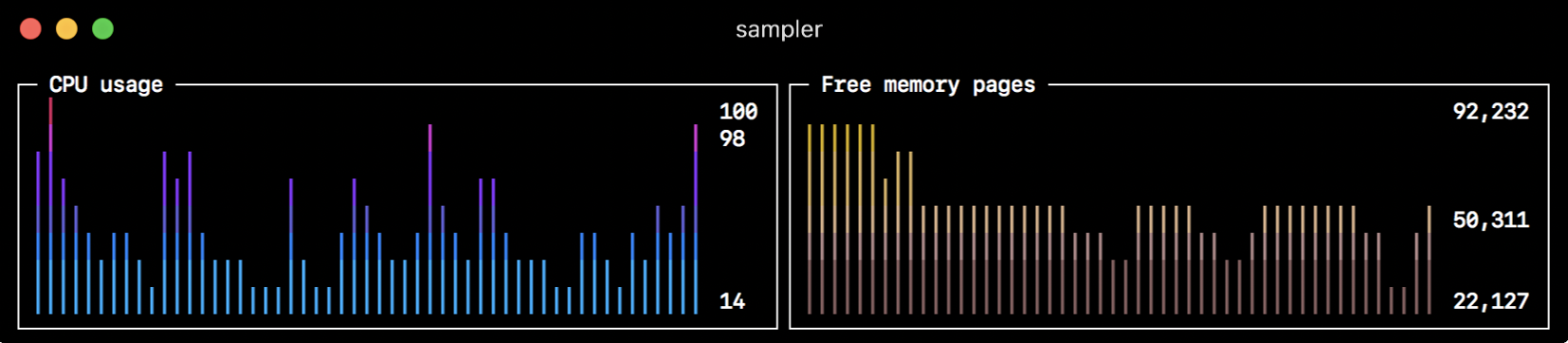
sparklines:
- title: CPU usage
rate-ms: 200
scale: 0
sample: ps -A -o %cpu | awk '{s+=$1} END {print s}'
- title: Free memory pages
rate-ms: 200
scale: 0
sample: memory_pressure | grep 'Pages free' | awk '{print $3}'Barchart(条状图)
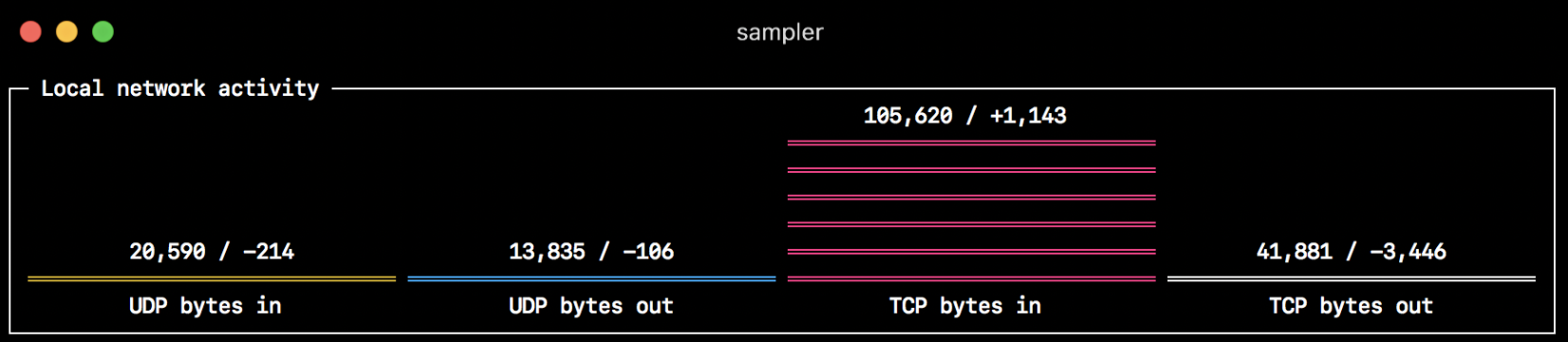
barcharts:
- title: Local network activity
rate-ms: 500 # sampling rate, default = 1000
scale: 0 # number of digits after sample decimal point, default = 1
items:
- label: UDP bytes in
sample: nettop -J bytes_in -l 1 -m udp | awk '{sum += $4} END {print sum}'
- label: UDP bytes out
sample: nettop -J bytes_out -l 1 -m udp | awk '{sum += $4} END {print sum}'
- label: TCP bytes in
sample: nettop -J bytes_in -l 1 -m tcp | awk '{sum += $4} END {print sum}'
- label: TCP bytes out
sample: nettop -J bytes_out -l 1 -m tcp | awk '{sum += $4} END {print sum}'Gauge(进度图)

gauges:
- title: Minute progress
rate-ms: 500 # sampling rate, default = 1000
scale: 2 # number of digits after sample decimal point, default = 1
percent-only: false # toggle display of the current value, default = false
color: 178 # 8-bit color number, default one is chosen from a pre-defined palette
cur:
sample: date +%S # sample script for current value
max:
sample: echo 60 # sample script for max value
min:
sample: echo 0 # sample script for min value
- title: Year progress
cur:
sample: date +%j
max:
sample: echo 365
min:
sample: echo 0Textbox(文本框)
textboxes:
- title: Local weather
rate-ms: 10000 # sampling rate, default = 1000
sample: curl wttr.in?0ATQF
border: false # border around the item, default = true
color: 178 # 8-bit color number, default is white
- title: Docker containers stats
rate-ms: 500
sample: docker stats --no-stream --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}"Asciibox(盒子)

asciiboxes:
- title: UTC time
rate-ms: 500 # sampling rate, default = 1000
font: 3d # font type, default = 2d
border: false # border around the item, default = true
color: 43 # 8-bit color number, default is white
sample: env TZ=UTC date +%r工具并且也支持类似的数据库触发器以告警发邮件等,如有需要可以看官方文档
