阅读完需:约 75 分钟
IO模型就是说用什么样的通道进行数据的发送和接收,Java共支持3种网络编程IO模式:BIO,NIO,AIO
之前有过学习这三种模式的理论内容
BIO(Blocking IO)
同步阻塞模型,一个客户端连接对应一个处理线程
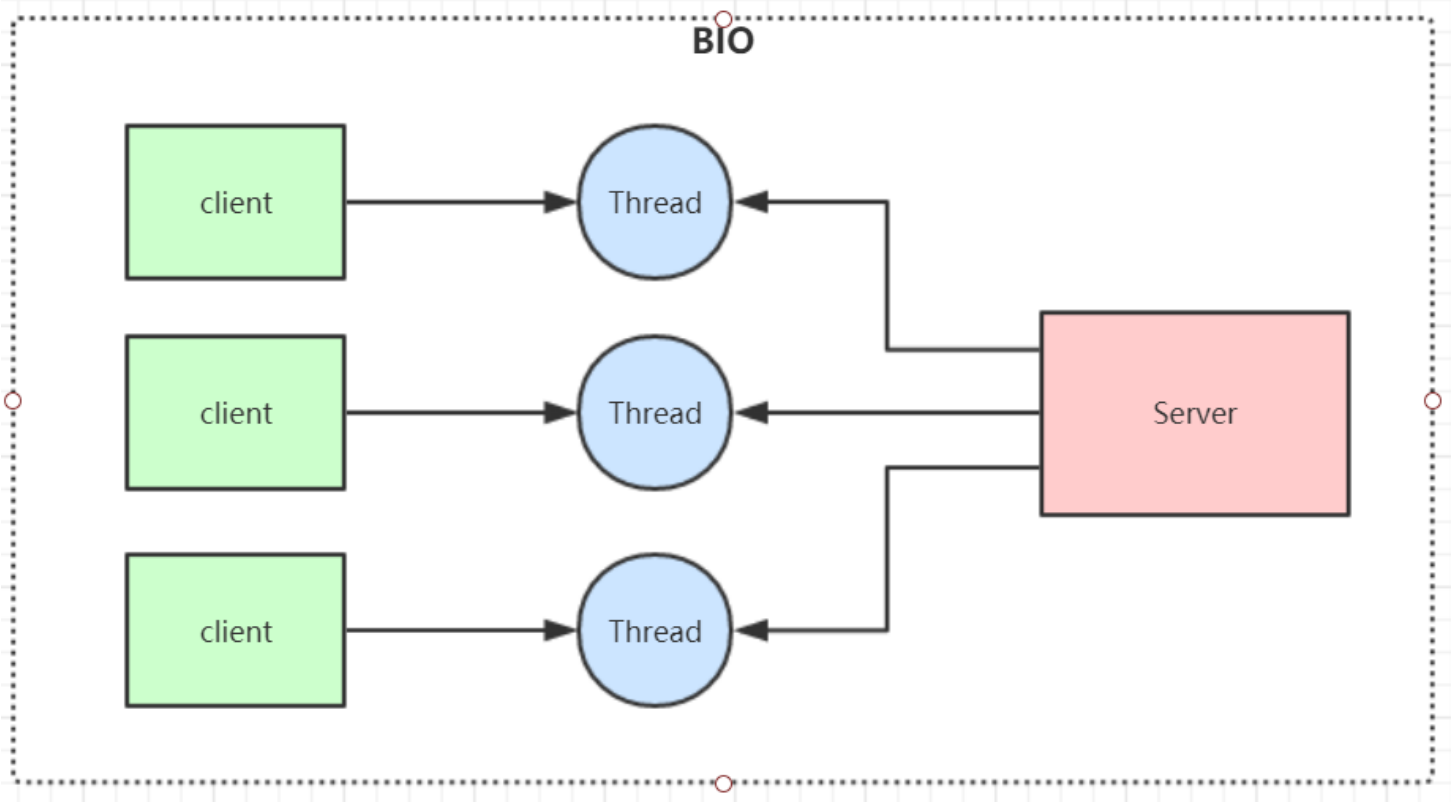
BIO代码示例:
服务端代码
public class SocketServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
System.out.println("等待连接。。");
//阻塞方法
Socket clientSocket = serverSocket.accept();
System.out.println("有客户端连接了。。");
new Thread(new Runnable() {
@Override
public void run() {
try {
handler(clientSocket);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
private static void handler(Socket clientSocket) throws IOException {
byte[] bytes = new byte[1024];
System.out.println("准备read。。");
//接收客户端的数据,阻塞方法,没有数据可读时就阻塞
int read = clientSocket.getInputStream().read(bytes);
System.out.println("read完毕。。");
if (read != -1) {
System.out.println("接收到客户端的数据:" + new String(bytes, 0, read));
}
// 向客户端发送数据
clientSocket.getOutputStream().write("HelloClient".getBytes());
clientSocket.getOutputStream().flush();
}
}客户端代码
public class SocketClient {
public static void main(String[] args) throws IOException, InterruptedException {
Socket socket = new Socket("127.0.0.1", 9000);
//向服务端发送数据
socket.getOutputStream().write("HelloServer".getBytes());
socket.getOutputStream().flush();
System.out.println("向服务端发送数据结束");
byte[] bytes = new byte[1024];
//接收服务端回传的数据
socket.getInputStream().read(bytes);
System.out.println("接收到服务端的数据:" + new String(bytes));
socket.close();
}
}缺点:
- IO代码里read操作是阻塞操作,如果连接不做数据读写操作会导致线程阻塞,浪费资源
- 如果线程很多,会导致服务器线程太多,压力太大,比如C10K问题
应用场景:
BIO 方式适用于连接数目比较小且固定的架构, 这种方式对服务器资源要求比较高, 但程序简单易理解。
- 阻塞模式下,相关方法都会导致线程暂停
-
ServerSocketChannel.accept会在没有连接建立时让线程暂停 -
SocketChannel.read会在通道中没有数据可读时让线程暂停 - 阻塞的表现其实就是线程暂停了,暂停期间不会占用 cpu,但线程相当于闲置
-
- 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持
- 但多线程下,有新的问题,体现在以下方面
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接
这里有个小问题需要清楚
Socket、SocketChannel有什么区别
Socket、SocketChannel二者的实质都是一样的,都是为了实现客户端与服务器端的连接而存在的,但是在使用上,却有很大的区别。
Socket在java.net包中,而SocketChannel在java.nio包中。
从包的不同,我们大体可以推断出他们主要的区别:Socket是阻塞连接(当然我们可以自己实现非阻塞),SocketChannel可以设置非阻塞连接。
使用ServerSocket、Socket类时,服务端Socket往往要为每一个客户端Socket分配一个线程,而每一个线程都有可能处于长时间的阻塞状态中。过多的线程也会影响服务器的性能(可以使用线程池优化)。而使用SocketChannel、ServerSocketChannel类可以非阻塞通信,这样使得服务器端只需要一个线程就能处理所有客户端socket的请求。
Socket、ServerSocket类可以传入不同参数直接实例化对象并绑定ip和端口,如:
Socket socket = new Socket("127.0.0.1", "8000");
ServerSocket serverSocket = new ServerSocket("8000");SocketChannel、ServerSocketChannel类需要借助Selector类控制
Selector selector = Selector.open();
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false); // 设置为非阻塞方式,如果为true 那么就为传统的阻塞方式
serverChannel.socket().bind(new InetSocketAddress(port)); // 绑定IP 及 端口
serverChannel.register(selector, SelectionKey.OP_ACCEPT); // 注册 OP_ACCEPT事件
new ServerThread().start(); // 开启一个线程 处理所有请求核心类
-
ServerSocketChannelServerSocket的替代类, 支持阻塞通信与非阻塞通信。 -
SocketChannelSocket的替代类, 支持阻塞通信与非阻塞通信。 -
Selector
为ServerSocketChannel监控接收客户端连接就绪事件, 为SocketChannel监控连接服务器读就绪和写就绪事件。 -
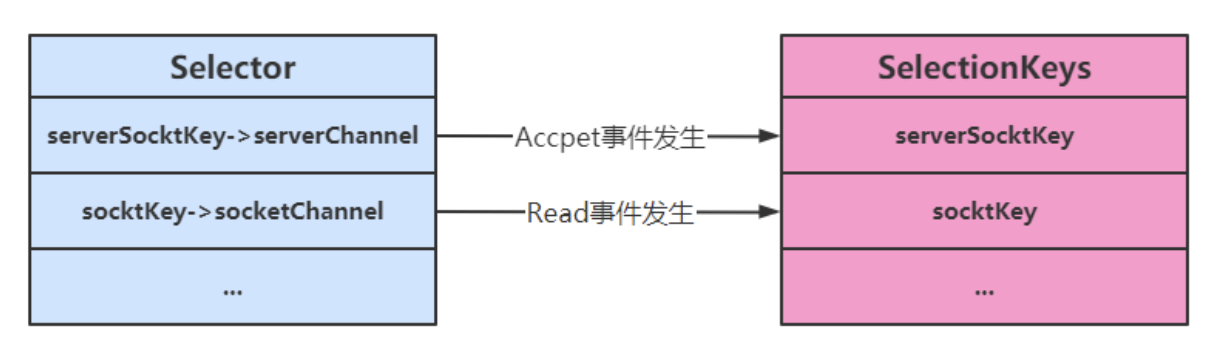
SelectionKey
代表ServerSocketChannel及SocketChannel向Selector注册事件的句柄。当一个SelectionKey对象位于Selector对象的selected-keys集合中时,就表示与这个SelectionKey对象相关的事件发生了。
在SelectionKey类中有几个静态常量:-
SelectionKey.OP_ACCEPT,客户端连接就绪事件,等于监听serversocket.accept(),返回一个socket。 -
SelectionKey.OP_CONNECT,准备连接服务器就绪,跟上面类似,只不过是对于socket的 相当于监听了socket.connect()。 -
SelectionKey.OP_READ,读就绪事件, 表示输入流中已经有了可读数据, 可以执行读操作。 -
SelectionKey.OP_WRITE,写就绪事件, 表示可以执行写操作。
-
NIO(Non Blocking IO)
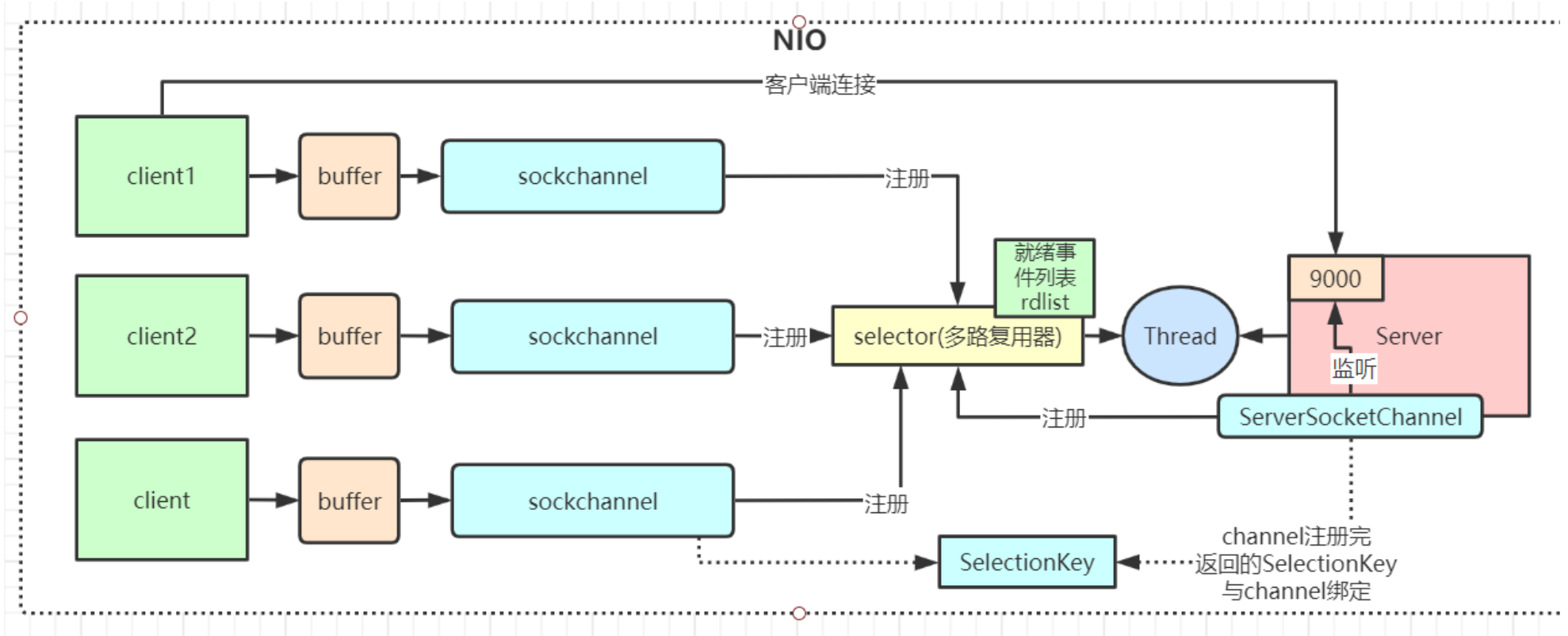
同步非阻塞,服务器实现模式为一个线程可以处理多个请求(连接),客户端发送的连接请求都会注册到多路复用器selector上,多路复用,器轮询到连接有IO请求就进行处理,JDK1.4开始引入。
应用场景:
NIO方式适用于连接数目多且连接比较短(轻操作) 的架构, 比如聊天服务器, 弹幕系统, 服务器间通讯,编程比较复杂
NIO非阻塞代码示例:
服务端代码
public class NioServer {
// 保存客户端连接
static List<SocketChannel> channelList = new ArrayList<>();
public static void main(String[] args) throws IOException {
// 创建NIO ServerSocketChannel,与BIO的serverSocket类似
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(9000));
// 设置ServerSocketChannel为非阻塞
serverSocket.configureBlocking(false);
System.out.println("服务启动成功");
while (true) {
// 非阻塞模式accept方法不会阻塞,否则会阻塞
// NIO的非阻塞是由操作系统内部实现的,底层调用了linux内核的accept函数
SocketChannel socketChannel = serverSocket.accept();
if (socketChannel != null) { // 如果有客户端进行连接
System.out.println("连接成功");
// 设置SocketChannel为非阻塞
socketChannel.configureBlocking(false);
// 保存客户端连接在List中
channelList.add(socketChannel);
}
// 遍历连接进行数据读取
Iterator<SocketChannel> iterator = channelList.iterator();
while (iterator.hasNext()) {
SocketChannel sc = iterator.next();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
// 非阻塞模式read方法不会阻塞,否则会阻塞
int len = sc.read(byteBuffer);
// 如果有数据,把数据打印出来
if (len > 0) {
System.out.println("接收到消息:" + new String(byteBuffer.array()));
} else if (len == -1) { // 如果客户端断开,把socket从集合中去掉
iterator.remove();
System.out.println("客户端断开连接");
}
}
}
}
}这里有一个问题,如果连接数太多的话,会有大量的无效遍历,假如有10000个连接,其中只有1000个连接有写数据,但是由于其他9000个连接并没有断开,我们还是要每次轮询遍历一万次,其中有十分之九的遍历都是无效的,这显然不是一个让人很满意的状态。
- 可以通过
ServerSocketChannel的configureBlocking(false)方法将获得连接设置为非阻塞的。此时若没有连接,accept会返回null - 可以通过
SocketChannel的configureBlocking(false)方法将从通道中读取数据设置为非阻塞的。若此时通道中没有数据可读,read会返回-1
NIO引入多路复用器代码示例:
public class NioSelectorServer {
public static void main(String[] args) throws IOException {
// 创建NIO ServerSocketChannel
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(9000));
// 设置ServerSocketChannel为非阻塞
serverSocket.configureBlocking(false);
// 打开Selector处理Channel,即创建epoll
Selector selector = Selector.open();
// 把ServerSocketChannel注册到selector上,并且selector对客户端accept连接操作感兴趣
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("服务启动成功");
while (true) {
// 阻塞等待需要处理的事件发生
selector.select();
// 获取selector中注册的全部事件的 SelectionKey 实例
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历SelectionKey对事件进行处理
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 如果是OP_ACCEPT事件,则进行连接获取和事件注册
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = server.accept();
socketChannel.configureBlocking(false);
// 这里只注册了读事件,如果需要给客户端发送数据可以注册写事件
socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("客户端连接成功");
} else if (key.isReadable()) { // 如果是OP_READ事件,则进行读取和打印
