阅读完需:约 15 分钟
Tomcat/Jetty 是目前比较流行的 Web 容器,两者接受请求之后都会转交给线程池处理,这样可以有效提高处理的能力与并发度。JDK 提高完整线程池实现,但是 Tomcat/Jetty 都没有直接使用。Jetty 采用自研方案,内部实现 QueuedThreadPool 线程池组件,而 Tomcat 采用扩展方案,踩在 JDK 线程池的肩膀上,扩展 JDK 原生线程池。
JDK 原生线程池可以说功能比较完善,使用也比较简单,那为何 Tomcat/Jetty 却不选择这个方案,反而自己去动手实现那?
JDK 线程池
通常我们可以将执行的任务分为两类:
- cpu 密集型任务
- io 密集型任务
cpu 密集型任务,需要线程长时间进行的复杂的运算,这种类型的任务需要少创建线程,过多的线程将会频繁引起上文切换,降低任务处理处理速度。
而 io 密集型任务,由于线程并不是一直在运行,可能大部分时间在等待 IO 读取/写入数据,增加线程数量可以提高并发度,尽可能多处理任务。
由于 Tomcat/Jetty 需要处理大量客户端请求任务,如果采用原生线程池,一旦接受请求数量大于线程池核心线程数,这些请求就会被放入到队列中,等待核心线程处理。这样做显然降低这些请求总体处理速度,所以两者都没采用 JDK 原生线程池。
线程池参数
-
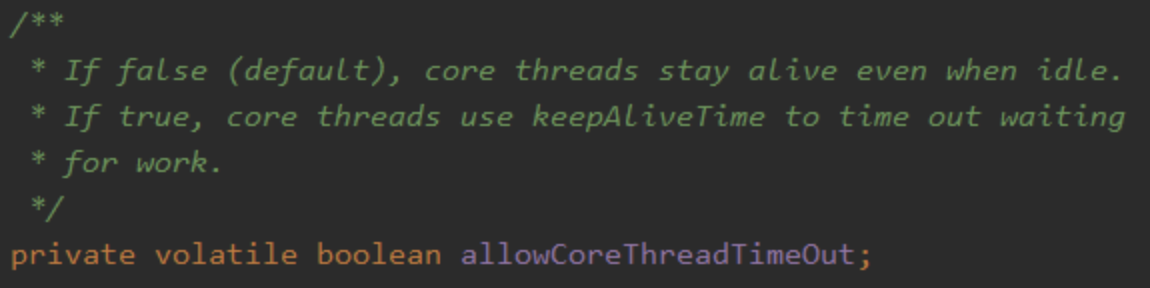
corePoolSize:the number of threads to keep in the pool, even if they are idle, unless {@code allowCoreThreadTimeOut} is set
(核心线程数大小:不管它们创建以后是不是空闲的。线程池需要保持 corePoolSize 数量的线程,除非设置了 allowCoreThreadTimeOut。) -
maximumPoolSize:the maximum number of threads to allow in the pool。
(最大线程数:线程池中最多允许创建 maximumPoolSize 个线程。) -
keepAliveTime:when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating。
(存活时间:如果经过 keepAliveTime 时间后,超过核心线程数的线程还没有接受到新的任务,那就回收。) -
unit:the time unit for the {@code keepAliveTime} argument
(keepAliveTime 的时间单位。) -
workQueue:the queue to use for holding tasks before they are executed. This queue will hold only the {@code Runnable} tasks submitted by the {@code execute} method。
(存放待执行任务的队列:当提交的任务数超过核心线程数大小后,再提交的任务就存放在这里。它仅仅用来存放被 execute 方法提交的 Runnable 任务。所以这里就不要翻译为工作队列了,好吗?不要自己给自己挖坑。) -
threadFactory:the factory to use when the executor creates a new thread。
(线程工程:用来创建线程工厂。比如这里面可以自定义线程名称,当进行虚拟机栈分析时,看着名字就知道这个线程是哪里来的,不会懵逼。) -
handler :the handler to use when execution is blocked because the thread bounds and queue capacities are reached。
(拒绝策略:当队列里面放满了任务、最大线程数的线程都在工作时,这时继续提交的任务线程池就处理不了,应该执行怎么样的拒绝策略。)
上面的 7 个参数中,我们主要需要关心的参数是: corePoolSize、maximumPoolSize、workQueue(队列长度)。
当我们自定义线程池的时候 corePoolSize、maximumPoolSize、workQueue(队列长度)该如何设置?
在回答这个问题前可以先看看美团的线程池参数的理解
线程执行流程
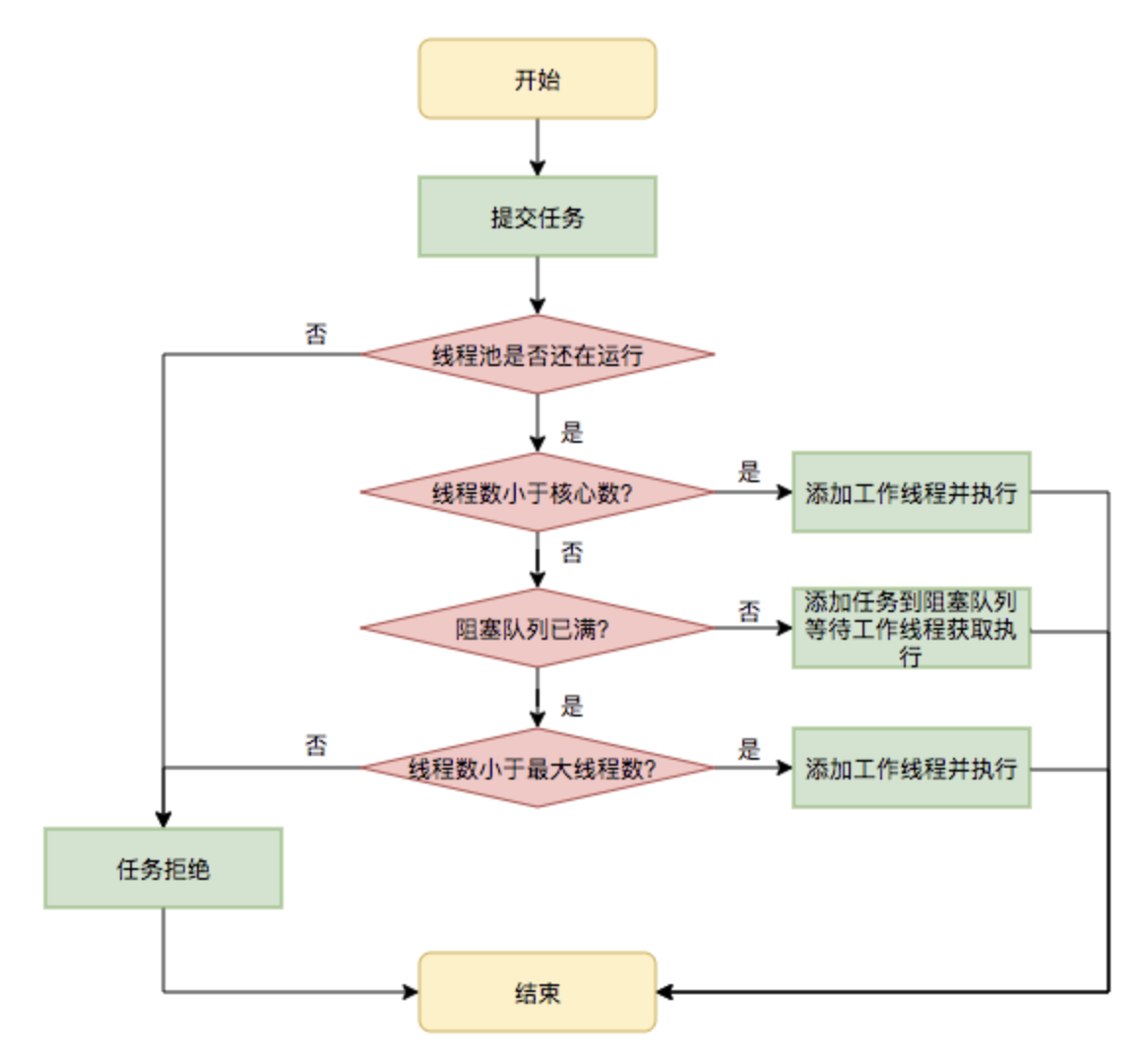
阻塞队列成员表,一览无余:

线程池使用面临的核心的问题在于:线程池的参数并不好配置。
一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;
另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大。
解决方案是什么呢?