除了支持PostgreSQL和MySQL数据库,也支持对Kafka、Docker的监控,这里不做过多扩展,但是和监控PostgreSQL的方式是一致的。
自定义 Sampler 监控
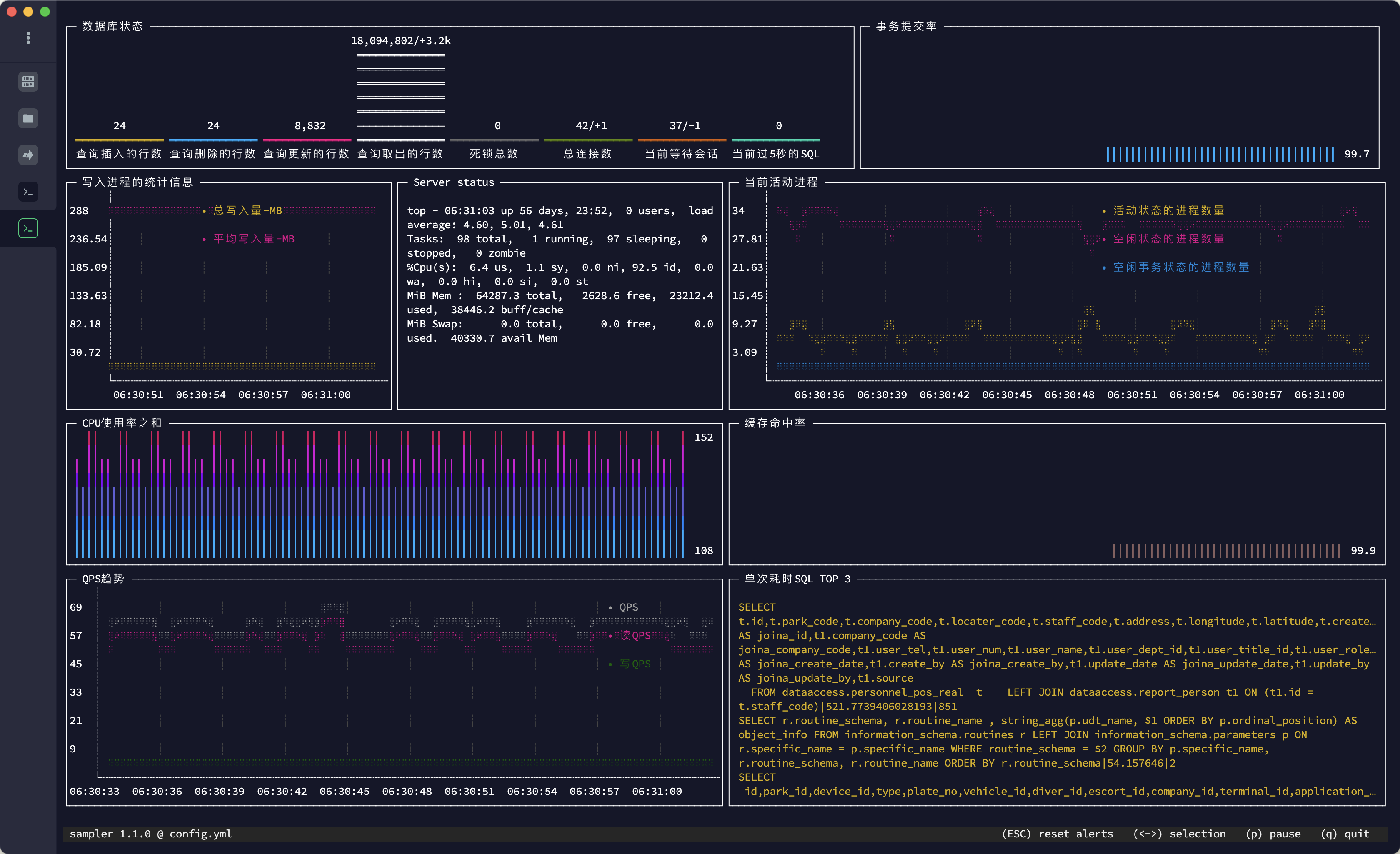
下面是我定义的监控图表与命令,主要监控数据库的读写信息状态
variables:
PGPASSWORD: xxxxx123456
postgres_connection: psql -U xxxxx -d smartpark --no-align --tuples-only
runcharts:
- title: 写入进程的统计信息
position: [[0, 8], [20, 12]]
rate-ms: 500
legend:
enabled: true
details: false
scale: 2
items:
- label: 总写入量-MB
color: 178
sample: psql -At -U xxxxx -d smartpark -c "select 8 * (buffers_checkpoint + buffers_clean + buffers_backend)/1024 as total_writen from pg_stat_bgwriter;"
- label: 平均写入量-MB
color: 162
sample: psql -At -U xxxxx -d smartpark -c "select buffers_checkpoint * 8 / (checkpoints_timed + checkpoints_req) as checkpoint_write_avg from pg_stat_bgwriter;"
- title: 当前活动进程
position: [[40, 8], [40, 12]]
rate-ms: 500
legend:
enabled: true
details: false
scale: 2
items:
- label: 活动状态的进程数量
color: 178
sample: psql -At -U xxxxx -d smartpark -c "select count(*) from pg_stat_activity where
state = 'active' and pid <> pg_backend_pid() and datname = current_database();"
- label: 空闲状态的进程数量
color: 162
sample: psql -At -U xxxxx -d smartpark -c "select count(*) from pg_stat_activity where
state = 'idle' and pid <> pg_backend_pid() and datname = current_database();"
- label: 空闲事务状态的进程数量
color: 32
sample: psql -At -U xxxxx -d smartpark -c "select count(*) from pg_stat_activity where
state = 'idle in transaction' and pid <> pg_backend_pid() and datname = current_database();"
- title: QPS趋势
position: [[0, 28], [40, 12]]
rate-ms: 500
legend:
enabled: true
details: false
scale: 2
items:
- label: QPS
color: 247
sample: psql -At -U xxxxx -d smartpark -c "
WITH A AS ( SELECT SUM ( calls ) s FROM pg_stat_statements WHERE dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database())),
b AS ( SELECT SUM ( calls ) s FROM pg_stat_statements, pg_sleep( 1 ) WHERE dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database())) SELECT
b.s - A.s
FROM A,b;"
- label: 读QPS
color: 162
sample: psql -At -U xxxxx -d smartpark -c "
with
