阅读完需:约 16 分钟
创建数据PUT
第一条数据:
PUT /test/_doc/1
{
"name":"xjh",
"age":21,
"desc":"shangjin",
"tags":["xx","ss","dd","gg"]
}第二条数据 :
PUT /test/_doc/2
{
"name":"xyh",
"age":21,
"desc":"shangjin",
"tags":["xx","ss","dd","gg","yy"]
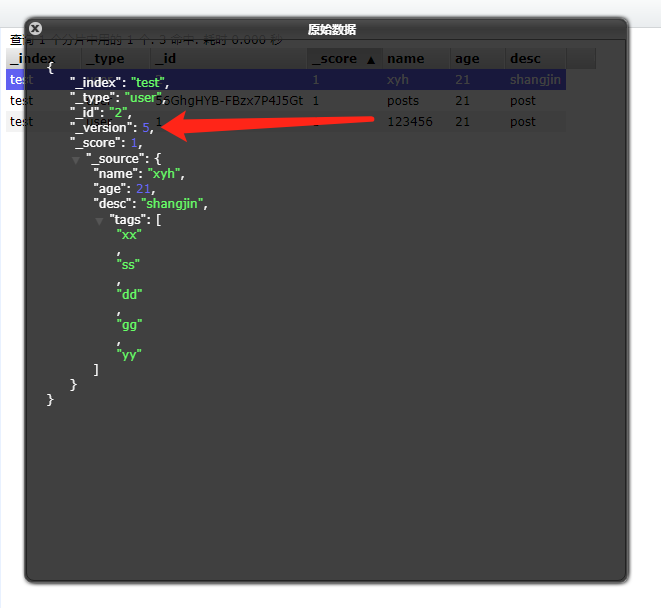
}1 , 2 表示新建文档的 id。
_type是早期版本的设计缺陷。
在5.x以前的版本里边,一个索引下面是支持多个type的。
6版本以后改为只支持一个type, type可以自定义。
7以后所有的typr就默认为_doc.
8版本后移除type
添加成功后,响应的 json 如下:
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_version" : 5,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}- _index 表示文档索引。
- _type 表示文档的类型。
- _id 表示文档的 id。
- _version 表示文档的版本(更新文档,版本会自动加 1,针对一个文档的)。
- result 表示执行结果。
- _shards 表示分片信息。
-
_seq_no和_primary_term这两个也是版本控制用的(针对当前 index)。
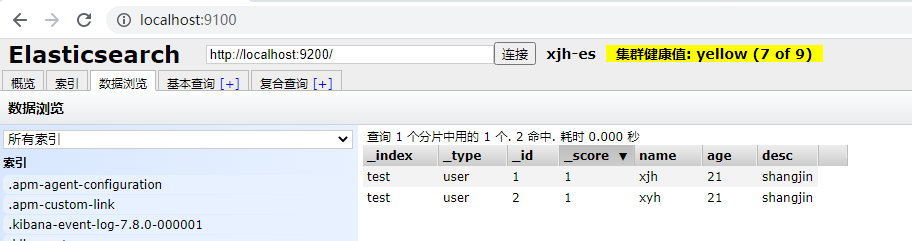
可以查看添加的文档:
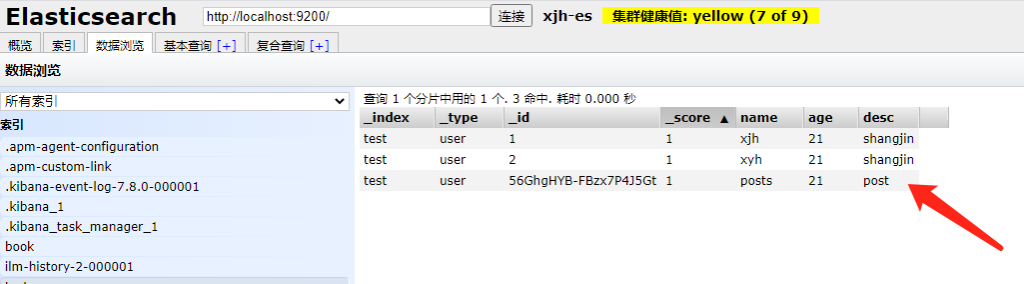
当然,添加文档时,也可以不指定 id,此时系统会默认给出一个 id,如果不指定 id,则需要使用 POST 请求,而不能使用 PUT 请求。
POST /test/_doc
{
"name":"posts",
"age":21,
"desc":"post",
"tags":["post"]
}
当执行 命令时,如果数据不存在,则新增该条数据,如果数据存在则修改该条数据。
通过 GET 命令查询一下 :
GET /test/_doc/1{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "xjh",
"age" : 21,
"desc" : "shangjin",
"tags" : [
"xx",
"ss",
"dd"
]
}
}
如果你想更新数据 可以覆盖这条数据 :
PUT /test/_doc/1
{
"name":"xyh",
"age":21,
"desc":"shangjin",
"tags":["gai"]
}返回结果:
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1
}
已经修改了,那么 PUT 可以更新数据但是。麻烦的是 原数据你还要重写一遍要 这不符合我们规矩。
更新数据 POST
注意,文档更新一次,version 就会自增 1。
可以直接更新整个文档:
PUT /test/_doc/2
{
"name":"xyh",
"age":21,
"desc":"55555",
"tags":["gai"]
}这种方式,更新的文档会覆盖掉原文档。
大多数时候,我们只是想更新文档字段,这个可以通过脚本来实现。
脚本来实现
POST /test/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.name=params.name",
"params": {
"name":"666666"
}
}
}更新的请求格式:POST {index}/_update/{id}
