阅读完需:约 20 分钟
MySQL查询过程
想要更好的优化查询,首先要了解其整体查询过程,从客户端发送查询请求,到接收到查询结果,MySQL服务器做了很多工作。
逻辑架构
MySQL逻辑架构整体分为三层,分别为客户端层、核心服务层、存储引擎层,共同协作完成。
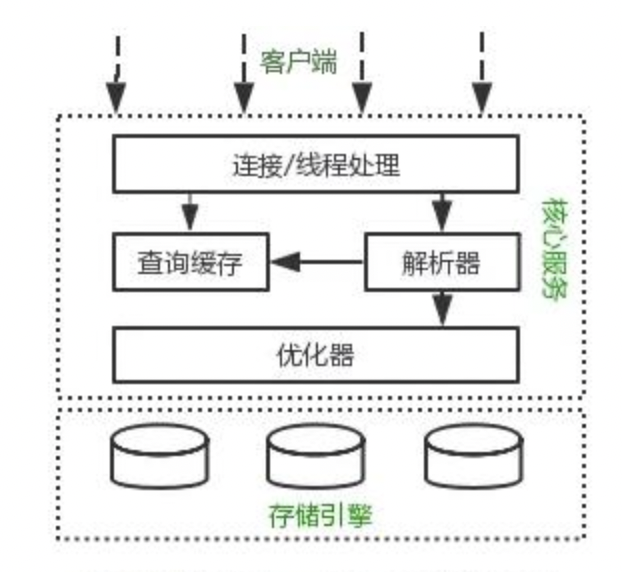
最上层为客户端层,比如:连接处理、授权认证、安全等功能等。
中间层是MySQL的核心服务,包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等),另外,所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
最下层为存储引擎,负责数据存储和提取,中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异。
具体执行过程
重点看下MySQL是如何优化和执行查询的,很多的查询优化工作就是遵循一些原则让MySQL的优化器能够按照预想的方式运行而已。
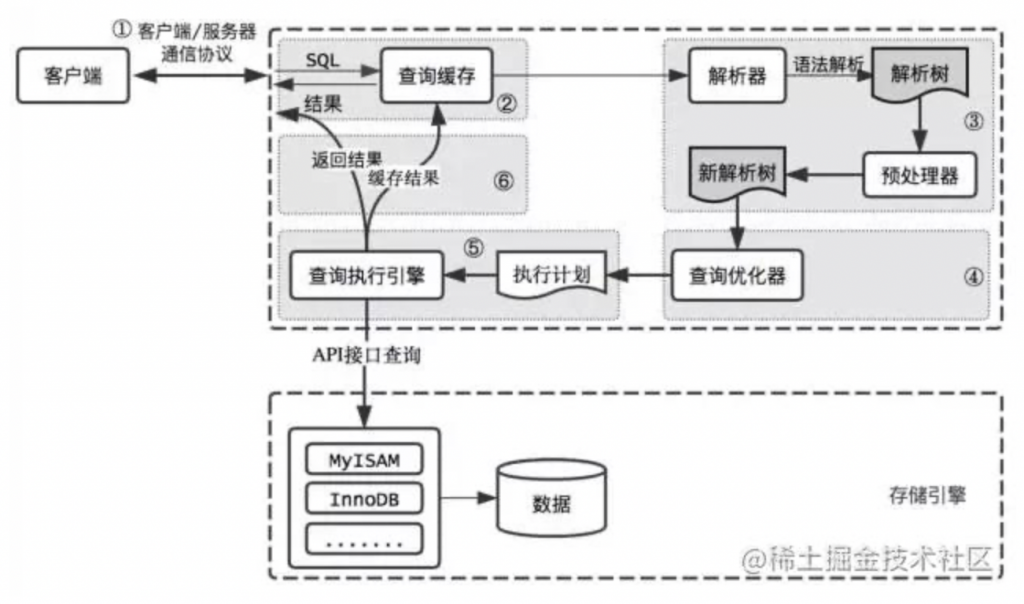
先说下总体流程:
- 客户端发送一条查询SQL给服务器;
- 服务器先检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果;
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
- 查询执行引擎根据优化器生成的执行计划,调用存储引擎的API来执行查询;
- 将结果返回给客户端;
1.客户端/服务端通信协议
MySQL客户端和服务器之间的通信协议是「半双工」:在任何一个时刻,要么由服务器向客户端发送数据,要么由客户端向服务器发送数据,不能同时发生,这也就意味着没法进行流量控制。
客户端用一个单独的数据包将查询请求发送给服务器,服务器响应给用户的数据通常会很多,由多个数据包组成,需要注意的是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送。
2.查询缓存
如果查询缓存是打开的,会检查这个查询语句是否命中查询缓存中的数据,如果命中,在检查一次用户权限后直接返回缓存中的结果。
查询缓存系统会跟踪查询中涉及的每个表,在任何的写操作时,MySQL必须将对应表的所有缓存都设置为失效,如果查询缓存非常大或者碎片很多,这个操作就可能带来很大的系统消耗。
另外,任何的查询语句在开始之前都必须经过检查,即使这条SQL语句永远不会命中缓存,如果查询结果可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗。
所以,打开缓存要慎重,只有当缓存带来的资源节约大于其本身消耗的资源时,才会给系统带来性能提升,可以将query_cache_type设置为DEMAND,这时只有加入SQL_CACHE的查询才会走缓存,其他查询则不会。
3.语法解析和预处理
通过关键字将SQL语句进行解析,生成一颗解析树,预处理则会根据MySQL规则进一步检查解析树是否合法。
4.查询优化
一条查询可以有很多种执行方式,优化器的作用就是找到这其中最好的执行计划,MySQL使用基于成本的优化器,它尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。
5.查询执行引擎
存储引擎接口提供了非常丰富的功能,但其底层仅有几十个接口,这些接口像搭积木一样完成了一次查询的大部分操作。
6.返回结果给客户端
结果集返回客户端是一个增量且逐步返回的过程,这样服务端就无须存储太多结果而消耗过多内存,也可以让客户端第一时间获得返回结果。
SELECT执行顺序
下面来看看SQL查询语句的执行顺序,每一步都会生成一个虚拟临时表,作为下一步的输入。
标准的SQL语法如下:
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
但执行顺序是这样的:
FROM
<left_table>
ON <join_condition> <join_type>