线程池参数动态化
尽管经过谨慎的评估,仍然不能够保证一次计算出来合适的参数,那么我们是否可以将修改线程池参数的成本降下来,这样至少可以发生故障的时候可以快速调整从而缩短故障恢复的时间呢?
基于这个思考,我们是否可以将线程池的参数从代码中迁移到分布式配置中心上,实现线程池参数可动态配置和即时生效,线程池参数动态化前后的参数修改流程对比如下:
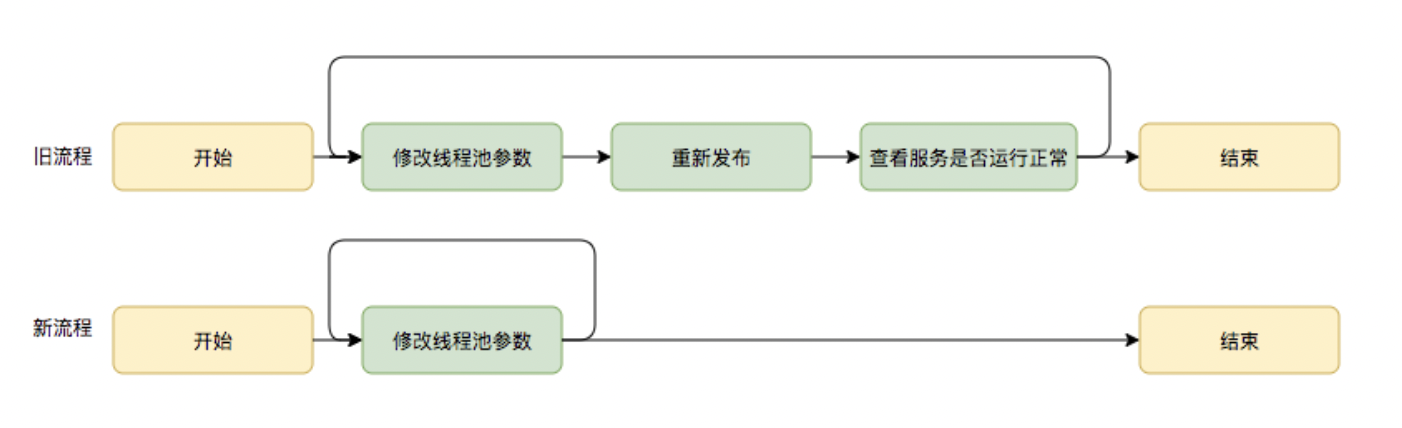
说实话看到这个图的时候我想起之前也有这样的想法的。
因为有一次定时任务用到了线程池,但是核心线程数和队列长度都设置的比较大,某一次任务触发后查出了大批数据,通过线程池提交任务,每个任务里面都会调用下游服务,导致下游服务长时间的压力过大,也没有做限流,所以影响了其对外提供的其他功能。
于是叫运维帮在(配置中心)调小了核心线程数,并且重启了服务。
配置中心天然支持动态更新,那能不能动态的修改线程池呢?
因为那个时候不知道一个构建好了的线程池,它的核心线程数和最大线程数是可以动态修改的。
所以最开始的想法是监听到参数变化后,直接弄一个新的线程池把原来的给替换掉。
但这样的问题是,偷天换日之后,原来的线程池里面的任务我怎么处理呢?
我不能等原来的线程池里面的任务执行完成后再换,因为这个时候任务一定是源源不断的过来的。
现有的解决方案的痛点
现在市面上大多数的答案都是先区分线程池中的任务是 IO 密集型还是 CPU 密集型。
如果是 CPU 密集型的,可以把核心线程数设置为核心数+1。
为什么要加一呢?
《Java并发编程实战》一书中给出的原因是:即使当计算(CPU)密集型的线程偶尔由于页缺失故障或者其他原因而暂停时,这个“额外”的线程也能确保 CPU 的时钟周期不会被浪费。
看不懂是不是?没关系我也看不懂。反正把它理解为一个备份的线程就行了。
这个地方还有个需要注意的小点就是,如果你的服务器上部署的不止一个应用,你就得考虑其他的应用的线程池配置情况。
经过精密的计算,你咔一下设置为核心数,结果项目部署上去了,发现还有其他的应用在和你抢 CPU,你想想难不难受。

理想很丰满,现实很骨感。
结果效果并不好,甚至让下游系统直呼受不了。
这个东西怎么说呢,还是得记住,面试的时候有用。真实场景中只能得到一个参考值,基于这个参考值,再去进行调整。
我们再看一下美团的那篇文章调研的现有解决方案列表:

第一个就是我们上面说的,和实际业务场景有所偏离。
第二个设置为 2*CPU 核心数,有点像是把任务都当做 IO 密集型去处理了。而且一个项目里面一般来说不止一个自定义线程池吧?比如有专门处理数据上送的线程池,有专门处理查询请求的线程池,这样去做一个简单的线程隔离。但是如果都用这样的参数配置的话,显然是不合理的。
第三个不说了,理想状态。流量是不可能这么均衡的,就拿美团来说,下午3,4点的流量,能和 12 点左右午饭时的流量比吗?
基于上面的这些解决方案的痛点,美团给出了动态化配置的解决方案。
动态更新的工作原理是什么?