a as (select sum(calls) s, sum(case when ltrim(query,' ') ~* '^select' then calls else 0 end) q from pg_stat_statements WHERE dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database())),
b as (select sum(calls) s, sum(case when ltrim(query,' ') ~* '^select' then calls else 0 end) q from pg_stat_statements , pg_sleep(1) WHERE dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database()))
select
b.q-a.q
from a,b;"
- label: 写QPS
color: 22
sample: psql -At -U xxxxx -d smartpark -c "
with
a as (select sum(calls) s, sum(case when ltrim(query,' ') ~* '^select' then calls else 0 end) q from pg_stat_statements WHERE dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database())),
b as (select sum(calls) s, sum(case when ltrim(query,' ') ~* '^select' then calls else 0 end) q from pg_stat_statements , pg_sleep(1) WHERE dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database()))
select
b.s-b.q-a.s+a.q
from a,b;"
barcharts:
- title: 数据库状态
position: [[0, 0], [48, 8]]
rate-ms: 500
scale: 0
items:
- label: 查询插入的行数
init: $postgres_connection
sample: select tup_inserted from pg_stat_database where datname = current_database();
- label: 查询删除的行数
init: $postgres_connection
sample: select tup_deleted from pg_stat_database where datname = current_database();
- label: 查询更新的行数
init: $postgres_connection
sample: select tup_updated from pg_stat_database where datname = current_database();
- label: 查询取出的行数
init: $postgres_connection
sample: select tup_fetched from pg_stat_database where datname = current_database();
- label: 死锁总数
init: $postgres_connection
sample: select deadlocks from pg_stat_database where datname = current_database();
- label: 总连接数
init: $postgres_connection
sample: select count(*) from pg_stat_activity where datname = current_database();
- label: 当前等待会话
init: $postgres_connection
sample: select count(*) from pg_stat_activity where wait_event_type is not null and datname = current_database();
- label: 当前过5秒的SQL
init: $postgres_connection
sample: select count(*) from pg_stat_activity where state='active' and now()-query_start > interval '5 second' and datname = current_database();
