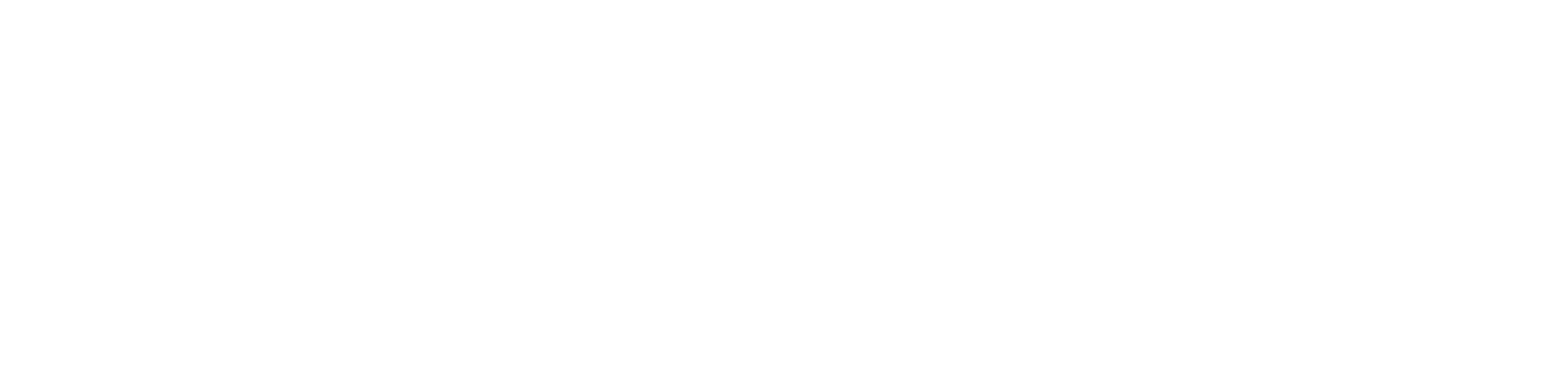
阅读完需:约 239 分钟
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系 统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写, Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。 (新版本已经不使用zookeeper)
官方文档
https://kafka.apache.org/documentation/#introduction
Kafka作为一个分布式的流平台,这到底意味着什么?
我们认为,一个流处理平台具有三个关键能力:
- 发布和订阅消息(流),在这方面,它类似于一个消息队列。
- 以容错(故障转移)的方式存储消息(流)。
- 在消息流发生时处理它们。
所有这些功能都是以分布式、高度可扩展、弹性、容错和安全的方式提供的。Kafka 可以部署在裸机硬件、虚拟机和容器上,也可以部署在本地和云端。您可以选择自行管理 Kafka 环境,也可以选择使用各种供应商提供的完全托管服务。
什么是kafka的优势?它主要应用于2大类应用:
- 构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。
- 构建实时流的应用程序,对数据流进行转换或反应。
要了解kafka是如何做这些事情的,让我们从下到上深入探讨kafka的能力。
首先几个概念:
- kafka作为一个集群运行在一个或多个服务器上。
- kafka集群存储的消息是以topic为类别记录的。
- 每个消息(也叫记录record,我习惯叫消息)是由一个key,一个value和时间戳构成。
Kafka 还有五个适用于 Java 和 Scala 的核心 API:
- 用于管理和检查主题、代理和其他 Kafka 对象的 管理 API 。
- Producer API,用于将事件流发布(写入)到一个或多个 Kafka 主题。
- Consumer API用于订阅(读取)一个或多个主题并处理为其生成的事件流。
- Kafka Streams API用于实现流处理应用程序和微服务。它提供了更高级别的函数来处理事件流,包括转换、有状态操作(例如聚合和连接)、窗口、基于事件时间的处理等等。从一个或多个主题读取输入,以便生成一个或多个主题的输出,从而有效地将输入流转换为输出流。
- Kafka Connect API用于构建和运行可重用的数据导入/导出连接器,这些连接器消耗(读取)或生成(写入)来自外部系统和应用程序的事件流,以便它们可以与 Kafka 集成。例如,关系数据库(如 PostgreSQL)的连接器可能会捕获对一组表的每个更改。然而,在实践中,您通常不需要实现自己的连接器,因为 Kafka 社区已经提供了数百个现成的连接器。
Kafka所使用的基本术语
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。 首先,让我们来看一下基础的消息(Message)相关术语:
| 名称 | 解释 |
| Broker | 一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群,消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条 消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 (在同一个Consumer Group中,一条消息只会被其中一个Consumer消费。这样可以保证每个消息只会被处理一次) |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个 partition内部消息是有序的 (每个分区的数据是不同的,分区有主从备份的,主负责读写,从仅负责备份) (消息生产者在发送消息到Kafka Topic时,会根据分区策略将消息分配到不同的Partition中) |
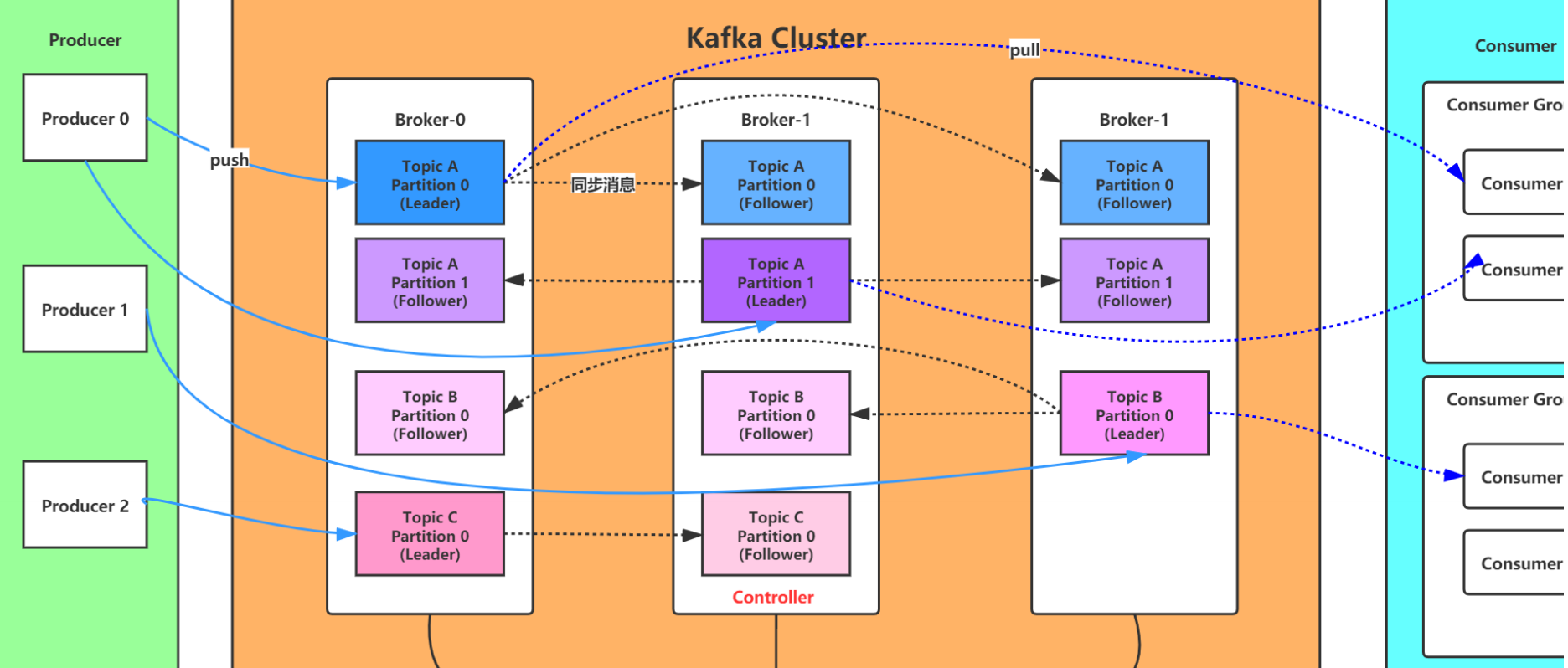
主题和日志 (Topic和Log)
让我们更深入的了解Kafka中的Topic。
Topic是发布的消息的类别名,一个topic可以有零个,一个或多个消费者订阅该主题的消息。
对于每个topic,Kafka集群都会维护一个分区log,就像下图中所示:
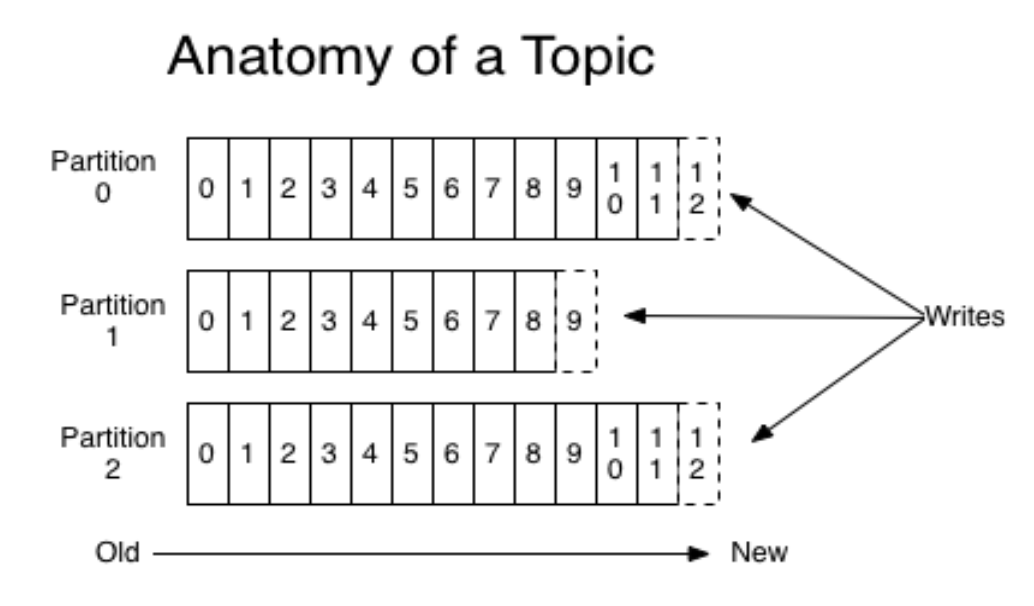
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition 中的message的offset可能是相同的。
Kafka集群保持所有的消息,直到它们过期(无论消息是否被消费),只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日志信息不会有什么影响
实际上消费者所持有的仅有的元数据就是这个offset(偏移量),也就是说offset由消费者来控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更早的位置,重新读取消息。可以看到这种设计对消费者来说操作自如,一个消费者的操作不会影响其它消费者对此log的处理。
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由consumer自 己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息, 或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer 来说,都是没有影响的,因为每个consumer维护各自的消费offset。
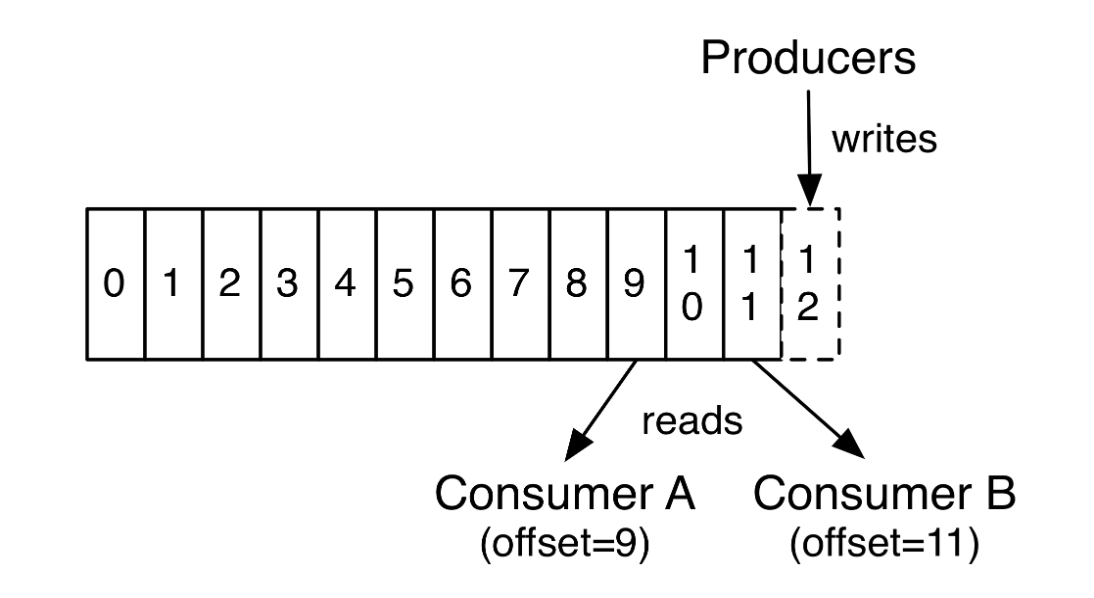
再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点。
可以这么来理解Topic,Partition和Broker
一个topic,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同topic,订单相关操作消息放入订单topic,用户相关操作消息放入用户topic,对于大型网站来说,后端数据都是海量的,订单消息很可能是非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,那么就可以在 topic内部划分多个partition来分片存储数据,不同的partition可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker。
分布式(Distribution)
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
生产者(Producers)
生产者往某个Topic上发布消息。生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。开发者负责如何选择分区的算法。
消费者(Consumers)
传统的消息传递模式有2种:队列( queue) 和(publish-subscribe)
- queue模式:多个consumer从服务器中读取数据,消息只会到达一个consumer。
- publish-subscribe模式:消息会被广播给所有的consumer。
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
- queue模式:所有的consumer都位于同一个consumer group 下。
- publish-subscribe模式:所有的consumer都有着自己唯一的consumer group。
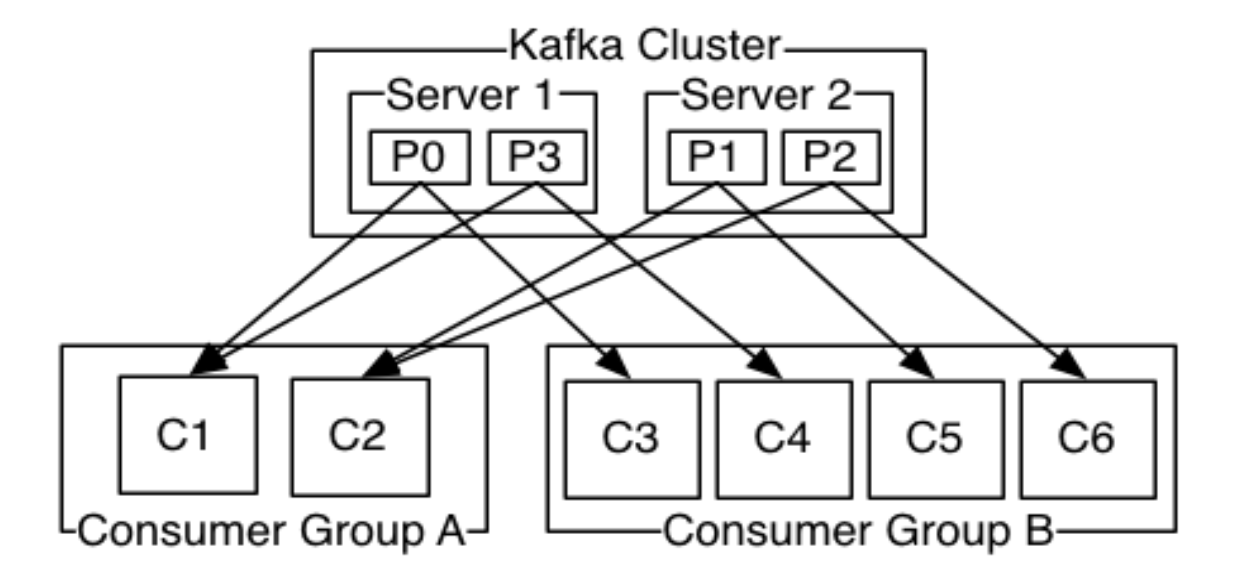
这个集群 由2个Consumer Group消费, A有2个consumer instances ,B有4个。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。
正像传统的消息系统一样,Kafka保证消息的顺序不变。传统的队列模型保持消息,并且保证它们的先后顺序不变。但是,尽管服务器保证了消息的顺序,消息还是异步的发送给各个消费者,消费者收到消息的先后顺序不能保证了。这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚,消息的顺序处理很让人头痛。如果只让一个消费者处理消息,又违背了并行处理的初衷。
在这一点上Kafka做的更好,尽管并没有完全解决上述问题。Kafka采用了一种分而治之的策略:分区。因为Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
Kafka的保证(Guarantees)
生产者发送到一个特定的Topic的分区上,消息将会按照它们发送的顺序依次加入,也就是说,如果一个消息M1和M2使用相同的producer发送,M1先发送,那么M1将比M2的offset低,并且优先的出现在日志中。 消费者收到的消息也是此顺序。 如果一个Topic配置了复制因子(replication factor)为N, 那么可以允许N-1服务器宕机而不丢失任何已经提交(committed)的消息。
消费顺序
一个partition同一个时刻在一个consumer group中只能有一个consumer instance在消费,从而保证消费顺序。
consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多,否则,多出来的 consumer消费不到消息。
在Kafka中,消费者组(Consumer Group)中的消费者实例(Consumer Instance)的数量与Topic中的分区(Partition)数量之间的关系对消息的消费方式有重要影响。
Kafka的设计原则是,一个消费者组中的每个消费者实例负责消费一个或多个分区的数据。分区的总数决定了可以并行消费的最大消费者数量。换句话说,消费者组中的一个消费者实例至少会分配到一个分区。
如果消费者组中的消费者实例数量多于分区的数量,那么确实会有一些消费者实例不会分配到任何分区。因此,这些多余的消费者实例将无法消费到任何消息,它们将处于空闲状态。
kafka的流处理
仅仅读,写和存储是不够的,kafka的目标是实时的流处理。
在kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出。
可以直接使用producer和consumer API进行简单的处理。对于复杂的转换,Kafka提供了更强大的Streams API。可构建聚合计算或连接流到一起的复杂应用程序。
助于解决此类应用面临的硬性问题:处理无序的数据,代码更改的再处理,执行状态计算等。
Streams API在Kafka中的核心:使用producer和consumer API作为输入,利用Kafka做状态存储,使用相同的组机制在stream处理器实例之间进行容错保障。
docker-compose搭建kafka集群
Kafka的Kraft模式简单来说就是基于raft协议重新实现了zookeeper的功能。传统的zookeeper集群已经被标记为弃用,将在kafka4.0中完全移除。由于去掉了zk组件,部署也简化了不少。现在基于Kraft模式和Docker Compose同时采用最新版Kafka v3.7.0来搭建集群。
关于Raft协议可以参考之前的
这里首先要说明的是,搭建的kafka是基于官方的文档来的,并且是没有开启认证的kafka集群
Kraft模式集群由两种角色的节点组成,分别是broker和controller角色。角色类型在节点启动时通过process.roles配置参数指定,允许指定broker或controller,或者同时指定二者,可就是一个节点兼顾两种角色。
- broker类型节点的职责是为客户端提供服务,即接收生产者消息,并推送给消费者。还可以与其它broker之间同步副本消息。broker内就是我们熟悉的topic分区副本等结构了。
- controller类型的节点可以参与Leader选举,有投票权和被投票权,只有被选举称为Leader节点时才能为集群提供服务。一个集群中只能有一个Leader节点,如果出现多个Leader的异常情况通常被称为脑裂,这不是我们关注的主题。Leader节点负责维护整个集群的元数据与调度broker协同工作,例如创建删除topic、分区重分配、preferred leader选举、topic分区拓展、broker上线下线等。
Kafka集群带来的好处是允许横向扩展broker节点,并且在线就可以完成扩展。
官方原版 docker-compose
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
---
version: '2'
services:
kafka-1:
image: apache/kafka:latest
hostname: kafka-1
container_name: kafka-1
ports:
- 29092:9092
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093'
KAFKA_LISTENERS: 'PLAINTEXT://:19092,CONTROLLER://:9093,PLAINTEXT_HOST://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-1:19092,PLAINTEXT_HOST://localhost:29092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
kafka-2:
image: apache/kafka:latest
hostname: kafka-2
container_name: kafka-2
ports:
- 39092:9092
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093'
KAFKA_LISTENERS: 'PLAINTEXT://:19092,CONTROLLER://:9093,PLAINTEXT_HOST://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-2:19092,PLAINTEXT_HOST://localhost:39092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
kafka-3:
image: apache/kafka:latest
hostname: kafka-3
container_name: kafka-3
ports:
- 49092:9092
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093'
KAFKA_LISTENERS: 'PLAINTEXT://:19092,CONTROLLER://:9093,PLAINTEXT_HOST://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-3:19092,PLAINTEXT_HOST://localhost:49092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'这里我们做出改变
我们搭建1个[broker]节点,3个[broker,controller]节点和 1个[controller]节点,一个五个节点来测试
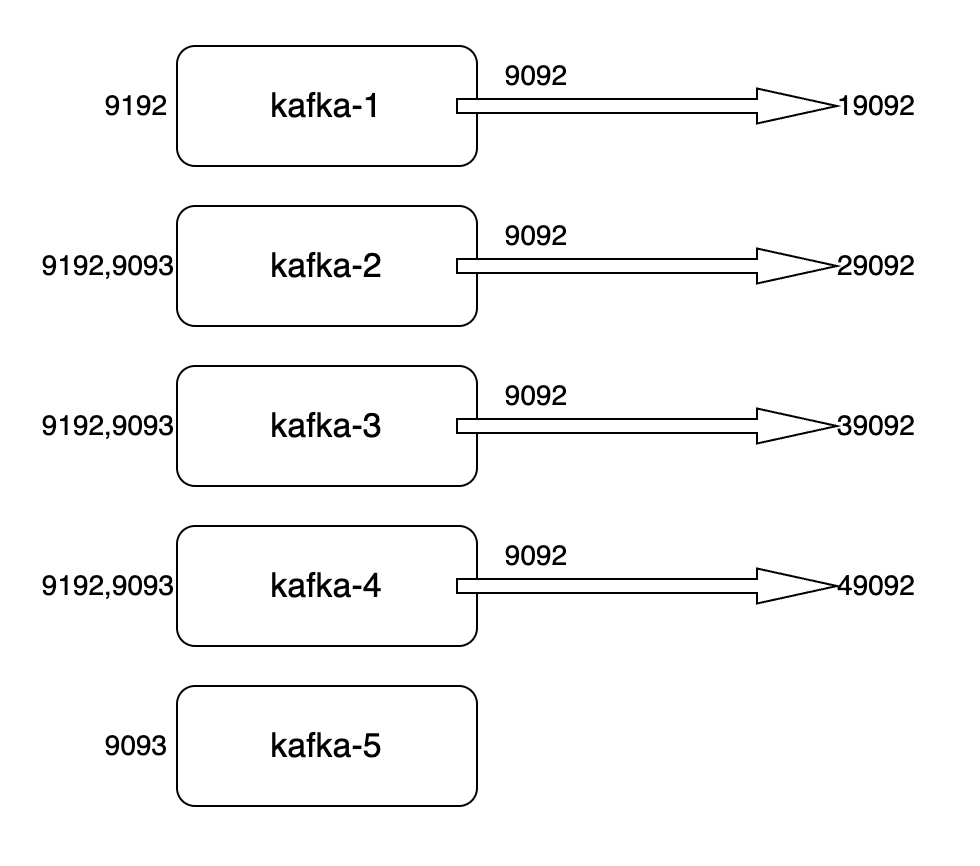
规划了三种流量路径:
- 外部流量 EXTERNAL://:9092,允许外部客户端(生产者、消费者、集群管理工具都算是外部客户端)连接到集群。我们将容器中的端口映射出来,暴漏出4各端口:19092、29092、39092、49092
- 控制流量 CONTROLLER://:9093,我们为控制节点间的通信设置了单独的端口9093,以防数据流量过载造成控制信息下发延迟或失败。
- 内部流量 INTERNAL://:9192,broker之间同步副本数据走内部端口9192。
version: '2'
services:
kafka-1:
image: apache/kafka:3.7.0
hostname: kafka-1
container_name: kafka-1
ports:
- 19092:9092
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: 'broker'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@kafka-2:9093,3@kafka-3:9093,4@kafka-4:9093,5@kafka-5:9093'
KAFKA_LISTENERS: 'INTERNAL://:9192,EXTERNAL://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'INTERNAL'
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-1:9192,EXTERNAL://10.4.3.41:19092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
kafka-2:
image: apache/kafka:3.7.0
hostname: kafka-2
container_name: kafka-2
ports:
- 29092:9092
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@kafka-2:9093,3@kafka-3:9093,4@kafka-4:9093,5@kafka-5:9093'
KAFKA_LISTENERS: 'INTERNAL://:9192,CONTROLLER://:9093,EXTERNAL://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'INTERNAL'
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-2:9192,EXTERNAL://10.4.3.41:29092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
kafka-3:
image: apache/kafka:3.7.0
hostname: kafka-3
container_name: kafka-3
ports:
- 39092:9092
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@kafka-2:9093,3@kafka-3:9093,4@kafka-4:9093,5@kafka-5:9093'
KAFKA_LISTENERS: 'INTERNAL://:9192,CONTROLLER://:9093,EXTERNAL://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'INTERNAL'
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-3:9192,EXTERNAL://10.4.3.41:39092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
kafka-4:
image: apache/kafka:3.7.0
hostname: kafka-4
container_name: kafka-4
ports:
- 49092:9092
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@kafka-2:9093,3@kafka-3:9093,4@kafka-4:9093,5@kafka-5:9093'
KAFKA_LISTENERS: 'INTERNAL://:9192,CONTROLLER://:9093,EXTERNAL://:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'INTERNAL'
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-4:9192,EXTERNAL://10.4.3.41:49092
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
kafka-5:
image: apache/kafka:3.7.0
hostname: kafka-5
container_name: kafka-5
ports:
- 59092:9092
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: 'controller'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT'
KAFKA_CONTROLLER_QUORUM_VOTERS: '2@kafka-2:9093,3@kafka-3:9093,4@kafka-4:9093,5@kafka-5:9093'
KAFKA_LISTENERS: 'CONTROLLER://:9093'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
CLUSTER_ID: '4L6g3nShT-eMCtK--X86sw'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
因为我这边宿主机IP是10.4.3.41,需要的话将它改为你IP地址,然后docker-compose up -d 就可以成功运行起来了
我们不但要把集群运行起来,还要理解这些参数的含义。上面的compose文件中使用环境变量作为启动参数传递给Kafka,与直接修改配置文件效果一样。在Kraft模式下,Kafka有如下三个配置文件可以配置。
-
./opt/kafka/config/kraft/controller.properties: 当节点作为[controller]角色运行时,会去读该文件中的配置项启动。 -
./opt/kafka/config/kraft/broker.properties: 当节点作为[broker]角色运行时,会去读该文件中的配置项启动。 -
./opt/kafka/config/kraft/server.properties: 当节点同时作为[broker, controller]角色运行时,会去读该文件中的配置项启动。
接下来我们来看看这些文件内常用的配置项(更多的配置参考上面三个文件里的配置自行添加):
-
KAFKA_NODE_ID: 配置节点ID,同一集群内节点ID不允许重复。 -
KAFKA_PROCESS_ROLES: 指定节点的角色,允许指定broker或controller,或者同时指定二者,可就是一个节点兼顾两种角色。 -
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 配置监听器对应的安全协议。 -
KAFKA_CONTROLLER_QUORUM_VOTERS: 指定集群内所有的controller节点,格式为:nodeId@ip:port。 -
KAFKA_LISTENERS: 列出节点监听器,通常不同的角色会监听不同的端口,它的格式是{LISTENER_NAME}://{hostname}:{port} -
KAFKA_INTER_BROKER_LISTENER_NAME: 指定其它broker节点与本节点通信的监听器。 -
KAFKA_ADVERTISED_LISTENERS: listeners选项配置了以怎样的协议监听某个端口。这个配置项类似防火墙的作用,对外公开允许它们使用怎样的IP和端口访问集群,这里外部指的是客户端(包括生产者、消费者、管理脚本等)或其它broker节点。 -
KAFKA_CONTROLLER_LISTENER_NAMES: 指定controller监听器名称列表。 -
CLUSTER_ID: 配置集群ID,同一个集群中的所有节点都应该指定相同的集群ID。 -
KAFKA_LOG_DIRS: 日志地址
基本上就是上面的这些配置,更多的可以去配置文件里找对应的
需要注意的是上述配置中的KAFKA_LISTENERS配置,会有点疑惑,特别强调一下
KAFKA_LISTENERS配置
为了保护Kafka集群安全,那么就要保证Kafka各节点之间的通信安全。每个Kafka节点必须指定一组Listener,用于接收来自客户端和其它Kafka节点的请求。为了对客户端进行身份验证,可以为每个Listener设置一种安全机制,以确保对集群内部或客户端之间的通信进行加密。
通过配置listeners,Kafka节点可以监听多个端口。这个属性可以接收以逗号分隔的Listener列表。必须为每个Kafka节点指定至少一个Listener。Listener的格式如下:
{LISTENER_NAME}://{hostname}:{port}LISTENER_NAME通常是一个见名知意的名称,用于说明Listener的目的。例如,把接收客户端流量的Listener称为CLIENT:
listeners=CLIENT://localhost:9092
Listener的安全协议在单独的配置中指定:
listener.security.protocol.map
这个配置项的值是一个map集合,Listener与安全协议使用冒号分隔,元素之间使用逗号分隔。如此以来就为每个Listener指定了安全协议。例如,指定CLIENTListener将使用SSL,而BROKERListener将使用PLAINTEXT。
listener.security.protocol.map=CLIENT:SSL,BROKER:PLAINTEXT
安全协议有如下选项(不区分大小写):
- PLAINTEXT
- SSL
- SASL_PLAINTEXT
- SASL_SSL
先看PLAINTEXT,该协议不提供安全性,也不需要任何额外的配置
如果每个Listener使用单独的安全协议,也可以使用安全协议名称直接作为listeners中的Listener名称。基于上面的示例,我们可以像下面这样定义:
listeners=SSL://localhost:9092,PLAINTEXT://localhost:9093
建议为Listener提供显式名称,因为这会让每个Listener的用途更清晰。
可以通过inter.broker.listener.name来配置Broker之间通信的Listener。Broker之间的通信主要是分区复制。如果没有指定,则Broker间Listener由security.inter.broker.protocol指定的安全协议确定,缺省为PLAINTEXT。
在KRaft集群中,配置项process.roles用于指定节点的角色,允许指定的角色有broker和controller,或者同时指定二者。配置项inter.broker.listener.name专门用于指定Broker之间的通信使用哪个Listener。另一方面,控制器必须使用单独的Listener,该Listener由controller.listener.names配置。并且与inter.broker.listener.name的值相同。
controller接收来自其它controller节点和broker节点的请求。由于这个原因,即使节点不是控制器角色(即它只是一个Broker),它仍然必须指定控制器Listener以及配置它所需的任何安全属性(译注:controller要知道集群中全部的节点信息,因此指定这个配置项,就可以把broker自身信息上报给controller)。
process.roles=broker # 本节点是broker节点
listeners=BROKER://localhost:9092
inter.broker.listener.name=BROKER
controller.quorum.voters=0@localhost:9093 # 指定全部控制器节点
controller.listener.names=CONTROLLER # 指定控制器Listener
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSL # 指定控制器Listener安全协议上面虽然配置了控制器Listener,但是它并未包含在listeners中,因为broker节点不需要开放控制器Listener。在这种情况下将使用controller.quorum.voters配置的端口。这是投票权配置项,它指定了所有控制器的列表。
对于同时启用broker和controller角色的KRaft集群节点,配置是类似的。唯一的区别是控制器Listener必须包含在listeners中:
process.roles=broker,controller
listeners=BROKER://localhost:9092,CONTROLLER://localhost:9093 # 此处需要同时指定代理Listener和控制器Listener
inter.broker.listener.name=BROKER
controller.quorum.voters=0@localhost:9093
controller.listener.names=CONTROLLER
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSLcontroller.quorum.voters中指定的端口要与listeners列表中公开的控制器Listener之一完全匹配。投票者精确匹配一个公开的控制器Listener。例如,这里CONTROLLERListener绑定到端口9093。然后,由controller.quorum.voters指定的连接字符串也必须使用端口9093。
控制器将接收controller.listener.names指定的任意Listener上的请求。通常只有一个控制器Listener,但也可能有更多。例如,集群通过滚动更新将活动Listener从一个端口或安全协议更改为另一个端口或安全协议的方法(一次滚动公开新的Listener,一次滚动删除旧的Listener)。当指定了多个控制器Listener时,列表中的第一个Listener将用于发送请求。
回归正题
在我们成功搭建好集群后还要测试一下集群是否可用
测试生产消费
# 创建主题
kafka-2:/opt/kafka/bin$ ./kafka-topics.sh --create --topic test-topic --bootstrap-server=10.4.3.41:29092
Created topic test-topic.