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
int len = socketChannel.read(byteBuffer);
// 如果有数据,把数据打印出来
if (len > 0) {
System.out.println("接收到消息:" + new String(byteBuffer.array()));
} else if (len == -1) { // 如果客户端断开连接,关闭Socket
System.out.println("客户端断开连接");
socketChannel.close();
}
}
//从事件集合里删除本次处理的key,防止下次select重复处理
iterator.remove();
}
}
}
}多路复用 Selector
单线程可以配合 Selector 完成对多个 Channel 可读写事件的监控,这称之为多路复用
- 多路复用仅针对网络 IO,普通文件 IO 无法利用多路复用
- 如果不用 Selector 的非阻塞模式,线程大部分时间都在做无用功,而 Selector 能够保证
- 有可连接事件时才去连接
- 有可读事件才去读取
- 有可写事件才去写入
- 限于网络传输能力,Channel 未必时时可写,一旦 Channel 可写,会触发 Selector 的可写事件
Accpet事件
获得选择器Selector
Selector selector = Selector.open();- 将通道设置为非阻塞模式,并注册到选择器中,并设置感兴趣的事件
- channel 必须工作在非阻塞模式
- FileChannel 没有非阻塞模式,因此不能配合 selector 一起使用
- 绑定的事件类型可以有
- connect – 客户端连接成功时触发
- accept – 服务器端成功接受连接时触发
- read – 数据可读入时触发,有因为接收能力弱,数据暂不能读入的情况
- write – 数据可写出时触发,有因为发送能力弱,数据暂不能写出的情况
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的实践
server.register(selector, SelectionKey.OP_ACCEPT);通过Selector监听事件,并获得就绪的通道个数,若没有通道就绪,线程会被阻塞
- 阻塞直到绑定事件发生
int count = selector.select(); - 阻塞直到绑定事件发生,或是超时(时间单位为 ms)
int count = selector.select(long timeout); -
不会阻塞,也就是不管有没有事件,立刻返回,自己根据返回值检查是否有事件
int count = selector.selectNow();
获取就绪事件并得到对应的通道,然后进行处理
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型,此处为Accept类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
// 获取连接并处理,而且是必须处理,否则需要取消
SocketChannel socketChannel = channel.accept();
// 处理完毕后移除
iterator.remove();
}
}事件发生后能否不处理
事件发生后,要么处理,要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为 nio 底层使用的是水平触发
Read事件
- 在Accept事件中,若有客户端与服务器端建立了连接,需要将其对应的SocketChannel设置为非阻塞,并注册到选择其中
- 添加Read事件,触发后进行读取操作
public class SelectServer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
// 创建选择器
Selector selector = Selector.open();
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的实践
server.register(selector, SelectionKey.OP_ACCEPT);
// 为serverKey设置感兴趣的事件
while (true) {
// 若没有事件就绪,线程会被阻塞,反之不会被阻塞。从而避免了CPU空转
// 返回值为就绪的事件个数
int ready = selector.select();
System.out.println("selector ready counts : " + ready);
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
System.out.println("before accepting...");
// 获取连接
SocketChannel socketChannel = channel.accept();
System.out.println("after accepting...");
// 设置为非阻塞模式,同时将连接的通道也注册到选择其中
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
// 处理完毕后移除
iterator.remove();
} else if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
System.out.println("before reading...");
channel.read(buffer);
System.out.println("after reading...");
buffer.flip();
ByteBufferUtil.debugRead(buffer);
buffer.clear();
// 处理完毕后移除
iterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}删除事件
当处理完一个事件后,一定要调用迭代器的remove方法移除对应事件,否则会出现错误。原因如下
以我们上面的 Read事件 的代码为例
- 当调用了
server.register(selector, SelectionKey.OP_ACCEPT)后,Selector中维护了一个集合,用于存放SelectionKey以及其对应的通道
// WindowsSelectorImpl 中的 SelectionKeyImpl数组
private SelectionKeyImpl[] channelArray = new SelectionKeyImpl[8];public class SelectionKeyImpl extends AbstractSelectionKey {
// Key对应的通道
final SelChImpl channel;
...
}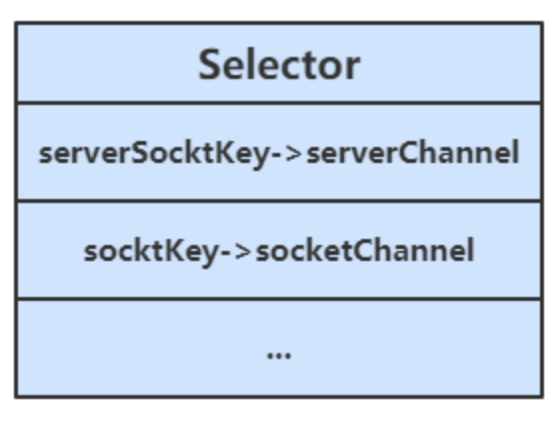
当选择器中的通道对应的事件发生后,selecionKey会被放到另一个集合中,但是selecionKey不会自动移除,所以需要我们在处理完一个事件后,通过迭代器手动移除其中的selecionKey。否则会导致已被处理过的事件再次被处理,就会引发错误
断开处理
当客户端与服务器之间的连接断开时,会给服务器端发送一个读事件,对异常断开和正常断开需要加以不同的方式进行处理
-
正常断开
- 正常断开时,服务器端的
channel.read(buffer)方法的返回值为-1,所以当结束到返回值为-1时,需要调用key的cancel方法取消此事件,并在取消后移除该事件
- 正常断开时,服务器端的
int read = channel.read(buffer);
// 断开连接时,客户端会向服务器发送一个写事件,此时read的返回值为-1
if(read == -1) {
// 取消该事件的处理
key.cancel();
channel.close();
} else {
...
}
// 取消或者处理,都需要移除key
iterator.remove();- 异常断开
- 异常断开时,会抛出
IOException异常, 在try-catch的catch块中捕获异常并调用key的cancel方法即可
- 异常断开时,会抛出
消息边界
不处理消息边界存在的问题
将缓冲区的大小设置为4个字节,发送2个汉字(你好),通过decode解码并打印时,会出现乱码
ByteBuffer buffer = ByteBuffer.allocate(4);
// 解码并打印
System.out.println(StandardCharsets.UTF_8.decode(buffer));
你�
��因为UTF-8字符集下,1个汉字占用3个字节,此时缓冲区大小为4个字节,一次读时间无法处理完通道中的所有数据,所以一共会触发两次读事件。这就导致 你好 的 好 字被拆分为了前半部分和后半部分发送,解码时就会出现问题
处理消息边界
传输的文本可能有以下三种情况
- 文本大于缓冲区大小
- 此时需要将缓冲区进行扩容
- 发生半包现象
- 发生粘包现象
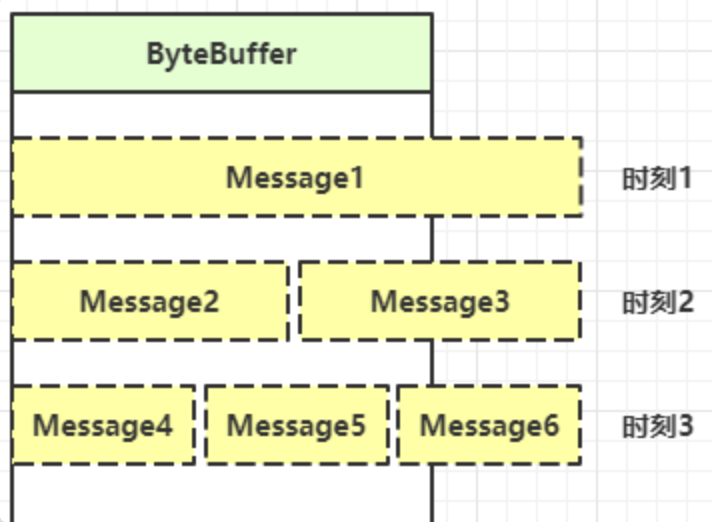
解决思路大致有以下三种
- 固定消息长度,数据包大小一样,服务器按预定长度读取,当发送的数据较少时,需要将数据进行填充,直到长度与消息规定长度一致。缺点是浪费带宽
- 另一种思路是按分隔符拆分,缺点是效率低,需要一个一个字符地去匹配分隔符
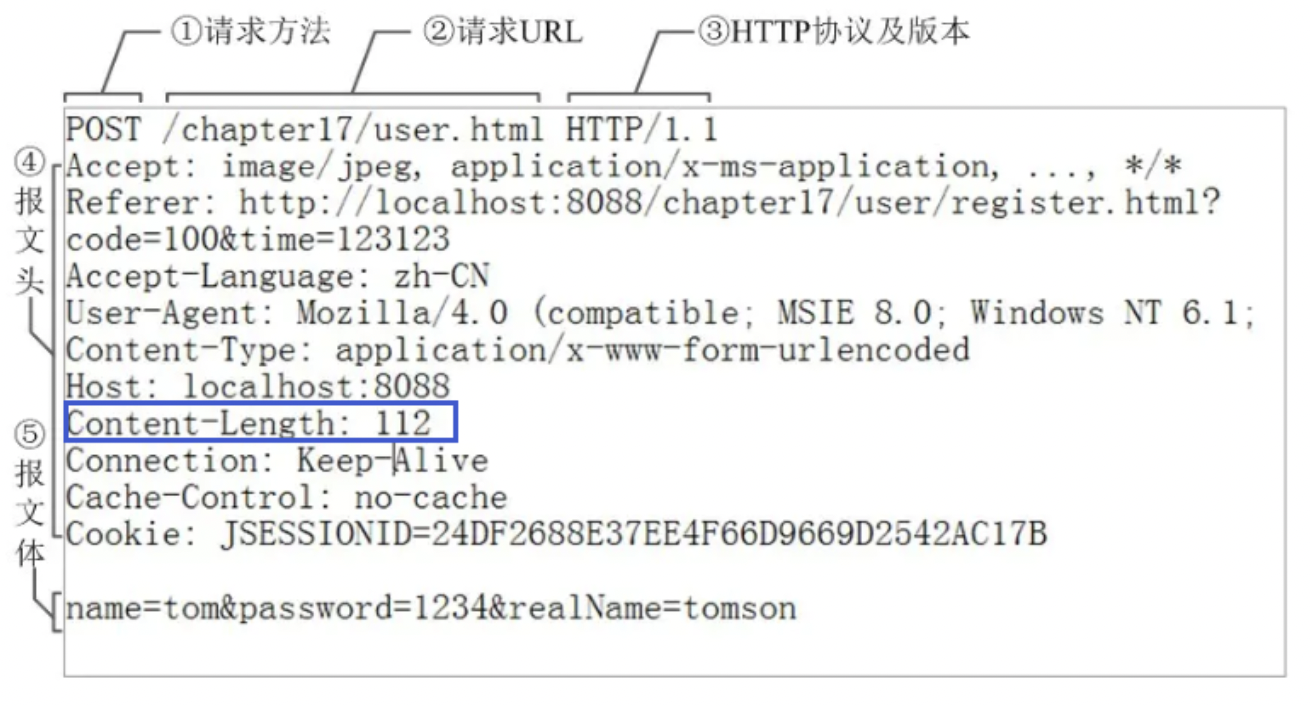
-
TLV 格式,即 Type 类型、Length 长度、Value 数据(也就是在消息开头用一些空间存放后面数据的长度),如HTTP请求头中的Content-Type与Content-Length。类型和长度已知的情况下,就可以方便获取消息大小,分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
- Http 1.1 是 TLV 格式
- Http 2.0 是 LTV 格式
附件与扩容
Channel的register方法还有第三个参数:附件,可以向其中放入一个Object类型的对象,该对象会与登记的Channel以及其对应的SelectionKey绑定,可以从SelectionKey获取到对应通道的附件
public final SelectionKey register(Selector sel, int ops, Object att)可通过SelectionKey的attachment()方法获得附件
ByteBuffer buffer = (ByteBuffer) key.attachment();我们需要在Accept事件发生后,将通道注册到Selector中时,对每个通道添加一个ByteBuffer附件,让每个通道发生读事件时都使用自己的通道,避免与其他通道发生冲突而导致问题
// 设置为非阻塞模式,同时将连接的通道也注册到选择其中,同时设置附件
socketChannel.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16);
// 添加通道对应的Buffer附件
socketChannel.register(selector, SelectionKey.OP_READ, buffer);当Channel中的数据大于缓冲区时,需要对缓冲区进行扩容操作。此代码中的扩容的判定方法:Channel调用compact方法后,的position与limit相等,说明缓冲区中的数据并未被读取(容量太小),此时创建新的缓冲区,其大小扩大为两倍。同时还要将旧缓冲区中的数据拷贝到新的缓冲区中,同时调用SelectionKey的attach方法将新的缓冲区作为新的附件放入SelectionKey中
// 如果缓冲区太小,就进行扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity()*2);
// 将旧buffer中的内容放入新的buffer中
ewBuffer.put(buffer);
// 将新buffer作为附件放到key中
key.attach(newBuffer);
}上面的代码可以改造一下
public class SelectServer {
public static void main(String[] args) {
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
// 创建选择器
Selector selector = Selector.open();
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的事件
server.register(selector, SelectionKey.OP_ACCEPT);
// 为serverKey设置感兴趣的事件
while (true) {
// 若没有事件就绪,线程会被阻塞,反之不会被阻塞。从而避免了CPU空转
// 返回值为就绪的事件个数
int ready = selector.select();
System.out.println("selector ready counts : " + ready);
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
System.out.println("before accepting...");
// 获取连接
SocketChannel socketChannel = channel.accept();
System.out.println("after accepting...");
// 设置为非阻塞模式,同时将连接的通道也注册到选择其中,同时设置附件