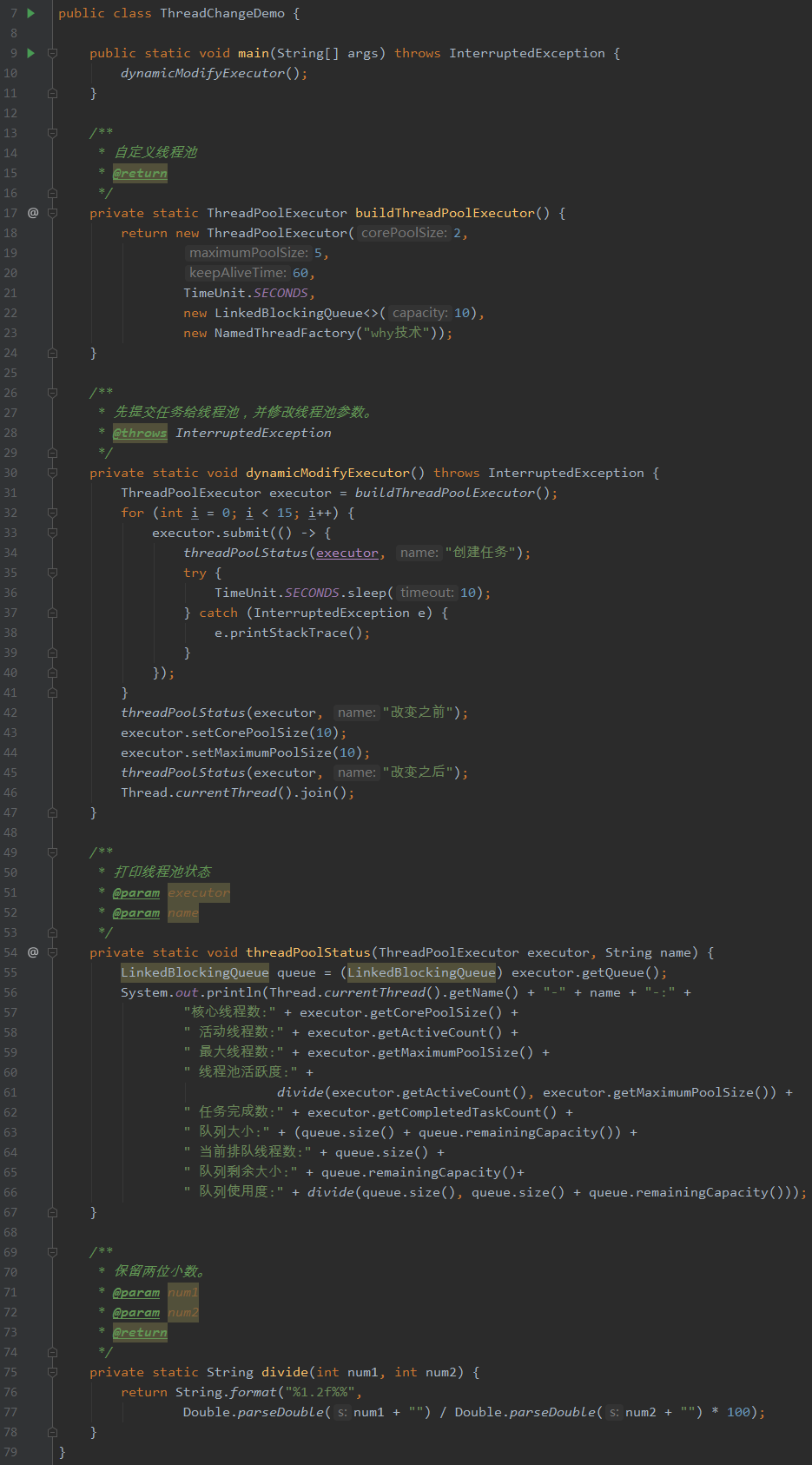
上面的程序就是自定义了一个核心线程数为 2,最大线程数为 5,队列长度为 10 的线程池。
然后给它塞 15 个耗时 10 秒的任务,直接让它 5 个最大线程都在工作,队列长度 10 个都塞满。
当前的情况下,队列里面的 10 个,前 5 个在 10 秒后会被执行,后 5 个在 20 秒后会被执行。
再加上最大线程数正在执行的 5 个,15 个任务全部执行完全需要 3 个 10 秒即 30 秒的时间。
这个时候,如果我们把核心线程数和最大线程数都修改为 10。
那么 10 个任务会直接被 10 个最大线程数接管,10 秒就会被处理完成。
剩下的 5 个任务会在 10 秒后被执行完成。
所以,15 个任务执行完成需要 2 个 10 秒即 20 秒的时间处理完成了。
先看 setCorePoolSize 方法:
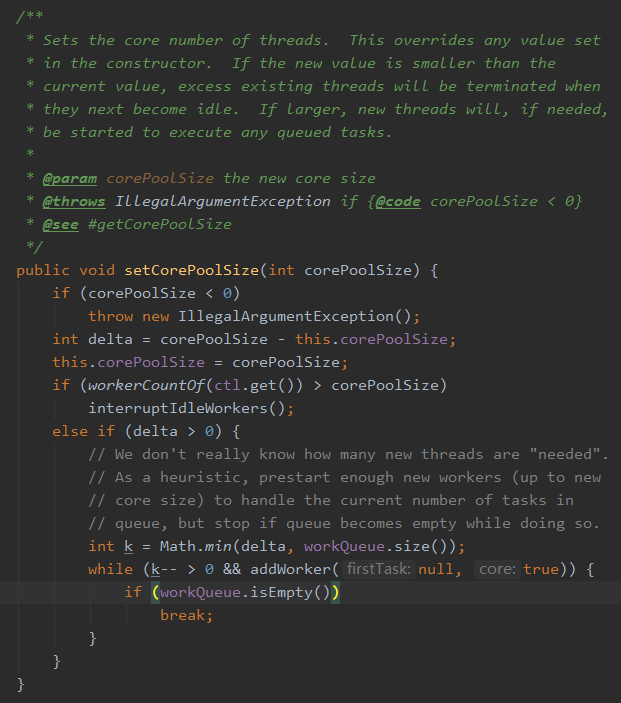
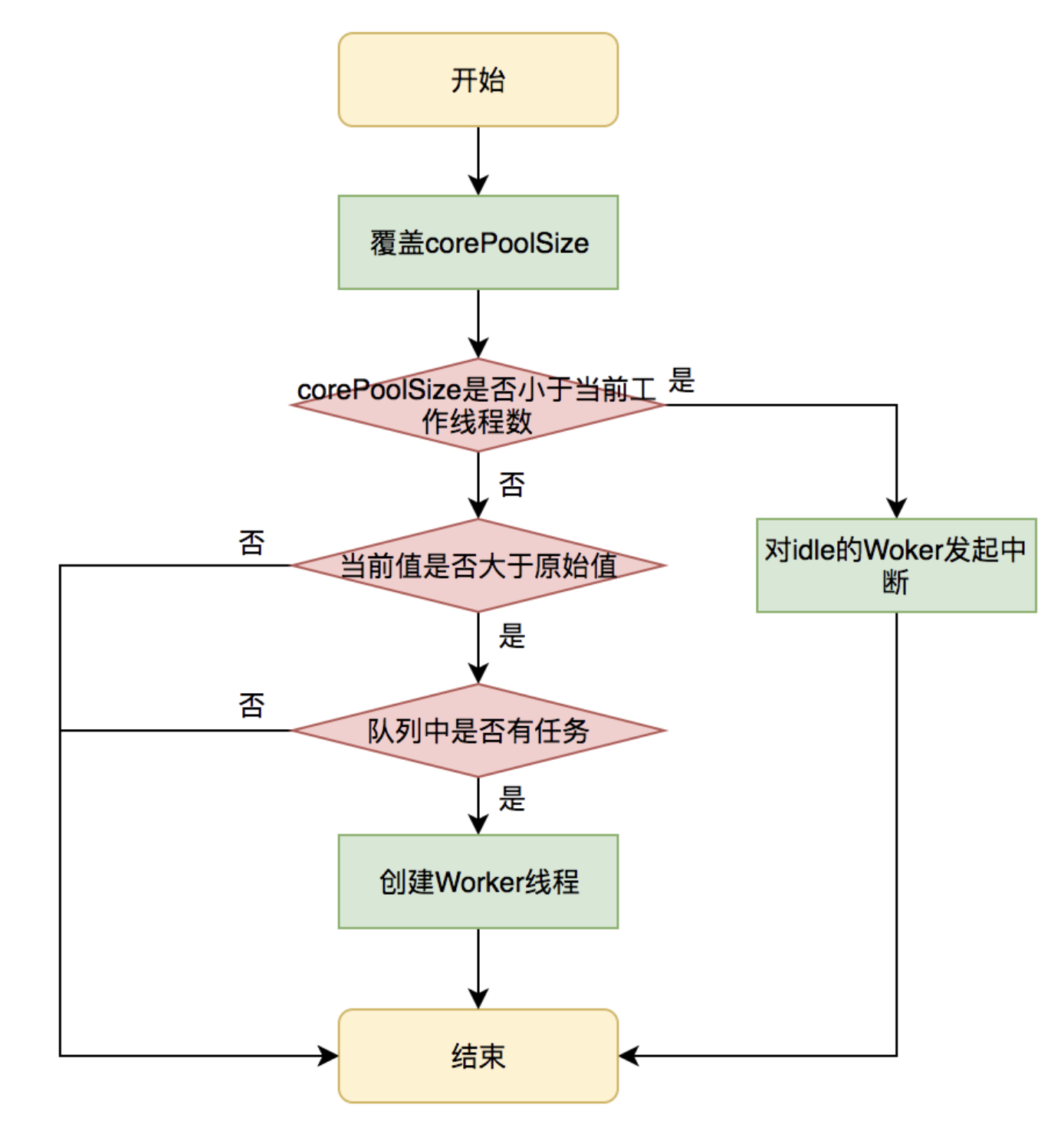
在运行期线程池使用方调用此方法设置corePoolSize之后,线程池会直接覆盖原来的corePoolSize值,并且基于当前值和原始值的比较结果采取不同的处理策略。