# 消息推送
kafka-2:/opt/kafka/bin$ ./kafka-console-producer.sh --bootstrap-server=10.4.3.41:39092 --topic test-topic
>测试消息发送
>123456
# 接受消息
kafka-3:/opt/kafka/bin$ ./kafka-console-consumer.sh --bootstrap-server=10.4.3.41:39092 --topic test-topic --from-beginning
测试消息发送
123456查看集群当前状态参数
# 查看集群信息
kafka-2:/opt/kafka/bin$ ./kafka-metadata-quorum.sh --bootstrap-server 10.4.3.41:29092 describe --status
ClusterId: Some(4L6g3nShT-eMCtK--X86sw)
LeaderId: 3
LeaderEpoch: 3
HighWatermark: 127353
MaxFollowerLag: 0
MaxFollowerLagTimeMs: 17
CurrentVoters: [2,3,4,5]
CurrentObservers: [1]
# 查看节点复制信息
kafka-2:/opt/kafka/bin$ ./kafka-metadata-quorum.sh --bootstrap-server 10.4.3.41:29092 describe --replication
NodeId LogEndOffset Lag LastFetchTimestamp LastCaughtUpTimestamp Status
3 127405 0 1711075091525 1711075091525 Leader
2 127405 0 1711075091320 1711075091320 Follower
4 127405 0 1711075091320 1711075091320 Follower
5 127405 0 1711075091320 1711075091320 Follower
1 127405 0 1711075091319 1711075091319 Observer上面的状态信息反应出了刚刚搭建集群的基本信息,Leader 为 3号节点,2,4,5为从节点,1号节点为broker节点为 观察者只负责对接客户端
kafka生产者Java客户端
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>3.7.0</version>
</dependency>kafka客户端发布record(消息)到kafka集群
新的生产者是线程安全的,在线程之间共享单个生产者实例,通常单例比多个实例要快。
一个简单的例子,使用producer发送一个有序的key/value(键值对),放到java的main方法里就能直接运行
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 测试属性
*
* @author enmalvi
* @date 2024/03/22
*/
public class TestPropertes {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}生产者的缓冲空间池保留尚未发送到服务器的消息,后台I/O线程负责将这些消息转换成请求发送到集群。如果使用后不关闭生产者,则会丢失这些消息。
也就是说,上面的例子,如果我最后不调用producer.close();那么消息是发不出去的,如果加上 Thread.sleep(10000L); 让线程等待一下也是可以的
那这是为什么呢?因为当进程结束时,kafka还有些消息在缓存中来不及发送,所以调用一下close(),告诉kafka生产者客户端立即发送。否则进程直接结束了,那你消息就没了。
假设close()之前,后台还有消息没发送,这时候客户端挂掉了,消息就会丢失。send()可以理解为只是保存消息。
close()方法会将缓存队列状态置为关闭,唤醒io线程将内存中的数据发往broker,如果每次send后都调close方法会不会有问题? 应该是服务停止时才调用close()方法避免消息丢失,而不是每次都去掉用
send()方法是异步的,添加消息到缓冲区等待发送,并立即返回。生产者将单个的消息批量在一起发送来提高效率
ack是判别请求是否为完整的条件(就是是判断是不是成功发送了)。我们指定了“all”将会阻塞消息,这种设置性能最低,但是是最可靠的。
retries,如果请求失败,生产者会自动重试,我们指定是0次,如果启用重试,则会有重复消息的可能性。
producer(生产者)缓存每个分区未发送的消息。缓存的大小是通过 batch.size 配置指定的。值较大的话将会产生更大的批。并需要更多的内存(因为每个“活跃”的分区都有1个缓冲区)。
默认缓冲可立即发送,即便缓冲空间还没有满,但是,如果你想减少请求的数量,可以设置linger.ms大于0。这将指示生产者发送请求之前等待一段时间,希望更多的消息填补到未满的批中。这类似于TCP的算法,例如上面的代码段,可能100条消息在一个请求发送,因为我们设置了linger(逗留)时间为1毫秒,然后,如果我们没有填满缓冲区,这个设置将增加1毫秒的延迟请求以等待更多的消息。需要注意的是,在高负载下,相近的时间一般也会组成批,即使是 linger.ms=0。在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的,更有效的请求。
buffer.memory 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定,之后它将抛出一个TimeoutException。
key.serializer和value.serializer示例,将用户提供的key和value对象ProducerRecord转换成字节,你可以使用附带的ByteArraySerializaer或StringSerializer处理简单的string或byte类型。
send()
public Future<RecordMetadata> send(ProducerRecord<K,V> record,Callback callback)异步发送一条消息到topic,并调用callback(当发送已确认)。
send是异步的,并且一旦消息被保存在等待发送的消息缓存中,此方法就立即返回。这样并行发送多条消息而不阻塞去等待每一条消息的响应。
发送的结果是一个RecordMetadata,它指定了消息发送的分区,分配的offset和消息的时间戳。如果topic使用的是CreateTime,则使用用户提供的时间戳或发送的时间(如果用户没有指定指定消息的时间戳)如果topic使用的是LogAppendTime,则追加消息时,时间戳是broker的本地时间。
由于send调用是异步的,它将为分配消息的此消息的RecordMetadata返回一个Future。如果future调用get(),则将阻塞,直到相关请求完成并返回该消息的metadata,或抛出发送异常。
如果要模拟一个简单的阻塞调用,你可以调用get()方法。
byte[] key = "key".getBytes();
byte[] value = "value".getBytes();
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("my-topic", key, value)
producer.send(record).get();完全无阻塞的话,可以利用回调参数提供的请求完成时将调用的回调通知。
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("the-topic", key, value);
producer.send(myRecord,
new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e != null)
e.printStackTrace();
System.out.println("The offset of the record we just sent is: " + metadata.offset());
}
});
发送到同一个分区的消息回调保证按一定的顺序执行,也就是说,在下面的例子中 callback1 保证执行 callback2 之前:
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1), callback1);
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key2, value2), callback2);注意:callback一般在生产者的I/O线程中执行,所以是相当的快的,否则将延迟其他的线程的消息发送。如果你需要执行阻塞或计算昂贵(消耗)的回调,建议在callback主体中使用自己的Executor来并行处理。
幂等和事务
KafkaProducer又支持两种模式:幂等生产者和事务生产者。
幂等生产者加强了Kafka的交付语义,从至少一次交付到精确一次交付。特别是生产者的重试将不再引入重复。
事务性生产者允许应用程序原子地将消息发送到多个分区(和主题!)。
要启用幂等(idempotence),必须将enable.idempotence配置设置为true。 如果设置,则retries(重试)配置将默认为Integer.MAX_VALUE,acks配置将默认为all。API没有变化,所以无需修改现有应用程序即可利用此功能。
此外,如果send(ProducerRecord)即使在无限次重试的情况下也会返回错误(例如消息在发送前在缓冲区中过期),那么建议关闭生产者,并检查最后产生的消息的内容,以确保它不重复。最后,生产者只能保证单个会话内发送的消息的幂等性。
要使用事务生产者和attendant API,必须设置transactional.id。如果设置了transactional.id,幂等性会和幂等所依赖的生产者配置一起自动启用。此外,应该对包含在事务中的topic进行耐久性配置。特别是,replication.factor应该至少是3,而且这些topic的min.insync.replicas应该设置为2。最后,为了实现从端到端的事务性保证,消费者也必须配置为只读取已提交的消息。
transactional.id的目的是实现单个生产者实例的多个会话之间的事务恢复。它通常是由分区、有状态的应用程序中的分片标识符派生的。因此,它对于在分区应用程序中运行的每个生产者实例来说应该是唯一的。
所有新的事务性API都是阻塞的,并且会在失败时抛出异常。下面的例子说明了新的API是如何使用的。它与上面的例子类似,只是所有100条消息都是一个事务的一部分。
// 设置Kafka生产者的配置属性
Properties props = new Properties();
props.put("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
props.put("enable.idempotence", true); // 启用幂等性
props.put("transactional.id", "my-transactional-id"); // 设置事务ID
// 创建Kafka事务生产者
Producer<String, String> producer = new KafkaProducer<>(props);
// 初始化事务
producer.initTransactions();
try {
producer.beginTransaction(); // 开始事务
// 发送消息
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("test2233", Integer.toString(i), "Message22" + i));
}
producer.commitTransaction(); // 提交事务
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// 无法从这些异常中恢复,只能关闭生产者并退出
producer.close();
} catch (KafkaException e) {
// 对于其他异常,只需中止事务并重试
producer.abortTransaction();
} finally {
producer.close(); // 关闭生产者
}每个生产者只能有一个未完成的事务。在beginTransaction()和commitTransaction()调用之间发送的所有消息都将是单个事务的一部分。当指定transactional.id时,生产者发送的所有消息都必须是事务的一部分。
事务生产者使用异常来传递错误状态。特别是,不需要为producer.send()指定回调,也不需要在返回的Future上调用.get():如果任何producer.send()或事务性调用在事务过程中遇到不可恢复的错误,就会抛出KafkaException。
kafka消费者Java客户端
kafka客户端从kafka集群中获取消息,并透明地处理kafka集群中出现故障broker,透明地调节适应集群中变化的数据分区。也和broker交互,负载平衡消费者。
offset(偏移量)和消费者位置
kafka为分区中的每条消息保存一个偏移量(offset),这个偏移量是该分区中一条消息的唯一标示。也表示消费者在分区的位置。例如,一个位置是5的消费者(说明已经消费了0到4的消息),下一个将接收消息的偏移量为5的消息。实际上这有两个与消费者相关的 “位置” 概念:
消费者的位置给出了下一条消息的偏移量。它比消费者在该分区中看到的最大偏移量要大一个。它在每次消费者在调用poll(Duration)中接收消息时自动增长。
已提交的位置是已安全保存的最后偏移量,如果进程失败或重新启动时,消费者将恢复到这个偏移量。消费者可以选择定期自动提交偏移量,也可以选择通过调用commit API来手动的控制(如:commitSync 和 commitAsync)。
这个主要区别是消费者来控制一条消息什么时候才被认为是已被消费的,控制权在消费者。
消费者组和主题订阅
Kafka的消费者组概念,通过 进程池 瓜分消息并处理消息。这些进程可以在同一台机器运行,也可分布到多台机器上,以增加可扩展性和容错性,相同group.id的消费者将视为同一个消费者组。
组中的每个消费者都通过subscribe API动态的订阅一个topic列表。kafka将已订阅topic的消息发送到每个消费者组中。并通过平衡分区在消费者分组中所有成员之间来达到平均。因此每个分区恰好地分配1个消费者(一个消费者组中)。所以如果一个topic有4个分区,并且一个消费者分组有只有2个消费者。那么每个消费者将消费2个分区。
消费者组的成员是动态维护的:如果一个消费者故障。分配给它的分区将重新分配给同一个分组中其他的消费者。同样的,如果一个新的消费者加入到分组,将从现有消费者中移一个给它。这被称为重新平衡分组。当新分区添加到订阅的topic时,或者当创建与订阅的正则表达式匹配的新topic时,也将重新平衡。将通过定时刷新自动发现新的分区,并将其分配给分组的成员。
从概念上讲,你可以将消费者分组看作是由多个进程组成的单一逻辑订阅者。作为一个多订阅系统,Kafka支持对于给定topic任何数量的消费者组,而不重复。
这是在消息系统中常见的功能的略微概括。所有进程都将是单个消费者分组的一部分(类似传统消息传递系统中的队列的语义),因此消息传递就像队列一样,在组中平衡。与传统的消息系统不同的是,虽然,你可以有多个这样的组。但每个进程都有自己的消费者组(类似于传统消息系统中pub-sub的语义),因此每个进程都会订阅到该主题的所有消息。
此外,当分组重新分配自动发生时,可以通过ConsumerRebalanceListener通知消费者,这允许他们完成必要的应用程序级逻辑,例如状态清除,手动偏移提交等。
它也允许消费者通过使用assign(Collection)手动分配指定分区,如果使用手动指定分配分区,那么动态分区分配和协调消费者组将失效。
发现消费者故障
订阅一组topic后,当调用poll(long)时,消费者将自动加入到组中。只要持续的调用poll,消费者将一直保持可用,并继续从分配的分区中接收消息。此外,消费者向服务器定时发送心跳。 如果消费者崩溃或无法在session.timeout.ms配置的时间内发送心跳,则消费者将被视为死亡,并且其分区将被重新分配。
还有一种可能,消费可能遇到“活锁”的情况,它持续的发送心跳,但是没有处理。为了预防消费者在这种情况下一直持有分区,我们使用max.poll.interval.ms活跃检测机制。 在此基础上,如果你调用的poll的频率大于最大间隔,则客户端将主动地离开组,以便其他消费者接管该分区。
发生这种情况时,你会看到offset提交失败(调用commitSync()引发的CommitFailedException)。这是一种安全机制,保障只有活动成员能够提交offset。所以要留在组中,你必须持续调用poll。
消费者提供两个配置设置来控制poll循环:
-
max.poll.interval.ms:增大poll的间隔,可以为消费者提供更多的时间去处理返回的消息(调用poll(long)返回的消息,通常返回的消息都是一批)。缺点是此值越大将会延迟组重新平衡。 -
max.poll.records:此设置限制每次调用poll返回的消息数,这样可以更容易的预测每次poll间隔要处理的最大值。通过调整此值,可以减少poll间隔,减少重新平衡分组的
对于消息处理时间不可预测地的情况,这些选项是不够的。 处理这种情况的推荐方法是将消息处理移到另一个线程中,让消费者继续调用poll。 但是必须注意确保已提交的offset不超过实际位置。另外,你必须禁用自动提交,并只有在线程完成处理后才为记录手动提交偏移量(取决于你)。 还要注意,你需要pause暂停分区,不会从poll接收到新消息,让线程处理完之前返回的消息(如果你的处理能力比拉取消息的慢,那创建新线程将导致你机器内存溢出)。
示例
自动提交偏移量(Automatic Offset Committing)
这是个【自动提交偏移量】的简单的kafka消费者API。
public class TestConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}设置enable.auto.commit,偏移量由auto.commit.interval.ms控制自动提交的频率。
集群是通过配置bootstrap.servers指定一个或多个broker。不用指定全部的broker,它将自动发现集群中的其余的borker(最好指定多个,万一有服务器故障)。
在这个例子中,客户端订阅了主题my-topic。消费者组叫test。
broker通过心跳机器自动检测test组中失败的进程,消费者会自动ping集群,告诉进群它还活着。只要消费者能够做到这一点,它就被认为是活着的,并保留分配给它分区的权利,如果它停止心跳的时间超过session.timeout.ms,那么就会认为是故障的,它的分区将被分配到别的进程。
这个deserializer设置如何把byte转成object类型,例子中,通过指定string解析器,我们告诉获取到的消息的key和value只是简单个string类型。
手动控制偏移量(Manual Offset Control)
不需要定时的提交offset,可以自己控制offset,当消息认为已消费过了,这个时候再去提交它们的偏移量。这个很有用的,当消费的消息结合了一些处理逻辑,这个消息就不应该认为是已经消费的,直到它完成了整个处理。
public class TestConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
consumer.commitSync();
}
}
}
}
设置enable.auto.commit 为 false , 在处理完数据后提交consumer.commitSync();
使用自动提交也可以“至少一次”。但是要求你必须下次调用poll(Duration)之前或关闭消费者之前,处理完所有返回的数据。如果操作失败,这将会导致已提交的offset超过消费的位置,从而导致丢失消息。使用手动控制offset的有点是,你可以直接控制消息何时提交。
上面的例子使用commitSync表示所有收到的消息为”已提交”,在某些情况下,你可以希望更精细的控制,通过指定一个明确消息的偏移量为“已提交”。在下面,我们的例子中,我们处理完每个分区中的消息后,提交偏移量。
public class TestConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of("my-topic"));
// while (true) {
// ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// for (ConsumerRecord<String, String> record : records) {
// System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
// consumer.commitSync();
// }
// }
try {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
System.out.println("偏移量"+lastOffset);
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
}
}
注意:已提交的offset应始终是你的程序将读取的下一条消息的offset。因此,调用commitSync(offsets)时,你应该加1个到最后处理的消息的offset。
订阅指定的分区(Manual Partition Assignment)
在前面的例子中,我们订阅我们感兴趣的topic,让kafka提供给我们平分后的topic分区。但是,在有些情况下,你可能需要自己来控制分配指定分区,例如:
- 如果这个消费者进程与该分区保存了某种本地状态(如本地磁盘的键值存储),则它应该只能获取这个分区的消息。
- 如果消费者进程本身具有高可用性,并且如果它失败,会自动重新启动(可能使用集群管理框架如YARN,Mesos,或者AWS设施,或作为一个流处理框架的一部分)。 在这种情况下,不需要Kafka检测故障,重新分配分区,因为消费者进程将在另一台机器上重新启动。
要使用此模式,,你只需调用assign(Collection)消费指定的分区即可:
public class TestConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
// props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 自定义分区
String topic = "my-topic";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
// consumer.subscribe(List.of("my-topic"));
// while (true) {
// ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// for (ConsumerRecord<String, String> record : records) {
// System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
// consumer.commitSync();
// }
// }
// 手动提交
try {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
System.out.println("偏移量"+lastOffset);
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
}
}
一旦手动分配分区,你可以在循环中调用poll(跟前面的例子一样)。消费者分组仍需要提交offset,只是现在分区的设置只能通过调用assign修改,因为手动分配不会进行分组协调,因此消费者故障不会引发分区重新平衡。每一个消费者是独立工作的(即使和其他的消费者共享GroupId)。为了避免offset提交冲突,通常你需要确认每一个consumer实例的gorupId都是唯一的。
注意,手动分配分区(即,assgin)和动态分区分配的订阅topic模式(即,subcribe)不能混合使用。
在Kafka之外存储偏移量
消费者可以不使用kafka内置的offset仓库。可以选择自己来存储offset。要注意的是,将消费的offset和结果存储在同一个的系统中,用原子的方式存储结果和offset,但这不能保证原子,要想消费是完全原子的,并提供的“正好一次”的消费保证比kafka默认的“至少一次”的语义要更高。你需要使用kafka的offset提交功能。
- 如果消费的结果存储在
关系数据库中,存储在数据库的offset,让提交结果和offset在单个事务中。这样,事物成功,则offset存储和更新。如果offset没有存储,那么偏移量也不会被更新。 - 如果offset和消费结果存储在本地仓库。例如,可以通过订阅一个指定的分区并将offset和索引数据一起存储来构建一个搜索索引。如果这是以原子的方式做的,常见的可能是,即使崩溃引起未同步的数据丢失。索引程序从它确保没有更新丢失的地方恢复,而仅仅丢失最近更新的消息。
每个消息都有自己的offset,所以要管理自己的偏移,你只需要做到以下几点:
- 配置
enable.auto.commit=false - 使用提供的
ConsumerRecord来保存你的位置。 - 在重启时用
seek(TopicPartition, long)恢复消费者的位置。
当分区分配也是手动完成的,这种类型的使用是最简单的。 如果分区分配是自动完成的,需要特别小心处理分区分配变更的情况。可以通过调用subscribe(Collection,ConsumerRebalanceListener)和subscribe(Pattern,ConsumerRebalanceListener)中提供的ConsumerRebalanceListener实例来完成的。例如,当分区向消费者获取时,消费者将通过实现ConsumerRebalanceListener.onPartitionsRevoked(Collection)来给这些分区提交它们offset。当分区分配给消费者时,消费者通过ConsumerRebalanceListener.onPartitionsAssigned(Collection)为新的分区正确地将消费者初始化到该位置。
ConsumerRebalanceListener的另一个常见用法是清除应用已移动到其他位置的分区的缓存。
控制消费的位置
大多数情况下,消费者只是简单的从头到尾的消费消息,周期性的提交位置(自动或手动)。kafka也支持消费者去手动的控制消费的位置,可以消费之前的消息也可以跳过最近的消息。
有几种情况,手动控制消费者的位置可能是有用的。
一种场景是对于时间敏感的消费者处理程序,对足够落后的消费者,直接跳过,从最近的消费开始消费。
另一个使用场景是本地状态存储系统。在这样的系统中,消费者将要在启动时初始化它的位置(无论本地存储是否包含)。同样,如果本地状态已被破坏(假设因为磁盘丢失),则可以通过重新消费所有数据并重新创建状态(假设kafka保留了足够的历史)在新的机器上重新创建。
kafka使用seek(TopicPartition, long)指定新的消费位置。用于查找服务器保留的最早和最新的offset的特殊的方法也可用(seekToBeginning(Collection) 和 seekToEnd(Collection))。
消费者流量控制
如果消费者分配了多个分区,并同时消费所有的分区,这些分区具有相同的优先级。在一些情况下,消费者需要首先消费一些指定的分区,当指定的分区有少量或者已经没有可消费的数据时,则开始消费其他分区。
例如流处理,当处理器从2个topic获取消息并把这两个topic的消息合并,当其中一个topic长时间落后另一个,则暂停消费,以便落后的赶上来。
kafka支持动态控制消费流量,分别在future的poll(long)中使用pause(Collection) 和 resume(Collection) 来暂停消费指定分配的分区,重新开始消费指定暂停的分区。
读取事务性消息
应用程序可以原子地写入多个主题和分区。为了使之工作,从这些分区读取的消费者应该被配置为只读取已提交的数据。这可以通过在消费者的配置中设置isolation.level=read_committed来实现。
在read_committed模式下,消费者将只读取那些已经成功提交的事务性消息(像读取非事务性消息一样)。在read_committed模式下,没有客户端缓冲。相反,read_committed消费者的分区的结束偏移量是分区中属于一个事务的第一个消息的偏移量。这个偏移被称为 “Last Stable Offset 最后稳定偏移”(LSO)。
一个read_committed消费者将只读到LSO,并过滤掉任何已经中止的事务性消息。LSO也会影响read_committed消费者的seekToEnd(Collection)和endOffsets(Collection)的行为。最后,对于read_committed消费者来说,取数lag(滞后指标)也被调整为相对LSO。
带有事务性消息的分区将包括提交或中止标记,这些标记表示事务的结果。那里的标记不会返回给应用程序,但在log中却有一个偏移量。因此,应用程序从带有事务消息的主题中读取时,会在消耗的偏移量中看到空白。这些缺失的消息将是事务标记,它们在两个隔离级别中为消费者过滤掉。此外,使用 read_committed 消费者的应用程序也可能会看到由于中止的事务而产生的空隙,因为这些消息不会被消费者返回,但确实是有效的偏移量。
kafka中的ACKS LSO LEO LW HW AR ISR OSR
- ACKS(Acknowledgments)确认、回执
- LSO(Log start offset)起始偏移量
- LW(Low watermark)低水位
- HW(High watermark)高水位
- LEO(Log end offset)日志末尾偏移量
- AR(Assigned replica)分配的副本
- ISR(In sync replica)正常同步的副本
- OSR(Out sync replica)非正常同步的副本
Replica,Leader,Follower 的关系
- Replica(包括Leader和Follower) :副本,同一分区的不同副本保存的是相同的消息,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- Leader (主池子):每个分区的多个副本中的”主副本”,生产者以及消费者只与 Leader 交互。
- Follower (从池子):每个分区的多个副本中的”从副本”,负责实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,从 Follower 副本中重新选举新的 Leader 副本对外提供服务。
ACKS三种类型
生产者(Producer)向Broker发送消息时,可以配置等待确认ACKS(Acknowledgments)的策略0、1和-1。
- 0代表不等待Broker确认,在这种情况下,不能保证服务器已经收到了记录。
- -1和1都需要等待Broker返回确认。
- 1代表这个确认是Broker将消息写到主(Leader)磁盘后返回,不用等待从(Follower)同步。
- -1则代表应答需要等待所有正常同步的副本ISR(In sync replica)写到消息日志(Log)后才会返回。
ISR的最坏情况
排除所有replica全部故障,ISR的最坏情况就是ISR中只剩leader自己一个了。
退化成 ack = 1的情况了,甚至还不如ack=1。
ack=1,说的是producer不等服务端完全同步完ISR,只要leader写入成功就行了,但是可没说不进行同步了。
该有的同步过程还是会进行的,但凡能同步,Kafka肯定会同步的,而ack=1的最坏情况,也是ISR中只剩下leader了。
AR、ISR、OSR
分区中的所有副本统称为AR(Assigned Repllicas)。
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。
消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度”是指可以忍受的滞后范围,这个范围可以通过参数进行配置。
与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas),由此可见:AR=ISR+OSR。在正常情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
Leader副本负责维护和跟踪ISR集合中所有的follower副本的滞后状态,当follower副本落后太多或者失效时,leader副本会吧它从ISR集合中剔除。如果OSR集合中follower副本“追上”了Leader副本,之后再ISR集合中的副本才有资格被选举为leader,而在OSR集合中的副本则没有机会(这个原则可以通过修改对应的参数配置来改变)
ISR机制
ISR 的核心就是:动态调整
因为ISR的机制就保证了,处于ISR内部的follower都是可以和leader进行同步的,一旦出现故障或延迟,就会被踢出ISR。
Kafka在启动的时候会开启两个与ISR相关的定时任务,名称分别为“isr-expiration”和”isr-change-propagation”.。isr-expiration任务会周期性的检测每个分区是否需要缩减其ISR集合。这个周期和“replica.lag.time.max.ms”参数有关。当检测到ISR中有是失效的副本的时候,就会缩减ISR集合。
-
replica.lag.time.max.ms从 10 秒增加到 30 秒。 - 配置参数
replica.lag.time.max.ms现在不仅指自上次从副本获取请求以来经过的时间,还指自副本上次赶上以来的时间。仍在从领导者获取消息但未赶上replica.lag.time.max.ms中最新消息的副本将被视为不同步。假设我们设置replica.lag.time.max.ms为5000毫秒(即5秒)。这意味着副本必须在主节点生成消息后的5秒内获取到该消息,并且在这5秒内还要完成追赶主节点的操作,否则将被视为不同步。
什么叫还要完成追赶主节点的操作,目前的理解是,并不是说 只要在 replica.lag.time.max.ms 时间内 follower 有同步消息,即认为该 follower 处于 ISR 中
因为这里还涉及一个速率问题(你理解为蓄水池一个放水一个注水的问题)。
如果leader副本的消息流入速度大于follower副本的拉取速度时,你follower就是实时同步有什么用?