sparklines:
- title: CPU使用率之和
position: [[0, 20], [40, 8]]
rate-ms: 200
scale: 0
sample: ps -A -o %cpu | awk '{s+=$1} END {print s}'
- title: 缓存命中率
position: [[40, 20], [40, 8]]
sample: psql -At -U xxxxx -d smartpark -c "select round(sum(blks_hit)*100/sum(blks_hit+blks_read),2)::numeric from
pg_stat_database where datname = current_database();"
- title: 事务提交率
position: [[48, 0], [32, 8]]
sample: psql -At -U xxxxx -d smartpark -c "select round(100*(xact_commit::numeric/(case when xact_commit > 0 then
xact_commit else 1 end + xact_rollback)),2)::numeric as commit_ratio from
pg_stat_database where datname = current_database();"
textboxes:
- title: Server status
position: [[20, 8], [20, 12]]
rate-ms: 500
sample: top -bn 1 | head -n 5
- title: 单次耗时SQL TOP 3
position: [[40, 28], [40, 12]]
rate-ms: 500
color: 178
sample: psql -At -U xxxxx -d smartpark -c "SELECT
query,
mean_exec_time,
calls
FROM
pg_stat_statements
WHERE
query NOT LIKE'%pg_%' and dbid = (SELECT pgd.oid FROM pg_database pgd WHERE pgd.datname = current_database())
ORDER BY
mean_exec_time DESC
LIMIT 3;"
在PostgreSQL的容器内运行 sampler -c config.yml
PostgreSQL 监控 – 高频指标
Sampler 监控配置文件里用的SQL就可以采用下面的SQL语句内容
总连接数
主要看趋势,直接与业务量挂钩
如果连接数接近max_connection水位,需要注意。
同时连接数应与数据库主机可用内存挂钩,每个连接保守估计10MB内存开销(这里还未计算SYSCACHE,RELCACHE)。
SYSCACHE 和 RELCACHE 是两个不同的数据库缓存机制。
- SYSCACHE 是系统缓存,它用于存储数据库的元数据信息,例如表结构、索引、约束等。这些信息在数据库启动时加载到内存中,以便快速访问。当数据库对象发生变化时,系统会自动更新缓存中的元数据信息。
- RELCACHE 是关系缓存,它用于存储查询结果集。当执行一个查询时,数据库会先检查 RELCACHE 中是否已经存在该查询的结果集。如果存在,则直接从缓存中获取结果集,否则执行查询并将结果集存储到缓存中。这样可以避免重复执行相同的查询,提高查询性能。
select count(*) from pg_stat_activity ;N秒内新建的连接数
主要看趋势,直接与业务量挂钩
如果突发大量连接,可能是新增了业务服务器,或者是性能抖动过导致业务大量新建连接满足并发的请求。
突然连接数下降,可能原因是业务服务器突然释放连接,或者业务服务器挂了。
select count(*) from pg_stat_activity where now()-backend_start > '? second'; SQL活跃统计
需要加载pg_stat_statements,如果需要跟踪IO时间,需要开启track_io_timing。
同时需要注意,由于pg_stat_statements跟踪的SQL有限,最近未访问过的SQL的跟踪信息可能被抛弃。所以统计并不是非常的精准。
具体使用看这里
QPS
QPS指标来自pg_stat_statements,由于这个插件有一个STATEMENT采集上限,可配置,例如最多采集1000条SQL,如果有新的SQL被采集到时,并且1000已用完,则会踢掉最老的SQL。所以我们这里统计的QPS并不是完全精确,不过还好PG内部会自动合并SQL,把一些条件替换成变量,这样即使不使用绑定变量,也能追踪到很多SQL。