对于当前值小于当前工作线程数的情况,说明有多余的worker线程,此时会向当前idle的worker线程发起中断请求以实现回收,多余的worker在下次idel的时候也会被回收;
对于当前值大于原始值且当前队列中有待执行任务,则线程池会创建新的worker线程来执行队列任务,setCorePoolSize具体流程如下:
看了美团的那篇文章后,我又去看了 Spring 的 ThreadPoolTaskExecutor类 (就是对JDK ThreadPoolExecutor 的一层包装,可以理解为装饰者模式)的 setCorePoolSize 方法: 注释上写的清清楚楚,可以在线程池运行时修改该参数。
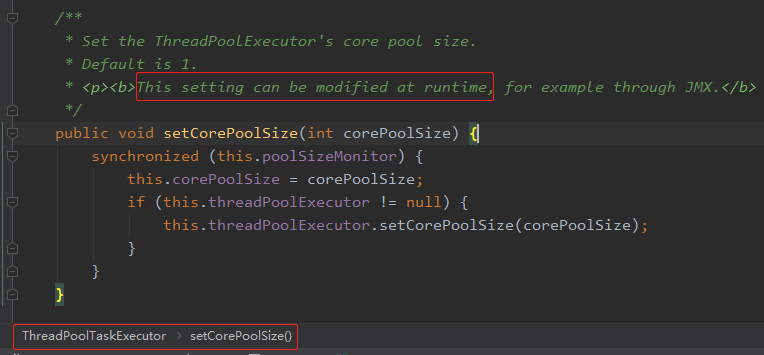
再品一品 JDK 的源码,其实源码也体现出了有修改的含义的,两个值去做差值,只是第一次设置的时候原来的值为 0 而已。
接着看 setMaximumPoolSize 源码:
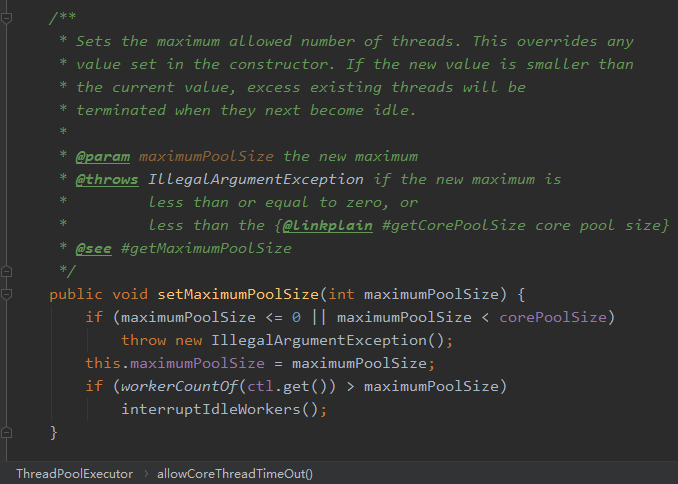
1.首先是参数合法性校验。
2.然后用传递进来的值,覆盖原来的值。
3.判断工作线程是否是大于最大线程数,如果大于,则对空闲线程发起中断请求。
经过前面两个方法的分析,我们知道了最大线程数和核心线程数可以动态调整。
动态设置的注意点有哪些?