socketChannel.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16);
socketChannel.register(selector, SelectionKey.OP_READ, buffer);
// 处理完毕后移除
iterator.remove();
} else if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
System.out.println("before reading...");
// 通过key获得附件(buffer)
ByteBuffer buffer = (ByteBuffer) key.attachment();
int read = channel.read(buffer);
if(read == -1) {
key.cancel();
channel.close();
} else {
// 通过分隔符来分隔buffer中的数据
split(buffer);
// 如果缓冲区太小,就进行扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity()*2);
// 将旧buffer中的内容放入新的buffer中
buffer.flip();
newBuffer.put(buffer);
// 将新buffer放到key中作为附件
key.attach(newBuffer);
}
}
System.out.println("after reading...");
// 处理完毕后移除
iterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void split(ByteBuffer buffer) {
buffer.flip();
for(int i = 0; i < buffer.limit(); i++) {
// 遍历寻找分隔符
// get(i)不会移动position
if (buffer.get(i) == '\n') {
// 缓冲区长度
int length = i+1-buffer.position();
ByteBuffer target = ByteBuffer.allocate(length);
// 将前面的内容写入target缓冲区
for(int j = 0; j < length; j++) {
// 将buffer中的数据写入target中
target.put(buffer.get());
}
// 打印结果
ByteBufferUtil.debugAll(target);
}
}
// 切换为写模式,但是缓冲区可能未读完,这里需要使用compact
buffer.compact();
}
}Write事件
服务器通过Buffer向通道中写入数据时,可能因为通道容量小于Buffer中的数据大小,导致无法一次性将Buffer中的数据全部写入到Channel中,这时便需要分多次写入,具体步骤如下
- 执行一次写操作,向将buffer中的内容写入到SocketChannel中,然后判断Buffer中是否还有数据
- 若Buffer中还有数据,则需要将SockerChannel注册到Seletor中,并关注写事件,同时将未写完的Buffer作为附件一起放入到SelectionKey中
int write = socket.write(buffer);
// 通道中可能无法放入缓冲区中的所有数据
if (buffer.hasRemaining()) {
// 注册到Selector中,关注可写事件,并将buffer添加到key的附件中
socket.configureBlocking(false);
socket.register(selector, SelectionKey.OP_WRITE, buffer);
}添加写事件的相关操作key.isWritable(),对Buffer再次进行写操作
- 每次写后需要判断Buffer中是否还有数据(是否写完)。若写完,需要移除SelecionKey中的Buffer附件,避免其占用过多内存,同时还需移除对写事件的关注
SocketChannel socket = (SocketChannel) key.channel();
// 获得buffer
ByteBuffer buffer = (ByteBuffer) key.attachment();
// 执行写操作
int write = socket.write(buffer);
System.out.println(write);
// 如果已经完成了写操作,需要移除key中的附件,同时不再对写事件感兴趣
if (!buffer.hasRemaining()) {
key.attach(null);
key.interestOps(0);
}代码示例如下
public class WriteServer {
public static void main(String[] args) {
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
server.configureBlocking(false);
Selector selector = Selector.open();
server.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select();
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 处理后就移除事件
iterator.remove();
if (key.isAcceptable()) {
// 获得客户端的通道
SocketChannel socket = server.accept();
// 写入数据
StringBuilder builder = new StringBuilder();
for(int i = 0; i < 500000000; i++) {
builder.append("a");
}
ByteBuffer buffer = StandardCharsets.UTF_8.encode(builder.toString());
// 先执行一次Buffer->Channel的写入,如果未写完,就添加一个可写事件
int write = socket.write(buffer);
System.out.println(write);
// 通道中可能无法放入缓冲区中的所有数据
if (buffer.hasRemaining()) {
// 注册到Selector中,关注可写事件,并将buffer添加到key的附件中
socket.configureBlocking(false);
socket.register(selector, SelectionKey.OP_WRITE, buffer);
}
} else if (key.isWritable()) {
SocketChannel socket = (SocketChannel) key.channel();
// 获得buffer
ByteBuffer buffer = (ByteBuffer) key.attachment();
// 执行写操作
int write = socket.write(buffer);
System.out.println(write);
// 如果已经完成了写操作,需要移除key中的附件,同时不再对写事件感兴趣
if (!buffer.hasRemaining()) {
key.attach(null);
key.interestOps(0);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}NIO 有三大核心组件: Channel(通道), Buffer(缓冲区),Selector(多路复用器)
-
channel类似于流,每个channel对应一个buffer缓冲区,buffer底层就是个数组 -
channel会注册到selector上,由selector根据channel读写事件的发生将其交由某个空闲的线程处理 -
NIO的Buffer和channel都是既可以读也可以写
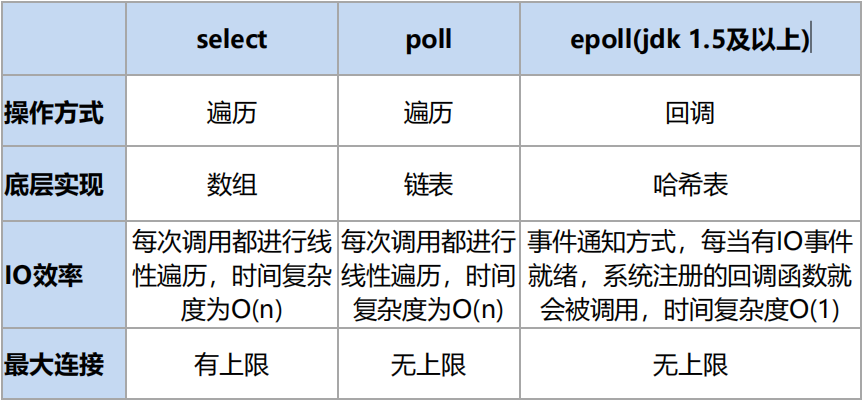
NIO底层在JDK1.4版本是用linux的内核函数select()或poll()来实现,跟上面的NioServer代码类似,selector每次都会轮询所有的 sockchannel看下哪个channel有读写事件,有的话就处理,没有就继续遍历,JDK1.5开始引入了epoll基于事件响应机制来优化NIO。
NioSelectorServer 代码里如下几个方法非常重要,我们从Hotspot与Linux内核函数级别来理解下
-
Selector.open()//创建多路复用器 -
socketChannel.register()//将channel注册到多路复用器上 -
selector.select()//阻塞等待需要处理的事件发生
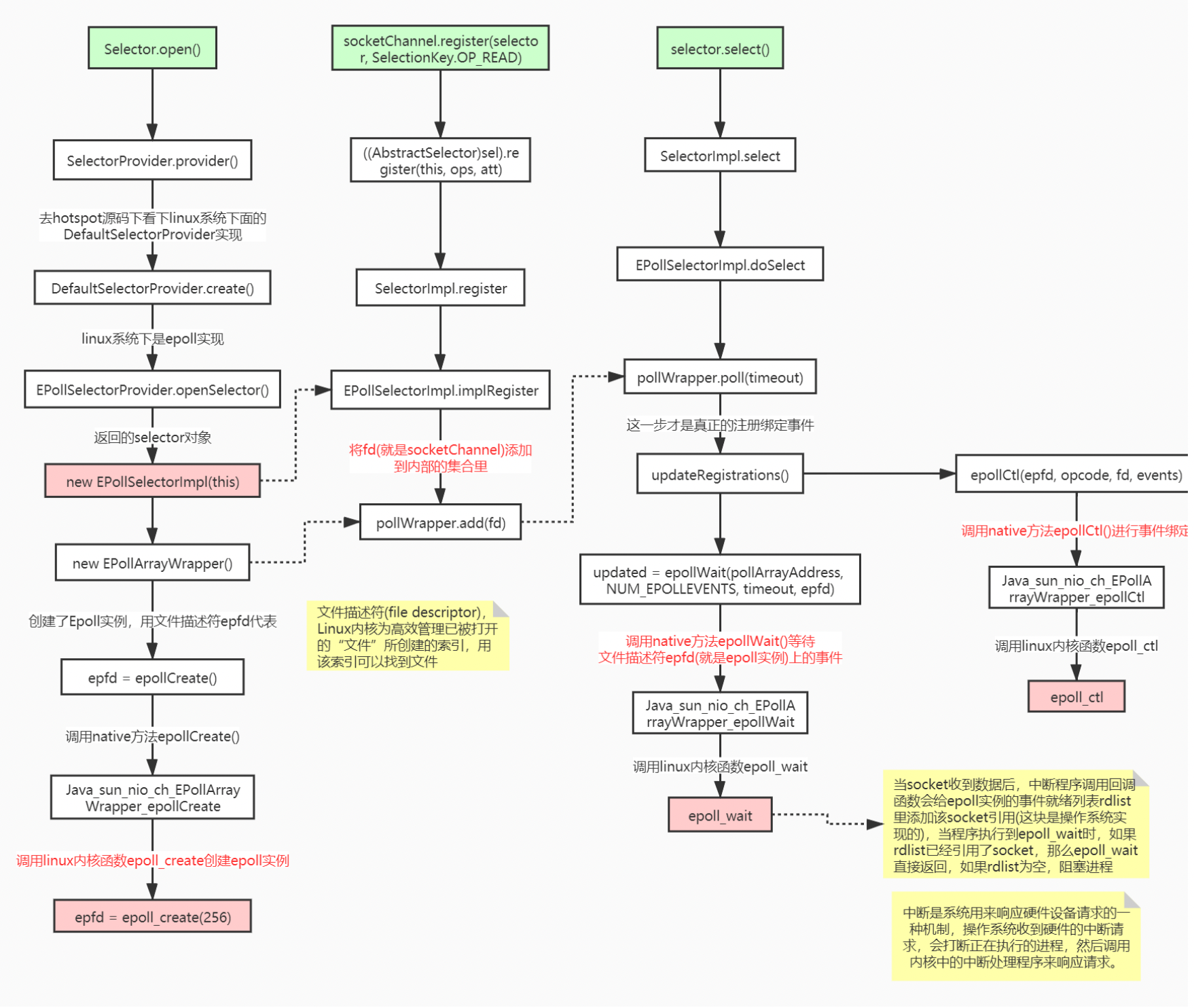
总结:NIO整个调用流程就是Java调用了操作系统的内核函数来创建Socket,获取到Socket的文件描述符,再创建一个Selector对象,对应操作系统的Epoll描述符,将获取到的Socket连接的文件描述符的事件绑定到Selector对应的Epoll文件描述符上,进行事件的异步通知,这样就实现了使用一条线程,并且不需要太多的无效的遍历,将事件处理交给了操作系统内核(操作系统中断 程序实现),大大提高了效率。
I/O多路复用底层主要用的Linux 内核函数(select,poll,epoll)来实现,windows不支持epoll实现,windows底层是基于winsock2的,select函数实现的(不开源)
AIO(NIO 2.0)
异步非阻塞, 由操作系统完成后回调通知服务端程序启动线程去处理, 一般适用于连接数较多且连接时间较长的应用
应用场景:
AIO方式适用于连接数目多且连接比较长(重操作)的架构,JDK7 开始支持
AIO代码示例:
服务端代码
public class AIOServer {
public static void main(String[] args) throws Exception {
final AsynchronousServerSocketChannel serverChannel =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(9000));
serverChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
@Override
public void completed(AsynchronousSocketChannel socketChannel, Object attachment) {
try {
System.out.println("2--"+Thread.currentThread().getName());
// 再此接收客户端连接,如果不写这行代码后面的客户端连接连不上服务端
serverChannel.accept(attachment, this);
System.out.println(socketChannel.getRemoteAddress());
ByteBuffer buffer = ByteBuffer.allocate(1024);
socketChannel.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
System.out.println("3--"+Thread.currentThread().getName());
buffer.flip();
System.out.println(new String(buffer.array(), 0, result));
socketChannel.write(ByteBuffer.wrap("HelloClient".getBytes()));
}
@Override
public void failed(Throwable exc, ByteBuffer buffer) {
exc.printStackTrace();
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, Object attachment) {
exc.printStackTrace();
}
});
System.out.println("1--"+Thread.currentThread().getName());
Thread.sleep(Integer.MAX_VALUE);
}
}客户端代码
public class AIOClient {
public static void main(String... args) throws Exception {
AsynchronousSocketChannel socketChannel = AsynchronousSocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 9000)).get();
socketChannel.write(ByteBuffer.wrap("HelloServer".getBytes()));
ByteBuffer buffer = ByteBuffer.allocate(512);
Integer len = socketChannel.read(buffer).get();
if (len != -1) {
System.out.println("客户端收到信息:" + new String(buffer.array(), 0, len));
}
}
}为什么Netty使用NIO而不是AIO?