典型的出工不出力,消息只会越差越多,这种follower肯定是要被踢出ISR的。
当follower副本将leader副本的LEO之前的日志全部同步时,则认为该follower副本已经追赶上leader副本。
此时更新该副本的lastCaughtUpTimeMs标识。
Kafka的副本管理器(ReplicaManager)启动时会启动一个副本过期检测的定时任务,
会定时检查当前时间与副本的lastCaughtUpTimeMs差值是否大于参数replica.lag.time.max.ms指定的值。
所以replica.lag.time.max.ms的正确理解是:
follower在过去的replica.lag.time.max.ms时间内,已经追赶上leader一次了。
follower 什么时候出问题
两个方面,一个是Kafka自身的问题,另一个是外部原因
Kafka源码注释中说明了一般有两种情况会导致副本失效:
- follower副本进程卡住,在一段时间内根本没有想leader副本发起同步请求,比如频繁的Full GC。
- follower副本进程同步过慢,在一段时间内都无法追赶上leader副本,比如IO开销过大。
或者是
- 通过工具增加了副本因子,那么新增加的副本在赶上leader副本之前也都是处于失效状态的。
- 如果一个follower副本由于某些原因(比如宕机)而下线,之后又上线,在追赶上leader副本之前也是出于失效状态。
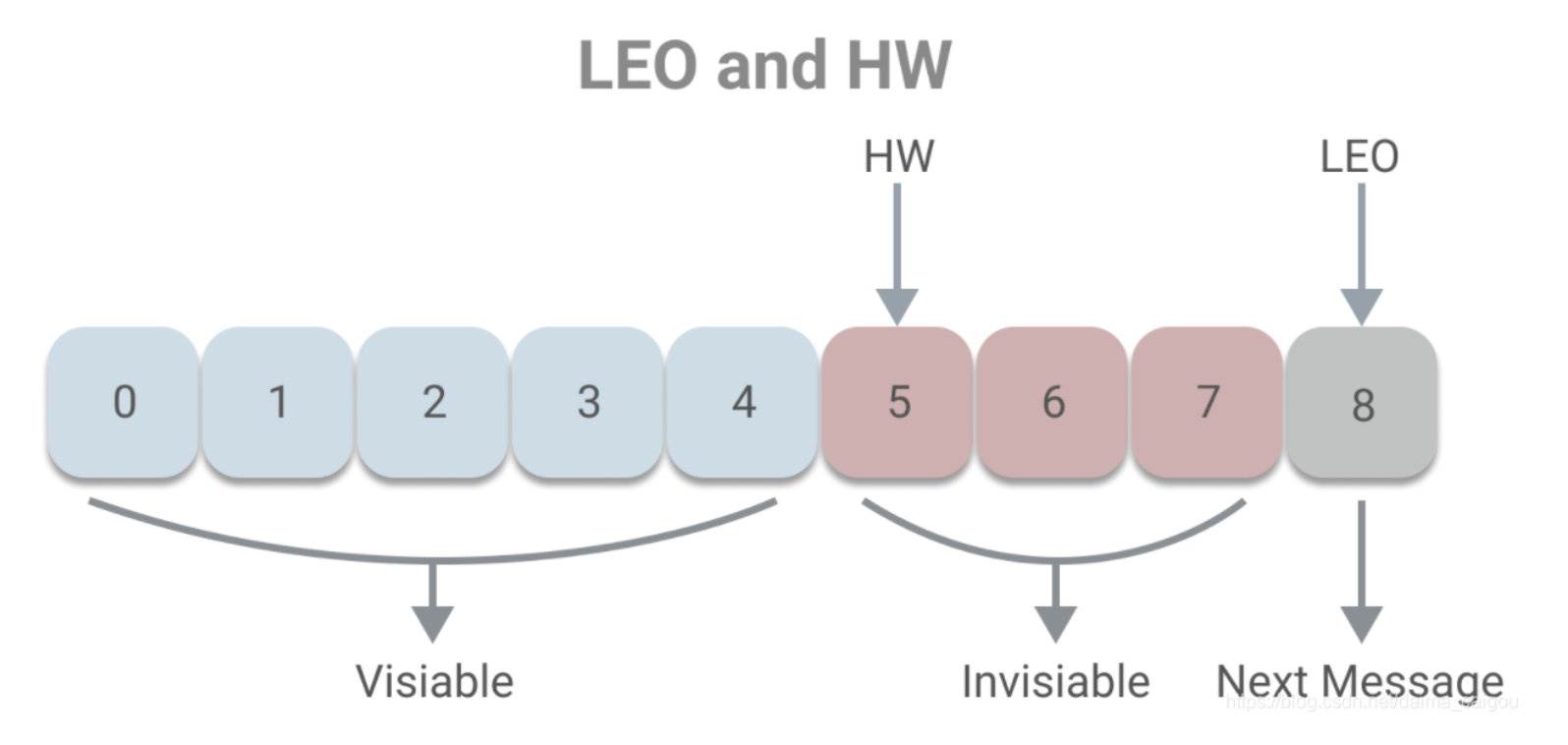
HW、LEO、LSO、LW
LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。
分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费这而言只能消费HW之前的消息。
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW, consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。
对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW, 此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。
LW是Low Watermark的缩写,俗称“低水位”,代表AR集合中最小的logStartOffset值,副本的拉取请求(FetchRequest,它有可能触发新建日志分段而旧的的被清理,进而导致logStartoffset的增加) 和删除请求(DeleteRecordRequest)都可能促使LW的增长。

LSO特指LastStableOffset。
消费端参数——isolation.level,这个参数用来配置消费者事务的隔离级别。字符串类型,“read_uncommitted”和“read_committed”,表示消费者所消费到的位置,如果设置为“read_committed“,那么消费这就会忽略事务未提交的消息,既只能消费到LSO(LastStableOffset)的位置,默认情况下,”read_uncommitted“,既可以消费到HW(High Watermak)的位置。
注:follower副本的事务隔离级别也为“read_uncommitted“,并且不可修改。
在开启kafka事务的同时,生产者发送了若干消息,(msg1,msg2)到broker中,如果生产者没有提交事务(执行CommitTransaction),那么对于isolation.level=read_committed的消费者而言是看不多这些消息的,而isolation.level=read_uncommitted则可以看到。事务中的第一条消息的位置可以标记为firstUnstableOffset(也就是msg1的位置)。
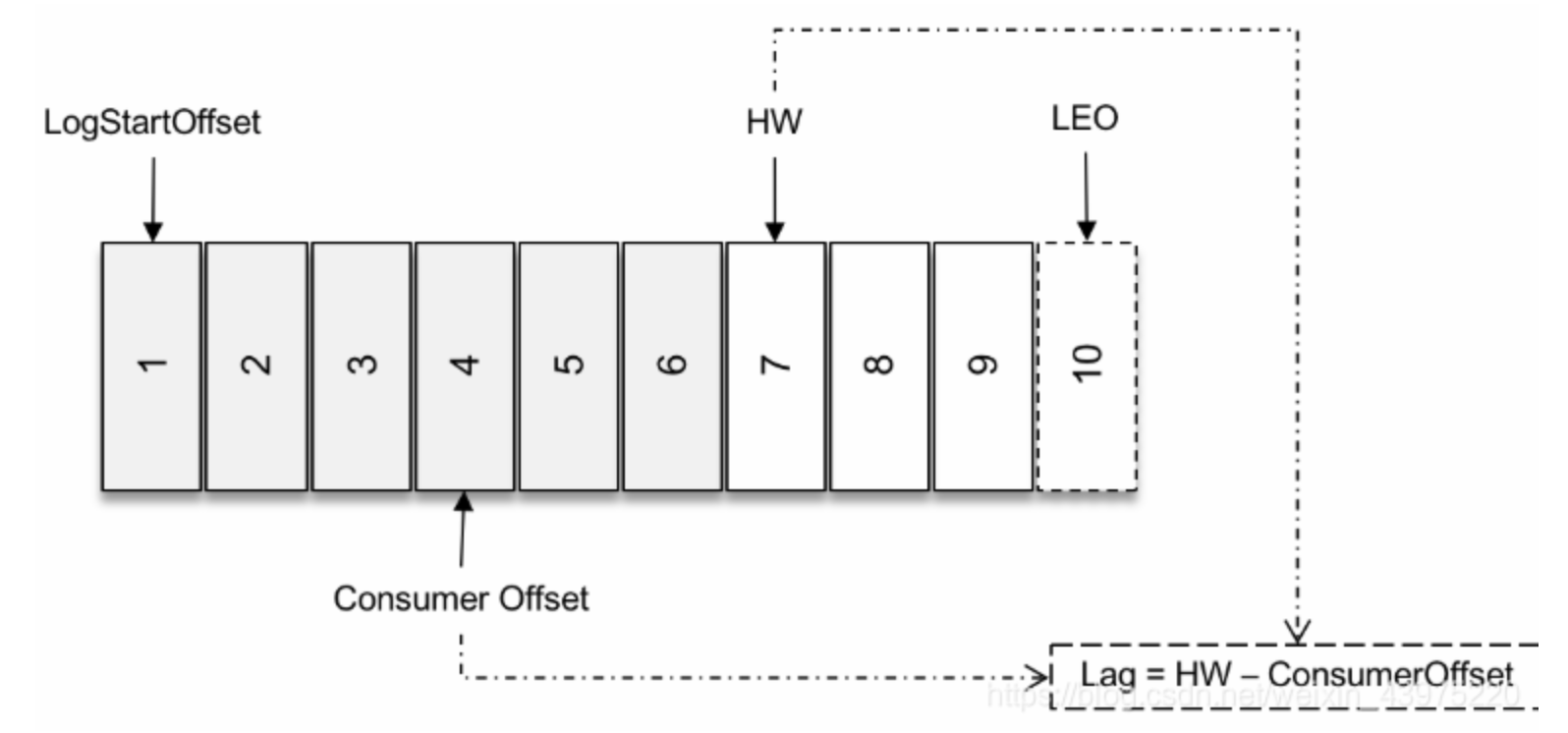
对每一个分区而言,它Lag等于HW-ConsumerOffset的值,其中ComsmerOffset表示当前的消费的位移,当然这只是针对普通的情况。如果为消息引入了事务,那么Lag的计算方式就会有所不同。
如果当消费者客户端的isolation.level的参数配置为“read_uncommitted“(默认),那么Lag的计算方式不受影响,如果这个参数配置为“read_committed“,那么就要引入LSO来进行计算了。
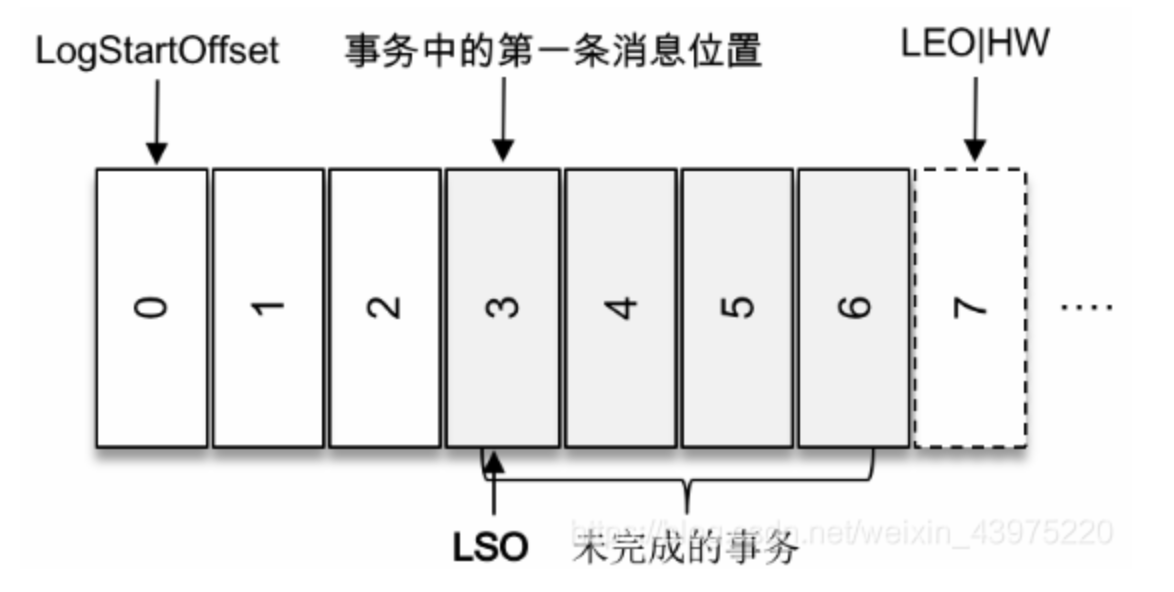
对于未完成的事务而言,LSO的值等于事务中的第一条消息所在的位置,(firstUnstableOffset)
对于已经完成的事务而言,它的值等同于HW相同,所以我们可以得出一个结论:LSO≤HW≤LEO
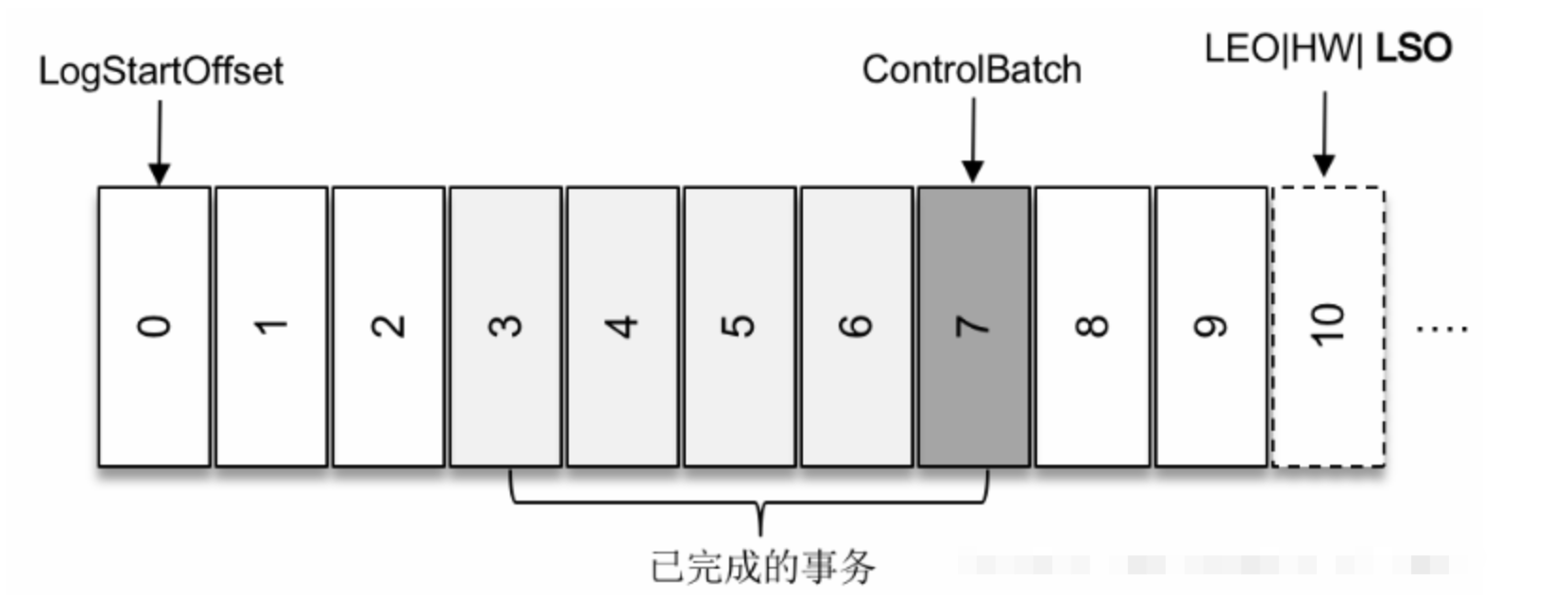
对于分区中未完成的事务,并且消费者客户端的isolation.level参数配置为”read_committed“的情况,它对应的Lag等于LSO-ComsumerOffset的值。
多线程处理
Kafka消费者不是线程安全的。所有网络I/O都发生在进行调用应用程序的线程中。用户的责任是确保多线程访问正确同步的。非同步访问将导致ConcurrentModificationException。
此规则唯一的例外是wakeup(),它可以安全地从外部线程来中断活动操作。在这种情况下,将从操作的线程阻塞并抛出一个WakeupException。这可用于从其他线程来关闭消费者。 以下代码段显示了典型模式:
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public KafkaConsumerRunner(KafkaConsumer consumer) {
this.consumer = consumer;
}
@Override
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(10000));
// Handle new records
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
在单独的线程中,可以通过设置关闭标志和唤醒消费者来关闭消费者。
closed.set(true);
consumer.wakeup();Kafka Streams客户端
Kafka Streams从一个或多个输入topic进行连续的计算并输出到0或多个外部topic中。
- 流式计算:输入是持续的,一般先定义目标计算,然后数据到来之后将计算逻辑应用于数据,往往用增量计算代替全量计算。
- 批量计算:一般先有全量数据集,然后定义计算逻辑,并将计算应用于全量数据。特点是全量计算,并且计算结果一次性全量输出。
KTable和KSteam
KTable和KSteam是Kafka中非常重要的概念,在此分析一下二者区别。
- KStream是一个数据流,可以认为所有的记录都通过Insert only的方式插入进这个数据流中。
- KTable代表一个完整的数据集,可以理解为数据库中的表。每条记录都是KV键值对,key可以理解为数据库中的主键,是唯一的,而value代表一条记录。我们可以认为KTable中的数据时通过Update only的方式进入的。如果是相同的key,会覆盖掉原来的那条记录。
- 综上来说,KStream是数据流,来多少数据就插入多少数据,是Insert only;KTable是数据集,相同key只允许保留最新的记录,也就是Update only
Kafka支持三种时间
- 事件发生时间:事件发生的时间,包含在数据记录中。发生时间由Producer在构造ProducerRecord时指定。并且需要Broker或者Topic将message.timestamp.type设置为CreateTime(默认值)才能生效。
- 消息接收时间:也即消息存入Broker的时间。当Broker或Topic将message.timestamp.type设置为LogAppendTime时生效。此时Broker会在接收到消息后,存入磁盘前,将其timestamp属性值设置为当前机器时间。一般消息接收时间比较接近于事件发生时间,部分场景下可代替事件发生时间。
- 消息处理时间。也即Kafka Stream处理消息时的时间。
流式数据在时间上无界的,但是聚合操作只能作用在特定(有界)的数据集,咋整?这时候就有了窗口的概念,在时间无界的数据流中定义一个边界来用于计算。
Kafka支持的窗口如下
- Hopping Time Window:举一个典型的应用场景,每隔5秒钟输出一次过去1个小时内网站的PV或者UV。里面有两个时间1小时和5秒钟,1小时指定了窗口的大小(Window size),5秒钟定义输出的时间间隔(Advance interval)。
- Tumbling Time Window:可以认为是Hopping Time Window的一种特例,窗口大小=输出时间间隔,它的特点是各个Window之间完全不相交。
- Sliding Window该窗口只用于2个KStream进行Join计算时。该窗口的大小定义了Join两侧KStream的数据记录被认为在同一个窗口的最大时间差。假设该窗口的大小为5秒,则参与Join的2个KStream中,记录时间差小于5的记录被认为在同一个窗口中,可以进行Join计算。
- Session Window该窗口用于对Key做Group后的聚合操作中。它需要对Key做分组,然后对组内的数据根据业务需求定义一个窗口的起始点和结束点。一个典型的案例是,希望通过Session Window计算某个用户访问网站的时间。对于一个特定的用户(用Key表示)而言,当发生登录操作时,该用户(Key)的窗口即开始,当发生退出操作或者超时时,该用户(Key)的窗口即结束。窗口结束时,可计算该用户的访问时间或者点击次数等。
Stream 示例
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>3.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.7.0</version>
</dependency>1、将topicA的数据写入到topicB中(纯复制)
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class MyStream {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"mystream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); //输入key的类型
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass()); //输入value的类型
//创建流构造器
StreamsBuilder builder = new StreamsBuilder();
//构建好builder,将myStreamIn topic中的数据写入到myStreamOut topic中
builder.stream("myStreamIn").to("myStreamOut");
final Topology topo=builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}往myStreamIn topic里发生数据,经过处理会转发至 myStreamOut
2、将TopicA中的数据实现wordcount写入到TopicB
工作中不可能像案例一一样将一个Topic的数据原封不动存入另一个Topic,一般是要经过处理,这就需要在流中加上逻辑。
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.KTable;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCountStream {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"wordcountstream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,2000); //提交时间设置为2秒
//prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,""earliest ); //earliest latest none 默认latest
//prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); //true(自动提交) false(手动提交)
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
//创建流构造器
//hello world
//hello java
StreamsBuilder builder = new StreamsBuilder();
KTable<String, Long> count = builder.stream("wordcount-input") //从kafka中一条一条取数据
.flatMapValues( //返回压扁后的数据
(value) -> { //对数据按空格进行切割,返回List集合
String[] split = value.toString().split(" ");
List<String> strings = Arrays.asList(split);
return strings;
}) //null hello,null world,null hello,null java
.map((k, v) -> {
return new KeyValue<String, String>(v,"1");
}).groupByKey().count();
count.toStream().foreach((k,v)->{
//为了测试方便,我们将kv输出到控制台
System.out.println("key:"+k+" "+"value:"+v);
});
count.toStream().map((x,y)->{
return new KeyValue<String,String>(x,y.toString()); //注意转成toString类型,我们前面设置的kv的类型都是string类型
}).to("wordcount-output");
final Topology topo=builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}发生消息为 null hello,null world,null hello,null java , 发送4次,示例是按空格区分统计,结果为:
key:null value:4
key:world,null value:4
key:hello,null value:8
key:java value:43、在TopicA中每输入一个值求和并写入到TopicB
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class SumStream {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"sumstream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,2000); //提交时间设置为2秒
//prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //earliest latest none 默认latest
//prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); //true(自动提交) false(手动提交)
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
//创建流构造器
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> source = builder.stream("suminput");
KTable<String, String> sum1 = source.map((key, value) ->
new KeyValue<String, String>("sum", value.toString())
).groupByKey().reduce((x, y) -> {
System.out.println("x: " + x + " " + "y: "+y);
Integer sum = Integer.valueOf(x) + Integer.valueOf(y);
System.out.println("sum: "+sum);
return sum.toString();
});
sum1.toStream().to("sumout");
final Topology topo=builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}发送的数据 为 1 ,可以发送很多次,结果为:
x: 1 y: 1
sum: 2
x: 2 y: 1
sum: 3
x: 3 y: 1
sum: 4
x: 4 y: 1
sum: 5窗口案例
4.1、每隔2秒钟输出一次过去5秒内topicA里的wordcount,结果写入到TopicB
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WindowStream {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"WindowStream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000); //提交时间设置为3秒
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> source = builder.stream("topicA");
KTable<Windowed<String>, Long> countKtable = source.flatMapValues(value -> Arrays.asList(value.toString().split("s+")))
.map((x, y) -> {
return new KeyValue<String, String>(y, "1");
}).groupByKey()
//加5秒窗口,按步长2秒滑动 Hopping Time Window
.windowedBy(TimeWindows.of(Duration.ofDays(Duration.ofSeconds(5).toMillis())).advanceBy(Duration.ofDays(Duration.ofSeconds(2).toMillis())))
// .windowedBy(SessionWindows.with(Duration.ofDays(Duration.ofSeconds(15).toMillis())))
.count();
//为了方便查看,输出到控制台
countKtable.toStream().foreach((x,y)->{
System.out.println("x: "+x+" y: "+y);
});
countKtable.toStream().map((x,y)-> {
return new KeyValue<String, String>(x.toString(), y.toString());
}).to("topicB");
final Topology topo=builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}往 topicA 里发送数据,topicB 接收数据
4.2、每隔5秒钟输出一次过去5秒内topicA里的wordcount,结果写入到TopicB
加5秒窗口,与上面不同的是,前一个5秒与下一个5秒没有任何交叉
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WindowStream2 {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"WindowStream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000); //提交时间设置为3秒
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> source = builder.stream("topicA");
KTable<Windowed<String>, Long> countKtable = source.flatMapValues(value -> Arrays.asList(value.toString().split("s+")))
.map((x, y) -> {
return new KeyValue<String, String>(y, "1");
}).groupByKey()
//加五秒的窗口(前一个5秒和下一个5秒没有任何交叉) Tumbling Time Window
.windowedBy(TimeWindows.of(Duration.ofDays(Duration.ofSeconds(5).toMillis())))
.count();
countKtable.toStream().foreach((x,y)->{
System.out.println("x: "+x+" y: "+y);
});
countKtable.toStream().map((x,y)-> {
return new KeyValue<String, String>(x.toString(), y.toString());
}).to("topicB");
final Topology topo=builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}测试方式和上一个一样
4.3、TopicA 15秒内的wordcount,结果写入TopicB
比如登录某app,20分钟内不操作,会自动退出。
一个典型的案例是,希望通过Session Window计算某个用户访问网站的时间。对于一个特定的用户(用Key表示)而言,当发生登录操作时,该用户(Key)的窗口即开始,当发生退出操作或者超时时,该用户(Key)的窗口即结束。窗口结束时,可计算该用户的访问时间或者点击次数等。
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WindowStream3 {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"WindowStream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000); //提交时间设置为3秒
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> source = builder.stream("topicA");
KTable<Windowed<String>, Long> countKtable = source.flatMapValues(value -> Arrays.asList(value.toString().split("s+")))
.map((x, y) -> {
return new KeyValue<String, String>(y, "1");
}).groupByKey()
.windowedBy(SessionWindows.with(Duration.ofDays(Duration.ofSeconds(15).toMillis())))
.count();
countKtable.toStream().foreach((x,y)->{
System.out.println("x: "+x+" y: "+y);
});
countKtable.toStream().map((x,y)-> {
return new KeyValue<String, String>(x.toString(), y.toString());
}).to("topicB");
final Topology topo=builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}Java管理kafka集群
Kafka的管理Java客户端,支持管理和检查topic、broker、配置和ACL。
创建Topic
private static void createTopics1() {
Properties properties = new Properties();
properties.put("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
properties.put("connections.max.idle.ms", 10000);
properties.put("request.timeout.ms", 5000);
try (AdminClient client = AdminClient.create(properties)) {
CreateTopicsResult result = client.createTopics(Arrays.asList(
new NewTopic("topic1R", 1, (short) 1),
new NewTopic("topic2R", 1, (short) 1),
new NewTopic("topic3R", 1, (short) 1)
));
try {
result.all().get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
}topic列表
private static void listTopics() {
Properties properties = new Properties();
properties.put("bootstrap.servers", "10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
properties.put("connections.max.idle.ms", 10000);
properties.put("request.timeout.ms", 5000);
try (AdminClient client = AdminClient.create(properties)) {
ListTopicsResult result = client.listTopics();
try {
result.listings().get().forEach(topic -> {
System.out.println(topic);
});
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
}
输出结果:
(name=topic1R, topicId=DNFrdpC0TPCACp7OM7emKQ, internal=false)
(name=topicA, topicId=JKCDyIsDTamDk0hUqbJV6A, internal=false)
(name=topicB, topicId=83eZPpVWQiSCX2-uO1gNUg, internal=false)
(name=topic1R2, topicId=K_-rnOsKSKmBD5j088jHBg, internal=false)
(name=streams-wordcount-counts-store-repartition, topicId=LOCZb55KTlShtBsfPLVynA, internal=false)
(name=topic2R2, topicId=qXXwrFSCRm2vQX5y76AK7Q, internal=false)
(name=topic3R2, topicId=tKWU5uCkSE-xIpHWCZCDlw, internal=false)
(name=test-zlm01, topicId=X-y8HhB0Tyy3N8QG3H14zg, internal=false)
(name=topic3R, topicId=4uiduc5cTx--ROg01eONgg, internal=false)
(name=streams-wordcount-KSTREAM-AGGREGATE-STATE-STORE-0000000004-changelog, topicId=1ogTVUjKTzex_a3ruWoGhQ, internal=false)
(name=streams-wordcount-output, topicId=EFLmB5QoRQCjLyF0JMme2A, internal=false)增加分区
private static void addPartition(){
Properties properties = new Properties();
properties.put("bootstrap.servers","10.4.3.41:29092,10.4.3.41:39092,10.4.3.41:49092");
properties.put("connections.max.idle.ms", 10000);
properties.put("request.timeout.ms", 5000);
try (AdminClient client = AdminClient.create(properties)) {
Map newPartitions = new HashMap<>();
// 增加到2个
newPartitions.put("topic1", NewPartitions.increaseTo(2));
CreatePartitionsResult rs = client.createPartitions(newPartitions);
try {
rs.all().get();
} catch (InterruptedException | ExecutionException e) {
throw new IllegalStateException(e);
}
}
}Kafka Broker配置
kafka >= 0.10
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
| zookeeper.connect | 以hostname:port的形式指定ZooKeeper连接字符串,其中host和port是ZooKeeper服务器的主机和端口。为了使得单个ZooKeeper机器宕机时通过其他ZooKeeper节点进行连接,你也可以以hostname1:port1,hostname2:port2,hostname3:port3的形式指定多个,提高可用性。也可以将ZooKeeper chroot路径作为其ZooKeeper连接字符串的一部分,将其数据放在全局ZooKeeper命名空间的某个路径下。例如,要提供一个 /chroot/path的chroot路径,你可以将连接字符串设为hostname1:port1,hostname2:port2,hostname3:port3/chroot/path。 |
string | null | 高 | |
| advertised.host.name | 已弃用:当advertised.listeners或listeners没设置时候才使用。请改用advertised.listeners。Hostname发布到Zookeeper供客户端使用。在IaaS环境中,Broker可能需要绑定不同的接口。如果没有设置,将会使用host.name(如果配置了)。否则将从java.net.InetAddress.getCanonicalHostName()获取。 |
string | null | 高 | |
| advertised.listeners | 发布给Zookeeper供客户端使用的监听地址(如果与 listeners 配置属性不同)。在IaaS环境中,broker可能需要绑定不同的接口。如果没设置,则使用listeners。与listeners不同是,0.0.0.0元地址是无效的。同样与listeners不同的是,此属性中可以有重复的端口,因此可以将一个listener配置为通告另一个listener的地址。 这在使用外部负载平衡器的某些情况下很有用。 |
string | null | 高 | |
| advertised.port | 过时的:当advertised.listeners或listeners没有设置才使用。请改用advertised.listeners。端口发布到Zookeeper供客户端使用,在IaaS环境中,broker可能需要绑定到不同的端口。如果没有设置,将和broker绑定的同一个端口。 |
int | null | 高 | |
| auto.create.topics.enable | 启用自动创建topic | boolean | true | 高 | |
| auto.leader.rebalance.enable | 启用自动平衡leader。如果需要,后台线程会定期检查并触发leader平衡。 | boolean | true | 高 | |
| background.threads | 用于各种后台处理任务的线程数 | int | 10 | [1,…] | 高 |
| broker.id | 服务器的broker id。如果未设置,将生成一个独一无二的broker id。要避免zookeeper生成的broker id和用户配置的broker id冲突,从reserved.broker.max.id + 1开始生成。 | int | -1 | 高 | |
| compression.type | 为给定topic指定最终的压缩类型。支持标准的压缩编码器(’gzip’, ‘snappy’, ‘lz4’)。也接受’未压缩’,就是没有压缩。保留由producer设置的原始的压缩编码。 | string | producer | 高 | |
| delete.topic.enable | 启用删除topic。如果此配置已关闭,通过管理工具删除topic将没有任何效果 | boolean | false | 高 | |
| host.name | 不赞成:当listeners没有设置才会使用。请改用listeners。如果设置,它将只绑定到此地址。如果没有设置,它将绑定到所有接口 |
string | “” | 高 | |
| leader.imbalance.check.interval.seconds | 由控制器触发分区再平衡检查的频率 | long | 300 | 高 | |
| leader.imbalance.per.broker.percentage | 允许每个broker的leader比例不平衡。如果每个broker的值高于此值,控制器将触发leader平衡,该值以百分比的形式指定。 | int | 10 | 高 | |
| listeners | 监听列表 – 监听的URL列表和协议(逗号分隔)。如果侦听协议不是安全协议,则还必须设置 listener.security.protocol.map。 监听的协议名称和端口号必须是唯一的。 将hostname留空则绑定到默认接口,将hostname留空则绑定到默认接口 合法的listener列表是: PLAINTEXT://myhost:9092,SSL://:9091 CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093 |
string | PLAINTEXT://:9092 | 高 | |
| log.dir | 保存日志数据的目录 (补充log.dirs属性) | string | /tmp/kafka-logs | 高 | |
| log.dirs | 保存日志数据的目录。如果未设置,则使用log.dir中的值 | string | null | 高 | |
| log.flush.interval.messages | 消息刷新到磁盘之前,累计在日志分区的消息数 | long | 9223372036854775807 | [1,…] | 高 |
| log.flush.interval.ms | topic中的消息在刷新到磁盘之前保存在内存中的最大时间(以毫秒为单位),如果未设置,则使用log.flush.scheduler.interval.ms中的值 | null | 高 | ||
| log.flush.offset.checkpoint.interval.ms | 我们更新的持续记录的最后一次刷新的频率。作为日志的恢复点。 | int | 60000 | [0,…] | 高 |
| log.flush.scheduler.interval.ms | 日志刷新的频率(以毫秒为单位)检查是否有任何日志需要刷新到磁盘 | long | 9223372036854775807 | 高 | |
| log.retention.bytes | 删除日志之前的最大大小 | long | -1 | 高 | |
| log.retention.hours | 删除日志文件保留的小时数(以小时为单位)。第三级是log.retention.ms属性 | int | 168 | 高 | |
| log.retention.minutes | 删除日志文件之前保留的分钟数(以分钟为单位)。次于log.retention.ms属性。如果没设置,则使用log.retention.hours的值。 | int | null | 高 | |
| log.retention.ms | 删除日志文件之前保留的毫秒数(以毫秒为单位),如果未设置,则使用log.retention.minutes的值。 | long | null | 高 | |
| log.roll.hours | 新建一个日志段的最大时间(以小时为单位),次于log.roll.ms属性。 | int | 168 | [1,…] | 高 |
| log.roll.jitter.hours | 从logRollTimeMillis(以小时为单位)减去最大抖动,次于log.roll.jitter.ms属性。 | int | 0 | [0,…] | 高 |
| log.roll.ms | 新建一个日志段之前的最大事时间(以毫秒为单位)。如果未设置,则使用log.roll.hours的值。 | long | null | 高 | |
| log.segment.bytes | 单个日志文件的最大大小 | int | 1073741824 | [14,…] | 高 |
| log.segment.delete.delay.ms | 从文件系统中删除文件之前的等待的时间 | long | 60000 | [0,…] | 高 |
| message.max.bytes | 服务器可以接收的消息的最大大小 | int | 1000012 | [0,…] | 高 |
| min.insync.replicas | 当producer设置acks为”all”(或”-1″)时。min.insync.replicas指定必须应答成功写入的replicas最小数。如果不能满足最小值,那么producer抛出一个异常(NotEnoughReplicas或NotEnoughReplicasAfterAppend)。 当一起使用时,min.insync.replicas和acks提供最大的耐用性保证。一个典型的场景是创建一个复制因子3的topic,设置min.insync.replicas为2,并且ack是“all”。如果多数副本没有接到写入时,将会抛出一个异常。 |
int | 1 | [1,…] | 高 |
| num.io.threads | 服务器用于执行网络请求的io线程数 | int | 8 | [1,…] | 高 |
| num.network.threads | 服务器用于处理网络请求的线程数。 | int | 3 | [1,…] | 高 |
| num.recovery.threads.per.data.dir | 每个数据的目录线程数,用于启动时日志恢复和关闭时flush。 | int | 1 | [1,…] | 高 |
| num.replica.fetchers | 从源broker复制消息的提取线程数。递增该值可提高follower broker的I/O的并发。 | int | 1 | 高 | |
| offset.metadata.max.bytes | offset提交关联元数据条目的最大大小 | int | 4096 | 高 | |
| offsets.commit.required.acks | commit之前需要的应答数,通常,不应覆盖默认的(-1) | short | -1 | 高 | |
