阅读完需:约 3 分钟
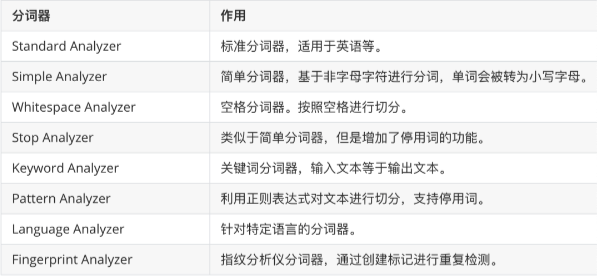
内置分词器
ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。查询分析则主要分为两个步骤:
- 词条化:分词器将输入的文本转为一个一个的词条流。
- 过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤器、小写过滤器等。
ElasticSearch 中内置了多种分词器可以供使用。
中文分词器
在 Es 中,使用较多的中文分词器是 elasticsearch-analysis-ik,这个是 es 的一个第三方插件,代码托管在 GitHub 上:
- https://github.com/medcl/elasticsearch-analysis-ik
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如 “游戏好玩” 会被分为”游”,”戏”,”好”,”玩”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word为最细粒度划分!
安装
第一种:
- 首先打开分词器官网:https://github.com/medcl/elasticsearch-analysis-ik。
- 在 https://github.com/medcl/elasticsearch-analysis-ik/releases 页面找到最新的正式版,下载下来。我们这里的下载链接是 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip。
- 将下载文件解压。
- 在 es/plugins 目录下,新建 ik 目录,并将解压后的所有文件拷贝到 ik 目录下。