在Linux系统上,AIO的底层实现仍使用Epoll,没有很好实现AIO,因此在性能上没有明显的优势,而且被JDK封装了一层不容易深度优化,Linux上AIO还不够成熟。Netty是异步非阻塞框架,Netty在NIO上做了很多异步的封装。
Linux 在 5.1 版本引入的一套新的异步 IO 实现。 相比 Linux 在 2.6 版本引入的 AIO,io_uring 性能强很多,接近 SPDK ,同时支持 buffer IO,但是目前各个框架没有发挥出来。
NIO 三大组件
Channel与Buffer
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理
简而言之,通道负责传输,缓冲区负责存储
常见的Channel有以下四种,其中FileChannel主要用于文件传输,其余三种用于网络通信
FileChannelDatagramChannelSocketChannelServerSocketChannel
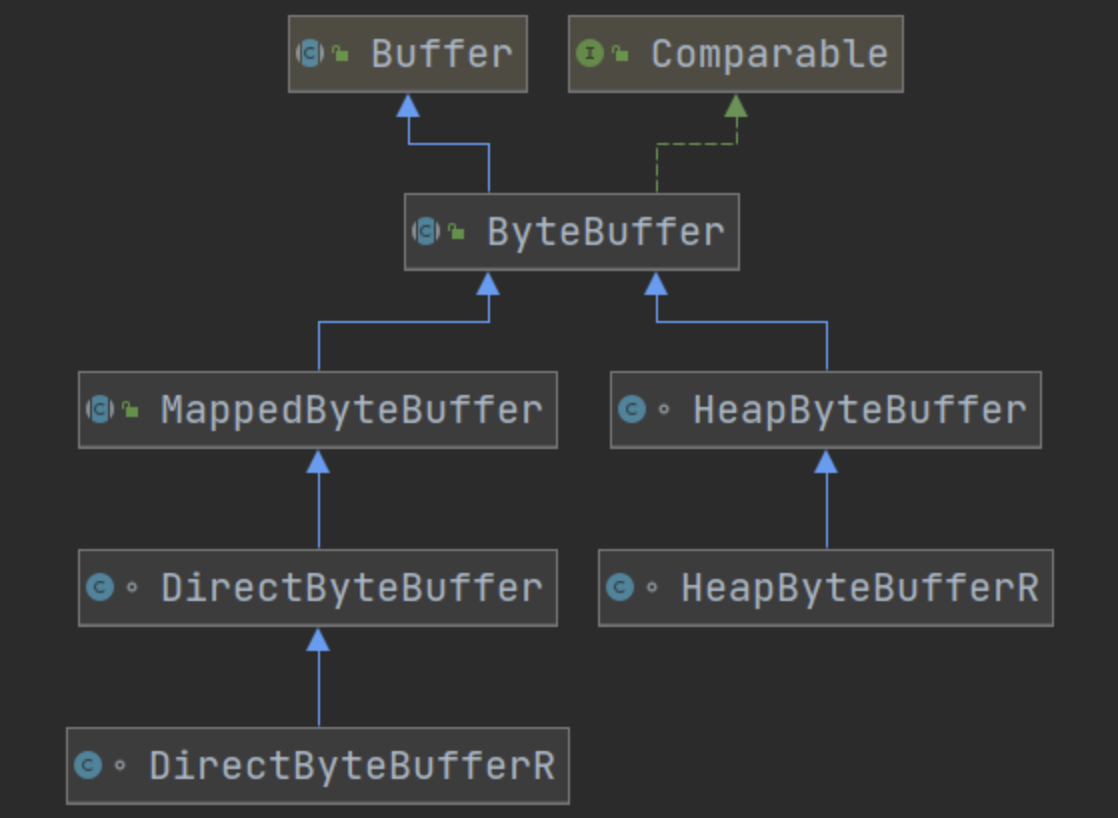
Buffer有以下几种,其中使用较多的是ByteBuffer
-
ByteBufferMappedByteBufferDirectByteBufferHeapByteBuffer
ShortBufferIntBufferLongBufferFloatBufferDoubleBufferCharBuffer
Selector
在使用Selector之前,处理socket连接还有以下两种方法
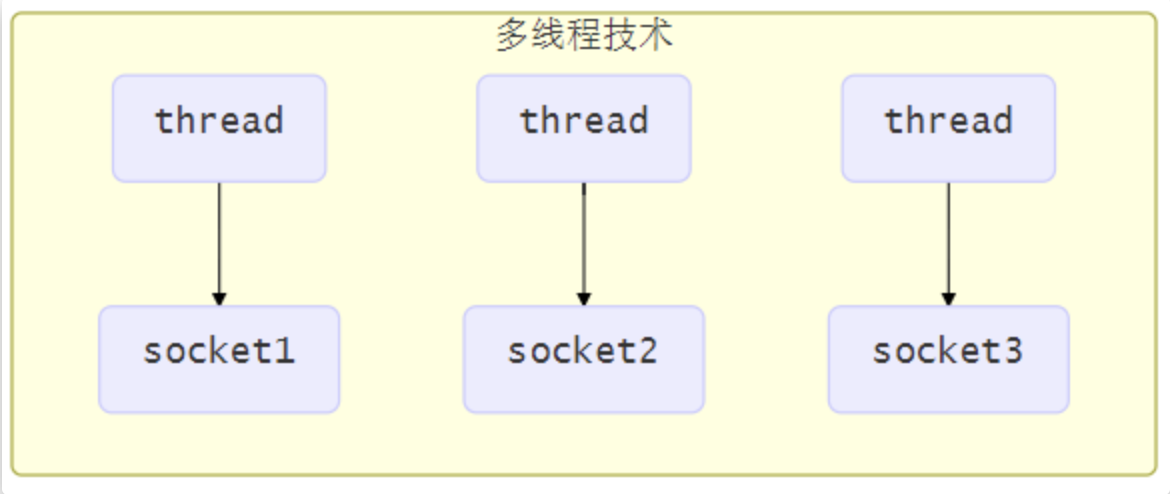
使用多线程技术
为每个连接分别开辟一个线程,分别去处理对应的socke连接
这种方法存在以下几个问题
- 内存占用高
- 每个线程都需要占用一定的内存,当连接较多时,会开辟大量线程,导致占用大量内存
- 线程上下文切换成本高
- 只适合连接数少的场景
- 连接数过多,会导致创建很多线程,从而出现问题
使用线程池技术
使用线程池,让线程池中的线程去处理连接
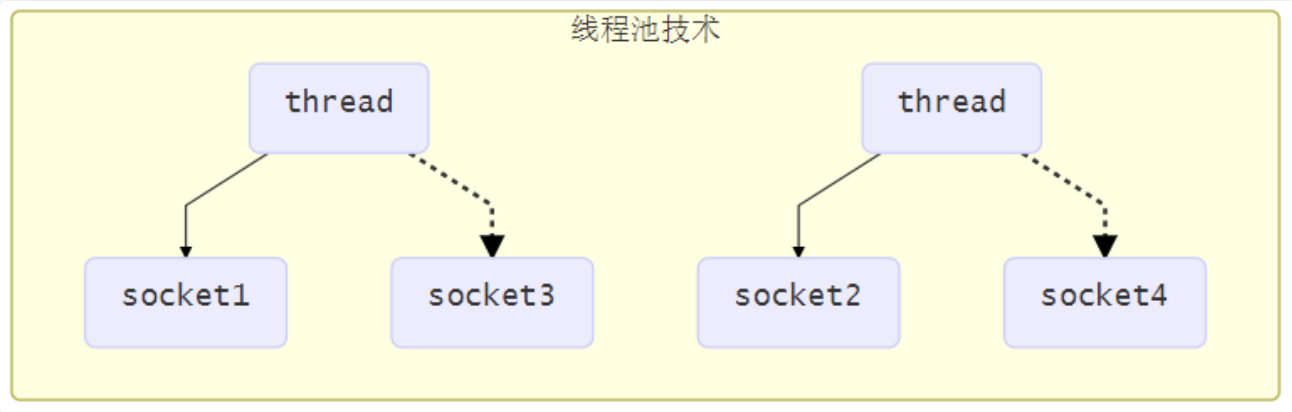
这种方法存在以下几个问题
- 阻塞模式下,线程仅能处理一个连接
- 线程池中的线程获取任务(task)后,只有当其执行完任务之后(断开连接后),才会去获取并执行下一个任务
- 若socke连接一直未断开,则其对应的线程无法处理其他socke连接
- 仅适合短连接场景
- 短连接即建立连接发送请求并响应后就立即断开,使得线程池中的线程可以快速处理其他连接
使用选择器
selector 的作用就是配合一个线程来管理多个 channel(fileChannel因为是阻塞式的,所以无法使用selector),获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,当一个channel中没有执行任务时,可以去执行其他channel中的任务。适合连接数多,但流量较少的场景
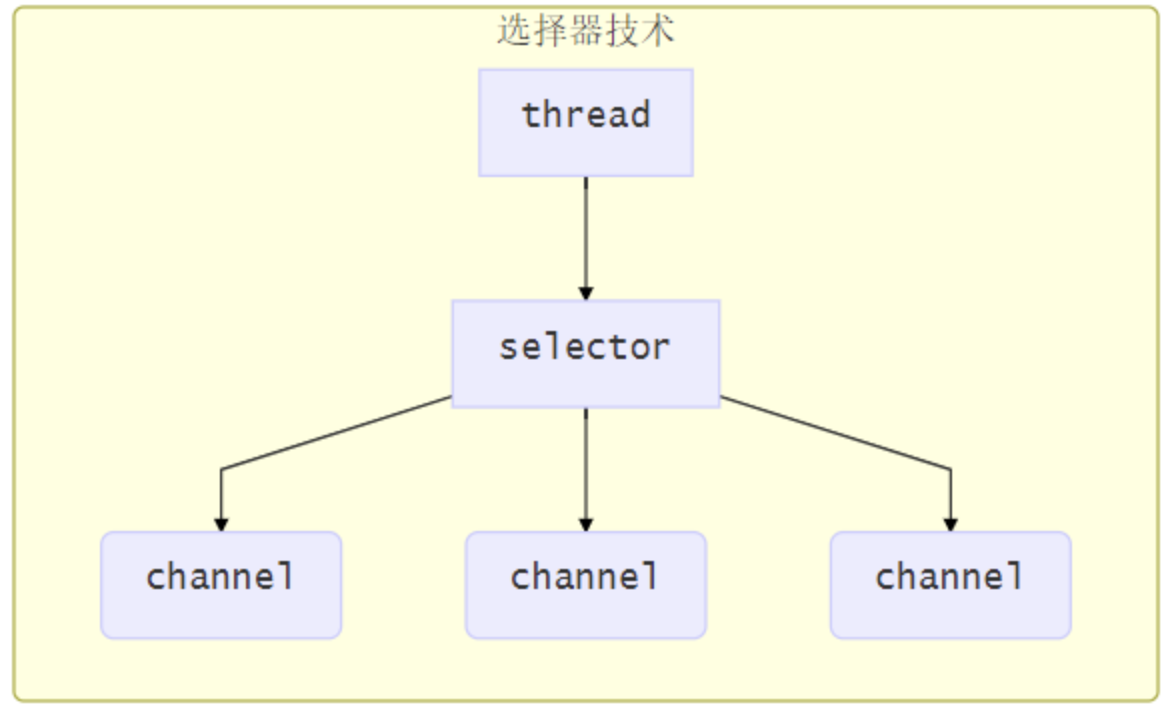
若事件未就绪,调用 selector 的 select() 方法会阻塞线程,直到 channel 发生了就绪事件。这些事件就绪后,select 方法就会返回这些事件交给 thread 来处理
简单地说:选择器的使命是完成IO的多路复用,其主要工作是通道的注册、监听、事 件查询。一个通道代表一条连接通路,通过选择器可以同时监控多个通道的IO(输入输出) 状况。选择器和通道的关系,是监控和被监控的关系。
选择器提供了独特的API方法,能够选出(select)所监控的通道已经发生了哪些IO事件, 包括读写就绪的IO操作事件。
在NIO编程中,一般是一个单线程处理一个选择器,一个选择器可以监控很多通道。所 以,通过选择器,一个单线程可以处理数百、数千、数万、甚至更多的通道。在极端情况下 (数万个连接),只用一个线程就可以处理所有的通道,这样会大量地减少线程之间上下文切换的开销。
通道和选择器之间的关联,通过register(注册)的方式完成。调用通道的Channel.register (Selector sel,int ops)方法,可以将通道实例注册到一个选择器中。register方法有两个参数:第一个参数,指定通道注册到的选择器实例;第二个参数,指定选择器要监控的IO事件类型。
可供选择器监控的通道IO事件类型,包括以下四种:
- 可读:
SelectionKey.OP_READ - 可写:
SelectionKey.OP_WRITE - 连接:
SelectionKey.OP_CONNECT - 接收:
SelectionKey.OP_ACCEPT
//监控通道的多种事件,用“按位或”运算符来实现
int key = SelectionKey.OP_READ | SelectionKey.OP_WRITE ;什么是IO事件呢?
这里的IO事件不是对通道的IO操作,而是通道处于某个IO操作的就绪状态,表示通道具备执行某个IO操作的条件。比方说某个 SocketChannel传输通道,如果完成了和对端的三次握手过程,则会发生“连接就绪” (OP_CONNECT)的事件。再比方说某个ServerSocketChannel服务器连接监听通道,在监听到一个新连接的到来时,则会发生“接收就绪”(OP_ACCEPT)的事件。还比方说,一 个SocketChannel通道有数据可读,则会发生“读就绪”(OP_READ)事件;一个等待写入 数据的SocketChannel通道,会发生写就绪(OP_WRITE)事件。
SelectableChannel可选择通道
并不是所有的通道,都是可以被选择器监控或选择的。比方说,FileChannel文件通道就不能被选择器复用。判断一个通道能否被选择器监控或选择,有一个前提:判断它是否继承了抽象类SelectableChannel(可选择通道),如果是则可以被选择,否则不能。
简单地说,一条通道若能被选择,必须继承SelectableChannel类。
SelectableChannel类,是何方神圣呢?它提供了实现通道的可选择性所需要的公共方法。 Java NIO中所有网络链接Socket套接字通道,都继承了SelectableChannel类,都是可选择的。 而FileChannel文件通道,并没有继承SelectableChannel,因此不是可选择通道。
SelectionKey选择键
通道和选择器的监控关系,本质是一种多对一的关联关系。这种关联关系,非常类似于数据库两个主表之间的关联关系,通道(Channel)和选择器(Selector)类似于数据库的主表,而选择键(SelectionKey)就类似于关联表,具体如下图所示:
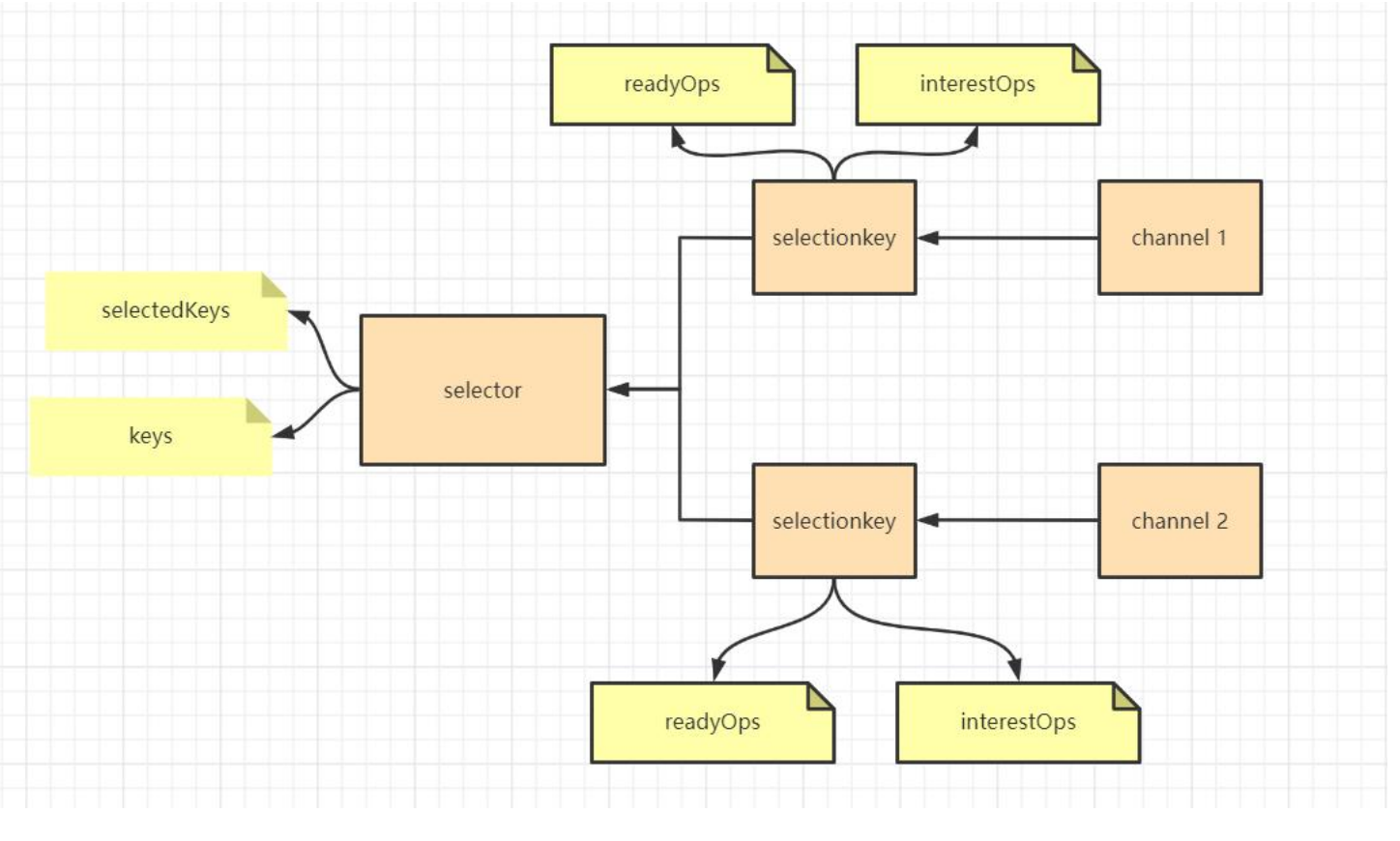
Selector并不直接去管理Channel,而是直接管理SelectionKey,通过SelectionKey与 Channel发生关系。
Java NIO源码中规定了,一个Channel最多能向Selector注册一次,注册之后就形成了唯一的SelectionKey,然后被Selector管理起来。Selector有一个核心成员keys, 专门用于管理注册上来的SelectionKey,Channel注册到Selector后所创建的那一个唯一的 SelectionKey,添加在这个keys成员中,这是一个HashSet类型的集合。除了成员keys之外, Selector还有一个核心成员selectedKeys,用于存放已经发生了IO事件的SelectionKey。
除了弄清SelectionKey和Channel、Selector之间的三角关系之后,还有一个核心问题,就是 SelectionKey和IO事件之间的关系。
际上,SelectionKey是IO事件的记录者(或存储者),SelectionKey 有两个核心成员, 存储着自己关联的Channel上的感兴趣IO事件和已经发生的IO事件。这两个核心成员定义在实现类SelectionKeyImpl中,代码如下:
public class SelectionKeyImpl extends AbstractSelectionKey {
final SelChImpl channel; // 关联的 Channel
public final SelectorImpl selector; // 关联的 选择键
// Index for a pollfd array in Selector that this key is registered with
private int index;
private volatile int interestOps; // 关联的 Channel 上的感兴趣 IO 事件
private int readyOps; // /已经发生的 IO 事件, 来自关联的 Channel
}Channel通道上可以发生多种IO事件,比如说读就绪事件、写就绪事件、新连接就绪事 件,但是SelectionKey记录事件的成员却是一个整数类型。这样问题就来了,一个整数如何记录多个事件呢?答案是,通过比特位来完成的。具体的IO事件所占用的哪一个比特位, 通过常量的方式定义在SelectionKey中
public static final int OP_ACCEPT = 1 << 4;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_WRITE = 1 << 2;
public static final int OP_READ = 1 << 0;通过SelectionKey的interestOps成员上相应的比特位,可以设置、查询关联的Channel所感兴趣的IO事件;通过SelectionKey的readyOps上相应的比特位,可以查询关联Channel所已经发生的IO事件。对于interestOps成员上的比特位,应用程序是可以设置的;但是对于 readyOps上的比特位,应用程序只能查询,不能设置。为啥呢?readyOps上的比特位代表了 已经发生的IO事件,是由选择器Selector去设置的,应用程序只能获取。
通道和选择器的监控关系注册成功后,Selector就可以查询就绪事件。具体的查询操作, 是通过调用选择器Selector的select( )系列方法来完成。通过select系列方法,选择器会通过JNI, 去进行底层操作系统的系统调用(比如select/epoll),可以不断地查询通道中所发生操作的就绪状态(或者IO事件),并且把这些发生了底层IO事件,转换成Java NIO中的IO事件,记录在的通道关联的SelectionKey的readyOps上。除此之外,发生了IO事件的选择键,还会记 录在Selector内部selectedKeys集合中。
简单来说,一旦在通道中发生了某些IO事件(就绪状态达成), 这个事件就被记录在SelectionKey的readyOps上,并且这个SelectionKey被记录在Selector内部 的selectedKeys集合中。当然,这里有两个前提 :
- 通道必须在Selector注册过;
- 所发生的事件必须是
SelectionKey上interestOps成员记录的事件。
选择器使用流程
- 获取选择器实例;
- 将通道注册到选择器中;
- 轮询感兴趣的IO就绪事件(选择键集合)。
第一步:选择器实例是通过调用静态工厂方法open()来获取的,Selector选择器的类方法open( )的内部,是向选择器SPI(SelectorProvider)发出请求, 通过默认的SelectorProvider(选择器提供者)对象,获取一个新的选择器实例。Java中SPI 全称为(Service Provider Interface,服务提供者接口),是JDK的一种可以扩展的服务提供 和发现机制。Java通过SPI的方式,提供选择器的默认实现版本。也就是说,其他的服务提 供商可以通过SPI的方式,提供定制化版本的选择器的动态替换或者扩展。
第二步:将通道注册到选择器实例。要实现选择器管理通道,需要将通道注册到相应的 选择器上,
上面通过调用通道的register(…)方法,将ServerSocketChannel通道注册到了一个选择器上。当然,在注册之前,首先需要准备好通道。
这里需要注意:注册到选择器的通道,必须处于非阻塞模式下,否则将抛出 IllegalBlockingModeException异常。这意味着,FileChannel文件通道不能与选择器一起使用, 因为FileChannel文件通道只有阻塞模式,不能切换到非阻塞模式;而Socket套接字相关的所有通道都可以。
其次,还需要注意:一个通道,并不一定要支持所有的四种IO事件。例如服务器监听 通道ServerSocketChannel,仅仅支持Accept(接收到新连接)IO事件;而传输通道 SocketChannel则不同,该类型通道不支持Accept类型的IO事件。
可以在注册之前,可以通过通道的validOps()方法,来获取该通道所有支持的IO事件集合。
第三步:选出感兴趣的IO就绪事件(选择键集合)。通过Selector选择器的select()方法,选出已经注册的、已经就绪的IO事件,并且保存到SelectionKey选择键集合中。SelectionKey 集合保存在选择器实例内部,其元素为SelectionKey类型实例。调用选择器的selectedKeys() 方法,可以取得选择键集合。 接下来,需要迭代集合的每一个选择键,根据具体IO事件类型
// 调用静态工厂方法 open()来获取 Selector 实例
Selector selector = Selector.open();
// 获取通道
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 设置为非阻塞
serverSocketChannel.configureBlocking(false);
// 绑定连接
serverSocketChannel.bind(new InetSocketAddress(18899));
// 将通道注册到选择器上,并制定监听事件为:“接收连接”事件
serverSocketChannel.register(selector,SelectionKey.OP_ACCEPT);
// 轮询,选择感兴趣的 IO 就绪事件(选择键集合)
while (selector.select() > 0) {
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
//根据具体的 IO 事件类型,执行对应的业务操作
if(key.isAcceptable()) {
// IO 事件:ServerSocketChannel 服务器监听通道有新连接
} else if (key.isConnectable()) {
// IO 事件:传输通道连接成功
} else if (key.isReadable()) {
// IO 事件:传输通道可读
} else if (key.isWritable()) {
// IO 事件:传输通道可写
}
//处理完成后,移除选择键 keyIterator.remove();
}
}处理完成后,需要将选择键从这个SelectionKey集合中移除,防止下一次循环的时候, 被重复的处理。SelectionKey集合不能添加元素,如果试图向SelectionKey选择键集合中添加 元素,则将抛出java.lang.UnsupportedOperationException异常。
用于选择就绪的IO事件的select()方法,有多个重载的实现版本,具体如下:
- select():阻塞调用,一直到至少有一个通道发生了注册的IO事件。