在脚本中,lang 表示脚本语言,painless 是 es 内置的一种脚本语言。source 表示具体执行的脚本,ctx 是一个上下文对象,通过 ctx 可以访问到 _source、_title 等。
脚本对应的是数据的基本信息:
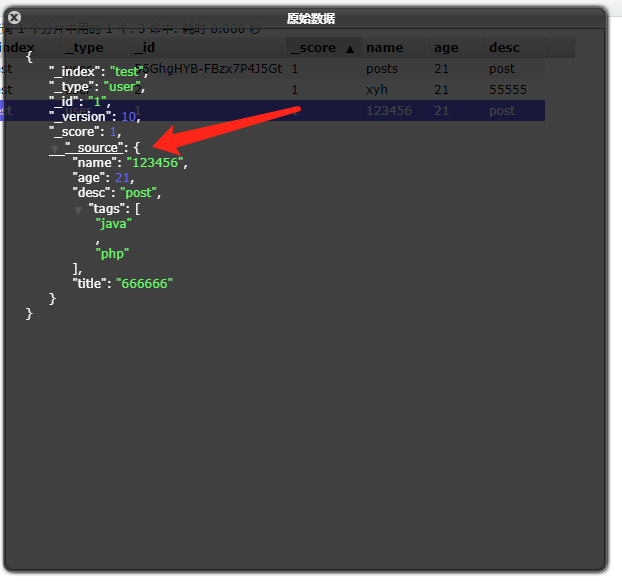
也可以向文档中添加字段:
POST /test/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.tags=[\"java\",\"php\"]"
}
}返回:
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 10,
"_seq_no" : 16,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "123456",
"age" : 21,
"desc" : "post",
"tags" : [
"java",
"php"
],
"title" : "666666"
}
}
查询更新
通过条件查询找到文档,然后再去更新。
例如将 title 中包含 666 的文档的 name 修改为 888。
POST test/_update_by_query
{
"script": {
"source": "ctx._source.name=\"888\"",
"lang": "painless"
},
"query": {
"term": {
"title":"666"
}
}
}返回:
{
"took" : 23,
"timed_out" : false,
"total" : 1,
"updated" : 1,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
不使用脚本
我们使用 POST 命令,在 id 后面跟 _update ,要修改的内容放到 doc 文档(属性)中即可。
POST /test/_update/1
{
"doc":{
"name":"123456"
}
}返回:
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 9,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 15,
"_primary_term" : 1
}
通过脚本语言,也可以修改数组。例如再增加一个 tag:
POST test/_update/1
{
"script":{
"lang": "painless",
"source":"ctx._source.tags.add(\"js\")"
}
}当然,也可以使用 if else 构造稍微复杂一点的逻辑。
POST test/_update/1
{
"script": {
"lang": "painless",
"source": "if (ctx._source.tags.contains(\"java\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}GET查询
条件查询_search?q=
简单的查询,我们上面已经不知不觉的使用熟悉了:
GET test/_doc/1如果仅仅只是想探测某一个文档是否存在,可以使用 head 请求:
HEAD test/_doc/2存在——200 – OK
不存在
{“statusCode”:404,”error”:”Not Found”,”message”:”404 – Not Found”}
当然也可以批量获取文档。
GET test/_mget
{
"ids":["1"]
}返回:
{
"docs" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "1",
"found" : false
}
]
}这里可能有小伙伴有疑问,GET 请求竟然可以携带请求体?