JOIN <right_table>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
SELECT
DISTINCT
<select_list>
ORDER BY
<order_by_condition>
LIMIT
<limit_number>
1.FROM
当涉及多个表的时候,左边表的输出会作为右边表的输入,之后会生成一个虚拟表VT1:
- 计算两个相关联表的笛卡尔积(CROSS JOIN) ,生成虚拟表VT1-J1;
- 基于虚拟表VT1-J1进行过滤,过滤出所有满足ON谓词条件的行,生成虚拟表VT1-J2;
- 如果使用了外连接(LEFT,RIGHT,FULL),主表(保留表)中的不符合ON条件的列也会被加入到VT1-J2中,生成虚拟表VT1-J3;
2.WHERE
对VT1过程中生成的临时表进行过滤,满足WHERE子句的列被插入到VT2表中:
- 与ON的区别:如果有外连接,ON针对过滤的是关联表,主表会返回所有的列,如果没有外连接,效果相同;
- 对主表的过滤应该放在WHERE;
- 于关联表,先条件查询后连接则用ON,先连接后条件查询则用WHERE;
3.GROUP BY
这个子句会把VT2中生成的表按照GROUP BY中的列进行分组,生成VT3表:
- 其后处理过程的语句,如SELECT,HAVING,所用到的列必须包含在GROUP BY中,对于没有出现的,得用聚合函数;
4.HAVING
对VT3表中的不同的组进行过滤,只用于分组后的数据,满足HAVING条件的子句被加入到VT4表中。
5.SELECT
这个子句对SELECT子句中的元素进行处理,生成VT5表:
- 计算SELECT子句中的表达式,生成VT5-J1;
- DISTINCT:寻找重复列,并删掉,会创建一张内存临时表VT5-J2,和虚拟表VT5-J1一样,不同的是对DISTINCT的列增加唯一索引,以此来除重复数据;
6.ORDER BY
从VT5-J2中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VT6表,这是唯一可使用SELECT中别名的地方。
7.LIMIT
从上一步得到的VT6虚拟表中选出从指定位置开始的指定行数据。
高级查询相关概念
连接查询
将多张表按照某个指定的条件进行数据拼接,SQL中将连接查询分成四类: 内连接、外连接、自然连接、交叉连接,其中自然连接和交叉连接很少用到,就不过多介绍了。
1.内连接 inner join
从左表中取出每一条记录,分别与右表中所有的记录进行匹配,匹配必须左表和右表中都满足条件,匹配的会保留结果,否则不保留。
2.外连接 left/right join
外连接分为两种:
- left join: 左外连接(左连接),以左表为主表
- right join: 右外连接(右连接),以右表为主表
以某张表为主,取出里面的所有记录,不管能不能匹配上条件,主表最终都会保留,然后与另外一张表进行连接,如果不能匹配,其他表的字段都置空NULL。
子查询
是在某个查询结果之上再进行查询,也就是一条select语句内部包含了另外一条select语句。
按子查询所在位置,可以划分为:
- From子查询:子查询跟在from之后;
- Where子查询: 子查询出where条件中;
- exists子查询: 子查询出现在exists里面;
下面举几个例子:
查找部门名称前缀为「小米」的所有员工:
SELECT name , sex , sal
FROM emp
WHERE no in (
SELECT no FROM dept
WHERE name LIKE '小米%'
);
查看所有员工的薪水,并按薪水排序:
SELECT name , sal
FROM (
SELECT name , sal
FROM emp ORDER BY sal
);
联合查询
将多次查询, 将结果进行拼接,字段不会增加,每一条select语句获取的字段数必须严格一致。
语法如下:
Select 语句1
Union [union选项]
Select语句2...