- select(long timeout):和select()一样,但最长阻塞时间为timeout指定的毫秒数。
- selectNow():非阻塞,不管有没有IO事件,都会立刻返回。
select()方法的返回值的是整数类型(int),表示发生了IO事件的数量。更准确地说,是从上一次select到这一次select之间,有多少通道发生了IO事件,更加准确地说,是指发生了选择器感兴趣(注册过)的IO事件数。
ByteBuffer
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- flip会使得buffer中的limit变为position,position变为0
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或者compact()切换至写模式
- 调用clear()方法时position=0,limit变为capacity
- 调用compact()方法时,会将缓冲区中的未读数据压缩到缓冲区前面
- 重复以上步骤
使用ByteBuffer读取文件中的内容
public class TestByteBuffer {
public static void main(String[] args) {
// 获得FileChannel
try (FileChannel channel = new FileInputStream("/Users/xxxx/Me/IDEA/enmalvi/Netty-Test/stu.txt").getChannel()) {
// 获得缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
int hasNext = 0;
StringBuilder builder = new StringBuilder();
while((hasNext = channel.read(buffer)) > 0) {
// 切换模式 limit=position, position=0
buffer.flip();
// 当buffer中还有数据时,获取其中的数据
while(buffer.hasRemaining()) {
builder.append((char)buffer.get());
}
// 切换模式 position=0, limit=capacity
buffer.clear();
}
System.out.println(builder.toString());
} catch (IOException e) {
}
}
}打印结果
"asdasdasd"
"asdasdasd"核心属性
字节缓冲区的父类Buffer中有几个核心属性,如下
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;- capacity:缓冲区的容量。通过构造函数赋予,一旦设置,无法更改
- limit:缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量
- position:下一个读写位置的索引(类似PC)。缓冲区的位置不能为负,并且不能大于limit
- mark:记录当前position的值。position被改变后,可以通过调用reset() 方法恢复到mark的位置。
以上四个属性必须满足以下要求
mark <= position <= limit <= capacity
核心方法
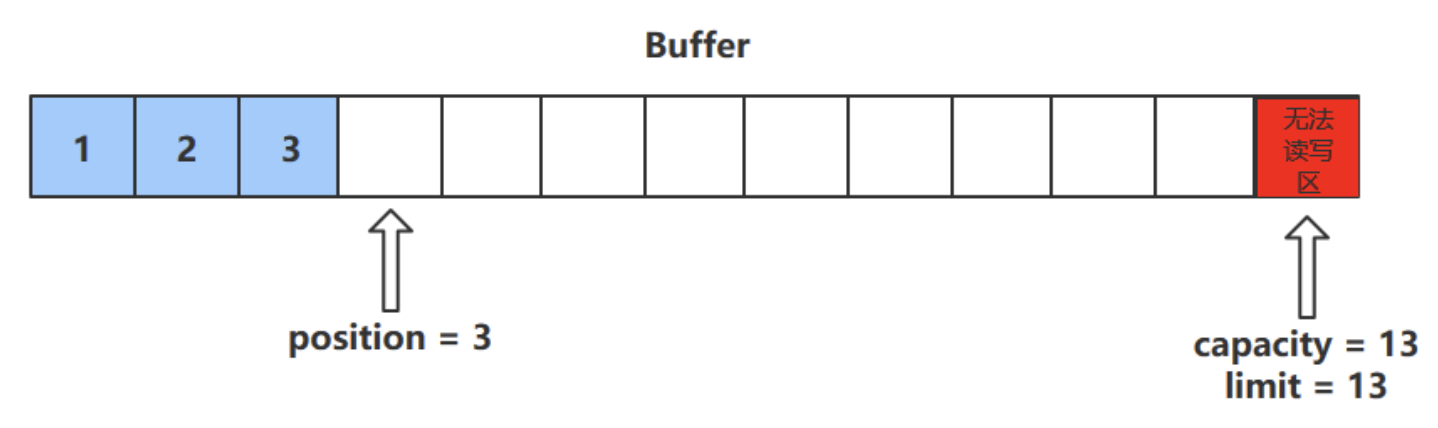
put()方法
- put()方法可以将一个数据放入到缓冲区中。
- 进行该操作后,postition的值会+1,指向下一个可以放入的位置。capacity = limit ,为缓冲区容量的值。
flip()方法
- flip()方法会切换对缓冲区的操作模式,由写->读 / 读->写
- 进行该操作后
- 如果是写模式->读模式,position = 0 , limit 指向最后一个元素的下一个位置,capacity不变
- 如果是读->写,则恢复为put()方法中的值
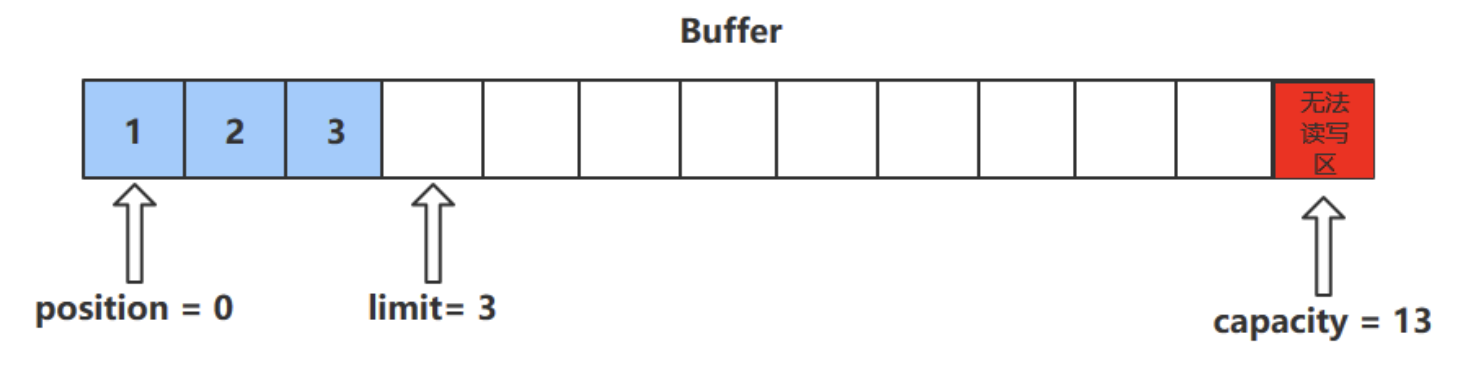
get()方法
- get()方法会读取缓冲区中的一个值
- 进行该操作后,position会+1,如果超过了limit则会抛出异常
- 注意:get(i)方法不会改变position的值
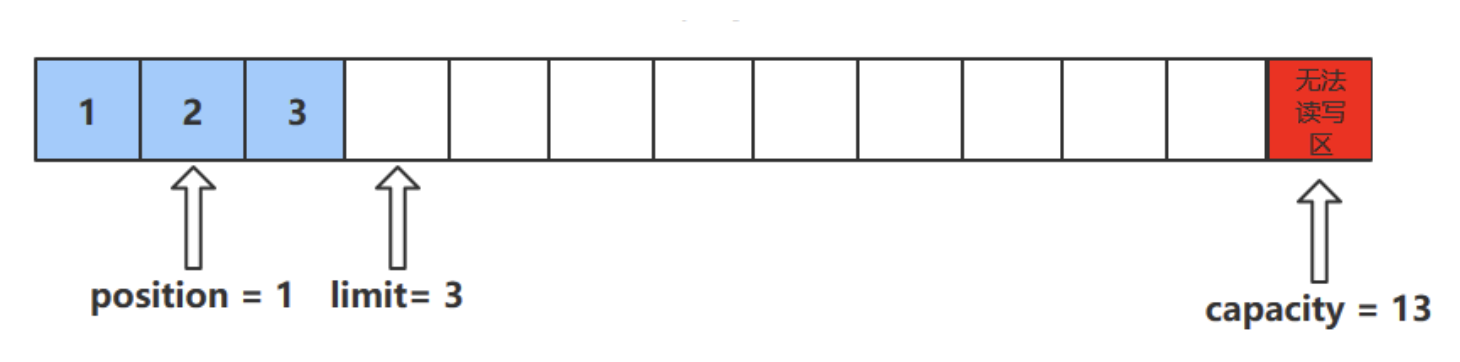
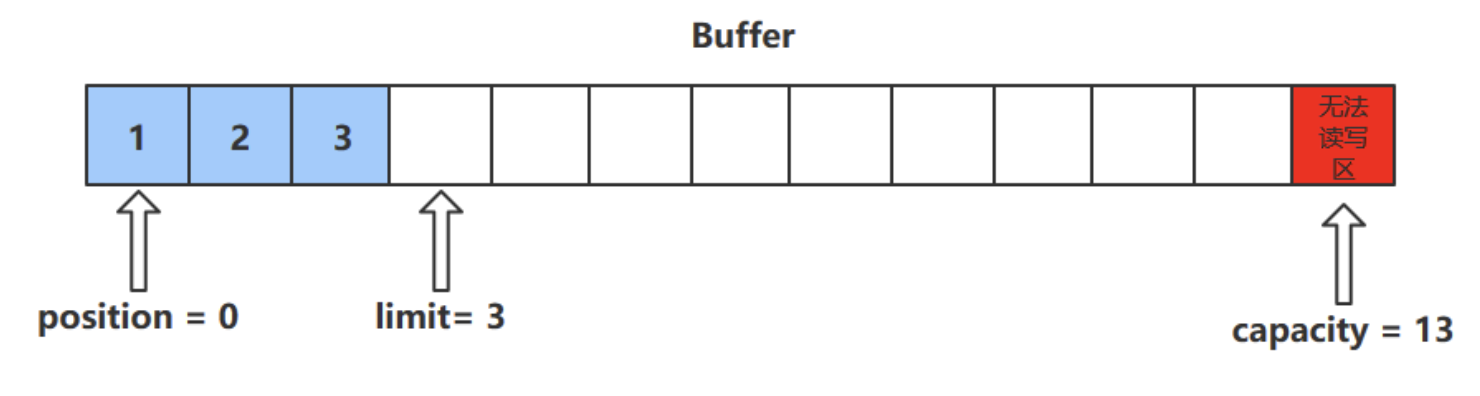
rewind()方法
- 该方法只能在读模式下使用
- rewind()方法后,会恢复position、limit和capacity的值,变为进行get()前的值
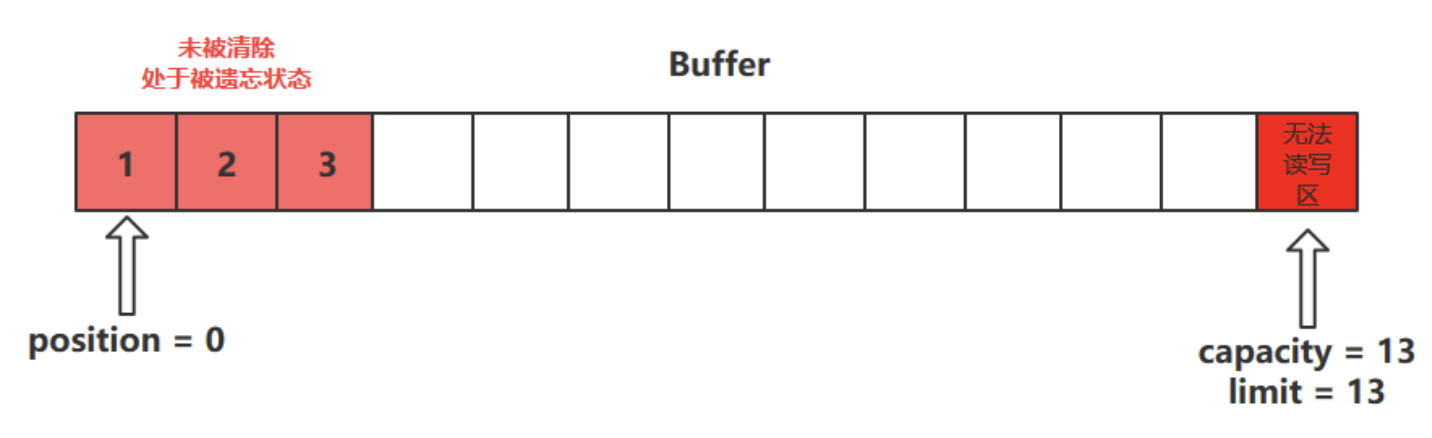
clean()方法
- clean()方法会将缓冲区中的各个属性恢复为最初的状态,position = 0, capacity = limit
- 此时缓冲区的数据依然存在,处于“被遗忘”状态,下次进行写操作时会覆盖这些数据
mark()和reset()方法
- mark()方法会将postion的值保存到mark属性中
- reset()方法会将position的值改为mark中保存的值
compact()方法
此方法为ByteBuffer的方法,而不是Buffer的方法
- compact会把未读完的数据向前压缩,然后切换到写模式
- 数据前移后,原位置的值并未清零,写时会覆盖之前的值
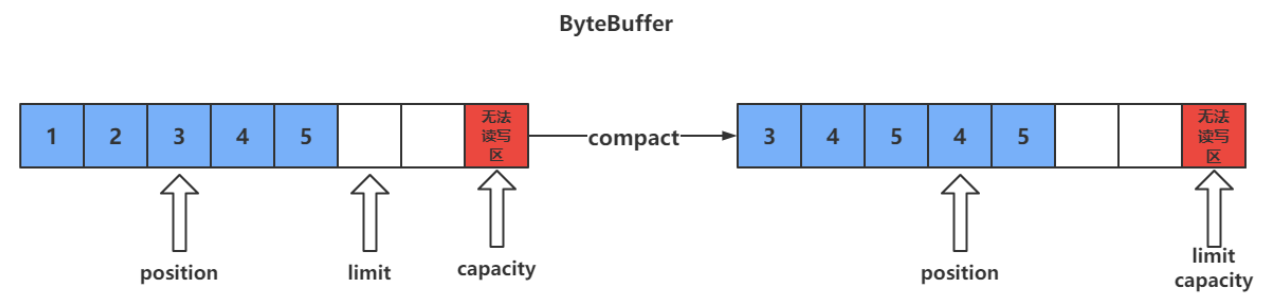
clear() VS compact()
clear只是对position、limit、mark进行重置,而compact在对position进行设置,以及limit、mark进行重置的同时,还涉及到数据在内存中拷贝(会调用arraycopy)。所以compact比clear更耗性能。但compact能保存你未读取的数据,将新数据追加到为读取的数据之后;而clear则不行,若你调用了clear,则未读取的数据就无法再读取到了
所以需要根据情况来判断使用哪种方法进行模式切换
ByteBuffer调试工具类
需要先导入netty依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.51.Final</version>
</dependency>public class ByteBufferUtil {
private static final char[] BYTE2CHAR = new char[256];
private static final char[] HEXDUMP_TABLE = new char[256 * 4];
private static final String[] HEXPADDING = new String[16];
private static final String[] HEXDUMP_ROWPREFIXES = new String[65536 >>> 4];
private static final String[] BYTE2HEX = new String[256];
private static final String[] BYTEPADDING = new String[16];
static {
final char[] DIGITS = "0123456789abcdef".toCharArray();
for (int i = 0; i < 256; i++) {
HEXDUMP_TABLE[i << 1] = DIGITS[i >>> 4 & 0x0F];
HEXDUMP_TABLE[(i << 1) + 1] = DIGITS[i & 0x0F];
}
int i;
// Generate the lookup table for hex dump paddings
for (i = 0; i < HEXPADDING.length; i++) {
int padding = HEXPADDING.length - i;
StringBuilder buf = new StringBuilder(padding * 3);
for (int j = 0; j < padding; j++) {
buf.append(" ");
}
HEXPADDING[i] = buf.toString();
}
// Generate the lookup table for the start-offset header in each row (up to 64KiB).
for (i = 0; i < HEXDUMP_ROWPREFIXES.length; i++) {
StringBuilder buf = new StringBuilder(12);
buf.append(StringUtil.NEWLINE);
buf.append(Long.toHexString(i << 4 & 0xFFFFFFFFL | 0x100000000L));
buf.setCharAt(buf.length() - 9, '|');
buf.append('|');
HEXDUMP_ROWPREFIXES[i] = buf.toString();
}
// Generate the lookup table for byte-to-hex-dump conversion
for (i = 0; i < BYTE2HEX.length; i++) {
BYTE2HEX[i] = ' ' + StringUtil.byteToHexStringPadded(i);
}
// Generate the lookup table for byte dump paddings
for (i = 0; i < BYTEPADDING.length; i++) {
int padding = BYTEPADDING.length - i;
StringBuilder buf = new StringBuilder(padding);
for (int j = 0; j < padding; j++) {
buf.append(' ');
}
BYTEPADDING[i] = buf.toString();
}
// Generate the lookup table for byte-to-char conversion
for (i = 0; i < BYTE2CHAR.length; i++) {
if (i <= 0x1f || i >= 0x7f) {
BYTE2CHAR[i] = '.';
} else {
BYTE2CHAR[i] = (char) i;
}
}
}
/**
* 打印所有内容
* @param buffer
*/
public static void debugAll(ByteBuffer buffer) {
int oldlimit = buffer.limit();
buffer.limit(buffer.capacity());
StringBuilder origin = new StringBuilder(256);
appendPrettyHexDump(origin, buffer, 0, buffer.capacity());
System.out.println("+--------+-------------------- all ------------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), oldlimit);
System.out.println(origin);
buffer.limit(oldlimit);
}
/**
* 打印可读取内容
* @param buffer
*/
public static void debugRead(ByteBuffer buffer) {
StringBuilder builder = new StringBuilder(256);
appendPrettyHexDump(builder, buffer, buffer.position(), buffer.limit() - buffer.position());
System.out.println("+--------+-------------------- read -----------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), buffer.limit());
System.out.println(builder);
}
private static void appendPrettyHexDump(StringBuilder dump, ByteBuffer buf, int offset, int length) {
if (MathUtil.isOutOfBounds(offset, length, buf.capacity())) {
throw new IndexOutOfBoundsException(
"expected: " + "0 <= offset(" + offset + ") <= offset + length(" + length
+ ") <= " + "buf.capacity(" + buf.capacity() + ')');
}
if (length == 0) {
return;
}
dump.append(
" +-------------------------------------------------+" +
StringUtil.NEWLINE + " | 0 1 2 3 4 5 6 7 8 9 a b c d e f |" +
StringUtil.NEWLINE + "+--------+-------------------------------------------------+----------------+");
final int startIndex = offset;
final int fullRows = length >>> 4;
final int remainder = length & 0xF;
// Dump the rows which have 16 bytes.
for (int row = 0; row < fullRows; row++) {
int rowStartIndex = (row << 4) + startIndex;
// Per-row prefix.
appendHexDumpRowPrefix(dump, row, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + 16;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(" |");
// ASCII dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append('|');
}
// Dump the last row which has less than 16 bytes.
if (remainder != 0) {
int rowStartIndex = (fullRows << 4) + startIndex;
appendHexDumpRowPrefix(dump, fullRows, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + remainder;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(HEXPADDING[remainder]);