某些特定的语言,例如 JavaScript 的 HTTP 请求库是不允许 GET 请求有请求体的,实际上在 RFC7231 文档中,并没有规定 GET 请求的请求体该如何处理,这样造成了一定程度的混乱,有的 HTTP 服务器支持 GET 请求携带请求体,有的 HTTP 服务器则不支持。虽然 es 工程师倾向于使用 GET 做查询,但是为了保证兼容性,es 同时也支持使用 POST 查询。例如上面的批量查询案例,也可以使用 POST 请求。
好了!我们来学习下条件查询 _search?q=
别忘 了 _search 和 from 属性中间的分隔符 ? 。
GET test/_search?q=name:888返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.7917595,
"hits" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "2",
"_score" : 1.7917595,
"_source" : {
"name" : "888",
"title" : "666",
"age" : 21,
"desc" : "55555",
"tags" : [
"gai"
]
}
}
]
}
}
我们看一下结果 返回并不是 数据本身,是给我们了一个 hits ,还有 _score得分,就是根据算法算出和查询条件匹配度高得分就搞。
构建查询
GET test/_search
{
"query":{
"match":{
"name": "888"
}
}
}上例,查询条件是一步步构建出来的,将查询条件添加到 match 中即可。返回结果还是一样的:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "2",
"_score" : 0.6931471,
"_source" : {
"name" : "888",
"title" : "666",
"age" : 21,
"desc" : "55555",
"tags" : [
"gai"
]
}
}
]
}除此之外,我们还可以查询全部:
GET test/_search #这是一个查询但是没有条件GET test/_search
{
"query":{
"match_all": {}
}
}match_all的值为空,表示没有查询条件,就像select * from table_name一样。
返回结果:全部查询出来了!
如果有个需求,我们仅是需要查看 name 和 desc 两个属性,其他的不要怎么办?
GET test/_search
{
"query":{
"match_all": {}
},
"_source": ["name","desc"]
}如上例所示,在查询中,通过 _source 来控制仅返回 name 和 age 属性。
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "56GhgHYB-FBzx7P4J5Gt",
"_score" : 1.0,
"_source" : {
"name" : "posts",
"desc" : "post"
}
},
{
"_index" : "test",
"_type" : "user",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "888",
"desc" : "55555"
}
}
]
}
}一般的,我们推荐使用构建查询,以后在与程序交互时的查询等也是使用构建查询方式处理查询条件,因为该方 式可以构建更加复杂的查询条件,也更加一目了然
排序查询
我们说到排序 有人就会想到:正序 或 倒序 那么我们先来倒序:
GET test/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}上例,在条件查询的基础上,我们又通过 sort 来做排序,排序对象是 age , order 是 desc 降序。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "56GhgHYB-FBzx7P4J5Gt",
"_score" : null,
"_source" : {
"name" : "posts",
"age" : 21,
"desc" : "post",
"tags" : [
"post"
]
},
"sort" : [
21
]
},
{
"_index" : "test",
"_type" : "user",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "888",
"title" : "666",
"age" : 12,
"desc" : "55555",
"tags" : [
"gai"
]
},
"sort" : [
12
]
}
]
}
}正序,就是 desc 换成了 asc
GET test/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
注意:在排序的过程中,只能使用可排序的属性进行排序。那么可以排序的属性有哪些呢?
- 数字
- 日期
- ID
其他都不行!