- 重启 es 服务。
第二种:
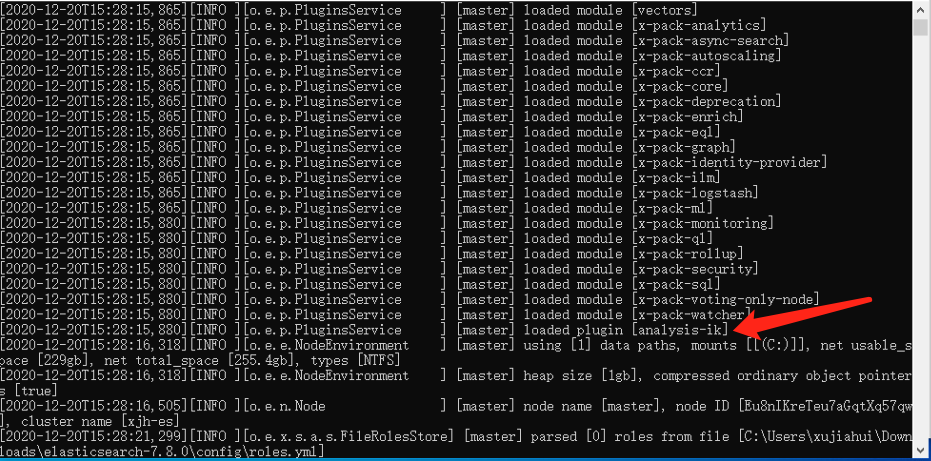
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip安装成功:
测试:
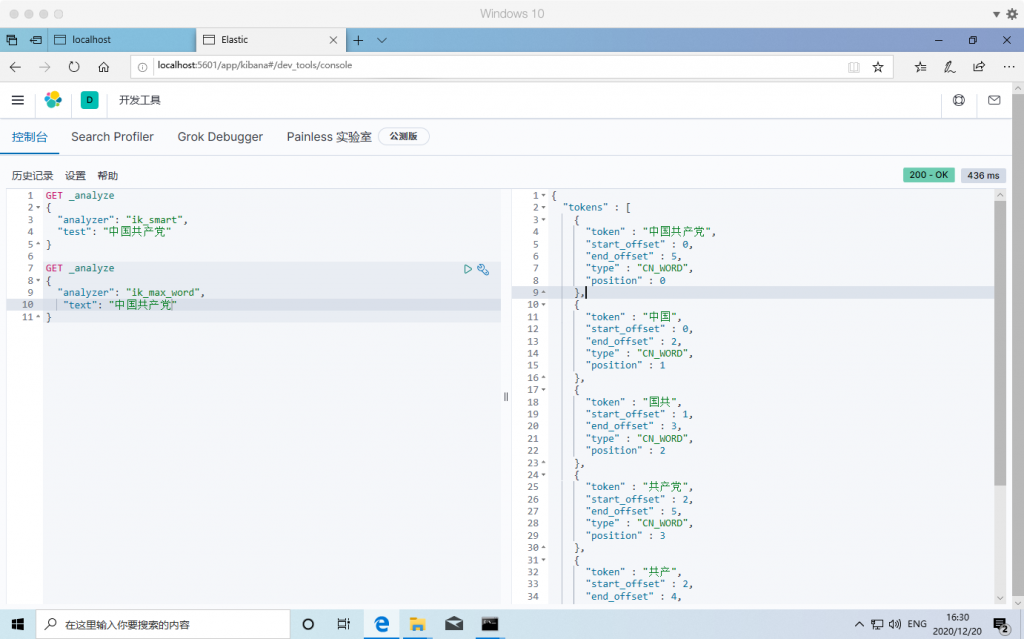
ik_max_word : 细粒度分词,会穷尽一个语句中所有分词可能
ik_smart : 粗粒度分词,优先匹配最长词,只有1个词!
自定义扩展词库
本地自定义
在 es/plugins/ik/config 目录下,新建 ext.dic 文件(文件名任意),在该文件中可以配置自定义的词库。
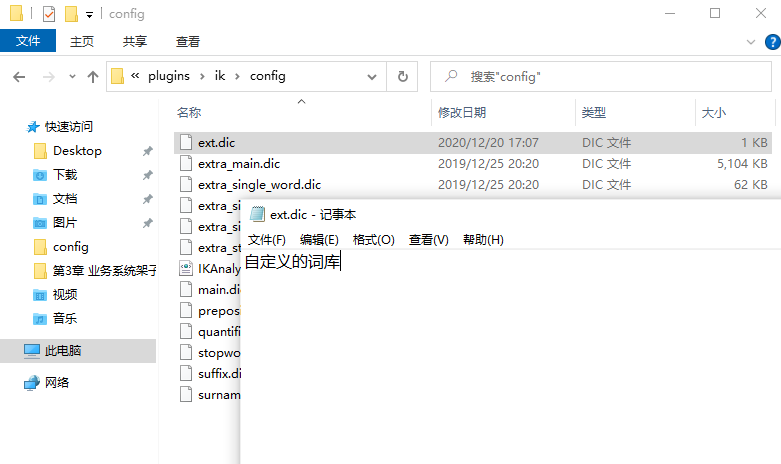
如果有多个词,换行写入新词即可。
然后在 es/plugins/ik/config/IKAnalyzer.cfg.xml 中配置扩展词典的位置:

远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 es 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
具体使用方式如下,新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 ext.dic 文件,写入扩展词:
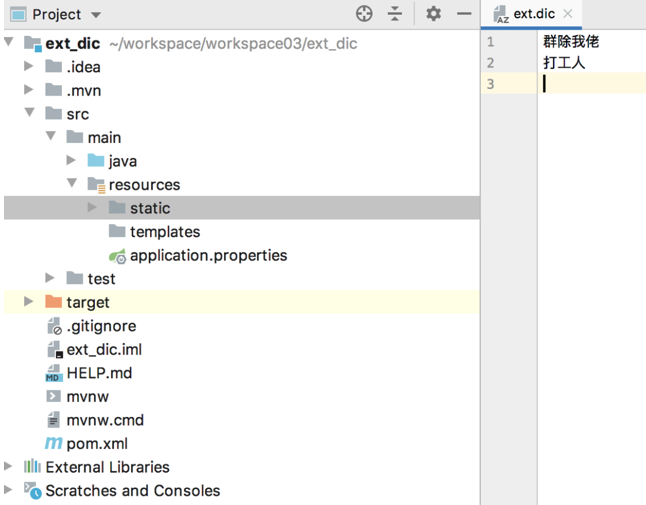
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展词接口:

配置完成后,重启 es ,即可生效。
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展