dump.append(" |");
// Ascii dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append(BYTEPADDING[remainder]);
dump.append('|');
}
dump.append(StringUtil.NEWLINE +
"+--------+-------------------------------------------------+----------------+");
}
private static void appendHexDumpRowPrefix(StringBuilder dump, int row, int rowStartIndex) {
if (row < HEXDUMP_ROWPREFIXES.length) {
dump.append(HEXDUMP_ROWPREFIXES[row]);
} else {
dump.append(StringUtil.NEWLINE);
dump.append(Long.toHexString(rowStartIndex & 0xFFFFFFFFL | 0x100000000L));
dump.setCharAt(dump.length() - 9, '|');
dump.append('|');
}
}
public static short getUnsignedByte(ByteBuffer buffer, int index) {
return (short) (buffer.get(index) & 0xFF);
}
}调用ByteBuffer的方法
public class TestByteBuffer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向buffer中写入1个字节的数据
buffer.put((byte)97);
// 使用工具类,查看buffer状态
ByteBufferUtil.debugAll(buffer);
// 向buffer中写入4个字节的数据
buffer.put(new byte[]{98, 99, 100, 101});
ByteBufferUtil.debugAll(buffer);
// 获取数据
buffer.flip();
ByteBufferUtil.debugAll(buffer);
System.out.println(buffer.get());
System.out.println(buffer.get());
ByteBufferUtil.debugAll(buffer);
// 使用compact切换模式
buffer.compact();
ByteBufferUtil.debugAll(buffer);
// 再次写入
buffer.put((byte)102);
buffer.put((byte)103);
ByteBufferUtil.debugAll(buffer);
}
}
打印结果
// 向缓冲区写入了一个字节的数据,此时postition为1
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 00 00 00 00 00 00 00 00 00 |a......... |
+--------+-------------------------------------------------+----------------+
// 向缓冲区写入四个字节的数据,此时position为5
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 调用flip切换模式,此时position为0,表示从第0个数据开始读取
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 读取两个字节的数据
97
98
// position变为2
+--------+-------------------- all ------------------------+----------------+
position: [2], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 65 00 00 00 00 00 |abcde..... |
+--------+-------------------------------------------------+----------------+
// 调用compact切换模式,此时position及其后面的数据被压缩到ByteBuffer前面去了
// 此时position为3,会覆盖之前的数据
+--------+-------------------- all ------------------------+----------------+
position: [3], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 63 64 65 64 65 00 00 00 00 00 |cdede..... |
+--------+-------------------------------------------------+----------------+
// 再次写入两个字节的数据,之前的 0x64 0x65 被覆盖
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 63 64 65 66 67 00 00 00 00 00 |cdefg..... |
+--------+-------------------------------------------------+----------------+字符串与ByteBuffer的相互转换
方法一
编码:字符串调用getByte方法获得byte数组,将byte数组放入ByteBuffer中
解码:先调用ByteBuffer的flip方法,然后通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
String str2 = "";
ByteBuffer buffer1 = ByteBuffer.allocate(16);
// 通过字符串的getByte方法获得字节数组,放入缓冲区中
buffer1.put(str1.getBytes());
ByteBufferUtil.debugAll(buffer1);
// 将缓冲区中的数据转化为字符串
// 切换模式
buffer1.flip();
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
ByteBufferUtil.debugAll(buffer1);
}
}打印结果
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [16]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00 |hello...........|
+--------+-------------------------------------------------+----------------+
hello
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00 |hello...........|
+--------+-------------------------------------------------+----------------+方法二
编码:通过StandardCharsets的encode方法获得ByteBuffer,此时获得的ByteBuffer为读模式,无需通过flip切换模式
解码:通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
String str2 = "";
// 通过StandardCharsets的encode方法获得ByteBuffer
// 此时获得的ByteBuffer为读模式,无需通过flip切换模式
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode(str1);
ByteBufferUtil.debugAll(buffer1);
// 将缓冲区中的数据转化为字符串
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
ByteBufferUtil.debugAll(buffer1);
}
}打印结果
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+
hello
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+方法三
编码:字符串调用getByte()方法获得字节数组,将字节数组传给ByteBuffer的wrap()方法,通过该方法获得ByteBuffer。同样无需调用flip方法切换为读模式
解码:通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
String str2 = "";
// 通过StandardCharsets的encode方法获得ByteBuffer
// 此时获得的ByteBuffer为读模式,无需通过flip切换模式
ByteBuffer buffer1 = ByteBuffer.wrap(str1.getBytes());
ByteBufferUtil.debugAll(buffer1);
// 将缓冲区中的数据转化为字符串
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
ByteBufferUtil.debugAll(buffer1);
}
}打印结果
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+
hello
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+粘包与半包
现象
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为
- Hello,world\n
- I’m Nyima\n
- How are you?\n
变成了下面的两个 byteBuffer (粘包,半包)
- Hello,world\nI’m Nyima\nHo
- w are you?\n
出现原因
粘包
发送方在发送数据时,并不是一条一条地发送数据,而是将数据整合在一起,当数据达到一定的数量后再一起发送。这就会导致多条信息被放在一个缓冲区中被一起发送出去
半包
接收方的缓冲区的大小是有限的,当接收方的缓冲区满了以后,就需要将信息截断,等缓冲区空了以后再继续放入数据。这就会发生一段完整的数据最后被截断的现象
解决办法—按分隔符拆分
- 通过get(index)方法遍历ByteBuffer,遇到分隔符时进行处理。注意:get(index)不会改变position的值
- 记录该段数据长度,以便于申请对应大小的缓冲区
- 将缓冲区的数据通过get()方法写入到target中
- 调用compact方法切换模式,因为缓冲区中可能还有未读的数据
public class ByteBufferDemo {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(32);
// 模拟粘包+半包
buffer.put("Hello,world\nI'm Nyima\nHo".getBytes());
// 调用split函数处理
split(buffer);
buffer.put("w are you?\n".getBytes());
split(buffer);
}
private static void split(ByteBuffer buffer) {
// 切换为读模式
buffer.flip();
for(int i = 0; i < buffer.limit(); i++) {
// 遍历寻找分隔符
// get(i)不会移动position
if (buffer.get(i) == '\n') {
// 缓冲区长度
int length = i+1-buffer.position();
ByteBuffer target = ByteBuffer.allocate(length);
// 将前面的内容写入target缓冲区
for(int j = 0; j < length; j++) {
// 将buffer中的数据写入target中
target.put(buffer.get());
}
// 打印查看结果
ByteBufferUtil.debugAll(target);
}
}
// 切换为写模式,但是缓冲区可能未读完,这里需要使用compact
buffer.compact();
}
}打印结果
+--------+-------------------- all ------------------------+----------------+
position: [12], limit: [12]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 65 6c 6c 6f 2c 77 6f 72 6c 64 0a |Hello,world. |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [10], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 49 27 6d 20 4e 79 69 6d 61 0a |I'm Nyima. |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [13], limit: [13]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 6f 77 20 61 72 65 20 79 6f 75 3f 0a |How are you?. |
+--------+-------------------------------------------------+----------------+文件编程
FileChannel
工作模式
FileChannel只能在阻塞模式下工作,所以无法搭配Selector
获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法
- 通过
FileInputStream获取的channel只能读 - 通过
FileOutputStream获取的channel只能写 - 通过
RandomAccessFile是否能读写根据构造RandomAccessFile时的读写模式决定
读取
通过 FileInputStream 获取channel,通过read方法将数据写入到ByteBuffer中
read方法的返回值表示读到了多少字节,若读到了文件末尾则返回-1
int readBytes = channel.read(buffer);可根据返回值判断是否读取完毕
while(channel.read(buffer) > 0) {
// 进行对应操作
...