调整的时候可能会出现核心线程数调整之后无效的情况,比如下面这种:
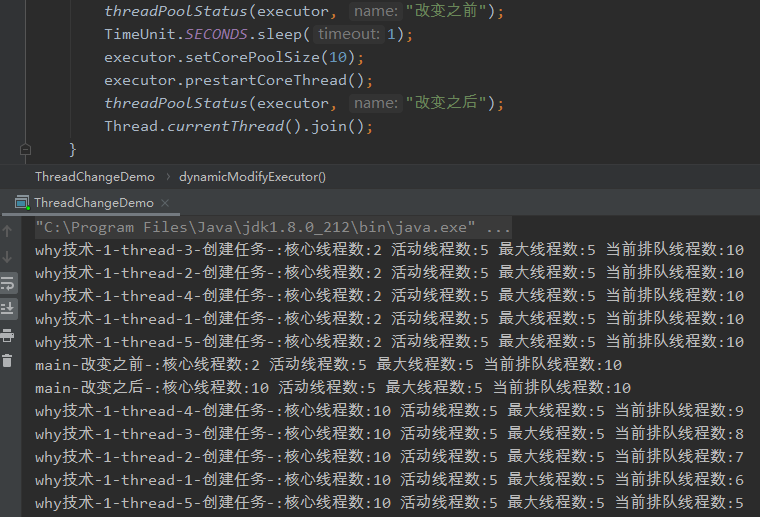
改变之前的核心线程数是 2,最大线程数为 5,我们动态修改核心线程数为 10。
但是从日志还是可以看出,修改之后核心线程数确实变成了 10,但活跃线程数还是为 5。
而且我调用了 prestartCoreThread 方法,该方法见名知意,你也知道是启动所有的核心线程数,所有不存在线程没有创建的问题。
工作线程数大于最大线程数,那么只是修改核心线程数,线程是无法增加的。
设置核心线程数的时候,同时设置最大线程数即可。其实可以把二者设置为相同的值:
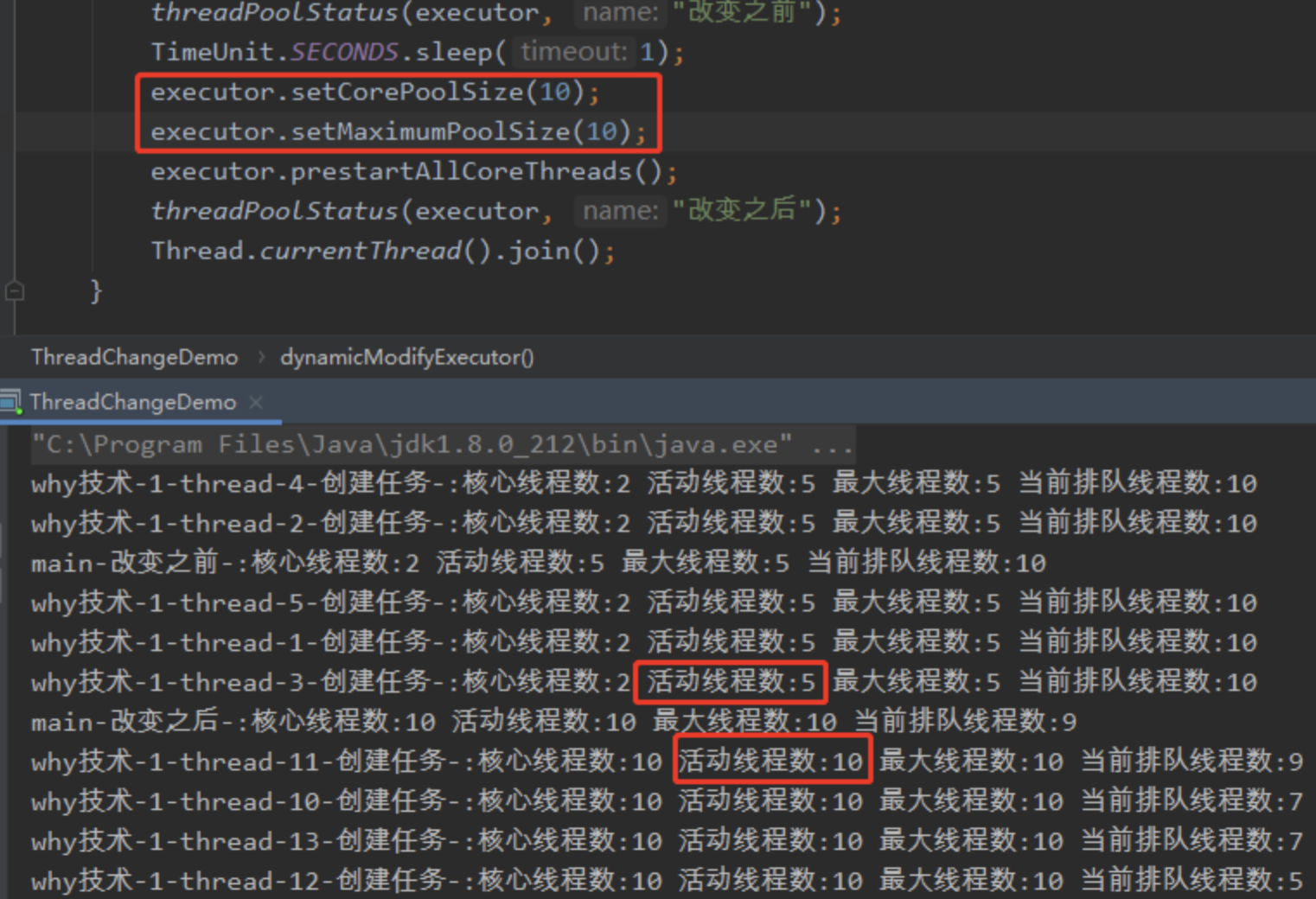
如果调整之后把活动线程数设置的值太大了,岂不是业务低峰期我们还需要人工把值调的小一点?
不存在的,还记得前面介绍 corePoolSize 参数的含义时的注解