Union选项:
- All: 保留所有;
- Distinct: 去重,默认选项;
介绍如何查看和分析SQL执行情况、排查SQL的性能问题
explain命令概述
工作中,MySQL会记录执行时间比较久的SQL语句,找出这些SQL语句是第一步,重要的是查看SQL语句的执行计划,对于MySQL执行计划的获取,可以通过explain方式来查看,这条命令的输出结果能够让我们了解MySQL优化器是如何执行SQL语句的。
MySQL优化器是基于开销来工作的,是在每条SQL语句执行的时候动态地计算出来的,命令用法十分简单, 在 SELECT 语句前加上 Explain 就可以了。
先来个示例
以基本的员工表为例,表的结构如下:
mysql> show create table employee \G;
*************************** 1. row ***************************
Table: mcc_employee
Create Table: CREATE TABLE `employee` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`userId` varchar(50) DEFAULT NULL COMMENT '员工编号',
`userName` varchar(50) DEFAULT NULL COMMENT '员工名称',
`nickName` varchar(50) DEFAULT NULL COMMENT '昵称',
`gender` varchar(10) DEFAULT NULL COMMENT '性别',
`mobilePhone` varchar(20) DEFAULT NULL COMMENT '手机号',
`miliao` varchar(100) DEFAULT NULL COMMENT '米聊号',
`email` varchar(100) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
一个简单的查询:
mysql> explain select * from employee where id =1 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employee
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
Extra: NULL
1 row in set (0.00 sec)
select_type为simple说明是一个普通的查询,不包含子查询和union查询。
字段概述
id字段:select查询的标识符. 每个select都会自动分配一个唯一的标识符,id数值越大的优先执行,id相同的从上往下顺序执行。
select_type:select查询的类型,当没有子查询或union查询时为simple,有子查询或union查询时,有几种情况,后面会详细介绍。
table:标识查询的是哪个表,显示这一行的数据是关于哪张表的,有时不是真实的表名字,看到的是derived(n是个数字,为id字段)
mysql> explain select * from (select * from (select * from employee where id =76) table1 ) table2 ;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 3 | DERIVED | mcc_inform | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
type:数据访问、读取操作类型,对性能影响比较大,后面会详细介绍。
possible_keys:此次查询中可能选用的索引,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。
key:此次查询中确切使用到的索引,如果没有选择索引,键是NULL。
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
ref: 哪个字段或常数与key一起被使用。
rows: 此查询一共扫描了多少行,这个是一个估计值。
filtered: 表示此查询条件所过滤的数据的百分比。
extra: 额外的信息,后面会详细介绍。
select_type字段详细介绍
表示查询的类型,是简单查询或复杂查询,如果是复杂查询,包含SIMPLE、SIMPLE、UNION、UNION RESULT、SUBQUERY、DEPENDENT、DEPENDENT UNION、DEPENDENT SUBQUERY、DERIVED等,了解这些,可以识别在执行那部分。
SIMPLE
简单select,不使用union或子查询等:
mysql> explain select * from employee where id =1 ;
+----+-------------+------------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+-------+---------------+---------+---------+-------+------+-------+
PRIMARY
如果是复杂查询,表示是最外层的select:
mysql> explain select * from (select * from employee where id =1) a ;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
UNION & UNION RESULT
UNION中的第二个或后面的SELECT语句,UNION RESULT为UNION的结果:
mysql> explain select * from employee where id =1 union all select * from employee where id=2;
+----+--------------+------------+-------+---------------+---------+---------+-------+------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+-------+---------------+---------+---------+-------+------+-----------------+
| 1 | PRIMARY | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
| 2 | UNION | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+-------+---------------+---------+---------+-------+------+-----------------+
SUBQUERY
子查询中的第一个SELECT:
mysql> explain select * from employee where id = (select id from employee where id =1);
+----+-------------+------------+-------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+---------+---------+-------+------+-------------+
| 1 | PRIMARY | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
| 2 | SUBQUERY | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