| offsets.commit.timeout.ms | Offset提交延迟,直到所有副本都收到提交或超时。 这类似于生产者请求超时。 | int | 5000 | [1,…] | 高 |
| offsets.load.buffer.size | 当加载offset到缓存时,从offset段读取的批量大小。 | int | 5242880 | [1,…] | 高 |
| offsets.retention.check.interval.ms | 检查过期的offset的频率。 | long | 600000 | [1,…] | 高 |
| offsets.retention.minutes | 当一个消费者组失去其所有消费者后(即为空时),其偏移量在被丢弃前将被保留这个保留期。对于独立的消费者(使用手动分配),偏移量将在最后一次提交的时间加上这个保留期后过期。 | int | 10080 | [1,…] | 高 |
| offsets.topic.compression.codec | 压缩编码器的offset topic – 压缩可以用于实现“原子”提交 | int | 0 | 高 | |
| offsets.topic.num.partitions | offset commit topic的分区数(部署之后不应更改) | int | 50 | [1,…] | 高 |
| offsets.topic.replication.factor | offset topic复制因子(ps:就是备份数,设置的越高来确保可用性)。为了确保offset topic有效的复制因子,第一次请求offset topic时,活的broker的数量必须最少最少是配置的复制因子数。 如果不是,offset topic将创建失败或获取最小的复制因子(活着的broker,复制因子的配置) | short | 3 | [1,…] | 高 |
| offsets.topic.segment.bytes | offset topic段字节应该相对较小一点,以便于加快日志压缩和缓存加载 | int | 104857600 | [1,…] | 高 |
| port | 不赞成:当listener没有设置才使用。请改用listeners。该port监听和接收连接。 |
int | 9092 | 高 | |
| queued.max.requests | 在阻塞网络线程之前允许的排队请求数 | int | 500 | [1,…] | 高 |
| quota.consumer.default | 过时的:当默认动态的quotas没有配置或在Zookeeper时。如果每秒获取的字节比此值高,所有消费者将通过clientId/consumer区分限流。 | long | 9223372036854775807 | [1,…] | 高 |
| quota.producer.default | 过时的:当默认动态的quotas没有配置,或在zookeeper时。如果生产者每秒比此值高,所有生产者将通过clientId区分限流。 | long | 9223372036854775807 | [1,…] | 高 |
| replica.fetch.min.bytes Minimum | 每个获取响应的字节数。如果没有满足字节数,等待replicaMaxWaitTimeMs。 | int | 1 | 高 | |
| replica.fetch.wait.max.ms | 跟随者副本发出每个获取请求的最大等待时间,此值应始终小于replica.lag.time.max.ms,以防止低吞吐的topic的ISR频繁的收缩。 | int | 500 | 高 | |
| replica.high.watermark. checkpoint.interval.ms |
达到高“水位”保存到磁盘的频率。 | long | 5000 | 高 | |
| replica.lag.time.max.ms | 如果一个追随者没有发送任何获取请求或至少在这个时间的这个leader的没有消费完。该leader将从isr中移除这个追随者。 | long | 10000 | 高 | |
| replica.socket.receive.buffer.bytes | 用于网络请求的socket接收缓存区 | int | 65536 | 高 | |
| replica.socket.timeout.ms | 网络请求的socket超时,该值最少是replica.fetch.wait.max.ms | int | 30000 | 高 | |
| request.timeout.ms | 该配置控制客户端等待请求的响应的最大时间,。如果超过时间还没收到消费。客户端将重新发送请求,如果重试次数耗尽,则请求失败。 | int | 30000 | 高 | |
| socket.receive.buffer.bytes | socket服务的SO_RCVBUF缓冲区。如果是-1,则默认使用OS的。 | int | 102400 | 高 | |
| socket.request.max.bytes | socket请求的最大字节数 | int | 104857600 | [1,…] | 高 |
| socket.send.buffer.bytes | socket服务的SO_SNDBUF缓冲区。如果是-1,则默认使用OS的。 | int | 102400 | 高 | |
| unclean.leader.election.enable | 是否启用不在ISR中的副本参与选举leader的最后的手段。这样做有可能丢失数据。 | boolean | true | 高 | |
| zookeeper.connection.timeout.ms | 连接zookeeper的最大等待时间,如果未设置,则使用zookeeper.session.timeout.ms。 | int | null | 高 | |
| zookeeper.session.timeout.ms | Zookeeper会话的超时时间 | int | 6000 | 高 | |
| zookeeper.set.acl | 设置客户端使用安全的ACL | boolean | false | 高 | |
| broker.id.generation.enable | 启用自动生成broker id。启用该配置时应检查reserved.broker.max.id。 | boolean | true | 中等 | |
| broker.rack | broker机架,用于机架感知副本分配的失败容错。例如:RACK1, us-east-1d
|
string | null | 中等 | |
| connections.max.idle.ms | 闲置连接超时:闲置时间超过该设置,则服务器socket处理线程将关闭这个连接。 | long | 600000 | 中等 | |
| controlled.shutdown.enable | 启用服务器的关闭控制。 | boolean | true | 中等 | |
| controlled.shutdown.max.retries | 控制因多种原因导致的shutdown失败,当这样失败发生,尝试重试的次数 | int | 3 | 中等 | |
| controlled.shutdown.retry.backoff.ms | 在每次重试之前,系统需要时间从导致先前故障的状态(控制器故障转移,复制延迟等)恢复。 此配置是重试之前等待的时间数。 | long | 5000 | 中等 | |
| controller.socket.timeout.ms | 控制器到broker通道的sockt超时时间 | int | 30000 | 中 | |
| default.replication.factor | 自动创建topic的默认的副本数 | int | 1 | 中 | |
| fetch.purgatory.purge.interval.requests | 拉取请求清洗间隔(请求数) | int | 1000 | 中 | |
| group.max.session.timeout.ms | 已注册的消费者允许的最大会话超时时间,设置的时候越长使消费者有更多时间去处理心跳之间的消息。但察觉故障的时间也拉长了。 | int | 300000 | 中 | |
| group.min.session.timeout.ms | 已经注册的消费者允许最小的会话超时时间,更短的时间去快速的察觉到故障,代价是频繁的心跳,这可能会占用大量的broker资源。 | int | 6000 | 中 | |
| inter.broker.protocol.version | 指定broker内部通讯使用的版本。通常在更新broker时使用。有效的值为:0.8.0, 0.8.1, 0.8.1.1, 0.8.2, 0.8.2.0, 0.8.2.1, 0.9.0.0, 0.9.0.1。查看ApiVersion找到的全部列表。 | string | 0.10.1-IV2 | 中 | |
| log.cleaner.backoff.ms | 当没有日志要清理时,休眠的时间 | long | 15000 | [0,…] | 中 |
| log.cleaner.dedupe.buffer.size | 用于日志去重的内存总量(所有cleaner线程) | long | 134217728 | 中 | |
| log.cleaner.delete.retention.ms | 删除记录保留多长时间? | long | 86400000 | 中 | |
| log.cleaner.enable | 在服务器上启用日志清洗处理?如果使用的任何topic的cleanup.policy=compact包含内部的offset topic,应启动。如果禁用,那些topic将不会被压缩并且会不断的增大。 | boolean | true | 中 | |
| log.cleaner.io.buffer.load.factor | 日志cleaner去重缓冲负载因子。去重缓冲区的百分比,较高的值将允许同时清除更多的日志,但将会导致更多的hash冲突。 | double | 0.9 | 中 | |
| log.cleaner.io.buffer.size | 所有日志清洁器线程I/O缓存的总内存 | int | 524288 | [0,…] | 中 |
| log.cleaner.io.max.bytes.per.second | 日志清理器限制,以便其读写i/o平均小与此值。 | double | 1.7976931348623157E308 | 中 | |
| log.cleaner.min.cleanable.ratio | 脏日志与日志的总量的最小比率,以符合清理条件 | double | 0.5 | 中 | |
| log.cleaner.min.compaction.lag.ms | 一条消息在日志保留不压缩的最小时间,仅适用于正在压缩的日志。 | long | 0 | 中 | |
| log.cleaner.threads | 用于日志清除的后台线程数 | int | 1 | [0,…] | 中 |
| log.cleanup.policy | 超过保留时间段的默认清除策略。逗号分隔的有效的策略列表。有效的策略有:“delete”和“compact” | list | [delete] | [compact, delete] | 中 |
| log.index.interval.bytes | 添加一个条目到offset的间隔 | int | 4096(4 kibibytes) | [0,…] | 中 |
| log.index.size.max.bytes | offset index的最大大小(字节) | int | 10485760 | [4,…] | 中 |
| log.message.format.version | 指定追加到日志中的消息格式版本。例如: 0.8.2, 0.9.0.0, 0.10.0。通过设置一个特定消息格式版本,用户需要保证磁盘上所有现有的消息小于或等于指定的版本。错误的设置将导致旧版本的消费者中断,因为消费者接收一个不理解的消息格式。 | string | 0.10.1-IV2 | 中 | |
| log.message.timestamp.difference.max.ms | 如果log.message.timestamp.type=CreateTime,broker接收消息时的时间戳和消息中指定的时间戳之间允许的最大差异。如果时间戳超过此阈值,则消息将被拒绝。如果log.message.timestamp.type=LogAppendTime,则此配置忽略。 | long | 9223372036854775807 | [0,…] | 中 |
| log.message.timestamp.type | 定义消息中的时间戳是消息创建时间或日志追加时间。该值可设置为CreateTime 或 LogAppendTime
|
string | CreateTime | [CreateTime, LogAppendTime] | 中 |
| log.preallocate | 在创建新段时预分配文件?如果你在Windowns上使用kafka,你可能需要设置它为true。 | boolean | false | 中 | |
| log.retention.check.interval.ms | 日志清除程序检查日志是否满足被删除的频率(以毫秒为单位) | long | 300000 | [1,…] | 中 |
| max.connections.per.ip | 允许每个ip地址的最大连接数。 | int | 2147483647 | [1,…] | 中 |
| max.connections.per.ip.overrides | per-ip或hostname覆盖默认最大连接数 | string | “” | 中 | |
| num.partitions | topic的默认分区数 | int | 1 | [1,…] | 中 |
| principal.builder.class | 实现PrincipalBuilder接口类的完全限定名,该接口目前用于构建与SSL SecurityProtocol连接的Principal。 | class | class org.apache.kafka. common.security.auth .DefaultPrincipalBuilder |
中 | |
| producer.purgatory.purge.interval.requests | 生产者请求purgatory的清洗间隔(请求数) | int | 1000 | 中 | |
| replica.fetch.backoff.ms | 当拉取分区发生错误时休眠的时间 | 1000 | [0,…] | 中 | |
| replica.fetch.max.bytes | 拉取每个分区的消息的字节数。这不是绝对的最大值,如果提取的第一个非空分区中的第一个消息大于这个值,则消息仍然返回,以确保进展。通过message.max.bytes (broker配置)或max.message.bytes (topic配置)定义broker接收的最大消息大小。 | int | 1048576 | [0,…] | 中 |
| replica.fetch.response.max.bytes | 预计整个获取响应的最大字节数,这不是绝对的最大值,如果提取的第一个非空分区中的第一个消息大于这个值,则消息仍然返回,以确保进展。通过message.max.bytes (broker配置)或max.message.bytes (topic配置)定义broker接收的最大消息大小。 | int | 10485760 | [0,…] | 中 |
| reserved.broker.max.id | broker.id的最大数 | int | 1000 | [0,…] | 中 |
| sasl.enabled.mechanisms | 可用的SASL机制列表,包含任何可用的安全提供程序的机制。默认情况下只有GSSAPI是启用的。 | list | [GSSAPI] | 中 | |
| sasl.kerberos.kinit.cmd | Kerberos kinit 命令路径。 | string | /usr/bin/kinit | 中 | |
| sasl.kerberos.min.time.before.relogin | 登录线程在刷新尝试的休眠时间。 | long | 60000 | 中 | |
| sasl.kerberos.principal.to.local.rules | principal名称映射到一个短名称(通常是操作系统用户名)。按顺序,使用与principal名称匹配的第一个规则将其映射其到短名称。忽略后面的规则。默认情况下,{username}/{hostname}@{REALM} 映射到 {username}。 | list | [DEFAULT] | 中 | |
| sasl.kerberos.service.name | Kafka运行的Kerberos principal名称。 可以在JAAS或Kafka的配置文件中定义。 | string | null | 中 | |
| sasl.kerberos.ticket.renew.jitter | 添加到更新时间的随机抖动的百分比 | time. double | 0.05 | 中 | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程休眠,直到从上次刷新到ticket的到期的时间已到达(指定窗口因子),在此期间它将尝试更新ticket。 | double | 0.8 | 中 | |
| sasl.mechanism.inter.broker.protocol | SASL机制,用于broker之间的通讯,默认是GSSAPI。 | string | GSSAPI | 中 | |
| security.inter.broker.protocol | broker之间的通讯协议,有效值有:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL。 | string | PLAINTEXT | 中 | |
| ssl.cipher.suites | 密码套件列表。认证,加密,MAC和秘钥交换算法的组合,用于使用TLS或SSL的网络协议交涉网络连接的安全设置,默认情况下,支持所有可用的密码套件。 |
list | null | 中 | |
| ssl.client.auth | 配置请求客户端的broker认证。常见的设置:ssl.client.auth=required 需要客户端认证。ssl.client.auth=requested 客户端认证可选,不同于requested ,客户端可选择不提供自身的身份验证信息* ssl.client.auth=none 不需要客户端身份认证 |
string | none | [required, requested, none] | 中 |
| ssl.enabled.protocols | 已启用的SSL连接协议列表。 | list | [TLSv1.2, TLSv1.1, TLSv1] | 中 | |
| ssl.key.password | 秘钥库文件中的私钥密码。对客户端是可选的。 | password | null | 中 | |
| ssl.keymanager.algorithm | 用于SSL连接的密钥管理工厂算法。默认值是Java虚拟机的密钥管理工厂算法。 | string | SunX509 | 中 | |
| ssl.keystore.location | 密钥仓库文件的位置。客户端可选,并可用于客户端的双向认证。 | string | null | 中 | |
| ssl.keystore.password | 密钥仓库文件的仓库密码。客户端可选,只有ssl.keystore.location配置了才需要。 | password | null | 中 | |
| ssl.keystore.type | 密钥仓库文件的格式。客户端可选。 | string | JKS | 中 | |
| ssl.protocol | 用于生成SSLContext,默认是TLS,适用于大多数情况。允许使用最新的JVM,LS, TLSv1.1 和TLSv1.2。 SSL,SSLv2和SSLv3 老的JVM也可能支持,由于有已知的安全漏洞,不建议使用。 | string | TLS | 中 | |
| ssl.provider | 用于SSL连接的安全提供程序的名称。默认值是JVM的安全程序。 | string | null | 中 | |
| ssl.trustmanager.algorithm | 信任管理工厂用于SSL连接的算法。默认为Java虚拟机配置的信任算法。 | string | PKIX | 中 | |
| ssl.truststore.location | 信任仓库文件的位置 | string | null | 中 | |
| ssl.truststore.password | 信任仓库文件的密码 | password | null | 中 | |
| ssl.truststore.type | 信任仓库文件的文件格式 | string | JKS | 中 | |
| authorizer.class.name | 用于认证的授权程序类 | string | “” | 低 | |
| metric.reporters | 度量报告的类列表,通过实现MetricReporter接口,允许插入新度量标准类。JmxReporter包含注册JVM统计。 |
list | [] | 低 | |
| metrics.num.samples | 维持计算度量的样本数。 | int | 2 | [1,…] | 低 |
| metrics.sample.window.ms | 计算度量样本的时间窗口 | long | 30000 | [1,…] | 低 |
| quota.window.num | 在内存中保留客户端限额的样本数 | int | 11 | [1,…] | 低 |
| quota.window.size.seconds | 每个客户端限额的样本时间跨度 | int | 1 | [1,…] | 低 |
| replication.quota.window.num | 在内存中保留副本限额的样本数 | int | 11 | [1,…] | 低 |
| replication.quota.window.size.seconds | 每个副本限额样本数的时间跨度 | int | 1 | [1,…] | 低 |
| ssl.endpoint.identification.algorithm | 端点身份标识算法,使用服务器证书验证服务器主机名。 | string | null | 低 | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现。 | string | null | 低 | |
| zookeeper.sync.time.ms | ZK follower可落后与leader多久。 | int | 2000 | 低 |
以下是kafka新版本的增量配置
kafka >= 1.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 | 更新模式 |
|---|---|---|---|---|---|---|
| group.initial.rebalance.delay.ms | 分组协调器在执行第一次重新平衡之前,等待更多消费者加入新组的时间。延迟时间越长,意味着重新平衡的次数可能越少,但会增加处理开始前的时间。 | int | 3000 | 中 | 只读 | |
| transaction.abort.timed.out.transaction.cleanup.interval.ms | 回滚已超时的事务的时间间隔。 | int | 10000 (10 seconds) | [1,…] | 低 | 只读 |
| transaction.remove.expired.transaction.cleanup.interval.ms | 删除因transactional.id.expiration.ms过期的事务的时间间隔。 |
int | 3600000 (1 hour) | [1,…] | 低 | 只读 |
| transaction.max.timeout.ms | 事务的最大允许超时时间。如果客户端请求的交易时间超过了这个时间,那么broker将在InitProducerIdRequest中返回一个错误。这可以防止客户端的超时时间过大,从而阻滞消费者从事务中包含的主题中读取。 | int | 900000 (15 minutes) | [1,…] | 高 | 只读 |
| transaction.state.log.load.buffer.size | 在将生产者id和事务加载到缓存中时,从事务日志段读取的批次大小(软限制,如果消息太大,则重写) | int | 5242880 | [1,…] | 高 | 只读 |
| transaction.state.log.min.isr | 覆盖事务topic的min.insync.replicas配置。 |
int | 2 | [1,…] | 高 | 只读 |
| transaction.state.log.num.partitions | 事务topic的分区数(部署后不应改变)。 | int | 50 | [1,…] | 高 | 只读 |
| transaction.state.log.replication.factor | 事务topic的复制因子(设置较高来确保可用性)。内部topic创建将失败,直到集群规模满足该复制因子要求。 | short | 3 | [1,…] | 高 | 只读 |
| transaction.state.log.segment.bytes | 事务topic段的字节数应保持相对较小,以利于加快日志压缩和缓存加载速度 | int | 104857600 (100 mebibytes) | [1,…] | 高 | 只读 |
| transactional.id.expiration.ms | 事务协调器在没有收到当前事务的任何事务状态更新的情况下,在其事务id过期前等待的时间,单位为ms。这个设置也会影响生产者id过期 – 一旦这个时间在给定的生产者id最后一次写入后过去,生产者id就会过期。请注意,如果由于主题的保留设置而删除了生产者id的最后一次写入,那么生产者id可能会更快过期。 | int | 604800000 (7 days) | [1,…] | 高 | 只读 |
kafka >= 2.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 | 动态更新模式 |
|---|---|---|---|---|---|---|
| sasl.client.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。 | class | null | 中间 | 只读 | |
| sasl.login.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的全称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler
|
class | null | 中间 | 只读 | |
| sasl.login.class | 实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。 |
class | null | 中间 | 只读 |
kafka >= 2.5
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 | 更新模式 |
|---|---|---|---|---|---|---|
| zookeeper.clientCnxnSocket | 当使用TLS连接到ZooKeeper时,通常设置为org.apache.zookeeper.ClientCnxnSocketNetty。覆盖任何同名的zookeeper.clientCnxnSocket设置的显式值。 |
string | null | 中间 | 只读 | |
| zookeeper.ssl.client.enable | 设置客户端连接到ZooKeeper时使用TLS。显式的值会覆盖任何通过zookeeper.client.secure设置的值(注意名称不同)。如果两者都没有设置,默认为false;当为true时,必须设置zookeeper.clientCnxnSocket(通常为org.apache.zookeeper.ClientCnxnSocketNetty);其他需要设置的值可能包括zookeeper.ssl.cipher.suites、zookeeper.ssl.crl.enable、zookeeper.ssl.enabled.protocols、zookeeper.ssl.endpoint. identification.algorithm,zookeeper.ssl.keystore.location,zookeeper.ssl.keystore.password,zookeeper.ssl.keystore.type,zookeeper.ssl. ocsp.enable, zookeeper.ssl.protocol, zookeeper.ssl.truststore.location, zookeeper.ssl.truststore.password, zookeeper.ssl.truststore.type。 |
boolean | false | 中间 | 只读 | |
| zookeeper.ssl.keystore.location | 当使用客户端证书与TLS连接到ZooKeeper时的keystore位置。覆盖任何通过zookeeper.ssl.keyStore.location系统属性设置的显式值(注意是驼峰大小)。 |
password | null | 中间 | 只读 | |
| zookeeper.ssl.keystore.password | 当使用客户端证书与TLS连接到ZooKeeper时的keystore密码。覆盖任何通过zookeeper.ssl.keyStore.password系统属性设置的显式值(注意驼峰大写)。 注意,ZooKeeper不支持与keystore密码不同的密钥密码,所以一定要将keystore中的密钥密码设置为与keystore密码相同,否则连接Zookeeper的尝试将失败。 |
password | null | 中间 | 只读 | |
| zookeeper.ssl.keystore.type | 当使用客户端证书与TLS连接到ZooKeeper时的keystore类型。覆盖任何通过zookeeper.ssl.keyStore.type系统属性设置的显式值(注意骆驼大写)。默认值为null意味着该类型将根据keystore的文件扩展名自动检测。 |
string | null | 中间 | 只读 | |
| zookeeper.ssl.protocol | 指定ZooKeeper TLS协商中使用的协议。一个显式的值会覆盖任何通过同名的zookeeper.ssl.protocol系统设置的值。 |
string | TLSv1.2 | 低 | 只读 | |
| zookeeper.ssl.cipher.suites | 指定在ZooKeeper TLS协商中使用的密码套件(csv),覆盖任何通过zookeeper.ssl.ciphersuites系统属性设置的显式值(注意单字 “ciphersuites”)。覆盖任何通过zookeeper.ssl.ciphersuites系统属性设置的显式值(注意 “ciphersuites “这个单字)。默认值为 “null “意味着启用的密码套件列表是由正在使用的Java运行时决定的。 |
boolean | false | 低 | 只读 | |
| zookeeper.ssl.crl.enable | 指定是否启用ZooKeeper TLS协议中的证书撤销列表。覆盖任何通过zookeeper.ssl.crl系统属性设置的显式值(注意是短名)。 |
boolean | false | 低 | 只读 | |
| zookeeper.ssl.enabled.protocols | 指定ZooKeeper TLS协商(csv)中启用的协议。覆盖任何通过zookeeper.ssl.enabledProtocols系统属性设置的显式值(注意骆驼大写)。默认值为 “null “意味着启用的协议将是zookeeper.ssl.protocol配置属性的值。 |
list | null | 低 | 只读 | |
| zookeeper.ssl.endpoint.identification.algorithm | 指定是否在ZooKeeper TLS协商过程中启用主机名验证,(不区分大小写)”https “表示启用ZooKeeper主机名验证,显式的空白值表示禁用(仅为测试目的建议禁用)。明确的值会覆盖任何通过zookeeper.ssl.hostnameVerification系统属性设置的 “true “或 “false “值(注意不同的名称和值;true意味着https,false意味着空白)。 |
string | HTTPS | 低 | 只读 | |
| zookeeper.ssl.ocsp.enable | 指定是否启用ZooKeeper TLS协议中的在线证书状态协议。覆盖任何通过zookeeper.ssl.ocsp系统属性设置的显式值(注意是短名)。 | boolean | false | 低 | 只读 |
kafka >= 2.7
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 | 更新模式 |
|---|---|---|---|---|---|---|
| ssl.truststore.certificates | 可信证书的格式由’ssl.truststore.type’指定。默认的SSL引擎工厂只支持带X.509证书的PEM格式。 | password | null | 中间 | 每个broker | |
| socket.connection.setup.timeout.max.ms | 客户端等待建立socket连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用一个0.2的随机因子,导致计算值在20%以下和20%以上的随机范围。 | long | 127000 (127 seconds) | 中间 | 只读 | |
| socket.connection.setup.timeout.ms | 客户端等待建立socket连接的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。 | long | 10000 (10 seconds) | 中间 | 只读 |
kafka >= 3.0.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| node.id | 当process.role为非空时,与该进程所扮演的角色相关的节点ID。这是在KRaft模式下运行时的必要配置。 |
int | -1 | 高 | |
| process.roles | 这个进程所扮演的角色:broker、controller,或者 broker,controller(两者都是)。此配置只适用于KRaft(Kafka Raft)模式的集群(而不是ZooKeeper)。对于Zookeeper集群,让这个配置无需定义或为空。 | list | “” | [broker, controller] |
高 |
| controller.listener.names | 以逗号分隔的controller使用的监听器的名称列表。如果在KRaft模式下运行,这是必须的。基于ZK的controller将不使用这个配置。 | string | null | 高 | |
| metadata.log.dir | 这个配置决定了我们将KRaft模式下的集群的元数据日志放在哪里。如果没有设置,元数据日志将被放置在log.dirs中的第一个日志目录。 | string | null | 高 | |
| broker.heartbeat.interval.ms | broker之间心跳之间的时间间隔(毫秒)。在KRaft模式下运行时使用。 | int | 2000 (2秒) | 中间 | |
| broker.session.timeout.ms | 如果没有心跳,broker持续的时间,以毫秒计。在KRaft模式下运行时使用。 | int | 9000 (9秒) | 中间 | |
| controller.quorum.voters | 选民的id/endpoint信息的map列表,逗号分隔{id}@{host}:{port}。例如:1@localhost:9092,2@localhost:9093,3@localhost:9094。 |
list | “” | 非空列表 | 高 |
| controller.quorum.election.backoff.max.ms | 这用于二进制指数退避机制,有助于防止选举陷入僵局。 | int | 1000 (1秒) | 高 | |
| controller.quorum.election.timeout.ms | 在触发新的选举之前,无法从leader那里获取的最大等待时间(毫秒)。 | int | 1000 (1秒) | 高 | |
| controller.quorum.fetch.timeout.ms | 在成为候选人并触发选民选举之前,没有从现任leader那里成功获取的最长时间;在四处询问是否有新的领导人纪元之前,没有从法定人数的大多数人那里获得获取的最长时间。 | int | 2000 (2秒) | 高 | |
| control.plane.listener.name | 用于controller和broker之间通信的监听器的名称。broker将使用control.plane.listener.name来定位监听器列表中的endpoint(端点),以监听来自controller的连接。例如,如果一个broker的配置是: listeners = INTERNAL://192.1.1.8:9092, EXTERNAL:/10.1.1.5:9093, CONTROLLER://192.1.1.8:9094 在controller方面,当它通过zookeeper发现一个broker发布的端点时,它将使用 control.plane.listener.name来寻找端点,它将用它来建立与broker的连接。例如,如果broker在zookeeper上发布的端点是:”endpoints” : ["INTERNAL://broker1.example.com:9092", "EXTERNAL://broker1.example.com:9093", "CONTROLLER://broker1.example.com:9094" ]而控制器的配置是: listener.security.protocol.map = INTERNAL:PLAINTEXT, EXTERNAL:SSL, CONTROLLER:SSL control.plane.listener.name = CONTROLLER 那么controller将使用 “broker1.example.com:9094″和安全协议 “SSL”来连接到broker。 如果没有明确配置,默认值将为空,将没有专门的端点用于controller连接。 |
string | null | 高 |
更多的broker配置详情,可以在scala类中的kafka.server.KafkaConfig找到。
Topic配置
与主题相关的配置既有服务器默认值,也有可选的每个主题覆盖。如果没有给出每个主题的配置,则使用服务器默认值。可以在主题创建时通过提供一个或多个选项来设置覆盖--config。此示例创建一个名为my-topic007 的主题,具有自定义最大消息大小和刷新率:
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --create --topic my-topic007 --partitions 1 --replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1
Created topic my-topic007.也可以稍后使用 alter configs 命令更改或设置覆盖。此示例更新my-topic007的最大消息大小:
kafka-1:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 10.4.3.41:29092 --entity-type topics --entity-name my-topic007 --alter --add-config max.message.bytes=128000
Completed updating config for topic my-topic007.