当 allowCoreThreadTimeOut 参数设置为 true 的时候,核心线程在空闲了 keepAliveTime 的时间后也会被回收的,相当于线程池自动给你动态修改了。
如何动态指定队列长度?
前面介绍了最大线程数和核心线程数的动态设置,但是你发现了吗,并没有设置队列长度的 set 方法啊?
先获取 Queue 对象出来再看一下呢?
首先我们看一下为什么没有提供队列长度的 set 方法呢:
因为队列的 capacity 是被 final 修饰了呀。

但是美团的文章明明说了,他们也支持队列的动态调整
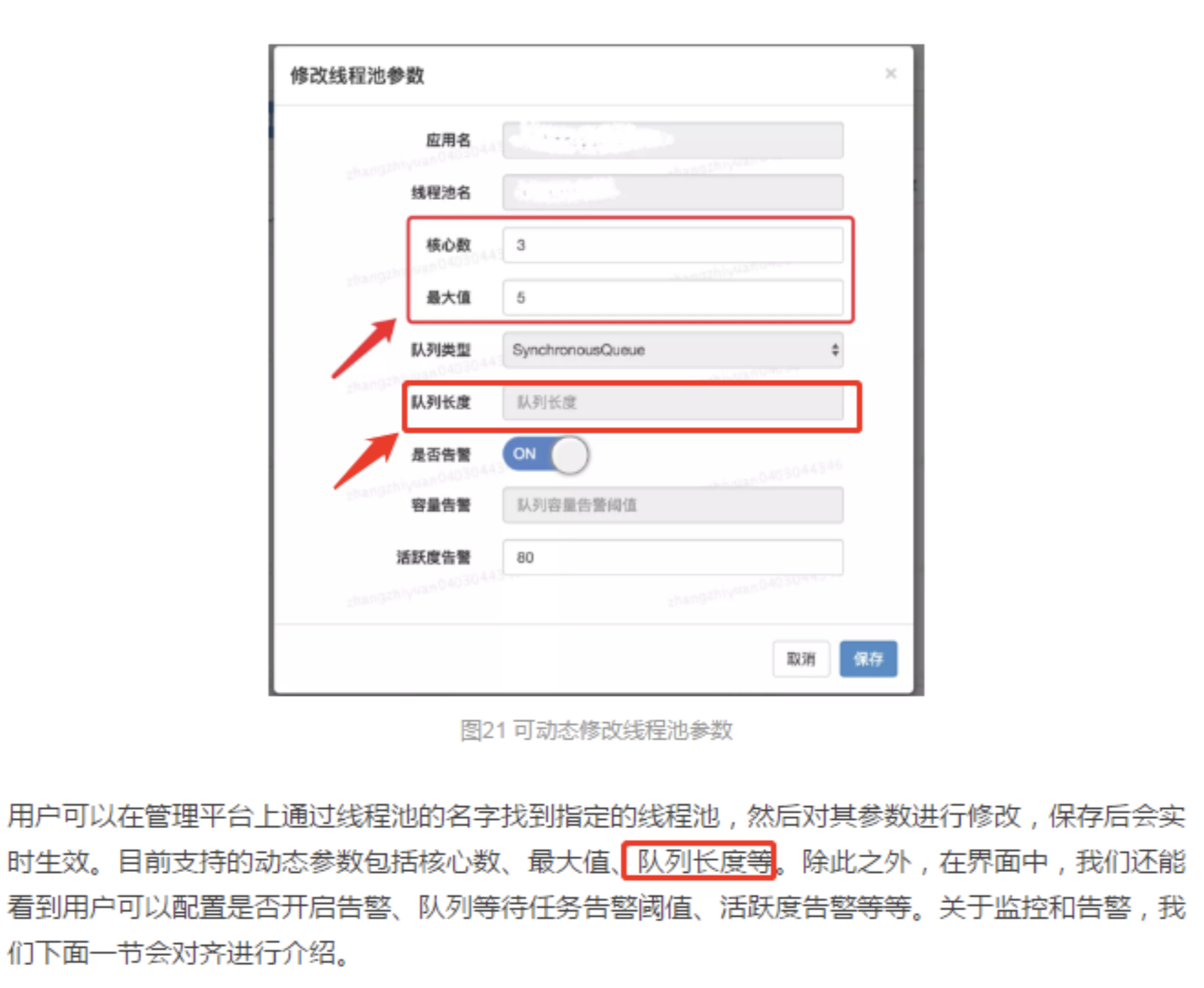
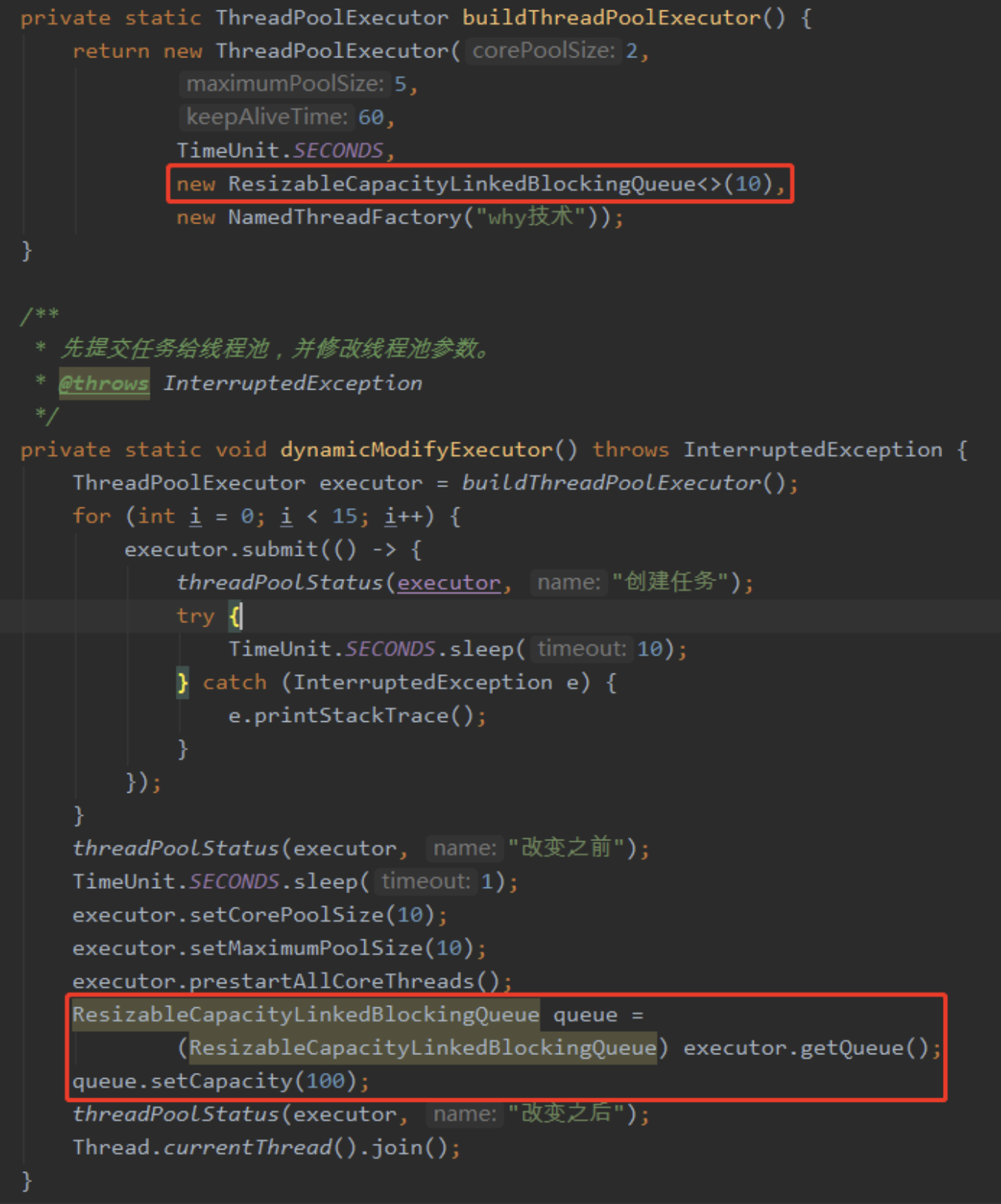
可是没有详细说明,但是别着急,接着看后面的内容可以发现他们有一个名字为 ResizableCapacityLinkedBlockIngQueue 的队列:
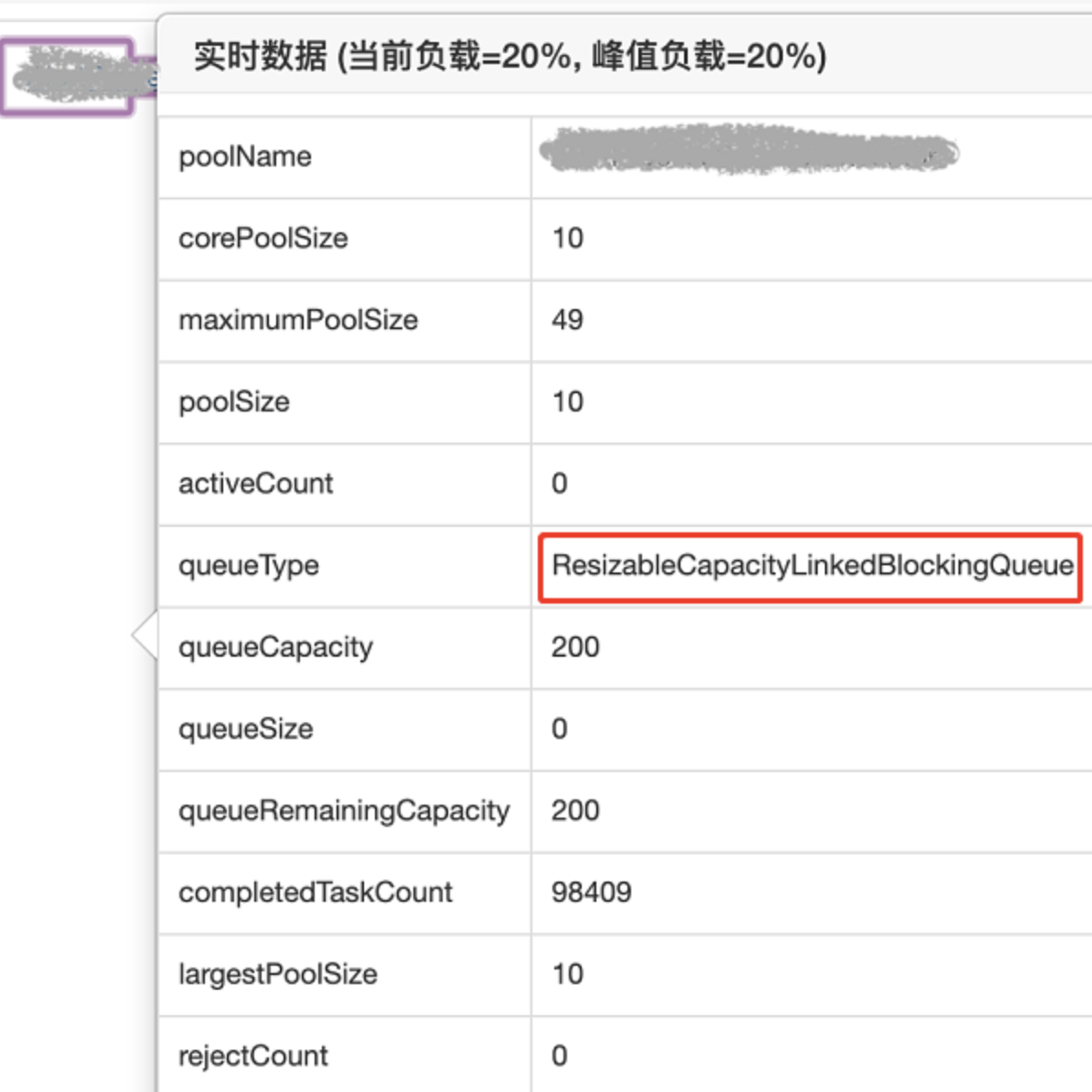
很明显,这是一个自定义队列了。
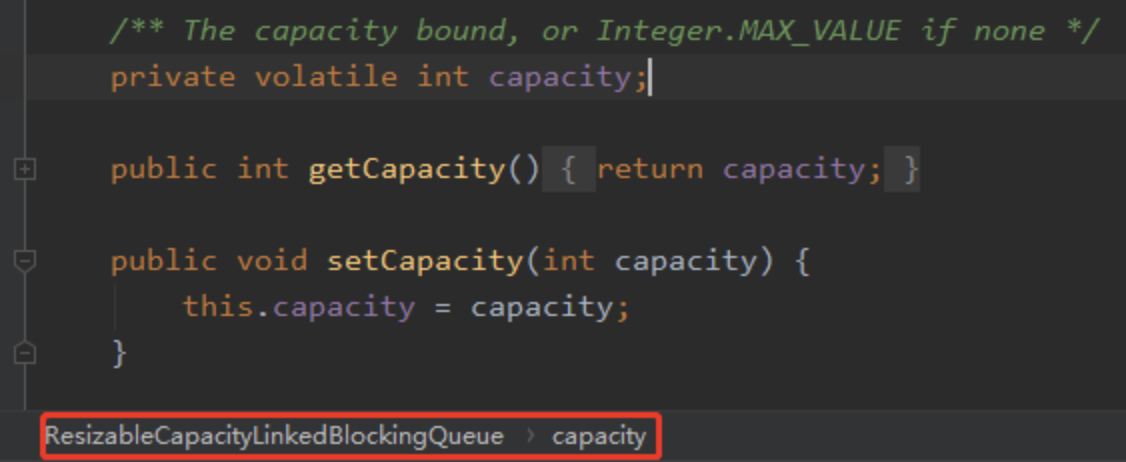
我们也可以按照这个思路自定义一个队列,让其可以对 Capacity 参数进行修改即可。
操作起来也非常方便,把 LinkedBlockingQueue 粘贴一份出来,修改个名字,然后把 Capacity 参数的 final 修饰符去掉,并提供其对应的 get/set 方法。
然后在程序里面把原来的队列换掉:
运行起来看看效果:
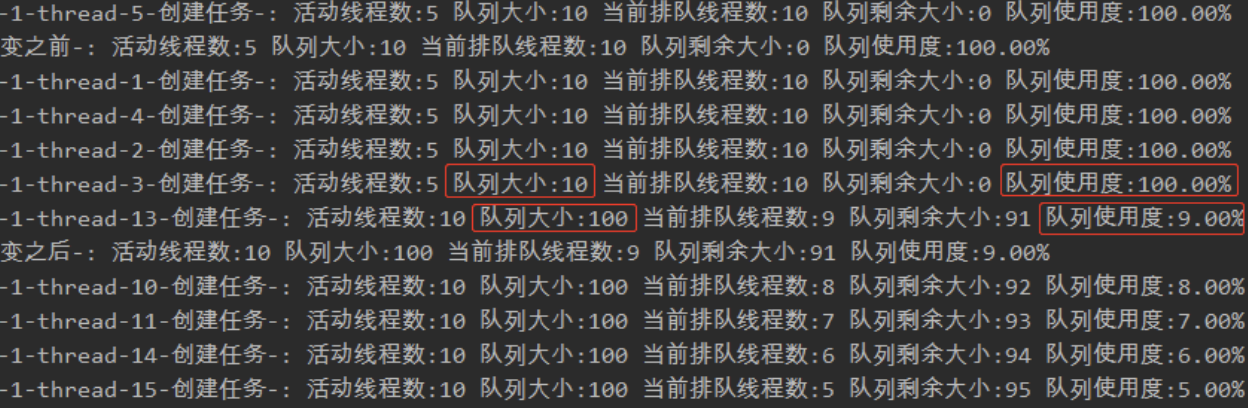
可以看到,队列大小确实从 10 变成了 100,队列使用度从 100% 降到了 9%。
我后来去看了美团的那篇文章下面的评论,有个评论是这样的:

这个过程中涉及到的问题有哪些?
问题一:线程池被创建后里面有线程吗?如果没有的话,你知道有什么方法对线程池进行预热吗?