}写入
因为channel也是有大小的,所以 write 方法并不能保证一次将 buffer 中的内容全部写入 channel。必须需要按照以下规则进行写入
// 通过hasRemaining()方法查看缓冲区中是否还有数据未写入到通道中
while(buffer.hasRemaining()) {
channel.write(buffer);
}关闭
通道需要close,一般情况通过try-with-resource进行关闭,最好使用以下方法获取strea以及channel,避免某些原因使得资源未被关闭
public class TestChannel {
public static void main(String[] args) throws IOException {
try (FileInputStream fis = new FileInputStream("stu.txt");
FileOutputStream fos = new FileOutputStream("student.txt");
FileChannel inputChannel = fis.getChannel();
FileChannel outputChannel = fos.getChannel()) {
// 执行对应操作
...
}
}
}位置
position
channel也拥有一个保存读取数据位置的属性,即position
long pos = channel.position();可以通过position(int pos)设置channel中position的值
long newPos = ...;
channel.position(newPos);设置当前位置时,如果设置为文件的末尾
- 这时读取会返回 -1
- 这时写入,会追加内容,但要注意如果 position 超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00)
强制写入
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘,而是等到缓存满了以后将所有数据一次性的写入磁盘。可以调用 force(true) 方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘
两个Channel传输数据
transferTo方法
使用transferTo方法可以快速、高效地将一个channel中的数据传输到另一个channel中,但一次只能传输2G的内容
transferTo底层使用了零拷贝技术
public class TestChannel {
public static void main(String[] args){
try (FileInputStream fis = new FileInputStream("enm.txt");
FileOutputStream fos = new FileOutputStream("why.txt");
FileChannel inputChannel = fis.getChannel();
FileChannel outputChannel = fos.getChannel()) {
// 参数:inputChannel的起始位置,传输数据的大小,目的channel
// 返回值为传输的数据的字节数
// transferTo一次只能传输2G的数据
inputChannel.transferTo(0, inputChannel.size(), outputChannel);
} catch (IOException e) {
e.printStackTrace();
}
}
}当传输的文件大于2G时,需要使用以下方法进行多次传输
public class TestChannel {
public static void main(String[] args){
try (FileInputStream fis = new FileInputStream("enm.txt");
FileOutputStream fos = new FileOutputStream("why.txt");
FileChannel inputChannel = fis.getChannel();
FileChannel outputChannel = fos.getChannel()) {
long size = inputChannel.size();
long capacity = inputChannel.size();
// 分多次传输
while (capacity > 0) {
// transferTo返回值为传输了的字节数
capacity -= inputChannel.transferTo(size-capacity, capacity, outputChannel);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}文件传输案例
文件传输Client端
public class NioSendClient {
/**
* 构造函数
* 与服务器建立连接
*
* @throws Exception
*/
public NioSendClient() {
}
private Charset charset = Charset.forName("UTF-8");
/**
* 向服务端传输文件
*
* @throws Exception
*/
public void sendFile() {
try {
//发送小文件
String srcPath = NioDemoConfig.SOCKET_SEND_FILE;
//发送一个大的
// String srcPath = NioDemoConfig.SOCKET_SEND_BIG_FILE;
File file = new File(srcPath);
if (!file.exists()) {
srcPath = IOUtil.getResourcePath(srcPath);
Logger.debug("srcPath=" + srcPath);
file = new File(srcPath);
if (!file.exists()) {
Logger.debug("文件不存在");
return;
}
}
FileChannel fileChannel = new FileInputStream(file).getChannel();
SocketChannel socketChannel = SocketChannel.open();
socketChannel.setOption(StandardSocketOptions.TCP_NODELAY, true);
socketChannel.socket().connect(
new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_IP
, NioDemoConfig.SOCKET_SERVER_PORT));
socketChannel.configureBlocking(false);
Logger.debug("Client 成功连接服务端");
while (!socketChannel.finishConnect()) {
//不断的自旋、等待,或者做一些其他的事情
}
//发送文件名称
ByteBuffer fileNameByteBuffer = charset.encode(file.getName());
ByteBuffer buffer = ByteBuffer.allocate(NioDemoConfig.SEND_BUFFER_SIZE);
// ByteBuffer buffer = ByteBuffer.allocateDirect(NioDemoConfig.SEND_BUFFER_SIZE);
//发送文件名称长度
// int fileNameLen = fileNameByteBuffer.capacity();
//
int fileNameLen = fileNameByteBuffer.remaining();
buffer.clear();
buffer.putInt(fileNameLen);
//切换到读模式
buffer.flip();
socketChannel.write(buffer);
Logger.info("Client 文件名称长度发送完成:", fileNameLen);
// 发送文件名称
socketChannel.write(fileNameByteBuffer);
Logger.info("Client 文件名称发送完成:", file.getName());
//发送文件长度
//清空
buffer.clear();
buffer.putInt((int) file.length());
//切换到读模式
buffer.flip();
//写入文件长度
socketChannel.write(buffer);
Logger.info("Client 文件长度发送完成:", file.length());
//发送文件内容
Logger.debug("开始传输文件");
int length = 0;
long offset = 0;
buffer.clear();
while ((length = fileChannel.read(buffer)) > 0) {
buffer.flip();
socketChannel.write(buffer);
offset += length;
Logger.debug("| " + (100 * offset / file.length()) + "% |");
buffer.clear();
}
//等待一分钟关闭连接
ThreadUtil.sleepSeconds(60);
if (length == -1) {
IOUtil.closeQuietly(fileChannel);
socketChannel.shutdownOutput();
IOUtil.closeQuietly(socketChannel);
}
Logger.debug("======== 文件传输成功 ========");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 入口
*
* @param args
*/
public static void main(String[] args) {
NioSendClient client = new NioSendClient(); // 启动客户端连接
client.sendFile(); // 传输文件
}
}
文件传输Server端
public class NioReceiveServer {
//接受文件路径
private static final String RECEIVE_PATH = NioDemoConfig.SOCKET_RECEIVE_PATH;
private Charset charset = Charset.forName("UTF-8");
/**
* 服务器端保存的客户端对象,对应一个客户端文件
*/
static class Session {
int step = 1; //1 读取文件名称的长度,2 读取文件名称 ,3 ,读取文件内容的长度, 4 读取文件内容
//文件名称
String fileName = null;
//长度
long fileLength;
int fileNameLength;
//开始传输的时间
long startTime;
//客户端的地址
InetSocketAddress remoteAddress;
//输出的文件通道
FileChannel fileChannel;
//接收长度
long receiveLength;
public boolean isFinished() {
return receiveLength >= fileLength;
}
}
private ByteBuffer buffer
= ByteBuffer.allocate(NioDemoConfig.SERVER_BUFFER_SIZE);
//使用Map保存每个客户端传输,当OP_READ通道可读时,根据channel找到对应的对象
Map<SelectableChannel, Session> clientMap = new HashMap<SelectableChannel, Session>();
public void startServer() throws IOException {
// 1、获取Selector选择器
Selector selector = Selector.open();
// 2、获取通道
ServerSocketChannel serverChannel = ServerSocketChannel.open();
ServerSocket serverSocket = serverChannel.socket();
// 3.设置为非阻塞
serverChannel.configureBlocking(false);
// 4、绑定连接
InetSocketAddress address
= new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_PORT);
serverSocket.bind(address);
// 5、将通道注册到选择器上,并注册的IO事件为:“接收新连接”
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
Logger.tcfo("serverChannel is linstening...");
// 6、轮询感兴趣的I/O就绪事件(选择键集合)
while (selector.select() > 0) {
if (null == selector.selectedKeys()) continue;
// 7、获取选择键集合
Iterator<SelectionKey> it = selector.selectedKeys().iterator();
while (it.hasNext()) {
// 8、获取单个的选择键,并处理
SelectionKey key = it.next();
if (null == key) continue;
// 9、判断key是具体的什么事件,是否为新连接事件
if (key.isAcceptable()) {
// 10、若接受的事件是“新连接”事件,就获取客户端新连接
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = server.accept();
if (socketChannel == null) continue;
// 11、客户端新连接,切换为非阻塞模式
socketChannel.configureBlocking(false);
socketChannel.setOption(StandardSocketOptions.TCP_NODELAY, true);
// 12、将客户端新连接通道注册到selector选择器上
SelectionKey selectionKey =
socketChannel.register(selector, SelectionKey.OP_READ);
// 余下为业务处理
Session session = new Session();
session.remoteAddress
= (InetSocketAddress) socketChannel.getRemoteAddress();
clientMap.put(socketChannel, session);
Logger.debug(socketChannel.getRemoteAddress() + "连接成功...");
} else if (key.isReadable()) {
handleData(key);
}
// NIO的特点只会累加,已选择的键的集合不会删除
// 如果不删除,下一次又会被select函数选中
it.remove();
}
}
}
/**
* 处理客户端传输过来的数据
*/
private void handleData(SelectionKey key) throws IOException {
SocketChannel socketChannel = (SocketChannel) key.channel();
int num = 0;
Session session = clientMap.get(key.channel());
buffer.clear();
while ((num = socketChannel.read(buffer)) > 0) {
Logger.cfo("收到的字节数 = " + num);
//切换到读模式
buffer.flip();
process(session, buffer);
buffer.clear();
// key.cancel();
}
}
// 非常抱歉,《netty zookeeper redis 高并发核心编程》 是08年08月出版的,3年了,当时候懒,没有解决文件传输的半包问题
// 传输文件的时候,经常出问题
// 很多小伙伴问我,怎么解决,我的答案都是: 半包问题,netty已经解决, nio的半包问题,不管也罢
// 一直到今天,2021.12.3
// 为了讲清楚 rocketmq, kakfa的 零复制, 才不得不来解决这个 nio 的半包问题
// 但是,比较复杂的,需要对nio 有比较熟练的使用 和深入的理解
// 下面的方案,只能说解决了80%
// 并没有完全解决, 但是,已经基本传输文件没有问题了
// 具体的解决过程,和解决的技巧,咱们 视频见
// 总之, nio 比较复杂,但是非常重要, 大家一定要从骨子里掌握
private void process(Session session, ByteBuffer buffer) {
while (len(buffer) > 0) { //客户端发送过来的,首先处理文件名长度
if (1 == session.step) {
int fileNameLengthByteLen = len(buffer);
System.out.println("读取文件名称长度之前,可读取的字节数 = " + fileNameLengthByteLen);
System.out.println("读取文件名称长度之前,buffer.remaining() = " + buffer.remaining());
System.out.println("读取文件名称长度之前,buffer.capacity() = " + buffer.capacity());
System.out.println("读取文件名称长度之前,buffer.limit() = " + buffer.limit());
System.out.println("读取文件名称长度之前,buffer.position() = " + buffer.position());
if (len(buffer) < 4) {
Logger.cfo("出现半包问题,需要更加复制的拆包方案");