对于业务SQL非常繁多并且大多数都是活跃SQL的场景,可以适当调大pg_stat_statements的track数,提高精准度。
除此之外,可以改进pg_stat_statements的功能,直接统计精准的QPS。
with
a as (select sum(calls) s, sum(case when ltrim(query,' ') ~* '^select' then calls else 0 end) q from pg_stat_statements),
b as (select sum(calls) s, sum(case when ltrim(query,' ') ~* '^select' then calls else 0 end) q from pg_stat_statements , pg_sleep(1))
select
b.s-a.s, -- QPS
b.q-a.q, -- 读QPS
b.s-b.q-a.s+a.q -- 写QPS
from a,b; active session(活跃会话数)
主要看趋势,直接与业务量挂钩
如果活跃会话数长时间超过CPU核数时,说明数据库响应变慢了,需要深刻关注。
select count(*) from pg_stat_activity where state='active'; long query(长时间查询)
当前系统中执行时间超过N秒的SQL有多少条,LONG QUERY与活跃会话的比例说明当前LONG SQL的占比。占比越高,说明该系统可能偏向OLAP,占比越低,说明该系统偏向OLTP业务。
select count(*) from pg_stat_activity where state='active' and now()-query_start > interval '? second'; long transaction(长事物)
当前系统中N秒未结束的事务有多少条
select count(*) from pg_stat_activity where now()-xact_start > interval '? second'; idle in transaction(事务中处于空闲的会话)
当前系统中在事务中并且处于空闲状态的会话有多少,很多,说明业务端的处理可能比较慢,如果结合锁等待发现有大量锁等待,并且活跃会话数有突增,可能需要关注并排查业务逻辑的问题。
select count(*) from pg_stat_activity where state='idle in transaction';
long idle in transaction(长时间处于空闲的事务)
当前系统中,有多少长期(超过N秒)处于空闲的事务。如果有较多这样的事务,说明业务端的处理时间超过N秒的情况非常普遍,应该尽快排查业务。
比如前端开启了游标,等待用户的翻页动作,用户可能开小差了。又比如业务上使用了一些交互模式,等用户的一些输入等。
这种情况应该尽量避免,否则长时间占用连接资源。
select count(*) from pg_stat_activity where state='idle in transaction' and now()-state_change > interval '? second'; waiting(等待中的会话)
当前系统中,处于等待中的会话有多少。如果很多,说明出现了大量的锁等待。
select count(*) from pg_stat_activity where wait_event_type is not null;
long waiting(等待超过N秒的会话)
当前系统中,等待超过N秒的会话有多少。
select count(*) from pg_stat_activity where wait_event_type is not null and now()-state_change > interval '? second';
2pc(2PC的事务)
当前系统中,2PC的事务有多少。如果接近max_prepared_transactions,需要注意。建议调大max_prepared_transactions,或者排查业务是否未及时提交。
select count(*) from pg_prepared_xacts;
long 2pc(长时间2PC的事务)
当前系统中,超过N秒未结束的2PC的事务有多少。如果很多,需要排查业务为什么未及时提交。
select count(*) from pg_prepared_xacts where now() - prepared > interval '? second';
