阅读完需:约 10 分钟
Kotlin 中的函数使用 fun{: .keyword } 关键字声明
函数定义

fun double(x: Int): Int {
}
fun yy(p: (Foo, String, Long) -> Any){
//p(Foo(), "Hello", 3L)
}p: (Foo, String, Long) -> Any 看成一个整体,它就是一个参数,不过它的返回值是Any,Any==object

如果一个函数不返回任何有用的值,它的返回类型是 Unit。Unit 是一种只有一个值——Unit 的类型。这个值不需要显式返回
fun printHello(name: String?): Unit {
if (name != null)
println("Hello ${name}")
else
println("Hi there!")
// `return Unit` 或者 `return` 是可选的
}函数用法
调用函数使用传统的方法
val result = double(2)调用成员函数使用点表示法
Sample().foo() // 创建类 Sample 实例并调用 foo函数与方法

class Foo {
fun bar(p0: String, p1: Long): Any{ TODO() }
}bar就是一个典型的有receiver的方法,因为他有类名Foo

这里其实就是将函数给简化了而已 , 特别要注意的是有receiver的方法:
(Foo, String, Long)->Any = Foo.(String, Long)->Any = Function3<Foo, String, Long, Any>这三个东西都是相等的,其中Function3<Foo, String, Long, Any>是泛型的体现

对于在顶级函数也就是没有类名的函数可以直接 :: 调用,有类名的函数需要加上类名。

fun yy(p: (Foo, String, Long) -> Any){
//p(Foo(), "Hello", 3L)
}
class Foo {
fun bar(p0: String, p1: Long): Any{ TODO() }
}
fun foo() { }
fun foo(p0: Int): String { TODO() } val x:(Foo, String, Long)->Any = Foo::bar
val x0: Function3<Foo, String, Long, Any> = Foo::bar
// (Foo, String, Long)->Any = Foo.(String, Long)->Any = Function3<Foo, String, Long, Any>
val y: (Foo, String, Long) -> Any = x
val z: Function3<Foo, String, Long, Any> = x
yy(x)
val f: ()->Unit = ::foo
val g: (Int) ->String = ::foo
val h: (Foo, String, Long)->Any
= Foo::bar

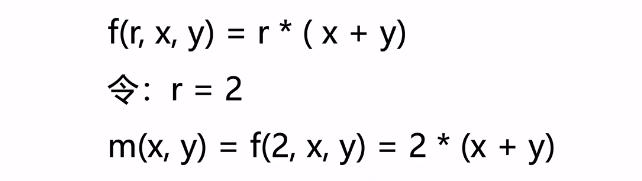
参数
函数参数使用 Pascal 表示法定义,即 name: type。参数用逗号隔开。每个参数必须有显式类型。
fun powerOf(number: Int, exponent: Int) {
……
}可变数量的参数(Varargs)
函数的参数(通常是最后一个)可以用 vararg 修饰符标记:

类似于java 中的
public static void main(String... args) {
System.out.println(Arrays.toString(args));
}kotlin中的使用方式:
fun <T> asList(vararg ts: T): List<T> {
val result = ArrayList<T>()
for (t in ts) // ts is an Array
result.add(t)
return result
}允许将可变数量的参数传递给函数:
val list = asList(1, 2, 3)在函数内部,类型 T 的 vararg 参数的可见方式是作为 T 数组,即上例中的 ts 变量具有类型 Array <out T>。只有一个参数可以标注为vararg。如果vararg参数不是列表中的最后一个参数, 可以使用命名参数语法传递其后的参数的值,或者,如果参数具有函数类型,则通过在括号外部传一个 lambda。
当我们调用 vararg-函数时,我们可以一个接一个地传参,例如 asList(1, 2, 3),或者,如果我们已经有一个数组并希望将其内容传给该函数,我们使用伸展(spread)操作符(在数组前面加 *):
val a = arrayOf(1, 2, 3)
val list = asList(-1, 0, *a, 4)多返回值