+----+-------------+------------+-------+---------------+---------+---------+-------+------+-------------+
DEPENDENT UNION & DEPENDENT SUBQUERY
DEPENDENT UNION,UNION中的第二个或后面的SELECT语句,但结果取决于外面的查询; DEPENDENT SUBQUERY,子查询中的第一个SELECT,但结果取决于外面的查询:
mysql> explain select * from employee where id in (select id from employee where id =1 union all select id from employee where id=2);
+----+--------------------+------------+-------+---------------+---------+---------+-------+------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+------------+-------+---------------+---------+---------+-------+------+-----------------+
| 1 | PRIMARY | employee | ALL | NULL | NULL | NULL | NULL | 26 | Using where |
| 2 | DEPENDENT SUBQUERY | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
| 3 | DEPENDENT UNION | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
| NULL | UNION RESULT | <union2,3> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+-------+---------------+---------+---------+-------+------+-----------------+
DERIVED
派生表的SELECT,FROM子句的子查询:
mysql> explain select * from (select * from employee where id =1) a ;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------+
type字段详细介绍
type表示数据访问/读取的操作类型,显示了连接使用了哪种类别,有无使用索引,它提供了判断查询是否高效的重要依据依据。
常见的类型有常用有,性能从差到好排序:ALL, index, range, ref, eq_ref, const, system, NULL
NULL
不用访问表或者索引就可以直接得到结果:
mysql> explain select sysdate();
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
const、system
如将主键或者唯一索引置于where列表中,MySQL就能将该查询转换为一个常量,当表中只有一行记录时,类型为system。
mysql> explain select * from (select id from mcc_inform where id =1) a;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 2 | DERIVED | employee | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
eq_ref
此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高:
mysql> explain select * from t3,t4 where t3.id=t4.accountid;
+----+-------------+-------+--------+-------------------+-----------+---------+----------------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+-------------------+-----------+---------+----------------------+------+-------+
| 1 | SIMPLE | t4 | ALL | NULL | NULL | NULL | NULL | 1000 | |
| 1 | SIMPLE | t3 | eq_ref | PRIMARY,idx_t3_id | idx_t3_id | 4 | dbatest.t4.accountid | 1 | |
+----+-------------+-------+--------+-------------------+-----------+---------+----------------------+------+-------+
ref
与eq_ref类似,不同的是ref不是唯一索引,此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了最左前缀规则索引的查询,可以用于使用=或<=>操作符的带索引的列:
index_merge
该联接类型表示使用了索引合并优化方法, where中可能有多个条件(或者join)涉及到多个字段,它们之间进行 AND 或者 OR,那么此时就有可能会使用到 index merge 技术。
index merge 技术如果简单的说,其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)。
range
表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录, 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中
index
表示全索引扫描(full index scan), 和 ALL 类型类似, 只不过 ALL 类型是全表扫描, 而 index 类型则仅仅扫描所有的索引, 而不扫描数据。
ALL
表示全表扫描, 这个类型的查询是性能最差的查询之一,一般不会出现。
extra字段详细介绍
EXplain中的很多额外的信息会在Extra字段显示,此字段能够给出让我们深入理解执行计划进一步的细节信息,介绍下常见的几个。
Using where
在查找使用索引的情况下,需要回表去查询所需的数据。
Using index
表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 说明性能不错。
Using filesort
当SQL中包含ORDER BY 操作,而且无法利用索引完成排序操作的时候,查询优化器不得不选择相应的排序算法来实现。
filesort主要用于查询数据结果集的排序操作,首先MySQL会使用sort_buffer_size大小的内存进行排序,如果结果集超过了sort_buffer_size大小,会把这一个排序后的chunk转移到file上,最后使用多路归并排序完成所有数据的排序操作。
filesort只能应用在单个表上,如果有多个表的数据需要排序,那么MySQL会先使用using temporary保存临时数据,然后再在临时表上使用filesort进行排序,最后输出结果。
Using temporary
查询有使用临时表, 一般出现于排序, 分组和多表join的情况, 查询效率不高, 建议优化.