膨胀点监测 – 多久以前的垃圾可以被回收
时间间隔越大,说明越容易导致膨胀。
排查这几个方向,长事务,长SQL,2PC,持有SNAPSHOT的QUERY。必要时把不合理的老的会话干掉。
with a as
(select min(xact_start) m from pg_stat_activity where backend_xid is not null or backend_xmin is not null),
b as (select min(prepared) m from pg_prepared_xacts)
select now()-least(a.m,b.m) from a,b; 备库发送延迟
SELECT
application_name,
client_addr,
client_hostname,
client_port,
STATE,
sync_priority,
sync_state,
pg_size_pretty ( pg_wal_lsn_diff ( pg_current_wal_lsn ( ), sent_lsn ) )
FROM
pg_stat_replication;备库APPLY延迟
SELECT
application_name,
client_addr,
client_hostname,
client_port,
STATE,
sync_priority,
sync_state,
pg_size_pretty ( pg_wal_lsn_diff ( pg_current_wal_lsn ( ), replay_lag ) )
FROM
pg_stat_replication;SLOT 延迟
SELECT
slot_name,
plugin,
slot_type,
TEMPORARY,
active,
active_pid,
pg_size_pretty ( pg_wal_lsn_diff ( pg_current_wal_lsn ( ), restart_lsn ) )
FROM
pg_replication_slots;归档延迟
最后一次归档失败时间减去最后一次归档成功的时间,求时间差。
select last_failed_time - last_archived_time from pg_stat_archiver; 事务提交数
select sum(xact_commit) from pg_stat_database; -- pg_stat_get_db_xact_commit 为stable函数,一个事务中两次调用之间只执行一次,所以需要外部多次执行。 事务回滚数
select sum(xact_rollback) from pg_stat_database; 全表扫描记录数
select sum(tup_returned) from pg_stat_database;
索引扫描回表记录数
select sum(tup_fetched) from pg_stat_database;
插入记录数
select sum(tup_inserted) from pg_stat_database;
更新记录数
select sum(tup_updated) from pg_stat_database;
删除记录数
select sum(tup_deleted) from pg_stat_database;
查询冲突数
select sum(conflicts) from pg_stat_database;
死锁数
select sum(deadlocks) from pg_stat_database;
注意事项
pg_stat_database 的 numbackends 与 sessions 与 pg_stat_activity 的数量之间的关系
pg_stat_database.numbackends:
- 表示当前连接到数据库的后端进程数量(即活动会话数)。每个连接到数据库的客户端都会创建一个后端进程,这些进程包括空闲的、正在执行查询的,以及其他状态的会话。
pg_stat_database.sessions:
- 该列在标准的
pg_stat_database视图中并不存在,可能是特定扩展或自定义视图中的一部分。如果存在,通常表示自上次统计重置以来的累计会话数量。
pg_stat_activity:
- 包含每个当前连接到数据库的会话的信息。这包括所有会话的详细信息,无论它们是空闲的、正在执行查询的、正在等待资源的,还是其他状态。
比较和关系
-
pg_stat_database.numbackends和pg_stat_activity的行数应该是一致的。每一个活动会话都会在pg_stat_activity中有一行表示,同时也会增加pg_stat_database.numbackends的计数。 -