分页查询
GET test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0, # 从第n条开始
"size": 1 # 返回n条数据
}返回结果:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "888",
"title" : "666",
"age" : 12,
"desc" : "55555",
"tags" : [
"gai"
]
},
"sort" : [
12
]
}
]
}
}
就返回了一条数据 是从第0条开始的返回一条数据 。
学到这里,我们也可以看到,我们的查询条件越来越多,开始仅是简单查询,慢慢增加条件查询,增加排序,对返回 结果进行限制。
所以,我们可以说:对elasticsearch于 来说,所有的查询条件都是可插拔的,彼此之间用 分 割。比如说,我们在查询中,仅对返回结果进行限制:
GET test/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 1
}布尔查询
先增加一个数据:
PUT test/_doc/3
{
"name":"bollen88",
"age":22,
"desc":"oooo",
"tags":["xx","ss","dd","gg","yy"]
}must (and)
我要查询所有 name 属性为“ 88 “的数据,并且年龄为22岁的!
GET test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "bollen88"
}
},
{
"match": {
"age": "22"
}
}
]
}
}
}我们通过在 bool 属性内使用 must 来作为查询条件!看结果,是不是 有点像 and 的感觉,里面的条件需要都满足!
返回:
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.3862944,
"hits" : [
{
"_index" : "test",
"_type" : "user",
"_id" : "3",
"_score" : 2.3862944,
"_source" : {
"name" : "bollen88",
"age" : 22,
"desc" : "oooo",
"tags" : [
"xx",
"ss",
"dd",
"gg",
"yy"
]
}
}
]
}
}
should (or)
查询 name 属性为“ 88 “的数据,或年龄为22岁的!
GET test/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "bollen88"
}
},
{
"match": {
"age": "22"
}
}
]
}
}
}must_not (not)
查询 年龄不是 18 的 数据,name 不是 88 的数据
GET test/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "bollen88"
}
},
{
"match": {
"age": "22"
}
}
]
}
}
}Fitter
查询 年龄大于 18 的 数据,name 是 88 的数据
GET test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "bollen88"
}
}
],
"filter": [
{
"range": {
"age": {
"gt": 10
}
}
}
]
}
}
}这里就用到了 fifilter 条件过滤查询,过滤条件的范围用 range 表示, gt 表示大于,大于多少呢?是10。其余操作如下:
- gt 表示大于
- gte 表示大于等于
- lt 表示小于
- lte 表示小于等于
要查询 name 是 88, age 在 20~30 之间的怎么查?
GET test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "bollen88"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
]
}
}
}短语检索
我要查询 tags为xx的数据
GET test/_search
{
"query": {
"match": {
"tags": "xx"
}
}
}返回了所有标签中带 xx 的记录!
既然按照标签检索,那么,能不能写多个标签呢?又该怎么写呢?
GET test/_search
{
"query": {
"match": {
"tags": "xx ss"
}
}
}返回:只要含有这个标签满足一个就给我返回这个数据了。
term查询精确查询
term 查询是直接通过倒排索引指定的 词条,也就是精确查找。
term和match的区别:
- match是经过分析(analyer)的,也就是说,文档是先被分析器处理了,根据不同的分析器,分析出的结果也会不同,在会根据分词 结果进行匹配。
- term是不经过分词的,直接去倒排索引查找精确的值。
注意 :我们现在用的es7版本 所以我们用 mappings properties 去给多个字段(fifields)指定类型的时候,不能给我们的 索引制定类型:
新建一个索引和添加数据:
PUT test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
PUT test2/_doc/1
{
"name": "xhg111",
"desc": "desc111"
}
PUT test2/_doc/2
{
"name": "xhg222",
"desc": "desc222"
}上述中test2索引中,字段name在被查询时会被分析器进行分析后匹配查询。而属于keyword类型不会被分析器处理。
我们来验证一下:
GET _analyze
{
"analyzer": "keyword",
"text": "xhg111 ss"
}返回:
{
"tokens" : [
{
"token" : "xhg111 ss",
"start_offset" : 0,
"end_offset" : 9,
"type" : "word",
"position" : 0
}
]
}
是不是没有被分析啊。就是简单的一个字符串啊。
GET _analyze
{
"analyzer": "standard",
"text": "xhg111 ss"
}返回:
{
"tokens" : [
{
"token" : "xhg111",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "ss",
"start_offset" : 7,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
那么我们看一下 们字符串是不是被分析了啊。
总结:keyword 字段类型不会被分析器分析!