fun multiReturnValues(): Triple<Int, Long, Double> {
return Triple(1, 3L, 4.0)
}
val (a, b, c) = multiReturnValues() //伪
val r = a + b
val r1 = a + c默认参数
函数参数可以有默认值,当省略相应的参数时使用默认值。与其他语言相比,这可以减少重载数量。

fun read(b: Array<Byte>, off: Int = 0, len: Int = b.size()) {
……
}默认值通过类型后面的 = 及给出的值来定义。覆盖方法总是使用与基类型方法相同的默认参数值。当覆盖一个带有默认参数值的方法时,必须从签名中省略默认参数值:
open class A {
open fun foo(i: Int = 10) { …… }
}
class B : A() {
override fun foo(i: Int) { …… } // 不能有默认值
}具名参数

如果默认的参数没有设置在最后一个那么当我们传入参的时候就是发生冲突,编译器无法判断要不要覆盖你的默认参数。所以需要指出你要给哪一个参数传递值。
命名参数
可以在调用函数时使用命名的函数参数。当一个函数有大量的参数或默认参数时这会非常方便。给定以下函数
fun reformat(str: String,
normalizeCase: Boolean = true,
upperCaseFirstLetter: Boolean = true,
divideByCamelHumps: Boolean = false,
wordSeparator: Char = ' ') {
println(str+normalizeCase+upperCaseFirstLetter+divideByCamelHumps+wordSeparator)
}我们可以使用默认参数来调用它
reformat(str)然而,当使用非默认参数调用它时,该调用看起来就像
reformat(str, true, true, false, '_')使用命名参数我们可以使代码更具有可读性
局部函数
Kotlin 支持局部函数,即一个函数在另一个函数内部
fun dfs(graph: Graph) {
fun dfs(current: Vertex, visited: Set<Vertex>) {
if (!visited.add(current)) return
for (v in current.neighbors)
dfs(v, visited)
}
dfs(graph.vertices[0], HashSet())
}局部函数可以访问外部函数(即闭包)的局部变量,所以在上例中,visited 可以是局部变量。
fun dfs(graph: Graph) {
val visited = HashSet<Vertex>()
fun dfs(current: Vertex) {
if (!visited.add(current)) return
for (v in current.neighbors)
dfs(v)
}
dfs(graph.vertices[0])
}成员函数
成员函数是在类或对象内部定义的函数
class Foo5 (int: Int) {
fun bar(p0: String, p1: Long): Any{ TODO() }
}
Foo5(1).bar("s",555)泛型函数
函数可以有泛型参数,通过在函数名前使用尖括号指定。
fun <T> singletonList(item: T): List<T> {
// ……
}尾递归函数
Kotlin 支持一种称为尾递归的函数式编程风格。这允许一些通常用循环写的算法改用递归函数来写,而无堆栈溢出的风险。当一个函数用 tailrec 修饰符标记并满足所需的形式时,编译器会优化该递归,留下一个快速而高效的基于循环的版本。