kafka-1:/opt/kafka/bin$ 要检查主题上设置的覆盖,您可以执行以下操作
kafka-1:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 10.4.3.41:29092 --entity-type topics --entity-name my-topic007 --describe
Dynamic configs for topic my-topic007 are:
flush.messages=1 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:flush.messages=1, DEFAULT_CONFIG:log.flush.interval.messages=9223372036854775807}
max.message.bytes=128000 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:max.message.bytes=128000, DEFAULT_CONFIG:message.max.bytes=1048588}
kafka-1:/opt/kafka/bin$ 要删除覆盖,您可以执行以下操作
kafka-1:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 10.4.3.41:29092 --entity-type topics --entity-name my-topic007 --alter --delete-config max.message.bytes
Completed updating config for topic my-topic007.
kafka-1:/opt/kafka/bin$ 前后覆盖对比
kafka-1:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 10.4.3.41:29092 --entity-type topics --entity-name my-topic007 --describe
Dynamic configs for topic my-topic007 are:
flush.messages=1 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:flush.messages=1, DEFAULT_CONFIG:log.flush.interval.messages=9223372036854775807}
max.message.bytes=128000 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:max.message.bytes=128000, DEFAULT_CONFIG:message.max.bytes=1048588}
kafka-1:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 10.4.3.41:29092 --entity-type topics --entity-name my-topic007 --alter --delete-config max.message.bytes
Completed updating config for topic my-topic007.
kafka-1:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 10.4.3.41:29092 --entity-type topics --entity-name my-topic007 --describe
Dynamic configs for topic my-topic007 are:
flush.messages=1 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:flush.messages=1, DEFAULT_CONFIG:log.flush.interval.messages=9223372036854775807}
kafka-1:/opt/kafka/bin$ 以下是主题级别的配置。服务器对此属性的默认配置在“服务器默认属性”标题下给出。给定的服务器默认配置值仅适用于没有显式主题配置覆盖的主题。
| 名称 | 描述 | 类型 | 默认 | 有效的值 | 服务器默认属性 | 重要程度 |
|---|---|---|---|---|---|---|
| cleanup.policy | “delete”或“compact”。指定在旧的日志段的保留策略。默认策略(“delete”),将达到保留时间或大小限制的日志废弃。 “compact”则压缩日志。 | list | delete | [compact, delete] | log.cleanup.policy | medium |
| compression.type | 针对指定的topic设置最终的压缩方式。标准的压缩格式有’gzip’, ‘snappy’, lz4。还可以设置’uncompressed’,就是不压缩;设置为’producer’这意味着保留生产者设置的原始压缩编解码。 | string | producer | [uncompressed, snappy, lz4, gzip, producer] | compression.type | medium |
| delete.retention.ms | 保留删除消息压缩topic的删除标记的时间。此设置还给出消费者如果从offset 0开始读取并确保获得最终阶段的有效快照的时间范围(否则,在完成扫描之前可能已经回收了)。 | long | 86400000 | [0,…] | log.cleaner.delete.retention.ms | medium |
| file.delete.delay.ms | 从文件系统中删除文件之前等待的时间 | long | 60000 | [0,…] | log.segment.delete.delay.ms | medium |
| flush.messages | 此设置允许指定我们强制fsync写入日志的数据的间隔。例如,如果这被设置为1,我们将在每个消息之后fsync; 如果是5,我们将在每五个消息之后fsync。一般,我们建议不要设置它,使用复制特性来保持持久性,并允许操作系统的后台刷新功能更高效。可以在每个topic的基础上覆盖此设置(请参阅每个主题的配置部分)。 | medium | long | 9223372036854775807 | [0,…] | log.flush.interval.messages |
| flush.ms | 此设置允许我们强制fsync写入日志的数据的时间间隔。例如,如果这设置为1000,那么在1000ms过去之后,我们将fsync。 一般,我们建议不要设置它,并使用复制来保持持久性,并允许操作系统的后台刷新功能,因为它更有效率 | long | 9223372036854775807 | [0,…] | log.flush.interval.ms | medium |
| follower.replication.throttled.replicas | follower复制限流列表。该列表应以[PartitionId]的形式描述一组副本:[BrokerId],[PartitionId]:[BrokerId]:…或者通配符’*’可用于限制此topic的所有副本。 | list | “” | [partitionId],[brokerId]:[partitionId],[brokerId]:… | follower.replication.throttled.replicas | medium |
| index.interval.bytes | 此设置控制Kafka向其offset索引添加索引条目的频率。默认设置确保我们大致每4096个字节索引消息。 更多的索引允许读取更接近日志中的确切位置,但使索引更大。你不需要改变这个值。 | int | 4096 | [0,…] | log.index.interval.bytes | medium |
| leader.replication.throttled.replicas | 在leader方面进行限制的副本列表。该列表设置以[PartitionId]的形式描述限制副本:[PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:…或使用通配符‘*’限制该topic的所有副本。 | list | “” | [partitionId],[brokerId]:[partitionId],[brokerId]:… | leader.replication.throttled.replicas | medium |
| max.message.bytes | kafka允许的最大的消息批次大小。如果增加此值,并且消费者的版本比0.10.2老,那么消费者的提取的大小也必须增加,以便他们可以获取大的消息批次。 在最新的消息格式版本中,消息总是分组批量来提高效率。在之前的消息格式版本中,未压缩的记录不会分组批量,并且此限制仅适用于该情况下的单个消息。 |
int | 1000012 | [0,…] | message.max.bytes | medium |
| message.format.version | 指定消息附加到日志的消息格式版本。该值应该是一个有效的ApiVersion。例如:0.8.2, 0.9.0.0, 0.10.0,更多细节检查ApiVersion。通过设置特定的消息格式版本,并且磁盘上的所有现有消息都小于或等于指定版本。不正确地设置此值将导致消费者使用旧版本,因为他们将接收到“不认识”的格式的消息。 | string | 0.11.0-IV2 | log.message.format.version | medium | |
| min.cleanable.dirty.ratio | 此配置控制日志压缩程序将尝试清除日志的频率(假设启用了日志压缩)。默认情况下,我们将避免清理超过50%日志被压缩的日志。 该比率限制日志中浪费的最大空间重复(在最多50%的日志中可以是重复的50%)。更高的比率意味着更少,更有效的清洁,但意味着日志中的浪费更多。 | double | 0.5 | [0,…,1] | log.cleaner.min.cleanable.ratio | medium |
| min.compaction.lag.ms | 消息在日志中保持不压缩的最短时间。仅适用于正在压缩的日志。 | long | 0 | [0,…] | log.cleaner.min.compaction.lag.ms | medium |
| min.insync.replicas | 当生产者设置应答为”all”(或“-1”)时,此配置指定了成功写入的副本应答的最小数。如果没满足此最小数,则生产者将引发异常(NotEnoughReplicas或NotEnoughReplicasAfterAppend) 当min.insync.replicas和acks强制更大的耐用性时。典型的情况是创建一个副本为3的topic,将min.insync.replicas设置为2,并设置acks为“all”。如果多数副本没有收到写入,这将确保生产者引发异常。 |
int | 1 | [1,…] | min.insync.replicas | medium |
| preallocate | 如果我们在创建新的日志段时在磁盘上预分配该文件,那么设为True。 | boolean | false | log.preallocate | medium | |
| retention.bytes | 如果我们使用“删除”保留策略,则此配置将控制日志可以增长的最大大小,之后我们将丢弃旧的日志段以释放空间。默认情况下,没有设置大小限制则仅限于时间限制。 | long | -1 | log.retention.bytes | medium | |
| retention.ms | 如果我们使用“删除”保留策略,则此配置控制我们将保留日志的最长时间,然后我们将丢弃旧的日志段以释放空间。这代表SLA消费者必须读取数据的时间长度。 | long | 604800000 | log.retention.ms | medium | |
| segment.bytes | 此配置控制日志的段文件大小。一次保留和清理一个文件,因此较大的段大小意味着较少的文件,但对保留率的粒度控制较少。 | int | 1073741824 | [14,…] | log.segment.bytes | medium |
| segment.index.bytes | 此配置控制offset映射到文件位置的索引的大小。我们预先分配此索引文件,并在日志滚动后收缩它。通常不需要更改此设置。 | int | 10485760 | [0,…] | log.index.size.max.bytes | medium |
| segment.jitter.ms | 从计划的段滚动时间减去最大随机抖动,以避免异常的段滚动 | long | 0 | [0,…] | log.roll.jitter.ms | medium |
| segment.ms | 此配置控制Kafka强制日志滚动的时间段,以确保保留可以删除或压缩旧数据,即使段文件未满。 | long | 604800000 | [0,…] | log.roll.ms | medium |
| unclean.leader.election.enable | 是否将不在ISR中的副本作为最后的手段选举为leader,即使这样做可能会导致数据丢失。 | boolean | false | unclean.leader.election.enable | medium |
kafka > 2.0
kafka新版本新增的配置
| 名称 | 描述 | 类型 | 默认 | 有效的值 | 服务器默认属性 | 重要程度 |
|---|---|---|---|---|---|---|
| message.downconversion.enable | 此配置控制是否启用消息格式的向下转换以满足消费请求。当设置为false时,broker不会对期待旧消息格式的消费者执行向下转换。broker 会对来自此类旧客户端的消费请求作出 UNSUPPORTED_VERSION 错误响应。这个配置不适用于复制到followers时可能需要的任何消息格式转换。 |
boolean | false | log.message.downconversion.enable | 低 |
Producer配置
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| bootstrap.servers | host/port列表,用于初始化建立和Kafka集群的连接。列表格式为host1:port1,host2:port2,….,无需添加所有的集群地址,kafka会根据提供的地址发现其他的地址(你可以多提供几个,以防提供的服务器关闭) | list | high | ||
| key.serializer | 实现 org.apache.kafka.common.serialization.Serializer 接口的 key 的 Serializer 类。 | class | high | ||
| value.serializer | 实现 org.apache.kafka.common.serialization.Serializer 接口的value 的 Serializer 类。 | class | high | ||
| acks | 生产者需要leader确认请求完成之前接收的应答数。此配置控制了发送消息的耐用性,支持以下配置: acks=0 如果设置为0,那么生产者将不等待任何消息确认。消息将立刻添加到socket缓冲区并考虑发送。在这种情况下不能保障消息被服务器接收到。并且重试机制不会生效(因为客户端不知道故障了没有)。每个消息返回的offset始终设置为-1。 acks=1,这意味着leader写入消息到本地日志就立即响应,而不等待所有follower应答。在这种情况下,如果响应消息之后但follower还未复制之前leader立即故障,那么消息将会丢失。 acks=all 这意味着leader将等待所有副本同步后应答消息。此配置保障消息不会丢失(只要至少有一个同步的副本或者)。这是最强壮的可用性保障。等价于acks=-1。 |
string | 1 | [all, -1, 0, 1] | high |
| buffer.memory | 生产者用来缓存等待发送到服务器的消息的内存总字节数。如果消息发送比可传递到服务器的快,生产者将阻塞max.block.ms之后,抛出异常。此设置应该大致的对应生产者将要使用的总内存,但不是硬约束,因为生产者所使用的所有内存都用于缓冲。一些额外的内存将用于压缩(如果启动压缩),以及用于保持发送中的请求。 |
long | 33554432 | [0,…] | high |
| compression.type | 数据压缩的类型。默认为空(就是不压缩)。有效的值有 none,gzip,snappy, 或 lz4。压缩全部的数据批,因此批的效果也将影响压缩的比率(更多的批次意味着更好的压缩)。 | string | none | high | |
| retries | 设置一个比零大的值,客户端如果发送失败则会重新发送。注意,这个重试功能和客户端在接到错误之后重新发送没什么不同。如果max.in.flight.requests.per.connection没有设置为1,有可能改变消息发送的顺序,因为如果2个批次发送到一个分区中,并第一个失败了并重试,但是第二个成功了,那么第二个批次将超过第一个。 | int | 0 | [0,…,2147483647] | high |
| ssl.key.password | 密钥仓库文件中的私钥的密码。 | password | null | high | |
| ssl.keystore.location | 密钥仓库文件的位置。可用于客户端的双向认证。 | string | null | high | |
| ssl.keystore.password | 密钥仓库文件的仓库密码。只有配置了ssl.keystore.location时才需要。 | password | null | high | |
| ssl.truststore.location | 信任仓库的位置 | string | null | high | |
| ssl.truststore.password | 信任仓库文件的密码 | password | null | high | |
| batch.size | 当多个消息要发送到相同分区的时,生产者尝试将消息批量打包在一起,以减少请求交互。这样有助于客户端和服务端的性能提升。该配置的默认批次大小(以字节为单位): 不会打包大于此配置大小的消息。 发送到broker的请求将包含多个批次,每个分区一个,用于发送数据。 较小的批次大小有可能降低吞吐量(批次大小为0则完全禁用批处理)。一个非常大的批次大小可能更浪费内存。因为我们会预先分配这个资源。 |
int | 16384 | [0,…] | medium |
| client.id | 当发出请求时传递给服务器的id字符串。这样做的目的是允许服务器请求记录记录这个【逻辑应用名】,这样能够追踪请求的源,而不仅仅只是ip/prot。 | string | “” | medium | |
| connections.max.idle.ms | 多少毫秒之后关闭闲置的连接。 | long | 540000 | medium | |
| linger.ms | 生产者组将发送的消息组合成单个批量请求。正常情况下,只有消息到达的速度比发送速度快的情况下才会出现。但是,在某些情况下,即使在适度的负载下,客户端也可能希望减少请求数量。此设置通过添加少量人为延迟来实现。- 也就是说,不是立即发出一个消息,生产者将等待一个给定的延迟,以便和其他的消息可以组合成一个批次。这类似于Nagle在TCP中的算法。此设置给出批量延迟的上限:一旦我们达到分区的batch.size值的记录,将立即发送,不管这个设置如何,但是,如果比这个小,我们将在指定的“linger”时间内等待更多的消息加入。此设置默认为0(即无延迟)。假设,设置 linger.ms=5,将达到减少发送的请求数量的效果,但对于在没有负载情况,将增加5ms的延迟。 | long | 0 | [0,…] | medium |
| max.block.ms | 该配置控制 KafkaProducer.send() 和 KafkaProducer.partitionsFor() 将阻塞多长时间。此外这些方法被阻止,也可能是因为缓冲区已满或元数据不可用。在用户提供的序列化程序或分区器中的锁定不会计入此超时。 | long | 60000 | [0,…] | medium |
| max.request.size | 请求的最大大小(以字节为单位)。此设置将限制生产者的单个请求中发送的消息批次数,以避免发送过大的请求。这也是最大消息批量大小的上限。请注意,服务器拥有自己的批量大小,可能与此不同。 | int | 1048576 | [0,…] | medium |
| partitioner.class | 实现Partitioner接口的的Partitioner类。 | class | org.apache.kafka.clients.producer.internals.DefaultPartitioner | medium | |
| receive.buffer.bytes | 读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果值为-1,则将使用OS默认值。 | int | 32768 | [-1,…] | medium |
| request.timeout.ms | 该配置控制客户端等待请求响应的最长时间。如果在超时之前未收到响应,客户端将在必要时重新发送请求,如果重试耗尽,则该请求将失败。 这应该大于replica.lag.time.max.ms,以减少由于不必要的生产者重试引起的消息重复的可能性。 | int | 30000 | [0,…] | medium |
| sasl.jaas.config | JAAS配置文件使用的格式的SASL连接的JAAS登录上下文参数。这里描述JAAS配置文件格式。该值的格式为:’(=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | Kafka运行的Kerberos主体名称。可以在Kafka的JAAS配置或Kafka的配置中定义。 | string | null | medium | |
| sasl.mechanism | SASL机制用于客户端连接。这是安全提供者可用与任何机制。GSSAPI是默认机制。 | string | GSSAPI | medium | |
| security.protocol | 用于与broker通讯的协议。 有效值为:PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSL。 | string | PLAINTEXT | medium | |
| send.buffer.bytes | 发送数据时,用于TCP发送缓存(SO_SNDBUF)的大小。如果值为 -1,将默认使用系统的。 | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | 启用SSL连接的协议列表。 | list | TLSv1.2,TLSv1.1,TLSv1 | medium | |
| ssl.keystore.type | 密钥存储文件的文件格式。对于客户端是可选的。 | string | JKS | medium | |
| ssl.protocol | 最近的JVM中允许的值是TLS,TLSv1.1和TLSv1.2。 较旧的JVM可能支持SSL,SSLv2和SSLv3,但由于已知的安全漏洞,不建议使用SSL。 | string | TLS | medium | |
| ssl.provider | 用于SSL连接的安全提供程序的名称。默认值是JVM的默认安全提供程序。 | string | null | medium | |
| ssl.truststore.type | 信任仓库文件的文件格式。 | string | JKS | medium | |
| enable.idempotence | 当设置为‘true’,生产者将确保每个消息正好一次复制写入到stream。如果‘false’,由于broker故障,生产者重试。即,可以在流中写入重试的消息。此设置默认是‘false’。请注意,启用幂等式需要将max.in.flight.requests.per.connection设置为1,重试次数不能为零。另外acks必须设置为“全部”。如果这些值保持默认值,我们将覆盖默认值。 如果这些值设置为与幂等生成器不兼容的值,则将抛出一个ConfigException异常。如果这些值设置为与幂等生成器不兼容的值,则将抛出一个ConfigException异常。 | boolean | false | low | |
| interceptor.classes | 实现ProducerInterceptor接口,你可以在生产者发布到Kafka群集之前拦截(也可变更)生产者收到的消息。默认情况下没有拦截器。 | list | null | low | |
| max.in.flight.requests.per.connection | 阻塞之前,客户端单个连接上发送的未应答请求的最大数量。注意,如果此设置设置大于1且发送失败,则会由于重试(如果启用了重试)会导致消息重新排序的风险。 | int | 5 | [1,…] | low |
| metadata.max.age.ms | 在一段时间段之后(以毫秒为单位),强制更新元数据,即使我们没有看到任何分区leader的变化,也会主动去发现新的broker或分区。 | long | 300000 | [0,…] | low |
| metric.reporters | 用作metrics reporters(指标记录员)的类的列表。实现MetricReporter接口,将受到新增加的度量标准创建类插入的通知。 JmxReporter始终包含在注册JMX统计信息中。 | list | “” | low | |
| metrics.num.samples | 维护用于计算度量的样例数量。 | int | 2 | [1,…] | low |
| metrics.recording.level | 指标的最高记录级别。 | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | 度量样例计算上 | long | 30000 | [0,…] | low |
| reconnect.backoff.max.ms | 重新连接到重复无法连接的代理程序时等待的最大时间(毫秒)。 如果提供,每个主机的回退将会连续增加,直到达到最大值。 计算后退增加后,增加20%的随机抖动以避免连接风暴。 | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | 尝试重新连接到给定主机之前等待的基本时间量。这避免了在循环中高频率的重复连接到主机。这种回退适应于客户端对broker的所有连接尝试。 | long | 50 | [0,…] | low |
| retry.backoff.ms | 尝试重试指定topic分区的失败请求之前等待的时间。这样可以避免在某些故障情况下高频次的重复发送请求。 | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit 命令路径。 | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | Login线程刷新尝试之间的休眠时间。 | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | 添加更新时间的随机抖动百分比。 | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将睡眠,直到从上次刷新ticket到期时间的指定窗口因子为止,此时将尝试续订ticket。 | double | 0.8 | low | |
| ssl.cipher.suites | 密码套件列表。这是使用TLS或SSL网络协议来协商用于网络连接的安全设置的认证,加密,MAC和密钥交换算法的命名组合。默认情况下,支持所有可用的密码套件。 | list | null | low | |
| ssl.endpoint.identification.algorithm | 使用服务器证书验证服务器主机名的端点识别算法。 | string | null | low | |
| ssl.keymanager.algorithm | 用于SSL连接的密钥管理因子算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。 | string | SunX509 | low | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现。 | string | null | low | |
| ssl.trustmanager.algorithm | 用于SSL连接的信任管理因子算法。默认值是JAVA虚拟机配置的信任管理工厂算法。 | string | PKIX | low | |
| transaction.timeout.ms | 生产者在主动中止正在进行的交易之前,交易协调器等待事务状态更新的最大时间(以ms为单位)。如果此值大于broker中的max.transaction.timeout.ms设置,则请求将失败,并报“InvalidTransactionTimeout”错误。 | int | 60000 | low | |
| transactional.id | 用于事务传递的TransactionalId。这样可以跨多个生产者会话的可靠性语义,因为它允许客户端保证在开始任何新事务之前使用相同的TransactionalId的事务已经完成。如果没有提供TransactionalId,则生产者被限制为幂等传递。请注意,如果配置了TransactionalId,则必须启用enable.idempotence。 默认值为空,这意味着无法使用事务。 | string | null | non-empty string | low |
kafka >= 2.0.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| sasl.client.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。 | class | null | 中间 | |
| sasl.login.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的全称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler
|
class | null | 中间 | |
| sasl.login.class | 实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。 |
class | null | 中间 |
kafka >= 2.1.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| client.dns.lookup | 控制客户端如何使用DNS查询。如果设置为 use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次从主机名中解析IP(s)(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为 resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在bootstrap阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为 default(已弃用),则尝试连接到查找返回的第一个IP地址,即使查找返回多个IP地址。 |
string | use_all_dns_ips | [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] |
中间 |
| delivery.timeout.ms | 调用send()返回后报告成功或失败的时间上限。这限制了消息在发送前被延迟的总时间,等待broker确认的时间(如果期望的话),以及允许重试发送失败的时间。如果遇到不可恢复的错误,重试次数已经用尽,或者消息被添加到一个达到较早发送到期期限的批次中,生产者可能会报告未能在这个配置之前发送记录。这个配置的值应该大于或等于request.timeout.ms和linger.ms之和。 |
int | 120000 (2 minutes) | [0,...] |
中间 |
kafka >= 2.7
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| ssl.truststore.certificates | 可信证书的格式由’ssl.truststore.type’指定。默认的SSL引擎工厂只支持带X.509证书的PEM格式。 | password | null | 高 | |
| socket.connection.setup.timeout.max.ms | 客户端等待建立socket连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用一个0.2的随机因子,导致计算值在20%以下和20%以上的随机范围。 | long | 127000 (127 seconds) | 中间 | |
| socket.connection.setup.timeout.ms | 客户端等待建立socket连接的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。 | long | 10000 (10 seconds) | 中间 |
Consumer配置
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| bootstrap.servers | host/port,用于和kafka集群建立初始化连接。因为这些服务器地址仅用于初始化连接,并通过现有配置的来发现全部的kafka集群成员(集群随时会变化),所以此列表不需要包含完整的集群地址(但尽量多配置几个,以防止配置的服务器宕机)。 | list | high | ||
| key.deserializer | key的解析序列化接口实现类(Deserializer)。 | class | high | ||
| value.deserializer | value的解析序列化接口实现类(Deserializer) | class | high | ||
| fetch.min.bytes | 服务器哦拉取请求返回的最小数据量,如果数据不足,请求将等待数据积累。默认设置为1字节,表示只要单个字节的数据可用或者读取等待请求超时,就会应答读取请求。将此值设置的越大将导致服务器等待数据累积的越长,这可能以一些额外延迟为代价提高服务器吞吐量。 | int | 1 | [0,…] | high |
| group.id | 此消费者所属消费者组的唯一标识。如果消费者用于订阅或offset管理策略的组管理功能,则此属性是必须的。 | string | “” | high | |
| heartbeat.interval.ms | 当使用Kafka的分组管理功能时,心跳到消费者协调器之间的预计时间。心跳用于确保消费者的会话保持活动状态,并当有新消费者加入或离开组时方便重新平衡。该值必须必比session.timeout.ms小,通常不高于1/3。它可以调整的更低,以控制正常重新平衡的预期时间。 | int | 3000(3秒) | high | |
| max.partition.fetch.bytes | 服务器将返回每个分区的最大数据量。如果拉取的第一个非空分区中第一个消息大于此限制,则仍然会返回消息,以确保消费者可以正常的工作。broker接受的最大消息大小通过message.max.bytes(broker config)或max.message.bytes (topic config)定义。参阅fetch.max.bytes以限制消费者请求大小。 |
int | 1048576 | [0,…] | high |
| session.timeout.ms | 用于发现消费者故障的超时时间。消费者周期性的发送心跳到broker,表示其还活着。如果会话超时期满之前没有收到心跳,那么broker将从分组中移除消费者,并启动重新平衡。请注意,该值必须在broker配置的group.min.session.timeout.ms和group.max.session.timeout.ms允许的范围内。 |
int | 45000(45s) | high | |
| ssl.key.password | 密钥存储文件中的私钥的密码。 客户端可选 | password | null | high | |
| ssl.keystore.location | 密钥存储文件的位置, 这对于客户端是可选的,并且可以用于客户端的双向认证。 | string | null | high | |
| ssl.keystore.password | 密钥仓库文件的仓库密码。客户端可选,只有ssl.keystore.location配置了才需要。 | password | null | high | |
| ssl.truststore.location | 信任仓库文件的位置 | string | null | high | |
| ssl.truststore.password | 信任仓库文件的密码 | password | null | high | |
| auto.offset.reset | 当Kafka中没有初始offset或如果当前的offset不存在时(例如,该数据被删除了),该怎么办。 earliest:自动将偏移重置为最早的偏移 latest:自动将偏移重置为最新偏移 none:如果消费者组找到之前的offset,则向消费者抛出异常 其他:抛出异常给消费者。 |
string | latest | [latest, earliest, none] | medium |
| connections.max.idle.ms | 指定在多少毫秒之后关闭闲置的连接 | long | 540000 | medium | |
| enable.auto.commit | 如果为true,消费者的offset将在后台周期性的提交 | boolean | true | medium | |
| exclude.internal.topics | 内部topic的记录(如偏移量)是否应向消费者公开。如果设置为true,则从内部topic接受记录的唯一方法是订阅它。 | boolean | true | medium | |
| fetch.max.bytes | 服务器为拉取请求返回的最大数据值。这不是绝对的最大值,如果在第一次非空分区拉取的第一条消息大于该值,该消息将仍然返回,以确保消费者继续工作。接收的最大消息大小通过message.max.bytes (broker config) 或 max.message.bytes (topic config)定义。注意,消费者是并行执行多个提取的。 | int | 52428800 | [0,…] | medium |
| max.poll.interval.ms | 使用消费者组管理时poll()调用之间的最大延迟。消费者在获取更多记录之前可以空闲的时间量的上限。如果此超时时间期满之前poll()没有调用,则消费者被视为失败,并且分组将重新平衡,以便将分区重新分配给别的成员。 | int | 300000 | [1,…] | medium |
| max.poll.records | 在单次调用poll()中返回的最大消息数。 |
int | 500 | [1,…] | medium |
| partition.assignment.strategy | 当使用组管理时,客户端将使用分区分配策略的类名来分配消费者实例之间的分区所有权 | list | class org.apache.kafka .clients.consumer .RangeAssignor |
medium | |
| receive.buffer.bytes | 读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。 如果值为-1,则将使用OS默认值。 | int | 65536 | [-1,…] | medium |
| request.timeout.ms | 配置控制客户端等待请求响应的最长时间。 如果在超时之前未收到响应,客户端将在必要时重新发送请求,如果重试耗尽则客户端将重新发送请求。 | int | 305000 | [0,…] | medium |
| sasl.jaas.config | JAAS配置文件中SASL连接登录上下文参数。 这里描述JAAS配置文件格式。 该值的格式为: ‘(=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | Kafka运行Kerberos principal名。可以在Kafka的JAAS配置文件或在Kafka的配置文件中定义。 | string | null | medium | |
| sasl.mechanism | 用于客户端连接的SASL机制。安全提供者可用的机制。GSSAPI是默认机制。 | string | GSSAPI | medium | |
| security.protocol | 用于与broker通讯的协议。 有效值为:PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSL。 | string | PLAINTEXT | medium | |
| send.buffer.bytes | 发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。 如果值为-1,则将使用OS默认值。 | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | 启用SSL连接的协议列表。 | list | TLSv1.2,TLSv1.1,TLSv1 | medium | |
| ssl.keystore.type | key仓库文件的文件格式,客户端可选。 | string | JKS | medium | |
| ssl.protocol | 用于生成SSLContext的SSL协议。 默认设置是TLS,这对大多数情况都是适用的。 最新的JVM中的允许值为TLS,TLSv1.1和TLSv1.2。 较旧的JVM可能支持SSL,SSLv2和SSLv3,但由于已知的安全漏洞,不建议使用SSL。 | string | TLS | medium | |
| ssl.provider | 用于SSL连接的安全提供程序的名称。 默认值是JVM的默认安全提供程序。 | string | null | medium | |
| ssl.truststore.type | 信任存储文件的文件格式。 | string | JKS | medium | |
| auto.commit.interval.ms | 如果enable.auto.commit设置为true,则消费者偏移量自动提交给Kafka的频率(以毫秒为单位)。 | int | 5000 | [0,…] | low |
| check.crcs | 自动检查CRC32记录的消耗。 这样可以确保消息发生时不会在线或磁盘损坏。 此检查增加了一些开销,因此在寻求极致性能的情况下可能会被禁用。 | boolean | true | low | |
| client.id | 在发出请求时传递给服务器的id字符串。 这样做的目的是通过允许将逻辑应用程序名称包含在服务器端请求日志记录中,来跟踪ip/port的请求源。 | string | “” | low | |
| fetch.max.wait.ms | 如果没有足够的数据满足fetch.min.bytes,服务器将在接收到提取请求之前阻止的最大时间。 | int | 500 | [0,…] | low |
| interceptor.classes | 用作拦截器的类的列表。 你可实现ConsumerInterceptor接口以允许拦截(也可能变化)消费者接收的消息。 默认情况下,没有拦截器。 | list | null | low | |
| metadata.max.age.ms | 在一定时间段之后(以毫秒为单位的),强制更新元数据,即使没有任何分区领导变化,任何新的broker或分区。 | long | 300000 | [0,…] | low |
| metric.reporters | 用作度量记录员类的列表。实现MetricReporter接口以允许插入通知新的度量创建的类。JmxReporter始终包含在注册JMX统计信息中。 | list | “” | low | |
| metrics.num.samples | 保持的样本数以计算度量。 | int | 2 | [1,…] | low |
| metrics.recording.level | 最高的记录级别。 | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | The window of time a metrics sample is computed over. | long | 30000 | [0,…] | low |
| reconnect.backoff.ms | 尝试重新连接指定主机之前等待的时间,避免频繁的连接主机,这种机制适用于消费者向broker发送的所有请求。 | long | 50 | [0,…] | low |
| retry.backoff.ms | 尝试重新发送失败的请求到指定topic分区之前的等待时间。避免在某些故障情况下,频繁的重复发送。 | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd Kerberos | kinit命令路径。 | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | 尝试/恢复之间的登录线程的休眠时间。 | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | 添加到更新时间的随机抖动百分比。 | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将休眠,直到从上次刷新到ticket的指定的时间窗口因子到期,此时将尝试续订ticket。 | double | 0.8 | low | |
| ssl.cipher.suites | 密码套件列表,用于TLS或SSL网络协议的安全设置,认证,加密,MAC和密钥交换算法的明明组合。默认情况下,支持所有可用的密码套件。 | list | null | low | |
| ssl.endpoint.identification.algorithm | 使用服务器证书验证服务器主机名的端点识别算法。 | string | null | low | |
| ssl.keymanager.algorithm | 密钥管理器工厂用于SSL连接的算法。 默认值是为Java虚拟机配置的密钥管理器工厂算法。 | string | SunX509 | low | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现。 | string | null | low | |
| ssl.trustmanager.algorithm | 信任管理器工厂用于SSL连接的算法。 默认值是为Java虚拟机配置的信任管理器工厂算法。 | string | PKIX | low |
kafka >= 2.0.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| sasl.client.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。 | class | null | 中间 | |
| sasl.login.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的全称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler
|
class | null | 中间 | |
| sasl.login.class | 实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。 |
class | null | 中间 |