现在我们来查询一下:
GET test2/_search // text 会被分析器分析 查询
{
"query": {
"term": {
"name": "xhg111"
}
}
}
GET test2/_search. // keyword 不会被分析所以直接查询
{
"query": {
"match": {
"desc": "desc111"
}
}
}查找多个精确值(terms)
官网地址(查找多个精确值):
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_finding_multiple_exact_values.html
PUT test2/_doc/3
{
"t1": "22",
"t2": "2020-12-21"
}
PUT test2/_doc/4
{
"t1": "33",
"t2": "2020-12-20"
}
# 查询 精确查找多个值
GET test2/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "22"
}
},
{
"term": {
"t1": "33"
}
}
]
}
}
}除了bool查询之外:
GET test2/_search
{
"query": {
"terms": {
"t1":["22","33"]
}
}
}高亮显示
GET test2/_search
{
"query": {
"match": {
"name": "xhg111"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}返回:
{
"took" : 98,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "test2",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"name" : "xhg111",
"desc" : "desc111"
},
"highlight" : {
"name" : [
"<em>xhg111</em>"
]
}
}
]
}
}我们可以看到 已 < em>xhg111< /em>经帮我们加上了一个< em>标签
这是es帮我们加的标签。也可以自己自定义样式
GET test2/_search
{
"query": {
"match": {
"name": "xhg111"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"name":{}
}
}
}返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "test2",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"name" : "xhg111",
"desc" : "desc111"
},
"highlight" : {
"name" : [
"<b class='key' style='color:red'>xhg111</b>"
]
}
}
]
}
}需要注意的是:自定义标签中属性或样式中的逗号一律用英文状态的单引号表示,应该与外部 es 语法 的双引号区分开。
DELETE删除
从索引中删除一个文档。
DELETE test2/_doc/3如果在添加文档时指定了路由,则删除文档时也需要指定路由,否则删除失败。
查询删除
查询删除是 POST 请求。
例如删除 t1 中包含 33 的文档:
POST test2/_delete_by_query
{
"query":{
"term":{
"t1":"33"
}
}
}也可以删除某一个索引下的所有文档:
POST test2/_delete_by_query
{
"query":{
"match_all":{
}
}
}批量操作
es 中通过 Bulk API 可以执行批量索引、批量删除、批量更新等操作。
首先需要将所有的批量操作写入一个 JSON 文件中,然后通过 POST 请求将该 JSON 文件上传并执行。
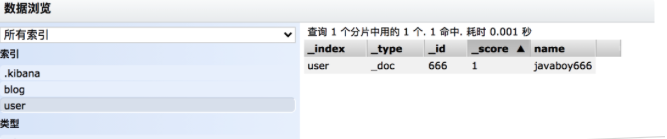
例如新建一个名为 aaa.json 的文件,内容如下:

首先第一行:index 表示要执行一个索引操作(这个表示一个 action,其他的 action 还有 create,delete,update)。_index 定义了索引名称,这里表示要创建一个名为 user 的索引,_id 表示新建文档的 id 为 666。
第二行是第一行操作的参数。
第三行的 update 则表示要更新。
第四行是第三行的参数。
注意,结尾要空出一行。
aaa.json 文件创建成功后,在该目录下,执行请求命令,如下:
curl -XPOST "http://localhost:9200/user/_bulk" -H "content-type:application/json" --data-binary @aaa.json
执行完成后,就会创建一个名为 user 的索引,同时向该索引中添加一条记录,再修改该记录,最终结果如下:
注意 elasticsearch 在第一个版本的开始 每个文档都储存在一个索引中,并分配一个 映射类型,映射类型用于表示被索引的文档或者实体的类型,这样带来了一些问题, 导致后来在 elasticsearch6.0.0 版本中一个文档只能包含一个映射类型,而在 7.0.0 中,映 射类型则将被弃用,到了 8.0.0 中则将完全被删除。
只要记得,一个索引下面只能创建一个类型就行了,其中各字段都具有唯一性,如果在创建映射的时候,如果没有指定文档类型,那么该索引的默认索引类型是 _doc ,不指定文档id则会内部帮我们生成一个id字符串。