throw new RuntimeException("出现半包问题,需要更加复制的拆包方案");
}
//获取文件名称长度
session.fileNameLength = buffer.getInt();
System.out.println("读取文件名称长度之后,buffer.remaining() = " + buffer.remaining());
System.out.println("读取文件名称长度 = " + session.fileNameLength);
session.step = 2;
} else if (2 == session.step) {
Logger.cfo("step 2");
if (len(buffer) < session.fileNameLength) {
Logger.cfo("出现半包问题,需要更加复制的拆包方案");
throw new RuntimeException("出现半包问题,需要更加复制的拆包方案");
}
byte[] fileNameBytes = new byte[session.fileNameLength];
//读取文件名称
buffer.get(fileNameBytes);
// 文件名
String fileName = new String(fileNameBytes, charset);
System.out.println("读取文件名称 = " + fileName);
File directory = new File(RECEIVE_PATH);
if (!directory.exists()) {
directory.mkdir();
}
Logger.info("NIO 传输目标dir:", directory);
session.fileName = fileName;
String fullName = directory.getAbsolutePath() + File.separatorChar + fileName;
Logger.info("NIO 传输目标文件:", fullName);
File file = new File(fullName.trim());
try {
if (!file.exists()) {
file.createNewFile();
}
FileChannel fileChannel = new FileOutputStream(file).getChannel();
session.fileChannel = fileChannel;
} catch (IOException e) {
e.printStackTrace();
}
session.step = 3;
} else if (3 == session.step) {
Logger.cfo("step 3");
//客户端发送过来的,首先处理文件内容长度
if (len(buffer) < 4) {
Logger.cfo("出现半包问题,需要更加复制的拆包方案");
throw new RuntimeException("出现半包问题,需要更加复制的拆包方案");
}
//获取文件内容长度
session.fileLength = buffer.getInt();
System.out.println("读取文件内容长度之后,buffer.remaining() = " + buffer.remaining());
System.out.println("读取文件内容长度 = " + session.fileLength);
session.step = 4;
session.startTime = System.currentTimeMillis();
} else if (4 == session.step) {
Logger.cfo("step 4");
//客户端发送过来的,最后是文件内容
session.receiveLength += len(buffer);
// 写入文件
try {
session.fileChannel.write(buffer);
} catch (IOException e) {
e.printStackTrace();
}
if (session.isFinished()) {
finished(session);
}
}
}
}
private void finished(Session session) {
IOUtil.closeQuietly(session.fileChannel);
Logger.info("上传完毕");
Logger.debug("文件接收成功,File Name:" + session.fileName);
Logger.debug(" Size:" + IOUtil.getFormatFileSize(session.fileLength));
long endTime = System.currentTimeMillis();
Logger.debug("NIO IO 传输毫秒数:" + (endTime - session.startTime));
}
/**
* 入口
*
* @param args
*/
public static void main(String[] args) throws Exception {
NioReceiveServer server = new NioReceiveServer();
server.startServer();
}
private static int len(ByteBuffer buffer) {
Logger.cfo(" >>> buffer left:" + buffer.remaining());
return buffer.remaining();
}
}零拷贝
零拷贝指的是数据无需拷贝到 JVM 内存中,同时具有以下三个优点
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
传统 IO 问题
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);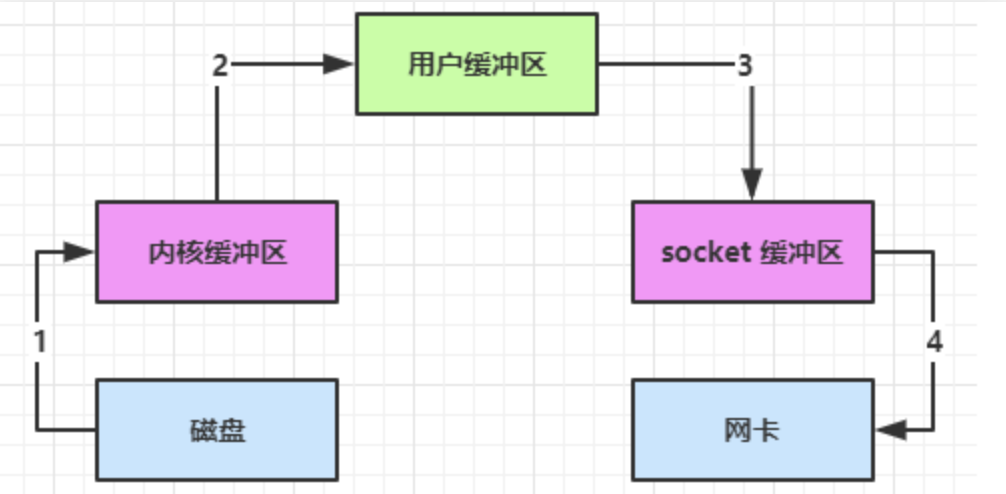
- Java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 Java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 CPU
DMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO - 从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 CPU 会参与拷贝,无法利用 DMA
- 调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,CPU 会参与拷贝
- 接下来要向网卡写数据,这项能力 Java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 CPU
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
NIO 优化
通过 DirectByteBuf
- ByteBuffer.allocate(10)
- 底层对应
HeapByteBuffer,使用的还是 Java 内存
- 底层对应
- ByteBuffer.allocateDirect(10)
- 底层对应
DirectByteBuffer,使用的是操作系统内存
- 底层对应
大部分步骤与优化前相同,唯有一点:Java 可以使用 DirectByteBuffer 将堆外内存映射到 JVM 内存中来直接访问使用
- 这块内存不受 JVM 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- Java 中的
DirectByteBuf对象仅维护了此内存的虚引用,内存回收分成两步-
DirectByteBuffer对象被垃圾回收,将虚引用加入引用队列- 当引用的对象ByteBuffer被垃圾回收以后,虚引用对象Cleaner就会被放入引用队列中,然后调用Cleaner的clean方法来释放直接内存
-
DirectByteBuffer的释放底层调用的是Unsafe的freeMemory方法
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
-
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
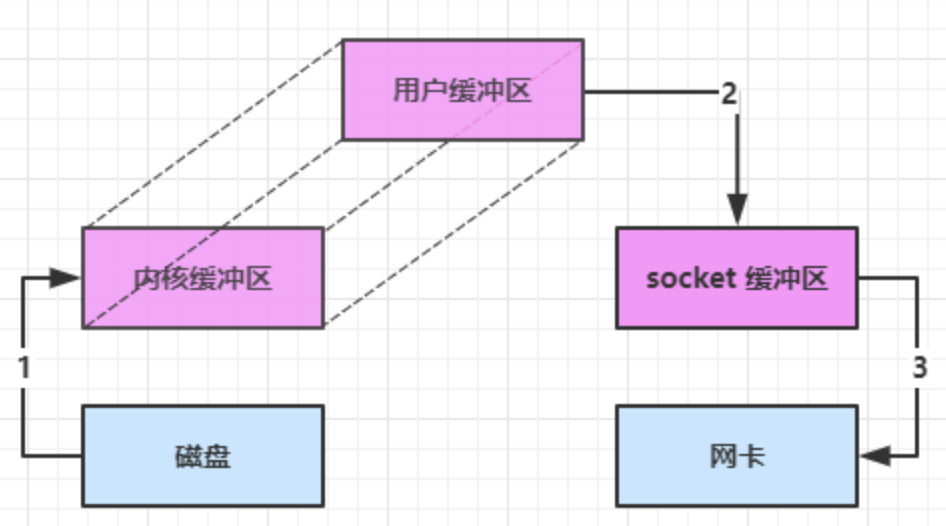
进一步优化
以下两种方式都是零拷贝,即无需将数据拷贝到用户缓冲区中(JVM内存中)
底层采用了 linux 2.1 后提供的 sendFile 方法,Java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据
- Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 CPU
- 数据从内核缓冲区传输到 socket 缓冲区,CPU 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 CPU
这种方法下
- 只发生了1次用户态与内核态的切换
- 数据拷贝了 3 次
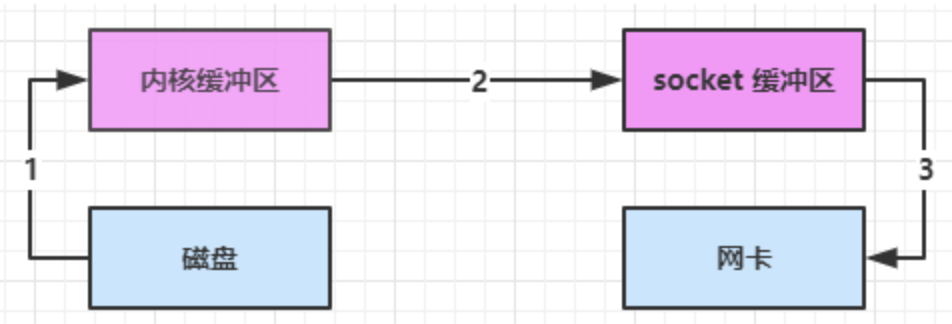
进一步优化
linux 2.4 对上述方法再次进行了优化
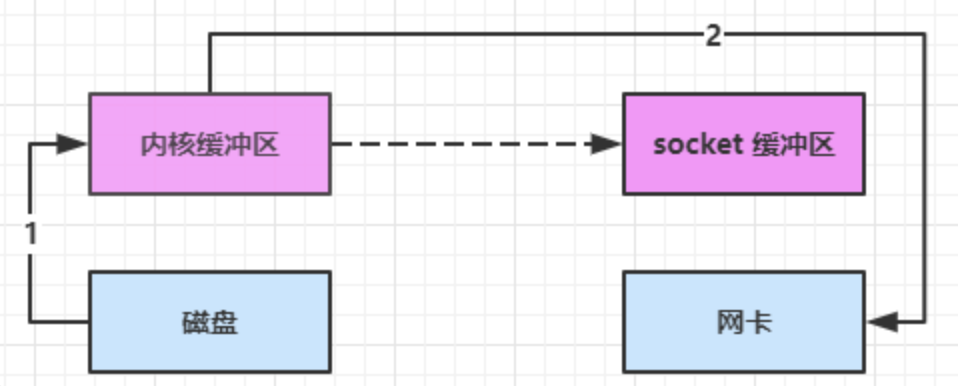
- Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 CPU
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 CPU
整个过程仅只发生了1次用户态与内核态的切换,数据拷贝了 2 次
NIO多线程优化
充分利用多核CPU,分两组选择器
- 单线程配一个选择器(Boss),专门处理 accept 事件
- 创建 cpu 核心数的线程(Worker),每个线程配一个选择器,轮流处理 read 事件
实现思路
- 创建一个负责处理Accept事件的Boss线程,与多个负责处理Read事件的Worker线程
-
Boss线程执行的操作
- 接受并处理Accepet事件,当Accept事件发生后,调用Worker的
register(SocketChannel socket)方法,让Worker去处理Read事件,其中需要根据标识robin去判断将任务分配给哪个Worker -
register(SocketChannel socket)方法会通过同步队列完成Boss线程与Worker线程之间的通信,让SocketChannel的注册任务被Worker线程执行。添加任务后需要调用selector.wakeup()来唤醒被阻塞的Selector
- 接受并处理Accepet事件,当Accept事件发生后,调用Worker的
-
Worker线程执行的操作
- 从同步队列中获取注册任务,并处理Read事件
// 创建固定数量的Worker
Worker[] workers = new Worker[4];
// 用于负载均衡的原子整数
AtomicInteger robin = new AtomicInteger(0);
// 负载均衡,轮询分配Worker
workers[robin.getAndIncrement()% workers.length].register(socket);public void register(final SocketChannel socket) throws IOException {
// 只启动一次
if (!started) {
// 初始化操作
}
// 向同步队列中添加SocketChannel的注册事件
// 在Worker线程中执行注册事件
queue.add(new Runnable() {
@Override
public void run() {
try {
socket.register(selector, SelectionKey.OP_READ);
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 唤醒被阻塞的Selector
// select类似LockSupport中的park,wakeup的原理类似LockSupport中的unpark
selector.wakeup();
}完整代码
/**
* Nio 多线程优化
*
* 单线程配一个选择器(Boss),专门处理 accept 事件
* 创建 cpu 核心数的线程(Worker),每个线程配一个选择器,轮流处理 read 事件
*
*/
public class ThreadsServer {
public static void main(String[] args) {
try (ServerSocketChannel server = ServerSocketChannel.open()) {
// 当前线程为Boss线程
Thread.currentThread().setName("Boss");
server.bind(new InetSocketAddress(8080));
// 负责轮询Accept事件的Selector
Selector boss = Selector.open();
server.configureBlocking(false);
server.register(boss, SelectionKey.OP_ACCEPT);
// 创建固定数量的Worker
Worker[] workers = new Worker[4];
// 用于负载均衡的原子整数
AtomicInteger robin = new AtomicInteger(0);
for(int i = 0; i < workers.length; i++) {
workers[i] = new Worker("worker-"+i);
}
while (true) {
boss.select();
Set<SelectionKey> selectionKeys = boss.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// BossSelector负责Accept事件
if (key.isAcceptable()) {
// 建立连接
SocketChannel socket = server.accept();
System.out.println("connected...");
socket.configureBlocking(false);
// socket注册到Worker的Selector中
System.out.println("before read...");
// 负载均衡,轮询分配Worker
workers[robin.getAndIncrement()% workers.length].register(socket);
System.out.println("after read...");
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
static class Worker implements Runnable {
private Thread thread;
private volatile Selector selector;
private String name;
private volatile boolean started = false;
/**
* 同步队列,用于Boss线程与Worker线程之间的通信
*/
private ConcurrentLinkedQueue<Runnable> queue;
public Worker(String name) {
this.name = name;
}
public void register(final SocketChannel socket) throws IOException {
// 只启动一次
if (!started) {
thread = new Thread(this, name);
selector = Selector.open();
queue = new ConcurrentLinkedQueue<>();
thread.start();
started = true;
}
// 向同步队列中添加SocketChannel的注册事件
// 在Worker线程中执行注册事件
queue.add(new Runnable() {
@Override
public void run() {
try {
socket.register(selector, SelectionKey.OP_READ);
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 唤醒被阻塞的Selector
// select类似LockSupport中的park,wakeup的原理类似LockSupport中的unpark
selector.wakeup();
}
@Override
public void run() {
while (true) {
try {
selector.select();
// 通过同步队列获得任务并运行
Runnable task = queue.poll();
if (task != null) {
// 获得任务,执行注册操作
task.run();
}
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while(iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// Worker只负责Read事件
if (key.isReadable()) {
// 简化处理,省略细节
SocketChannel socket = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(16);
socket.read(buffer);
buffer.flip();
ByteBufferUtil.debugAll(buffer);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
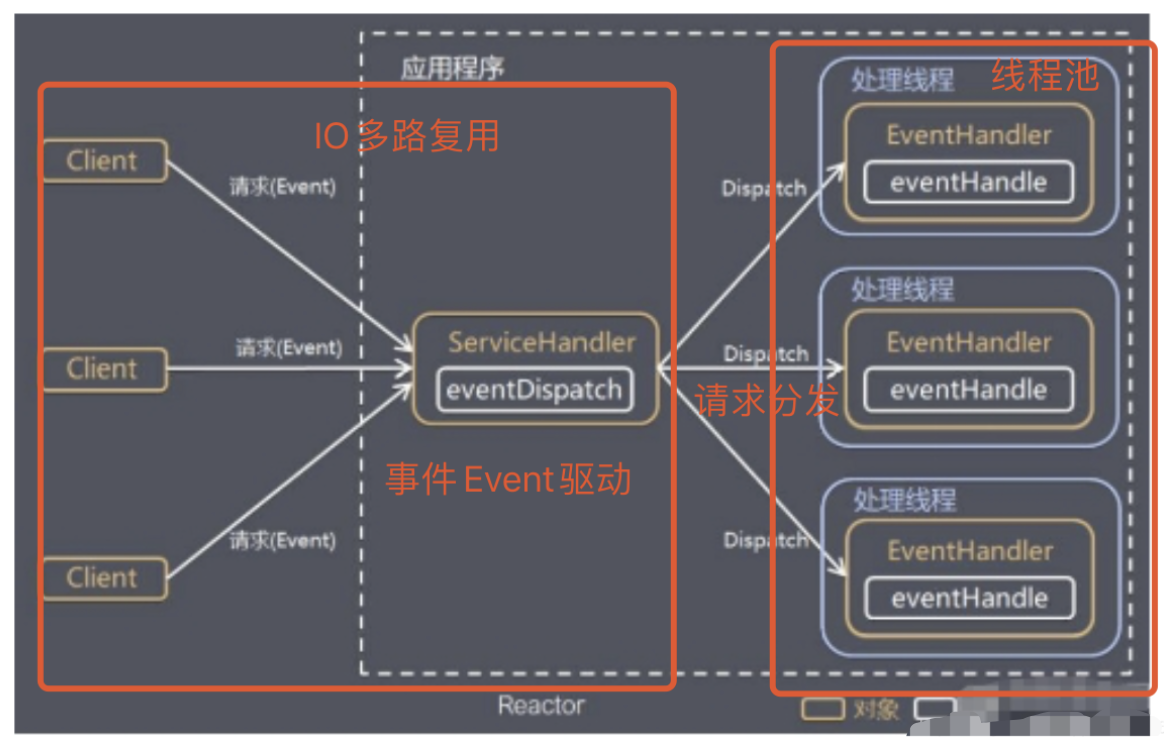
}I/O 复用 + 线程池,就是 Reactor 模式基本设计思想
- Reactor 模式,通过一个或多个输入同时传递给服务处理器的模式(基于事件驱动)
- 服务器端程序处理传入的多个请求,并将它们同步分派到相应的处理线程, 因此Reactor模式也叫 Dispatcher模式
- Reactor 模式使用IO复用监听事件, 收到事件后,分发给某个线程(进程), 这点就是网络服务器高并发处理关键
上述代码虽然是Reactor的设计思想,但是代码实现上还是有区别的