kafka >= 2.1.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| client.dns.lookup | 控制客户端如何使用DNS查询。如果设置为 use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次从主机名中解析IP(s)(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为 resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在bootstrap阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为 default(已弃用),则尝试连接到查找返回的第一个IP地址,即使查找返回多个IP地址。 |
string | use_all_dns_ips | [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] |
中间 |
kafka >= 2.7
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| ssl.truststore.certificates | 可信证书的格式由’ssl.truststore.type’指定。默认的SSL引擎工厂只支持带X.509证书的PEM格式。 | password | null | 高 | |
| socket.connection.setup.timeout.max.ms | 客户端等待建立socket连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用一个0.2的随机因子,导致计算值在20%以下和20%以上的随机范围。 | long | 127000 (127 seconds) | 中间 | |
| socket.connection.setup.timeout.ms | 客户端等待建立socket连接的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。 | long | 10000 (10 seconds) | 中间 |
旧消费者配置
| 名称 | 默认 | 描述 |
|---|---|---|
| group.id | 标识消费者所属消费者组(独一的)。通过设置相同的组ID,多个消费者表明属于该消费者组的一部分。 | |
| zookeeper.connect | 指定ZooKeeper连接字符串,格式为hostname:port,其中host和port是ZooKeeper服务器的主机和端口。 为了使ZooKeeper宕机时连接到其他ZooKeeper节点,你还可以以hostname1:host1,hostname2:port2,hostname3:port3的形式指定多个主机。 还可以设置ZooKeeper chroot路径,作为其ZooKeeper连接字符串的一部分,将其数据放置在全局ZooKeeper命名空间中的某个路径下。 如果是这样,消费者应该在其连接字符串中使用相同的chroot路径。 例如,要给出/chroot/path的chroot路径,你需要将该值设置为: hostname1:port1,hostname2:port2,hostname3:port3/chroot/path。 |
|
| consumer.id | null | 如果未设置将自动生成。 |
| socket.timeout.ms | 30 * 1000 | 网络请求socker的超时时间。实际的超时是 max.fetch.wait+socket.timeout.ms的时间。 |
| socket.receive.buffer.bytes | 64 * 1024 | 网络请求socker的接收缓存大小 |
| fetch.message.max.bytes | 1024 * 1024 | 每个拉取请求的每个topic分区尝试获取的消息的字节大小。这些字节将被读入每个分区的内存,因此这有助于控制消费者使用的内存。 拉取请求的大小至少与服务器允许的最大消息的大小一样大,否则生产者可能发送大于消费者可以拉取的消息。 |
| num.consumer.fetchers | 1 | 用于拉取数据的拉取线程数。 |
| auto.commit.enable | true | 如果为true,请定期向ZooKeeper提交消费者已经获取的消息的偏移量。 当进程失败时,将使用这种承诺偏移量作为新消费者开始的位置。 |
| auto.commit.interval.ms | 60 * 1000 | 消费者offset提交到zookeeper的频率(以毫秒为单位) |
| queued.max.message.chunks | 2 | 消费缓存消息块的最大大小。每个块可以达到fetch.message.max.bytes。 |
| rebalance.max.retries | 4 | 当新的消费者加入消费者组时,消费者集合尝试“重新平衡”负载,并为每个消费者分配分区。如果消费者集合在分配时发生时发生变化,则重新平衡将失败并重试。此设置控制尝试之前的最大尝试次数。 |
| fetch.min.bytes | 1 | 拉取请求返回最小的数据量。如果没有足够的数据,请求将等待数据积累,然后应答请求。 |
| fetch.wait.max.ms | 100 | 如果没有足够的数据(fetch.min.bytes),服务器将在返回请求数据之前阻塞的最长时间。 |
| rebalance.backoff.ms | 2000 | 重新平衡时重试之间的回退时间。如果未设置,则使用zookeeper.sync.time.ms中的值。 |
| refresh.leader.backoff.ms | 200 | 回退时间等待,然后再尝试选举一个刚刚失去leader的分区。 |
| auto.offset.reset | largest | 如果ZooKeeper中没有初始偏移量,或偏移值超出范围,该怎么办? 最小:自动将偏移重置为最小偏移 最大:自动将偏移重置为最大偏移 * 其他任何事情:抛出异常消费者 |
| consumer.timeout.ms | -1 | 如果在指定的时间间隔后没有消息可用,则向用户发出超时异常 |
| exclude.internal.topics | true | 来自内部topic的消息(如偏移量)是否应该暴露给消费者。 |
| client.id | group id value | 客户端ID是每个请求中发送的用户指定的字符串,用于帮助跟踪调用。 它应该逻辑地标识发出请求的应用程序。 |
| zookeeper.session.timeout.ms | 6000 | ZooKeeper会话超时。如果消费者在这段时间内没有对ZooKeeper心跳,那么它被认为是死亡的,并且会发生重新平衡。 |
| zookeeper.connection.timeout.ms | 6000 | 与zookeeper建立连接时客户端等待的最长时间。 |
| zookeeper.sync.time.ms | 2000 | ZK follower可以罗ZK leader多久 |
| offsets.storage | zookeeper | 选择存储偏移量的位置(zookeeper或kafka)。 |
| offsets.channel.backoff.ms | 1000 | 重新连接offset通道或重试失败的偏移提取/提交请求时的回退周期。 |
| offsets.channel.socket.timeout.ms | 10000 | 读取offset拉取/提交响应的Socker的超时时间。此超时也用于查询offset manager的ConsumerMetadata请求。 |
| offsets.commit.max.retries | 5 | 失败时重试偏移提交的最大次数。此重试计数仅适用于停机期间的offset提交,它不适用于自动提交线程的提交。它也不适用于在提交offset之前查询偏移协调器的尝试。即如果消费者元数据请求由于任何原因而失败,则将重试它,并且重试不计入该限制。 |
| dual.commit.enabled | true | 如果使用“kafka”作为offsets.storage,则可以向ZooKeeper(除Kafka之外)进行双重提交offset。在从基于zookeeper的offset存储迁移到kafka存储的时候可以这么做。对于任何给定的消费者组,在该组中的所有实例已迁移到提交到broker(而不是直接到ZooKeeper)的新的版本之后,可以关闭这个。 |
| partition.assignment.strategy | range | 在“range”或“roundrobin”策略之间选择将分区分配给消费者流。 循环分区分配器分配所有可用的分区和所有可用的消费者线程。然后,继续从分区到消费者线程进行循环任务。如果所有消费者实例的订阅是相同的,则分区将被均匀分布。(即,分区所有权计数将在所有消费者线程之间的差异仅在一个delta之内。)循环分配仅在以下情况下被允许:(a)每个主题在消费者实例中具有相同数量的流(b)订阅的topic的对于组内的每个消费者实例都是相同的。 范围(Range)分区基于每个topic。对于每个主题,我们按数字顺序排列可用的分区,并以字典顺序排列消费者线程。然后,我们将分区数除以消费者流(线程)的总数来确定分配给每个消费者的分区数。如果不均匀分割,那么前几个消费者将会有多的分区。 |
Streams配置
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| application.id | 流处理应用程序标识。必须在Kafka集群中是独一无二的。 1)默认客户端ID前缀,2)成员资格管理的group-id,3)changgelog的topic前缀 | string | high | ||
| bootstrap.servers | 用于建立与Kafka集群的初始连接的主机/端口列表。 客户端将会连接所有服务器,跟指定哪些服务器无关 – 通过指定的服务器列表会自动发现全部的服务器。此列表格式host1:port1,host2:port2,…由于这些服务器仅用于初始连接以发现完整的集群成员(可能会动态更改),所以此列表不需要包含完整集 的服务器(您可能需要多个服务器,以防指定的服务器关闭)。 | list | high | ||
| replication.factor | 流处理程序创建更改日志topic和重新分配topic的副本数 | int | 1 | high | |
| state.dir | 状态存储的目录地址。 | string | /tmp/kafka-streams | high | |
| cache.max.bytes.buffering | 用于缓冲所有线程的最大内存字节数 | long | 10485760 | [0,…] | low |
| client.id | 发出请求时传递给服务器的id字符串。 这样做的目的是通过允许将逻辑应用程序名称包含在服务器端请求日志记录中,来追踪请求源的ip/port。 | string | “” | high | |
| default.key.serde | 用于实现Serde接口的key的默认序列化器/解串器类。 | class | org.apache.kafka.common.serialization.Serdes$ByteArraySerde | medium | |
| default.timestamp.extractor | 实现TimestampExtractor接口的默认时间戳提取器类。 | class | org.apache.kafka.streams.processor.FailOnInvalidTimestamp | medium | |
| default.value.serde | 用于实现Serde接口的值的默认serializer / deserializer类。 | class | org.apache.kafka.common.serialization.Serdes$ByteArraySerde | medium | |
| num.standby.replicas | 每个任务的备用副本数。 | int | 0 | low | |
| num.stream.threads | 执行流处理的线程数。 | int | 1 | low | |
| processing.guarantee | 应使用的加工保证。可能的值为at_least_once(默认)和exact_once。 | string | at_least_once | [at_least_once, exactly_once] | medium |
| security.protocol | 用于与broker沟通的协议。 有效值为:PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSL。 | string | PLAINTEXT | medium | |
| application.server | host:port指向用户嵌入定义的末端,可用于发现单个KafkaStreams应用程序中状态存储的位置 | string | “” | low | |
| buffered.records.per.partition | 每个分区缓存的最大记录数。 | int | 1000 | low | |
| commit.interval.ms | 用于保存process位置的频率。 注意,如果’processing.guarantee’设置为’exact_once’,默认值为100,否则默认值为30000。 | long | 30000 | low | |
| connections.max.idle.ms | 关闭闲置的连接时间(以毫秒为单位)。 | long | 540000 | medium | |
| key.serde | 用于实现Serde接口的key的Serializer/deserializer类.此配置已被弃用,请改用default.key.serde | class | null | low | |
| metadata.max.age.ms | 即使我们没有看到任何分区leader发生变化,主动发现新的broker或分区,强制更新元数据时间(以毫秒为单位)。 | long | 300000 | [0,…] | low |
| metric.reporters | metric reporter的类列表。实现MetricReporter接口,JmxReporter始终包含在注册JMX统计信息中。 | list | “” | low | |
| metrics.num.samples | 保持的样本数以计算度量。 | int | 2 | [1,…] | low |
| metrics.recording.level | 日志级别。 | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | 时间窗口计算度量标准。 | long | 30000 | [0,…] | low |
| partition.grouper | 实现PartitionGrouper接口的Partition grouper类。 | class | org.apache .kafka.streams .processor .DefaultPartitionGrouper |
medium | |
| poll.ms | 阻塞输入等待的时间(以毫秒为单位)。 | long | 100 | low | |
| receive.buffer.bytes | 读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。 如果值为-1,则将使用OS默认值。 | int | 32768 | [0,…] | medium |
| reconnect.backoff.max.ms | 因故障无法重新连接broker,重新连接的等待的最大时间(毫秒)。如果提供,每个主机会连续增加,直到达到最大值。随机递增20%的随机抖动以避免连接风暴。 | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | 尝试重新连接之前等待的时间。避免在高频繁的重复连接服务器。 这种backoff适用于消费者向broker发送的所有请求。 | long | 50 | [0,…] | low |
| request.timeout.ms | 控制客户端等待请求响应的最长时间。如果在配置时间内未收到响应,客户端将在需要时重新发送请求,如果重试耗尽,则请求失败。 | int | 40000 | [0,…] | low |
| retry.backoff.ms | 尝试重试失败请求之前等待的时间。以避免了在某些故障情况下,在频繁重复发送请求。 | long | 100 | [0,…] | low |
| rocksdb.config.setter | 一个Rocks DB配置setter类,或实现RocksDBConfigSetter接口的类名 | null | low | ||
| send.buffer.bytes | 发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。 如果值为-1,则将使用OS默认值。 | int | 131072 | [0,…] | low |
| state.cleanup.delay.ms | 在分区迁移删除状态之前等待的时间(毫秒)。 | long | 60000 | low | |
| timestamp.extractor | 实现TimestampExtractor接口的Timestamp抽取器类。此配置已弃用,请改用default.timestamp.extractor | class | null | low | |
| windowstore.changelog.additional.retention.ms | 添加到Windows维护管理器以确保数据不会从日志中过早删除。默认为1天 | long | 86400000 | low | |
| zookeeper.connect | Zookeeper连接字符串,用于Kafka主题管理。此配置已被弃用,将被忽略,因为Streams API不再使用Zookeeper。 | string | “” | low |
Connect配置
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| config.storage.topic | kafka topic仓库配置 | string | high | ||
| group.id | 唯一的字符串,用于标识此worker所属的Connect集群组。 | string | high | ||
| key.converter | 用于Kafka Connect和写入到Kafka的序列化消息的之间格式转换的转换器类。 这可以控制写入或从kafka读取的消息中的键的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 | class | high | ||
| offset.storage.topic | 连接器的offset存储到哪个topic中 | string | high | ||
| status.storage.topic | 追踪连接器和任务状态存储到哪个topic中 | string | high | ||
| value.converter | 用于Kafka Connect格式和写入Kafka的序列化格式之间转换的转换器类。 控制了写入或从Kafka读取的消息中的值的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 | class | high | ||
| internal.key.converter | 用于在Kafka Connect格式和写入Kafka的序列化格式之间转换的转换器类。 这可以控制写入或从Kafka读取的消息中的key的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 此设置用于控制框架内部使用的记账数据的格式,例如配置和偏移量,因此用户可以使用运行各种Converter实现。 | class | low | ||
| internal.value.converter | 用于在Kafka Connect格式和写入Kafka的序列化格式之间转换的转换器类。 这控制了写入或从Kafka读取的消息中的值的格式,并且由于这与连接器无关,因此它允许任何连接器使用任何序列化格式。 常见格式的示例包括JSON和Avro。 此设置用于控制框架内部使用的记账数据的格式,例如配置和偏移量,因此用户可以使用运行各种Converter实现。 | class | low | ||
| bootstrap.servers | 用于建立与Kafka集群的初始连接的主机/端口列表。此列表用来发现完整服务器集的初始主机。 该列表的格式应为host1:port1,host2:port2,….由于这些服务器仅用于初始连接以发现完整的集群成员资格(可能会动态更改),因此,不需要包含完整的服务器(尽管如此,你需要多配置几个,以防止配置的宕机)。 | list | localhost:9092 | high | |
| heartbeat.interval.ms | 心跳间隔时间。心跳用于确保会话保持活动,并在新成员加入或离开组时进行重新平衡。 该值必须设置为低于session.timeout.ms,但通常应设置为不高于该值的1/3。 | int | 3000 | high | |
| rebalance.timeout.ms | 限制所有组中消费者的任务处理数据和提交offset所需的时间。如果超时,那么woker将从组中删除,这也将导致offset提交失败。 | int | 60000 | high | |
| session.timeout.ms | 用于察觉worker故障的超时时间。worker定时发送心跳以表明自己是活着的。如果broker在会话超时时间到期之前没有接收到心跳,那么broker将从分组中移除该worker,并启动重新平衡。注意,该值必须在group.min.session.timeout.ms和group.max.session.timeout.ms范围内。 |
int | 10000 | high | |
| ssl.key.password | 密钥存储文件中私钥的密码。 这对于客户端是可选的。 | password | null | high | |
| ssl.keystore.location | 密钥存储文件的位置。 这对于客户端是可选的,可以用于客户端的双向身份验证。 | string | null | high | |
| ssl.keystore.password | 密钥存储文件的存储密码。 客户端是可选的,只有配置了ssl.keystore.location才需要。 | password | null | high | |
| ssl.truststore.location | 信任存储文件的位置。 | string | null | high | |
| ssl.truststore.password | 信任存储文件的密码。 | password | null | high | |
| connections.max.idle.ms | 多少毫秒之后关闭空闲的连接。 | long | 540000 | medium | |
| receive.buffer.bytes | 读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。 如果值为-1,则将使用OS默认值。 | int | 32768 | [0,…] | medium |
| request.timeout.ms | 配置控制客户端等待请求响应的最长时间。 如果在超时之前未收到响应,客户端将在必要时重新发送请求,如果重试耗尽,则该请求将失败。 | int | 40000 | [0,…] | medium |
| sasl.jaas.config | 用于JAAS配置文件的SASL连接的JAAS登录上下文参数格式。这里描述了JAAS配置文件的格式。该值的格式为:’ (=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | Kafka运行的Kerberos principal名称。 可以在Kafka的JAAS配置或Kafka的配置中定义。 | string | null | medium | |
| sasl.mechanism | 用户客户端连接的SASL机制。可以提供者任何安全机制。 GSSAPI是默认机制。 | string | GSSAPI | medium | |
| security.protocol | 用于和broker通讯的策略。有效的值有:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL。 | string | PLAINTEXT | medium | |
| send.buffer.bytes | 发送数据时使用TCP发送缓冲区(SO_SNDBUF)的大小。如果值为-1,则将使用OS默认。 | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | 启用SSL连接的协议列表。 | list | TLSv1.2,TLSv1 .1,TLSv1 |
medium | |
| ssl.keystore.type | 密钥存储文件的文件格式。 对于客户端是可选的。 | string | JKS | medium | |
| ssl.protocol | 用于生成SSLContext的SSL协议。 默认设置是TLS,这对大多数情况都是适用的。 最新的JVM中的允许值为TLS,TLSv1.1和TLSv1.2。 旧的JVM可能支持SSL,SSLv2和SSLv3,但由于已知的安全漏洞,不建议使用SSL。 | string | TLS | medium | |
| ssl.provider | 用于SSL连接的安全提供程序的名称。 默认值是JVM的默认安全提供程序。 | string | null | medium | |
| ssl.truststore.type | 信任存储文件的文件格式。 | string | JKS | medium | |
| worker.sync.timeout.ms | 当worker与其他worker不同步并需要重新同步配置时,需等待一段时间才能离开组,然后才能重新加入。 | int | 3000 | medium | |
| worker.unsync.backoff.ms | 当worker与其他worker不同步,并且无法在worker.sync.timeout.ms 期间追赶上,在重新连接之前,退出Connect集群的时间。 | int | 300000 | medium | |
| access.control.allow.methods | 通过设置Access-Control-Allow-Methods标头来设置跨源请求支持的方法。 Access-Control-Allow-Methods标头的默认值允许GET,POST和HEAD的跨源请求。 | string | “” | low | |
| access.control.allow.origin | 将Access-Control-Allow-Origin标头设置为REST API请求。要启用跨源访问,请将其设置为应该允许访问API的应用程序的域,或者 *” 以允许从任何的域。 默认值只允许从REST API的域访问。 |
string | “” | low | |
| client.id | 在发出请求时传递给服务器的id字符串。这样做的目的是通过允许逻辑应用程序名称包含在请求消息中,来跟踪请求来源。而不仅仅是ip/port | string | “” | low | |
| config.storage.replication.factor | 当创建配置仓库topic时的副本数 | short | 3 | [1,…] | low |
| metadata.max.age.ms | 在没有任何分区leader改变,主动地发现新的broker或分区的时间。 | long | 300000 | [0,…] | low |
| metric.reporters | A list of classes to use as metrics reporters. Implementing the MetricReporter interface allows plugging in classes that will be notified of new metric creation. The JmxReporter is always included to register JMX statistics. | list | “” | low | |
| metrics.num.samples | 保留计算metrics的样本数(译者不清楚是做什么的) | int | 2 | [1,…] | low |
| metrics.sample.window.ms | The window of time a metrics sample is computed over. | long | 30000 | [0,…] | low |
| offset.flush.interval.ms | 尝试提交任务偏移量的间隔。 | long | 60000 | low | |
| offset.flush.timeout.ms | 在取消进程并恢复要在之后尝试提交的offset数据之前,等待消息刷新并分配要提交到offset仓库的offset数据的最大毫秒数。 | long | 5000 | low | |
| offset.storage.partitions | 创建offset仓库topic的分区数 | int | 25 | [1,…] | low |
| offset.storage.replication.factor | 创建offset仓库topic的副本数 | short | 3 | [1,…] | low |
| plugin.path | 包含插件(连接器,转换器,转换)逗号(,)分隔的路径列表。该列表应包含顶级目录,其中包括以下任何组合:a)包含jars与插件及其依赖关系的目录 b)具有插件及其依赖项的uber-jars c)包含插件类的包目录结构的目录及其依赖关系,注意:将遵循符号链接来发现依赖关系或插件。 示例:plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors | list | null | low | |
| reconnect.backoff.max.ms | 无法连接broker时等待的最大时间(毫秒)。如果设置,则每个host的将会持续的增加,直到达到最大值。计算增加后,再增加20%的随机抖动,以避免高频的反复连接。 | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | 尝试重新连接到主机之前等待的时间。 避免了高频率反复的连接主机。 这种机制适用于消费者向broker发送的所有请求。 | long | 50 | [0,…] | low |
| rest.advertised.host.name | 如果设置,其他wokers将通过这个hostname进行连接。 | string | null | low | |
| rest.advertised.port | 如果设置,其他的worker将通过这个端口进行连接。 | int | null | low | |
| rest.host.name | REST API的主机名。 如果设置,它将只绑定到这个接口。 | string | null | low | |
| rest.port | 用于监听REST API的端口 | int | 8083 | low | |
| retry.backoff.ms | 失败请求重新尝试之前的等待时间,避免了在某些故障的情况下,频繁的重复发送请求。 | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit命令路径. | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | 尝试refresh之间登录线程的休眠时间. | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | 添加到更新时间的随机抖动百分比。 | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将休眠,直到从上次刷新ticket到期,此时将尝试续订ticket。 | double | 0.8 | low | |
| ssl.cipher.suites | 密码套件列表。用于TLS或SSL网络协议协商网络连接的安全设置的认证,加密,MAC和密钥交换算法的命名组合。 默认情况下,支持所有可用的密码套件。 | list | null | low | |
| ssl.endpoint.identification.algorithm | 末端识别算法使用服务器证书验证服务器主机名。 | string | null | low | |
| ssl.keymanager.algorithm | 用于SSL连接的key管理工厂的算法,默认值是Java虚拟机配置的密钥管理工厂算法。 | string | SunX509 | low | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现。 | string | null | low | |
| ssl.trustmanager.algorithm | 用于SSL连接的信任管理仓库算法。默认值是Java虚拟机配置的信任管理器工厂算法。 | string | PKIX | low | |
| status.storage.partitions | 用于创建状态仓库topic的分区数 | int | 5 | [1,…] | low |
| status.storage.replication.factor | 用于创建状态仓库topic的副本数 | short | 3 | [1,…] | low |
| task.shutdown.graceful.timeout.ms | 等待任务正常关闭的时间,这是总时间,不是每个任务,所有任务触发关闭,然后依次等待。 | long | 5000 | low |
kafka >= 2.0.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| sasl.client.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。 | class | null | 中间 | |
| sasl.login.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的全称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler
|
class | null | 中间 | |
| sasl.login.class | 实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。 |
class | null | 中间 |
kafka >= 2.7
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| ssl.truststore.certificates | 可信证书的格式由’ssl.truststore.type’指定。默认的SSL引擎工厂只支持带X.509证书的PEM格式。 | password | null | 高 | |
| socket.connection.setup.timeout.max.ms | 客户端等待建立socket连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用一个0.2的随机因子,导致计算值在20%以下和20%以上的随机范围。 | long | 127000 (127 seconds) | 中间 | |
| socket.connection.setup.timeout.ms | 客户端等待建立socket连接的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。 | long | 10000 (10 seconds) | 中间 |
AdminClient配置
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| bootstrap.servers | host/port,用于和kafka集群建立初始化连接。因为这些服务器地址仅用于初始化连接,并通过现有配置的来发现全部的kafka集群成员(集群随时会变化),所以此列表不需要包含完整的集群地址(但尽量多配置几个,以防止配置的服务器宕机)。 | list | high | ||
| ssl.key.password | 密钥仓库文件中的私钥密码。对于客户端是可选的。 | password | null | high | |
| ssl.keystore.location | 密钥仓库文件的位置。这对于客户端是可选的,可以用于客户端的双向认证。 | string | null | high | |
| ssl.keystore.password | 密钥仓库文件的仓库密钥。这对于客户端是可选的,只有配置了ssl.keystore.location才需要。 | password | null | high | |
| ssl.truststore.location | 信任存储文件的位置。 | string | null | high | |
| ssl.truststore.password | 信任存储文件的密码。如果未设置密码,对信任库的访问仍然可用,但是完整性检查将被禁用。 | password | null | high | |
| client.id | 在发出请求时传递给服务器的id字符串。这样做的目的是通过允许在服务器端请求日志记录中包含逻辑应用程序名称来跟踪请求源的ip/port。 | string | “” | medium | |
| connections.max.idle.ms | 关闭闲置连接的时间。 | long | 300000 | medium | |
| receive.buffer.bytes | 读取数据时使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果值为-1,则将使用OS默认值。 | int | 65536 | [-1,…] | medium |
| request.timeout.ms | 配置控制客户端等待请求响应的最长时间。如果在超时之前未收到响应,客户端将在必要时重新发送请求,如果重试耗尽,则该请求将失败。 | int | 120000 | [0,…] | medium |
| sasl.jaas.config | JAAS配置文件使用的格式的SASL连接的JAAS登录上下文参数。这里描述JAAS配置文件格式。该值的格式为:’ (=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | Kafka运行的Kerberos principal名。可以在Kafka的JAAS配置或Kafka的配置中定义。 | string | null | medium | |
| sasl.mechanism | 用于客户端连接的SASL机制。安全提供者可用的任何机制。GSSAPI是默认机制。 | string | GSSAPI | medium | |
| security.protocol | 与broker通讯的协议。有效的值有: PLAINTEXT, SSL, SASL_PLAINTEXT,SASL_SSL. | string | PLAINTEXT | medium | |
| send.buffer.bytes | 发送数据时时使用TCP发送缓冲区(SO_SNDBUF)的大小。如果值为-1,则使用OS默认值。 | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | 启用SSL连接的协议列表。 | list | TLSv1.2,TLSv1.1,TLSv1 | medium | |
| ssl.keystore.type | 密钥仓库文件的文件格式。对于客户端是可选的。 | string | JKS | medium | |
| ssl.protocol | 用于生成SSLContext的SSL协议。默认设置是TLS,这对大多数情况都是适用的。最新的JVM中允许的值是TLS,TLSv1.1和TLSv1.2。较旧的JVM可能支持SSL,SSLv2和SSLv3,但由于已知的安全漏洞,不建议使用。 | string | TLS | medium | |
| ssl.provider | 用于SSL连接的安全提供程序的名称。 默认值是JVM的默认安全提供程序。 | string | null | medium | |
| ssl.truststore.type | 信任仓库文件的文件格式 | string | JKS | medium | |
| metadata.max.age.ms | 我们强制更新元数据的时间段(以毫秒为单位),即使我们没有任何分区leader发生变化,主动发现任何新的broker或分区。 | long | 300000 | [0,…] | low |
| metric.reporters | 用作指标记录的类的列表。实现MetricReporter接口,以允许插入将被通知新的度量创建的类。JmxReporter始终包含在注册JMX统计信息中。 | list | “” | low | |
| metrics.num.samples | 用于计算度量维护的样例数。 | int | 2 | [1,…] | low |
| metrics.recording.level | The highest recording level for metrics. | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | 时间窗口计算度量标准。 | long | 30000 | [0,…] | low |
| reconnect.backoff.max.ms | 重新连接到重复无法连接的broker程序时等待的最大时间(毫秒)。如果提供,每个主机的回退将会连续增加,直到达到最大值。 计算后退增加后,增加20%的随机抖动以避免连接风暴。 | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | 尝试重新连接到给定主机之前等待的基本时间量。这避免了在频繁的重复连接主机。此配置适用于client对broker的所有连接尝试。 | long | 50 | [0,…] | low |
| retries | 在失败之前重试调用的最大次数 | int | 5 | [0,…] | low |
| retry.backoff.ms | 尝试重试失败的请求之前等待的时间。这样可以避免在某些故障情况下以频繁的重复发送请求。 | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit命令路径。 | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | 刷新尝试之间的登录线程睡眠时间。 | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | 添加到更新时间的随机抖动百分比。 | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将休眠,直到从上次刷新到“票”到期时间的指定窗口为止,此时将尝试续订“票”。 | double | 0.8 | low | |
| ssl.cipher.suites | 密码套件列表。是TLS或SSL网络协议来协商用于网络连接的安全设置的认证,加密,MAC和密钥交换算法的命名组合。默认情况下,支持所有可用的密码套件。 | list | null | low | |
| ssl.endpoint.identification.algorithm | 使用服务器证书验证服务器主机名的端点识别算法。 | string | null | low | |
| ssl.keymanager.algorithm | 用于SSL连接的密钥管理工厂算法。默认值是Java虚拟机配置的密钥管理器工厂算法。 | string | SunX509 | low | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现。 | string | null | low | |
| ssl.trustmanager.algorithm | 用于SSL连接的信任管理工厂算法,默认是Java虚拟机机制。 | string | PKIX | low |
kafka >= 2.0.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| sasl.client.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL客户端回调处理程序类的全称。 | class | null | 中间 | |
| sasl.login.callback.handler.class | 实现AuthenticateCallbackHandler接口的SASL登录回调处理程序类的全称。对于broker来说,登录回调处理程序配置必须以监听器前缀和小写的SASL机制名称为前缀。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.callback.handler.class=com.example.CustomScramLoginCallbackHandler
|
class | null | 中间 | |
| sasl.login.class | 实现Login接口的类的全称。对于broker来说,login config必须以监听器前缀和SASL机制名称为前缀,并使用小写。例如,listener.name.sasl_ssl.scram-sha-256.sasl.login.class=com.example.CustomScramLogin。 |
class | null | 中间 |
kafka >= 2.1.0
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| client.dns.lookup | 控制客户端如何使用DNS查询。如果设置为 use_all_dns_ips,则依次连接到每个返回的IP地址,直到成功建立连接。断开连接后,使用下一个IP。一旦所有的IP都被使用过一次,客户端就会再次从主机名中解析IP(s)(然而,JVM和操作系统都会缓存DNS名称查询)。如果设置为 resolve_canonical_bootstrap_servers_only,则将每个引导地址解析成一个canonical名称列表。在bootstrap阶段之后,这和use_all_dns_ips的行为是一样的。如果设置为 default(已弃用),则尝试连接到查找返回的第一个IP地址,即使查找返回多个IP地址。 |
string | use_all_dns_ips | [default, use_all_dns_ips, resolve_canonical_bootstrap_servers_only] | 中间 |
kafka >= 2.7
| 名称 | 描述 | 类型 | 默认 | 有效值 | 重要程度 |
|---|---|---|---|---|---|
| ssl.truststore.certificates | 可信证书的格式由’ssl.truststore.type’指定。默认的SSL引擎工厂只支持带X.509证书的PEM格式。 | password | null | 高 | |
| socket.connection.setup.timeout.max.ms | 客户端等待建立socket连接的最大时间。连接设置超时时间将随着每一次连续的连接失败而成倍增加,直到这个最大值。为了避免连接风暴,超时时间将被应用一个0.2的随机因子,导致计算值在20%以下和20%以上的随机范围。 | long | 127000 (127 seconds) | 中间 | |
| socket.connection.setup.timeout.ms | 客户端等待建立socket连接的时间。如果在超时之前没有建立连接,客户端将关闭socket通道。 | long | 10000 (10 seconds) | 中间 |
更多的配置可以参考文档
https://github.com/apachecn/kafka-doc-zh
kafka 命令
查看kafka版本
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --version
3.7.0Topic创建
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --create --bootstrap-server 10.4.3.41:29092 --replication-factor 3 --partitions 3 --topic test-nmd
Created topic test-nmd.