pg_stat_activity不仅包含正在执行查询或事务的会话,还包含空闲会话、等待锁的会话等。因此,pg_stat_activity的行数不应该大于pg_stat_database.numbackends,它们应当是相等的。
-- 从 pg_stat_database 获取 numbackends
SELECT datname, numbackends
FROM pg_stat_database;
-- 从 pg_stat_activity 获取当前活动会话数
SELECT datname, COUNT(*) AS active_sessions
FROM pg_stat_activity
GROUP BY datname;
pg_stat_database.numbackends 和 pg_stat_activity 的行数应当一致,表示当前连接到数据库的所有会话。pg_stat_activity 包含了所有会话的详细信息,不仅仅是正在执行查询或事务的会话。因此,pg_stat_activity 的数量不会比 numbackends 大,而是应该与之相等。
pg_stat_activity 的数量超出了max_connections
超级用户连接
- PostgreSQL 允许超级用户连接到数据库,即使连接数已经达到了
max_connections的限制。 - 这是为了确保管理员可以在连接数已满的情况下进行管理和维护。
保留连接数
- PostgreSQL 会为超级用户保留几个连接数,以便在达到最大连接数时仍能进行管理操作。
- 这个保留连接数是
superuser_reserved_connections参数指定的默认值,通常为 3。
复制连接(Replication Connections)
- 除了
max_connections之外,PostgreSQL 还有一个单独的参数max_wal_senders来控制最大 WAL 发送进程数。 - 这些进程用于流复制,不计入
max_connections。
系统进程
- 一些系统进程如
autovacuum、background writer、checkpointer等可能会显示在pg_stat_activity中,但这些通常也被视为数据库连接。 - 这些进程不会占用
max_connections。
重置统计信息:如果在查询之间重置了统计信息(例如使用 pg_stat_reset()),可能会导致数据不一致。
区分普通连接和特殊连接
SELECT pid, usename, application_name, client_addr, state, backend_type
FROM pg_stat_activity
ORDER BY backend_type;backend_type 列显示了不同类型的连接,比如:
-
client backend: 普通客户端连接。 -
background writer: 后台写进程。 -
autovacuum launcher: 自动清理进程。 -
wal sender: WAL 发送进程(用于复制)。
pg_stat_activity 的 wait_event_type 与 pg_stat_database 的 deadlocks 关系
pg_stat_activity 中的 wait_event_type 与 pg_stat_database 中的 deadlocks 之间存在一定的关联,它们都与数据库的并发性能和锁竞争有关。具体如下:
-
等待事件类型(wait_event_type):
pg_stat_activity视图中的wait_event_type字段显示了每个数据库进程当前的等待状态。这个状态可以帮助我们了解进程是否在等待某些资源,例如锁、日志写入等。当多个事务尝试以不同的顺序锁定相同的资源时,可能会导致死锁,这时wait_event_type可能会显示与锁等待相关的事件类型。 -
死锁数(deadlocks):
pg_stat_database视图中的deadlocks字段记录了数据库中发生的死锁数量。死锁是指两个或多个事务在等待对方释放资源,从而导致彼此永远等待的情况。当检测到死锁时,PostgreSQL 会选择牺牲其中一个事务来解除死锁状态。 -
关系:当
pg_stat_activity中的进程因为锁而等待时,如果这种等待导致了死锁的发生,那么pg_stat_database中的deadlocks计数就可能增加。因此,高频率的锁等待事件可能会影响到数据库的死锁数。通过监控这两个指标,可以更好地理解数据库的并发行为,并进行相应的优化,比如调整锁策略或者优化查询以减少锁竞争。
综上所述,wait_event_type 可以帮助我们实时监控和诊断进程的等待状态,而 deadlocks 提供了关于数据库死锁发生情况的历史数据。两者都是数据库性能分析和调优的重要指标。