tailrec fun findFixPoint(x: Double = 1.0): Double
= if (x == Math.cos(x)) x else findFixPoint(Math.cos(x))这段代码计算余弦的不动点(fixpoint of cosine),这是一个数学常数。 它只是重复地从 1.0 开始调用 Math.cos,直到结果不再改变,产生0.7390851332151607的结果。最终代码相当于这种更传统风格的代码:
private fun findFixPoint(): Double {
var x = 1.0
while (true) {
val y = Math.cos(x)
if (x == y) return y
x = y
}
}要符合 tailrec 修饰符的条件的话,函数必须将其自身调用作为它执行的最后一个操作。在递归调用后有更多代码时,不能使用尾递归,并且不能用在 try/catch/finally 块中。目前尾部递归只在 JVM 后端中支持。
Kotlin 中的 Receiver
Receiver
字面意思是接收者,为什么kotlin会有这个概念?首先kotlin中函数是一等公民,和java不一样,java中的函数(准确来说是方法)需要依赖于类,kotlin的函数不依赖类,它可以在任何地方定义,那么在某些场景就会有一些问题
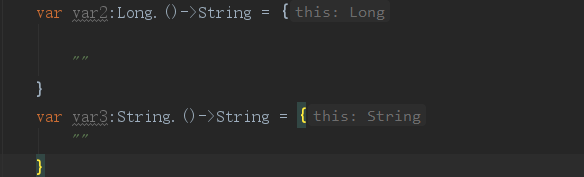
如果函数有Receiver,那么this 就是对应的Receiver,如果不写Receiver ,那么this 表示什么?
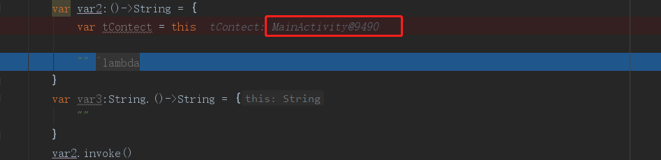
看到没,没写的话,默认是这个函数所定义的类里面,那如果我们lambda表达式里嵌套lambda表达式,最里层的上下文是哪个呢
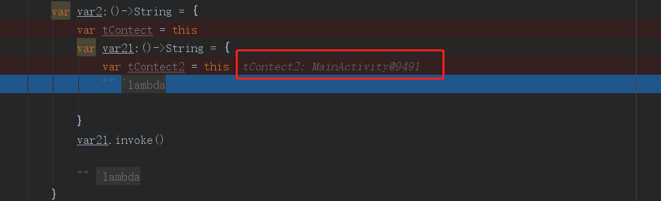
与第一层的上下文一致
到这里,我们可以总结下:
- 1.函数默认Receiver是该函数所定义的类内(感觉有点废话)
- 2.函数内this指向的是Receiver
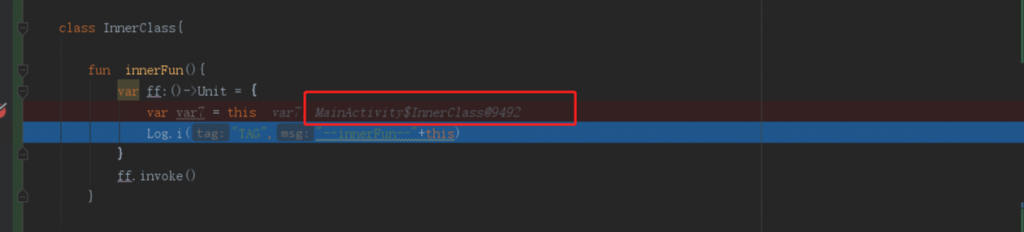
函数默认Receiver是该函数所定义的类内 。这句废话,其实是有原因的,
这和kotlin lanbda 表达式原理有关。
kotlin会为lambda表达式生成一个新类,类名为自己所处的类名(Test)+ 所处的方法名(test)+ 数字(从1开始,有多个则依次递增)。该类继承了Lambda类并实现了对应的Function接口,那按照这个原理,那么lambda表达式内的this指向的就是编译器为lambda生成的新类,这与我上面的两点总结不符合,但是上面两点总结是根据事实而来,这说明在JVM层面,肯定对这种情况作了处理,至于怎么处理的,我也没有找到具体的依据。
这里从Java与kotlin之间的联系来解读下为什么JVM会做这种转换处理以及为什么需要Receiver这个概念。
我们知道Java中我们通常说的函数其实是不准确的,应该称为方法,Java中的方法需依赖于类,java中的this指向的是调用者本身。
因为kotlin(本文讨论的kotlin是基于java)是基于Java之上的封装,所以对于开发者而言,this 不管是在kotlin 还是在java中 概念都应该保持统一,即代表上下文,或者说this指向的都是调用这本身,但是kotlin 中的函数是有自己的类型,或者说它可以自己调用自己,不需要依赖类,这样就会存在一些问题,那怎样将kotlin中的this翻译成Java中的this呢,在转换的时候怎么处理,这时候就借用了Receiver这个概念了,kotlin可以默认或者指定某个函数的Receiver,这样类似于对这个函数做了一份主权申明:“这个函数是定义在我这个类的”。这样做的好处就是在转换成Java语言时可以根据Receiver来明确上下文this。
我们可以在kotlin 字节码中找的到了$Receicer 这个常量。