kafka-1:/opt/kafka/bin$ kafka-topics.sh 相关可选参数
-
--alter更改分区数和副本分配。此处不再支持通过–alter更新现有主题的配置(kafka configs CLI支持使用–bootstrap server选项更改主题配置)。 -
--at-min-isr-partitions如果在描述主题时设置了最小isr分区,则仅显示isr计数等于配置的最小值的分区。 -
--bootstrap-server<String:server to REQUIRED:连接到的Kafka服务器>到。 -
--command-config<String:command-Property-file包含要作为配置属性文件的配置> 传递给管理客户端。这仅与–bootstrap服务器选项一起使用,用于描述和更改代理配置 -
--config<String:name=value> 正在创建的主题的主题配置覆盖。以下内容是有效配置的列表:(具体含义参考上文的Topic配置)- cleanup.policy
- compression.type
- delete.retention.ms
- file.delete.delay.ms
- flush.messages
- flush.ms
- follower.replication.throttled.
- replicas
- index.interval.bytes
- leader.replication.throttled.replicas
- local.retention.bytes
- local.retention.ms
- max.compaction.lag.ms
- max.message.bytes
- message.downconversion.enable
- message.format.version
- message.timestamp.after.max.ms
- message.timestamp.before.max.ms
- message.timestamp.difference.max.ms
- message.timestamp.type
- min.cleanable.dirty.ratio
- min.compaction.lag.ms
- min.insync.replicas
- preallocate
- remote.storage.enable
- retention.bytes
- retention.ms
- segment.bytes
- segment.index.bytes
- segment.jitter.ms
- segment.ms
- unclean.leader.election.enable
-
--create创建一个新主题。 -
--delete删除主题 -
--delete-config<String:name> 要为现有主题删除的主题配置覆盖(请参阅–config选项下的配置列表)。–bootstrap服务器选项不支持。 -
--describe列出给定主题的详细信息。 -
--exclude-internal运行list或describe命令时排除内部主题。默认情况下会列出内部主题 -
--help打印使用信息。 -
--if-exists如果在更改、删除或描述主题时设置,则仅当主题存在时才执行该操作。 -
--if-not-exists(如果在创建主题时设置),则仅当主题不存在时才执行该操作。 -
--list列出所有可用的主题。 -
--partitions<Integer:分区数> 正在创建或更改的主题的分区数(警告:如果为具有键的主题增加分区,则分区逻辑或消息顺序将受到影响)。如果创建时未指定,则默认为集群默认值(集群中kafka的数量),推荐使用默认值。 -
--replica-assignment<String:broker_id_for_part1_replica1的手动分区列表:创建或更改的broker_id_for_part1_replica2主题的分配。broker_id_for_part2_replica1:broker_id_for_part2_replica2,…> -
--replication-factor<Integer:正在创建的主题中每个复制因子> 分区的复制因子。如果未提供,则默认为集群默认值(集群中kafka的数量)。 -
--topic<String:topic> 要创建、更改、描述或删除的主题。它还接受一个正则表达式,但–create选项除外。将主题名称置于双引号中,并使用“\”前缀转义正则表达式符号;例如“测试主题”。 -
--topic-id<String:topic id> 要描述的主题id。这仅与用于描述主题的–bootstrap服务器选项一起使用。 -
--topics-with-overrides如果在描述主题时设置了覆盖,则仅显示具有覆盖配置的主题 -
--unavailable-partitions如果在描述主题时设置了不可用分区,则仅显示引线不可用的分区 -
--under-min-isr-partitions如果在描述主题时设置了最小isr分区,则只显示isr计数小于配置的最小值的分区。 -
--under-replicated-partitions如果在描述主题时设置,则仅显示在已复制的分区下 -
--version显示kafka版本。
删除Topic
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --delete --topic test-nmd支持正则表达式匹配Topic来进行删除,只需要将topic 用双引号包裹起来
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --delete --topic "test.*". : 表示任意匹配除换行符 \n 之外的任何单字符
* : 匹配前面的子表达式零次或多次
.* : 任意字符
Topic分区扩容
--alter 更改分区数和副本分配。
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --alter --topic test-nmds --partitions 4批量扩容利用正则表达式
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --topic "test-nmds.*" --bootstrap-server 10.4.3.41:29092 --alter --partitions 5分区数量能增加但是不能减少
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --topic "test-nmds.*" --bootstrap-server 10.4.3.41:29092 --alter --partitions 5
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --topic "test-nmds.*" --bootstrap-server 10.4.3.41:29092 --alter --partitions 3
Error while executing topic command : The topic test-nmds currently has 5 partition(s); 3 would not be an increase.
[2024-03-29 08:57:55,055] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: The topic test-nmds currently has 5 partition(s); 3 would not be an increase.
(org.apache.kafka.tools.TopicCommand)相关可选参数
--replica-assignment
副本分区分配方式;创建topic的时候可以自己指定副本分配情况
当使用’--replica-assignment‘这个命令时,不再需要指定分区数量和副本数量,kafka会根据’--replica-assignment‘后面的参数自动获取分区和副本的信息
以’,’区分分区数量,’:’前后为该分区的副本所存储的broker
./kafka-topics.sh --create --bootstrap-server 10.4.3.41:29092 --replica-assignment "1:2,2:3" --topic tpc03查看topic的信息
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --topic tpc03 --bootstrap-server 10.4.3.41:29092 --describe --exclude-internal
Topic: tpc03 TopicId: 2rFVsf3cS7CYL7QxnF_WdA PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: tpc03 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: tpc03 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3比如上面的命令 “1:2,2:3” ,指的是创建2个分区,第一个分区在节点 1 ,2 上 ,第二个分区在节点 2,3 上,因为我们知道分区是分布在不同的节点上的,每个分区有各自的Leader与Follower。
可以分布在多个节点上,比如 1:2:3 ,就是 1,2,3节点上,注意这里的1,2,3是broker的ID,也就是 KAFKA_NODE_ID
kafka-2:/opt/kafka/bin$ ./kafka-topics.sh --create --bootstrap-server 82.157.173.74:29092 --replica-assignment "1:2:3,2:3:4" --topic tpc05
Created topic tpc05.
kafka-2:/opt/kafka/bin$ ./kafka-topics.sh --topic tpc05 --bootstrap-server 82.157.173.74:29092 --describe --exclude-internal
Topic: tpc05 TopicId: XsPaDaTnQTeBgjgjHuqj3A PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: tpc05 Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: tpc05 Partition: 1 Leader: 2 Replicas: 2,3,4 Isr: 2,3,4查询Topic列表
--bootstrap server<String:server to REQUIRED:连接到的Kafka服务器>
--list:列出所有可用的主题
连接单个kafka
./kafka-topics.sh --list --bootstrap-server 82.157.173.74:29092连接多个kafka,用英文逗号隔开
./kafka-topics.sh --bootstrap-server 82.157.173.74:29092,82.157.173.74:39092,82.157.173.74:49092 --list查询匹配Topic列表(正则表达式)
查询tpc0开头的所有Topic列表
./kafka-topics.sh --bootstrap-server 82.157.173.74:29092 --list --exclude-internal --topic "tpc0.*"相关可选参数
-
--exclude-internal- 排除kafka内部topic,比如
__consumer_offsets-*
- 排除kafka内部topic,比如
-
--topic- 可以正则表达式进行匹配,展示topic名称
查看Topic详情
--describe:列出给定主题的详细信息
./kafka-topics.sh --bootstrap-server 82.157.173.74:29092 --describe --topic tpc03结果
kafka-2:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 82.157.173.74:29092 --describe --topic tpc03
Topic: tpc03 TopicId: yddcaIFHT26Zqrnf_VafeQ PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: tpc03 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: tpc03 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2这里同样可以使用正则表达式
kafka-2:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 82.157.173.74:29092 --describe --topic "tpc0.*"
Topic: tpc03 TopicId: yddcaIFHT26Zqrnf_VafeQ PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: tpc03 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: tpc03 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2
Topic: tpc05 TopicId: XsPaDaTnQTeBgjgjHuqj3A PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: tpc05 Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: tpc05 Partition: 1 Leader: 2 Replicas: 2,3,4 Isr: 2以下是输出内容的解释,第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息。
- leader 节点负责给定 partition 的所有读写请求。
- replicas 表示某个partition在哪几个broker上存在备份。不管这个节点是不是”leader“,甚至这个节点挂了,也会列出。
- isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
配置查询
查询其他配置/clients/users/brokers/broker-loggers 的查询
只需要将--entity-type 改成对应的类型就行了 (topics/clients/users/brokers/broker-loggers)
-
--entity-type:实体类型(主题/客户端/用户/经纪人/经纪人记录器/ips/客户端指标) --entity-name:实体名称(主题名称/客户端id/用户主体名称/代理id/ip/客户端度量)
例如
./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --all --entity-type topics下面用查询Topic为例子
kafka-configs.sh 相关可选参数
-
--add-config<String>:要添加的配置的键值对。方括号可用于对包含逗号的值进行分组:“k1=v1,k2=[v1,v2,v2],k3=v3”。以下是有效配置的列表:- For entity-type ‘topics’:
- cleanup.policy
- compression.type
- delete.retention.ms
- file.delete.delay.ms
- flush.messages
- flush.ms
- follower.replication.throttled.
- replicas
- index.interval.bytes
- leader.replication.throttled.replicas
- local.retention.bytes
- local.retention.ms
- max.compaction.lag.ms
- max.message.bytes
- message.downconversion.enable
- message.format.version
- message.timestamp.after.max.ms
- message.timestamp.before.max.ms
- message.timestamp.difference.max.ms
- message.timestamp.type
- min.cleanable.dirty.ratio
- min.compaction.lag.ms
- min.insync.replicas
- preallocate
- remote.storage.enable
- retention.bytes
- retention.ms
- segment.bytes
- segment.index.bytes
- segment.jitter.ms
- segment.ms
- unclean.leader.election.enable
- For entity-type ‘brokers’:
- advertised.listeners
- background.threads
- compression.type
- follower.replication.throttled.rate
- leader.replication.throttled.rate
- listener.security.protocol.map
- listeners
- log.cleaner.backoff.ms
- log.cleaner.dedupe.buffer.size
- log.cleaner.delete.retention.ms
- log.cleaner.io.buffer.load.factor
- log.cleaner.io.buffer.size
- log.cleaner.io.max.bytes.per.second
- log.cleaner.max.compaction.lag.ms
- log.cleaner.min.cleanable.ratio
- log.cleaner.min.compaction.lag.ms
- log.cleaner.threads
- log.cleanup.policy
- log.flush.interval.messages
- log.flush.interval.ms
- log.index.interval.bytes
- log.index.size.max.bytes
- log.local.retention.bytes
- log.local.retention.ms
- log.message.downconversion.enable
- log.message.timestamp.after.max.ms
- log.message.timestamp.before.max.ms
- log.message.timestamp.difference.max.
- ms
- log.message.timestamp.type
- log.preallocate
- log.retention.bytes
- log.retention.ms
- log.roll.jitter.ms
- log.roll.ms
- log.segment.bytes
- log.segment.delete.delay.ms
- max.connection.creation.rate
- max.connections
- max.connections.per.ip
- max.connections.per.ip.overrides
- message.max.bytes
- metric.reporters
- min.insync.replicas
- num.io.threads
- num.network.threads
- num.recovery.threads.per.data.dir
- num.replica.fetchers
- principal.builder.class
- producer.id.expiration.ms
- remote.log.index.file.cache.total.
- size.bytes
- replica.alter.log.dirs.io.max.bytes.
- per.second
- sasl.enabled.mechanisms
- sasl.jaas.config
- sasl.kerberos.kinit.cmd
- sasl.kerberos.min.time.before.relogin
- sasl.kerberos.principal.to.local.rules
- sasl.kerberos.service.name
- sasl.kerberos.ticket.renew.jitter
- sasl.kerberos.ticket.renew.window.
- factor
- sasl.login.refresh.buffer.seconds
- sasl.login.refresh.min.period.seconds
- sasl.login.refresh.window.factor
- sasl.login.refresh.window.jitter
- sasl.mechanism.inter.broker.protocol
- ssl.cipher.suites
- ssl.client.auth
- ssl.enabled.protocols
- ssl.endpoint.identification.algorithm
- ssl.engine.factory.class
- ssl.key.password
- ssl.keymanager.algorithm
- ssl.keystore.certificate.chain
- ssl.keystore.key
- ssl.keystore.location
- ssl.keystore.password
- ssl.keystore.type
- ssl.protocol
- ssl.provider
- ssl.secure.random.implementation
- ssl.trustmanager.algorithm
- ssl.truststore.certificates
- ssl.truststore.location
- ssl.truststore.password
- ssl.truststore.type
- transaction.partition.verification.
- enable
- unclean.leader.election.enable
- For entity-type ‘users’:
- SCRAM-SHA-256
- SCRAM-SHA-512
- consumer_byte_rate
- controller_mutation_rate
- producer_byte_rate
- request_percentage
- For entity-type ‘clients’:
- consumer_byte_rate
- controller_mutation_rate
- producer_byte_rate
- request_percentage
- For entity-type ‘ips’:
- connection_creation_rate
- For entity-type ‘client-metrics’:
- interval.ms
- match
- metrics
- 实体类型“users”和“clients”可以一起指定,以更新特定用户的客户端的配置。
-
--add-config-file<String>:要添加配置的属性文件的路径。有关有效配置的列表,请参阅添加配置。 -
--all:列出给定主题、broker或broker记录器实体的所有配置(当实体类型为broker时,包括静态配置) -
--alter:更改实体的配置。 -
--bootstrap-controller<String:要连接的Kafka控制器。要连接的控制器> -
--bootstrap-server<String:server to要连接的Kafka服务器。connect to> -
--broker<String>:broker的ID。 -
--broker-defaults:所有broker的配置默认值。 -
--broker-logger<String>:其记录器配置的broker的ID。 -
--client<String>:客户端的ID。 -
--client-defaults:所有客户端的配置默认值。 -
--command-config<String:command 包含要作为配置属性文件的配置的属性文件>:传递给管理客户端。这仅与–bootstrap服务器选项一起使用,用于描述和更改代理配置。 -
--delete-config<String>:配置键以删除“k1,k2” -
--describe:列出给定实体的配置。 -
--entity-default:客户端的默认实体名称/用户/经纪人/ips的默认实体名称(适用于命令行中的相应实体类型) -
--entity-name:实体名称(主题名称/客户端id/用户主体名称/代理id/ip/客户端度量) -
--entity-type:实体类型(主题/客户端/用户/经纪人/经纪人记录器/ips/客户端指标) -
--force:抑制控制台提示 -
--help:打印使用信息。 -
--ip<String>:ip地址。 -
--ip-defaults:所有ip的配置默认值。 -
--topic<String>:主题的名称。 -
--user<String>:用户的主体名称。 -
--user-defaults:所有用户的配置默认值。 -
--version:显示卡夫卡版本。 -
--zk-tls-config-file客户端tls连接属性的文件。- 除了zookeeper.clientCnxnSocket之外的任何属性,
- zookeeper.ssl.cipher.suites,
- zookeeper.ssl.client.enable,
- zookeeper.ssl.crl.enable, zookeeper.
- ssl.enabled.protocols, zookeeper.ssl.
- endpoint.identification.algorithm,
- zookeeper.ssl.keystore.location,
- zookeeper.ssl.keystore.password,
- zookeeper.ssl.keystore.type,
- zookeeper.ssl.ocsp.enable, zookeeper.
- ssl.protocol, zookeeper.ssl.
- truststore.location, zookeeper.ssl.
- truststore.password, zookeeper.ssl.
- truststore.type are ignored.
-
--zookeeper<String:urls>:已弃用。动物园管理员连接的连接字符串,格式为host:port。可以给定多个URLS以允许故障转移。为用户配置SCRAM凭据时需要,或在相关代理关闭时配置动态代理时需要。否则不允许。
查询Topic配置(动态配置)
-
--describe:列出给定实体的配置 -
--entity-type:实体类型(主题/客户端/用户/经纪人/经纪人记录器/ips/客户端指标) --entity-name:实体名称(主题名称/客户端id/用户主体名称/代理id/ip/客户端度量)
查询单个Topic
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --describe --bootstrap-server 82.157.173.74:29092 --topic tpc03
Dynamic configs for topic tpc03 are:因为现在没有给这个topic配置信息,所以没有
或者是这个命令
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --entity-type topics --entity-name tpc03
Dynamic configs for topic tpc03 are:查询所有Topic配置(包括内部Topic)
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --entity-type topics
Dynamic configs for topic tpc123 are:
Dynamic configs for topic tpc05 are:
Dynamic configs for topic tpc03 are:查看Topic的详细配置(静态+动态)
只需要加上一个参数--all
./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --all --topic tpc03kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --all --topic tpc03
All configs for topic tpc03 are:
cleanup.policy=delete sensitive=false synonyms={DEFAULT_CONFIG:log.cleanup.policy=delete}
compression.type=producer sensitive=false synonyms={DEFAULT_CONFIG:compression.type=producer}
delete.retention.ms=86400000 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.delete.retention.ms=86400000}
file.delete.delay.ms=60000 sensitive=false synonyms={DEFAULT_CONFIG:log.segment.delete.delay.ms=60000}
flush.messages=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.flush.interval.messages=9223372036854775807}
flush.ms=9223372036854775807 sensitive=false synonyms={}
follower.replication.throttled.replicas= sensitive=false synonyms={}
index.interval.bytes=4096 sensitive=false synonyms={DEFAULT_CONFIG:log.index.interval.bytes=4096}
leader.replication.throttled.replicas= sensitive=false synonyms={}
local.retention.bytes=-2 sensitive=false synonyms={DEFAULT_CONFIG:log.local.retention.bytes=-2}
local.retention.ms=-2 sensitive=false synonyms={DEFAULT_CONFIG:log.local.retention.ms=-2}
max.compaction.lag.ms=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.max.compaction.lag.ms=9223372036854775807}
max.message.bytes=1048588 sensitive=false synonyms={DEFAULT_CONFIG:message.max.bytes=1048588}
message.downconversion.enable=true sensitive=false synonyms={DEFAULT_CONFIG:log.message.downconversion.enable=true}
message.format.version=3.0-IV1 sensitive=false synonyms={DEFAULT_CONFIG:log.message.format.version=3.0-IV1}
message.timestamp.after.max.ms=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.message.timestamp.after.max.ms=9223372036854775807}
message.timestamp.before.max.ms=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.message.timestamp.before.max.ms=9223372036854775807}
message.timestamp.difference.max.ms=9223372036854775807 sensitive=false synonyms={DEFAULT_CONFIG:log.message.timestamp.difference.max.ms=9223372036854775807}
message.timestamp.type=CreateTime sensitive=false synonyms={DEFAULT_CONFIG:log.message.timestamp.type=CreateTime}
min.cleanable.dirty.ratio=0.5 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.min.cleanable.ratio=0.5}
min.compaction.lag.ms=0 sensitive=false synonyms={DEFAULT_CONFIG:log.cleaner.min.compaction.lag.ms=0}
min.insync.replicas=1 sensitive=false synonyms={DEFAULT_CONFIG:min.insync.replicas=1}
preallocate=false sensitive=false synonyms={DEFAULT_CONFIG:log.preallocate=false}
remote.storage.enable=false sensitive=false synonyms={}
retention.bytes=-1 sensitive=false synonyms={DEFAULT_CONFIG:log.retention.bytes=-1}
retention.ms=604800000 sensitive=false synonyms={}
segment.bytes=1073741824 sensitive=false synonyms={DEFAULT_CONFIG:log.segment.bytes=1073741824}
segment.index.bytes=10485760 sensitive=false synonyms={DEFAULT_CONFIG:log.index.size.max.bytes=10485760}
segment.jitter.ms=0 sensitive=false synonyms={}
segment.ms=604800000 sensitive=false synonyms={}
unclean.leader.election.enable=false sensitive=false synonyms={DEFAULT_CONFIG:unclean.leader.election.enable=false}查看所有topic的信息
./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --all --entity-type topicsTopic添加/修改动态配置
-
--alter:更改实体的配置 -
--add-config<String>:要添加的配置的键值对。方括号可用于对包含逗号的值进行分组:“k1=v1,k2=[v1,v2,v2],k3=v3”。以下是有效配置的列表
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --alter --add-config file.delete.delay.ms=222222,retention.ms=999999 --topic tpc03
Completed updating config for topic tpc03.查询动态信息
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --describe --topic tpc03
Dynamic configs for topic tpc03 are:
file.delete.delay.ms=222222 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:file.delete.delay.ms=222222, DEFAULT_CONFIG:log.segment.delete.delay.ms=60000}
retention.ms=999999 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:retention.ms=999999}Topic删除动态配置
-
--delete-config<String>:配置键以删除“k1,k2”
kafka-2:/opt/kafka/bin$ ./kafka-configs.sh --bootstrap-server 82.157.173.74:29092 --alter --delete-config file.delete.delay.ms --topic tpc03
Completed updating config for topic tpc03.Producer生产者配置
kafka-console-producer.sh 相关可选参数
-
-h, --help:显示此帮助消息并退出 -
--topicTopic:生成指向此主题的消息 -
--num-recordsNUM-RECORDS:要生成的消息数 -
--payload-delimiterPAYLOAD-DELIMITER:提供了在提供–payload文件时使用的分隔符。默认为新行。请注意,如果未提供–payload文件,则会忽略此参数。(默认:\n) -
--throughputTHROUGHPUT:将最大消息吞吐量限制为大约throughput消息/秒。Set将其设置为-1以禁用节流。 -
--producer-propsPROP-NAME=PROP-VALUE [PROP-NAME=PROP-VALUE …]:kafka生产者相关的配置属性,如bootstrap.servers、client.id等。这些配置优先于通过–producter.config传递的配置。 -
--producer.configCONFIG-FILE:生产者配置属性文件。 -
--print-metrics:在测试结束时打印出指标。(默认值:false) -
--transactional-idTRANSACTIONAL-ID:如果事务持续时间ms>0,则要使用的transactionalId。在测试时很有用并发事务的性能。(默认值:performance-producer-default-transactional-id) -
--transaction-duration-msTRANSACTION-DURATION:每笔交易的最大期限。commitTransaction将在此时间之后调用已经过去。只有当该值为正数时,才启用事务。(默认值:0)必须指定–record-size or –payload-file,但不能同时指定两者。 -
--record-sizeRECORD-SIZE:消息大小(以字节为单位)。请注意,您必须提供其中一个–record-size or –payload-file. -
--payload-filePAYLOAD-FILE:从中读取消息有效载荷的文件。这仅适用于UTF-8编码的文本文件。有效载荷将从该文件中读取,并且当发送消息。请注意,您必须恰好提供一个–record-size or –payload-file. -
--batch-size:单个批处理中发送的消息数,200(默认值) -
--compression-codec:压缩编解码器,none、gzip(默认值)snappy、lz4、zstd -
--max-block-ms:在发送请求期间,生产者将阻止的最长时间,60000ms(默认值) -
--max-memory-bytes:生产者用来缓冲等待发送到服务器的总内存,33554432(默认值) -
--max-partition-memory-bytes:为分区分配的缓冲区大小,字节 -
--message-send-max-retries:最大的重试发送次数 -
--metadata-expiry-ms:强制更新元数据的时间阈值(ms) -
--producer-property:将自定义属性传递给生成器的机制,如:key=value -
--producer.config:生产者配置属性文件–producer-property优先于此配置,配置文件完整路径 -
--property:自定义消息读取器,parse.key=true/false key.separator=ignore.error=true/false -
--request-required-acks:生产者请求的确认方式,0、1(默认值)、all -
--request-timeout-ms:生产者请求的确认超时时间,1500(默认值) -
--retry-backoff-ms:生产者重试前,刷新元数据的等待时间阈值,100(默认值) -
--socket-buffer-size:TCP接收缓冲大小,102400(默认值) -
--timeout:消息排队异步等待处理的时间阈值,1000(默认值) -
--sync:同步发送消息 -
--version:显示 Kafka 版本,不配合其他参数时,显示为本地Kafka版本
属性文件
#根据一个或多个许可给Apache软件基金会(ASF)
#贡献者许可协议。请参阅随分发的通知文件
#有关版权所有权的其他信息,请参阅本作品。
#ASF根据Apache许可证2.0版将此文件授权给您
#(“许可证”);除非符合
#许可证。您可以在获取许可证副本
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#除非适用法律要求或书面同意,软件
#根据许可证进行的分发是在“按原样”的基础上进行的,
#无任何明示或暗示的保证或条件。
#有关管理权限的特定语言,请参阅许可证和
#许可证下的限制。
#请参阅org.apache.kafka.clients.producer。ProducerConfig了解更多详细信息
#############################生产者基础知识#############################
#用于引导集群其余部分知识的代理列表
#格式:host1:port1,host2:port2。。。
bootstrap.servers=localhost:9092
#为生成的所有数据指定压缩编解码器:none、gzip、snappy、lz4、zstd
compression.type=无
#用于对记录进行分区的分区器类的名称;
#默认情况下使用“粘性”分区逻辑,在分区之间均匀地分配负载,但通过
#partitioner.class=
#客户端等待请求响应的最长时间
#request.timeout.ms=
#“KafkaProducer.send”和“KafkaProducer.partitionsFor”将阻止多长时间
#max.block.ms=
#生产者将等待给定的延迟,以允许发送其他记录,从而可以批处理发送
#linger.ms=
#请求的最大大小(以字节为单位)
#max.request.size=
#对发送到分区的多个记录进行批处理时的默认批处理大小(以字节为单位)
#batch.size=
#生产者可用于缓冲等待发送到服务器的记录的总内存字节数
#buffer.memory=生产无key消息
./kafka-console-producer.sh --bootstrap-server 10.4.3.41:29092 --topic top01生产有key消息
./kafka-console-producer.sh --bootstrap-server 10.4.3.41:29092 --topic top01 --property parse.key=true默认消息key与消息value间使用“Tab键”进行分隔,所以消息key以及value中切勿使用转义字符(\t)
Consumer消费者配置
kafka-console-consumer.sh相关可选参数
-
--bootstrap-server<String:server to REQUIRED:要连接的服务器。connect to> -
--consumer-property<String:将用户定义的consumer_prop>:属性以key=value形式传递给consumer的机制。 -
--consumer.config<String:config file>:消费者配置属性文件。请注意,[使用者属性]优先于此配置。 -
--enable-systest-events:除了记录消耗的消息之外,还记录使用者的生命周期事件。(这是针对系统测试的。) -
--formatter<String:class>:用于格式化显示的kafka消息的类的名称。(默认值:kafka.tools.DefaultMessageFormatter) -