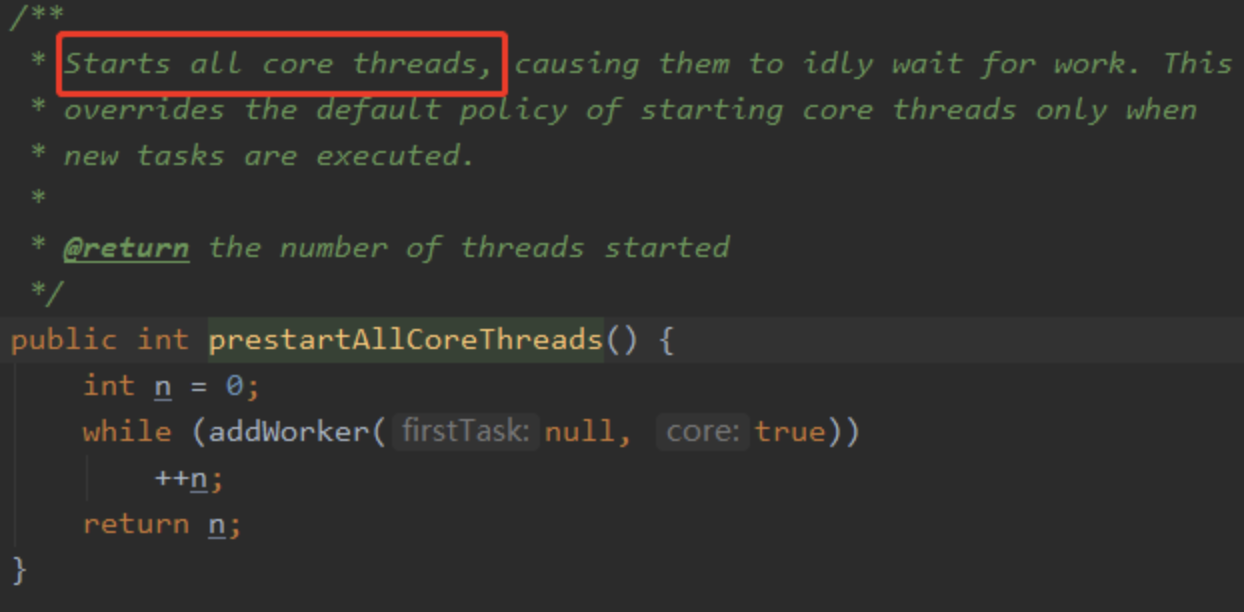
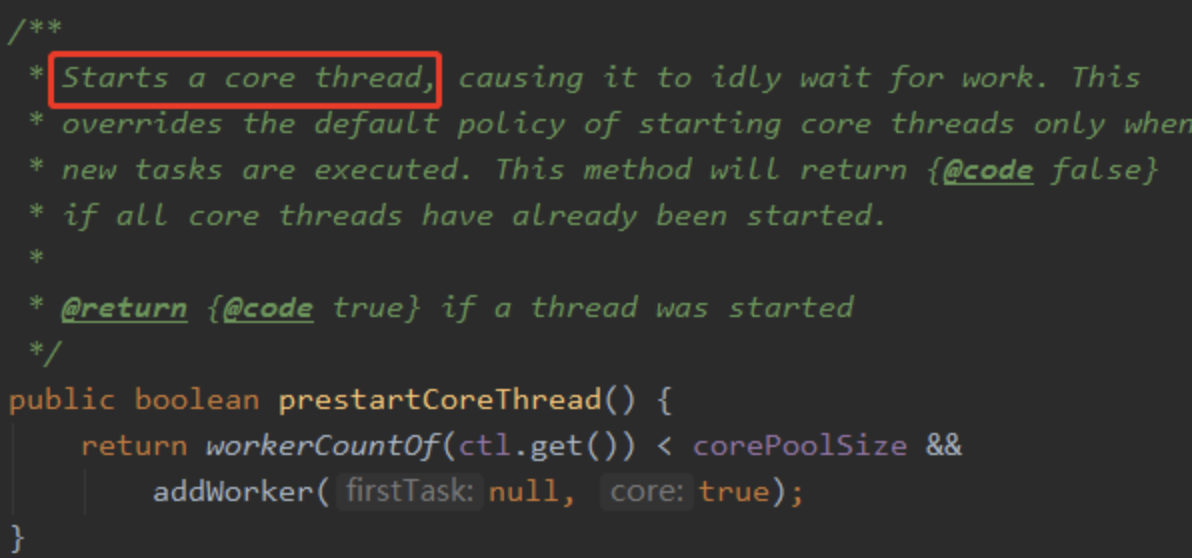
线程池被创建后如果没有任务过来,里面是不会有线程的。如果需要预热的话可以调用下面的两个方法:
全部启动:
仅启动一个:
问题二:核心线程数会被回收吗?需要什么设置?
核心线程数默认是不会被回收的,如果需要回收核心线程数,需要调用下面的方法:
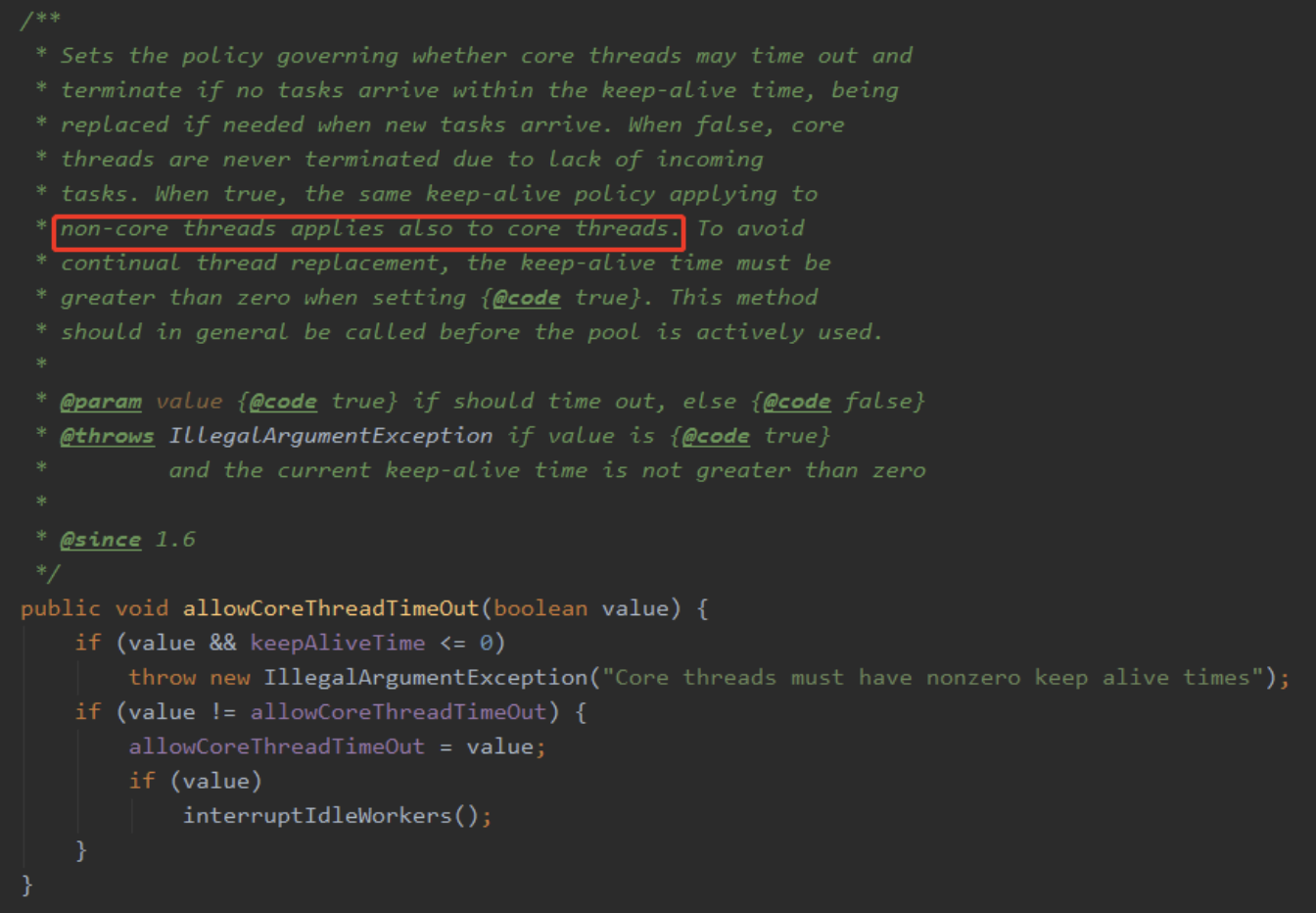
allowCoreThreadTimeOut 该值默认为 false。