--formatter-config<String:config配置属性文件以初始化文件>:消息格式化程序。请注意,[property]优先于此配置。 -
--from-beginning:如果使用者还没有建立的消费偏移量,请从日志中出现的最早消息开始,而不是从最新消息开始。 -
--group<String:使用者组id>:使用者的使用者组id。 -
--help:打印使用信息。 -
--include<String:Java regex(String)>:正则表达式,指定要包含以供使用的主题列表。 -
--isolation-level<String>:设置为read_committed,以便筛选出未提交的事务消息。设置为read_uncommitted可读取所有消息。(默认值:read_uncommitted) -
--key-deserializer<String:密钥的反序列化程序> -
--max-messages<Integer:num_messages>:消费的最大数据量,若不指定,则持续消费下去。 -
--offset<String:consume offset>:从(非负数)开始消耗的偏移量,或“最早”表示从开始,或“最近”表示从结束(默认值:最新) -
--partition<Integer:partition>:从中消费的分区。除非指定了“–offset”,否则消耗从分区的末尾开始。 -
--property<String:prop>:初始化消息格式化程序的属性。 - 默认属性包括:
- print.timestamp=true|false
- print.key=true|false
- print.offset=true|false
- print.partition=true|false
- print.headers=true|false
- print.value=true|false
- key.separator=
- line.separator=
- headers.separator=
- null.literal=
- key.deserializer=
- value.deserializer=
- header.deserializer=
- 用户还可以为其格式化程序传递自定义属性;更具体地说,用户可以传入使用’key键控的属性。反序列化程序。“,”值。反序列化程序。’和“headers.deserializer”前缀以配置其反序列化程序。
-
--skip-message-on-error:如果在处理消息时出现错误,请跳过它而不是停止。 -
--timeout-ms<Integer:timeout_ms>:如果指定了,如果在指定的时间间隔内没有消息可供使用,则退出。 -
--topic<String:topic>:要消费的主题。 -
--value-deserializer<String:值的反序列化程序> -
--version:显示kafka版本。 -
--whitelist<String:Java正则表达式已弃用,请改用–include;(String)>:如果指定了–include,则忽略。指定要包含以供使用的主题列表的正则表达式。
1. 新客户端从头消费--from-beginning (注意这里是新客户端,如果之前已经消费过了是不会从头消费的)
-
--from-beginning:如果使用者还没有建立的消费偏移量,请从日志中出现的最早消息开始,而不是从最新消息开始。
下面没有指定客户端名称,所以每次执行都是新客户端都会从头消费
./kafka-console-consumer.sh --bootstrap-server 10.4.3.41:29092 --topic top01 --from-beginning2. 正则表达式匹配topic进行消费--whitelist
-
--whitelist<String:Java正则表达式已弃用,请改用–include;(String)>:如果指定了–include,则忽略。指定要包含以供使用的主题列表的正则表达式。
./kafka-console-consumer.sh --bootstrap-server 10.4.3.41:29092 --whitelist "top01.*" 消费所有的topic,并且还从头消费
./kafka-console-consumer.sh --bootstrap-server 10.4.3.41:29092 --whitelist "top01.*" --from-beginning3. 显示key进行消费--property print.key=true
./kafka-console-consumer.sh --bootstrap-server 10.4.3.41:29092 --whitelist "top01.*" --from-beginning --property print.key=true显示与不显示的区别

4. 指定分区消费--partition 指定起始偏移量消费--offset
-
--partition<Integer:partition>:从中消费的分区。除非指定了“–offset”,否则消耗从分区的末尾开始。 -
--offset<String:consume offset>:从(非负数)开始消耗的偏移量,或“最早”表示从开始,或“最近”表示从结束(默认值:最新)
./kafka-console-consumer.sh --bootstrap-server 10.4.3.41:29092 --topic top01 --partition 0 --offset 1005. 创建消费者组消费--group
-
--group<String:使用者组id>:使用者的使用者组id。
注意给客户端命名之后,如果之前有过消费,那么--from-beginning就不会再从头消费了
./kafka-console-consumer.sh --bootstrap-server 10.4.3.41:29092 --topic top01 --group test-group- 消费者 > topic的分区数
- 同一个分区内的消息只能被同一个组中的一个消费者消费,当消费者数量多于分区数量时,多于的消费者空闲(不能消费数据)。
- 消费者 <= topic的分区数
- 当分区数多于消费者数的时候,有的消费者对应多个分区。
- 当分区数等于消费者数的时候,每个消费者对应一个分区。
- 多个消费者组
- 启动多个组,相同的数据会被不同组的消费者消费多次。
Group消费者组管理
kafka-consumer-groups.sh相关可选参数
-
--all-groups:应用于所有使用者组。 -
--all-topics:考虑在“重置偏移量”过程中分配给一个组的所有主题。 - –bootstrap-server <String:server to REQUIRED:要连接的服务器。connect to>
-
--by-duration<String:duration>:将偏移量重置为当前时间戳的偏移量。格式:“PnDTnHnMnS” -
--command-config<String:command-Property-file包含要作为配置属性文件的配置>传递给Admin-Client和Consumer。 -
--delete:传入组以删除整个使用者组的主题分区偏移量和所有权信息。例如–组g1–组g2 -
--delete-offsets:删除使用者组的偏移量。一次支持一个用户组和多个主题。 -
--describe:描述使用者组并列出与给定组相关的偏移滞后(尚未处理的消息数)。 -
--dry-run:只显示结果,不执行对消费者群体的更改。支持的操作:重置偏移。 -
--execute:执行操作。支持的操作:重置偏移。 -
--export:将操作执行导出到CSV文件。支持的操作:重置偏移。 -
--from-file:将偏移重置为CSV文件中定义的值。 -
--group:我们希望对其采取行动的消费者组。 -
--help:打印使用信息。 -
--list:列出所有消费者组。 -
--members:描述小组成员。此选项只能与“–description”和“–bootstrap server”选项一起使用。示例:–bootstrap server localhost:9092–description–group group1–members -
--offsets:描述组并列出组中的所有主题分区及其偏移滞后。这是的默认子操作,只能与“–description”和“–bootstrap server”选项一起使用。示例:–引导服务器localhost:9092–description–group group1–偏移量 -
--reset-offsets:重置使用者组的偏移量。一次支持一个使用者组,并且实例应该处于非活动状态。有两个执行选项:–dry-run(默认值)计划要重置的偏移量,–execute更新偏移量。此外,–export选项用于将结果导出为CSV格式。您必须选择以下重置规范之一:–到日期时间、–按持续时间、–到最早、–到最近、–按移位、–从文件、–到当前、–到偏移量。- –to-datetime
- –by-duration
- –to-earliest
- –to-latest
- –shift-by
- –from-file
- –to-current
- –to-offset
- 要定义范围,请使用–all-topics或–topic。除非使用“–from file”,否则必须指定一个作用域。
-
--shift-by<Long:number of offset>:重置偏移量将当前偏移量移动“n”,其中“n”可以是正或负。 -
--state[String]:当使用“–describe”指定时,包括组的状态。示例:–bootstrap server localhost:9092–describe–group group1–state使用“–list”指定时,它显示所有组的状态。它还可以用于列出具有特定状态的组。示例:–bootstrap server localhost:9092–list–state stable,empty此选项只能与’–description’、’-list’和’-bootstrap server’选项一起使用。 -
--timeout:可以为某些用例设置的超时。例如,在描述组时,可以使用它来指定在组稳定之前(当组刚刚创建或正在进行一些更改时)等待的最大时间(以毫秒为单位)。(默认值:5000) -
--to-current:将偏移重置为当前偏移。 -
--to-datetime<String:datetime>:将偏移量重置为从日期时间的偏移量。格式:’YYYY-MM-DDTH:MM:SS.sss’ -
--to-earliest:将偏移重置为最早偏移。 -
--to-latest:将偏移重置为最新偏移。 -
--to-offset:将偏移重置为特定偏移。 -
--topic<String:topic>:应删除其使用者组信息的主题或应包含在重置偏移过程中的主题。在“重置偏移量”的情况下,可以使用以下格式指定分区:“topic1:0,1,2”,其中0,1,2是要包含在进程中的分区。重置偏移量还支持多个主题输入。 -
--verbose:在描述组时提供附加信息(如果有的话)。此选项只能与“–偏移量”/“–成员”/“–state”和“–引导服务器”选项一起使用。示例:–bootstrap server localhost:9092–describe–group group1–members–verbose -
--version:显示kafka版本。
查看消费者组列表
-
--list:列出所有消费者组
kafka-3:/opt/kafka/bin$ ./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --list
test-group查看消费者组详情
指定消费者组
-
--describe:描述使用者组并列出与给定组相关的偏移滞后(尚未处理的消息数) -
--group
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --group test-group03
- GROUP —— 组名
- TOPIC —— 主题名
- PARTITION —— 所在分区
- CURRENT-OFFSET —— 最新的消费者偏移量
- LOG-END-OFFSET —— 日志最近数据的偏移量( 主题对应分区消息的结束偏移量(HW) )
- LAG —— 还未消费的数据
- CONSUMER-ID —— 消费者ID
- HOST —— 客户端地址
- CLIENT-ID —— 客户端ID
所有消费者组
-
--all-groups:应用于所有消费者组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --all-groups成员(消费者客户端)信息
所有消费组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --members --all-groups指定消费组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --members --group test-group03消费者组状态
所有消费组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --state --all-groupskafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --state --all-groups
Consumer group 'test-group' has no active members.
GROUP COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS
test-group 10.4.3.41:19092 (1) Empty 0
Consumer group 'test-group03' has no active members.
GROUP COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS
test-group03 10.4.3.41:49092 (4) Empty 0指定消费组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --describe --state --group test-group03删除消费者组
所有消费组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --delete --all-groups指定消费组
./kafka-consumer-groups.sh --bootstrap-server 10.4.3.41:29092 --delete --group test-group03想要删除消费组前提是这个消费组的所有客户端都停止消费/不在线才能够成功删除
重置消费组的偏移量
-
--reset-offsets重置消费组的偏移量
下面的示例使用的参数是: --dry-run ;这个参数表示预执行,会打印出来将要处理的结果;
等你想真正执行的时候请换成参数--excute ;
下面示例 重置模式都是 --to-earliest 重置到最早的;
请根据需要参考下面 相关重置Offset的模式 换成其他模式;
重置指定消费组的偏移量 --group
重置指定消费组的所有Topic的偏移量--all-topics
kafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --reset-offsets --to-earliest --group test-group05 --bootstrap-server 10.4.3.41:29092 --dry-run --all-topics
GROUP TOPIC PARTITION NEW-OFFSET
test-group05 top01 1 0
test-group05 top01 0 0
test-group05 top01 2 0 重置指定消费组的指定Topic的偏移量--topic
kafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --reset-offsets --to-earliest --group test-group05 --bootstrap-server 10.4.3.41:29092 --dry-run --topic top01
GROUP TOPIC PARTITION NEW-OFFSET
test-group05 top01 0 0
test-group05 top01 1 0
test-group05 top01 2 0 重置所有消费组的偏移量 --all-groups
重置所有消费组的所有Topic的偏移量--all-topics
kafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --reset-offsets --to-earliest --all-groups --bootstrap-server 10.4.3.41:29092 --dry-run --all-topics
GROUP TOPIC PARTITION NEW-OFFSET
test-group05 top01 1 0
test-group05 top01 0 0
test-group05 top01 2 0
test-group top01 1 0
test-group top01 0 0
test-group top01 2 0 重置所有消费组中指定Topic的偏移量--topic
kafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --reset-offsets --to-earliest --all-groups --bootstrap-server 10.4.3.41:29092 --dry-run --topic top01
GROUP TOPIC PARTITION NEW-OFFSET
test-group05 top01 0 0
test-group05 top01 1 0
test-group05 top01 2 0
test-group top01 0 0
test-group top01 1 0
test-group top01 2 0 --reset-offsets 后面需要接重置的模式
| 参数 | 描述 | 例子 |
--to-earliest |
重置offset到最开始的那条offset(找到还未被删除最早的那个offset) | |
--to-current |
直接重置offset到当前的offset,也就是LOE | |
--to-latest |
重置到最后一个offset | |
--to-datetime |
重置到指定时间的offset;格式为:YYYY-MM-DDTHH:mm:SS.sss; |
–to-datetime “2021-6-26T00:00:00.000” |
--to-offset |
重置到指定的offset,但是通常情况下,匹配到多个分区,这里是将匹配到的所有分区都重置到这一个值; 如果 1.目标最大offset<--to-offset, 这个时候重置为目标最大offset;2.目标最小offset>--to-offset ,则重置为最小; 3.否则的话才会重置为--to-offset的目标值; 一般不用这个 |
--to-offset 3465 |
--shift-by |
按照偏移量增加或者减少多少个offset;正的为往前增加;负的往后退;当然这里也是匹配所有的; |
--shift-by 100 、--shift-by -100
|
--from-file |
根据CVS文档来重置; |
--from-file着重讲解一下
上面其他的一些模式重置的都是匹配到的所有分区; 不能够每个分区重置到不同的offset;不过--from-file可以让我们更灵活一点;
先配置cvs文档,格式为: Topic:分区号: 重置目标偏移量
top01,1,5
top01,2,10
kafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --reset-offsets --group test-group05 --bootstrap-server 10.4.3.41:29092 --dry-run --from-file top01.csv
[2024-04-01 07:13:07,190] WARN New offset (5) is higher than latest offset for topic partition top01-1. Value will be set to 1 (kafka.admin.ConsumerGroupCommand$)
GROUP TOPIC PARTITION NEW-OFFSET
test-group05 top01 1 1
test-group05 top01 2 10 删除偏移量delete-offsets
能够执行成功的一个前提是消费组是不可用状态
偏移量被删除了之后,Consumer Group下次启动的时候,会从头消费
kafka-2:/opt/kafka/bin$ ./kafka-consumer-groups.sh --delete-offsets --group test-group05 --bootstrap-server 10.4.3.41:29092 --topic top01
Request succeed for deleting offsets with topic top01 group test-group05
TOPIC PARTITION STATUS
top01 0 Successful
top01 1 Successful
top01 2 Successful kafka自带压测命令
生产者压力测试kafka-producer-perf-test.sh
发送1024条消息--num-records 100并且每条消息大小为1KB--record-size 1024 最大吞吐量每秒10000条--throughput 100
kafka-2:/opt/kafka/bin$ ./kafka-producer-perf-test.sh --topic top01 --num-records 100 --throughput 100000 --producer-props bootstrap.servers=10.4.3.41:29092 --record-size 1024
100 records sent, 217.864924 records/sec (0.21 MB/sec), 24.50 ms avg latency, 433.00 ms max latency, 21 ms 50th, 33 ms 95th, 433 ms 99th, 433 ms 99.9th.相关可选参数
| 参数 | 描述 | 例子 |
--topic |
指定消费的topic | |
--num-records |
发送多少条消息 | |
--throughput |
每秒消息最大吞吐量 | |
--producer-props |
生产者配置, k1=v1,k2=v2 | --producer-props bootstrap.servers= localhost:9092,client.id=test_client |
--producer.config |
生产者配置文件 |
--producer.config config/producer.propeties |
--print-metrics |
在test结束的时候打印监控信息,默认false | --print-metrics true |
--transactional-id |
指定事务 ID,测试并发事务的性能时需要,只有在 –transaction-duration-ms > 0 时生效,默认值为 performance-producer-default-transactional-id | |
--transaction-duration-ms |
指定事务持续的最长时间,超过这段时间后就会调用 commitTransaction 来提交事务,只有指定了 > 0 的值才会开启事务,默认值为 0 | |
--record-size |
一条消息的大小byte; 和 –payload-file 两个中必须指定一个,但不能同时指定 | |
--payload-file |
指定消息的来源文件,只支持 UTF-8 编码的文本文件,文件的消息分隔符通过 --payload-delimeter指定,默认是用换行\nl来分割的,和 –record-size 两个中必须指定一个,但不能同时指定 ; 如果提供的消息 |
|
--payload-delimeter |
如果通过 --payload-file 指定了从文件中获取消息内容,那么这个参数的意义是指定文件的消息分隔符,默认值为 \n,即文件的每一行视为一条消息;如果未指定--payload-file则此参数不生效;发送消息的时候是随机送文件里面选择消息发送的; |
消费者压力测试kafka-consumer-perf-test.sh
kafka-2:/opt/kafka/bin$ ./kafka-consumer-perf-test.sh -topic top01 --bootstrap-server 10.4.3.41:29092 --messages 100
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2024-04-01 07:52:39:121, 2024-04-01 07:52:42:607, 0.0595, 0.0171, 276, 79.1738, 3398, 88, 0.6762, 3136.3636相关可选参数
参数 |
描述 |
例子 |
|---|---|---|
|
||
|
消费者配置文件 |
|
|
结果打印出来的时间格式化 |
默认:yyyy-MM-dd HH:mm:ss:SSS |
|
单次请求获取数据的大小 |
默认1048576 |
|
指定消费的topic |
|
|
||
|
消费组ID |
|
|
如果设置了,则不打印header信息 |
|
|
需要消费的数量 |
|
|
feth 数据的线程数 |
默认:1 |
|
结束的时候打印监控数据 |
|
|
||
|
消费线程数; |
默认 10 |
kafka持续批量推送消息
单次发送100条消息--max-messages 100
一共要推送多少条,默认为-1,-1表示一直推送到进程关闭位置
kafka-2:/opt/kafka/bin$ ./kafka-verifiable-producer.sh --topic top01 --bootstrap-server 10.4.3.41:29092 --max-messages 100
{"timestamp":1711958877693,"name":"startup_complete"}
{"timestamp":1711958877988,"name":"producer_send_success","key":null,"value":"0","partition":1,"topic":"top01","offset":31460}
{"timestamp":1711958877993,"name":"producer_send_success","key":null,"value":"1","partition":1,"topic":"top01","offset":31461}
……每秒发送最大吞吐量不超过消息 --throughput 100
推送消息时的吞吐量,单位messages/sec。默认为-1,表示没有限制
kafka-2:/opt/kafka/bin$ ./kafka-verifiable-producer.sh --topic top01 --bootstrap-server 10.4.3.41:29092 --throughput 100
{"timestamp":1711958987564,"name":"startup_complete"}
{"timestamp":1711958987872,"name":"producer_send_success","key":null,"value":"0","topic":"top01","partition":1,"offset":32272}
{"timestamp":1711958987876,"name":"producer_send_success","key":null,"value":"1","topic":"top01","partition":1,"offset":32273}
{"timestamp":1711958987876,"name":"producer_send_success","key":null,"value":"2","topic":"top01","partition":1,"offset":32274}发送的消息体带前缀--value-prefix
./kafka-verifiable-producer.sh --topic top01 --bootstrap-server 10.4.3.41:29092 --value-prefix 666
{"timestamp":1711959099597,"name":"producer_send_success","key":null,"value":"666.251482","topic":"top01","partition":0,"offset":184573}
{"timestamp":1711959099597,"name":"producer_send_success","key":null,"value":"666.251483","topic":"top01","partition":0,"offset":184574}其他参数:
-
--producer.config CONFIG_FILE指定producer的配置文件 -
--acks ACKS每次推送消息的ack值,默认是-1
kafka持续批量拉取消息
持续消费
./kafka-verifiable-consumer.sh --group-id test-group05 --bootstrap-server 10.4.3.41:29092 --topic top01
{"timestamp":1711959369125,"name":"offsets_committed","offsets":[{"topic":"top01","partition":0,"offset":388261}],"success":true}
{"timestamp":1711959369126,"name":"records_consumed","count":500,"partitions":[{"topic":"top01","partition":0,"count":500,"minOffset":388261,"maxOffset":388760}]}单次最大消费10条消息--max-messages 10
kafka-2:/opt/kafka/bin$ ./kafka-verifiable-consumer.sh --group-id test-group05 --bootstrap-server 10.4.3.41:29092 --topic top01 --max-messages 10
{"timestamp":1711959442958,"name":"startup_complete"}
{"timestamp":1711959446440,"name":"partitions_assigned","partitions":[{"topic":"top01","partition":0},{"topic":"top01","partition":1},{"topic":"top01","partition":2}]}
{"timestamp":1711959446554,"name":"records_consumed","count":500,"partitions":[{"topic":"top01","partition":2,"count":10,"minOffset":419608,"maxOffset":419617}]}
{"timestamp":1711959446564,"name":"offsets_committed","offsets":[{"topic":"top01","partition":2,"offset":419618}],"success":true}
{"timestamp":1711959446573,"name":"partitions_revoked","partitions":[{"topic":"top01","partition":0},{"topic":"top01","partition":1},{"topic":"top01","partition":2}]}
{"timestamp":1711959446598,"name":"shutdown_complete"}相关可选参数
参数 |
描述 |
例子 |
|---|---|---|
|
指定连接到的kafka服务; |
–bootstrap-server localhost:9092 |
|
指定消费的topic |
|
|
消费者id;不指定的话每次都是新的组id |
|
|
消费组实例ID,唯一值 |
|
|
单次最大消费的消息数量 |
|
|
是否开启offset自动提交;默认为false |
|
|
当以前没有消费记录时,选择要拉取offset的策略,可以是 |
|
|
consumer分配分区策略,默认是 |
|
|
指定consumer的配置文件 |
Leader重新选举
每当代理停止或崩溃时,该代理的分区的领导权就会转移到其他副本。当代理重新启动时,它只会成为其所有分区的追随者,这意味着它不会用于客户端读取和写入。
为了避免这种不平衡,Kafka 有一个首选副本的概念。如果分区的副本列表为 1、5、9,则节点 1 优先作为节点 5 或 9 的领导者,因为它在副本列表中较早。默认情况下,Kafka 集群将尝试恢复首选副本的领导地位。
kafka-leader-election.sh可选参数
| 参数 | 描述 | 例子 |
| –bootstrap-server 指定kafka服务 | 指定连接到的kafka服务 | –bootstrap-server localhost:9092 |
| –topic | 指定Topic,此参数跟–all-topic-partitions和path-to-json-file 三者互斥 | |
| –partition | 指定分区,跟–topic搭配使用 | |
| –election-type | 两个选举策略(PREFERRED: 优先副本选举,如果第一个副本不在线的话会失败;UNCLEAN: 策略) | |
| –all-topic-partitions | 所有topic所有分区执行Leader重选举; 此参数跟–topic和path-to-json-file 三者互斥 | |
| –path-to-json-file | 配置文件批量选举,此参数跟–topic和all-topic-partitions 三者互斥 |
- 指定Topic指定分区用重新
PREFERRED:优先副本策略进行Leader重选举
./kafka-leader-election.sh --bootstrap-server 10.4.3.41:29092 --topic top01 --election-type PREFERRED --partition 1- 所有Topic所有分区用重新
PREFERRED:优先副本策略进行Leader重选举
./kafka-leader-election.sh --bootstrap-server 10.4.3.41:29092 --election-type preferred --all-topic-partitions- 设置配置文件批量指定topic和分区进行Leader重选举
先配置leader-election.json文件
{
"partitions": [
{
"topic": "test_create_topic4",
"partition": 1
},
{
"topic": "test_create_topic4",
"partition": 2
}
]
}./kafka-leader-election.sh --bootstrap-server xxx:9090 --election-type preferred --path-to-json-file config/leader-election.json分区分配迁移
该工具将给定主题列表的所有分区均匀分布在新的代理集上。在此移动过程中,主题的复制因子保持不变。实际上,主题输入列表的所有分区的副本都从旧的代理集移动到新添加的代理。
已知,Kafka 集群中有2个 kafka broker ,id 分别为 1、2,现在再加两个 broker 节点,id 为 3、4 。Kafka 只会负载均衡新创建的 topic 分区。所以现在,我们需要将已存在的 test009 topic 的 2 个分区(分区数据不固定)均匀分布在 4 个 broker 节点上,以便实现尽可能的负载均衡,提高写入和消费速度。
Kafka 不会对已存在的分区进行均衡分配,所以需要我们手动执行分区分配操作。
分区重新分配工具可以在 3 种互斥的模式下运行:
- –generate:在此模式下,给定主题列表和代理列表,该工具会生成候选重新分配,以将指定主题的所有分区移动到新代理。此选项仅提供了一种在给定主题和目标代理列表的情况下生成分区重新分配计划的便捷方法。
- –execute:在此模式下,该工具根据用户提供的重新分配计划启动分区的重新分配。 (使用 –reassignment-json-file 选项)。这可以是由管理员手工制作的自定义重新分配计划,也可以使用 –generate 选项提供
- –verify:在此模式下,该工具验证上次 –execute 期间列出的所有分区的重新分配状态。状态可以是成功完成、失败或正在进行
1、声明要分配分区的 topic 列表
Kafka 的 bin 目录中有一个 kafka-reassign-partitions.sh 脚本工具,我们可以通过它分配分区。在此之前,我们需要先按照要求定义一个文件,里面说明哪些 topic 需要分配分区。文件内容如下:
temp@gpu41:~/kafka$ cat topic-generate.json
{
"topics": [
{
"topic": "test009"
}
],
"version": 1
}2、通过 –topics-to-move-json-file 参数,生成分区分配策略 –generate
./kafka-reassign-partitions.sh --bootstrap-server 10.4.3.41:29092 --topics-to-move-json-file topic-generate.json --broker-list "1,2,3,4" --generateCurrent partition replica assignment
{"version":1,"partitions":[{"topic":"test009","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"test009","partition":1,"replicas":[1,2],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"test009","partition":0,"replicas":[2,3],"log_dirs":["any","any"]},{"topic":"test009","partition":1,"replicas":[3,4],"log_dirs":["any","any"]}]}- –broker-list:值为要分配的 kafka broker id,以逗号分隔,该参数必不可少。脚本会根据你的 topic-generate.json 文件,获取 topic 列表,为这些 topic 生成分布在 broker list 上面的分区分配策略。
输出结果中有你当前的分区分配策略,也有 Kafka 期望的分配策略,在期望的分区分配策略里,kafka 已经尽可能的为你分配均衡。
-
Current partition replica assignment当前分区副本分配,里面的内容备份,以便回滚到原来的分区分配状态。 -
Proposed partition reassignment configuration建议的分区重新分配配置,里面的内容拷贝到一个新的文件中(文件名称、格式任意,但要保证内容为json格式)。
3、通过 –reassignment-json-file 参数,执行分区分配策略 –execute
kafka-1:/opt/kafka/bin$ ./kafka-reassign-partitions.sh --bootstrap-server 10.4.3.41:29092 --reassignment-json-file topic-execute01.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test009","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"test009","partition":1,"replicas":[1,2],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for test009-0,test009-14、通过 –reassignment-json-file 参数,检查分区分配进度 –verify
kafka-1:/opt/kafka/bin$ ./kafka-reassign-partitions.sh --bootstrap-server 10.4.3.41:29092 --reassignment-json-file topic-execute01.json --verify
Status of partition reassignment:
Reassignment of partition test009-0 is completed.
Reassignment of partition test009-1 is completed.
Clearing broker-level throttles on brokers 1,2,3,4
Clearing topic-level throttles on topic test009再来看一下 topic : test009 的详细信息
原来的配置信息
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --describe --topic test009
Topic: test009 TopicId: WfIh3WepRlOzPLKANlBoUw PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: test009 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test009 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2迁移后的信息
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --describe --topic test009
Topic: test009 TopicId: WfIh3WepRlOzPLKANlBoUw PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: test009 Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: test009 Partition: 1 Leader: 3 Replicas: 3,4 Isr: 4,3增大分区副本数
1、增加 partition 0 所属的 replicas broker id
修改 topic-execute01.json 文件,增加 partition 0 所属的 replicas broker id 。
{
"version": 1,
"partitions": [
{
"topic": "test009",
"partition": 0,
"replicas": [
1,
2,
3,
4
],
"log_dirs": [
"any",
"any",
"any",
"any"
]
},
{
"topic": "test009",
"partition": 1,
"replicas": [
3,
4
],
"log_dirs": [
"any",
"any"
]
}
]
}分别修改replicas与replicas,数量要对应,然后和之前迁移的操作一样
2、通过 –reassignment-json-file 参数,执行分区副本分配策略 –execute
kafka-1:/opt/kafka/bin$ ./kafka-reassign-partitions.sh --bootstrap-server 10.4.3.41:29092 --reassignment-json-file topic-execute01.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test009","partition":0,"replicas":[2,3],"log_dirs":["any","any"]},{"topic":"test009","partition":1,"replicas":[3,4],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for test009-0,test009-1查看一下 topic:test009 ,发现:Replicas 列表正如上述 topic-execute01.json 描述的一样
kafka-1:/opt/kafka/bin$ ./kafka-topics.sh --bootstrap-server 10.4.3.41:29092 --describe --topic test009
Topic: test009 TopicId: WfIh3WepRlOzPLKANlBoUw PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: test009 Partition: 0 Leader: 2 Replicas: 1,2,3,4 Isr: 2 Adding Replicas: 1,4 Removing Replicas:
Topic: test009 Partition: 1 Leader: 3 Replicas: 3,4 Isr: 3